1.8 KiB
Informations de base
Apache Hadoop est un framework open source qui prend en charge le stockage et le traitement distribué de grands ensembles de données à l'aide de clusters informatiques. Le stockage est géré par le système de fichiers distribué Hadoop (HDFS) et le traitement est effectué en utilisant MapReduce et d'autres applications (par exemple, Apache Storm, Flink et Spark) via YARN.
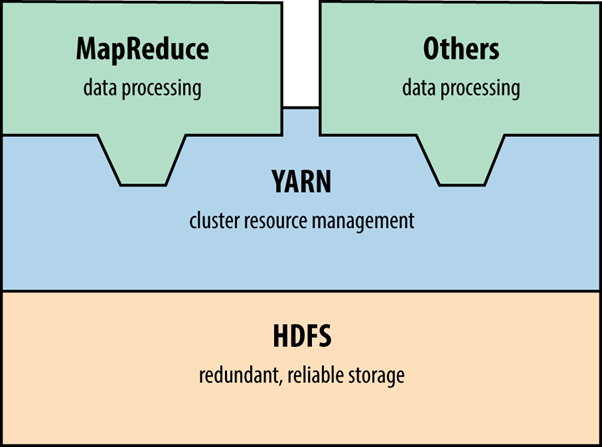
Figure 15-1. Architecture Hadoop 2.0
Vous pouvez interroger les services MapReduce et HDFS en utilisant les scripts Nmap répertoriés dans le tableau suivant (y compris les détails des ports par défaut). Au moment de la rédaction, Metasploit ne prend pas en charge Hadoop.
| Nom du script | Port | Objectif |
|---|---|---|
| hadoop-jobtracker-info | 50030 | Récupérer des informations à partir des services de suivi de tâches et de travaux MapReduce |
| hadoop-tasktracker-info | 50060 | |
| hadoop-namenode-info | 50070 | Récupérer des informations à partir du nœud de nom HDFS |
| hadoop-datanode-info | 50075 | Récupérer des informations à partir du nœud de données HDFS |
| hadoop-secondary-namenode-info | 50090 | Récupérer des informations à partir du nœud de nom secondaire HDFS |
Des clients HDFS légers en Python et en Go sont disponibles en ligne. Hadoop s'exécute sans authentification par défaut. Vous pouvez configurer les services HDFS, YARN et MapReduce pour utiliser Kerberos.