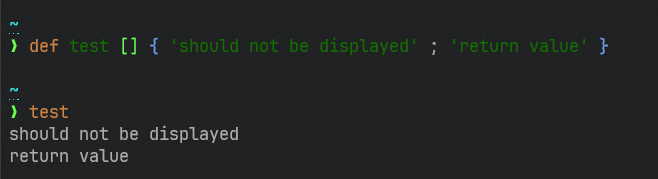
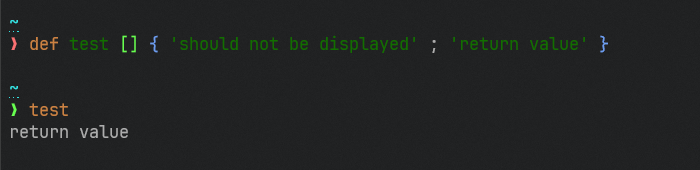
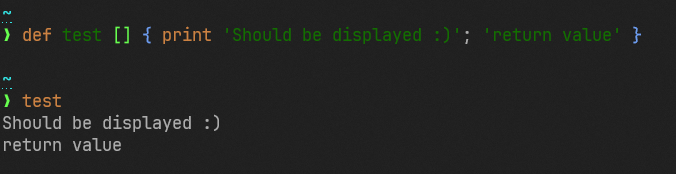
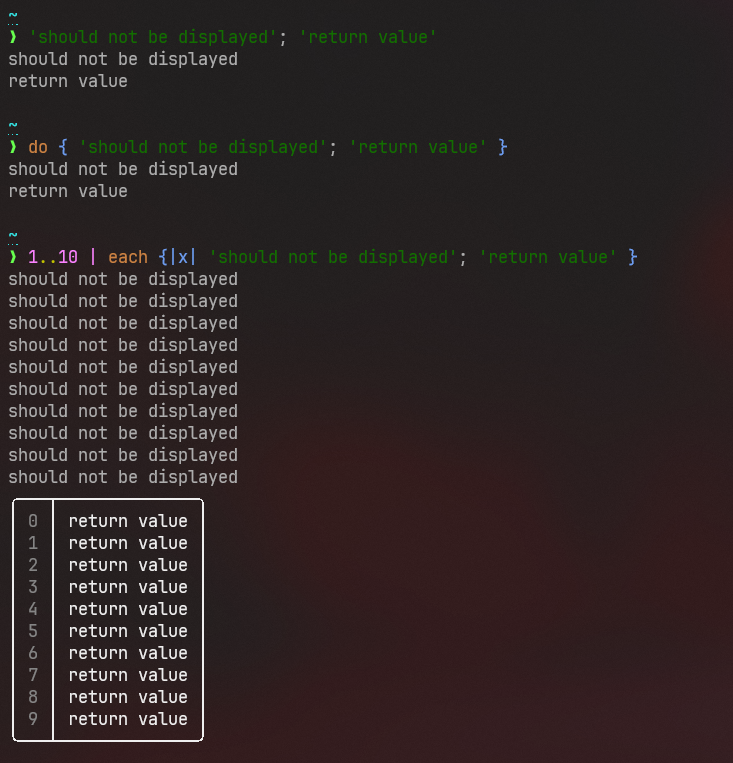
This is a follow-up to https://github.com/nushell/nushell/pull/8379 and
https://github.com/nushell/nushell/discussions/8502.
This PR makes it so that the new `?` syntax for marking a path member as
optional short-circuits, as voted on in the
[8502](https://github.com/nushell/nushell/discussions/8502) poll.
Previously, `{ foo: 123 }.bar?.baz` would raise an error:
```
> { foo: 123 }.bar?.baz
× Data cannot be accessed with a cell path
╭─[entry #15:1:1]
1 │ { foo: 123 }.bar?.baz
· ─┬─
· ╰── nothing doesn't support cell paths
╰────
```
Here's what was happening:
1. The `bar?` path member access returns `nothing` because there is no field named `bar` on the record
2. The `baz` path member access fails when trying to access a `baz` field on that `nothing` value
After this change, `{ foo: 123 }.bar?.baz` returns `nothing`; the failed `bar?` access immediately returns `nothing` and the `baz` access never runs.
# Description
Resolves issue #8370
Adds the following flags to commands `from csv` and `from tsv`:
- `--flexible`: allow the number of fields in records to be variable
- `-c --comment`: a comment character to ignore lines starting with it
- `-q --quote`: a quote character to ignore separators in strings,
defaults to '\"'
- `-e --escape`: an escape character for strings containing the quote
character
Internally, the `Value` struct has an additional helper function
`as_char` which converts it to a single `char`
# User-Facing Changes
The single quoted string `'\t'` can no longer be used as a parameter for
the flag `--separator '\t'` as it is interpreted as a two-character
string. One needs to use from now on the flag with a double quoted
string like so: `-s "\t"` which correctly interprets the string as a
single `char`.
This is a follow up from https://github.com/nushell/nushell/pull/7540.
Please provide feedback if you have the time!
## Summary
This PR lets you use `?` to indicate that a member in a cell path is
optional and Nushell should return `null` if that member cannot be
accessed.
Unlike the previous PR, `?` is now a _postfix_ modifier for cell path
members. A cell path of `.foo?.bar` means that `foo` is optional and
`bar` is not.
`?` does _not_ suppress all errors; it is intended to help in situations
where data has "holes", i.e. the data types are correct but something is
missing. Type mismatches (like trying to do a string path access on a
date) will still fail.
### Record Examples
```bash
{ foo: 123 }.foo # returns 123
{ foo: 123 }.bar # errors
{ foo: 123 }.bar? # returns null
{ foo: 123 } | get bar # errors
{ foo: 123 } | get bar? # returns null
{ foo: 123 }.bar.baz # errors
{ foo: 123 }.bar?.baz # errors because `baz` is not present on the result from `bar?`
{ foo: 123 }.bar.baz? # errors
{ foo: 123 }.bar?.baz? # returns null
```
### List Examples
```
〉[{foo: 1} {foo: 2} {}].foo
Error: nu:🐚:column_not_found
× Cannot find column
╭─[entry #30:1:1]
1 │ [{foo: 1} {foo: 2} {}].foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
〉[{foo: 1} {foo: 2} {}].foo?
╭───┬───╮
│ 0 │ 1 │
│ 1 │ 2 │
│ 2 │ │
╰───┴───╯
〉[{foo: 1} {foo: 2} {}].foo?.2 | describe
nothing
〉[a b c].4? | describe
nothing
〉[{foo: 1} {foo: 2} {}] | where foo? == 1
╭───┬─────╮
│ # │ foo │
├───┼─────┤
│ 0 │ 1 │
╰───┴─────╯
```
# Breaking changes
1. Column names with `?` in them now need to be quoted.
2. The `-i`/`--ignore-errors` flag has been removed from `get` and
`select`
1. After this PR, most `get` error handling can be done with `?` and/or
`try`/`catch`.
4. Cell path accesses like this no longer work without a `?`:
```bash
〉[{a:1 b:2} {a:3}].b.0
2
```
We had some clever code that was able to recognize that since we only
want row `0`, it's OK if other rows are missing column `b`. I removed
that because it's tricky to maintain, and now that query needs to be
written like:
```bash
〉[{a:1 b:2} {a:3}].b?.0
2
```
I think the regression is acceptable for now. I plan to do more work in
the future to enable streaming of cell path accesses, and when that
happens I'll be able to make `.b.0` work again.
# Description
The correction made here concerns the issue #8431. Indeed, the algorithm
initially proposed to remove elements of a `vector` performed a loop
with `remove` and an incident therefore appeared when several values
were equal because the deletion was done outside the length of the
vector:
```rust
let mut found = false;
for (i, col) in cols.clone().iter().enumerate() {
if col == col_name {
cols.remove(i);
vals.remove(i);
found = true;
}
}
```
Then, `[[a, a]; [1, 2]] | reject a: ` gave `thread 'main' panicked at
'removal index (is 1) should be < len (is 1)',
crates/nu-protocol/src/value/mod.rs:1213:54`.
The proposed correction is therefore the implementation of the
`retain_mut` utility dedicated to this functionality.
```rust
let mut found = false;
let mut index = 0;
cols.retain_mut(|col| {
if col == col_name {
found = true;
vals.remove(index);
false
} else {
index += 1;
true
}
});
```
# Description
Our `ShellError` at the moment has a `std::mem::size_of<ShellError>` of
136 bytes (on AMD64). As a result `Value` directly storing the struct
also required 136 bytes (thanks to alignment requirements).
This change stores the `Value::Error` `ShellError` on the heap.
Pro:
- Value now needs just 80 bytes
- Should be 1 cacheline less (still at least 2 cachelines)
Con:
- More small heap allocations when dealing with `Value::Error`
- More heap fragmentation
- Potential for additional required memcopies
# Further code changes
Includes a small refactor of `try` due to a type mismatch in its large
match.
# User-Facing Changes
None for regular users.
Plugin authors may have to update their matches on `Value` if they use
`nu-protocol`
Needs benchmarking to see if there is a benefit in real world workloads.
**Update** small improvements in runtime for workloads with high volume
of values. Significant reduction in maximum resident set size, when many
values are held in memory.
# Tests + Formatting
# Description
Fix for data ambiguity noted in #8244.
Basic change is to use nanosecond resolution for unix timestamps (stored
in type Int). Previously, a timestamp might have seconds, milliseconds
or nanoseconds, but it turned out there were overlaps in data ranges
between different resolutions, so there wasn't always a unique mapping
back to date/time.
Due to higher precision, the *range* of dates that timestamps can map to
is restricted. Unix timestamps with seconds resolution and 64 bit
storage can cover all dates from the Big Bang to eternity. Timestamps
with seconds resolution and 32 bit storage can only represent dates from
1901-12-13 through 2038-01-19. The nanoseconds resolution and 64 bit
storage used with this fix can represent dates from 1677-09-21T00:12:44
to 2262-04-11T23:47:16, something of a compromise.
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
## `<datetime> | into int`
Converts to nanosecond resolution
```rust
〉date now | into int
1678084730502126846
```
This is the number of non-leap nanoseconds after the unix epoch date:
1970-01-01T00:00:00+00:00.
Conversion fails for dates outside the supported range:
```rust
〉1492-10-12 | into int
Error: nu:🐚:incorrect_value
× Incorrect value.
╭─[entry #51:1:1]
1 │ 1492-10-12 | into int
· ────┬───
· ╰── DateTime out of timestamp range 1677-09-21T00:12:43 and 2262-04-11T23:47:16
╰────
```
## `<int> | into datetime`
Can no longer fail or produce incorrect results for any 64-bit input:
```rust
〉0 | into datetime
Thu, 01 Jan 1970 00:00:00 +0000 (53 years ago)
〉"7fffffffffffffff" | into int -r 16 | into datetime
Fri, 11 Apr 2262 23:47:16 +0000 (in 239 years)
〉("7fffffffffffffff" | into int -r 16) * -1 | into datetime
Tue, 21 Sep 1677 00:12:43 +0000 (345 years ago)
```
## `<date> | date to-record` and `<date> | date to-table`
Now both have a `nanosecond` field.
```rust
〉"7fffffffffffffff" | into int -r 16 | into datetime | date to-record
╭────────────┬───────────╮
│ year │ 2262 │
│ month │ 4 │
│ day │ 11 │
│ hour │ 23 │
│ minute │ 47 │
│ second │ 16 │
│ nanosecond │ 854775807 │
│ timezone │ +00:00 │
╰────────────┴───────────╯
〉"7fffffffffffffff" | into int -r 16 | into datetime | date to-table
╭───┬──────┬───────┬─────┬──────┬────────┬────────┬────────────┬──────────╮
│ # │ year │ month │ day │ hour │ minute │ second │ nanosecond │ timezone │
├───┼──────┼───────┼─────┼──────┼────────┼────────┼────────────┼──────────┤
│ 0 │ 2262 │ 4 │ 11 │ 23 │ 47 │ 16 │ 854775807 │ +00:00 │
╰───┴──────┴───────┴─────┴──────┴────────┴────────┴────────────┴──────────╯
```
This change was not mandated by the OP problem, but it is nice to be
able to see the nanosecond bits that were present in Nushell `date` type
all along.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Fixes#8341.
The `CustomValue::to_json()` function is an odd duck; it defaults to
returning `null`, and no `CustomValue` implementations override it to do
anything useful. I forgot to implement `to_json()` for `SQLiteDatabase`,
so `open foo.db | to json` was returning `null`.
To fix this, I've removed `CustomValue::to_json()` and now `to json`
will collect a `CustomValue` into a regular `Value` before doing a JSON
conversion.
Continuation of #8229 and #8326
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
# Call to action
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Commits (so far)
- Remove `ShellError::FeatureNotEnabled`
- Name fields on `SE::ExternalNotSupported`
- Name field on `SE::InvalidProbability`
- Name fields on `SE::NushellFailed` variants
- Remove unused `SE::NushellFailedSpannedHelp`
- Name field on `SE::VariableNotFoundAtRuntime`
- Name fields on `SE::EnvVarNotFoundAtRuntime`
- Name fields on `SE::ModuleNotFoundAtRuntime`
- Remove usused `ModuleOrOverlayNotFoundAtRuntime`
- Name fields on `SE::OverlayNotFoundAtRuntime`
- Name field on `SE::NotFound`
Continuation of #8229
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
- Name fields of `SE::IncorrectValue`
- Merge and name fields on `SE::TypeMismatch`
- Name fields on `SE::UnsupportedOperator`
- Name fields on `AssignmentRequires*` and fix doc
- Name fields on `SE::UnknownOperator`
- Name fields on `SE::MissingParameter`
- Name fields on `SE::DelimiterError`
- Name fields on `SE::IncompatibleParametersSingle`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
Feel free to add review comments if you spot inconsistent use of
`ShellError` variants.
- Name fields on `ShellError::OperatorOverflow`
- Name fields on `ShellError::PipelineMismatch`
- Add doc to `ShellError::OnlySupportsThisInputType`
- Name `ShellError::OnlySupportsThisInputType`
- Name field on `ShellError::PipelineEmpty`
- Comment about issues with `TypeMismatch*`
- Fix a few `exp_input_type`s
- Name fields on `ShellError::InvalidRange`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
As title, I found this feature is useful to me too :)
Closes: #8039
# User-Facing Changes
```
❯ 3 * "ab"
ababab
❯ 3 * [1 2 3]
╭───┬───╮
│ 0 │ 1 │
│ 1 │ 2 │
│ 2 │ 3 │
│ 3 │ 1 │
│ 4 │ 2 │
│ 5 │ 3 │
│ 6 │ 1 │
│ 7 │ 2 │
│ 8 │ 3 │
╰───┴───╯
```
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
I noticed that `open some_big_file | into binary` cannot be cancelled
with `ctrl+c`.
This small PR fixes that by checking `ctrl+c` in
`RawStream::into_bytes()`, and does the same in
`RawStream::into_string()` for good measure.
This PR makes `++` (the append operator) work with strings and binary
values. Can now do things like:
```bash
〉"a" ++ "b"
ab
〉0x[01 02] ++ 0x[03]
Length: 3 (0x3) bytes | printable whitespace ascii_other non_ascii
00000000: 01 02 03 •••
```
Closes#8015.
# Description
Closes#6768.
BEFORE:
```
〉{ foo: [{a:1, b:2},2,3,4,5] }
╭─────┬────────────────╮
│ foo │ [table 5 rows] │
╰─────┴────────────────╯
```
AFTER:
```
〉{ foo: [{a:1, b:2},2,3,4,5] }
╭─────┬────────────────╮
│ foo │ [list 5 items] │
╰─────┴────────────────╯
```
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
# Description
This PR bumps the required rust version to 1.66.1.
# User-Facing Changes
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This is an attempt to implement a new `Value::LazyRecord` variant for
performance reasons.
`LazyRecord` is like a regular `Record`, but it's possible to access
individual columns without evaluating other columns. I've implemented
`LazyRecord` for the special `$nu` variable; accessing `$nu` is
relatively slow because of all the information in `scope`, and [`$nu`
accounts for about 2/3 of Nu's startup time on
Linux](https://github.com/nushell/nushell/issues/6677#issuecomment-1364618122).
### Benchmarks
I ran some benchmarks on my desktop (Linux, 12900K) and the results are
very pleasing.
Nu's time to start up and run a command (`cargo build --release;
hyperfine 'target/release/nu -c "echo \"Hello, world!\""' --shell=none
--warmup 10`) goes from **8.8ms to 3.2ms, about 2.8x faster**.
Tests are also much faster! Running `cargo nextest` (with our very slow
`proptest` tests disabled) goes from **7.2s to 4.4s (1.6x faster)**,
because most tests involve launching a new instance of Nu.
### Design (updated)
I've added a new `LazyRecord` trait and added a `Value` variant wrapping
those trait objects, much like `CustomValue`. `LazyRecord`
implementations must implement these 2 functions:
```rust
// All column names
fn column_names(&self) -> Vec<&'static str>;
// Get 1 specific column value
fn get_column_value(&self, column: &str) -> Result<Value, ShellError>;
```
### Serializability
`Value` variants must implement `Serializable` and `Deserializable`, which poses some problems because I want to use unserializable things like `EngineState` in `LazyRecord`s. To work around this, I basically lie to the type system:
1. Add `#[typetag::serde(tag = "type")]` to `LazyRecord` to make it serializable
2. Any unserializable fields in `LazyRecord` implementations get marked with `#[serde(skip)]`
3. At the point where a `LazyRecord` normally would get serialized and sent to a plugin, I instead collect it into a regular `Value::Record` (which can be serialized)
I have changed `assert!(a == b)` calls to `assert_eq!(a, b)`, which give
better error messages. Similarly for `assert!(a != b)` and
`assert_ne!(a, b)`. Basically all instances were comparing primitives
(string slices or integers), so there is no loss of generality from
special-case macros,
I have also fixed a number of typos in comments, variable names, and a
few user-facing messages.
# Description
_(Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.)_
I implemented the status bar we talk about yesterday. The idea was
inspired by the progress bar of `wget`.
I decided to go for the second suggestion by `@Reilly`
> 2. add an Option<usize> or whatever to RawStream (and ListStream?) for
situations where you do know the length ahead of time
For now only works with the command `save` but after the approve of this
PR we can see how we can implement it on commands like `cp` and `mv`
When using `fetch` nushell will check if there is any `content-length`
attribute in the request header. If so, then `fetch` will send it
through the new `Option` variable in the `RawStream` to the `save`.
If we know the total size we show the progress bar

but if we don't then we just show the stats like: data already saved,
bytes per second, and time lapse.


Please let me know If I need to make any changes and I will be happy to
do it.
# User-Facing Changes
A new flag (`--progress` `-p`) was added to the `save` command
Examples:
```nu
fetch https://github.com/torvalds/linux/archive/refs/heads/master.zip | save --progress -f main.zip
fetch https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso | save --progress -f main.zip
open main.zip --raw | save --progress main.copy
```
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
-
I am getting some errors and its weird because the errors are showing up
in files i haven't touch. Is this normal?
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: Reilly Wood <reilly.wood@icloud.com>
# Description
This closes#7498, as well as fixes an issue reported in
https://github.com/nushell/nushell/pull/7002#issuecomment-1368340773
BEFORE:
```
〉[{foo: 'bar'} {}] | get foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #5:1:1]
1 │ [{foo: 'bar'} {}] | get foo
· ────────┬──────── ─┬─
· │ ╰── value originates here
· ╰── cannot find column 'Empty cell'
╰────
〉[{foo: 'bar'} {}].foo
╭───┬─────╮
│ 0 │ bar │
│ 1 │ │
╰───┴─────╯
```
AFTER:
```
〉[{foo: 'bar'} {}] | get foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #1:1:1]
1 │ [{foo: 'bar'} {}] | get foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
〉[{foo: 'bar'} {}].foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #3:1:1]
1 │ [{foo: 'bar'} {}].foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
```
EDIT: This also changes the semantics of `get`/`select` `-i` somewhat.
I've decided to leave it like this because it works more intuitively
with `default` and `compact`.
BEFORE:
```
〉[{a:1} {b:2} {a:3}] | select -i foo | to nuon
null
```
AFTER:
```
〉[{a:1} {b:2} {a:3}] | select -i foo | to nuon
[[foo]; [null], [null], [null]]
```
# User-Facing Changes
See above. EDIT: the issue with holes in cases like ` [{foo: 'bar'}
{}].foo.0` versus ` [{foo: 'bar'} {}].0.foo` has been resolved.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Closes#7572 by adding a cache for compiled regexes of type
`Arc<Mutex<LruCache<String, Regex>>>` to `EngineState` .
The cache is limited to 100 entries (limit chosen arbitrarily) and
evicts least-recently-used items first.
This PR makes a noticeable difference when using regexes for
`color_config`, e.g.:
```bash
#first set string formatting in config.nu like:
string: { if $in =~ '^#\w{6}$' { $in } else { 'white' } }`
# then try displaying and exploring a table with many strings
# this is instant after the PR, but takes hundreds of milliseconds before
['#ff0033', '#0025ee', '#0087aa', 'string', '#4101ff', '#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff', '#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff', '#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff', '#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff','#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff','#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff','#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff','#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff','#ff0033', '#0025ee', '#0087aa', 'string', '#6103ff']
```
## New dependency (`lru`)
This uses [the popular `lru` crate](https://lib.rs/crates/lru). The new
dependency adds 19.8KB to a Linux release build of Nushell. I think this
is OK, especially since the crate can be useful elsewhere in Nu.
# Description
* I was dismayed to discover recently that UnsupportedInput and
TypeMismatch are used *extremely* inconsistently across the codebase.
UnsupportedInput is sometimes used for input type-checks (as per the
name!!), but *also* used for argument type-checks. TypeMismatch is also
used for both.
I thus devised the following standard: input type-checking *only* uses
UnsupportedInput, and argument type-checking *only* uses TypeMismatch.
Moreover, to differentiate them, UnsupportedInput now has *two* error
arrows (spans), one pointing at the command and the other at the input
origin, while TypeMismatch only has the one (because the command should
always be nearby)
* In order to apply that standard, a very large number of
UnsupportedInput uses were changed so that the input's span could be
retrieved and delivered to it.
* Additionally, I noticed many places where **errors are not propagated
correctly**: there are lots of `match` sites which take a Value::Error,
then throw it away and replace it with a new Value::Error with
less/misleading information (such as reporting the error as an
"incorrect type"). I believe that the earliest errors are the most
important, and should always be propagated where possible.
* Also, to standardise one broad subset of UnsupportedInput error
messages, who all used slightly different wordings of "expected
`<type>`, got `<type>`", I created OnlySupportsThisInputType as a
variant of it.
* Finally, a bunch of error sites that had "repeated spans" - i.e. where
an error expected two spans, but `call.head` was given for both - were
fixed to use different spans.
# Example
BEFORE
```
〉20b | str starts-with 'a'
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #31:1:1]
1 │ 20b | str starts-with 'a'
· ┬
· ╰── Input's type is filesize. This command only works with strings.
╰────
〉'a' | math cos
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #33:1:1]
1 │ 'a' | math cos
· ─┬─
· ╰── Only numerical values are supported, input type: String
╰────
〉0x[12] | encode utf8
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #38:1:1]
1 │ 0x[12] | encode utf8
· ───┬──
· ╰── non-string input
╰────
```
AFTER
```
〉20b | str starts-with 'a'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ 20b | str starts-with 'a'
· ┬ ───────┬───────
· │ ╰── only string input data is supported
· ╰── input type: filesize
╰────
〉'a' | math cos
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #2:1:1]
1 │ 'a' | math cos
· ─┬─ ────┬───
· │ ╰── only numeric input data is supported
· ╰── input type: string
╰────
〉0x[12] | encode utf8
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #3:1:1]
1 │ 0x[12] | encode utf8
· ───┬── ───┬──
· │ ╰── only string input data is supported
· ╰── input type: binary
╰────
```
# User-Facing Changes
Various error messages suddenly make more sense (i.e. have two arrows
instead of one).
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Currently, `filesize_format`/`filesize_metric` conflicts are resolved as
follows: if the `filesize_format` ends in "ib", then that overrides
`filesize_metric`, otherwise, `filesize_metric` overrides
`filesize_format`. This removes this difficult-to-predict asymmetric
behaviour, and makes it so that `filesize_metric` always overrides
`filesize_format`.
This also adds tests for `$env.config.filesize.format` and
`$env.config.filesize.metric` values.
REMINDER: `filesize_metric` means "increments of 1000", and refers to
KB-MB-GB-TB etc.
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
A follow-up to #7497. That change made it so that `get foo` would
eliminate non-record rows; I think that was an unintentional and
undesirable side-effect.
Before #7497:
```bash
〉[$nothing, { item: "foo" }] | get item
╭───┬─────╮
│ 0 │ │
│ 1 │ foo │
╰───┴─────╯
```
After #7497:
```bash
〉[$nothing, {item: "foo"}] | get item
╭───┬─────╮
│ 0 │ foo │
╰───┴─────╯
```
After this PR:
```bash
〉[$nothing, { item: "foo" }] | get item
╭───┬─────╮
│ 0 │ │
│ 1 │ foo │
╰───┴─────╯
```
cc: @merelymyself
# Description
Fixes#7494.
```
/home/gabriel/CodingProjects/nushell〉[[{foo: bar}]] | get foo 12/16/2022 12:31:17 PM
Error: nu::parser::not_found (link)
× Not found.
╭─[entry #1:1:1]
1 │ [[{foo: bar}]] | get foo
· ───────┬──────
· ╰── did not find anything under this name
╰────
```
# User-Facing Changes
cell paths no longer drill into nested tables.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
I've been working on streaming and pipeline interruption lately. It was
bothering me that checking ctrl+c (something we want to do often) always
requires a bunch of boilerplate like:
```rust
use std::sync::atomic::Ordering;
if let Some(ctrlc) = &engine_state.ctrlc {
if ctrlc.load(Ordering::SeqCst) {
...
```
I added a helper method to cut that down to:
```rust
if nu_utils::ctrl_c::was_pressed(&engine_state.ctrlc) {
...
```
# Description
Closes#7059. Rather than generate a new Record each time $env.config is
accessed (as described in that issue), instead `$env.config = ` now A)
parses the input record, then B) un-parses it into a clean Record with
only the valid values, and stores that as an env-var. The reasoning for
this is that I believe `config_to_nu_record()` (the method that performs
step B) will be useful in later PRs. (See below)
As a result, this also "fixes" the following "bug":
```
〉$env.config = 'butts'
$env.config is not a record
〉$env.config
butts
```
~~Instead, `$env.config = 'butts'` now turns `$env.config` into the
default (not the default config.nu, but `Config::default()`, which
notably has empty keybindings, color_config, menus and hooks vecs).~~
This doesn't attempt to fix#7110. cc @Kangaxx-0
# Example of new behaviour
OLD:
```
〉$env.config = ($env.config | merge { foo: 1 })
$env.config.foo is an unknown config setting
〉$env.config.foo
1
```
NEW:
```
〉$env.config = ($env.config | merge { foo: 1 })
Error:
× Config record contains invalid values or unknown settings
Error:
× Error while applying config changes
╭─[entry #1:1:1]
1 │ $env.config = ($env.config | merge { foo: 1 })
· ┬
· ╰── $env.config.foo is an unknown config setting
╰────
help: This value has been removed from your $env.config record.
〉$env.config.foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #1:1:1]
1 │ $env.config = ($env.config | merge { foo: 1 })
· ──┬──
· ╰── value originates here
╰────
╭─[entry #2:1:1]
1 │ $env.config.foo
· ─┬─
· ╰── cannot find column 'foo'
╰────
```
# Example of new errors
OLD:
```
$env.config.cd.baz is an unknown config setting
$env.config.foo is an unknown config setting
$env.config.bar is an unknown config setting
$env.config.table.qux is an unknown config setting
$env.config.history.qux is an unknown config setting
```
NEW:
```
Error:
× Config record contains invalid values or unknown settings
Error:
× Error while applying config changes
╭─[C:\Users\Leon\AppData\Roaming\nushell\config.nu:267:1]
267 │ abbreviations: true # allows `cd s/o/f` to expand to `cd some/other/folder`
268 │ baz: 3,
· ┬
· ╰── $env.config.cd.baz is an unknown config setting
269 │ }
╰────
help: This value has been removed from your $env.config record.
Error:
× Error while applying config changes
╭─[C:\Users\Leon\AppData\Roaming\nushell\config.nu:269:1]
269 │ }
270 │ foo: 1,
· ┬
· ╰── $env.config.foo is an unknown config setting
271 │ bar: 2,
╰────
help: This value has been removed from your $env.config record.
Error:
× Error while applying config changes
╭─[C:\Users\Leon\AppData\Roaming\nushell\config.nu:270:1]
270 │ foo: 1,
271 │ bar: 2,
· ┬
· ╰── $env.config.bar is an unknown config setting
╰────
help: This value has been removed from your $env.config record.
Error:
× Error while applying config changes
╭─[C:\Users\Leon\AppData\Roaming\nushell\config.nu:279:1]
279 │ }
280 │ qux: 4,
· ┬
· ╰── $env.config.table.qux is an unknown config setting
281 │ }
╰────
help: This value has been removed from your $env.config record.
Error:
× Error while applying config changes
╭─[C:\Users\Leon\AppData\Roaming\nushell\config.nu:285:1]
285 │ file_format: "plaintext" # "sqlite" or "plaintext"
286 │ qux: 2
· ┬
· ╰── $env.config.history.qux is an unknown config setting
287 │ }
╰────
help: This value has been removed from your $env.config record.
```
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
While perusing Value.rs, I noticed the `Value::int()`, `Value::float()`,
`Value::boolean()` and `Value::string()` constructors, which seem
designed to make it easier to construct various Values, but which aren't
used often at all in the codebase. So, using a few find-replaces
regexes, I increased their usage. This reduces overall LOC because
structures like this:
```
Value::Int {
val: a,
span: head
}
```
are changed into
```
Value::int(a, head)
```
and are respected as such by the project's formatter.
There are little readability concerns because the second argument to all
of these is `span`, and it's almost always extremely obvious which is
the span at every callsite.
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Closes#7110. ~~Note that unlike "real" `mut` vars, $env can be deeply
mutated via stuff like `$env.PYTHON_IO_ENCODING = utf8` or
`$env.config.history.max_size = 2000`. So, it's a slightly awkward
special case, arguably justifiable because of what $env represents (the
environment variables of your system, which is essentially "outside"
normal Nushell regulations).~~
EDIT: Now allows all `mut` vars to be deeply mutated using `=`, on
request.
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Also enforce this by #[non_exhaustive] span such that going forward we
cannot, in debug builds (1), construct invalid spans.
The motivation for this stems from #6431 where I've seen crashes due to
invalid slice indexing.
My hope is this will mitigate such senarios
1. https://github.com/nushell/nushell/pull/6431#issuecomment-1278147241
# Description
(description of your pull request here)
# Tests
Make sure you've done the following:
- [ ] Add tests that cover your changes, either in the command examples,
the crate/tests folder, or in the /tests folder.
- [ ] Try to think about corner cases and various ways how your changes
could break. Cover them with tests.
- [ ] If adding tests is not possible, please document in the PR body a
minimal example with steps on how to reproduce so one can verify your
change works.
Make sure you've run and fixed any issues with these commands:
- [x] `cargo fmt --all -- --check` to check standard code formatting
(`cargo fmt --all` applies these changes)
- [ ] `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- [ ] `cargo test --workspace --features=extra` to check that all the
tests pass
# Documentation
- [ ] If your PR touches a user-facing nushell feature then make sure
that there is an entry in the documentation
(https://github.com/nushell/nushell.github.io) for the feature, and
update it if necessary.
Fixes#7246 and #1898.
Darren noticed that `open /dev/random` could not be interrupted by
`ctrl+c`. Thankfully the solution was very simple; it looks like we just
forgot to check `ctrlc` in the `impl Iterator for RawStream`!
To reproduce this, just run `open /dev/random` and then cancel it with
`ctrl+c`.
We already have the binary `bit-xor` and the shortcircuiting logical
`or`(`||`) and `and`(`&&`).
This introduces `xor` as a compact form for both brevity and clarity.
You can express the operation through `not`/`and`/`or` with a slight
risk of introducing bugs through typos.
Operator precedence
`and` > `xor` > `or`
Added logic and precedence tests.
# Description
This command converts things into records.
<img width="466" alt="Screenshot 2022-11-24 at 2 10 54 PM"
src="https://user-images.githubusercontent.com/343840/203858104-0e4445da-9c37-4c7c-97ec-68ec3515bc4b.png">
<img width="716" alt="Screenshot 2022-11-24 at 5 04 11 PM"
src="https://user-images.githubusercontent.com/343840/203872621-48cab199-ba57-44fe-8f36-9e1469b9c4ef.png">
It also converts dates into record but I couldn't get the test harness
to accept an example.
Thanks to @WindSoilder for writing the "hard" parts of this. :)
_(Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.)_
_(Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.)_
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: WindSoilder <WindSoilder@outlook.com>
This adds new pipeline connectors called out> and err> which redirect either stdout or stderr to a file. You can also use out+err> (or err+out>) to redirect both streams into a file.
This adds support for (limited) mutable variables. Mutable variables are created with mut much the same way immutable variables are made with let.
Mutable variables allow mutation via the assignment operator (=).
❯ mut x = 100
❯ $x = 200
❯ print $x
200
Mutable variables are limited in that they're only tended to be used in the local code block. Trying to capture a local variable will result in an error:
❯ mut x = 123; {|| $x }
Error: nu::parser::expected_keyword (link)
× Capture of mutable variable.
The intent of this limitation is to reduce some of the issues with mutable variables in general: namely they make code that's harder to reason about. By reducing the scope that a mutable variable can be used it, we can help create local reasoning about them.
Mutation can occur with fields as well, as in this case:
❯ mut y = {abc: 123}
❯ $y.abc = 456
❯ $y
On a historical note: mutable variables are something that we resisted for quite a long time, leaning as much as we could on the functional style of pipelines and dataflow. That said, we've watched folks struggle to work with reduce as an approximation for patterns that would be trivial to express with local mutation. With that in mind, we're leaning towards the happy path.
* Add failing test that list of ints and floats is List<Number>
* Start defining subtype relation
* Make it possible to declare input and output types for commands
- Enforce them in tests
* Declare input and output types of commands
* Add formatted signatures to `help commands` table
* Revert SyntaxShape::Table -> Type::Table change
* Revert unnecessary derive(Hash) on SyntaxShape
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}