mirror of
https://github.com/bevyengine/bevy
synced 2025-01-03 16:58:56 +00:00
This implements the following: * **Sprite Batching**: Collects sprites in a vertex buffer to draw many sprites with a single draw call. Sprites are batched by their `Handle<Image>` within a specific z-level. When possible, sprites are opportunistically batched _across_ z-levels (when no sprites with a different texture exist between two sprites with the same texture on different z levels). With these changes, I can now get ~130,000 sprites at 60fps on the `bevymark_pipelined` example. * **Sprite Color Tints**: The `Sprite` type now has a `color` field. Non-white color tints result in a specialized render pipeline that passes the color in as a vertex attribute. I chose to specialize this because passing vertex colors has a measurable price (without colors I get ~130,000 sprites on bevymark, with colors I get ~100,000 sprites). "Colored" sprites cannot be batched with "uncolored" sprites, but I think this is fine because the chance of a "colored" sprite needing to batch with other "colored" sprites is generally probably way higher than an "uncolored" sprite needing to batch with a "colored" sprite. * **Sprite Flipping**: Sprites can be flipped on their x or y axis using `Sprite::flip_x` and `Sprite::flip_y`. This is also true for `TextureAtlasSprite`. * **Simpler BufferVec/UniformVec/DynamicUniformVec Clearing**: improved the clearing interface by removing the need to know the size of the final buffer at the initial clear. 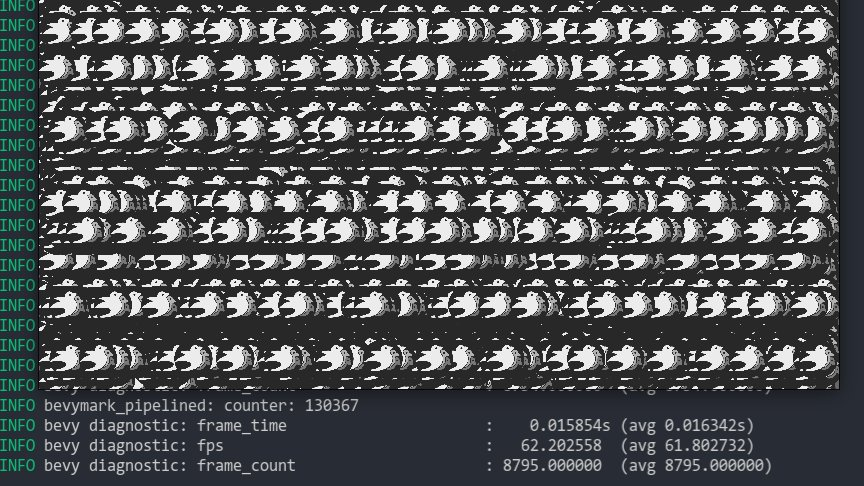 Note that this moves sprites away from entity-driven rendering and back to extracted lists. We _could_ use entities here, but it necessitates that an intermediate list is allocated / populated to collect and sort extracted sprites. This redundant copy, combined with the normal overhead of spawning extracted sprite entities, brings bevymark down to ~80,000 sprites at 60fps. I think making sprites a bit more fixed (by default) is worth it. I view this as acceptable because batching makes normal entity-driven rendering pretty useless anyway (and we would want to batch most custom materials too). We can still support custom shaders with custom bindings, we'll just need to define a specific interface for it.
{kind=link}
90 lines
2.2 KiB
Rust
90 lines
2.2 KiB
Rust
use crate::{
|
|
render_resource::Buffer,
|
|
renderer::{RenderDevice, RenderQueue},
|
|
};
|
|
use bevy_core::{cast_slice, Pod};
|
|
use wgpu::BufferUsages;
|
|
|
|
pub struct BufferVec<T: Pod> {
|
|
values: Vec<T>,
|
|
buffer: Option<Buffer>,
|
|
capacity: usize,
|
|
item_size: usize,
|
|
buffer_usage: BufferUsages,
|
|
}
|
|
|
|
impl<T: Pod> Default for BufferVec<T> {
|
|
fn default() -> Self {
|
|
Self {
|
|
values: Vec::new(),
|
|
buffer: None,
|
|
capacity: 0,
|
|
buffer_usage: BufferUsages::all(),
|
|
item_size: std::mem::size_of::<T>(),
|
|
}
|
|
}
|
|
}
|
|
|
|
impl<T: Pod> BufferVec<T> {
|
|
pub fn new(buffer_usage: BufferUsages) -> Self {
|
|
Self {
|
|
buffer_usage,
|
|
..Default::default()
|
|
}
|
|
}
|
|
|
|
#[inline]
|
|
pub fn buffer(&self) -> Option<&Buffer> {
|
|
self.buffer.as_ref()
|
|
}
|
|
|
|
#[inline]
|
|
pub fn capacity(&self) -> usize {
|
|
self.capacity
|
|
}
|
|
|
|
#[inline]
|
|
pub fn len(&self) -> usize {
|
|
self.values.len()
|
|
}
|
|
|
|
#[inline]
|
|
pub fn is_empty(&self) -> bool {
|
|
self.values.is_empty()
|
|
}
|
|
|
|
pub fn push(&mut self, value: T) -> usize {
|
|
let index = self.values.len();
|
|
self.values.push(value);
|
|
index
|
|
}
|
|
|
|
pub fn reserve(&mut self, capacity: usize, device: &RenderDevice) {
|
|
if capacity > self.capacity {
|
|
self.capacity = capacity;
|
|
let size = self.item_size * capacity;
|
|
self.buffer = Some(device.create_buffer(&wgpu::BufferDescriptor {
|
|
label: None,
|
|
size: size as wgpu::BufferAddress,
|
|
usage: BufferUsages::COPY_DST | self.buffer_usage,
|
|
mapped_at_creation: false,
|
|
}));
|
|
}
|
|
}
|
|
|
|
pub fn write_buffer(&mut self, device: &RenderDevice, queue: &RenderQueue) {
|
|
if self.values.is_empty() {
|
|
return;
|
|
}
|
|
self.reserve(self.values.len(), device);
|
|
if let Some(buffer) = &self.buffer {
|
|
let range = 0..self.item_size * self.values.len();
|
|
let bytes: &[u8] = cast_slice(&self.values);
|
|
queue.write_buffer(buffer, 0, &bytes[range]);
|
|
}
|
|
}
|
|
|
|
pub fn clear(&mut self) {
|
|
self.values.clear();
|
|
}
|
|
}
|