19 KiB
4. Mechanizmy Uwagowe
Mechanizmy Uwagowe i Samo-Uwaga w Sieciach Neuronowych
Mechanizmy uwagowe pozwalają sieciom neuronowym skupić się na konkretnych częściach wejścia podczas generowania każdej części wyjścia. Przypisują różne wagi różnym wejściom, pomagając modelowi zdecydować, które wejścia są najbardziej istotne dla danego zadania. Jest to kluczowe w zadaniach takich jak tłumaczenie maszynowe, gdzie zrozumienie kontekstu całego zdania jest niezbędne do dokładnego tłumaczenia.
{% hint style="success" %}
Celem tej czwartej fazy jest bardzo prosty: Zastosować kilka mechanizmów uwagowych. Będą to powtarzające się warstwy, które będą uchwytywać relację słowa w słowniku z jego sąsiadami w aktualnym zdaniu używanym do trenowania LLM.
Do tego celu używa się wielu warstw, więc wiele parametrów do uczenia będzie uchwytywać te informacje.
{% endhint %}
Zrozumienie Mechanizmów Uwagowych
W tradycyjnych modelach sekwencja-do-sekwencji używanych do tłumaczenia języków, model koduje sekwencję wejściową w stałej wielkości wektor kontekstowy. Jednak to podejście ma trudności z długimi zdaniami, ponieważ stały wektor kontekstowy może nie uchwycić wszystkich niezbędnych informacji. Mechanizmy uwagowe rozwiązują to ograniczenie, pozwalając modelowi rozważać wszystkie tokeny wejściowe podczas generowania każdego tokenu wyjściowego.
Przykład: Tłumaczenie Maszynowe
Rozważmy tłumaczenie niemieckiego zdania "Kannst du mir helfen diesen Satz zu übersetzen" na angielski. Tłumaczenie słowo po słowie nie dałoby gramatycznie poprawnego zdania w języku angielskim z powodu różnic w strukturach gramatycznych między językami. Mechanizm uwagi umożliwia modelowi skupienie się na istotnych częściach zdania wejściowego podczas generowania każdego słowa zdania wyjściowego, co prowadzi do dokładniejszego i spójnego tłumaczenia.
Wprowadzenie do Samo-Uwagi
Samo-uwaga, lub intra-uwaga, to mechanizm, w którym uwaga jest stosowana w obrębie jednej sekwencji w celu obliczenia reprezentacji tej sekwencji. Pozwala to każdemu tokenowi w sekwencji zwracać uwagę na wszystkie inne tokeny, pomagając modelowi uchwycić zależności między tokenami, niezależnie od ich odległości w sekwencji.
Kluczowe Pojęcia
- Tokeny: Indywidualne elementy sekwencji wejściowej (np. słowa w zdaniu).
- Osadzenia: Wektorowe reprezentacje tokenów, uchwycające informacje semantyczne.
- Wagi Uwagowe: Wartości, które określają znaczenie każdego tokenu w stosunku do innych.
Obliczanie Wag Uwagowych: Przykład Krok po Kroku
Rozważmy zdanie "Hello shiny sun!" i przedstawmy każde słowo za pomocą 3-wymiarowego osadzenia:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Naszym celem jest obliczenie wektora kontekstowego dla słowa "shiny" przy użyciu samo-uwagi.
Krok 1: Obliczanie Wyników Uwagowych
{% hint style="success" %} Po prostu pomnóż każdą wartość wymiaru zapytania przez odpowiednią wartość każdego tokenu i dodaj wyniki. Otrzymujesz 1 wartość dla każdej pary tokenów. {% endhint %}
Dla każdego słowa w zdaniu oblicz wynik uwagi w odniesieniu do "shiny", obliczając iloczyn skalarny ich osadzeń.
Wynik Uwagowy między "Hello" a "shiny"

Wynik Uwagowy między "shiny" a "shiny"

Wynik Uwagowy między "sun" a "shiny"

Krok 2: Normalizacja Wyników Uwagowych w Celu Uzyskania Wag Uwagowych
{% hint style="success" %} Nie gub się w terminach matematycznych, cel tej funkcji jest prosty, znormalizować wszystkie wagi tak, aby suma wynosiła 1.
Ponadto, funkcja softmax jest używana, ponieważ akcentuje różnice dzięki części wykładniczej, co ułatwia wykrywanie użytecznych wartości. {% endhint %}
Zastosuj funkcję softmax do wyników uwagowych, aby przekształcić je w wagi uwagowe, które sumują się do 1.
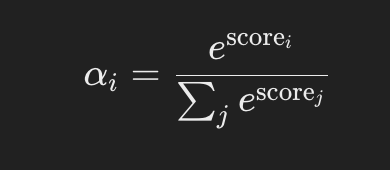
Obliczanie wykładników:

Obliczanie sumy:

Obliczanie wag uwagowych:

Krok 3: Obliczanie Wektora Kontekstowego
{% hint style="success" %} Po prostu weź każdą wagę uwagową i pomnóż ją przez odpowiednie wymiary tokenów, a następnie zsumuj wszystkie wymiary, aby uzyskać tylko 1 wektor (wektor kontekstowy) {% endhint %}
Wektor kontekstowy jest obliczany jako ważona suma osadzeń wszystkich słów, przy użyciu wag uwagowych.

Obliczanie każdego składnika:
- Ważone Osadzenie "Hello":



Sumując ważone osadzenia:
wektor kontekstowy=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
Ten wektor kontekstowy reprezentuje wzbogaconą osadzenie dla słowa "shiny", uwzględniając informacje ze wszystkich słów w zdaniu.
Podsumowanie Procesu
- Oblicz Wyniki Uwagowe: Użyj iloczynu skalarnego między osadzeniem docelowego słowa a osadzeniami wszystkich słów w sekwencji.
- Normalizuj Wyniki, aby Uzyskać Wagi Uwagowe: Zastosuj funkcję softmax do wyników uwagowych, aby uzyskać wagi, które sumują się do 1.
- Oblicz Wektor Kontekstowy: Pomnóż osadzenie każdego słowa przez jego wagę uwagową i zsumuj wyniki.
Samo-Uwaga z Uczonymi Wagami
W praktyce mechanizmy samo-uwagi używają uczących się wag, aby nauczyć się najlepszych reprezentacji dla zapytań, kluczy i wartości. Obejmuje to wprowadzenie trzech macierzy wag:

Zapytanie to dane do użycia jak wcześniej, podczas gdy macierze kluczy i wartości to po prostu losowe macierze do uczenia.
Krok 1: Oblicz Zapytania, Klucze i Wartości
Każdy token będzie miał swoją własną macierz zapytania, klucza i wartości, mnożąc swoje wartości wymiarowe przez zdefiniowane macierze:

Te macierze przekształcają oryginalne osadzenia w nową przestrzeń odpowiednią do obliczania uwagi.
Przykład
Zakładając:
- Wymiar wejściowy
din=3(rozmiar osadzenia) - Wymiar wyjściowy
dout=2(pożądany wymiar dla zapytań, kluczy i wartości)
Zainicjuj macierze wag:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
Oblicz zapytania, klucze i wartości:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Krok 2: Obliczanie uwagi z przeskalowanym iloczynem skalarnym
Obliczanie wyników uwagi
Podobnie jak w poprzednim przykładzie, ale tym razem, zamiast używać wartości wymiarów tokenów, używamy macierzy kluczy tokenu (już obliczonej przy użyciu wymiarów):. Tak więc, dla każdego zapytania qi i klucza kj:
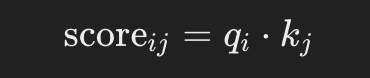
Skalowanie wyników
Aby zapobiec zbyt dużym iloczynom skalarnym, przeskaluj je przez pierwiastek kwadratowy z wymiaru klucza dk:
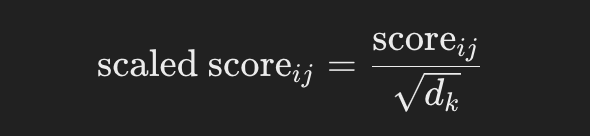
{% hint style="success" %} Wynik jest dzielony przez pierwiastek kwadratowy z wymiarów, ponieważ iloczyny skalarne mogą stać się bardzo duże, a to pomaga je regulować. {% endhint %}
Zastosuj Softmax, aby uzyskać wagi uwagi: Jak w początkowym przykładzie, znormalizuj wszystkie wartości, aby ich suma wynosiła 1.

Krok 3: Obliczanie wektorów kontekstu
Jak w początkowym przykładzie, po prostu zsumuj wszystkie macierze wartości, mnożąc każdą z nich przez jej wagę uwagi:

Przykład kodu
Zabierając przykład z https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb, możesz sprawdzić tę klasę, która implementuje funkcjonalność samouwaga, o której rozmawialiśmy:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
Zauważ, że zamiast inicjować macierze losowymi wartościami, używa się nn.Linear, aby oznaczyć wszystkie wagi jako parametry do trenowania.
{% endhint %}
Causal Attention: Ukrywanie Przyszłych Słów
Dla LLM-ów chcemy, aby model brał pod uwagę tylko tokeny, które pojawiają się przed bieżącą pozycją, aby przewidzieć następny token. Causal attention, znane również jako masked attention, osiąga to poprzez modyfikację mechanizmu uwagi, aby zapobiec dostępowi do przyszłych tokenów.
Stosowanie Maski Causal Attention
Aby zaimplementować causal attention, stosujemy maskę do wyników uwagi przed operacją softmax, aby pozostałe sumowały się do 1. Ta maska ustawia wyniki uwagi przyszłych tokenów na minus nieskończoność, zapewniając, że po softmax ich wagi uwagi wynoszą zero.
Kroki
- Oblicz Wyniki Uwagi: Tak jak wcześniej.
- Zastosuj Maskę: Użyj macierzy górnej trójkątnej wypełnionej minus nieskończonością powyżej przekątnej.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf')
masked_scores = attention_scores + mask
- Zastosuj Softmax: Oblicz wagi uwagi, używając zamaskowanych wyników.
attention_weights = torch.softmax(masked_scores, dim=-1)
Maskowanie Dodatkowych Wag Uwagi za Pomocą Dropout
Aby zapobiec przeuczeniu, możemy zastosować dropout do wag uwagi po operacji softmax. Dropout losowo zeruje niektóre z wag uwagi podczas treningu.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
Zwykła utrata to około 10-20%.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Rozszerzenie uwagi z pojedynczej głowy na uwagę z wieloma głowami
Uwaga z wieloma głowami w praktyce polega na wykonywaniu wielu instancji funkcji uwagi własnej, z których każda ma swoje własne wagi, dzięki czemu obliczane są różne wektory końcowe.
Przykład kodu
Możliwe byłoby ponowne wykorzystanie poprzedniego kodu i dodanie tylko opakowania, które uruchamia go kilka razy, ale to jest bardziej zoptymalizowana wersja z https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb, która przetwarza wszystkie głowy jednocześnie (zmniejszając liczbę kosztownych pętli for). Jak widać w kodzie, wymiary każdego tokena są dzielone na różne wymiary w zależności od liczby głów. W ten sposób, jeśli token ma 8 wymiarów i chcemy użyć 3 głów, wymiary będą podzielone na 2 tablice po 4 wymiary, a każda głowa użyje jednej z nich:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Dla innej kompaktowej i wydajnej implementacji możesz użyć klasy torch.nn.MultiheadAttention w PyTorch.
{% hint style="success" %} Krótka odpowiedź ChatGPT na pytanie, dlaczego lepiej jest podzielić wymiary tokenów między głowami, zamiast pozwalać każdej głowie sprawdzać wszystkie wymiary wszystkich tokenów:
Chociaż pozwolenie każdej głowie na przetwarzanie wszystkich wymiarów osadzenia może wydawać się korzystne, ponieważ każda głowa miałaby dostęp do pełnych informacji, standardową praktyką jest podział wymiarów osadzenia między głowami. Takie podejście równoważy wydajność obliczeniową z wydajnością modelu i zachęca każdą głowę do uczenia się różnorodnych reprezentacji. Dlatego podział wymiarów osadzenia jest ogólnie preferowany w porównaniu do pozwolenia każdej głowie na sprawdzanie wszystkich wymiarów. {% endhint %}