mirror of
https://github.com/bevyengine/bevy
synced 2025-02-18 06:58:34 +00:00
# Objective - Supercedes #8872 - Improve sprite rendering performance after the regression in #9236 ## Solution - Use an instance-rate vertex buffer to store per-instance data. - Store color, UV offset and scale, and a transform per instance. - Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine 3x4 matrix and store the transpose of that in the per-instance data. This is similar to how MeshUniform uses transpose affine matrices. - Use a special index buffer that has batches of 6 indices referencing 4 vertices. The lower 2 bits indicate the x and y of a quad such that the corners are: ``` 10 11 00 01 ``` UVs are implicit but get modified by UV offset and scale The remaining upper bits contain the instance index. ## Benchmarks I will compare versus `main` before #9236 because the results should be as good as or faster than that. Running `bevymark -- 10000 16` on an M1 Max with `main` at `e8b38925` in yellow, this PR in red: 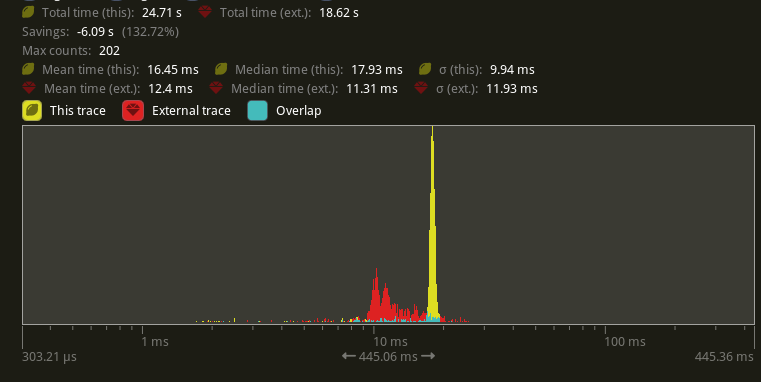 Looking at the median frame times, that's a 37% reduction from before. --- ## Changelog - Changed: Improved sprite rendering performance by leveraging an instance-rate vertex buffer. --------- Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
21 lines
440 B
WebGPU Shading Language
21 lines
440 B
WebGPU Shading Language
#define_import_path bevy_render::maths
|
|
|
|
fn affine_to_square(affine: mat3x4<f32>) -> mat4x4<f32> {
|
|
return transpose(mat4x4<f32>(
|
|
affine[0],
|
|
affine[1],
|
|
affine[2],
|
|
vec4<f32>(0.0, 0.0, 0.0, 1.0),
|
|
));
|
|
}
|
|
|
|
fn mat2x4_f32_to_mat3x3_unpack(
|
|
a: mat2x4<f32>,
|
|
b: f32,
|
|
) -> mat3x3<f32> {
|
|
return mat3x3<f32>(
|
|
a[0].xyz,
|
|
vec3<f32>(a[0].w, a[1].xy),
|
|
vec3<f32>(a[1].zw, b),
|
|
);
|
|
}
|