| .. | ||
| heap-overflow.md | ||
| README.md | ||
| use-after-free.md | ||
Heap
Grundlagen des Heaps
Der Heap ist im Grunde der Ort, an dem ein Programm Daten speichern kann, wenn es Daten anfordert, indem es Funktionen wie malloc, calloc aufruft. Darüber hinaus wird dieser Speicher freigegeben, wenn er nicht mehr benötigt wird, indem die Funktion free aufgerufen wird.
Wie gezeigt, befindet sich der Heap direkt nach dem Laden des Binärprogramms im Speicher (überprüfen Sie den Abschnitt [heap]):

Grundlegende Chunk-Allokation
Wenn Daten im Heap gespeichert werden sollen, wird ein Teil des Heaps dafür reserviert. Dieser Speicher gehört zu einem Bin und es wird nur der angeforderte Datensatz + der Speicher der Bin-Header + der minimale Bin-Größenoffset für den Chunk reserviert. Das Ziel ist es, so wenig Speicher wie möglich zu reservieren, ohne die Suche nach jedem Chunk zu komplizieren. Dafür werden die Metadaten-Chunk-Informationen verwendet, um zu wissen, wo sich jeder verwendete/freie Chunk befindet.
Es gibt verschiedene Möglichkeiten, den Speicher zu reservieren, hauptsächlich abhängig vom verwendeten Bin, aber eine allgemeine Methodik ist wie folgt:
- Das Programm beginnt mit der Anforderung einer bestimmten Speichermenge.
- Wenn in der Liste der Chunks einer verfügbar ist, der groß genug ist, um die Anforderung zu erfüllen, wird er verwendet.
- Dies kann sogar bedeuten, dass ein Teil des verfügbaren Chunks für diese Anforderung verwendet wird und der Rest zur Chunks-Liste hinzugefügt wird.
- Wenn kein verfügbarer Chunk in der Liste vorhanden ist, aber noch Speicher im allokierten Heap-Speicher vorhanden ist, erstellt der Heap-Manager einen neuen Chunk.
- Wenn nicht genügend Heap-Speicher vorhanden ist, um den neuen Chunk zuzuweisen, fordert der Heap-Manager den Kernel auf, den dem Heap zugewiesenen Speicher zu erweitern und diesen Speicher dann zu verwenden, um den neuen Chunk zu generieren.
- Wenn alles fehlschlägt, gibt
mallocnull zurück.
Beachten Sie, dass wenn der angeforderte Speicher eine Schwelle überschreitet, mmap verwendet wird, um den angeforderten Speicher abzubilden.
Arenen
In multithreaded Anwendungen muss der Heap-Manager Rennbedingungen verhindern, die zu Abstürzen führen könnten. Anfangs wurde dies mit einem globalen Mutex erreicht, um sicherzustellen, dass nur ein Thread gleichzeitig auf den Heap zugreifen konnte, aber dies führte aufgrund des durch den Mutex verursachten Engpasses zu Leistungsproblemen.
Um dies zu lösen, führte der ptmalloc2-Heap-Allocator "Arenen" ein, wobei jede Arena als eigener Heap mit eigenen Datenstrukturen und Mutex fungiert, sodass mehrere Threads Heap-Operationen ausführen können, ohne sich gegenseitig zu beeinträchtigen, solange sie verschiedene Arenen verwenden.
Die Standard-"main"-Arena behandelt Heap-Operationen für Single-Thread-Anwendungen. Wenn neue Threads hinzugefügt werden, weist der Heap-Manager ihnen sekundäre Arenen zu, um die Kontention zu verringern. Zuerst versucht er, jeden neuen Thread einer ungenutzten Arena zuzuweisen, wobei bei Bedarf neue erstellt werden, bis zu einer Grenze von 2 Mal den CPU-Kernen für 32-Bit-Systeme und 8 Mal für 64-Bit-Systeme. Sobald die Grenze erreicht ist, müssen Threads Arenen teilen, was zu potenzieller Kontention führt.
Im Gegensatz zur Hauptarena, die die brk-Systemaufruf verwendet, erstellen sekundäre Arenen "Subheaps" mit mmap und mprotect, um das Verhalten des Heaps zu simulieren und die Speicherverwaltung für Multithread-Operationen flexibler zu gestalten.
Subheaps
Subheaps dienen als Speichervorräte für sekundäre Arenen in Multithread-Anwendungen, die es ihnen ermöglichen, ihre eigenen Heap-Regionen separat vom Haupt-Heap zu erweitern und zu verwalten. Hier ist, wie sich Subheaps vom ursprünglichen Heap unterscheiden und wie sie funktionieren:
- Ursprünglicher Heap vs. Subheaps:
- Der ursprüngliche Heap befindet sich direkt nach dem Binärprogramm des Programms im Speicher und erweitert sich mit dem
sbrk-Systemaufruf. - Subheaps, die von sekundären Arenen verwendet werden, werden durch
mmaperstellt, einem Systemaufruf, der eine bestimmte Speicherregion zuweist.
- Speichervorbelegung mit
mmap:
- Wenn der Heap-Manager einen Subheap erstellt, reserviert er einen großen Speicherblock über
mmap. Diese Reservierung allokiert nicht sofort Speicher; sie kennzeichnet lediglich einen Bereich, den andere Systemprozesse oder Allokationen nicht verwenden sollten. - Standardmäßig beträgt die reservierte Größe für einen Subheap 1 MB für 32-Bit-Prozesse und 64 MB für 64-Bit-Prozesse.
- Schrittweise Erweiterung mit
mprotect:
- Der reservierte Speicherbereich ist anfangs als
PROT_NONEmarkiert, was bedeutet, dass der Kernel diesem Bereich noch keinen physischen Speicher zuweist. - Um den Subheap zu "erweitern", verwendet der Heap-Manager
mprotect, um die Seitenerlaubnis vonPROT_NONEinPROT_READ | PROT_WRITEzu ändern, wodurch der Kernel aufgefordert wird, physischen Speicher an die zuvor reservierten Adressen zuzuweisen. Dieser schrittweise Ansatz ermöglicht es dem Subheap, sich bei Bedarf zu erweitern. - Sobald der gesamte Subheap erschöpft ist, erstellt der Heap-Manager einen neuen Subheap, um die Allokation fortzusetzen.
Metadaten
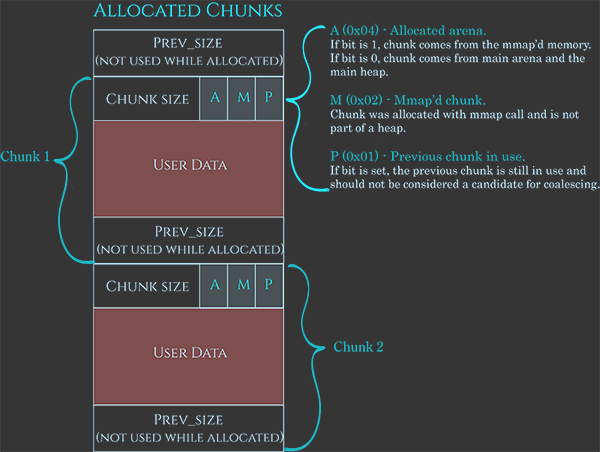
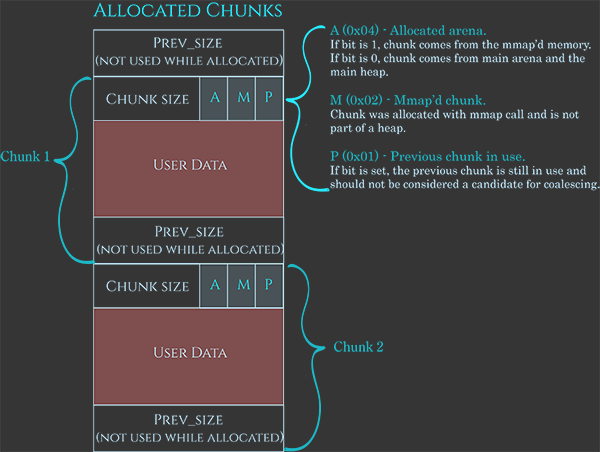
Wie bereits erwähnt, haben diese Chunks auch Metadaten, die in diesem Bild sehr gut dargestellt sind:
https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
{kind=link}
Die Metadaten sind in der Regel 0x08B, was die aktuelle Chunkgröße angibt und die letzten 3 Bits verwendet, um anzuzeigen:
A: Wenn 1, stammt es aus einem Subheap, wenn 0, befindet es sich in der Hauptarena.M: Wenn 1, gehört dieser Chunk zu einem mit mmap allokierten Speicher und nicht zu einem Heap.P: Wenn 1, ist der vorherige Chunk in Benutzung.
Dann der Platz für die Benutzerdaten und schließlich 0x08B, um die vorherige Chunkgröße anzuzeigen, wenn der Chunk verfügbar ist (oder um Benutzerdaten zu speichern, wenn er allokiert ist).
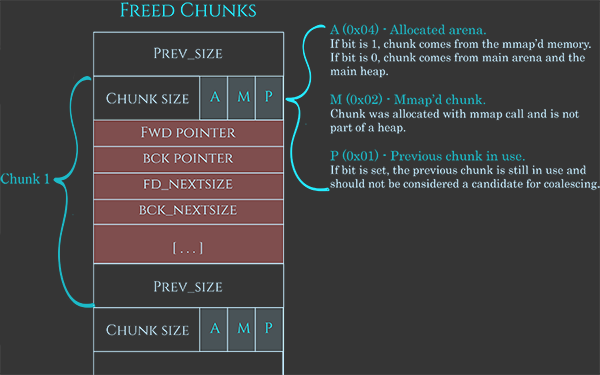
Darüber hinaus enthalten die Benutzerdaten, wenn verfügbar, auch einige Daten:
- Zeiger auf den nächsten Chunk
- Zeiger auf den vorherigen Chunk
- Größe des nächsten Chunks in der Liste
- Größe des vorherigen Chunks in der Liste
https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
Beachten Sie, wie das Verknüpfen der Liste auf diese Weise verhindert, dass ein Array benötigt wird, in dem jeder einzelne Chunk registriert wird.
Freischutz
Um sich vor dem versehentlichen oder beabsichtigten Missbrauch der Freifunktion zu schützen, führt sie vor der Ausführung einige Überprüfungen durch:
- Sie überprüft, ob die Adresse ausgerichtet ist auf einer 8-Byte- oder 16-Byte-Grenze bei 64-Bit (
(address % 16) == 0), da malloc sicherstellt, dass alle Allokationen ausgerichtet sind. - Sie überprüft, ob das Feld der Chunkgröße nicht unmöglich ist - entweder weil es zu klein, zu groß, keine ausgerichtete Größe ist oder das Ende des Adressraums des Prozesses überschneiden würde.
- Sie überprüft, ob der Chunk innerhalb der Grenzen der Arena liegt.
- Sie überprüft, ob der Chunk nicht bereits als frei markiert ist, indem sie das entsprechende "P"-Bit überprüft, das in den Metadaten am Anfang des nächsten Chunks liegt.
Bins
Um die Effizienz zu verbessern, wie Chunks gespeichert werden, befindet sich jeder Chunk nicht nur in einer verketteten Liste, sondern es gibt mehrere Typen. Diese werden als Bins bezeichnet und es gibt 5 Arten von Bins: 62 Small Bins, 63 Large Bins, 1 Unsorted Bin, 10 Fast Bins und 64 Tcache Bins pro Thread.
Die Anfangsadresse für jeden Unsorted, Small und Large Bin befindet sich im selben Array. Der Index 0 wird nicht verwendet, 1 ist der Unsorted Bin, Bins 2-64 sind Small Bins und Bins 65-127 sind Large Bins.
Small Bins
Small Bins sind schneller als Large Bins, aber langsamer als Fast Bins.
Jeder Bin der 62 wird Chunks derselben Größe haben: 16, 24, ... (mit einer maximalen Größe von 504 Bytes in 32-Bit und 1024 in 64-Bit). Dies hilft bei der Geschwindigkeit beim Auffinden des Bins, in dem ein Speicherplatz allokiert werden soll, sowie beim Einfügen und Entfernen von Einträgen in diesen Listen.
Large Bins
Im Gegensatz zu Small Bins, die Chunks fester Größen verwalten, handhabt jeder Large Bin einen Bereich von Chunk-Größen. Dies ist flexibler und ermöglicht es dem System, verschiedene Größen ohne die Notwendigkeit eines separaten Bins für jede Größe unterzubringen.
In einem Speicherzuweiser beginnen Large Bins dort, wo Small Bins enden. Die Bereiche für Large Bins werden progressiv größer, was bedeutet, dass der erste Bin Chunks von 512 bis 576 Bytes abdecken könnte, während der nächste 576 bis 640 Bytes abdeckt. Dieses Muster setzt sich fort, wobei der größte Bin alle Chunks über 1 MB enthält.
Large Bins sind langsamer in der Bedienung im Vergleich zu Small Bins, da sie eine Liste von variierenden Chunk-Größen sortieren und durchsuchen müssen, um die beste Passform für eine Allokation zu finden. Wenn ein Chunk in einen Large Bin eingefügt wird, muss er sortiert werden, und bei der Speicherzuweisung muss das System den richtigen Chunk finden. Diese zusätzliche Arbeit macht sie langsamer, aber da große Allokationen seltener sind als kleine, ist dies ein akzeptabler Kompromiss.
Es gibt:
- 32 Bins im Bereich von 64B
- 16 Bins im Bereich von 512B
- 8 Bins im Bereich von 4096B
- 4 Bins im Bereich von 32768B
- 2 Bins im Bereich von 262144B
- 1 Bin für verbleibende Größen
Unsorted Bin
Der Unsorted Bin ist ein schneller Cache, den der Heap-Manager verwendet, um die Speicherzuweisung zu beschleunigen. So funktioniert es: Wenn ein Programm Speicher freigibt, platziert der Heap-Manager ihn nicht sofort in einem bestimmten Bin. Stattdessen versucht er zuerst, ihn mit benachbarten freien Chunks zu verschmelzen, um einen größeren Block freien Speichers zu erstellen. Dann platziert er diesen neuen Chunk in einem allgemeinen Bin namens "Unsorted Bin".
Wenn ein Programm Speicher anfordert, überprüft der Heap-Manager zuerst den Unsorted Bin, um zu sehen, ob es einen Chunk der richtigen Größe gibt. Wenn er einen findet, verwendet er ihn sofort, was schneller ist als das Durchsuchen anderer Bins. Wenn er keinen geeigneten Chunk findet, verschiebt er die freigegebenen Chunks in ihre richtigen Bins, entweder Small oder Large, basierend auf ihrer Größe.
Der Unsorted Bin ist also eine Möglichkeit, die Speicherzuweisung zu beschleunigen, indem kürzlich freigegebener Speicher schnell wiederverwendet wird und die Notwendigkeit zeitaufwändiger Suchen und Verschmelzungen reduziert wird.
{% hint style="danger" %} Beachten Sie, dass auch wenn Chunks unterschiedlichen Kategorien angehören, von Zeit zu Zeit, wenn ein verfügbarer Chunk mit einem anderen verfügbaren Chunk kollidiert (auch wenn sie unterschiedlichen Kategorien angehören), werden sie zusammengeführt. {% endhint %}
Fast Bins
Fast Bins sind darauf ausgelegt, die Speicherzuweisung für kleine Chunks zu beschleunigen, indem kürzlich freigegebene Chunks in einer schnell zugänglichen Struktur aufbewahrt werden. Diese Bins verwenden einen Last-In, First-Out (LIFO)-Ansatz, was bedeutet, dass der zuletzt freigegebene Chunk der erste ist, der wiederverwendet wird, wenn eine neue Allokationsanforderung vorliegt. Dieses Verhalten ist vorteilhaft für die Geschwindigkeit, da es schneller ist, vom oberen Ende eines Stapels (LIFO) einzufügen und zu entfernen, im Vergleich zu einer Warteschlange (FIFO).
Zusätzlich verwenden Fast Bins einfach verkettete Listen, keine doppelt verketteten, was die Geschwindigkeit weiter verbessert. Da Chunks in Fast Bins nicht mit Nachbarn zusammengeführt werden, ist keine komplexe Struktur erforderlich, die das Entfernen aus der Mitte ermöglicht. Eine einfach verkettete Liste ist einfacher und schneller für diese Operationen.
Im Grunde genommen zeigt der Header (der Zeiger auf den ersten Chunk, der überprüft werden soll) immer auf den zuletzt freigegebenen Chunk dieser Größe. Also:
- Wenn ein neuer Chunk dieser Größe allokiert wird, zeigt der Header auf einen freien Chunk, der verwendet werden soll. Da dieser freie Chunk auf den nächsten zu verwendenden zeigt, wird diese Adresse im Header gespeichert, damit die nächste Allokation weiß, wo sie einen verfügbaren Chunk erhält.
- Wenn ein Chunk freigegeben wird, speichert der freie Chunk die Adresse zum aktuellen verfügbaren Chunk und die Adresse zu diesem neu freigegebenen Chunk wird im Header platziert.
{% hint style="danger" %} Chunks in Fast Bins werden nicht automatisch als verfügbar festgelegt, sodass sie für einige Zeit als Fast Bin Chunks gehalten werden, anstatt sich mit anderen Chunks zusammenführen zu können. {% endhint %}
Tcache (Per-Thread Cache) Bins
Auch wenn Threads versuchen, ihren eigenen Heap zu haben (siehe Arenas und Subheaps), besteht die Möglichkeit, dass ein Prozess mit vielen Threads (wie ein Webserver) den Heap mit anderen Threads teilen wird. In diesem Fall ist die Hauptlösung die Verwendung von Sperren, die die Threads erheblich verlangsamen können.
Daher ist ein Tcache ähnlich einem Fast Bin pro Thread in der Hinsicht, dass es sich um eine einfach verkettete Liste handelt, die Chunks nicht zusammenführt. Jeder Thread hat 64 einfach verkettete Tcache Bins. Jeder Bin kann maximal 7 Chunks derselben Größe haben im Bereich von 24 bis 1032B auf 64-Bit-Systemen und 12 bis 516B auf 32-Bit-Systemen.
Wenn ein Thread einen Chunk freigibt, wenn er nicht zu groß ist, um im Tcache allokiert zu werden und der entsprechende Tcache Bin nicht voll ist (bereits 7 Chunks), wird er dort allokiert. Wenn er nicht in den Tcache gehen kann, muss er auf das Freigeben der globalen Sperre warten, um die Freigabeoperation global durchführen zu können.
Wenn ein Chunk allokiert wird, und es gibt einen freien Chunk der benötigten Größe im Tcache, wird er verwendet, falls nicht, muss er auf das Freigeben der globalen Sperre warten, um einen im globalen Bin zu finden oder einen neuen zu erstellen.
Es gibt auch eine Optimierung, in diesem Fall, während die globale Sperre vorhanden ist, wird der Thread seinen Tcache mit Heap Chunks (7) der angeforderten Größe füllen, sodass er sie im Tcache finden kann, falls er mehr benötigt.
Bins Reihenfolge
Für die Allokation:
- Wenn ein verfügbarer Chunk in Tcache dieser Größe vorhanden ist, verwende Tcache
- Wenn er sehr groß ist, verwende mmap
- Erlange den Arena-Heap-Sperrriegel und:
- Wenn genügend kleine Größe vorhanden ist, verwende den verfügbaren Fastbin-Chunk der angeforderten Größe und fülle den Tcache aus dem Fastbin vor
- Überprüfe jeden Eintrag in der unsortierten Liste auf die Suche nach einem ausreichend großen Chunk und fülle den Tcache bei Bedarf vor
- Überprüfe die kleinen oder großen Bins (je nach angeforderter Größe) und fülle den Tcache bei Bedarf vor
- Erstelle einen neuen Chunk aus dem verfügbaren Speicher
- Wenn kein verfügbarer Speicher vorhanden ist, hole mehr mit
sbrk - Wenn der Haupt-Heap-Speicher nicht weiter wachsen kann, erstelle einen neuen Bereich mit mmap
- Wenn kein verfügbarer Speicher vorhanden ist, hole mehr mit
- Wenn nichts funktioniert hat, gib Null zurück
Für das Freigeben:
- Wenn der Zeiger Null ist, beende
- Führe
free-Integritätsprüfungen im Chunk durch, um zu versuchen zu überprüfen, ob es sich um einen legitimen Chunk handelt- Wenn klein genug und Tcache nicht voll ist, platziere es dort
- Wenn das Bit M gesetzt ist (nicht Heap), verwende
munmap - Erlange den Arena-Heap-Sperrriegel:
- Wenn es in einen Fastbin passt, platziere es dort
- Wenn der Chunk > 64KB ist, konsolidiere die Fastbins sofort und platziere die resultierenden zusammengeführten Chunks im unsortierten Bin.
- Führe den Chunk rückwärts und vorwärts mit benachbarten freigegebenen Chunks in den kleinen, großen und unsortierten Bins zusammen, falls vorhanden.
- Wenn es sich oben im Kopf befindet, füge es in den ungenutzten Speicher ein
- Wenn nicht die vorherigen, speichere es in der unsortierten Liste
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void main(void)
{
char *ptr;
ptr = malloc(0x10);
strcpy(ptr, "panda");
}
Setzen Sie einen Haltepunkt am Ende der Hauptfunktion und finden wir heraus, wo die Informationen gespeichert wurden:

Es ist möglich zu sehen, dass der String panda unter 0xaaaaaaac12a0 gespeichert wurde (die Adresse, die als Antwort von malloc innerhalb von x0 gegeben wurde). Wenn Sie 0x10 Bytes davor überprüfen, ist es möglich zu sehen, dass das 0x0 repräsentiert, dass der vorherige Chunk nicht verwendet wird (Länge 0) und dass die Länge dieses Chunks 0x21 beträgt.
Die zusätzlichen reservierten Leerzeichen (0x21-0x10=0x11) stammen von den hinzugefügten Headern (0x10) und 0x1 bedeutet nicht, dass 0x21B reserviert wurde, sondern die letzten 3 Bits der Länge des aktuellen Headers haben einige spezielle Bedeutungen. Da die Länge immer auf 16 Byte ausgerichtet ist (bei 64-Bit-Maschinen), werden diese Bits tatsächlich nie von der Längenzahl verwendet.
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena