16 KiB
9200 - Pentesting Elasticsearch
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
-
Travaillez-vous dans une entreprise de cybersécurité ? Voulez-vous voir votre entreprise annoncée dans HackTricks ? ou voulez-vous avoir accès à la dernière version de PEASS ou télécharger HackTricks en PDF ? Consultez les PLANS D'ABONNEMENT !
-
Découvrez The PEASS Family, notre collection exclusive de NFTs
-
Obtenez le swag officiel PEASS & HackTricks
-
Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez moi sur Twitter 🐦@carlospolopm.
-
Partagez vos astuces de piratage en soumettant des PR au repo hacktricks et au repo hacktricks-cloud.
Informations de base
À partir de la page principale, vous pouvez trouver des descriptions utiles :
Elasticsearch est un moteur de recherche et d'analyse distribué et open source pour tous les types de données, y compris textuelles, numériques, géospatiales, structurées et non structurées. Elasticsearch est construit sur Apache Lucene et a été publié pour la première fois en 2010 par Elasticsearch N.V. (maintenant connu sous le nom d'Elastic). Connu pour ses API REST simples, sa nature distribuée, sa rapidité et sa scalabilité, Elasticsearch est le composant central de l'Elastic Stack, un ensemble d'outils open source pour l'ingestion, l'enrichissement, le stockage, l'analyse et la visualisation de données. Communément appelé ELK Stack (après Elasticsearch, Logstash et Kibana), Elastic Stack comprend maintenant une riche collection d'agents d'expédition légers appelés Beats pour l'envoi de données à Elasticsearch.
Qu'est-ce qu'un index Elasticsearch ?
Un index Elasticsearch est une collection de documents qui sont liés les uns aux autres. Elasticsearch stocke les données sous forme de documents JSON. Chaque document corrèle un ensemble de clés (noms de champs ou de propriétés) avec leurs valeurs correspondantes (chaînes, nombres, booléens, dates, tableaux de valeurs, géolocalisations ou autres types de données).
Elasticsearch utilise une structure de données appelée index inversé, conçue pour permettre des recherches de texte intégral très rapides. Un index inversé répertorie chaque mot unique qui apparaît dans n'importe quel document et identifie tous les documents dans lesquels chaque mot apparaît.
Pendant le processus d'indexation, Elasticsearch stocke les documents et construit un index inversé pour rendre les données du document interrogeables en temps quasi réel. L'indexation est initiée avec l'API d'index, par laquelle vous pouvez ajouter ou mettre à jour un document JSON dans un index spécifique.
Port par défaut : 9200/tcp
Énumération manuelle
Bannière
Le protocole utilisé pour accéder à Elasticsearch est HTTP. Lorsque vous y accédez via HTTP, vous trouverez des informations intéressantes : http://10.10.10.115:9200/

Si vous ne voyez pas cette réponse en accédant à /, voir la section suivante.
Authentification
Par défaut, Elasticsearch n'a pas d'authentification activée, donc par défaut, vous pouvez accéder à tout ce qui se trouve dans la base de données sans utiliser de crédentials.
Vous pouvez vérifier que l'authentification est désactivée avec une requête à :
curl -X GET "ELASTICSEARCH-SERVER:9200/_xpack/security/user"
{"error":{"root_cause":[{"type":"exception","reason":"Security must be explicitly enabled when using a [basic] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."}],"type":"exception","reason":"Security must be explicitly enabled when using a [basic] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."},"status":500}
Cependant, si vous envoyez une requête à / et que vous recevez une réponse comme celle-ci :
{"error":{"root_cause":[{"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":"Basic realm=\"security\" charset=\"UTF-8\""}}],"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":"Basic realm=\"security\" charset=\"UTF-8\""}},"status":401}
Cela signifie que l'authentification est configurée et que vous avez besoin de valides identifiants pour obtenir des informations à partir d'Elasticsearch. Ensuite, vous pouvez essayer de le bruteforcer (il utilise l'authentification de base HTTP, donc tout ce qui peut bruteforcer l'authentification de base HTTP peut être utilisé).
Voici une liste des noms d'utilisateur par défaut : elastic (superutilisateur), remote_monitoring_user, beats_system, logstash_system, kibana, kibana_system, apm_system, _anonymous_._ Les anciennes versions d'Elasticsearch ont le mot de passe par défaut changeme pour cet utilisateur.
curl -X GET http://user:password@IP:9200/
Énumération de base des utilisateurs
Pour commencer, nous pouvons utiliser la méthode GET pour récupérer la liste des index disponibles sur Elasticsearch. Pour cela, nous pouvons envoyer une requête GET à l'URL http://<IP>:9200/_cat/indices?v. Cela nous donnera une liste des index disponibles sur le serveur Elasticsearch.
Ensuite, nous pouvons utiliser la méthode GET pour récupérer la liste des documents dans un index spécifique. Pour cela, nous pouvons envoyer une requête GET à l'URL http://<IP>:9200/<nom_de_l'index>/_search?size=1000. Cela nous donnera une liste des 1000 premiers documents dans l'index spécifié.
Enfin, nous pouvons utiliser la méthode GET pour récupérer les détails d'un document spécifique. Pour cela, nous pouvons envoyer une requête GET à l'URL http://<IP>:9200/<nom_de_l'index>/_doc/<ID_du_document>. Cela nous donnera les détails du document spécifié.
#List all roles on the system:
curl -X GET "ELASTICSEARCH-SERVER:9200/_security/role"
#List all users on the system:
curl -X GET "ELASTICSEARCH-SERVER:9200/_security/user"
#Get more information about the rights of an user:
curl -X GET "ELASTICSEARCH-SERVER:9200/_security/user/<USERNAME>"
Informations sur Elastic
Voici quelques points d'accès que vous pouvez obtenir via GET pour obtenir des informations sur Elasticsearch :
| _cat | /_cluster | /_security |
|---|---|---|
| /_cat/segments | /_cluster/allocation/explain | /_security/user |
| /_cat/shards | /_cluster/settings | /_security/privilege |
| /_cat/repositories | /_cluster/health | /_security/role_mapping |
| /_cat/recovery | /_cluster/state | /_security/role |
| /_cat/plugins | /_cluster/stats | /_security/api_key |
| /_cat/pending_tasks | /_cluster/pending_tasks | |
| /_cat/nodes | /_nodes | |
| /_cat/tasks | /_nodes/usage | |
| /_cat/templates | /_nodes/hot_threads | |
| /_cat/thread_pool | /_nodes/stats | |
| /_cat/ml/trained_models | /_tasks | |
| /_cat/transforms/_all | /_remote/info | |
| /_cat/aliases | ||
| /_cat/allocation | ||
| /_cat/ml/anomaly_detectors | ||
| /_cat/count | ||
| /_cat/ml/data_frame/analytics | ||
| /_cat/ml/datafeeds | ||
| /_cat/fielddata | ||
| /_cat/health | ||
| /_cat/indices | ||
| /_cat/master | ||
| /_cat/nodeattrs | ||
| /_cat/nodes |
Ces points d'accès ont été pris à partir de la documentation où vous pouvez en trouver plus.
De plus, si vous accédez à /_cat, la réponse contiendra les points d'accès /_cat/* pris en charge par l'instance.
Dans /_security/user (si l'authentification est activée), vous pouvez voir quel utilisateur a le rôle de superuser.
Indices
Vous pouvez rassembler tous les indices en accédant à http://10.10.10.115:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana 6tjAYZrgQ5CwwR0g6VOoRg 1 0 1 0 4kb 4kb
yellow open quotes ZG2D1IqkQNiNZmi2HRImnQ 5 1 253 0 262.7kb 262.7kb
yellow open bank eSVpNfCfREyYoVigNWcrMw 5 1 1000 0 483.2kb 483.2kb
Pour obtenir des informations sur le type de données stockées dans un index, vous pouvez accéder à : http://host:9200/<index> par exemple dans ce cas http://10.10.10.115:9200/bank

Dump de l'index
Si vous voulez dump tous les contenus d'un index, vous pouvez accéder à : http://host:9200/<index>/_search?pretty=true comme http://10.10.10.115:9200/bank/_search?pretty=true

Prenez un moment pour comparer le contenu de chaque document (entrée) à l'intérieur de l'index bancaire et les champs de cet index que nous avons vus dans la section précédente.
Ainsi, à ce stade, vous pouvez remarquer qu'il y a un champ appelé "total" à l'intérieur de "hits" qui indique que 1000 documents ont été trouvés à l'intérieur de cet index mais seulement 10 ont été récupérés. C'est parce que par défaut, il y a une limite de 10 documents.
Mais maintenant que vous savez que cet index contient 1000 documents, vous pouvez dump tous les documents en indiquant le nombre d'entrées que vous voulez dans le paramètre size : http://10.10.10.115:9200/quotes/_search?pretty=true&size=1000
Remarque : Si vous indiquez un nombre plus grand, toutes les entrées seront quand même dumpées, par exemple vous pourriez indiquer size=9999 et ce serait étrange s'il y avait plus d'entrées (mais vous devriez vérifier).
Dump de tout
Pour tout dump, vous pouvez simplement aller sur le même chemin qu'avant mais sans indiquer aucun index http://host:9200/_search?pretty=true comme http://10.10.10.115:9200/_search?pretty=true
Rappelez-vous que dans ce cas, la limite par défaut de 10 résultats sera appliquée. Vous pouvez utiliser le paramètre size pour dump une plus grande quantité de résultats. Lisez la section précédente pour plus d'informations.
Recherche
Si vous cherchez des informations, vous pouvez faire une recherche brute sur tous les index en allant à http://host:9200/_search?pretty=true&q=<search_term> comme dans http://10.10.10.115:9200/_search?pretty=true&q=Rockwell

Si vous voulez simplement chercher dans un index, vous pouvez simplement le spécifier sur le chemin : http://host:9200/<index>/_search?pretty=true&q=<search_term>
Remarquez que le paramètre q utilisé pour rechercher le contenu prend en charge les expressions régulières
Vous pouvez également utiliser quelque chose comme https://github.com/misalabs/horuz pour fuzz un service elasticsearch.
Permissions d'écriture
Vous pouvez vérifier vos permissions d'écriture en essayant de créer un nouveau document dans un nouvel index en exécutant quelque chose comme ce qui suit :
curl -X POST '10.10.10.115:9200/bookindex/books' -H 'Content-Type: application/json' -d'
{
"bookId" : "A00-3",
"author" : "Sankaran",
"publisher" : "Mcgrahill",
"name" : "how to get a job"
}'
Cette commande va créer un nouvel index appelé bookindex avec un document de type books qui a les attributs "bookId", "author", "publisher" et "name"
Remarquez comment le nouvel index apparaît maintenant dans la liste:
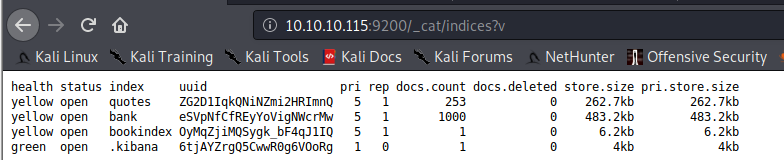
Et notez les propriétés créées automatiquement:

Énumération automatique
Certains outils obtiendront certaines des données présentées précédemment:
msf > use auxiliary/scanner/elasticsearch/indices_enum
Shodan
port:9200 elasticsearch
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
-
Travaillez-vous dans une entreprise de cybersécurité ? Voulez-vous voir votre entreprise annoncée dans HackTricks ? ou voulez-vous avoir accès à la dernière version de PEASS ou télécharger HackTricks en PDF ? Consultez les PLANS D'ABONNEMENT !
-
Découvrez The PEASS Family, notre collection exclusive de NFTs
-
Obtenez le swag officiel PEASS & HackTricks
-
Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez moi sur Twitter 🐦@carlospolopm.
-
Partagez vos astuces de piratage en soumettant des PR au repo hacktricks et au repo hacktricks-cloud.