| .. | ||
| heap-overflow.md | ||
| README.md | ||
| use-after-free.md | ||
Montón
Conceptos básicos del montón
El montón es básicamente el lugar donde un programa podrá almacenar datos cuando solicite datos llamando a funciones como malloc, calloc... Además, cuando esta memoria ya no sea necesaria, estará disponible llamando a la función free.
Como se muestra, está justo después de donde se carga el binario en la memoria (ver la sección [heap]):

Asignación básica de fragmentos
Cuando se solicita almacenar algunos datos en el montón, se asigna un espacio del montón para ello. Este espacio pertenecerá a un bin y solo se reservará para el fragmento los datos solicitados + el espacio de los encabezados del bin + el desplazamiento mínimo del tamaño del bin. El objetivo es reservar la menor cantidad de memoria posible sin complicar la búsqueda de cada fragmento. Para esto, se utiliza la información de metadatos del fragmento para saber dónde está cada fragmento usado/libre.
Existen diferentes formas de reservar el espacio, principalmente dependiendo del bin utilizado, pero una metodología general es la siguiente:
- El programa comienza solicitando cierta cantidad de memoria.
- Si en la lista de fragmentos hay alguno disponible lo suficientemente grande para cumplir con la solicitud, se utilizará.
- Esto incluso podría significar que parte del fragmento disponible se utilizará para esta solicitud y el resto se agregará a la lista de fragmentos.
- Si no hay ningún fragmento disponible en la lista pero aún hay espacio en la memoria del montón asignada, el administrador del montón crea un nuevo fragmento.
- Si no hay suficiente espacio en el montón para asignar el nuevo fragmento, el administrador del montón solicita al kernel que expanda la memoria asignada al montón y luego use esta memoria para generar el nuevo fragmento.
- Si todo falla,
mallocdevuelve nulo.
Tenga en cuenta que si la memoria solicitada supera un umbral, se utilizará mmap para asignar la memoria solicitada.
Arenas
En aplicaciones multihilo, el administrador del montón debe prevenir condiciones de carrera que podrían provocar bloqueos. Inicialmente, esto se hacía utilizando un mutex global para garantizar que solo un hilo pudiera acceder al montón a la vez, pero esto causaba problemas de rendimiento debido al cuello de botella inducido por el mutex.
Para abordar esto, el asignador de montón ptmalloc2 introdujo "arenas", donde cada arena actúa como un montón separado con sus propias estructuras de datos y mutex, permitiendo que múltiples hilos realicen operaciones de montón sin interferir entre sí, siempre y cuando utilicen diferentes arenas.
La arena "principal" predeterminada maneja las operaciones de montón para aplicaciones de un solo hilo. Cuando se agregan nuevos hilos, el administrador del montón les asigna arenas secundarias para reducir la contención. Primero intenta adjuntar cada nuevo hilo a una arena no utilizada, creando nuevas si es necesario, hasta un límite de 2 veces los núcleos de la CPU para sistemas de 32 bits y 8 veces para sistemas de 64 bits. Una vez que se alcanza el límite, los hilos deben compartir arenas, lo que puede provocar contención potencial.
A diferencia de la arena principal, que se expande utilizando la llamada al sistema brk, las arenas secundarias crean "submontones" utilizando mmap y mprotect para simular el comportamiento del montón, lo que permite flexibilidad en la gestión de la memoria para operaciones multihilo.
Submontones
Los submontones sirven como reservas de memoria para las arenas secundarias en aplicaciones multihilo, lo que les permite crecer y gestionar sus propias regiones de montón de forma independiente al montón principal. Así es como los submontones difieren del montón inicial y cómo operan:
- Montón inicial vs. Submontones:
- El montón inicial se encuentra directamente después del binario del programa en la memoria, y se expande utilizando la llamada al sistema
sbrk. - Los submontones, utilizados por las arenas secundarias, se crean a través de
mmap, una llamada al sistema que asigna una región de memoria especificada.
- Reserva de memoria con
mmap:
- Cuando el administrador del montón crea un submontón, reserva un bloque grande de memoria a través de
mmap. Esta reserva no asigna memoria de inmediato; simplemente designa una región que otros procesos del sistema o asignaciones no deben utilizar. - Por defecto, el tamaño reservado para un submontón es de 1 MB para procesos de 32 bits y 64 MB para procesos de 64 bits.
- Expansión gradual con
mprotect:
- La región de memoria reservada inicialmente se marca como
PROT_NONE, lo que indica que el kernel no necesita asignar memoria física a este espacio aún. - Para "expandir" el submontón, el administrador del montón utiliza
mprotectpara cambiar los permisos de página dePROT_NONEaPROT_READ | PROT_WRITE, lo que hace que el kernel asigne memoria física a las direcciones reservadas anteriormente. Este enfoque paso a paso permite que el submontón se expanda según sea necesario. - Una vez que se agota todo el submontón, el administrador del montón crea un nuevo submontón para continuar con la asignación.
Metadatos
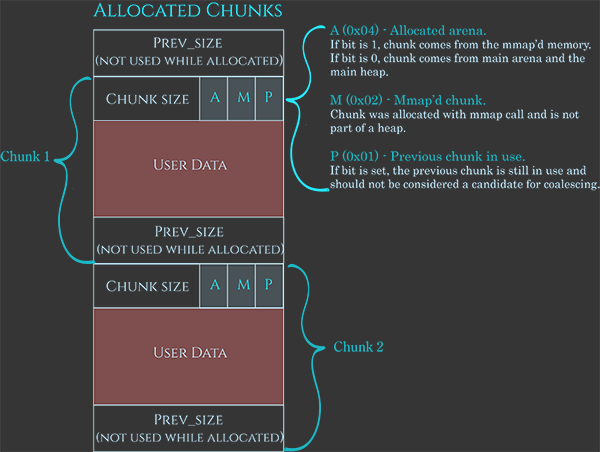
Como se comentó anteriormente, estos fragmentos también tienen algunos metadatos, muy bien representados en esta imagen:
https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
{kind=link}
Los metadatos suelen ser 0x08B, indicando el tamaño actual del fragmento utilizando los últimos 3 bits para indicar:
A: Si es 1, proviene de un submontón; si es 0, está en la arena principal.M: Si es 1, este fragmento es parte de un espacio asignado con mmap y no es parte de un montón.P: Si es 1, el fragmento anterior está en uso.
Luego, el espacio para los datos del usuario, y finalmente 0x08B para indicar el tamaño del fragmento anterior cuando el fragmento está disponible (o para almacenar los datos del usuario cuando se asigna).
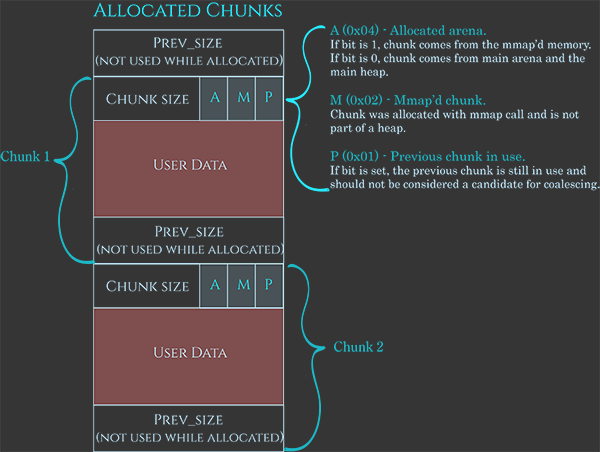
Además, cuando está disponible, los datos del usuario se utilizan para contener también algunos datos:
- Puntero al siguiente fragmento.
- Puntero al fragmento anterior.
- Tamaño del siguiente fragmento en la lista.
- Tamaño del fragmento anterior en la lista.
https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
Observe cómo al vincular la lista de esta manera se evita la necesidad de tener una matriz donde se registra cada fragmento individual.
Protecciones de liberación
Para protegerse del abuso accidental o intencional de la función free, antes de ejecutar sus acciones realiza algunas comprobaciones:
- Verifica que la dirección esté alineada en un límite de 8 bytes o 16 bytes en un límite de 64 bits (
(dirección % 16) == 0), ya que malloc garantiza que todas las asignaciones estén alineadas. - Verifica que el campo de tamaño del fragmento no sea imposible, ya sea porque es demasiado pequeño, demasiado grande, no es un tamaño alineado o se superpondría al final del espacio de direcciones del proceso.
- Verifica que el fragmento se encuentre dentro de los límites de la arena.
- Verifica que el fragmento no esté marcado como libre comprobando el bit correspondiente "P" que se encuentra en los metadatos al inicio del siguiente fragmento.
Bins
Para mejorar la eficiencia en cómo se almacenan los fragmentos, cada fragmento no está solo en una lista enlazada, sino que hay varios tipos. Estos son los bins y hay 5 tipos de bins: 62 bins pequeños, 63 bins grandes, 1 bin desordenado, 10 bins rápidos y 64 bins tcache por hilo.
La dirección inicial de cada bin desordenado, pequeño y grande está dentro del mismo array. El índice 0 no se usa, el 1 es el bin desordenado, los bins 2-64 son bins pequeños y los bins 65-127 son bins grandes.
Bins pequeños
Los bins pequeños son más rápidos que los bins grandes pero más lentos que los bins rápidos.
Cada bin de los 62 tendrá fragmentos del mismo tamaño: 16, 24, ... (con un tamaño máximo de 504 bytes en 32 bits y 1024 en 64 bits). Esto ayuda en la rapidez para encontrar el bin donde se debe asignar un espacio e insertar y eliminar entradas en estas listas.
Bins grandes
A diferencia de los bins pequeños, que manejan fragmentos de tamaños fijos, cada bin grande maneja un rango de tamaños de fragmentos. Esto es más flexible, permitiendo al sistema acomodar varios tamaños sin necesidad de un bin separado para cada tamaño.
En un asignador de memoria, los bins grandes comienzan donde terminan los bins pequeños. Los rangos para los bins grandes crecen progresivamente, lo que significa que el primer bin podría cubrir fragmentos de 512 a 576 bytes, mientras que el siguiente cubre de 576 a 640 bytes. Este patrón continúa, con el bin más grande conteniendo todos los fragmentos por encima de 1MB.
Los bins grandes son más lentos de operar en comparación con los bins pequeños porque deben ordenar y buscar a través de una lista de tamaños de fragmentos variables para encontrar el mejor ajuste para una asignación. Cuando se inserta un fragmento en un bin grande, debe ser ordenado, y al asignar memoria, el sistema debe encontrar el fragmento correcto. Este trabajo adicional los hace más lentos, pero como las asignaciones grandes son menos comunes que las pequeñas, es un compromiso aceptable.
Hay:
- 32 bins de rango de 64B
- 16 bins de rango de 512B
- 8 bins de rango de 4096B
- 4 bins de rango de 32768B
- 2 bins de rango de 262144B
- 1 bin para tamaños restantes
Bin desordenado
El bin desordenado es una caché rápida utilizada por el administrador de montón para hacer que la asignación de memoria sea más rápida. Así es como funciona: Cuando un programa libera memoria, el administrador de montón no la coloca inmediatamente en un bin específico. En su lugar, primero intenta fusionarla con cualquier fragmento libre vecino para crear un bloque más grande de memoria libre. Luego, coloca este nuevo fragmento en un bin general llamado "bin desordenado".
Cuando un programa solicita memoria, el administrador de montón primero verifica el bin desordenado para ver si hay un fragmento del tamaño correcto. Si encuentra uno, lo utiliza de inmediato, lo cual es más rápido que buscar en otros bins. Si no encuentra un fragmento adecuado, mueve los fragmentos liberados a sus bins correctos, ya sea pequeños o grandes, según su tamaño.
Por lo tanto, el bin desordenado es una forma de acelerar la asignación de memoria reutilizando rápidamente la memoria liberada recientemente y reduciendo la necesidad de búsquedas y fusiones que consumen tiempo.
{% hint style="danger" %} Ten en cuenta que incluso si los fragmentos son de diferentes categorías, de vez en cuando, si un fragmento disponible choca con otro fragmento disponible (incluso si son de diferentes categorías), se fusionarán. {% endhint %}
Bins rápidos
Los bins rápidos están diseñados para acelerar la asignación de memoria para fragmentos pequeños manteniendo fragmentos liberados recientemente en una estructura de acceso rápido. Estos bins utilizan un enfoque de Último en Entrar, Primero en Salir (LIFO), lo que significa que el fragmento liberado más recientemente es el primero en reutilizarse cuando hay una nueva solicitud de asignación. Este comportamiento es ventajoso para la velocidad, ya que es más rápido insertar y eliminar desde la parte superior de una pila (LIFO) en comparación con una cola (FIFO).
Además, los bins rápidos utilizan listas enlazadas simples, no doblemente enlazadas, lo que mejora aún más la velocidad. Dado que los fragmentos en los bins rápidos no se fusionan con vecinos, no es necesario una estructura compleja que permita la eliminación desde el medio. Una lista enlazada simple es más simple y rápida para estas operaciones.
Básicamente, lo que sucede aquí es que el encabezado (el puntero al primer fragmento a verificar) siempre apunta al fragmento liberado más reciente de ese tamaño. Entonces:
- Cuando se asigna un nuevo fragmento de ese tamaño, el encabezado apunta a un fragmento libre para usar. Como este fragmento libre apunta al siguiente fragmento a usar, esta dirección se almacena en el encabezado para que la próxima asignación sepa dónde obtener un fragmento disponible.
- Cuando se libera un fragmento, el fragmento libre guardará la dirección al fragmento disponible actual y la dirección a este fragmento recién liberado se colocará en el encabezado.
{% hint style="danger" %} Los fragmentos en los bins rápidos no se establecen automáticamente como disponibles, por lo que se mantienen como fragmentos de bins rápidos durante algún tiempo en lugar de poder fusionarse con otros fragmentos. {% endhint %}
Bins Tcache (Caché por hilo)
Aunque los hilos intentan tener su propio montón (ver Arenas y Subheaps), existe la posibilidad de que un proceso con muchos hilos (como un servidor web) termine compartiendo el montón con otros hilos. En este caso, la solución principal es el uso de candados, que podrían ralentizar significativamente los hilos.
Por lo tanto, un tcache es similar a un bin rápido por hilo en el sentido de que es una lista enlazada simple que no fusiona fragmentos. Cada hilo tiene 64 bins tcache enlazados individualmente. Cada bin puede tener un máximo de 7 fragmentos del mismo tamaño que van desde 24 a 1032B en sistemas de 64 bits y de 12 a 516B en sistemas de 32 bits.
Cuando un hilo libera un fragmento, si no es demasiado grande para ser asignado en el tcache y el bin tcache no está lleno (ya tiene 7 fragmentos), se asignará allí. Si no puede ir al tcache, deberá esperar a que el candado del montón esté disponible para poder realizar la operación de liberación global.
Cuando se asigna un fragmento, si hay un fragmento libre del tamaño necesario en el tcache, se utilizará, de lo contrario, deberá esperar a que el candado del montón esté disponible para encontrar uno en los bins globales o crear uno nuevo.
También hay una optimización, en este caso, mientras tiene el candado del montón, el hilo llenará su tcache con fragmentos del montón (7) del tamaño solicitado, por si necesita más, los encontrará en el tcache.
Orden de los contenedores
Para asignar:
- Si hay un fragmento disponible en Tcache de ese tamaño, usar Tcache
- Si es muy grande, usar mmap
- Obtener el bloqueo del montón de la arena y:
- Si hay suficientes fragmentos de tamaño pequeño en el fast bin disponibles del tamaño solicitado, usarlo y rellenar la tcache desde el fast bin
- Revisar cada entrada en la lista no ordenada buscando un fragmento lo suficientemente grande y rellenar la tcache si es posible
- Revisar los contenedores pequeños o grandes (según el tamaño solicitado) y rellenar la tcache si es posible
- Crear un nuevo fragmento a partir de la memoria disponible
- Si no hay memoria disponible, obtener más usando
sbrk - Si la memoria principal del montón no puede crecer más, crear un nuevo espacio usando mmap
- Si no hay memoria disponible, obtener más usando
- Si nada funcionó, devolver nulo
Para liberar:
- Si el puntero es Nulo, terminar
- Realizar comprobaciones de integridad de
freeen el fragmento para intentar verificar que es un fragmento legítimo- Si es lo suficientemente pequeño y la tcache no está llena, colocarlo allí
- Si el bit M está establecido (no es del montón), usar
munmap - Obtener el bloqueo del montón de la arena:
- Si encaja en un fastbin, colocarlo allí
- Si el fragmento es > 64KB, consolidar inmediatamente los fastbins y colocar los fragmentos fusionados resultantes en el contenedor no ordenado.
- Fusionar el fragmento hacia atrás y hacia adelante con fragmentos liberados vecinos en los contenedores pequeños, grandes y no ordenados si los hay.
- Si está en la parte superior de la cabeza, fusionarlo en la memoria no utilizada
- Si no es ninguno de los anteriores, almacenarlo en la lista no ordenada
\
Ejemplo rápido de montón de https://guyinatuxedo.github.io/25-heap/index.html pero en arm64:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void main(void)
{
char *ptr;
ptr = malloc(0x10);
strcpy(ptr, "panda");
}
Establece un punto de interrupción al final de la función principal y descubramos dónde se almacenó la información:
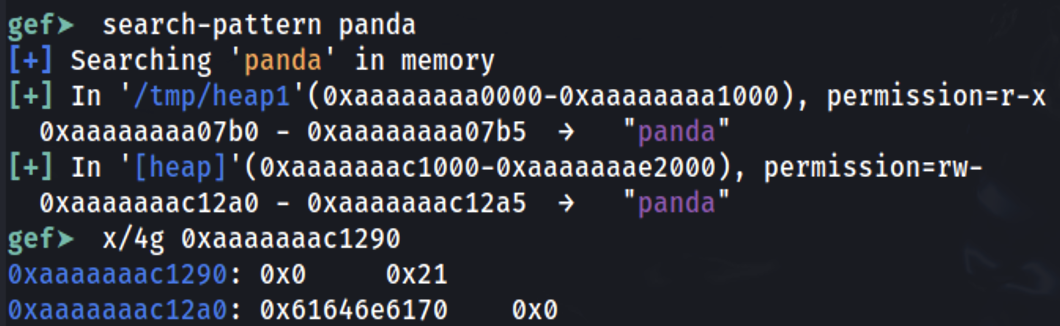
Es posible ver que la cadena panda se almacenó en 0xaaaaaaac12a0 (que fue la dirección dada como respuesta por malloc dentro de x0). Revisando 0x10 bytes antes, es posible ver que el 0x0 representa que el fragmento anterior no está en uso (longitud 0) y que la longitud de este fragmento es 0x21.
Los espacios adicionales reservados (0x21-0x10=0x11) provienen de los encabezados añadidos (0x10) y el 0x1 no significa que se reservaron 0x21B, sino que los últimos 3 bits de la longitud del encabezado actual tienen algunos significados especiales. Dado que la longitud siempre está alineada en bloques de 16 bytes (en máquinas de 64 bits), estos bits en realidad nunca se van a utilizar en el número de longitud.
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena