| .. | ||
| docker-breakout-privilege-escalation | ||
| namespaces | ||
| abusing-docker-socket-for-privilege-escalation.md | ||
| apparmor.md | ||
| authz-and-authn-docker-access-authorization-plugin.md | ||
| cgroups.md | ||
| docker-privileged.md | ||
| README.md | ||
| seccomp.md | ||
| weaponizing-distroless.md | ||
Bezpieczeństwo Docker
Zacznij od zera i stań się ekspertem od hakowania AWS dzięki htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną na HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud na GitHubie.

Użyj Trickest, aby łatwo tworzyć i automatyzować przepływy pracy z wykorzystaniem najbardziej zaawansowanych narzędzi społeczności.
Zdobądź dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Podstawowe zabezpieczenia silnika Docker
Silnik Docker wykorzystuje Przestrzenie nazw i Grupy kontrolne (Cgroups) jądra Linuxa do izolowania kontenerów, oferując podstawową warstwę zabezpieczeń. Dodatkową ochronę zapewnia Upuszczanie uprawnień (Capabilities dropping), Seccomp oraz SELinux/AppArmor, zwiększając izolację kontenerów. Plugin auth może dodatkowo ograniczyć działania użytkownika.
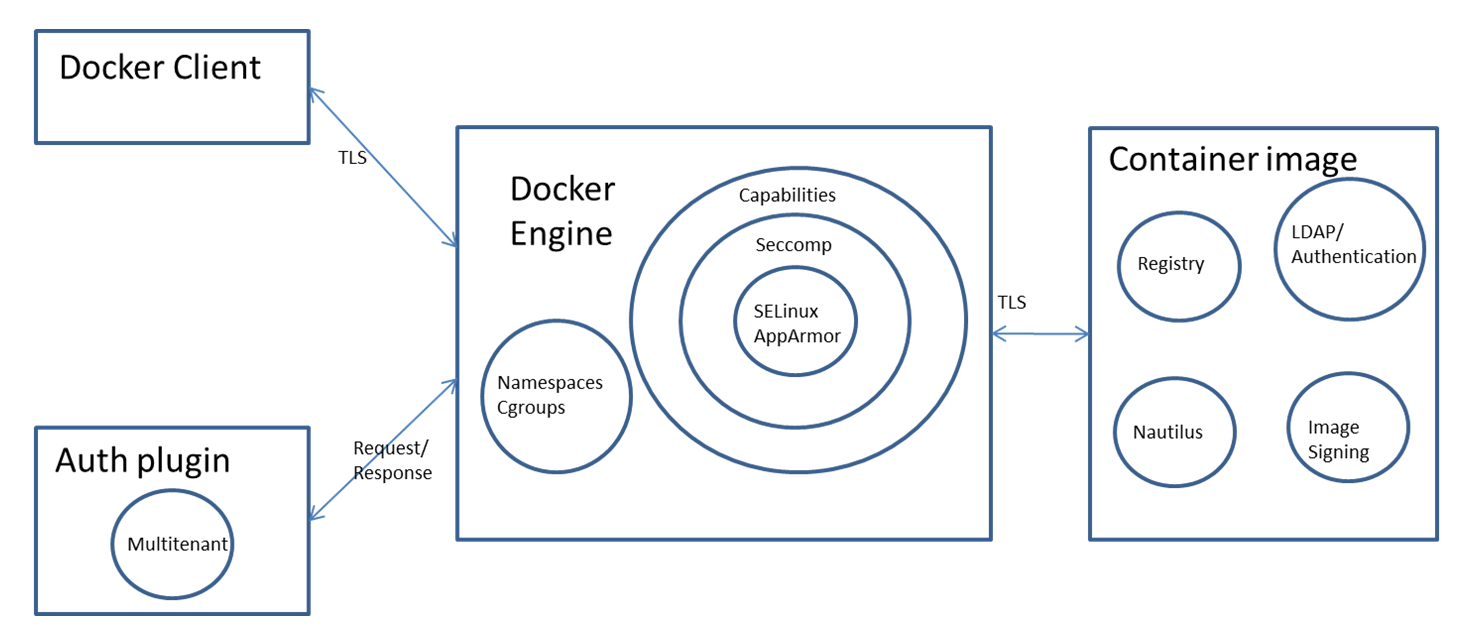
Bezpieczny dostęp do silnika Docker
Silnik Docker można uzyskać lokalnie za pomocą gniazda Unix lub zdalnie za pomocą protokołu HTTP. W przypadku zdalnego dostępu istotne jest korzystanie z HTTPS i TLS w celu zapewnienia poufności, integralności i uwierzytelnienia.
Silnik Docker domyślnie nasłuchuje na gnieździe Unix pod adresem unix:///var/run/docker.sock. W systemach Ubuntu opcje uruchamiania Dockera są zdefiniowane w /etc/default/docker. Aby umożliwić zdalny dostęp do interfejsu API i klienta Dockera, wystarczy wystawić demona Dockera na gnieździe HTTP, dodając następujące ustawienia:
DOCKER_OPTS="-D -H unix:///var/run/docker.sock -H tcp://192.168.56.101:2376"
sudo service docker restart
Jednak wystawianie demona Dockera przez HTTP nie jest zalecane ze względów bezpieczeństwa. Zaleca się zabezpieczenie połączeń za pomocą protokołu HTTPS. Istnieją dwa główne podejścia do zabezpieczenia połączenia:
- Klient weryfikuje tożsamość serwera.
- Zarówno klient, jak i serwer wzajemnie uwierzytelniają swoje tożsamości.
Certyfikaty są wykorzystywane do potwierdzenia tożsamości serwera. Aby uzyskać szczegółowe przykłady obu metod, zapoznaj się z tym przewodnikiem.
Bezpieczeństwo obrazów kontenerów
Obrazy kontenerów można przechowywać w prywatnych lub publicznych repozytoriach. Docker oferuje kilka opcji przechowywania obrazów kontenerów:
- Docker Hub: Usługa publicznego rejestru od Dockera.
- Docker Registry: Projekt open-source, który pozwala użytkownikom hostować własny rejestr.
- Docker Trusted Registry: Komercyjny rejestr Dockera oferujący uwierzytelnianie użytkowników oparte na rolach oraz integrację z usługami katalogowymi LDAP.
Skanowanie obrazów
Kontenery mogą mieć luki bezpieczeństwa zarówno z powodu obrazu bazowego, jak i z powodu oprogramowania zainstalowanego na nim. Docker pracuje nad projektem o nazwie Nautilus, który skanuje kontenery pod kątem bezpieczeństwa i wyświetla luki. Nautilus działa poprzez porównanie każdej warstwy obrazu kontenera z repozytorium podatności w celu zidentyfikowania luk bezpieczeństwa.
Aby uzyskać więcej informacji, przeczytaj to.
docker scan
Polecenie docker scan umożliwia skanowanie istniejących obrazów Dockera za pomocą nazwy obrazu lub identyfikatora. Na przykład, uruchom poniższe polecenie, aby przeskanować obraz hello-world:
docker scan hello-world
Testing hello-world...
Organization: docker-desktop-test
Package manager: linux
Project name: docker-image|hello-world
Docker image: hello-world
Licenses: enabled
✓ Tested 0 dependencies for known issues, no vulnerable paths found.
Note that we do not currently have vulnerability data for your image.
trivy -q -f json <container_name>:<tag>
snyk container test <image> --json-file-output=<output file> --severity-threshold=high
clair-scanner -w example-alpine.yaml --ip YOUR_LOCAL_IP alpine:3.5
Podpisywanie obrazów Docker
Podpisywanie obrazów Docker zapewnia bezpieczeństwo i integralność obrazów używanych w kontenerach. Oto zwięzłe wyjaśnienie:
- Zaufanie do Zawartości Dockera wykorzystuje projekt Notary, oparty na The Update Framework (TUF), do zarządzania podpisami obrazów. Więcej informacji można znaleźć na stronach Notary i TUF.
- Aby aktywować zaufanie do zawartości Dockera, ustaw
export DOCKER_CONTENT_TRUST=1. Ta funkcja jest domyślnie wyłączona w wersji Dockera 1.10 i nowszych. - Po włączeniu tej funkcji, można pobierać tylko podpisane obrazy. Pierwsze przesłanie obrazu wymaga ustawienia haseł dla kluczy root i tagowania, a Docker obsługuje również Yubikey dla zwiększonego bezpieczeństwa. Więcej szczegółów można znaleźć tutaj.
- Próba pobrania niepodpisanego obrazu przy włączonym zaufaniu do zawartości kończy się błędem "Brak danych zaufania dla najnowszej wersji".
- Podczas kolejnych przesyłek obrazów, Docker prosi o hasło klucza repozytorium do podpisania obrazu.
Aby zabezpieczyć swoje klucze prywatne, użyj polecenia:
tar -zcvf private_keys_backup.tar.gz ~/.docker/trust/private
Podczas zmiany hostów Dockerowych konieczne jest przeniesienie kluczy roota i repozytorium, aby utrzymać operacje.
Użyj Trickest, aby łatwo budować i automatyzować przepływy pracy zasilane przez najbardziej zaawansowane narzędzia społecznościowe na świecie.
Otrzymaj dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Funkcje Bezpieczeństwa Kontenerów
Podsumowanie funkcji bezpieczeństwa kontenerów
Główne funkcje izolacji procesów
W środowiskach skonteneryzowanych izolacja projektów i ich procesów jest kluczowa dla bezpieczeństwa i zarządzania zasobami. Oto uproszczone wyjaśnienie kluczowych koncepcji:
Przestrzenie nazw (Namespaces)
- Cel: Zapewnienie izolacji zasobów, takich jak procesy, sieć i systemy plików. W szczególności w Dockerze przestrzenie nazw utrzymują procesy kontenera oddzielone od hosta i innych kontenerów.
- Użycie
unshare: Polecenieunshare(lub wywołanie systemowe) jest wykorzystywane do tworzenia nowych przestrzeni nazw, zapewniając dodatkową warstwę izolacji. Jednak podczas gdy Kubernetes nie blokuje tego domyślnie, Docker tak. - Ograniczenie: Tworzenie nowych przestrzeni nazw nie pozwala procesowi powrócić do domyślnych przestrzeni nazw hosta. Aby przeniknąć do przestrzeni nazw hosta, zazwyczaj wymagane jest dostęp do katalogu
/prochosta, korzystając znsenterdo wejścia.
Grupy Kontrolne (CGroups)
- Funkcja: Głównie używane do przydzielania zasobów między procesami.
- Aspekt bezpieczeństwa: Same CGroups nie oferują izolacji bezpieczeństwa, z wyjątkiem funkcji
release_agent, która w przypadku błędnej konfiguracji może potencjalnie być wykorzystana do nieautoryzowanego dostępu.
Odrzucanie Uprawnień (Capability Drop)
- Znaczenie: Jest to istotna funkcja bezpieczeństwa dla izolacji procesów.
- Funkcjonalność: Ogranicza działania, które może wykonać proces root poprzez odrzucenie określonych uprawnień. Nawet jeśli proces działa z uprawnieniami roota, brak niezbędnych uprawnień uniemożliwia mu wykonywanie uprzywilejowanych działań, ponieważ wywołania systemowe zakończą się niepowodzeniem z powodu niewystarczających uprawnień.
To są pozostałe uprawnienia po odrzuceniu pozostałych przez proces:
{% code overflow="wrap" %}
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=ep
{% endcode %}
Seccomp
Jest domyślnie włączony w Dockerze. Pomaga jeszcze bardziej ograniczyć syscalle, które proces może wywołać.
Domyślny profil Seccomp Dockera można znaleźć pod adresem https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
AppArmor
Docker ma szablon, który można aktywować: https://github.com/moby/moby/tree/master/profiles/apparmor
To pozwoli na ograniczenie uprawnień, syscalle, dostęp do plików i folderów...
Namespaces
Namespaces to funkcja jądra Linuxa, która dzieli zasoby jądra tak, że jedna grupa procesów widzi jeden zestaw zasobów, podczas gdy inna grupa procesów widzi inny zestaw zasobów. Funkcja działa poprzez posiadanie tego samego przestrzeni nazw dla zestawu zasobów i procesów, ale te przestrzenie nazw odnoszą się do odrębnych zasobów. Zasoby mogą istnieć w wielu przestrzeniach.
Docker wykorzystuje następujące przestrzenie nazw jądra Linuxa do osiągnięcia izolacji kontenerów:
- przestrzeń nazw pid
- przestrzeń nazw montowania
- przestrzeń nazw sieciowa
- przestrzeń nazw ipc
- przestrzeń nazw UTS
Dla więcej informacji na temat przestrzeni nazw sprawdź następującą stronę:
{% content-ref url="namespaces/" %} namespaces {% endcontent-ref %}
cgroups
Funkcja jądra Linuxa cgroups zapewnia możliwość ograniczenia zasobów takich jak cpu, pamięć, io, przepustowość sieci wśród zestawu procesów. Docker pozwala tworzyć kontenery przy użyciu funkcji cgroup, co umożliwia kontrolę zasobów dla konkretnego kontenera.
Poniżej znajduje się kontener utworzony z ograniczeniem pamięci przestrzeni użytkownika do 500m, pamięci jądra do 50m, udziału CPU do 512, wagi blkioweight do 400. Udział CPU to współczynnik kontrolujący użycie CPU kontenera. Ma domyślną wartość 1024 i zakres od 0 do 1024. Jeśli trzy kontenery mają ten sam udział CPU wynoszący 1024, każdy kontener może zużyć do 33% CPU w przypadku konfliktu zasobów CPU. blkio-weight to współczynnik kontrolujący IO kontenera. Ma domyślną wartość 500 i zakres od 10 do 1000.
docker run -it -m 500M --kernel-memory 50M --cpu-shares 512 --blkio-weight 400 --name ubuntu1 ubuntu bash
Aby uzyskać cgroup kontenera, można wykonać:
docker run -dt --rm denial sleep 1234 #Run a large sleep inside a Debian container
ps -ef | grep 1234 #Get info about the sleep process
ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the hosts and some may be shred with it)
Dla dalszych informacji sprawdź:
{% content-ref url="cgroups.md" %} cgroups.md {% endcontent-ref %}
Uprawnienia
Uprawnienia pozwalają na dokładniejszą kontrolę uprawnień, które mogą być udzielone użytkownikowi root. Docker wykorzystuje funkcję możliwości jądra Linuxa do ograniczenia operacji, które można wykonać wewnątrz kontenera niezależnie od rodzaju użytkownika.
Gdy uruchamiany jest kontener Docker, proces odrzuca wrażliwe uprawnienia, które proces mógłby wykorzystać do ucieczki z izolacji. Ma to zapewnić, że proces nie będzie w stanie wykonywać wrażliwych działań i uciec:
{% content-ref url="../linux-capabilities.md" %} linux-capabilities.md {% endcontent-ref %}
Seccomp w Dockerze
Jest to funkcja zabezpieczeń, która pozwala Dockerowi ograniczyć wywołania systemowe, które mogą być używane wewnątrz kontenera:
{% content-ref url="seccomp.md" %} seccomp.md {% endcontent-ref %}
AppArmor w Dockerze
AppArmor to ulepszenie jądra do ograniczania kontenerów do ograniczonego zestawu zasobów z profilami na poziomie programu:
{% content-ref url="apparmor.md" %} apparmor.md {% endcontent-ref %}
SELinux w Dockerze
- System Etykietowania: SELinux przypisuje unikalną etykietę do każdego procesu i obiektu systemu plików.
- Egzekwowanie Polityki: Egzekwuje polityki bezpieczeństwa, które definiują, jakie działania etykieta procesu może wykonać na innych etykietach w systemie.
- Etykiety Procesów Kontenera: Gdy silniki kontenerów inicjują procesy kontenera, zazwyczaj są one przypisywane do ograniczonej etykiety SELinux, zwykle
container_t. - Etykietowanie Plików w Kontenerach: Pliki wewnątrz kontenera są zazwyczaj oznaczone jako
container_file_t. - Zasady Polityki: Polityka SELinux głównie zapewnia, że procesy z etykietą
container_tmogą tylko współdziałać (czytać, pisać, wykonywać) z plikami oznaczonymi jakocontainer_file_t.
Ten mechanizm zapewnia, że nawet jeśli proces wewnątrz kontenera zostanie skompromitowany, jest on ograniczony do współdziałania tylko z obiektami posiadającymi odpowiadające etykiety, znacznie ograniczając potencjalne szkody wynikające z takich kompromitacji.
{% content-ref url="../selinux.md" %} selinux.md {% endcontent-ref %}
AuthZ & AuthN
W Dockerze wtyczka autoryzacji odgrywa kluczową rolę w zabezpieczeniach, decydując, czy zezwolić czy zablokować żądania do demona Dockera. Decyzja ta jest podejmowana poprzez analizę dwóch kluczowych kontekstów:
- Kontekst Autoryzacji: Obejmuje kompleksowe informacje o użytkowniku, takie jak kim są i w jaki sposób się uwierzytelnili.
- Kontekst Komendy: Obejmuje wszystkie istotne dane związane z żądaniem.
Te konteksty pomagają zapewnić, że tylko legalne żądania od uwierzytelnionych użytkowników są przetwarzane, zwiększając bezpieczeństwo operacji Dockera.
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
Atak typu DoS z kontenera
Jeśli nie ograniczasz odpowiednio zasobów, jakie może wykorzystać kontener, skompromitowany kontener może przeprowadzić atak typu DoS na host, na którym działa.
- Atak DoS CPU
# stress-ng
sudo apt-get install -y stress-ng && stress-ng --vm 1 --vm-bytes 1G --verify -t 5m
# While loop
docker run -d --name malicious-container -c 512 busybox sh -c 'while true; do :; done'
- Atak DoS na pasmo
nc -lvp 4444 >/dev/null & while true; do cat /dev/urandom | nc <target IP> 4444; done
Interesujące flagi Docker
--privileged flag
Na następnej stronie możesz dowiedzieć się, co oznacza flaga --privileged:
{% content-ref url="docker-privileged.md" %} docker-privileged.md {% endcontent-ref %}
--security-opt
no-new-privileges
Jeśli uruchamiasz kontener, w którym atakujący uzyskuje dostęp jako użytkownik o niskich uprawnieniach. Jeśli masz źle skonfigurowany binarny suid, atakujący może go wykorzystać i eskalować uprawnienia wewnątrz kontenera. Co może pozwolić mu na jego opuszczenie.
Uruchomienie kontenera z opcją no-new-privileges włączoną zapobiegnie tego rodzaju eskalacji uprawnień.
docker run -it --security-opt=no-new-privileges:true nonewpriv
Inne
#You can manually add/drop capabilities with
--cap-add
--cap-drop
# You can manually disable seccomp in docker with
--security-opt seccomp=unconfined
# You can manually disable seccomp in docker with
--security-opt apparmor=unconfined
# You can manually disable selinux in docker with
--security-opt label:disable
Dla więcej opcji --security-opt sprawdź: https://docs.docker.com/engine/reference/run/#security-configuration
Inne Aspekty Bezpieczeństwa
Zarządzanie Sekretami: Najlepsze Praktyki
Niezwykle istotne jest unikanie osadzania sekretów bezpośrednio w obrazach Dockera lub korzystania z zmiennych środowiskowych, ponieważ te metody ujawniają Twoje wrażliwe informacje każdemu, kto ma dostęp do kontenera poprzez polecenia takie jak docker inspect lub exec.
Woluminy Dockera są bezpieczniejszą alternatywą, zalecaną do dostępu do wrażliwych informacji. Mogą być wykorzystywane jako tymczasowy system plików w pamięci, zmniejszając ryzyko związane z docker inspect i logowaniem. Niemniej jednak, użytkownicy root oraz ci z dostępem exec do kontenera mogą wciąż uzyskać dostęp do sekretów.
Sekrety Dockera oferują jeszcze bardziej bezpieczną metodę obsługi wrażliwych informacji. Dla przypadków wymagających sekretów podczas fazy budowy obrazu, BuildKit prezentuje efektywne rozwiązanie z obsługą sekretów czasu budowy, poprawiając szybkość budowy i zapewniając dodatkowe funkcje.
Aby skorzystać z BuildKit, można go aktywować na trzy sposoby:
- Poprzez zmienną środowiskową:
export DOCKER_BUILDKIT=1 - Poprzez prefiksowanie poleceń:
DOCKER_BUILDKIT=1 docker build . - Poprzez włączenie go domyślnie w konfiguracji Dockera:
{ "features": { "buildkit": true } }, a następnie ponowne uruchomienie Dockera.
BuildKit pozwala na użycie sekretów czasu budowy za pomocą opcji --secret, zapewniając, że te sekrety nie są uwzględniane w pamięci podręcznej budowy obrazu ani w ostatecznym obrazie, korzystając z polecenia:
docker build --secret my_key=my_value ,src=path/to/my_secret_file .
Dla potrzebnych tajemnic w uruchomionym kontenerze, Docker Compose i Kubernetes oferują solidne rozwiązania. Docker Compose wykorzystuje klucz secrets w definicji usługi do określenia plików z tajemnicami, jak pokazano w przykładowym pliku docker-compose.yml:
version: "3.7"
services:
my_service:
image: centos:7
entrypoint: "cat /run/secrets/my_secret"
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret_file.txt
Ta konfiguracja pozwala na korzystanie z tajemnic podczas uruchamiania usług za pomocą Docker Compose.
W środowiskach Kubernetes, tajemnice są obsługiwane natywnie i mogą być dalsze zarządzane za pomocą narzędzi takich jak Helm-Secrets. Kontrole dostępu oparte na rolach (RBAC) Kubernetes wzmacniają bezpieczeństwo zarządzania tajemnicami, podobnie jak w Docker Enterprise.
gVisor
gVisor to jądro aplikacji, napisane w Go, które implementuje znaczną część powierzchni systemu Linux. Zawiera środowisko wykonawcze Open Container Initiative (OCI) o nazwie runsc, które zapewnia granice izolacji między aplikacją a jądrem hosta. Środowisko wykonawcze runsc integruje się z Dockerem i Kubernetes, ułatwiając uruchamianie kontenerów w piaskownicy.
{% embed url="https://github.com/google/gvisor" %}
Kata Containers
Kata Containers to społeczność open source, która pracuje nad budową bezpiecznego środowiska wykonawczego kontenerów z lekkimi maszynami wirtualnymi, które działają i wydają się jak kontenery, ale zapewniają silniejszą izolację obciążenia za pomocą technologii wirtualizacji sprzętowej jako drugiej warstwy obrony.
{% embed url="https://katacontainers.io/" %}
Porady Podsumowujące
- Nie używaj flagi
--privilegedani nie montuj gniazda Dockera wewnątrz kontenera. Gniazdo Dockera pozwala na uruchamianie kontenerów, więc jest łatwym sposobem na przejęcie pełnej kontroli nad hostem, na przykład poprzez uruchomienie innego kontenera z flagą--privileged. - Nie uruchamiaj jako root wewnątrz kontenera. Użyj innego użytkownika i przestrzenie nazw użytkownika. Root w kontenerze jest taki sam jak na hoście, chyba że jest przemapowany za pomocą przestrzeni nazw użytkownika. Jest on tylko lekko ograniczony, głównie przez przestrzenie nazw Linuxa, zdolności i cgroups.
- Odrzuć wszystkie zdolności (
--cap-drop=all) i włącz tylko te, które są wymagane (--cap-add=...). Wiele obciążeń nie potrzebuje żadnych zdolności, a dodanie ich zwiększa zakres potencjalnego ataku. - Użyj opcji bez nowych uprawnień bezpieczeństwa aby zapobiec procesom zdobywaniu większych uprawnień, na przykład poprzez binarne suid.
- Ogranicz zasoby dostępne dla kontenera. Limity zasobów mogą chronić maszynę przed atakami typu odmowa usługi.
- Dostosuj profile seccomp, AppArmor (lub SELinux), aby ograniczyć działania i wywołania systemowe dostępne dla kontenera do minimum wymaganego.
- Używaj oficjalnych obrazów Dockera i wymagaj podpisów lub buduj swoje własne na ich podstawie. Nie dziedzicz obrazów z tylnymi drzwiami. Przechowuj również klucze root, hasło w bezpiecznym miejscu. Docker ma plany dotyczące zarządzania kluczami za pomocą UCP.
- Regularnie odbudowuj swoje obrazy, aby zastosować łatki bezpieczeństwa na hoście i obrazach.
- Mądrze zarządzaj swoimi tajemnicami, aby utrudnić atakującemu dostęp do nich.
- Jeśli udsłuchujesz demona Dockera, użyj protokołu HTTPS z uwierzytelnianiem klienta i serwera.
- W pliku Dockerfile, preferuj COPY zamiast ADD. ADD automatycznie wypakowuje skompresowane pliki i może kopiować pliki z adresów URL. COPY nie ma tych możliwości. Zaleca się unikanie użycia ADD, aby nie być podatnym na ataki poprzez zdalne adresy URL i pliki Zip.
- Miej oddzielne kontenery dla każdej mikro-usługi
- Nie umieszczaj ssh wewnątrz kontenera, polecenie “docker exec” może być użyte do połączenia się przez ssh z kontenerem.
- Używaj mniejszych obrazów kontenerów
Ucieczka z Docker / Eskalacja uprawnień
Jeśli jesteś wewnątrz kontenera Dockera lub masz dostęp do użytkownika w grupie docker, możesz spróbować uciec i eskalować uprawnienia:
{% content-ref url="docker-breakout-privilege-escalation/" %} docker-breakout-privilege-escalation {% endcontent-ref %}
Pomijanie Pluginu Autoryzacji Dockera
Jeśli masz dostęp do gniazda Dockera lub użytkownika w grupie docker, ale twoje działania są ograniczone przez plugin autoryzacji Dockera, sprawdź, czy możesz go pominąć:
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
Utrwalanie Dockera
- Narzędzie docker-bench-security to skrypt, który sprawdza dziesiątki powszechnych praktyk dotyczących wdrażania kontenerów Dockera w produkcji. Testy są zautomatyzowane i oparte na CIS Docker Benchmark v1.3.1.
Należy uruchomić narzędzie z hosta uruchamiającego Dockera lub z kontenera z wystarczającymi uprawnieniami. Dowiedz się, jak go uruchomić w pliku README: https://github.com/docker/docker-bench-security.
Odnośniki
- https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
- https://twitter.com/_fel1x/status/1151487051986087936
- https://ajxchapman.github.io/containers/2020/11/19/privileged-container-escape.html
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-1overview/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-2docker-engine/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-3engine-access/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-4container-image/
- https://en.wikipedia.org/wiki/Linux_namespaces
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://www.redhat.com/sysadmin/privileged-flag-container-engines
- https://docs.docker.com/engine/extend/plugins_authorization
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
- https://resources.experfy.com/bigdata-cloud/top-20-docker-security-tips/
Użyj Trickest do łatwego tworzenia i automatyzowania prac z wykorzystaniem najbardziej zaawansowanych narzędzi społeczności.
Zdobądź dostęp już dziś:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Dowiedz się, jak hakować AWS od zera do bohatera z htARTE (HackTricks AWS Red Team Expert)!
Inne sposoby wsparcia HackTricks:
- Jeśli chcesz zobaczyć swoją firmę reklamowaną w HackTricks lub pobrać HackTricks w formacie PDF, sprawdź PLANY SUBSKRYPCYJNE!
- Zdobądź oficjalne gadżety PEASS & HackTricks
- Odkryj Rodzinę PEASS, naszą kolekcję ekskluzywnych NFT
- Dołącz do 💬 grupy Discord lub grupy telegramowej lub śledź nas na Twitterze 🐦 @carlospolopm.
- Podziel się swoimi sztuczkami hakerskimi, przesyłając PR-y do HackTricks i HackTricks Cloud na GitHubie.