1.8 KiB
Información básica
Apache Hadoop es un marco de código abierto que admite el almacenamiento y procesamiento distribuido de grandes conjuntos de datos utilizando clústeres informáticos. El almacenamiento es manejado por el Sistema de Archivos Distribuidos de Hadoop (HDFS) y el procesamiento se realiza mediante el uso de MapReduce y otras aplicaciones (por ejemplo, Apache Storm, Flink y Spark) a través de YARN.
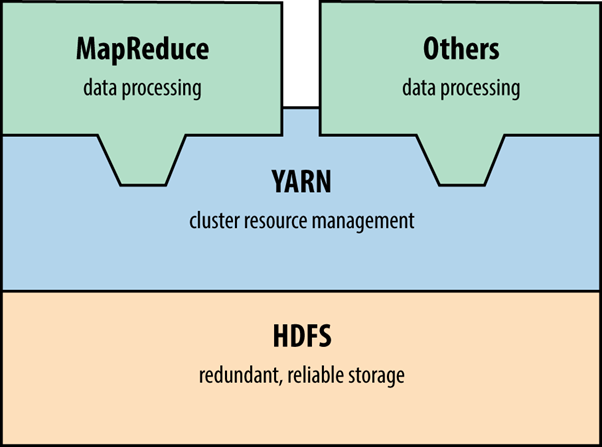
Figura 15-1. Arquitectura de Hadoop 2.0
Puede consultar los servicios MapReduce y HDFS utilizando los scripts de Nmap que se enumeran en la siguiente tabla (incluidos los detalles de los puertos predeterminados). En el momento de escribir este artículo, Metasploit no admite Hadoop.
| Nombre del script | Puerto | Propósito |
|---|---|---|
| hadoop-jobtracker-info | 50030 | Recuperar información de los servicios de seguimiento de trabajos y tareas de MapReduce |
| hadoop-tasktracker-info | 50060 | |
| hadoop-namenode-info | 50070 | Recuperar información del nodo de nombre HDFS |
| hadoop-datanode-info | 50075 | Recuperar información del nodo de datos HDFS |
| hadoop-secondary-namenode-info | 50090 | Recuperar información del nodo de nombre secundario HDFS |
Hay clientes HDFS ligeros de Python y Go disponibles en línea. Hadoop se ejecuta sin autenticación de forma predeterminada. Puede configurar los servicios HDFS, YARN y MapReduce para que usen Kerberos.