| .. | ||
| docker-breakout-privilege-escalation | ||
| namespaces | ||
| abusing-docker-socket-for-privilege-escalation.md | ||
| apparmor.md | ||
| authz-and-authn-docker-access-authorization-plugin.md | ||
| cgroups.md | ||
| docker-privileged.md | ||
| README.md | ||
| seccomp.md | ||
| weaponizing-distroless.md | ||
Segurança do Docker

Use o Trickest para criar e automatizar fluxos de trabalho com as ferramentas comunitárias mais avançadas do mundo.
Acesse hoje:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- Você trabalha em uma empresa de segurança cibernética? Você quer ver sua empresa anunciada no HackTricks? ou você quer ter acesso à última versão do PEASS ou baixar o HackTricks em PDF? Confira os PLANOS DE ASSINATURA!
- Descubra The PEASS Family, nossa coleção exclusiva de NFTs
- Adquira o swag oficial do PEASS & HackTricks
- Junte-se ao 💬 grupo Discord ou ao grupo telegram ou siga-me no Twitter 🐦@carlospolopm.
- Compartilhe suas técnicas de hacking enviando PRs para o repositório hacktricks e hacktricks-cloud repo.
Segurança básica do Docker Engine
O Docker Engine faz o trabalho pesado de executar e gerenciar contêineres. O Docker Engine usa recursos do kernel Linux, como Namespaces e Cgroups, para fornecer isolamento básico entre contêineres. Ele também usa recursos como Capabilities dropping, Seccomp, SELinux/AppArmor para obter um melhor isolamento.
Por fim, um plugin de autenticação pode ser usado para limitar as ações que os usuários podem executar.
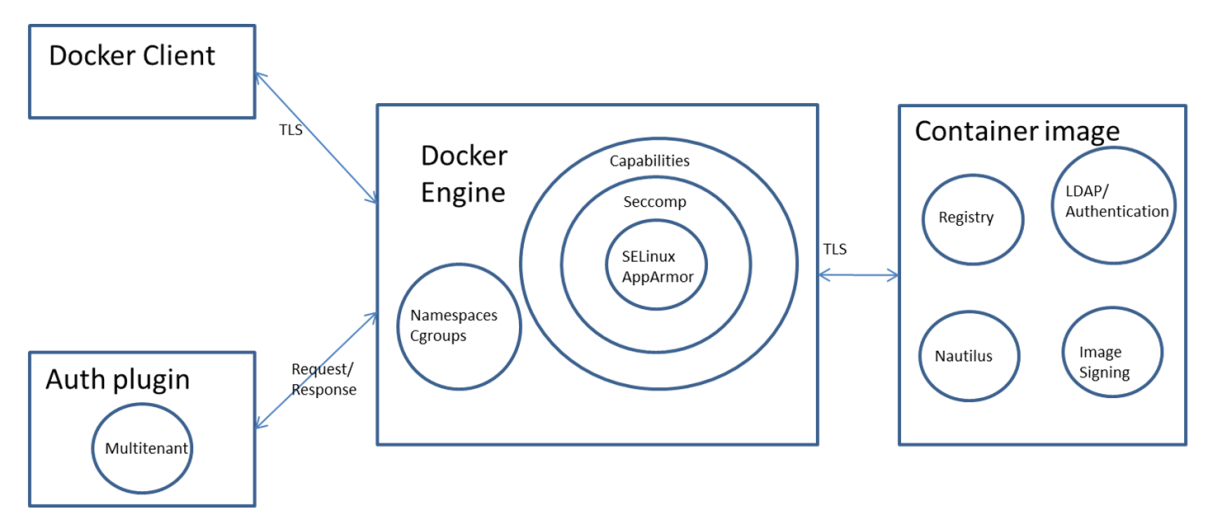
Acesso seguro ao Docker Engine
O cliente Docker pode acessar o Docker Engine localmente usando um soquete Unix ou remotamente usando o mecanismo http. Para usá-lo remotamente, é necessário usar https e TLS para garantir confidencialidade, integridade e autenticação.
Por padrão, ele escuta no soquete Unix unix:///var/
run/docker.sock e nas distribuições Ubuntu, as opções de inicialização do Docker são especificadas em /etc/default/docker. Para permitir que a API e o cliente do Docker acessem o Docker Engine remotamente, precisamos expor o daemon do Docker usando um soquete http. Isso pode ser feito por:
DOCKER_OPTS="-D -H unix:///var/run/docker.sock -H
tcp://192.168.56.101:2376" -> add this to /etc/default/docker
Sudo service docker restart -> Restart Docker daemon
Expor o daemon do Docker usando http não é uma boa prática e é necessário garantir a segurança da conexão usando https. Existem duas opções: a primeira opção é para o cliente verificar a identidade do servidor e a segunda opção é para ambos, cliente e servidor, verificarem a identidade um do outro. Certificados estabelecem a identidade de um servidor. Para um exemplo de ambas as opções, confira esta página.
Segurança da imagem do container
As imagens do container são armazenadas em um repositório privado ou público. Seguem abaixo as opções que o Docker fornece para armazenar imagens do container:
- Docker hub – Este é um serviço de registro público fornecido pelo Docker.
- Docker registry – Este é um projeto de código aberto que os usuários podem usar para hospedar seu próprio registro.
- Docker trusted registry – Esta é a implementação comercial do Docker do registro Docker e fornece autenticação de usuário baseada em função, juntamente com a integração do serviço de diretório LDAP.
Verificação de imagem
Os containers podem ter vulnerabilidades de segurança devido à imagem base ou ao software instalado em cima da imagem base. O Docker está trabalhando em um projeto chamado Nautilus que faz a verificação de segurança dos containers e lista as vulnerabilidades. O Nautilus funciona comparando cada camada da imagem do container com o repositório de vulnerabilidades para identificar falhas de segurança.
Para mais informações, leia isto.
Como verificar imagens
O comando docker scan permite verificar imagens do Docker existentes usando o nome ou ID da imagem. Por exemplo, execute o seguinte comando para verificar a imagem hello-world:
docker scan hello-world
Testing hello-world...
Organization: docker-desktop-test
Package manager: linux
Project name: docker-image|hello-world
Docker image: hello-world
Licenses: enabled
✓ Tested 0 dependencies for known issues, no vulnerable paths found.
Note that we do not currently have vulnerability data for your image.
Assinatura de Imagem Docker
As imagens de contêineres Docker podem ser armazenadas em um registro público ou privado. É necessário assinar as imagens de contêineres para confirmar que as imagens não foram adulteradas. O publicador de conteúdo é responsável por assinar a imagem do contêiner e enviá-la para o registro.
A seguir estão alguns detalhes sobre a confiança do conteúdo do Docker:
- A confiança do conteúdo do Docker é uma implementação do projeto de código aberto Notary. O projeto de código aberto Notary é baseado no projeto The Update Framework (TUF).
- A confiança do conteúdo do Docker é habilitada com
export DOCKER_CONTENT_TRUST=1. A partir da versão 1.10 do Docker, a confiança do conteúdo não é habilitada por padrão. - Quando a confiança do conteúdo está habilitada, só podemos baixar imagens assinadas. Quando a imagem é enviada, precisamos inserir a chave de marcação.
- Quando o publicador envia a imagem pela primeira vez usando o comando docker push, é necessário inserir uma senha para a chave raiz e a chave de marcação. Outras chaves são geradas automaticamente.
- O Docker também adicionou suporte para chaves de hardware usando o Yubikey e os detalhes estão disponíveis aqui.
A seguir está o erro que obtemos quando a confiança do conteúdo está habilitada e a imagem não está assinada.
$ docker pull smakam/mybusybox
Using default tag: latest
No trust data for latest
O seguinte resultado mostra a imagem do contêiner sendo enviada para o Docker Hub com a assinatura ativada. Como esta não é a primeira vez, o usuário é solicitado a inserir apenas a frase secreta para a chave do repositório.
$ docker push smakam/mybusybox:v2
The push refers to a repository [docker.io/smakam/mybusybox]
a7022f99b0cc: Layer already exists
5f70bf18a086: Layer already exists
9508eff2c687: Layer already exists
v2: digest: sha256:8509fa814029e1c1baf7696b36f0b273492b87f59554a33589e1bd6283557fc9 size: 2205
Signing and pushing trust metadata
Enter passphrase for repository key with ID 001986b (docker.io/smakam/mybusybox):
É necessário armazenar a chave raiz, a chave do repositório e a frase secreta em um local seguro. O seguinte comando pode ser usado para fazer backup das chaves privadas:
tar -zcvf private_keys_backup.tar.gz ~/.docker/trust/private
Quando mudei o host do Docker, tive que mover as chaves raiz e as chaves do repositório para operar a partir do novo host.
Use Trickest para construir e automatizar fluxos de trabalho com as ferramentas comunitárias mais avançadas do mundo.
Acesse hoje:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Recursos de Segurança de Contêineres
Resumo dos Recursos de Segurança de Contêineres
Namespaces
Os namespaces são úteis para isolar um projeto dos outros, isolando as comunicações de processos, rede, montagens... É útil isolar o processo do docker de outros processos (e até mesmo da pasta /proc) para que ele não possa escapar abusando de outros processos.
Seria possível "escapar" ou mais exatamente criar novos namespaces usando o binário unshare (que usa a chamada de sistema unshare). O Docker, por padrão, impede isso, mas o Kubernetes não (no momento em que este escrito foi feito).
De qualquer forma, isso é útil para criar novos namespaces, mas não para voltar aos namespaces padrão do host (a menos que você tenha acesso a algum /proc dentro dos namespaces do host, onde poderia usar o nsenter para entrar nos namespaces do host).
CGroups
Isso permite limitar recursos e não afeta a segurança do isolamento do processo (exceto pelo release_agent que pode ser usado para escapar).
Descarte de Capacidades
Acho que este é um dos recursos mais importantes em relação à segurança do isolamento de processos. Isso ocorre porque, sem as capacidades, mesmo que o processo esteja sendo executado como root, você não poderá executar algumas ações privilegiadas (porque a chamada de sistema chamada syscall retornará um erro de permissão porque o processo não tem as capacidades necessárias).
Essas são as capacidades restantes após o processo descartar as outras:
{% code overflow="wrap" %}
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=ep
{% endcode %}
Seccomp
Ele é habilitado por padrão no Docker. Ele ajuda a limitar ainda mais as syscalls que o processo pode chamar.
O perfil padrão do Docker Seccomp pode ser encontrado em https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
AppArmor
O Docker tem um modelo que você pode ativar: https://github.com/moby/moby/tree/master/profiles/apparmor
Isso permitirá reduzir as capacidades, syscalls, acesso a arquivos e pastas...
Namespaces
Namespaces são um recurso do kernel Linux que particiona recursos do kernel de forma que um conjunto de processos veja um conjunto de recursos enquanto outro conjunto de processos vê um conjunto diferente de recursos. O recurso funciona tendo o mesmo namespace para um conjunto de recursos e processos, mas esses namespaces se referem a recursos distintos. Os recursos podem existir em vários espaços.
O Docker faz uso dos seguintes Namespaces do kernel Linux para alcançar o isolamento do Container:
- namespace pid
- namespace mount
- namespace de rede
- namespace ipc
- namespace UTS
Para mais informações sobre os namespaces, verifique a seguinte página:
{% content-ref url="namespaces/" %} namespaces {% endcontent-ref %}
cgroups
O recurso do kernel Linux cgroups fornece a capacidade de restringir recursos como CPU, memória, IO, largura de banda de rede entre um conjunto de processos. O Docker permite criar Containers usando o recurso cgroup que permite o controle de recursos para o Container específico.
A seguir, é apresentado um Container criado com memória de espaço do usuário limitada a 500m, memória do kernel limitada a 50m, compartilhamento de CPU para 512, peso de blkioweight para 400. O compartilhamento de CPU é uma proporção que controla o uso da CPU do Container. Ele tem um valor padrão de 1024 e varia entre 0 e 1024. Se três Containers tiverem o mesmo compartilhamento de CPU de 1024, cada Container pode usar até 33% da CPU em caso de contenção de recursos da CPU. blkio-weight é uma proporção que controla o IO do Container. Ele tem um valor padrão de 500 e varia entre 10 e 1000.
docker run -it -m 500M --kernel-memory 50M --cpu-shares 512 --blkio-weight 400 --name ubuntu1 ubuntu bash
Para obter o cgroup de um contêiner, você pode fazer:
docker run -dt --rm denial sleep 1234 #Run a large sleep inside a Debian container
ps -ef | grep 1234 #Get info about the sleep process
ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the hosts and some may be shred with it)
Para mais informações, consulte:
{% content-ref url="cgroups.md" %} cgroups.md {% endcontent-ref %}
Capacidades
As capacidades permitem um controle mais preciso das capacidades que podem ser permitidas para o usuário root. O Docker usa o recurso de capacidade do kernel Linux para limitar as operações que podem ser feitas dentro de um contêiner independentemente do tipo de usuário.
Quando um contêiner Docker é executado, o processo descarta as capacidades sensíveis que o processo poderia usar para escapar do isolamento. Isso tenta garantir que o processo não possa executar ações sensíveis e escapar:
{% content-ref url="../linux-capabilities.md" %} linux-capabilities.md {% endcontent-ref %}
Seccomp no Docker
Este é um recurso de segurança que permite ao Docker limitar as chamadas de sistema que podem ser usadas dentro do contêiner:
{% content-ref url="seccomp.md" %} seccomp.md {% endcontent-ref %}
AppArmor no Docker
AppArmor é um aprimoramento do kernel para confinar contêineres a um conjunto limitado de recursos com perfis por programa:
{% content-ref url="apparmor.md" %} apparmor.md {% endcontent-ref %}
SELinux no Docker
SELinux é um sistema de rotulagem. Cada processo e cada objeto do sistema de arquivos tem um rótulo. As políticas do SELinux definem regras sobre o que um rótulo de processo pode fazer com todos os outros rótulos no sistema.
Os motores de contêiner lançam processos de contêiner com um único rótulo SELinux confinado, geralmente container_t, e depois definem o contêiner dentro do contêiner para ser rotulado como container_file_t. As regras de política do SELinux basicamente dizem que os processos container_t só podem ler/escrever/executar arquivos rotulados como container_file_t.
{% content-ref url="../selinux.md" %} selinux.md {% endcontent-ref %}
AuthZ e AuthN
Um plugin de autorização aprova ou nega solicitações ao daemon do Docker com base no contexto atual de autenticação e no contexto de comando. O contexto de autenticação contém todos os detalhes do usuário e o método de autenticação. O contexto de comando contém todos os dados relevantes da solicitação.
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
Flags interessantes do Docker
Flag --privileged
Na página a seguir, você pode aprender o que a flag --privileged implica:
{% content-ref url="docker-privileged.md" %} docker-privileged.md {% endcontent-ref %}
--security-opt
no-new-privileges
Se você estiver executando um contêiner em que um invasor consegue acessar como um usuário de baixo privilégio. Se você tiver um binário suid mal configurado, o invasor pode abusar dele e escalar privilégios dentro do contêiner. O que pode permitir que ele escape dele.
Executar o contêiner com a opção no-new-privileges habilitada irá impedir esse tipo de escalonamento de privilégios.
docker run -it --security-opt=no-new-privileges:true nonewpriv
Outros
#You can manually add/drop capabilities with
--cap-add
--cap-drop
# You can manually disable seccomp in docker with
--security-opt seccomp=unconfined
# You can manually disable seccomp in docker with
--security-opt apparmor=unconfined
# You can manually disable selinux in docker with
--security-opt label:disable
Para mais opções de --security-opt, consulte: https://docs.docker.com/engine/reference/run/#security-configuration
Use o Trickest para construir e automatizar fluxos de trabalho com as ferramentas comunitárias mais avançadas do mundo.
Acesse hoje:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Outras Considerações de Segurança
Gerenciando Segredos
Em primeiro lugar, não os coloque dentro da sua imagem!
Além disso, não use variáveis de ambiente para suas informações confidenciais. Qualquer pessoa que possa executar docker inspect ou exec no contêiner pode encontrar seu segredo.
Os volumes do Docker são melhores. Eles são a maneira recomendada de acessar suas informações confidenciais na documentação do Docker. Você pode usar um volume como sistema de arquivos temporário mantido na memória. Os volumes removem o risco de docker inspect e de registro. No entanto, usuários root ainda podem ver o segredo, assim como qualquer pessoa que possa exec no contêiner.
Ainda melhor do que volumes, use segredos do Docker.
Se você apenas precisa do segredo em sua imagem, pode usar o BuildKit. O BuildKit reduz significativamente o tempo de construção e tem outros recursos interessantes, incluindo suporte a segredos em tempo de construção.
Existem três maneiras de especificar o backend do BuildKit para que você possa usar seus recursos agora:
- Defina-o como uma variável de ambiente com
export DOCKER_BUILDKIT=1. - Inicie seu comando
buildouruncomDOCKER_BUILDKIT=1. - Ative o BuildKit por padrão. Defina a configuração em /etc/docker/daemon.json como true com:
{ "features": { "buildkit": true } }. Em seguida, reinicie o Docker. - Em seguida, você pode usar segredos no momento da construção com a flag
--secretassim:
docker build --secret my_key=my_value ,src=path/to/my_secret_file .
Onde o seu arquivo especifica suas informações confidenciais como um par de chave-valor.
Essas informações confidenciais são excluídas do cache de construção da imagem e da imagem final.
Se você precisar de sua informação confidencial em seu contêiner em execução, e não apenas durante a construção da imagem, use Docker Compose ou Kubernetes.
Com o Docker Compose, adicione o par de chave-valor das informações confidenciais a um serviço e especifique o arquivo de informações confidenciais. A dica é do Stack Exchange answer para informações confidenciais do Docker Compose, da qual o exemplo abaixo é adaptado.
Exemplo de docker-compose.yml com informações confidenciais:
version: "3.7"
services:
my_service:
image: centos:7
entrypoint: "cat /run/secrets/my_secret"
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret_file.txt
Se você estiver usando o Compose, inicie-o como de costume com docker-compose up --build my_service.
Se você estiver usando o Kubernetes, ele tem suporte para segredos. O Helm-Secrets pode ajudar a tornar a gestão de segredos no K8s mais fácil. Além disso, o K8s tem Controles de Acesso Baseados em Função (RBAC) - assim como o Docker Enterprise. O RBAC torna a gestão de segredos mais gerenciável e segura para as equipes.
gVisor
gVisor é um kernel de aplicativo, escrito em Go, que implementa uma porção substancial da superfície do sistema Linux. Ele inclui um tempo de execução Open Container Initiative (OCI) chamado runsc que fornece uma fronteira de isolamento entre o aplicativo e o kernel do host. O tempo de execução runsc integra-se com o Docker e o Kubernetes, tornando simples a execução de contêineres isolados.
{% embed url="https://github.com/google/gvisor" %}
Kata Containers
Kata Containers é uma comunidade de código aberto que trabalha para construir um tempo de execução de contêiner seguro com máquinas virtuais leves que parecem e funcionam como contêineres, mas fornecem uma isolamento de carga de trabalho mais forte usando tecnologia de virtualização de hardware como uma segunda camada de defesa.
{% embed url="https://katacontainers.io/" %}
Dicas de Resumo
- Não use a flag
--privilegedou monte um socket do Docker dentro do contêiner. O socket do Docker permite a criação de contêineres, então é uma maneira fácil de assumir o controle total do host, por exemplo, executando outro contêiner com a flag--privileged. - Não execute como root dentro do contêiner. Use um usuário diferente e namespaces de usuário. O root no contêiner é o mesmo que no host, a menos que seja remapeado com namespaces de usuário. Ele é apenas levemente restrito por, principalmente, namespaces do Linux, capacidades e cgroups.
- Descarte todas as capacidades (
--cap-drop=all) e habilite apenas as necessárias (--cap-add=...). Muitas cargas de trabalho não precisam de nenhuma capacidade e adicioná-las aumenta o escopo de um possível ataque. - Use a opção de segurança "no-new-privileges" para impedir que os processos ganhem mais privilégios, por exemplo, através de binários suid.
- Limite os recursos disponíveis para o contêiner. Os limites de recursos podem proteger a máquina de ataques de negação de serviço.
- Ajuste os perfis de seccomp, AppArmor (ou SELinux) para restringir as ações e syscalls disponíveis para o contêiner ao mínimo necessário.
- Use imagens oficiais do Docker e exija assinaturas ou construa as suas próprias com base nelas. Não herde ou use imagens comprometidas. Armazene também as chaves raiz e a frase secreta em um local seguro. O Docker tem planos para gerenciar chaves com o UCP.
- Reconstrua regularmente suas imagens para aplicar patches de segurança ao host e às imagens.
- Gerencie seus segredos com sabedoria para que seja difícil para o atacante acessá-los.
- Se você expõe o daemon do Docker, use HTTPS com autenticação de cliente e servidor.
- Em seu Dockerfile, prefira COPY em vez de ADD. ADD extrai automaticamente arquivos compactados e pode copiar arquivos de URLs. COPY não tem essas capacidades. Sempre que possível, evite usar ADD para não ficar suscetível a ataques através de URLs remotas e arquivos Zip.
- Tenha contêineres separados para cada microsserviço.
- Não coloque ssh dentro do contêiner, "docker exec" pode ser usado para ssh para o contêiner.
- Tenha imagens de contêiner menores.
Quebra de Segurança / Escalação de Privilégios do Docker
Se você estiver dentro de um contêiner do Docker ou tiver acesso a um usuário no grupo docker, você pode tentar escapar e escalar privilégios:
{% content-ref url="docker-breakout-privilege-escalation/" %} docker-breakout-privilege-escalation {% endcontent-ref %}
Bypass do Plugin de Autenticação do Docker
Se você tiver acesso ao socket do Docker ou tiver acesso a um usuário no grupo docker, mas suas ações estiverem sendo limitadas por um plugin de autenticação do Docker, verifique se você pode burlá-lo:
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
Fortalecimento do Docker
- A ferramenta docker-bench-security é um script que verifica dezenas de práticas recomendadas comuns em torno da implantação de contêineres Docker em produção. Os testes são todos automatizados e baseados no CIS Docker Benchmark v1.3.1.
Você precisa executar a ferramenta no host que executa o Docker ou em um contêiner com privilégios suficientes. Descubra como executá-lo no README: https://github.com/docker/docker-bench-security.
Referências
- [https