mirror of
https://github.com/bevyengine/bevy
synced 2025-01-04 17:28:56 +00:00
# Objective `extract_meshes` can easily be one of the most expensive operations in the blocking extract schedule for 3D apps. It also has no fundamentally serialized parts and can easily be run across multiple threads. Let's speed it up by parallelizing it! ## Solution Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in conjunction with `Query::par_iter` to build a set of thread-local queues, and collect them after going wide. ## Performance Using `cargo run --profile stress-test --features trace_tracy --example many_cubes`. Yellow is this PR. Red is main. `extract_meshes`: 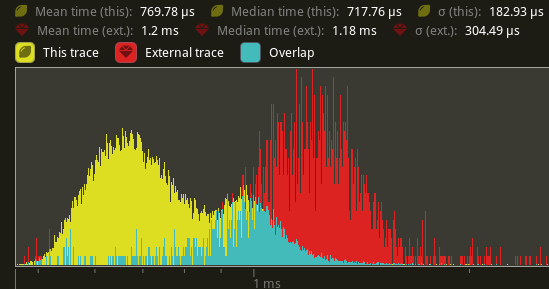 An average reduction from 1.2ms to 770us is seen, a 41.6% improvement. Note: this is still not including #9950's changes, so this may actually result in even faster speedups once that's merged in. |
||
|---|---|---|
| .. | ||
| src | ||
| Cargo.toml | ||