| .. | ||
| 4.-pre-training.md | ||
| 5.-fine-tuning-for-classification.md | ||
| README.md | ||
LLM Training - Data Preparation
https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703f313233These are my notes from the book https://www.manning.com/books/build-a-large-language-model-from-scratch (very recommended)
Pretraining
The pre-training phase of a LLM is the moment where the LLM gets a lot of data that makes the LLM learn about the language and everything in general. This base is usually later used to fine-tune it in order to specialise the model into a specific topic.
Main LLM components
Usually a LLM is characterised for the configuration used to train it. This are the common components when training a LLM:
- Parameters: Parameters are the learnable weights and biases in the neural network. These are the numbers that the training process adjusts to minimize the loss function and improve the model's performance on the task. LLMs usually use millions of parameters.
- Embedding Dimension: The size of the vector used to represent each token or word. LLMs usually sue billions of dimensions.
- Hidden Dimension: The size of the hidden layers in the neural network.
- Number of Layers (Depth): How many layers the model has. LLMs usually use tens of layers.
- Number of Attention Heads: In transformer models, this is how many separate attention mechanisms are used in each layer. LLMs usually use tens of heads.
- Dropout: Dropout is something like the percentage of data that is removed (probabilities turn to 0) during training used to prevent overfitting. LLMs usually use between 0-20%.
Configuration of the GPT-2 model:
GPT_CONFIG_124M = {
"vocab_size": 50257, // Vocabulary size of the BPE tokenizer
"context_length": 1024, // Context length
"emb_dim": 768, // Embedding dimension
"n_heads": 12, // Number of attention heads
"n_layers": 12, // Number of layers
"drop_rate": 0.1, // Dropout rate: 10%
"qkv_bias": False // Query-Key-Value bias
}
Tokenizing
Tokenizing consists on separating the data in specific chunks and assign them specific IDs (numbers).
A very simple tokenizer for texts might to just get each word of a text separately, and also punctuation symbols and remove spaces.
Therefore, "Hello, world!" would be: ["Hello", ",", "world", "!"]
Then, in order to assign each of the words and symbols a token ID (number), it's needed to create the tokenizer vocabulary. If you are tokenizing for example a book, this could be all the different word of the book in alphabetic order with some extra tokens like:
[BOS] (Beginning of sequence): Placed at the beggining of a text, it indicates the start of a text (used to separate none related texts).[EOS] (End of sequence): Placed at the end of a text, it indicates the end of a text (used to separate none related texts).[PAD] (padding): When a batch size is larger than one (usually), this token is used to incrase the length of that batch to be as bigger as the others.[UNK] (unknown): To represent unknown words.
Following the example, having tokenized a text assigning each word and symbol of the text a position in the vocabulary, the tokenized sentence "Hello, world!" -> ["Hello", ",", "world", "!"] would be something like: [64, 455, 78, 467] supposing that Hello is at pos 64, "," is at pos 455... in the resulting vocabulary array.
However, if in the text used to generate the vocabulary the word "Bye" didn't exist, this will result in: "Bye, world!" -> ["[UNK]", ",", "world", "!"] -> [987, 455, 78, 467] supposing the token for [UNK] is at 987.
BPE - Byte Pair Encoding
In order to avoid problems like needing to tokenize all the possible words for texts, LLMs like GPT used BPE which basically encodes frequent pairs of bytes to reduce the size of the text in a more optimized format until it cannot be reduced more (check wikipedia). Note that this way there aren't "unknown" words for the vocabulary and the final vocabulary will be all the discovered sets of frequent bytes together grouped as much as possible while bytes that aren't frequently linked with the same byte will be a token themselves.
Code Example
Let's understand this better from a code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb:
# Download a text to pre-train the model
import urllib.request
url = ("https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt")
file_path = "the-verdict.txt"
urllib.request.urlretrieve(url, file_path)
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
# Tokenize the code using GPT2 tokenizer version
import tiktoken
token_ids = tiktoken.get_encoding("gpt2").encode(txt, allowed_special={"[EOS]"}) # Allow the user of the tag "[EOS]"
# Print first 50 tokens
print(token_ids[:50])
#[40, 367, 2885, 1464, 1807, 3619, 402, 271, 10899, 2138, 257, 7026, 15632, 438, 2016, 257, 922, 5891, 1576, 438, 568, 340, 373, 645, 1049, 5975, 284, 502, 284, 3285, 326, 11, 287, 262, 6001, 286, 465, 13476, 11, 339, 550, 5710, 465, 12036, 11, 6405, 257, 5527, 27075, 11]
Data Sampling
LLMs like GPT work by predicting the next word based on the previous ones, therefore in order to prepare some data for training it's necessary to prepare the data this way.
For example, using the text "Lorem ipsum dolor sit amet, consectetur adipiscing elit,"
In order to prepare the model to learn predicting the following word (supposing each word is a token using the very basic tokenizer), and using a max size of 4 and a sliding window of 1, this is how the text should be prepared:
Input: [
["Lorem", "ipsum", "dolor", "sit"],
["ipsum", "dolor", "sit", "amet,"],
["dolor", "sit", "amet,", "consectetur"],
["sit", "amet,", "consectetur", "adipiscing"],
],
Target: [
["ipsum", "dolor", "sit", "amet,"],
["dolor", "sit", "amet,", "consectetur"],
["sit", "amet,", "consectetur", "adipiscing"],
["amet,", "consectetur", "adipiscing", "elit,"],
["consectetur", "adipiscing", "elit,", "sed"],
]
Note that if the sliding window would have been 2, it means that the next entry in the input array will start 2 tokens after and not just one, but the target array will still be predicting only 1 token. In pytorch, this sliding window is expressed in the parameter stride (the smaller stride is, the more overfitting, usually this is equals to the max_length so the same tokens aren't repeated).
Code Example
Let's understand this better from a code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb:
# Download the text to pre-train the LLM
import urllib.request
url = ("https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt")
file_path = "the-verdict.txt"
urllib.request.urlretrieve(url, file_path)
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
"""
Create a class that will receive some params lie tokenizer and text
and will prepare the input chunks and the target chunks to prepare
the LLM to learn which next token to generate
"""
import torch
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
"""
Create a data loader which given the text and some params will
prepare the inputs and targets with the previous class and
then create a torch DataLoader with the info
"""
import tiktoken
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
"""
Finally, create the data loader with the params we want:
- The used text for training
- batch_size: The size of each batch
- max_length: The size of each entry on each batch
- stride: The sliding window (how many tokens should the next entry advance compared to the previous one). The smaller the more overfitting, usually this is equals to the max_length so the same tokens aren't repeated.
- shuffle: Re-order randomly
"""
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=4, stride=1, shuffle=False
)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
# Note the batch_size of 8, the max_length of 4 and the stride of 1
[
# Input
tensor([[ 40, 367, 2885, 1464],
[ 367, 2885, 1464, 1807],
[ 2885, 1464, 1807, 3619],
[ 1464, 1807, 3619, 402],
[ 1807, 3619, 402, 271],
[ 3619, 402, 271, 10899],
[ 402, 271, 10899, 2138],
[ 271, 10899, 2138, 257]]),
# Target
tensor([[ 367, 2885, 1464, 1807],
[ 2885, 1464, 1807, 3619],
[ 1464, 1807, 3619, 402],
[ 1807, 3619, 402, 271],
[ 3619, 402, 271, 10899],
[ 402, 271, 10899, 2138],
[ 271, 10899, 2138, 257],
[10899, 2138, 257, 7026]])
]
# With stride=4 this will be the result:
[
# Input
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]]),
# Target
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
]
Token Embeddings
Now that we have all the text encoded in tokens it's time to create token embeddings. This embeddings are going to be the weights given each token in the vocabulary on each dimension to train. They usually start by being random small values .
For example, for a vocabulary of size 6 and 3 dimensions (LLMs has ten of thousands of vocabs and billions of dimensions), this is how it's possible to generate some starting embeddings:
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(6, 3)
print(embedding_layer.weight)
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
# This is a way to search the weights based on the index, "3" in this case:
print(embedding_layer(torch.tensor([3])))
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
Note how each token in the vocabulary (each of the 6 rows), has 3 dimensions (3 columns) with a value on each.
Therefore, in our training, each token will have a set of values (dimensions) that will apply weights to it. Therefore, if a training batch is of size 8, with max length of 4 and 256 dimensions. It means that each batch will be a matrix of 8 x 4 x 256 (imagine batches of hundreds of entries, with hundreds of tokens per entries with billions of dimensions...).
The values of the dimensions are fine tuned during the training.
Token Positions Embeddings
If you noticed, the embeddings gives some weights to tokens based only on the token. So if a word (supposing a word is a token) is at the beginning of a text, it'll have the same weights as if it's at the end, although its contributions to the sentence might be different.
Therefore, it's possible to apply absolute positional embeddings or relative positional embeddings. One will take into account the position of the token in the whole sentence, while the other will take into account distances between tokens.
OpenAI GPT uses absolute positional embeddings.
Note that because absolute positional embeddings uses the same dimensions as the token embeddings, they will be added with them but won't add extra dimensions to the matrix.
The position values are fine tuned during the training.
Code Example
Following with the code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb:
# Use previous code...
# Create dimensional emdeddings
"""
BPE uses a vocabulary of 50257 words
Let's supose we want to use 256 dimensions (instead of the millions used by LLMs)
"""
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
## Generate the dataloader like before
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
# Apply embeddings
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
torch.Size([8, 4, 256]) # 8 x 4 x 256
# Generate absolute embeddings
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape) # torch.Size([8, 4, 256])
Attention Mechanisms and Self-Attention in Neural Networks
Attention mechanisms allow neural networks to focus on specific parts of the input when generating each part of the output. They assign different weights to different inputs, helping the model decide which inputs are most relevant to the task at hand. This is crucial in tasks like machine translation, where understanding the context of the entire sentence is necessary for accurate translation.
Understanding Attention Mechanisms
In traditional sequence-to-sequence models used for language translation, the model encodes an input sequence into a fixed-size context vector. However, this approach struggles with long sentences because the fixed-size context vector may not capture all necessary information. Attention mechanisms address this limitation by allowing the model to consider all input tokens when generating each output token.
Example: Machine Translation
Consider translating the German sentence "Kannst du mir helfen diesen Satz zu übersetzen" into English. A word-by-word translation would not produce a grammatically correct English sentence due to differences in grammatical structures between languages. An attention mechanism enables the model to focus on relevant parts of the input sentence when generating each word of the output sentence, leading to a more accurate and coherent translation.
Introduction to Self-Attention
Self-attention, or intra-attention, is a mechanism where attention is applied within a single sequence to compute a representation of that sequence. It allows each token in the sequence to attend to all other tokens, helping the model capture dependencies between tokens regardless of their distance in the sequence.
Key Concepts
- Tokens: Individual elements of the input sequence (e.g., words in a sentence).
- Embeddings: Vector representations of tokens, capturing semantic information.
- Attention Weights: Values that determine the importance of each token relative to others.
Calculating Attention Weights: A Step-by-Step Example
Let's consider the sentence "Hello shiny sun!" and represent each word with a 3-dimensional embedding:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Our goal is to compute the context vector for the word "shiny" using self-attention.
Step 1: Compute Attention Scores
{% hint style="success" %} Just multiply each dimension value of the query with the relevant one of each token and add the results. You get 1 value per pair of tokens. {% endhint %}
For each word in the sentence, compute the attention score with respect to "shiny" by calculating the dot product of their embeddings.
Attention Score between "Hello" and "shiny"

Attention Score between "shiny" and "shiny"

Attention Score between "sun" and "shiny"

Step 2: Normalize Attention Scores to Obtain Attention Weights
{% hint style="success" %} Don't get lost in the mathematical terms, the goal of this function is simple, normalize all the weights so they sum 1 in total.
Moreover, softmax function is used because it accentuates differences due to the exponential part, making easier to detect useful values. {% endhint %}
Apply the softmax function to the attention scores to convert them into attention weights that sum to 1.

Calculating the exponentials:

Calculating the sum:

Calculating attention weights:

Step 3: Compute the Context Vector
{% hint style="success" %} Just get each attention weight and multiply it to the related token dimensions and then sum all the dimensions to get just 1 vector (the context vector) {% endhint %}
The context vector is computed as the weighted sum of the embeddings of all words, using the attention weights.
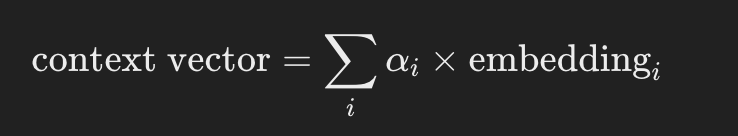
Calculating each component:
-
Weighted Embedding of "Hello":

-
Weighted Embedding of "shiny":

-
Weighted Embedding of "sun":

Summing the weighted embeddings:
context vector=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
This context vector represents the enriched embedding for the word "shiny," incorporating information from all words in the sentence.
Summary of the Process
- Compute Attention Scores: Use the dot product between the embedding of the target word and the embeddings of all words in the sequence.
- Normalize Scores to Get Attention Weights: Apply the softmax function to the attention scores to obtain weights that sum to 1.
- Compute Context Vector: Multiply each word's embedding by its attention weight and sum the results.
Self-Attention with Trainable Weights
In practice, self-attention mechanisms use trainable weights to learn the best representations for queries, keys, and values. This involves introducing three weight matrices:

The query is the data to use like before, while the keys and values matrices are just random-trainable matrices.
Step 1: Compute Queries, Keys, and Values
Each token will have its own query, key and value matrix by multiplying its dimension values by the defined matrices:

These matrices transform the original embeddings into a new space suitable for computing attention.
Example
Assuming:
- Input dimension
din=3(embedding size) - Output dimension
dout=2(desired dimension for queries, keys, and values)
Initialize the weight matrices:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
Compute queries, keys, and values:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Step 2: Compute Scaled Dot-Product Attention
Compute Attention Scores
Similar to the example from before, but this time, instead of using the values of the dimensions of the tokens, we use the key matrix of the token (calculated already using the dimensions):. So, for each query qi and key kj:
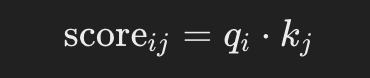
Scale the Scores
To prevent the dot products from becoming too large, scale them by the square root of the key dimension dk:

{% hint style="success" %} The score is divided by the square root of the dimensions because dot products might become very large and this helps to regulate them. {% endhint %}
Apply Softmax to Obtain Attention Weights: Like in the initial example, normalize all the values so they sum 1.

Step 3: Compute Context Vectors
Like in the initial example, just sum all the values matrices multiplying each one by its attention weight:

Code Example
Grabbing an example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb you can check this class that implements the self-attendant functionality we talked about:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
Note that instead of initializing the matrices with random values, nn.Linear is used to mark all the wights as parameters to train.
{% endhint %}
Causal Attention: Hiding Future Words
For LLMs we want the model to consider only the tokens that appear before the current position in order to predict the next token. Causal attention, also known as masked attention, achieves this by modifying the attention mechanism to prevent access to future tokens.
Applying a Causal Attention Mask
To implement causal attention, we apply a mask to the attention scores before the softmax operation so the reminding ones will still sum 1. This mask sets the attention scores of future tokens to negative infinity, ensuring that after the softmax, their attention weights are zero.
Steps
-
Compute Attention Scores: Same as before.
-
Apply Mask: Use an upper triangular matrix filled with negative infinity above the diagonal.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf') masked_scores = attention_scores + mask -
Apply Softmax: Compute attention weights using the masked scores.
attention_weights = torch.softmax(masked_scores, dim=-1)
Masking Additional Attention Weights with Dropout
To prevent overfitting, we can apply dropout to the attention weights after the softmax operation. Dropout randomly zeroes some of the attention weights during training.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
A regular dropout is about 10-20%.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Extending Single-Head Attention to Multi-Head Attention
Multi-head attention in practical terms consist on executing multiple instances of the self-attention function each of them with their own weights so different final vectors are calculated.
Code Example
It could be possible to reuse the previous code and just add a wrapper that launches it several time, but this is a more optimised version from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb that processes all the heads at the same time (reducing the number of expensive for loops). As you can see in the code, the dimensions of each token is divided in different dimensions according to the number of heads. This way if token have 8 dimensions and we want to use 3 heads, the dimensions will be divided in 2 arrays of 4 dimensions and each head will use one of them:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
For another compact and efficient implementation you could use the torch.nn.MultiheadAttention class in PyTorch.
{% hint style="success" %} Short answer of ChatGPT about why it's better to divide dimensions of tokens among the heads instead of having each head check all the dimensions of all the tokens:
While allowing each head to process all embedding dimensions might seem advantageous because each head would have access to the full information, the standard practice is to divide the embedding dimensions among the heads. This approach balances computational efficiency with model performance and encourages each head to learn diverse representations. Therefore, splitting the embedding dimensions is generally preferred over having each head check all dimensions. {% endhint %}
LLM Architecture
LLM architecture example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
A high level representation can be observed in:
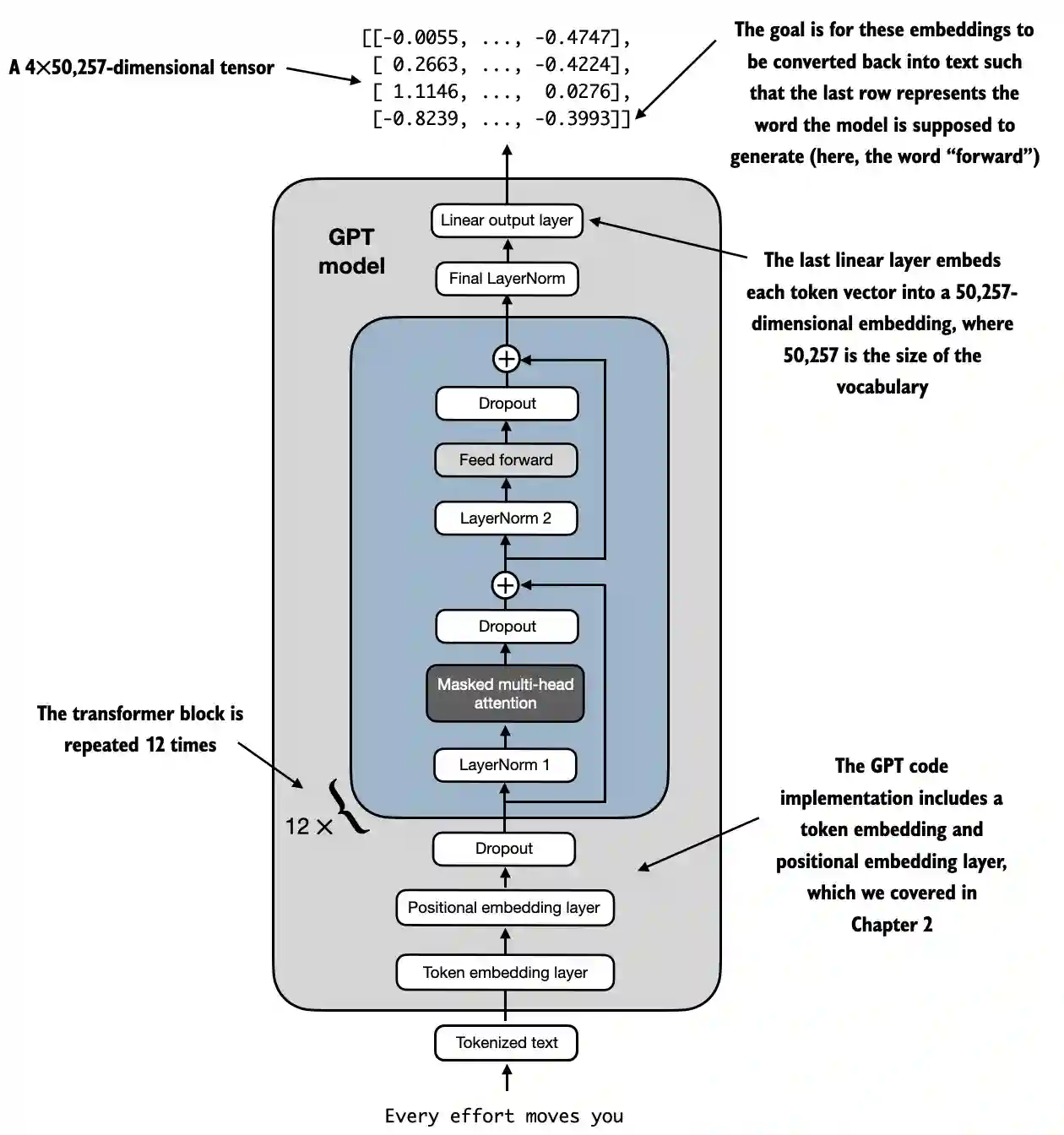
- Input (Tokenized Text): The process begins with tokenized text, which is converted into numerical representations.
- Token Embedding and Positional Embedding Layer: The tokenized text is passed through a token embedding layer and a positional embedding layer, which captures the position of tokens in a sequence, critical for understanding word order.
- Transformer Blocks: The model contains 12 transformer blocks, each with multiple layers. These blocks repeat the following sequence:
- Masked Multi-Head Attention: Allows the model to focus on different parts of the input text at once.
- Layer Normalization: A normalization step to stabilize and improve training.
- Feed Forward Layer: Responsible for processing the information from the attention layer and making predictions about the next token.
- Dropout Layers: These layers prevent overfitting by randomly dropping units during training.
- Final Output Layer: The model outputs a 4x50,257-dimensional tensor, where 50,257 represents the size of the vocabulary. Each row in this tensor corresponds to a vector that the model uses to predict the next word in the sequence.
- Goal: The objective is to take these embeddings and convert them back into text. Specifically, the last row of the output is used to generate the next word, represented as "forward" in this diagram.
Code representation
import torch
import torch.nn as nn
import tiktoken
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
# Shortcut connection for feed forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
Let's explain it step by step:
GELU Activation Function
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
Purpose and Functionality
- GELU (Gaussian Error Linear Unit): An activation function that introduces non-linearity into the model.
- Smooth Activation: Unlike ReLU, which zeroes out negative inputs, GELU smoothly maps inputs to outputs, allowing for small, non-zero values for negative inputs.
- Mathematical Definition:

{% hint style="info" %} The goal of the use of this function after linear layers inside the FeedForward layer is to change the linear data to be none linear to allow the model to learn complex, non-linear relationships. {% endhint %}
FeedForward Neural Network
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
x = self.layers[0](x)# x shape: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[1](x) # x shape remains: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[2](x) # x shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Purpose and Functionality
- Position-wise FeedForward Network: Applies a two-layer fully connected network to each position separately and identically.
- Layer Details:
- First Linear Layer: Expands the dimensionality from
emb_dimto4 * emb_dim. - GELU Activation: Applies non-linearity.
- Second Linear Layer: Reduces the dimensionality back to
emb_dim.
- First Linear Layer: Expands the dimensionality from
{% hint style="info" %} As you can see, the Feed Forward network uses 3 layers. The first one is a linear layer that will multiply the dimensions by 4 using linear weights (parameters to train inside the model). Then, the GELU function is used in all those dimensions to apply none-linear variations to capture richer representations and finally another linear layer is used to get back to the original size of dimensions. {% endhint %}
Multi-Head Attention Mechanism
This was already explained in an earlier section.
Purpose and Functionality
- Multi-Head Self-Attention: Allows the model to focus on different positions within the input sequence when encoding a token.
- Key Components:
- Queries, Keys, Values: Linear projections of the input, used to compute attention scores.
- Heads: Multiple attention mechanisms running in parallel (
num_heads), each with a reduced dimension (head_dim). - Attention Scores: Computed as the dot product of queries and keys, scaled and masked.
- Masking: A causal mask is applied to prevent the model from attending to future tokens (important for autoregressive models like GPT).
- Attention Weights: Softmax of the masked and scaled attention scores.
- Context Vector: Weighted sum of the values, according to attention weights.
- Output Projection: Linear layer to combine the outputs of all heads.
{% hint style="info" %} The goal of this network is to find the relations between tokens in the same context. Moreover, the tokens are divided in different heads in order to prevent overfitting although the final relations found per head are combined at the end of this network.
Moreover, during training a causal mask is applied so later tokens are not taken into account when looking the specific relations to a token and some dropout is also applied to prevent overfitting. {% endhint %}
Layer Normalization
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # Prevent division by zero during normalization.
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
Purpose and Functionality
- Layer Normalization: A technique used to normalize the inputs across the features (embedding dimensions) for each individual example in a batch.
- Components:
eps: A small constant (1e-5) added to the variance to prevent division by zero during normalization.scaleandshift: Learnable parameters (nn.Parameter) that allow the model to scale and shift the normalized output. They are initialized to ones and zeros, respectively.
- Normalization Process:
- Compute Mean (
mean): Calculates the mean of the inputxacross the embedding dimension (dim=-1), keeping the dimension for broadcasting (keepdim=True). - Compute Variance (
var): Calculates the variance ofxacross the embedding dimension, also keeping the dimension. Theunbiased=Falseparameter ensures that the variance is calculated using the biased estimator (dividing byNinstead ofN-1), which is appropriate when normalizing over features rather than samples. - Normalize (
norm_x): Subtracts the mean fromxand divides by the square root of the variance pluseps. - Scale and Shift: Applies the learnable
scaleandshiftparameters to the normalized output.
- Compute Mean (
{% hint style="info" %} The goal is to ensure a mean of 0 with a variance of 1 across all dimensions of the same token . The goal of this is to stabilize the training of deep neural networks by reducing the internal covariate shift, which refers to the change in the distribution of network activations due to the updating of parameters during training. {% endhint %}
Transformer Block
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for attention block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm1(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.att(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for feedforward block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm2(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.ff(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Purpose and Functionality
- Composition of Layers: Combines multi-head attention, feedforward network, layer normalization, and residual connections.
- Layer Normalization: Applied before the attention and feedforward layers for stable training.
- Residual Connections (Shortcuts): Add the input of a layer to its output to improve gradient flow and enable training of deep networks.
- Dropout: Applied after attention and feedforward layers for regularization.
Step-by-Step Functionality
- First Residual Path (Self-Attention):
- Input (
shortcut): Save the original input for the residual connection. - Layer Norm (
norm1): Normalize the input. - Multi-Head Attention (
att): Apply self-attention. - Dropout (
drop_shortcut): Apply dropout for regularization. - Add Residual (
x + shortcut): Combine with the original input.
- Input (
- Second Residual Path (FeedForward):
- Input (
shortcut): Save the updated input for the next residual connection. - Layer Norm (
norm2): Normalize the input. - FeedForward Network (
ff): Apply the feedforward transformation. - Dropout (
drop_shortcut): Apply dropout. - Add Residual (
x + shortcut): Combine with the input from the first residual path.
- Input (
{% hint style="info" %}
The transformer block groups all the networks together and applies some normalization and dropouts to improve the training stability and results.
Note how dropouts are done after the use of each network while normalization is applied before.
Moreover, it also uses shortcuts which consists on adding the output of a network with its input. This helps to prevent the vanishing gradient problem by making sure that initial layers contribute "as much" as the last ones. {% endhint %}
GPTModel
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# shape: (vocab_size, emb_dim)
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# shape: (context_length, emb_dim)
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# Stack of TransformerBlocks
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
# shape: (emb_dim, vocab_size)
def forward(self, in_idx):
# in_idx shape: (batch_size, seq_len)
batch_size, seq_len = in_idx.shape
# Token embeddings
tok_embeds = self.tok_emb(in_idx)
# shape: (batch_size, seq_len, emb_dim)
# Positional embeddings
pos_indices = torch.arange(seq_len, device=in_idx.device)
# shape: (seq_len,)
pos_embeds = self.pos_emb(pos_indices)
# shape: (seq_len, emb_dim)
# Add token and positional embeddings
x = tok_embeds + pos_embeds # Broadcasting over batch dimension
# x shape: (batch_size, seq_len, emb_dim)
x = self.drop_emb(x) # Dropout applied
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.trf_blocks(x) # Pass through Transformer blocks
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.final_norm(x) # Final LayerNorm
# x shape remains: (batch_size, seq_len, emb_dim)
logits = self.out_head(x) # Project to vocabulary size
# logits shape: (batch_size, seq_len, vocab_size)
return logits # Output shape: (batch_size, seq_len, vocab_size)
Purpose and Functionality
- Embedding Layers:
- Token Embeddings (
tok_emb): Converts token indices into embeddings. As reminder, these are the weights given to each dimension of each token in the vocabulary. - Positional Embeddings (
pos_emb): Adds positional information to the embeddings to capture the order of tokens. As reminder, these are the weights given to token according to it's position in the text.
- Token Embeddings (
- Dropout (
drop_emb): Applied to embeddings for regularisation. - Transformer Blocks (
trf_blocks): Stack ofn_layerstransformer blocks to process embeddings. - Final Normalization (
final_norm): Layer normalization before the output layer. - Output Layer (
out_head): Projects the final hidden states to the vocabulary size to produce logits for prediction.
{% hint style="info" %} The goal of this class is to use all the other mentioned networks to predict the next token in a sequence, which is fundamental for tasks like text generation.
Note how it will use as many transformer blocks as indicated and that each transformer block is using one multi-head attestation net, one feed forward net and several normalizations. So if 12 transformer blocks are used, multiply this by 12.
Moreover, a normalization layer is added before the output and a final linear layer is applied a the end to get the results with the proper dimensions. Note how each final vector has the size of the used vocabulary. This is because it's trying to get a probability per possible token inside the vocabulary. {% endhint %}
Number of Parameters to train
Having the GPT structure defined it's possible to find out the number of parameters to train:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
model = GPTModel(GPT_CONFIG_124M)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# Total number of parameters: 163,009,536
Step-by-Step Calculation
1. Embedding Layers: Token Embedding & Position Embedding
- Layer:
nn.Embedding(vocab_size, emb_dim) - Parameters:
vocab_size * emb_dim
token_embedding_params = 50257 * 768 = 38,597,376
- Layer:
nn.Embedding(context_length, emb_dim) - Parameters:
context_length * emb_dim
position_embedding_params = 1024 * 768 = 786,432
Total Embedding Parameters
embedding_params = token_embedding_params + position_embedding_params
embedding_params = 38,597,376 + 786,432 = 39,383,808
2. Transformer Blocks
There are 12 transformer blocks, so we'll calculate the parameters for one block and then multiply by 12.
Parameters per Transformer Block
a. Multi-Head Attention
- Components:
- Query Linear Layer (
W_query):nn.Linear(emb_dim, emb_dim, bias=False) - Key Linear Layer (
W_key):nn.Linear(emb_dim, emb_dim, bias=False) - Value Linear Layer (
W_value):nn.Linear(emb_dim, emb_dim, bias=False) - Output Projection (
out_proj):nn.Linear(emb_dim, emb_dim)
- Query Linear Layer (
- Calculations:
-
Each of
W_query,W_key,W_value:qkv_params = emb_dim * emb_dim = 768 * 768 = 589,824Since there are three such layers:
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472 -
Output Projection (
out_proj):out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592 -
Total Multi-Head Attention Parameters:
mha_params = total_qkv_params + out_proj_params mha_params = 1,769,472 + 590,592 = 2,360,064
-
b. FeedForward Network
- Components:
- First Linear Layer:
nn.Linear(emb_dim, 4 * emb_dim) - Second Linear Layer:
nn.Linear(4 * emb_dim, emb_dim)
- First Linear Layer:
- Calculations:
-
First Linear Layer:
ff_first_layer_params = (emb_dim * 4 * emb_dim) + (4 * emb_dim) ff_first_layer_params = (768 * 3072) + 3072 = 2,359,296 + 3,072 = 2,362,368 -
Second Linear Layer:
ff_second_layer_params = (4 * emb_dim * emb_dim) + emb_dim ff_second_layer_params = (3072 * 768) + 768 = 2,359,296 + 768 = 2,360,064 -
Total FeedForward Parameters:
ff_params = ff_first_layer_params + ff_second_layer_params ff_params = 2,362,368 + 2,360,064 = 4,722,432
-
c. Layer Normalizations
-
Components:
- Two
LayerNorminstances per block. - Each
LayerNormhas2 * emb_dimparameters (scale and shift).
- Two
-
Calculations:
pythonCopy codelayer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
d. Total Parameters per Transformer Block
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
Total Parameters for All Transformer Blocks
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
3. Final Layers
a. Final Layer Normalization
- Parameters:
2 * emb_dim(scale and shift)
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
b. Output Projection Layer (out_head)
- Layer:
nn.Linear(emb_dim, vocab_size, bias=False) - Parameters:
emb_dim * vocab_size
pythonCopy codeoutput_projection_params = 768 * 50257 = 38,597,376
4. Summing Up All Parameters
pythonCopy codetotal_params = (
embedding_params +
total_transformer_blocks_params +
final_layer_norm_params +
output_projection_params
)
total_params = (
39,383,808 +
85,026,816 +
1,536 +
38,597,376
)
total_params = 163,009,536
Generate Text
Having a model that predicts the next token like the one before, it's just needed to take the last token values from the output (as they will be the ones of the predicted token), which will be a value per entry in the vocabulary and then use the softmax function to normalize the dimensions into probabilities that sums 1 and then get the index of the of the biggest entry, which will be the index of the word inside the vocabulary.
Code from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))