| .. | ||
| heap-overflow.md | ||
| README.md | ||
| use-after-free.md | ||
Heap
Conceitos Básicos do Heap
O heap é basicamente o local onde um programa pode armazenar dados quando solicita dados chamando funções como malloc, calloc... Além disso, quando essa memória não é mais necessária, ela é liberada chamando a função free.
Como mostrado, o heap está logo após onde o binário está sendo carregado na memória (verifique a seção [heap]):

Alocação Básica de Chunks
Quando alguns dados são solicitados para serem armazenados no heap, um espaço do heap é alocado para ele. Este espaço pertencerá a um bin e apenas os dados solicitados + o espaço dos cabeçalhos do bin + o deslocamento mínimo do tamanho do bin serão reservados para o chunk. O objetivo é reservar a menor quantidade de memória possível sem tornar complicado encontrar onde cada chunk está. Para isso, as informações de metadados do chunk são usadas para saber onde cada chunk usado/livre está.
Existem diferentes maneiras de reservar o espaço, principalmente dependendo do bin usado, mas uma metodologia geral é a seguinte:
- O programa começa solicitando uma certa quantidade de memória.
- Se na lista de chunks houver alguém disponível grande o suficiente para atender à solicitação, ele será usado.
- Isso pode até significar que parte do chunk disponível será usada para essa solicitação e o restante será adicionado à lista de chunks.
- Se não houver nenhum chunk disponível na lista, mas ainda houver espaço na memória alocada do heap, o gerenciador de heap cria um novo chunk.
- Se não houver espaço suficiente no heap para alocar o novo chunk, o gerenciador de heap pede ao kernel para expandir a memória alocada para o heap e depois usa essa memória para gerar o novo chunk.
- Se tudo falhar, o
mallocretorna nulo.
Observe que se a memória solicitada ultrapassar um limite, o mmap será usado para mapear a memória solicitada.
Arenas
Em aplicações multithread, o gerenciador de heap deve evitar condições de corrida que podem levar a falhas. Inicialmente, isso era feito usando um mutex global para garantir que apenas uma thread pudesse acessar o heap de cada vez, mas isso causava problemas de desempenho devido ao gargalo induzido pelo mutex.
Para resolver isso, o alocador de heap ptmalloc2 introduziu "arenas", onde cada arena age como um heap separado com suas próprias estruturas de dados e mutex, permitindo que várias threads realizem operações de heap sem interferir umas com as outras, desde que usem arenas diferentes.
A arena "principal" padrão lida com operações de heap para aplicativos de thread única. Quando novas threads são adicionadas, o gerenciador de heap as atribui a arenas secundárias para reduzir a contenção. Ele primeiro tenta anexar cada nova thread a uma arena não utilizada, criando novas se necessário, até um limite de 2 vezes os núcleos da CPU para sistemas de 32 bits e 8 vezes para sistemas de 64 bits. Uma vez que o limite é atingido, as threads devem compartilhar arenas, levando a uma possível contenção.
Ao contrário da arena principal, que se expande usando a chamada de sistema brk, as arenas secundárias criam "subheaps" usando mmap e mprotect para simular o comportamento do heap, permitindo flexibilidade no gerenciamento de memória para operações multithread.
Subheaps
Os subheaps servem como reservas de memória para arenas secundárias em aplicações multithread, permitindo que cresçam e gerenciem suas próprias regiões de heap separadamente do heap principal. Veja como os subheaps diferem do heap inicial e como operam:
- Heap Inicial vs. Subheaps:
- O heap inicial está localizado diretamente após o binário do programa na memória e se expande usando a chamada de sistema
sbrk. - Os subheaps, usados pelas arenas secundárias, são criados por meio de
mmap, uma chamada de sistema que mapeia uma região de memória especificada.
- Reserva de Memória com
mmap:
- Quando o gerenciador de heap cria um subheap, ele reserva um grande bloco de memória por meio de
mmap. Essa reserva não aloca memória imediatamente; simplesmente designa uma região que outros processos do sistema ou alocações não devem usar. - Por padrão, o tamanho reservado para um subheap é de 1 MB para processos de 32 bits e 64 MB para processos de 64 bits.
- Expansão Gradual com
mprotect:
- A região de memória reservada é inicialmente marcada como
PROT_NONE, indicando que o kernel não precisa alocar memória física para este espaço ainda. - Para "expandir" o subheap, o gerenciador de heap usa
mprotectpara alterar as permissões da página dePROT_NONEparaPROT_READ | PROT_WRITE, fazendo com que o kernel aloque memória física para os endereços previamente reservados. Esse abordagem passo a passo permite que o subheap se expanda conforme necessário. - Uma vez que todo o subheap esteja esgotado, o gerenciador de heap cria um novo subheap para continuar a alocação.
Metadados
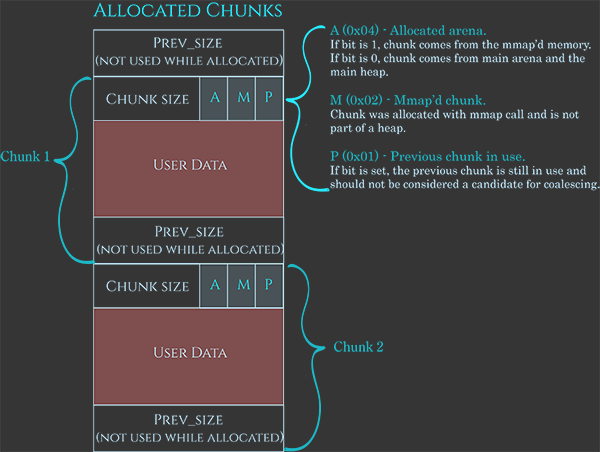
Como comentado anteriormente, esses chunks também possuem alguns metadados, muito bem representados nesta imagem:

https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
{kind=link}
Os metadados geralmente são 0x08B, indicando o tamanho atual do chunk usando os últimos 3 bits para indicar:
A: Se 1, vem de um subheap; se 0, está na arena principal.M: Se 1, este chunk faz parte de um espaço alocado com mmap e não faz parte de um heap.P: Se 1, o chunk anterior está em uso.
Em seguida, o espaço para os dados do usuário e, finalmente, 0x08B para indicar o tamanho do chunk anterior quando o chunk estiver disponível (ou para armazenar os dados do usuário quando estiver alocado).
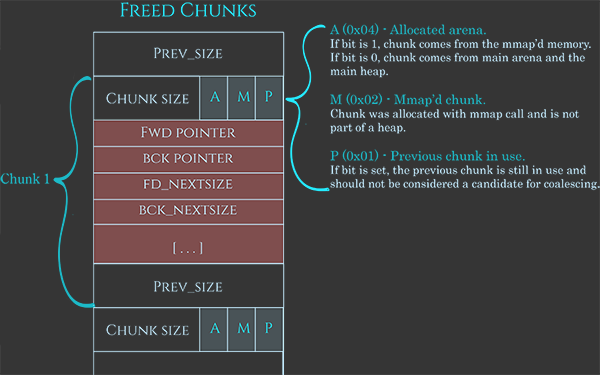
Além disso, quando disponível, os dados do usuário são usados para conter também algumas informações:
- Ponteiro para o próximo chunk.
- Ponteiro para o chunk anterior.
- Tamanho do próximo chunk na lista.
- Tamanho do chunk anterior na lista.
https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png
Observe como organizar a lista dessa maneira evita a necessidade de ter uma matriz onde cada chunk único está sendo registrado.
Proteções de Liberação
Para proteger contra o uso acidental ou intencional da função free, antes de executar suas ações, ela realiza algumas verificações:
- Verifica se o endereço está alinhado em um limite de 8 bytes ou 16 bytes em um limite de 64 bits (
(endereço % 16) == 0), já que o malloc garante que todas as alocações são alinhadas. - Verifica se o campo de tamanho do chunk não é impossível - seja porque é muito pequeno, muito grande, não é um tamanho alinhado ou sobrepõe o final do espaço de endereço do processo.
- Verifica se o chunk está dentro dos limites da arena.
- Verifica se o chunk não está marcado como livre verificando o bit "P" correspondente que está nos metadados no início do próximo chunk.
Bins
Para melhorar a eficiência de como os chunks são armazenados, cada chunk não está apenas em uma lista encadeada, mas existem vários tipos. Estes são os bins e existem 5 tipos de bins: 62 small bins, 63 large bins, 1 unsorted bin, 10 fast bins e 64 tcache bins por thread.
O endereço inicial de cada unsorted, small e large bins está dentro do mesmo array. O índice 0 não é utilizado, 1 é o unsorted bin, os bins 2-64 são small bins e os bins 65-127 são large bins.
Small Bins
Small bins são mais rápidos que large bins, mas mais lentos que fast bins.
Cada bin dos 62 terá chunks do mesmo tamanho: 16, 24, ... (com um tamanho máximo de 504 bytes em 32 bits e 1024 em 64 bits). Isso ajuda na velocidade de encontrar o bin onde um espaço deve ser alocado e na inserção e remoção de entradas nessas listas.
Large Bins
Ao contrário dos small bins, que gerenciam chunks de tamanhos fixos, cada large bin lida com uma faixa de tamanhos de chunk. Isso é mais flexível, permitindo que o sistema acomode vários tamanhos sem precisar de um bin separado para cada tamanho.
Em um alocador de memória, large bins começam onde small bins terminam. As faixas para large bins crescem progressivamente maiores, significando que o primeiro bin pode cobrir chunks de 512 a 576 bytes, enquanto o próximo cobre de 576 a 640 bytes. Esse padrão continua, com o maior bin contendo todos os chunks acima de 1MB.
Large bins são mais lentos de operar em comparação com small bins porque eles precisam ordenar e pesquisar em uma lista de tamanhos de chunk variados para encontrar o melhor encaixe para uma alocação. Quando um chunk é inserido em um large bin, ele precisa ser ordenado, e quando a memória é alocada, o sistema precisa encontrar o chunk certo. Esse trabalho extra os torna mais lentos, mas como alocações grandes são menos comuns do que as pequenas, é uma troca aceitável.
Existem:
- 32 bins de faixa de 64B
- 16 bins de faixa de 512B
- 8 bins de faixa de 4096B
- 4 bins de faixa de 32768B
- 2 bins de faixa de 262144B
- 1 bin para tamanhos restantes
Unsorted bin
O unsorted bin é um cache rápido usado pelo gerenciador de heap para tornar a alocação de memória mais rápida. Veja como funciona: Quando um programa libera memória, o gerenciador de heap não a coloca imediatamente em um bin específico. Em vez disso, primeiro tenta fundir com quaisquer chunks livres vizinhos para criar um bloco maior de memória livre. Em seguida, coloca esse novo chunk em um bin geral chamado "unsorted bin".
Quando um programa solicita memória, o gerenciador de heap verifica primeiro o unsorted bin para ver se há um chunk do tamanho certo. Se encontrar um, o utiliza imediatamente, o que é mais rápido do que procurar em outros bins. Se não encontrar um chunk adequado, move os chunks liberados para seus bins corretos, seja small ou large, com base em seus tamanhos.
Portanto, o unsorted bin é uma maneira de acelerar a alocação de memória reutilizando rapidamente a memória liberada recentemente e reduzindo a necessidade de pesquisas e fusões demoradas.
{% hint style="danger" %} Observe que mesmo que os chunks sejam de categorias diferentes, de tempos em tempos, se um chunk disponível estiver colidindo com outro chunk disponível (mesmo que sejam de categorias diferentes), eles serão fundidos. {% endhint %}
Fast bins
Fast bins são projetados para acelerar a alocação de memória para pequenos chunks mantendo chunks liberados recentemente em uma estrutura de acesso rápido. Esses bins usam uma abordagem Last-In, First-Out (LIFO), o que significa que o chunk liberado mais recentemente é o primeiro a ser reutilizado quando há uma nova solicitação de alocação. Esse comportamento é vantajoso para a velocidade, pois é mais rápido inserir e remover do topo de uma pilha (LIFO) em comparação com uma fila (FIFO).
Além disso, fast bins usam listas encadeadas simples, não duplamente encadeadas, o que melhora ainda mais a velocidade. Como os chunks em fast bins não são mesclados com vizinhos, não há necessidade de uma estrutura complexa que permita a remoção do meio. Uma lista encadeada simples é mais simples e rápida para essas operações.
Basicamente, o que acontece aqui é que o cabeçalho (o ponteiro para o primeiro chunk a ser verificado) está sempre apontando para o chunk liberado mais recentemente desse tamanho. Então:
- Quando um novo chunk é alocado desse tamanho, o cabeçalho está apontando para um chunk livre para usar. Como este chunk livre está apontando para o próximo a ser usado, este endereço é armazenado no cabeçalho para que a próxima alocação saiba onde obter um chunk disponível.
- Quando um chunk é liberado, o chunk livre salvará o endereço para o chunk disponível atual e o endereço para este novo chunk liberado será colocado no cabeçalho.
{% hint style="danger" %} Chunks em fast bins não são definidos automaticamente como disponíveis, então eles permanecem como chunks de fast bin por algum tempo em vez de poderem ser mesclados com outros chunks. {% endhint %}
Tcache (Cache por Thread) Bins
Mesmo que as threads tentem ter sua própria heap (veja Arenas e Subheaps), há a possibilidade de que um processo com muitas threads (como um servidor web) acabe compartilhando a heap com outras threads. Nesse caso, a solução principal é o uso de lockers, que podem desacelerar significativamente as threads.
Portanto, um tcache é semelhante a um fast bin por thread no sentido de que é uma lista encadeada simples que não mescla chunks. Cada thread tem 64 tcache bins singly-linked. Cada bin pode ter um máximo de 7 chunks do mesmo tamanho variando de 24 a 1032B em sistemas de 64 bits e 12 a 516B em sistemas de 32 bits.
Quando uma thread libera um chunk, se não for muito grande para ser alocado no tcache e o respectivo tcache bin não estiver cheio (já com 7 chunks), será alocado lá. Se não puder ir para o tcache, precisará aguardar o bloqueio da heap para poder realizar a operação de liberação globalmente.
Quando um chunk é alocado, se houver um chunk livre do tamanho necessário no Tcache, ele será usado, caso contrário, precisará aguardar o bloqueio da heap para poder encontrar um nos bins globais ou criar um novo.
Há também uma otimização, nesse caso, enquanto tiver o bloqueio da heap, a thread preencherá seu Tcache com chunks da heap (7) do tamanho solicitado, para que, caso precise de mais, os encontre no Tcache.
Ordem dos Bins
Para alocação:
- Se houver um chunk disponível no Tcache desse tamanho, use o Tcache
- Se for muito grande, use mmap
- Obtenha o bloqueio do heap da arena e:
- Se houver tamanho pequeno suficiente, um chunk de fast bin disponível do tamanho solicitado, use-o e preencha o tcache a partir do fast bin
- Verifique cada entrada na lista não ordenada procurando por um chunk grande o suficiente e preencha o tcache se possível
- Verifique os bins pequenos ou grandes (de acordo com o tamanho solicitado) e preencha o tcache se possível
- Crie um novo chunk a partir da memória disponível
- Se não houver memória disponível, obtenha mais usando
sbrk - Se a memória do heap principal não puder crescer mais, crie um novo espaço usando mmap
- Se nada funcionar, retorne nulo
Para liberar:
- Se o ponteiro for Nulo, termine
- Execute verificações de integridade
freeno chunk para tentar verificar se é um chunk legítimo - Se for pequeno o suficiente e o tcache não estiver cheio, coloque-o lá
- Se o bit M estiver definido (não heap), use
munmap - Obtenha o bloqueio do heap da arena:
- Se couber em um fastbin, coloque-o lá
- Se o chunk for > 64KB, consolide imediatamente os fastbins e coloque os chunks mesclados resultantes no bin não ordenado.
- Mesclar o chunk para trás e para frente com chunks liberados vizinhos nos bins pequenos, grandes e não ordenados, se houver.
- Se estiver no topo da cabeça, mesclar na memória não utilizada
- Se não for o anterior, armazená-lo na lista não ordenada
\
Exemplo rápido de heap de https://guyinatuxedo.github.io/25-heap/index.html mas em arm64:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void main(void)
{
char *ptr;
ptr = malloc(0x10);
strcpy(ptr, "panda");
}
Defina um ponto de interrupção no final da função principal e vamos descobrir onde as informações foram armazenadas:
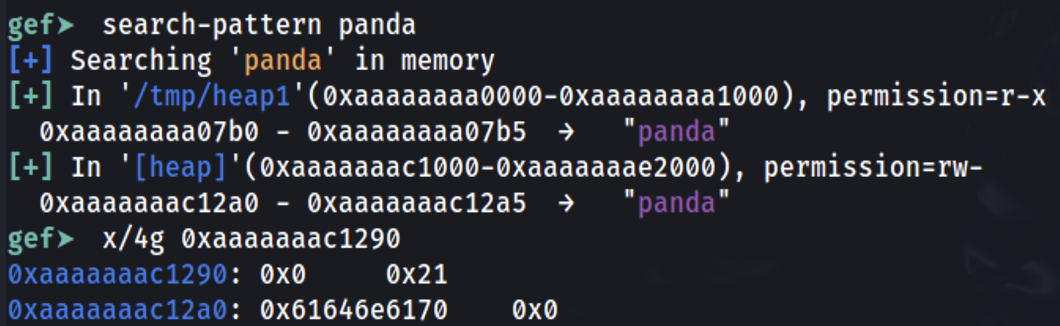
É possível ver que a string panda foi armazenada em 0xaaaaaaac12a0 (que foi o endereço fornecido como resposta pelo malloc dentro de x0). Verificando 0x10 bytes antes, é possível ver que o 0x0 representa que o chunk anterior não está em uso (comprimento 0) e que o comprimento deste chunk é 0x21.
Os espaços extras reservados (0x21-0x10=0x11) vêm dos cabeçalhos adicionados (0x10) e 0x1 não significa que foi reservado 0x21B, mas os últimos 3 bits do comprimento do cabeçalho atual têm alguns significados especiais. Como o comprimento é sempre alinhado em múltiplos de 16 bytes (em máquinas de 64 bits), esses bits na verdade nunca serão usados pelo número de comprimento.
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena