# Objective
First of all, this PR took heavy inspiration from #7760 and #5715. It
intends to also fix#5569, but with a slightly different approach.
This also fixes#9335 by reexporting `DynEq`.
## Solution
The advantage of this API is that we can intern a value without
allocating for zero-sized-types and for enum variants that have no
fields. This PR does this automatically in the `SystemSet` and
`ScheduleLabel` derive macros for unit structs and fieldless enum
variants. So this should cover many internal and external use cases of
`SystemSet` and `ScheduleLabel`. In these optimal use cases, no memory
will be allocated.
- The interning returns a `Interned<dyn SystemSet>`, which is just a
wrapper around a `&'static dyn SystemSet`.
- `Hash` and `Eq` are implemented in terms of the pointer value of the
reference, similar to my first approach of anonymous system sets in
#7676.
- Therefore, `Interned<T>` does not implement `Borrow<T>`, only `Deref`.
- The debug output of `Interned<T>` is the same as the interned value.
Edit:
- `AppLabel` is now also interned and the old
`derive_label`/`define_label` macros were replaced with the new
interning implementation.
- Anonymous set ids are reused for different `Schedule`s, reducing the
amount of leaked memory.
### Pros
- `InternedSystemSet` and `InternedScheduleLabel` behave very similar to
the current `BoxedSystemSet` and `BoxedScheduleLabel`, but can be copied
without an allocation.
- Many use cases don't allocate at all.
- Very fast lookups and comparisons when using `InternedSystemSet` and
`InternedScheduleLabel`.
- The `intern` module might be usable in other areas.
- `Interned{ScheduleLabel, SystemSet, AppLabel}` does implement
`{ScheduleLabel, SystemSet, AppLabel}`, increasing ergonomics.
### Cons
- Implementors of `SystemSet` and `ScheduleLabel` still need to
implement `Hash` and `Eq` (and `Clone`) for it to work.
## Changelog
### Added
- Added `intern` module to `bevy_utils`.
- Added reexports of `DynEq` to `bevy_ecs` and `bevy_app`.
### Changed
- Replaced `BoxedSystemSet` and `BoxedScheduleLabel` with
`InternedSystemSet` and `InternedScheduleLabel`.
- Replaced `impl AsRef<dyn ScheduleLabel>` with `impl ScheduleLabel`.
- Replaced `AppLabelId` with `InternedAppLabel`.
- Changed `AppLabel` to use `Debug` for error messages.
- Changed `AppLabel` to use interning.
- Changed `define_label`/`derive_label` to use interning.
- Replaced `define_boxed_label`/`derive_boxed_label` with
`define_label`/`derive_label`.
- Changed anonymous set ids to be only unique inside a schedule, not
globally.
- Made interned label types implement their label trait.
### Removed
- Removed `define_boxed_label` and `derive_boxed_label`.
## Migration guide
- Replace `BoxedScheduleLabel` and `Box<dyn ScheduleLabel>` with
`InternedScheduleLabel` or `Interned<dyn ScheduleLabel>`.
- Replace `BoxedSystemSet` and `Box<dyn SystemSet>` with
`InternedSystemSet` or `Interned<dyn SystemSet>`.
- Replace `AppLabelId` with `InternedAppLabel` or `Interned<dyn
AppLabel>`.
- Types manually implementing `ScheduleLabel`, `AppLabel` or `SystemSet`
need to implement:
- `dyn_hash` directly instead of implementing `DynHash`
- `as_dyn_eq`
- Pass labels to `World::try_schedule_scope`, `World::schedule_scope`,
`World::try_run_schedule`. `World::run_schedule`, `Schedules::remove`,
`Schedules::remove_entry`, `Schedules::contains`, `Schedules::get` and
`Schedules::get_mut` by value instead of by reference.
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce code duplication and improve APIs of Bevy's [global
taskpools](https://github.com/bevyengine/bevy/blob/main/crates/bevy_tasks/src/usages.rs).
## Solution
- As all three of the global taskpools have identical implementations
and only differ in their identifiers, this PR moves the implementation
into a macro to reduce code duplication.
- The `init` method is renamed to `get_or_init` to more accurately
reflect what it really does.
- Add a new `try_get` method that just returns `None` when the pool is
uninitialized, to complement the other getter methods.
- Minor documentation improvements to accompany the above changes.
---
## Changelog
- Added a new `try_get` method to the global TaskPools
- The global TaskPools' `init` method has been renamed to `get_or_init`
for clarity
- Documentation improvements
## Migration Guide
- Uses of `ComputeTaskPool::init`, `AsyncComputeTaskPool::init` and
`IoTaskPool::init` should be changed to `::get_or_init`.
# Objective
Closes#9955.
Use the same interface for all "pure" builder types: taking and
returning `Self` (and not `&mut Self`).
## Solution
Changed `DynamicSceneBuilder`, `SceneFilter` and `TableBuilder` to take
and return `Self`.
## Changelog
### Changed
- `DynamicSceneBuilder` and `SceneBuilder` methods in `bevy_ecs` now
take and return `Self`.
## Migration guide
When using `bevy_ecs::DynamicSceneBuilder` and `bevy_ecs::SceneBuilder`,
instead of binding the builder to a variable, directly use it. Methods
on those types now consume `Self`, so you will need to re-bind the
builder if you don't `build` it immediately.
Before:
```rust
let mut scene_builder = DynamicSceneBuilder::from_world(&world);
let scene = scene_builder.extract_entity(a).extract_entity(b).build();
```
After:
```rust
let scene = DynamicSceneBuilder::from_world(&world)
.extract_entity(a)
.extract_entity(b)
.build();
```
# Objective
- Followup to #7184.
- ~Deprecate `TypeUuid` and remove its internal references.~ No longer
part of this PR.
- Use `TypePath` for the type registry, and (de)serialisation instead of
`std::any::type_name`.
- Allow accessing type path information behind proxies.
## Solution
- Introduce methods on `TypeInfo` and friends for dynamically querying
type path. These methods supersede the old `type_name` methods.
- Remove `Reflect::type_name` in favor of `DynamicTypePath::type_path`
and `TypeInfo::type_path_table`.
- Switch all uses of `std::any::type_name` in reflection, non-debugging
contexts to use `TypePath`.
---
## Changelog
- Added `TypePathTable` for dynamically accessing methods on `TypePath`
through `TypeInfo` and the type registry.
- Removed `type_name` from all `TypeInfo`-like structs.
- Added `type_path` and `type_path_table` methods to all `TypeInfo`-like
structs.
- Removed `Reflect::type_name` in favor of
`DynamicTypePath::reflect_type_path` and `TypeInfo::type_path`.
- Changed the signature of all `DynamicTypePath` methods to return
strings with a static lifetime.
## Migration Guide
- Rely on `TypePath` instead of `std::any::type_name` for all stability
guarantees and for use in all reflection contexts, this is used through
with one of the following APIs:
- `TypePath::type_path` if you have a concrete type and not a value.
- `DynamicTypePath::reflect_type_path` if you have an `dyn Reflect`
value without a concrete type.
- `TypeInfo::type_path` for use through the registry or if you want to
work with the represented type of a `DynamicFoo`.
- Remove `type_name` from manual `Reflect` implementations.
- Use `type_path` and `type_path_table` in place of `type_name` on
`TypeInfo`-like structs.
- Use `get_with_type_path(_mut)` over `get_with_type_name(_mut)`.
## Note to reviewers
I think if anything we were a little overzealous in merging #7184 and we
should take that extra care here.
In my mind, this is the "point of no return" for `TypePath` and while I
think we all agree on the design, we should carefully consider if the
finer details and current implementations are actually how we want them
moving forward.
For example [this incorrect `TypePath` implementation for
`String`](3fea3c6c0b/crates/bevy_reflect/src/impls/std.rs (L90))
(note that `String` is in the default Rust prelude) snuck in completely
under the radar.
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
- Fixes#9884
- Add API for ignoring ambiguities on certain resource or components.
## Solution
- Add a `IgnoreSchedulingAmbiguitiy` resource to the world which holds
the `ComponentIds` to be ignored
- Filter out ambiguities with those component id's.
## Changelog
- add `allow_ambiguous_component` and `allow_ambiguous_resource` apis
for ignoring ambiguities
---------
Co-authored-by: Ryan Johnson <ryanj00a@gmail.com>
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
Add a new method so you can do `set_if_neq` with dereferencing
components: `as_deref_mut()`!
## Solution
Added an as_deref_mut method so that we can use `set_if_neq()` without
having to wrap up types for derefencable components
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
The `States::variants` method was once used to construct `OnExit` and
`OnEnter` schedules for every possible value of a given `States` type.
[Since the switch to lazily initialized
schedules](https://github.com/bevyengine/bevy/pull/8028/files#diff-b2fba3a0c86e496085ce7f0e3f1de5960cb754c7d215ed0f087aa556e529f97f),
we no longer need to track every possible value.
This also opens the door to `States` types that aren't enums.
## Solution
- Remove the unused `States::variants` method and its associated type.
- Remove the enum-only restriction on derived States types.
---
## Changelog
- Removed `States::variants` and its associated type.
- Derived `States` can now be datatypes other than enums.
## Migration Guide
- `States::variants` no longer exists. If you relied on this function,
consider using a library that provides enum iterators.
# Objective
- There were a few typos in the project.
- This PR fixes these typos.
## Solution
- Fixing the typos.
Signed-off-by: SADIK KUZU <sadikkuzu@hotmail.com>
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Scheduling low cost systems has significant overhead due to task pool
contention and the extra machinery to schedule and run them. Event
update systems are the prime example of a low cost system, requiring a
guaranteed O(1) operation, and there are a *lot* of them.
## Solution
Add a run condition to every event system so they only run when there is
an event in either of it's two internal Vecs.
---
## Changelog
Changed: Event update systems will not run if there are no events to
process.
## Migration Guide
`Events<T>::update_system` has been split off from the the type and can
be found at `bevy_ecs::event::event_update_system`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
Improve code-gen for `QueryState::validate_world` and
`SystemState::validate_world`.
## Solution
* Move panics into separate, non-inlined functions, to reduce the code
size of the outer methods.
* Mark the panicking functions with `#[cold]` to help the compiler
optimize for the happy path.
* Mark the functions with `#[track_caller]` to make debugging easier.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Occasionally, it is useful to pull `ComponentInfo` or
`ComponentDescriptor` out of the `Components` collection so that they
can be inspected without borrowing the whole `World`.
## Solution
Make `ComponentInfo` and `ComponentDescriptor` `Clone`, so that
reflection-heavy code can store them in a side table.
---
## Changelog
- Implement `Clone` for `ComponentInfo` and `ComponentDescriptor`
# Objective
- I spoke with some users in the ECS channel of bevy discord today and
they suggested that I implement a fallible form of .insert for
components.
- In my opinion, it would be nice to have a fallible .insert like
.try_insert (or to just make insert be fallible!) because it was causing
a lot of panics in my game. In my game, I am spawning terrain chunks and
despawning them in the Update loop. However, this was causing bevy_xpbd
to panic because it was trying to .insert some physics components on my
chunks and a race condition meant that its check to see if the entity
exists would pass but then the next execution step it would not exist
and would do an .insert and then panic. This means that there is no way
to avoid a panic with conditionals.
Luckily, bevy_xpbd does not care about inserting these components if the
entity is being deleted and so if there were a .try_insert, like this PR
provides it could use that instead in order to NOT panic.
( My interim solution for my own game has been to run the entity despawn
events in the Last schedule but really this is just a hack and I should
not be expected to manage the scheduling of despawns like this - it
should just be easy and simple. IF it just so happened that bevy_xpbd
ran .inserts in the Last schedule also, this would be an untenable soln
overall )
## Solution
- Describe the solution used to achieve the objective above.
Add a new command named TryInsert (entitycommands.try_insert) which
functions exactly like .insert except if the entity does not exist it
will not panic. Instead, it will log to info. This way, crates that are
attaching components in ways which they do not mind that the entity no
longer exists can just use try_insert instead of insert.
---
## Changelog
## Additional Thoughts
In my opinion, NOT panicing should really be the default and having an
.insert that does panic should be the odd edgecase but removing the
panic! from .insert seems a bit above my paygrade -- although i would
love to see it. My other thought is it would be good for .insert to
return an Option AND not panic but it seems it uses an event bus right
now so that seems to be impossible w the current architecture.
# Objective
Currently, in bevy, it's valid to do `Query<&mut Foo, Changed<Foo>>`.
This assumes that `filter_fetch` and `fetch` are mutually exclusive,
because of the mutable reference to the tick that `Mut<Foo>` implies and
the reference that `Changed<Foo>` implies. However nothing guarantees
that.
## Solution
Documenting this assumption as a safety invariant is the least thing.
I'm adopting this ~~child~~ PR.
# Objective
- Working with exclusive world access is not always easy: in many cases,
a standard system or three is more ergonomic to write, and more
modularly maintainable.
- For small, one-off tasks (commonly handled with scripting), running an
event-reader system incurs a small but flat overhead cost and muddies
the schedule.
- Certain forms of logic (e.g. turn-based games) want very fine-grained
linear and/or branching control over logic.
- SystemState is not automatically cached, and so performance can suffer
and change detection breaks.
- Fixes https://github.com/bevyengine/bevy/issues/2192.
- Partial workaround for https://github.com/bevyengine/bevy/issues/279.
## Solution
- Adds a SystemRegistry resource to the World, which stores initialized
systems keyed by their SystemSet.
- Allows users to call world.run_system(my_system) and
commands.run_system(my_system), without re-initializing or losing state
(essential for change detection).
- Add a Callback type to enable convenient use of dynamic one shot
systems and reduce the mental overhead of working with Box<dyn
SystemSet>.
- Allow users to run systems based on their SystemSet, enabling more
complex user-made abstractions.
## Future work
- Parameterized one-shot systems would improve reusability and bring
them closer to events and commands. The API could be something like
run_system_with_input(my_system, my_input) and use the In SystemParam.
- We should evaluate the unification of commands and one-shot systems
since they are two different ways to run logic on demand over a World.
### Prior attempts
- https://github.com/bevyengine/bevy/pull/2234
- https://github.com/bevyengine/bevy/pull/2417
- https://github.com/bevyengine/bevy/pull/4090
- https://github.com/bevyengine/bevy/pull/7999
This PR continues the work done in
https://github.com/bevyengine/bevy/pull/7999.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Alejandro Pascual Pozo <alejandro.pascual.pozo@gmail.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Dmytro Banin <banind@cs.washington.edu>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Replace instances of
```rust
for x in collection.iter{_mut}() {
```
with
```rust
for x in &{mut} collection {
```
This also changes CI to no longer suppress this lint. Note that since
this lint only shows up when using clippy in pedantic mode, it was
probably unnecessary to suppress this lint in the first place.
# Objective
- When reading API docs and seeing a reference to `ComponentId`, it
isn't immediately clear how to get one from your `Component`. It could
be made to be more clear.
## Solution
- Improve cross-linking of docs about `ComponentId`
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
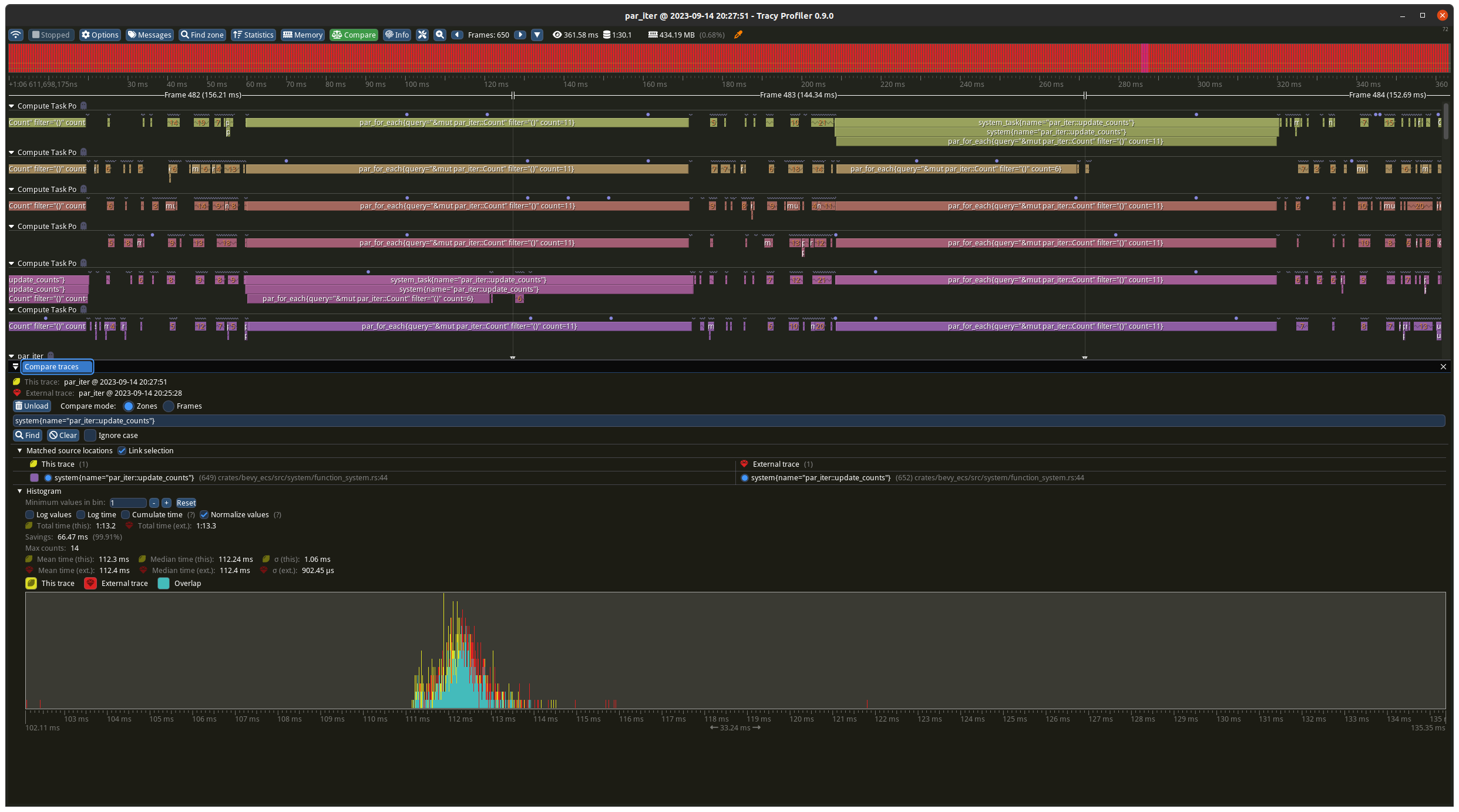
# Objective
The reasoning is similar to #8687.
I'm building a dynamic query. Currently, I store the ReflectFromPtr in
my dynamic `Fetch` type.
[See relevant
code](97ba68ae1e/src/fetches.rs (L14-L17))
However, `ReflectFromPtr` is:
- 16 bytes for TypeId
- 8 bytes for the non-mutable function pointer
- 8 bytes for the mutable function pointer
It's a lot, it adds 32 bytes to my base `Fetch` which is only
`ComponendId` (8 bytes) for a total of 40 bytes.
I only need one function per fetch, reducing the total dynamic fetch
size to 16 bytes.
Since I'm querying the components by the ComponendId associated with the
function pointer I'm using, I don't need the TypeId, it's a redundant
check.
In fact, I've difficulties coming up with situations where checking the
TypeId beforehand is relevant. So to me, if ReflectFromPtr makes sense
as a public API, exposing the function pointers also makes sense.
## Solution
- Make the fields public through methods.
---
## Changelog
- Add `from_ptr` and `from_ptr_mut` methods to `ReflectFromPtr` to
access the underlying function pointers
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
## Migration guide
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
# Objective
Rename RemovedComponents::iter/iter_with_id to read/read_with_id to make
it clear that it consume the data
Fixes#9755.
(It's my first pull request, if i've made any mistake, please let me
know)
## Solution
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
## Changelog
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
Deprecate RemovedComponents::iter/iter_with_id
Remove IntoIterator implementation
Update removal_detection example accordingly
---
## Migration Guide
Rename calls of RemovedComponents::iter/iter_with_id to
read/read_with_id
Replace IntoIterator iteration (&mut <RemovedComponents>) with .read()
---------
Co-authored-by: denshi_ika <mojang2824@gmail.com>
# Objective
When using `set_if_neq`, sometimes you'd like to know if the new value
was different from the old value so that you can perform some additional
branching.
## Solution
Return a bool from this function, which indicates whether or not the
value was overwritten.
---
## Changelog
* `DetectChangesMut::set_if_neq` now returns a boolean indicating
whether or not the value was changed.
## Migration Guide
The trait method `DetectChangesMut::set_if_neq` now returns a boolean
value indicating whether or not the value was changed. If you were
implementing this function manually, you must now return `true` if the
value was overwritten and `false` if the value was not.
# Objective
- The tick access methods mention "ticks" (as in: plural). Yet, most of
them only access a single tick.
## Solution
- Rename those methods and fix docs to reflect the singular aspect of
the return values
---
## Migration Guide
The following method names were renamed, from `foo_ticks_bar` to
`foo_tick_bar` (`ticks` is now singular, `tick`):
- `ComponentSparseSet::get_added_ticks` → `get_added_tick`
- `ComponentSparseSet::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks` → `get_added_tick`
- `Column::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks_unchecked` → `get_added_tick_unchecked`
- `Column::get_changed_ticks_unchecked` → `get_changed_tick_unchecked`
# Objective
- Make it possible to snapshot/save states
- Useful for re-using parts of the state system for rollback safe states
- Or to save states with scenes/savegames
## Solution
- Conditionally add the derive if the `bevy_reflect` is enabled
---
## Changelog
- `NextState<S>` and `State<S>` now implement `Reflect` as long as `S`
does.
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
- Fixes#9244.
## Solution
- Changed the `(Into)SystemSetConfigs` traits and structs be more like
the `(Into)SystemConfigs` traits and structs.
- Replaced uses of `IntoSystemSetConfig` with `IntoSystemSetConfigs`
- Added generic `ItemConfig` and `ItemConfigs` types.
- Changed `SystemConfig(s)` and `SystemSetConfig(s)` to be type aliases
to `ItemConfig(s)`.
- Added generic `process_configs` to `ScheduleGraph`.
- Changed `configure_sets_inner` and `add_systems_inner` to reuse
`process_configs`.
---
## Changelog
- Added `run_if` to `IntoSystemSetConfigs`
- Deprecated `Schedule::configure_set` and `App::configure_set`
- Removed `IntoSystemSetConfig`
## Migration Guide
- Use `App::configure_sets` instead of `App::configure_set`
- Use `Schedule::configure_sets` instead of `Schedule::configure_set`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently we don't have panicking alternative for getting components
from `Query` like for resources. Partially addresses #9443.
## Solution
- Add these functions.
---
## Changelog
### Added
- `Query::component` and `Query::component_mut` to get specific
component from query and panic on error.
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.
# Objective
- Fixes#9641
- Anonymous sets are named by their system members. When
`ScheduleBuildSettings::report_sets` is on, systems are named by their
sets. So when getting the anonymous set name this would cause an
infinite recursion.
## Solution
- When getting the anonymous system set name, don't get their system's
names with the sets the systems belong to.
## Other Possible solutions
- An alternate solution might be to skip anonymous sets when getting the
system's name for an anonymous set's name.
# Objective
- I broke ambiguity reporting in one of my refactors.
`conflicts_to_string` should have been using the passed in parameter
rather than the one stored on self.
# Objective
- The current `EventReader::iter` has been determined to cause confusion
among new Bevy users. It was suggested by @JoJoJet to rename the method
to better clarify its usage.
- Solves #9624
## Solution
- Rename `EventReader::iter` to `EventReader::read`.
- Rename `EventReader::iter_with_id` to `EventReader::read_with_id`.
- Rename `ManualEventReader::iter` to `ManualEventReader::read`.
- Rename `ManualEventReader::iter_with_id` to
`ManualEventReader::read_with_id`.
---
## Changelog
- `EventReader::iter` has been renamed to `EventReader::read`.
- `EventReader::iter_with_id` has been renamed to
`EventReader::read_with_id`.
- `ManualEventReader::iter` has been renamed to
`ManualEventReader::read`.
- `ManualEventReader::iter_with_id` has been renamed to
`ManualEventReader::read_with_id`.
- Deprecated `EventReader::iter`
- Deprecated `EventReader::iter_with_id`
- Deprecated `ManualEventReader::iter`
- Deprecated `ManualEventReader::iter_with_id`
## Migration Guide
- Existing usages of `EventReader::iter` and `EventReader::iter_with_id`
will have to be changed to `EventReader::read` and
`EventReader::read_with_id` respectively.
- Existing usages of `ManualEventReader::iter` and
`ManualEventReader::iter_with_id` will have to be changed to
`ManualEventReader::read` and `ManualEventReader::read_with_id`
respectively.
# Objective
The latest `clippy` release has a much more aggressive application of
the
[`explicit_iter_loop`](https://rust-lang.github.io/rust-clippy/master/index.html#/explicit_into_iter_loop?groups=pedantic)
pedantic lint.
As a result, clippy now suggests the following:
```diff
-for event in events.iter() {
+for event in &mut events {
```
I'm generally in favor of this lint. Using `for mut item in &mut query`
is also recommended over `for mut item in query.iter_mut()` for good
reasons IMO.
But, it is my personal belief that `&mut events` is much less clear than
`events.iter()`.
Why? The reason is that the events from `EventReader` **are not
mutable**, they are immutable references to each event in the event
reader. `&mut events` suggests we are getting mutable access to events —
similarly to `&mut query` — which is not the case. Using `&mut events`
is therefore misleading.
`IntoIterator` requires a mutable `EventReader` because it updates the
internal `last_event_count`, not because it let you mutate it.
So clippy's suggested improvement is a downgrade.
## Solution
Do not implement `IntoIterator` for `&mut events`.
Without the impl, clippy won't suggest its "fix". This also prevents
generally people from using `&mut events` for iterating `EventReader`s,
which makes the ecosystem every-so-slightly better.
---
## Changelog
- Removed `IntoIterator` impl for `&mut EventReader`
## Migration Guide
- `&mut EventReader` does not implement `IntoIterator` anymore. replace
`for foo in &mut events` by `for foo in events.iter()`
# Objective
- Some of the old ambiguity tests didn't get ported over during schedule
v3.
## Solution
- Port over tests from
15ee98db8d/crates/bevy_ecs/src/schedule/ambiguity_detection.rs (L279-L612)
with minimal changes
- Make a method to convert the ambiguity conflicts to a string for
easier verification of correct results.
# Objective
Fix#4278Fix#5504Fix#9422
Provide safe ways to borrow an entire entity, while allowing disjoint
mutable access. `EntityRef` and `EntityMut` are not suitable for this,
since they provide access to the entire world -- they are just helper
types for working with `&World`/`&mut World`.
This has potential uses for reflection and serialization
## Solution
Remove `EntityRef::world`, which allows it to soundly be used within
queries.
`EntityMut` no longer supports structural world mutations, which allows
multiple instances of it to exist for different entities at once.
Structural world mutations are performed using the new type
`EntityWorldMut`.
```rust
fn disjoint_system(
q2: Query<&mut A>,
q1: Query<EntityMut, Without<A>>,
) { ... }
let [entity1, entity2] = world.many_entities_mut([id1, id2]);
*entity1.get_mut::<T>().unwrap() = *entity2.get().unwrap();
for entity in world.iter_entities_mut() {
...
}
```
---
## Changelog
- Removed `EntityRef::world`, to fix a soundness issue with queries.
+ Removed the ability to structurally mutate the world using
`EntityMut`, which allows it to be used in queries.
+ Added `EntityWorldMut`, which is used to perform structural mutations
that are no longer allowed using `EntityMut`.
## Migration Guide
**Note for maintainers: ensure that the guide for #9604 is updated
accordingly.**
Removed the method `EntityRef::world`, to fix a soundness issue with
queries. If you need access to `&World` while using an `EntityRef`,
consider passing the world as a separate parameter.
`EntityMut` can no longer perform 'structural' world mutations, such as
adding or removing components, or despawning the entity. Additionally,
`EntityMut::world`, `EntityMut::world_mut` , and
`EntityMut::world_scope` have been removed.
Instead, use the newly-added type `EntityWorldMut`, which is a helper
type for working with `&mut World`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Move schedule name into `Schedule` to allow the schedule name to be
used for errors and tracing in Schedule methods
- Fixes#9510
## Solution
- Move label onto `Schedule` and adjust api's on `World` and `Schedule`
to not pass explicit label where it makes sense to.
- add name to errors and tracing.
- `Schedule::new` now takes a label so either add the label or use
`Schedule::default` which uses a default label. `default` is mostly used
in doc examples and tests.
---
## Changelog
- move label onto `Schedule` to improve error message and logging for
schedules.
## Migration Guide
`Schedule::new` and `App::add_schedule`
```rust
// old
let schedule = Schedule::new();
app.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
app.add_schedule(schedule);
```
if you aren't using a label and are using the schedule struct directly
you can use the default constructor.
```rust
// old
let schedule = Schedule::new();
schedule.run(world);
// new
let schedule = Schedule::default();
schedule.run(world);
```
`Schedules:insert`
```rust
// old
let schedule = Schedule::new();
schedules.insert(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
schedules.insert(schedule);
```
`World::add_schedule`
```rust
// old
let schedule = Schedule::new();
world.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
world.add_schedule(schedule);
```
# Objective
Every frame, `Events::update` gets called, which clears out any old
events from the buffer. There should be a way of taking ownership of
these old events instead of throwing them away. My use-case is dumping
old events into a debug menu so they can be inspected later.
One potential workaround is to just have a system that clones any
incoming events and stores them in a list -- however, this requires the
events to implement `Clone`.
## Solution
Add `Events::update_drain`, which returns an iterator of the events that
were removed from the buffer.
# Objective
- Fixes: #9508
- Fixes: #9526
## Solution
- Adds
```rust
fn configure_schedules(&mut self, schedule_build_settings: ScheduleBuildSettings)
```
to `Schedules`, and `App` to simplify applying `ScheduleBuildSettings`
to all schedules.
---
## Migration Guide
- No breaking changes.
- Adds `Schedule::get_build_settings()` getter for the schedule's
`ScheduleBuildSettings`.
- Can replaced manual configuration of all schedules:
```rust
// Old
for (_, schedule) in app.world.resource_mut::<Schedules>().iter_mut() {
schedule.set_build_settings(build_settings);
}
// New
app.configure_schedules(build_settings);
```
# Objective
To enable non exclusive system usage of reflected components and make
reflection more ergonomic to use by making it more in line with standard
entity commands.
## Solution
- Implements a new `EntityCommands` extension trait for reflection
related functions in the reflect module of bevy_ecs.
- Implements 4 new commands, `insert_reflect`,
`insert_reflect_with_registry`, `remove_reflect`, and
`remove_reflect_with_registry`. Both insert commands take a `Box<dyn
Reflect>` component while the remove commands take the component type
name.
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module. (Might be worth making these just public to enable user end
custom entity commands in a different pr)
- Added basic tests to ensure the commands are actually working.
- Documentation of functions.
---
## Changelog
Added:
- Implements 4 new commands on the new entity commands extension.
- `insert_reflect`
- `remove_reflect`
- `insert_reflect_with_registry`
- `remove_reflect_with_registry`
The commands operate the same except the with_registry commands take a
generic parameter for a resource that implements `AsRef<TypeRegistry>`.
Otherwise the default commands use the `AppTypeRegistry` for reflection
data.
Changed:
- Made `EntityCommands` fields pub(crate) to allow access in the reflect
module.
> Hopefully this time it works. Please don't make me rebase again ☹
# Objective
- Fixes#4917
- Replaces #9602
## Solution
- Replaced `EntityCommand` implementation for `FnOnce` to apply to
`FnOnce(EntityMut)` instead of `FnOnce(Entity, &mut World)`
---
## Changelog
- `FnOnce(Entity, &mut World)` no longer implements `EntityCommand`.
This is a breaking change.
## Migration Guide
### 1. New-Type `FnOnce`
Create an `EntityCommand` type which implements the method you
previously wrote:
```rust
pub struct ClassicEntityCommand<F>(pub F);
impl<F> EntityCommand for ClassicEntityCommand<F>
where
F: FnOnce(Entity, &mut World) + Send + 'static,
{
fn apply(self, id: Entity, world: &mut World) {
(self.0)(id, world);
}
}
commands.add(ClassicEntityCommand(|id: Entity, world: &mut World| {
/* ... */
}));
```
### 2. Extract `(Entity, &mut World)` from `EntityMut`
The method `into_world_mut` can be used to gain access to the `World`
from an `EntityMut`.
```rust
let old = |id: Entity, world: &mut World| {
/* ... */
};
let new = |mut entity: EntityMut| {
let id = entity.id();
let world = entity.into_world_mut();
/* ... */
};
```
# Objective
The name `ManualEventIterator` is long and unnecessary, as this is the
iterator type used for both `EventReader` and `ManualEventReader`.
## Solution
Rename `ManualEventIterator` to `EventIterator`. To ease migration, add
a deprecated type alias with the old name.
---
## Changelog
- The types `ManualEventIterator{WithId}` have been renamed to
`EventIterator{WithId}`.
## Migration Guide
The type `ManualEventIterator` has been renamed to `EventIterator`.
Additonally, `ManualEventIteratorWithId` has been renamed to
`EventIteratorWithId`.
# Objective
#5483 allows for the creation of non-`Sync` locals. However, it's not
actually possible to use these types as there is a `Sync` bound on the
`Deref` impls.
## Solution
Remove the unnecessary bounds.
# Objective
- have errors in configure_set and configure_sets show the line number
of the user calling location rather than pointing to schedule.rs
- use display formatting for the errors
## Example Error Text
```text
// dependency loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: DependencyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:39
// after
thread 'main' panicked at 'System set `A` depends on itself.', examples/stress_tests/bevymark.rs:16:9
// hierarchy loop
// before
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: HierarchyLoop("A")', crates\bevy_ecs\src\schedule\schedule.rs:682:3
// after
thread 'main' panicked at 'System set `A` contains itself.', examples/stress_tests/bevymark.rs:16:9
// configuring a system type set
// before
thread 'main' panicked at 'configuring system type sets is not allowed', crates\bevy_ecs\src\schedule\config.rs:394:9
//after
thread 'main' panicked at 'configuring system type sets is not allowed', examples/stress_tests/bevymark.rs:16:9
```
Code to produce errors:
```rust
use bevy::prelude::*;
#[derive(SystemSet, Clone, Debug, PartialEq, Eq, Hash)]
enum TestSet {
A,
}
fn main() {
fn foo() {}
let mut app = App::empty();
// Hierarchy Loop
app.configure_set(Main, TestSet::A.in_set(TestSet::A));
// Dependency Loop
app.configure_set(Main, TestSet::A.after(TestSet::A));
// Configure System Type Set
app.configure_set(Main, foo.into_system_set());
}
```
# Objective
- Fixes#9321
## Solution
- `EntityMap` has been replaced by a simple `HashMap<Entity, Entity>`.
---
## Changelog
- `EntityMap::world_scope` has been replaced with `World::world_scope`
to avoid creating a new trait. This is a public facing change to the
call semantics, but has no effect on results or behaviour.
- `EntityMap`, as a `HashMap`, now operates on `&Entity` rather than
`Entity`. This changes many standard access functions (e.g, `.get`) in a
public-facing way.
## Migration Guide
- Calls to `EntityMap::world_scope` can be directly replaced with the
following:
`map.world_scope(&mut world)` -> `world.world_scope(&mut map)`
- Calls to legacy `EntityMap` methods such as `EntityMap::get` must
explicitly include de/reference symbols:
`let entity = map.get(parent);` -> `let &entity = map.get(&parent);`
# Objective
Make code relating to event more readable.
Currently the `impl` block of `Events` is split in two, and the big part
of its implementations are put at the end of the file, far from the
definition of the `struct`.
## Solution
- Move and merge the `impl` blocks of `Events` next to its definition.
- Move the `EventSequence` definition and implementations before the
`Events`, because they're pretty trivial and help understand how
`Events` work, rather than being buried bellow `Events`.
I separated those two steps in two commits to not be too confusing. I
didn't modify any code of documentation. I want to do a second PR with
such modifications after this one is merged.
# Objective
Similar to #6344, but contains only `ReflectBundle` changes. Useful for
scripting. The implementation has also been updated to look exactly like
`ReflectComponent`.
---
## Changelog
### Added
- Reflection for bundles.
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
Any time we wish to transform the output of a system, we currently use
system piping to do so:
```rust
my_system.pipe(|In(x)| do_something(x))
```
Unfortunately, system piping is not a zero cost abstraction. Each call
to `.pipe` requires allocating two extra access sets: one for the second
system and one for the combined accesses of both systems. This also adds
extra work to each call to `update_archetype_component_access`, which
stacks as one adds multiple layers of system piping.
## Solution
Add the `AdapterSystem` abstraction: similar to `CombinatorSystem`, this
allows you to implement a trait to generically control how a system is
run and how its inputs and outputs are processed. Unlike
`CombinatorSystem`, this does not have any overhead when computing world
accesses which makes it ideal for simple operations such as inverting or
ignoring the output of a system.
Add the extension method `.map(...)`: this is similar to `.pipe(...)`,
only it accepts a closure as an argument instead of an `In<T>` system.
```rust
my_system.map(do_something)
```
This has the added benefit of making system names less messy: a system
that ignores its output will just be called `my_system`, instead of
`Pipe(my_system, ignore)`
---
## Changelog
TODO
## Migration Guide
The `system_adapter` functions have been deprecated: use `.map` instead,
which is a lightweight alternative to `.pipe`.
```rust
// Before:
my_system.pipe(system_adapter::ignore)
my_system.pipe(system_adapter::unwrap)
my_system.pipe(system_adapter::new(T::from))
// After:
my_system.map(std::mem::drop)
my_system.map(Result::unwrap)
my_system.map(T::from)
// Before:
my_system.pipe(system_adapter::info)
my_system.pipe(system_adapter::dbg)
my_system.pipe(system_adapter::warn)
my_system.pipe(system_adapter::error)
// After:
my_system.map(bevy_utils::info)
my_system.map(bevy_utils::dbg)
my_system.map(bevy_utils::warn)
my_system.map(bevy_utils::error)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- break up large build_schedule system to make it easier to read
- Clean up related error messages.
- I have a follow up PR that adds the schedule name to the error
messages, but wanted to break this up from that.
## Changelog
- refactor `build_schedule` to be easier to read
## Sample Error Messages
Dependency Cycle
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
```text
thread 'main' panicked at 'System dependencies contain cycle(s).
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
', crates\bevy_ecs\src\schedule\schedule.rs:228:13
```
Hierarchy Cycle
```text
thread 'main' panicked at 'System set hierarchy contains cycle(s).
schedule has 1 in_set cycle(s):
cycle 1: set 'A' contains itself
set 'A'
... which contains set 'B'
... which contains set 'A'
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
System Type Set
```text
thread 'main' panicked at 'Tried to order against `SystemTypeSet(fn foo())` in a schedule that has more than one `SystemTypeSet(fn foo())` instance. `SystemTypeSet(fn foo())` is a `SystemTypeSet` and cannot be used for ordering if ambiguous. Use a different set without this restriction.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Hierarchy Redundancy
```text
thread 'main' panicked at 'System set hierarchy contains redundant edges.
hierarchy contains redundant edge(s) -- system set 'X' cannot be child of set 'A', longer path exists
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Systems have ordering but interset
```text
thread 'main' panicked at '`A` and `C` have a `before`-`after` relationship (which may be transitive) but share systems.', crates\bevy_ecs\src\schedule\schedule.rs:227:51
```
Cross Dependency
```text
thread 'main' panicked at '`A` and `B` have both `in_set` and `before`-`after` relationships (these might be transitive). This combination is unsolvable as a system cannot run before or after a set it belongs to.', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
Ambiguity
```text
thread 'main' panicked at 'Systems with conflicting access have indeterminate run order.
1 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- res_mut and res_ref
conflict on: ["bevymark::ambiguity::X"]
', crates\bevy_ecs\src\schedule\schedule.rs:230:13
```
# Objective
Sometimes you want to create a plugin with a custom run condition. In a
function, you take the `Condition` trait and then make a
`BoxedCondition` from it to store it. And then you want to add that
condition to a system, but you can't, because there is only the `run_if`
function available which takes `impl Condition<M>` instead of
`BoxedCondition`. So you have to create a wrapper type for the
`BoxedCondition` and implement the `System` and `ReadOnlySystem` traits
for the wrapper (Like it's done in the picture below). It's very
inconvenient and boilerplate. But there is an easy solution for that:
make the `run_if_inner` system that takes a `BoxedCondition` public.
Also, it makes sense to make `in_set_inner` function public as well with
the same motivation.

A chunk of the source code of the `bevy-inspector-egui` crate.
## Solution
Make `run_if_inner` function public.
Rename `run_if_inner` to `run_if_dyn`.
Make `in_set_inner` function public.
Rename `in_set_inner` to `in_set_dyn`.
## Changelog
Changed visibility of `run_if_inner` from `pub(crate)` to `pub`.
Renamed `run_if_inner` to `run_if_dyn`.
Changed visibility of `in_set_inner` from `pub(crate)` to `pub`.
Renamed `in_set_inner` to `in_set_dyn`.
## Migration Guide
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
* `Local` and `SystemName` implement `Debug` manually, but they could
derive it.
* `QueryState` and `dyn System` have unconventional debug formatting.
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
While being nobody other's issue as far I can tell, I want to create a
trait I plan to implement on `App` where more than one schedule is
modified.
My workaround so far was working with a closure that returns an
`ExecutorKind` from a match of the method variable.
It makes it easier for me to being able to clone `ExecutorKind` and I
don't see this being controversial for others working with Bevy.
I did nothing more than adding `Clone` to the derived traits, no
migration guide needed.
(If this worked out then the GitHub editor is not too shabby.)
# Objective
Just like
[`set_if_neq`](https://docs.rs/bevy_ecs/latest/bevy_ecs/change_detection/trait.DetectChangesMut.html#method.set_if_neq),
being able to express the "I don't want to unnecessarily trigger the
change detection" but with the ability to handle the previous value if
change occurs.
## Solution
Add `replace_if_neq` to `DetectChangesMut`.
---
## Changelog
- Added `DetectChangesMut::replace_if_neq`: like `set_if_neq` change the
value only if the new value if different from the current one, but
return the previous value if the change occurs.
Add a `RunSystem` extension trait to allow for immediate execution of
systems on a `World` for debugging and/or testing purposes.
# Objective
Fixes#6184
Initially, I made this CL as `ApplyCommands`. After a discussion with
@cart , we decided a more generic implementation would be better to
support all systems. This is the new revised CL. Sorry for the long
delay! 😅
This CL allows users to do this:
```rust
use bevy::prelude::*;
use bevy::ecs::system::RunSystem;
struct T(usize);
impl Resource for T {}
fn system(In(n): In<usize>, mut commands: Commands) -> usize {
commands.insert_resource(T(n));
n + 1
}
let mut world = World::default();
let n = world.run_system_with(1, system);
assert_eq!(n, 2);
assert_eq!(world.resource::<T>().0, 1);
```
## Solution
This is implemented as a trait extension and not included in any
preludes to ensure it's being used consciously.
Internally, it just initializes and runs a systems, and applies any
deferred parameters all "in place".
The trait has 2 functions (one of which calls the other by default):
- `run_system_with` is the general implementation, which allows user to
pass system input parameters
- `run_system` is the ergonomic wrapper for systems with no input
parameter (to avoid having the user pass `()` as input).
~~Additionally, this trait is also implemented for `&mut App`. I added
this mainly for ergonomics (`app.run_system` vs.
`app.world.run_system`).~~ (Removed based on feedback)
---------
Co-authored-by: Pascal Hertleif <killercup@gmail.com>
# Objective
- Fixes#9114
## Solution
Inside `ScheduleGraph::build_schedule()` the variable `node_count =
self.systems.len() + self.system_sets.len()` is used to calculate the
indices for the `reachable` bitset derived from `self.hierarchy.graph`.
However, the number of nodes inside `self.hierarchy.graph` does not
always correspond to `self.systems.len() + self.system_sets.len()` when
`ambiguous_with` is used, because an ambiguous set is added to
`system_sets` (because we need an `NodeId` for the ambiguity graph)
without adding a node to `self.hierarchy`.
In this PR, we rename `node_count` to the more descriptive name
`hg_node_count` and set it to `self.hierarchy.graph.node_count()`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fixes#9113
## Solution
disable `multi-threaded` default feature
## Migration Guide
The `multi-threaded` feature in `bevy_ecs` and `bevy_tasks` is no longer
enabled by default. However, this remains a default feature for the
umbrella `bevy` crate. If you depend on `bevy_ecs` or `bevy_tasks`
directly, you should consider enabling this to allow systems to run in
parallel.
# Objective
The `lifetimeless` module has been a source of confusion for bevy users
for a while now.
## Solution
Add a couple paragraph explaining that, yes, you can use one of the type
alias safely, without ever leaking any memory.
# Objective
Cloning a `WorldQuery` type's "fetch" struct was made unsafe in #5593,
by adding the `unsafe fn clone_fetch` to `WorldQuery`. However, as that
method's documentation explains, it is not the right place to put the
safety invariant:
> While calling this method on its own cannot cause UB it is marked
`unsafe` as the caller must ensure that the returned value is not used
in any way that would cause two `QueryItem<Self>` for the same
`archetype_index` or `table_row` to be alive at the same time.
You can clone a fetch struct all you want and it will never cause
undefined behavior -- in order for something to go wrong, you need to
improperly call `WorldQuery::fetch` with it (which is marked unsafe).
Additionally, making it unsafe to clone a fetch struct does not even
prevent undefined behavior, since there are other ways to incorrectly
use a fetch struct. For example, you could just call fetch more than
once for the same entity, which is not currently forbidden by any
documented invariants.
## Solution
Document a safety invariant on `WorldQuery::fetch` that requires the
caller to not create aliased `WorldQueryItem`s for mutable types. Remove
the `clone_fetch` function, and add the bound `Fetch: Clone` instead.
---
## Changelog
- Removed the associated function `WorldQuery::clone_fetch`, and added a
`Clone` bound to `WorldQuery::Fetch`.
## Migration Guide
### `fetch` invariants
The function `WorldQuery::fetch` has had the following safety invariant
added:
> If this type does not implement `ReadOnlyWorldQuery`, then the caller
must ensure that it is impossible for more than one `Self::Item` to
exist for the same entity at any given time.
This invariant was always required for soundness, but was previously
undocumented. If you called this function manually anywhere, you should
check to make sure that this invariant is not violated.
### Removed `clone_fetch`
The function `WorldQuery::clone_fetch` has been removed. The associated
type `WorldQuery::Fetch` now has the bound `Clone`.
Before:
```rust
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>
unsafe fn clone_fetch<'w>(fetch: &Self::Fetch<'w>) -> Self::Fetch<'w> {
MyFetch {
field1: fetch.field1,
field2: fetch.field2.clone(),
...
}
}
}
```
After:
```rust
#[derive(Clone)]
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>;
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
### **Adopted #6430**
# Objective
`MutUntyped` is the untyped variant of `Mut<T>` that stores a `PtrMut`
instead of a `&mut T`. Working with a `MutUntyped` is a bit annoying,
because as soon you want to use the ptr e.g. as a `&mut dyn Reflect` you
cannot use a type like `Mut<dyn Reflect>` but instead need to carry
around a `&mut dyn Reflect` and a `impl FnMut()` to mark the value as
changed.
## Solution
* Provide a method `map_unchanged` to turn a `MutUntyped` into a
`Mut<T>` by mapping the `PtrMut<'a>` to a `&'a mut T`
This can be used like this:
```rust
// SAFETY: ptr is of type `u8`
let val: Mut<u8> = mut_untyped.map_unchanged(|ptr| unsafe { ptr.deref_mut::<u8>() });
// SAFETY: from the context it is known that `ReflectFromPtr` was made for the type of the `MutUntyped`
let val: Mut<dyn Reflect> = mut_untyped.map_unchanged(|ptr| unsafe { reflect_from_ptr.as_reflect_ptr_mut(ptr) });
```
Note that nothing prevents you from doing
```rust
mut_untyped.map_unchanged(|ptr| &mut ());
```
or using any other mutable reference you can get, but IMO that is fine
since that will only result in a `Mut` that will dereference to that
value and mark the original value as changed. The lifetimes here prevent
anything bad from happening.
## Alternatives
1. Make `Ticks` public and provide a method to get construct a `Mut`
from `Ticks` and `&mut T`. More powerful and more easy to misuse.
2. Do nothing. People can still do everything they want, but they need
to pass (`&mut dyn Reflect, impl FnMut() + '_)` around instead of
`Mut<dyn Reflect>`
## Changelog
- add `MutUntyped::map_unchanged` to turn a `MutUntyped` into its typed
counterpart
---------
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
Fixes#9200
Switches ()'s to []'s when talking about the optional `_mut` suffix in
the ECS Query Struct page to have more idiomatic docs.
## Solution
Replace `()` with `[]` in appropriate doc pages.
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Remove need to call `.get()` on two ticks to compare them for
equality.
## Solution
- Derive `Eq` and `PartialEq`.
---
## Changelog
> `Tick` now implements `Eq` and `PartialEq`
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title. This is necessary in order to update
[`bevy-trait-query`](https://crates.io/crates/bevy-trait-query) to Bevy
0.11.
---
## Changelog
Added the unsafe function `UnsafeWorldCell::storages`, which provides
unchecked access to the internal data stores of a `World`.
# Objective
`World::entity`, `World::entity_mut` and `Commands::entity` should be
marked with `track_caller` to display where (in user code) the call with
the invalid `Entity` was made. `Commands::entity` already has the
attibute, but it does nothing due to the call to `unwrap_or_else`.
## Solution
- Apply the `track_caller` attribute to the `World::entity_mut` and
`World::entity`.
- Remove the call to `unwrap_or_else` which makes the `track_caller`
attribute useless (because `unwrap_or_else` is not `track_caller`
itself). The avoid eager evaluation of the panicking branch it is never
inlined.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
Partially address #5504. Fix#4278. Provide "whole entity" access in
queries. This can be useful when you don't know at compile time what
you're accessing (i.e. reflection via `ReflectComponent`).
## Solution
Implement `WorldQuery` for `EntityRef`.
- This provides read-only access to the entire entity, and supports
anything that `EntityRef` can normally do.
- It matches all archetypes and tables and will densely iterate when
possible.
- It marks all of the ArchetypeComponentIds of a matched archetype as
read.
- Adding it to a query will cause it to panic if used in conjunction
with any other mutable access.
- Expanded the docs on Query to advertise this feature.
- Added tests to ensure the panics were working as intended.
- Added `EntityRef` to the ECS prelude.
To make this safe, `EntityRef::world` was removed as it gave potential
`UnsafeCell`-like access to other parts of the `World` including aliased
mutable access to the components it would otherwise read safely.
## Performance
Not great beyond the additional parallelization opportunity over
exclusive systems. The `EntityRef` is fetched from `Entities` like any
other call to `World::entity`, which can be very random access heavy.
This could be simplified if `ArchetypeRow` is available in
`WorldQuery::fetch`'s arguments, but that's likely not something we
should optimize for.
## Future work
An equivalent API where it gives mutable access to all components on a
entity can be done with a scoped version of `EntityMut` where it does
not provide `&mut World` access nor allow for structural changes to the
entity is feasible as well. This could be done as a safe alternative to
exclusive system when structural mutation isn't required or the target
set of entities is scoped.
---
## Changelog
Added: `Access::has_any_write`
Added: `EntityRef` now implements `WorldQuery`. Allows read-only access
to the entire entity, incompatible with any other mutable access, can be
mixed with `With`/`Without` filters for more targeted use.
Added: `EntityRef` to `bevy::ecs::prelude`.
Removed: `EntityRef::world`
## Migration Guide
TODO
---------
Co-authored-by: Carter Weinberg <weinbergcarter@gmail.com>
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Use `AppTypeRegistry` on API defined in `bevy_ecs`
(https://github.com/bevyengine/bevy/pull/8895#discussion_r1234748418)
A lot of the API on `Reflect` depends on a registry. When it comes to
the ECS. We should use `AppTypeRegistry` in the general case.
This is however impossible in `bevy_ecs`, since `AppTypeRegistry` is
defined in `bevy_app`.
## Solution
- Move `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
- Still add the resource in the `App` plugin, since bevy_ecs itself
doesn't know of plugins
Note that `bevy_ecs` is a dependency of `bevy_app`, so nothing
revolutionary happens.
## Alternative
- Define the API as a trait in `bevy_app` over `bevy_ecs`. (though this
prevents us from using bevy_ecs internals)
- Do not rely on `AppTypeRegistry` for the API in question, requring
users to extract themselves the resource and pass it to the API methods.
---
## Changelog
- Moved `AppTypeRegistry` resource definition from `bevy_app` to
`bevy_ecs`
## Migration Guide
- If you were **not** using a `prelude::*` to import `AppTypeRegistry`,
you should update your imports:
```diff
- use bevy::app::AppTypeRegistry;
+ use bevy::ecs::reflect::AppTypeRegistry
```
# Objective
`WorldQuery::Fetch` is a type used to optimize the implementation of
queries. These types are hidden and not intended to be outside of the
engine, so there is no need to provide type aliases to make it easier to
refer to them. If a user absolutely needs to refer to one of these
types, they can always just refer to the associated type directly.
## Solution
Deprecate these type aliases.
---
## Changelog
- Deprecated the type aliases `QueryFetch` and `ROQueryFetch`.
## Migration Guide
The type aliases `bevy_ecs::query::QueryFetch` and `ROQueryFetch` have
been deprecated. If you need to refer to a `WorldQuery` struct's fetch
type, refer to the associated type defined on `WorldQuery` directly:
```rust
// Before:
type MyFetch<'w> = QueryFetch<'w, MyQuery>;
type MyFetchReadOnly<'w> = ROQueryFetch<'w, MyQuery>;
// After:
type MyFetch<'w> = <MyQuery as WorldQuery>::Fetch;
type MyFetchReadOnly<'w> = <<MyQuery as WorldQuery>::ReadOnly as WorldQuery>::Fetch;
```
Repetitively fetching ReflectResource and ReflectComponent from the
TypeRegistry is costly.
We want to access the underlying `fn`s. to do so, we expose the
`ReflectResourceFns` and `ReflectComponentFns` stored in ReflectResource
and ReflectComponent.
---
## Changelog
- Add the `fn_pointers` methods to `ReflectResource` and
`ReflectComponent` returning the underlying `ReflectResourceFns` and
`ReflectComponentFns`
# Objective
- Fixes#7811
## Solution
- I added `Has<T>` (and `HasFetch<T>` ) and implemented `WorldQuery`,
`ReadonlyWorldQuery`, and `ArchetypeFilter` it
- I also added documentation with an example and a unit test
I believe I've done everything right but this is my first contribution
and I'm not an ECS expert so someone who is should probably check my
implementation. I based it on what `Or<With<T>,>`, would do. The only
difference is that `Has` does not update component access - adding `Has`
to a query should never affect whether or not it is disjoint with
another query *I think*.
---
## Changelog
## Added
- Added `Has<T>` WorldQuery to find out whether or not an entity has a
particular component.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Cleanup the `reflect.rs` file in `bevy_ecs`, it's very large and can
get difficult to navigate
## Solution
- Split the file into 3 modules, re-export the types in the
`reflect/mod.rs` to keep a perfectly identical API.
- Add **internal** architecture doc explaining how `ReflectComponent`
works. Note that this doc is internal only, since `component.rs` is not
exposed publicly.
### Tips to reviewers
To review this change properly, you need to compare it to the previous
version of `reflect.rs`. The diff from this PR does not help at all!
What you will need to do is compare `reflect.rs` individually with each
newly created file.
Here is how I did it:
- Adding my fork as remote `git remote add nicopap
https://github.com/nicopap/bevy.git`
- Checkout out the branch `git checkout nicopap/split_ecs_reflect`
- Checkout the old `reflect.rs` by running `git checkout HEAD~1 --
crates/bevy_ecs/src/reflect.rs`
- Compare the old with the new with `git diff --no-index
crates/bevy_ecs/src/reflect.rs crates/bevy_ecs/src/reflect/component.rs`
You could also concatenate everything into a single file and compare
against it:
- `cat
crates/bevy_ecs/src/reflect/{component,resource,map_entities,mod}.rs >
new_reflect.rs`
- `git diff --no-index crates/bevy_ecs/src/reflect.rs new_reflect.rs`
# Objective
Resolves#7558.
Systems that are known to never modify the world implement the trait
`ReadOnlySystem`. This is a perfect place to add a safe API for running
a system with a shared reference to a World.
---
## Changelog
- Added the trait method `ReadOnlySystem::run_readonly`, which allows a
system to be run using `&World`.
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
`ComponentIdFor` is a type that gives you access to a component's
`ComponentId` in a system. It is currently awkward to use, since it must
be wrapped in a `Local<>` to be used.
## Solution
Make `ComponentIdFor` a proper SystemParam.
---
## Changelog
- Refactored the type `ComponentIdFor` in order to simplify how it is
used.
## Migration Guide
The type `ComponentIdFor<T>` now implements `SystemParam` instead of
`FromWorld` -- this means it should be used as the parameter for a
system directly instead of being used in a `Local`.
```rust
// Before:
fn my_system(
component_id: Local<ComponentIdFor<MyComponent>>,
) {
let component_id = **component_id;
}
// After:
fn my_system(
component_id: ComponentIdFor<MyComponent>,
) {
let component_id = component_id.get();
}
```
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
The method `UnsafeWorldCell::read_change_tick` was renamed in #8588, but
I forgot to update a usage of this method in a doctest.
## Solution
Update the method call.
# Objective
To mirror the `Ref` added as `WorldQuery`, and the `Mut` in
`EntityMut::get_mut`, we add `EntityRef::get_ref`, which retrieves `T`
with tick information, but *immutably*.
## Solution
- Add the method in question, also add it to`UnsafeEntityCell` since
this seems to be the best way of getting that information.
Also update/add safety comments to neighboring code.
---
## Changelog
- Add `EntityRef::get_ref` to get an `Option<Ref<T>>` from `EntityRef`
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The method `QueryState::par_iter` does not currently force the query to
be read-only. This means you can unsoundly mutate a world through an
immutable reference in safe code.
```rust
fn bad_system(world: &World, mut query: Local<QueryState<&mut T>>) {
query.par_iter(world).for_each_mut(|mut x| *x = unsoundness);
}
```
## Solution
Use read-only versions of the `WorldQuery` types.
---
## Migration Guide
The function `QueryState::par_iter` now forces any world accesses to be
read-only, similar to how `QueryState::iter` works. Any code that
previously mutated the world using this method was *unsound*. If you
need to mutate the world, use `par_iter_mut` instead.
# Objective
Make a combined system cloneable if both systems are cloneable on their
own. This is necessary for using chained conditions (e.g
`cond1.and_then(cond2)`) with `distributive_run_if()`.
## Solution
Implement `Clone` for `CombinatorSystem<Func, A, B>` where `A, B:
Clone`.
# Objective
EntityRef::get_change_ticks mentions that ComponentTicks is useful to
create change detection for your own runtime.
However, ComponentTicks doesn't even expose enough data to create
something that implements DetectChanges. Specifically, we need to be
able to extract the last change tick.
## Solution
We add a method to get the last change tick. We also add a method to get
the added tick.
## Changelog
- Add `last_changed_tick` and `added_tick` to `ComponentTicks`
# Objective
- Fixes#8811 .
## Solution
- Rename "write" method to "apply" in Command trait definition.
- Rename other implementations of command trait throughout bevy's code
base.
---
## Changelog
- Changed: `Command::write` has been changed to `Command::apply`
- Changed: `EntityCommand::write` has been changed to
`EntityCommand::apply`
## Migration Guide
- `Command::write` implementations need to be changed to implement
`Command::apply` instead. This is a mere name change, with no further
actions needed.
- `EntityCommand::write` implementations need to be changed to implement
`EntityCommand::apply` instead. This is a mere name change, with no
further actions needed.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- I can't map unsized type using `Ref::map` (for example `dyn Reflect`)
## Solution
- Allow unsized types (this is possible because `Ref` stores a reference
to `T`)
# Objective
`QueryState` exposes a `get_manual` and `iter_manual` method. However,
there is now `iter_many_manual`.
`iter_many_manual` is useful when you have a `&World` (eg: the `world`
in a `Scene`) and want to run a query several times on it (eg:
iteratively navigate a hierarchy by calling `iter_many` on `Children`
component).
`iter_many`'s need for a `&mut World` makes the API much less flexible.
The exclusive access pattern requires doing some very funky dance and
excludes a category of algorithms for hierarchy traversal.
## Solution
- Add a `iter_many_manual` method to `QueryState`
### Alternative
My current workaround is to use `get_manual`. However, this doesn't
benefit from the optimizations on `QueryManyIter`.
---
## Changelog
- Add a `iter_many_manual` method to `QueryState`
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
`Ref` is a useful way of accessing change detection data.
However, unlike `Mut`, it doesn't expose a constructor or even a way to
go from `Ref<A>` to `Ref<B>`.
Such methods could be useful, for example, to 3rd party crates that want
to expose change detection information in a clean way.
My use case is to map a `Ref<T>` into a `Ref<dyn Reflect>`, and keep
change detection info to avoid running expansive routines.
## Solution
We add the `new` and `map` methods. Since similar methods exist on `Mut`
where they are much more footgunny to use, I judged that it was
acceptable to create such methods.
## Workaround
Currently, it's not possible to create/project `Ref`s. One can define
their own `Ref` and implement `ChangeDetection` on it. One would then
use `ChangeTrackers` to populate the custom `Ref` with tick data.
---
## Changelog
- Added the `Ref::map` and `Ref::new` methods for more ergonomic `Ref`s
---------
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
Be consistent with `Resource`s and `Components` and have `Event` types
be more self-documenting.
Although not susceptible to accidentally using a function instead of a
value due to `Event`s only being initialized by their type, much of the
same reasoning for removing the blanket impl on `Resource` also applies
here.
* Not immediately obvious if a type is intended to be an event
* Prevent invisible conflicts if the same third-party or primitive types
are used as events
* Allows for further extensions (e.g. opt-in warning for missed events)
## Solution
Remove the blanket impl for the `Event` trait. Add a derive macro for
it.
---
## Changelog
- `Event` is no longer implemented for all applicable types. Add the
`#[derive(Event)]` macro for events.
## Migration Guide
* Add the `#[derive(Event)]` macro for events. Third-party types used as
events should be wrapped in a newtype.
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
- `apply_system_buffers` is an unhelpful name: it introduces a new
internal-only concept
- this is particularly rough for beginners as reasoning about how
commands work is a critical stumbling block
## Solution
- rename `apply_system_buffers` to the more descriptive `apply_deferred`
- rename related fields, arguments and methods in the internals fo
bevy_ecs for consistency
- update the docs
## Changelog
`apply_system_buffers` has been renamed to `apply_deferred`, to more
clearly communicate its intent and relation to `Deferred` system
parameters like `Commands`.
## Migration Guide
- `apply_system_buffers` has been renamed to `apply_deferred`
- the `apply_system_buffers` method on the `System` trait has been
renamed to `apply_deferred`
- the `is_apply_system_buffers` function has been replaced by
`is_apply_deferred`
- `Executor::set_apply_final_buffers` is now
`Executor::set_apply_final_deferred`
- `Schedule::apply_system_buffers` is now `Schedule::apply_deferred`
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
- Supress false positive `redundant_clone` lints.
- Supress inactionable `result_large_err` lint.
Most of the size(50 out of 68 bytes) is coming from
`naga::WithSpan<naga::valid::ValidationError>`
# Objective
The `Condition` trait is only implemented for systems and system
functions that take no input. This can make it awkward to write
conditions that are intended to be used with system piping.
## Solution
Add an `In` generic to the trait. It defaults to `()`.
---
## Changelog
- Made the `Condition` trait generic over system inputs.
# Objective
Several of our built-in `Command` types are too public:
- `GetOrSpawn` is public, even though it only makes sense to call it
from within `Commands::get_or_spawn`.
- `Remove` and `RemoveResource` contain public `PhantomData` marker
fields.
## Solution
Remove `GetOrSpawn` and use an anonymous command. Make the marker fields
private.
---
## Migration Guide
The `Command` types `Remove` and `RemoveResource` may no longer be
constructed manually.
```rust
// Before:
commands.add(Remove::<T> {
entity: id,
phantom: PhantomData,
});
// After:
commands.add(Remove::<T>::new(id));
// Before:
commands.add(RemoveResource::<T> { phantom: PhantomData });
// After:
commands.add(RemoveResource::<T>::new());
```
The command type `GetOrSpawn` has been removed. It was not possible to
use this type outside of `bevy_ecs`.
# Objective
Add documentation to `Query` and `QueryState` errors in bevy_ecs
(`QuerySingleError`, `QueryEntityError`, `QueryComponentError`)
## Solution
- Change display message for `QueryEntityError::QueryDoesNotMatch`: this
error can also happen when the entity has a component which is filtered
out (with `Without<C>`)
- Fix wrong reference in the documentation of `Query::get_component` and
`Query::get_component_mut` from `QueryEntityError` to
`QueryComponentError`
- Complete the documentation of the three error enum variants.
- Add examples for `QueryComponentError::MissingReadAccess` and
`QueryComponentError::MissingWriteAccess`
- Add reference to `QueryState` in `QueryEntityError`'s documentation.
---
## Migration Guide
Expect `QueryEntityError::QueryDoesNotMatch`'s display message to
change? Not sure that counts.
---------
Co-authored-by: harudagondi <giogdeasis@gmail.com>
# Objective
Fix#7833.
Safety comments in the multi-threaded executor don't really talk about
system world accesses, which makes it unclear if the code is actually
valid.
## Solution
Update the `System` trait to use `UnsafeWorldCell`. This type's API is
written in a way that makes it much easier to cleanly maintain safety
invariants. Use this type throughout the multi-threaded executor, with a
liberal use of safety comments.
---
## Migration Guide
The `System` trait now uses `UnsafeWorldCell` instead of `&World`. This
type provides a robust API for interior mutable world access.
- The method `run_unsafe` uses this type to manage world mutations
across multiple threads.
- The method `update_archetype_component_access` uses this type to
ensure that only world metadata can be used.
```rust
let mut system = IntoSystem::into_system(my_system);
system.initialize(&mut world);
// Before:
system.update_archetype_component_access(&world);
unsafe { system.run_unsafe(&world) }
// After:
system.update_archetype_component_access(world.as_unsafe_world_cell_readonly());
unsafe { system.run_unsafe(world.as_unsafe_world_cell()) }
```
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow for directly call methods on states without first calling
`state.get().my_method()`
## Solution
- Implement `Deref` for `State<S>` with `Target = S`
---
*I did not implement `DerefMut` because states hold no data and should
only be changed via `NextState::set()`*
# Objective
This method has no documentation and it's extremely unclear what it
does, or what the returned tick represents.
## Solution
Write documentation.
# Objective
The unit test `chang_tick_wraparound` is meant to ensure that change
ticks correctly deal with wrapping by setting the world's
`last_change_tick` to `u32::MAX`. However, since systems don't use* the
value of `World::last_change_tick`, this test doesn't actually involve
any wrapping behavior.
*exclusive systems do use `World::last_change_tick`; however it gets
overwritten by the system's own last tick in `System::run`.
## Solution
Use `QueryState` instead of systems in the unit test. This approach
actually uses `World::last_change_tick`, so it properly tests that
change ticks deal with wrapping correctly.
# Objective
`ScheduleGraph` currently stores run conditions in a
`Option<Vec<BoxedCondition>>`. The `Option` is unnecessary, since we can
just use an empty vector instead of `None`.
# Objective
The method `UnsafeWorldCell::world_mut` is a special case, since its
safety contract is more difficult to satisfy than the other methods on
`UnsafeWorldCell`. Rewrite its documentation to be specific about when
it can and cannot be used. Provide examples and emphasize that it is
unsound to call in most cases.
# Objective
The method `UnsafeWorldCell::read_change_tick` is longer than it needs
to be. `World` only has a method called this because it has two methods
for getting a change tick: one that takes `&self` and one that takes
`&mut self`. Since this distinction is not applicable to
`UnsafeWorldCell`, we should just call this method `change_tick`.
## Solution
Deprecate the current method and add a new one called `change_tick`.
---
## Changelog
- Renamed `UnsafeWorldCell::read_change_tick` to `change_tick`.
## Migration Guide
The `UnsafeWorldCell` method `read_change_tick` has been renamed to
`change_tick`.
# Objective
Fixes#8528
## Solution
Manually implement `PartialEq`, `Eq`, `PartialOrd`, `Ord`, and `Hash`
for `bevy_ecs::event::EventId`. These new implementations do not rely on
the `Event` implementing the same traits allowing `EventId` to be used
in more cases.
# Objective
After fixing dynamic scene to only map specific entities, we want
map_entities to default to the less error prone behavior and have the
previous behavior renamed to "map_all_entities." As this is a breaking
change, it could not be pushed out with the bug fix.
## Solution
Simple rename and refactor.
## Changelog
### Changed
- `map_entities` now accepts a list of entities to apply to, with
`map_all_entities` retaining previous behavior of applying to all
entities in the map.
## Migration Guide
- In `bevy_ecs`, `ReflectMapEntities::map_entites` now requires an
additional `entities` parameter to specify which entities it applies to.
To keep the old behavior, use the new
`ReflectMapEntities::map_all_entities`, but consider if passing the
entities in specifically might be better for your use case to avoid
bugs.
# Objective
- Handle dangling entity references inside scenes
- Handle references to entities with generation > 0 inside scenes
- Fix a latent bug in `Parent`'s `MapEntities` implementation, which
would, if the parent was outside the scene, cause the scene to be loaded
into the new world with a parent reference potentially pointing to some
random entity in that new world.
- Fixes#4793 and addresses #7235
## Solution
- DynamicScenes now identify entities with a `Entity` instead of a u32,
therefore including generation
- `World` exposes a new `reserve_generations` function that despawns an
entity and advances its generation by some extra amount.
- `MapEntities` implementations have a new `get_or_reserve` function
available that will always return an `Entity`, establishing a new
mapping to a dead entity when the entity they are called with is not in
the `EntityMap`. Subsequent calls with that same `Entity` will return
the same newly created dead entity reference, preserving equality
semantics.
- As a result, after loading a scene containing references to dead
entities (or entities otherwise outside the scene), those references
will all point to different generations on a single entity id in the new
world.
---
## Changelog
### Changed
- In serialized scenes, entities are now identified by a u64 instead of
a u32.
- In serialized scenes, components with entity references now have those
references serialize as u64s instead of structs.
### Fixed
- Scenes containing components with entity references will now
deserialize and add to a world reliably.
## Migration Guide
- `MapEntities` implementations must change from a `&EntityMap`
parameter to a `&mut EntityMapper` parameter and can no longer return a
`Result`. Finally, they should switch from calling `EntityMap::get` to
calling `EntityMapper::get_or_reserve`.
---------
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Methods for interacting with world schedules currently have two
variants: one that takes `impl ScheduleLabel` and one that takes `&dyn
ScheduleLabel`. Operations such as `run_schedule` or `schedule_scope`
only use the label by reference, so there is little reason to have an
owned variant of these functions.
## Solution
Decrease maintenance burden by merging the `ref` variants of these
functions with the owned variants.
---
## Changelog
- Deprecated `World::run_schedule_ref`. It is now redundant, since
`World::run_schedule` can take values by reference.
## Migration Guide
The method `World::run_schedule_ref` has been deprecated, and will be
removed in the next version of Bevy. Use `run_schedule` instead.
# Objective
Label traits such as `ScheduleLabel` currently have a major footgun: the
trait is implemented for `Box<dyn ScheduleLabel>`, but the
implementation does not function as one would expect since `Box<T>` is
considered to be a distinct type from `T`. This is because the behavior
of the `ScheduleLabel` trait is specified mainly through blanket
implementations, which prevents `Box<dyn ScheduleLabel>` from being
properly special-cased.
## Solution
Replace the blanket-implemented behavior with a series of methods
defined on `ScheduleLabel`. This allows us to fully special-case
`Box<dyn ScheduleLabel>` .
---
## Changelog
Fixed a bug where boxed label types (such as `Box<dyn ScheduleLabel>`)
behaved incorrectly when compared with concretely-typed labels.
## Migration Guide
The `ScheduleLabel` trait has been refactored to no longer depend on the
traits `std::any::Any`, `bevy_utils::DynEq`, and `bevy_utils::DynHash`.
Any manual implementations will need to implement new trait methods in
their stead.
```rust
impl ScheduleLabel for MyType {
// Before:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
// After:
fn dyn_clone(&self) -> Box<dyn ScheduleLabel> { ... }
fn as_dyn_eq(&self) -> &dyn DynEq {
self
}
// No, `mut state: &mut` is not a typo.
fn dyn_hash(&self, mut state: &mut dyn Hasher) {
self.hash(&mut state);
// Hashing the TypeId isn't strictly necessary, but it prevents collisions.
TypeId::of::<Self>().hash(&mut state);
}
}
```
Added helper extracted from #7711. that PR contains some controversy
conditions, but this one should be good to go.
---
## Changelog
### Added
- `any_component_removed` condition.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Follow-up to #8377.
As the system module has been refactored, there are many types that no
longer make sense to live in the files that they do:
- The `IntoSystem` trait is in `function_system.rs`, even though this
trait is relevant to all kinds of systems. Same for the `In<T>` type.
- `PipeSystem` is now just an implementation of `CombinatorSystem`, so
`system_piping.rs` no longer needs its own file.
## Solution
- Move `IntoSystem`, `In<T>`, and system piping combinators & tests into
the top-level `mod.rs` file for `bevy_ecs::system`.
- Move `PipeSystem` into `combinator.rs`.
# Objective
- Currently, it is not possible to call `.pipe` on a system that takes
any input other than `()`.
- The `IntoPipeSystem` trait is currently very difficult to parse due to
its use of generics.
## Solution
Remove the `IntoPipeSystem` trait, and move the `pipe` method to
`IntoSystem`.
---
## Changelog
- System piping has been made more flexible: it is now possible to call
`.pipe` on a system that takes an input.
## Migration Guide
The `IntoPipeSystem` trait has been removed, and the `pipe` method has
been moved to the `IntoSystem` trait.
```rust
// Before:
use bevy_ecs::system::IntoPipeSystem;
schedule.add_systems(first.pipe(second));
// After:
use bevy_ecs::system::IntoSystem;
schedule.add_systems(first.pipe(second));
```
# Objective
- Fixes unclear warning when `insert_non_send_resource` is called on a
Send resource
## Solution
- Add a message to the asssert statement that checks this
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The implementation of `System::run_unsafe` for `FunctionSystem` requires
that the world is the same one used to initialize the system. However,
the `System` trait has no requirements that the world actually matches,
which makes this implementation unsound.
This was previously mentioned in
https://github.com/bevyengine/bevy/pull/7605#issuecomment-1426491871
Fixes part of #7833.
## Solution
Add the safety invariant that
`System::update_archetype_component_access` must be called prior to
`System::run_unsafe`. Since
`FunctionSystem::update_archetype_component_access` properly validates
the world, this ensures that `run_unsafe` is not called with a
mismatched world.
Most exclusive systems are not required to be run on the same world that
they are initialized with, so this is not a concern for them. Systems
formed by combining an exclusive system with a regular system *do*
require the world to match, however the validation is done inside of
`System::run` when needed.
# Objective
This PR attempts to improve query compatibility checks in scenarios
involving `Or` filters.
Currently, for the following two disjoint queries, Bevy will throw a
panic:
```
fn sys(_: Query<&mut C, Or<(With<A>, With<B>)>>, _: Query<&mut C, (Without<A>, Without<B>)>) {}
```
This PR addresses this particular scenario.
## Solution
`FilteredAccess::with` now stores a vector of `AccessFilters`
(representing a pair of `with` and `without` bitsets), where each member
represents an `Or` "variant".
Filters like `(With<A>, Or<(With<B>, Without<C>)>` are expected to be
expanded into `A * B + A * !C`.
When calculating whether queries are compatible, every `AccessFilters`
of a query is tested for incompatibility with every `AccessFilters` of
another query.
---
## Changelog
- Improved system and query data access compatibility checks in
scenarios involving `Or` filters
---------
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
If you want to execute a schedule on the world using arbitrarily complex
behavior, you currently need to use "hokey-pokey strats": remove the
schedule from the world, do your thing, and add it back to the world.
Not only is this cumbersome, it's potentially error-prone as one might
forget to re-insert the schedule.
## Solution
Add the `World::{try}schedule_scope{ref}` family of functions, which is
a convenient abstraction over hokey pokey strats. This method
essentially works the same way as `World::resource_scope`.
### Example
```rust
// Run the schedule five times.
world.schedule_scope(MySchedule, |world, schedule| {
for _ in 0..5 {
schedule.run(world);
}
});
```
---
## Changelog
Added the `World::schedule_scope` family of methods, which provide a way
to get mutable access to a world and one of its schedules at the same
time.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
The behavior of change detection within `PipeSystem` is very tricky and
subtle, and is not currently covered by any of our tests as far as I'm
aware.
# Objective
Upon closer inspection, there are a few functions in the ECS that are
not being inlined, even with the highest optimizations and LTO enabled:
- Almost all
[WorldQuery::init_fetch](9fd5f20e25/results/query_get.s (L57))
calls. Affects `Query::get` calls in hot loops. In particular, the
`WorldQuery` implementation for `()` is used *everywhere* as the default
filter and is effectively a no-op.
-
[Entities::get](9fd5f20e25/results/query_get.s (L39)).
Affects `Query::get`, `World::get`, and any component insertion or
removal.
-
[Entities::set](9fd5f20e25/results/entity_remove.s (L2487)).
Affects any component insertion or removal.
-
[Tick::new](9fd5f20e25/results/entity_insert.s (L1368)).
I've only seen this in component insertion and spawning.
- ArchetypeRow::new
- BlobVec::set_len
Almost all of these have trivial or even empty implementations or have
significant opportunity to be optimized into surrounding code when
inlined with LTO enabled.
## Solution
Inline them
# Objective
The method `World::try_run_schedule` currently panics if the `Schedules`
resource does not exist, but it should just return an `Err`. Similarly,
`World::add_schedule` panics unnecessarily if the resource does not
exist.
Also, the documentation for `World::add_schedule` is completely wrong.
## Solution
When the `Schedules` resource does not exist, we now treat it the same
as if it did exist but was empty. When calling `add_schedule`, we
initialize it if it does not exist.
# Objective
Fixes#8215 and #8152. When systems panic, it causes the main thread to
panic as well, which clutters the output.
## Solution
Resolves the panic in the multi-threaded scheduler. Also adds an extra
message that tells the user the system that panicked.
Using the example from the issue, here is what the messages now look
like:
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Update, panicking_system)
.run();
}
fn panicking_system() {
panic!("oooh scary");
}
```
### Before
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2m 58s
Running `target\debug\bevy_test.exe`
2023-03-30T22:19:09.234932Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'Compute Task Pool (5)' panicked at 'A system has panicked so the executor cannot continue.: RecvError', E:\Projects\Rust\bevy\crates\bevy_ecs\src\schedule\executor\multi_threaded.rs:194:60
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', E:\Projects\Rust\bevy\crates\bevy_tasks\src\task_pool.rs:376:49
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
### After
```
Compiling bevy_test v0.1.0 (E:\Projects\Rust\bevy_test)
Finished dev [unoptimized + debuginfo] target(s) in 2.39s
Running `target\debug\bevy_test.exe`
2023-03-30T22:11:24.748513Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "Windows 10 Pro", kernel: "19044", cpu: "AMD Ryzen 5 2600 Six-Core Processor", core_count: "6", memory: "15.9 GiB" }
thread 'Compute Task Pool (5)' panicked at 'oooh scary', src\main.rs:11:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Encountered a panic in system `bevy_test::panicking_system`!
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\bevy_test.exe` (exit code: 101)
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix#8191.
Currently, a state transition will be triggered whenever the `NextState`
resource has a value, even if that "transition" is to the same state as
the previous one. This caused surprising/meaningless behavior, such as
the existence of an `OnTransition { from: A, to: A }` schedule.
## Solution
State transition schedules now only run if the new state is not equal to
the old state. Change detection works the same way, only being triggered
when the states compare not equal.
---
## Changelog
- State transition schedules are no longer run when transitioning to and
from the same state.
## Migration Guide
State transitions are now only triggered when the exited and entered
state differ. This means that if the world is currently in state `A`,
the `OnEnter(A)` schedule (or `OnExit`) will no longer be run if you
queue up a state transition to the same state `A`.
# Objective
Noticed while writing #7728 that we are using `trace!` logs in our event
functions. This has shown to have significant overhead, even trace level
logs are disabled globally, as seen in #7639.
## Solution
Use the `detailed_trace!` macro introduced in #7639. Also removed the
`event_trace` function that was only used in one location.
---
## Changelog
Changed: Event trace logs are now feature gated behind the
`detailed-trace` feature.
Fixes#8333
# Objective
Fixes issue which causes failure to compile if using
`#![deny(missing_docs)]`.
## Solution
Added some very basic commenting to the generated read-only fields.
honestly I feel this to be up for debate since the comments are very
basic and give very little useful information but the purpose of this PR
is to fix the issue at hand.
---
## Changelog
Added comments to the derive macro and the projects now successfully
compile.
---------
Co-authored-by: lupan <kallll5@hotmail.com>
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
State requires a kind of awkward `state.0` to get the current state and
exposes the field directly to manipulation.
## Solution
Make it accessible through a getter method as well as privatize the
field to make sure false assumptions about setting the state aren't
made.
## Migration Guide
- Use `State::get` instead of accessing the tuple field directly.
# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
While migrating the engine to use the `Tick` type in #7905, I forgot to
update `UnsafeWorldCell::increment_change_tick`.
## Solution
Update the function.
---
## Changelog
- The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
## Migration Guide
The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
Our regression tests for `SystemParam` currently consist of a bunch of
loosely dispersed struct definitions. This is messy, and doesn't fully
test their functionality.
## Solution
Group the struct definitions into functions annotated with `#[test]`.
This not only makes the module more organized, but it allows us to call
`assert_is_system`, which has the potential to catch some bugs that
would have been missed with the old approach. Also, this approach is
consistent with how `WorldQuery` regression tests are organized.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
I ran into a case where I need to create a `CommandQueue` and push
standard `Command` actions like `Insert` or `Remove` to it manually. I
saw that `Remove` looked as follows:
```rust
struct Remove<T> {
entity: Entity,
phantom: PhantomData<T>
}
```
so naturally, I tried to use `Remove::<Foo>::from(entity)` but it didn't
exist. We need to specify the `PhantomData` explicitly when creating
this command action. The same goes for `RemoveResource` and
`InitResource`
## Solution
This PR implements the following:
- `From<Entity>` for `Remove<T>`
- `Default` for `RemoveResource` and `InitResource`
- use these traits in the implementation of methods of `Commands`
- rename `phantom` field on the structs above to `_phantom` to have a
more uniform field naming scheme for the command actions
---
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
- Added: implemented `From<Entity>` for `Remove<T>` and `Default` for
`RemoveResource` and `InitResource` for ergonomics
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This MR is a rebased and alternative proposal to
https://github.com/bevyengine/bevy/pull/5602
# Objective
- https://github.com/bevyengine/bevy/pull/4447 implemented untyped
(using component ids instead of generics and TypeId) APIs for
inserting/accessing resources and accessing components, but left
inserting components for another PR (this one)
## Solution
- add `EntityMut::insert_by_id`
- split `Bundle` into `DynamicBundle` with `get_components` and `Bundle:
DynamicBundle`. This allows the `BundleInserter` machinery to be reused
for bundles that can only be written, not read, and have no statically
available `ComponentIds`
- Compared to the original MR this approach exposes unsafe endpoints and
requires the user to manage instantiated `BundleIds`. This is quite easy
for the end user to do and does not incur the performance penalty of
checking whether component input is correctly provided for the
`BundleId`.
- This MR does ensure that constructing `BundleId` itself is safe
---
## Changelog
- add methods for inserting bundles and components to:
`world.entity_mut(entity).insert_by_id`
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
`EntityMut::move_entity_from_remove` had two soundness bugs:
- When removing the entity from the archetype, the swapped entity had its table row updated to the same as the removed entity's
- When removing the entity from the table, the swapped entity did not have its table row updated
`BundleInsert::insert` had two/three soundness bugs
- When moving an entity to a new archetype from an `insert`, the swapped entity had its table row set to a different entities
- When moving an entity to a new table from an `insert`, the swapped entity did not have its table row updated
See added tests for examples that trigger those bugs
`EntityMut::despawn` had two soundness bugs
- When despawning an entity, the swapped entity had its table row set to a different entities even if the table didnt change
- When despawning an entity, the swapped entity did not have its table row updated
# Objective
- A more intuitive distinction between the two. `remove_intersection` is verbose and unclear.
- `EntityMut::remove` and `Commands::remove` should match.
## Solution
- What the title says.
---
## Migration Guide
Before
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).remove::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove_intersection::<Parent>();
}
}
}
```
After
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).take::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove::<Parent>();
}
}
}
```
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
While we use `#[doc(hidden)]` to try and hide marker generics from the user, these types reveal themselves in compiler errors, adding visual noise and confusion.
## Solution
Replace the `AlreadyWasSystem` marker generic with `()`, to reduce visual noise in error messages. This also makes it possible to return `impl Condition<()>` from combinators.
For function systems, use their function signature as the marker type. This should drastically improve the legibility of some error messages.
The `InputMarker` type has been removed, since it is unnecessary.
# Objective
Several places in the ECS use marker generics to avoid overlapping trait implementations, but different places alternately refer to it as `Params` and `Marker`. This is potentially confusing, since it might not be clear that the same pattern is being used. Additionally, users might be misled into thinking that the `Params` type corresponds to the `SystemParam`s of a system.
## Solution
Rename `Params` to `Marker`.
# Objective
Fixes#3980
## Solution
Added examples to show how to run a `Schedule`, one with a unique system, and another with several systems
---
## Changelog
- Added: examples in docs to show how to run a `Schedule`
Co-authored-by: remiCzn <77072160+remiCzn@users.noreply.github.com>
# Objective
The `BoxedCondition` type alias does not require the underlying system to be read-only.
## Solution
Define the type alias using `ReadOnlySystem` instead of `System`.
Graph theory make head hurty. Closes#7367.
Basically, when we topologically sort the dependency graph, we already find its strongly-connected components (a really [neat algorithm][1]). This PR adds an algorithm that can dissect those into simple cycles, giving us more useful error reports.
test: `system_build_errors::dependency_cycle`
```
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
```
```
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
```
test: `system_build_errors::hierarchy_cycle`
```
schedule has 1 in_set cycle(s):
cycle 1: system set 'A' contains itself
system set 'A'
... which contains system set 'B'
... which contains system set 'A'
```
[1]: https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
Add some more useful common run conditions.
Some of these existed in `iyes_loopless`. I know people used them, and it would be a regression for those users, when they try to migrate to new Bevy stageless, if they are missing.
I also took the opportunity to add a few more new ones.
---
## Changelog
### Added
- More "common run conditions": on_event, resource change detection, state_changed, any_with_component
# Objective
Fix#5026.
## Solution
Only make a `trace!` log if the event count changed.
---
## Changelog
Changed: `EventWriter::send_batch` will only log a TRACE level log if the batch is non-empty.
# Objective
Fix#7584.
## Solution
Add an abstraction for creating custom system combinators with minimal boilerplate. Use this to implement AND/OR combinators. Use this to simplify the implementation of `PipeSystem`.
## Example
Feel free to bikeshed on the syntax.
I chose the names `and_then`/`or_else` to emphasize the fact that these short-circuit, while I chose method syntax to empasize that the arguments are *not* treated equally.
```rust
app.add_systems((
my_system.run_if(resource_exists::<R>().and_then(resource_equals(R(0)))),
our_system.run_if(resource_exists::<R>().or_else(resource_exists::<S>())),
));
```
---
## Todo
- [ ] Decide on a syntax
- [x] Write docs
- [x] Write tests
## Changelog
+ Added the extension methods `.and_then(...)` and `.or_else(...)` to run conditions, which allows combining run conditions with short-circuiting behavior.
+ Added the trait `Combine`, which can be used with the new `CombinatorSystem` to create system combinators with custom behavior.
# Objective
- Fixes#7442.
## Solution
- Added `report_sets` option to `ScheduleBuildSettings` like described in the linked issue.
The output of the `3d_scene` example when reporting ambiguities with `report_sets` and `use_shortnames` set to `true` (and with #7755 applied) now looks like this:
```
82 pairs of systems with conflicting data access have indeterminate execution order. Consider adding `before`, `after`, or `ambiguous_with` relationships between these:
-- filesystem_watcher_system (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<DynamicScene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Scene> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Shader> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Mesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<SkinnedMeshInverseBindposes> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Image> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<TextureAtlas> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<ColorMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Font> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<FontAtlasSet> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<StandardMaterial> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<Gltf> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfNode> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfPrimitive> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<GltfMesh> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSource> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AudioSink> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- update_asset_storage_system<AnimationClip> (LoadAssets) and apply_system_buffers (FirstFlush)
conflict on: bevy_ecs::world::World
-- scene_spawner_system (Update) and close_when_requested (Update)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- exit_on_all_closed (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<Projection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<OrthographicProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (CalculateBoundsFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- camera_system<PerspectiveProjection> (CameraUpdateSystem, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- calculate_bounds (CalculateBounds, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and visibility_propagate_system (PostUpdate, VisibilityPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_text2d_layout (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and ui_stack_system (PostUpdate, Stack)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and text_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_image_calculated_size_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and flex_node_system (Flex, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and add_clusters (AddClusters, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (CalculateBoundsFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- visibility_propagate_system (PostUpdate, VisibilityPropagate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_text2d_layout (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- ui_stack_system (PostUpdate, Stack) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- text_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- update_image_calculated_size_system (PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and apply_system_buffers (AddClustersFlush, PostUpdate)
conflict on: bevy_ecs::world::World
-- flex_node_system (Flex, PostUpdate) and animation_player (PostUpdate)
conflict on: ["bevy_transform::components::transform::Transform"]
-- apply_system_buffers (AddClustersFlush, PostUpdate) and play_queued_audio_system<AudioSource> (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and animation_player (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and propagate_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and sync_simple_transforms (PostUpdate, TransformPropagate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_cascades (PostUpdate, UpdateDirectionalLightCascades)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_clipping_system (PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<Projection> (PostUpdate, UpdateProjectionFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<PerspectiveProjection> (PostUpdate, UpdatePerspectiveFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_frusta<OrthographicProjection> (PostUpdate, UpdateOrthographicFrusta)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and check_visibility (CheckVisibility, PostUpdate)
conflict on: bevy_ecs::world::World
-- apply_system_buffers (AddClustersFlush, PostUpdate) and update_directional_light_frusta (PostUpdate, UpdateLightFrusta)
conflict on: bevy_ecs::world::World
-- Assets<Scene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Shader>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Mesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<SkinnedMeshInverseBindposes>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Image>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<TextureAtlas>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<ColorMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Font>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<FontAtlasSet>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<StandardMaterial>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<Gltf>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfNode>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfPrimitive>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<GltfMesh>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSource>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AudioSink>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<AnimationClip>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
-- Assets<DynamicScene>::asset_event_system (AssetEvents) and apply_system_buffers (PostUpdateFlush)
conflict on: bevy_ecs::world::World
```
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Allow using `Local<WorldId>` in systems.
## Solution
- Describe the solution used to achieve the objective above.
---
## Changelog
+ `WorldId` now implements the `FromWorld` trait.
…top sort. reduce mem alloc
# Objective
- Reduce alloc count.
- Improve code quality.
## Solution
- use `TarjanScc::run` directly, which calls a closure with each scc, in closure, we can detect cycles and flatten nodes
# Objective
`ChangeTrackers<>` is a `WorldQuery` type that lets you access the change ticks for a component. #7097 has added `Ref<>`, which gives access to a component's value in addition to its change ticks. Since bevy's access model does not separate a component's value from its change ticks, there is no benefit to using `ChangeTrackers<T>` over `Ref<T>`.
## Solution
Deprecate `ChangeTrackers<>`.
---
## Changelog
* `ChangeTrackers<T>` has been deprecated. It will be removed in Bevy 0.11.
## Migration Guide
`ChangeTrackers<T>` has been deprecated, and will be removed in the next release. Any usage should be replaced with `Ref<T>`.
```rust
// Before (0.9)
fn my_system(q: Query<(&MyComponent, ChangeTrackers<MyComponent>)>) {
for (value, trackers) in &q {
if trackers.is_changed() {
// Do something with `value`.
}
}
}
// After (0.10)
fn my_system(q: Query<Ref<MyComponent>>) {
for value in &q {
if value.is_changed() {
// Do something with `value`.
}
}
}
```
# Objective
Fixes#7736
## Solution
Implement the `SystemParam` trait for `WorldId`
## Changelog
- `WorldId` can now be taken as a system parameter and will return the id of the world the system is running in
# Objective
- Fixes#7659.
## Solution
- This PR extracted the `distributive_run_if` part of #7676, because it does not require the controversial introduction of anonymous system sets.
- The distinctive name should make the user aware about the differences between `IntoSystemConfig::run_if` and `IntoSystemConfigs::distributive_run_if`.
- The documentation explains in detail the consequences of using the API and possible pit falls when using it.
- A test demonstrates the possibility of changing the condition result, resulting in some of the systems not being run.
---
## Changelog
### Added
- Add `distributive_run_if` to `IntoSystemConfigs` to enable adding a run condition to each system when using `add_systems`.
follow-up to https://github.com/bevyengine/bevy/pull/7716
# Objective
System access is only populated in `System::initialize`, so without calling `initialize` it's actually impossible to see most ambiguities.
## Solution
- make `initialize` public. The method is idempotent, so calling it multiple times doesn't hurt
# Objective
Continuation of https://github.com/bevyengine/bevy/pull/5719
Now that we have a definable type for the iterator.
---
## Changelog
- Implemented IntoIterator for EventReader so you can now do `&mut reader` instead of `reader.iter()` for events.
# Objective
Fix#7440. Fix#7441.
## Solution
* Remove builder functions on `ScheduleBuildSettings` in favor of public fields, move docs to the fields.
* Add `use_shortnames` and use it in `get_node_name` to feed it through `bevy_utils::get_short_name`.
# Objective
Web builds do not support running on multiple threads right now. Defaulting to the multi-threaded executor has significant overhead without any benefit.
## Solution
Default to the single threaded executor on wasm32 builds.
# Objective
- other tools (bevy_mod_debugdump) would like to have access to the ambiguities so that they can do their own reporting/visualization
## Solution
- store `conflicting_systems` in `ScheduleGraph` after calling `build_schedule`
The solution isn't very pretty and as pointed out it https://github.com/bevyengine/bevy/pull/7522, there may be a better way of exposing this, but this is the quick and dirty way if we want to have this functionality exposed in 0.10.
# Objective
- RemovedComponents is just a thin wrapper around Events/ManualEventReader which is the same as an EventReader, so most usecases that of an EventReader will probably be useful for RemovedComponents too.
I was thinking of making a trait for this but I don't think it is worth the overhead currently.
## Solution
- Mirror the api surface of EventReader
# Objective
Motivated by #7469.
`EventReader` iterators use the default implementations for `.nth()` and `.last()`, which includes iterating over and throwing out all events before the desired one.
## Solution
Add specialized implementations for these methods that directly updates the unread event counter and returns a reference to the desired event.
TODO:
- [x] Add a unit test.
- [x] ~~Add a benchmark, to see if the compiler was doing this automatically already.~~ *On second thought, this doesn't feel like a very useful thing to include in the benchmark suite.*
# Objective
- it would be nice to be able to associate a `NodeId` of a system type set to the `NodeId` of the actual system (used in bevy_mod_debugdump)
## Solution
- make `system_type` return the type id of the system
- that way you can check if a `dyn SystemSet` is the system type set of a `dyn System`
- I don't know if this information is already present somewhere else in the scheduler or if there is a better way to expose it
# Objective
Fixes#7702.
## Solution
- Added an test that ensures that no error is returned if a system or set is inside two different sets that share the same base set.
- Added an check to only return an error if the two base sets are not equal.
# Objective
The `ScheduleGraph` should be expose so that crates like [bevy_mod_debugdump](https://github.com/jakobhellermann/bevy_mod_debugdump/blob/stageless/docs/README.md) can access useful information.
## Solution
- expose `ScheduleGraph`, `NodeId`, `BaseSetMembership`, `Dag`
- add accessor functions for sets and systems
## Changelog
- expose `ScheduleGraph` for use in third party tools
This does expose our use of `petgraph` as a graph library, so we can only change that as a breaking change.
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
The trait `Condition<>` is implemented for any type that can be converted into a `ReadOnlySystem` which takes no inputs and returns a bool. However, due to the current implementation, consumers of the trait cannot rely on the fact that `<T as Condition>::System` implements `ReadOnlySystem`. In cases such as the `not` combinator (added in #7559), we are required to add redundant `T::System: ReadOnlySystem` trait bounds, even though this should be implied by the `Condition<>` trait.
## Solution
Add a hidden associated type which allows the compiler to figure out that the `System` associated type implements `ReadOnlySystem`.
…able like Table. Rename clear to clear_entities to clarify that metadata keeps, only value cleared
# Objective
- Provide some inspectability for SparseSets.
## Solution
- `Tables` has these three methods, len, is_empty and iter too. Add these methods to `SparseSets`, so user can print the shape of storage.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- Add `len`, `is_empty`, `iter` methods on SparseSets.
- Rename `clear` to `clear_entities` to clarify its purpose.
- Add `new_for_test` on `ComponentInfo` to make test code easy.
- Add test case covering new methods.
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- Simply adding new functionality is not a breaking change.
# Objective
This PR improves message that caused by duplicate components in bundle.
## Solution
Show names of duplicate components.
The solution is not very elegant, in my opinion, I will be happy to listen to suggestions for improving it
Co-authored-by: Саня Череп <41489405+SDesya74@users.noreply.github.com>
# Objective
While porting my crate `bevy_trait_query` to bevy 0.10, I ran into an issue with the `DetectChangesMut` trait. Due to the way that the `set_if_neq` method (added in #6853) is implemented, you are forced to write a nonsense implementation of it for dynamically sized types. This edge case shows up when implementing trait queries, since `DetectChangesMut` is implemented for `Mut<dyn Trait>`.
## Solution
Simplify the generics for `set_if_neq` and add the `where Self::Target: Sized` trait bound to it. Add a default implementation so implementers don't need to implement a method with nonsensical trait bounds.
# Objective
The `SystemParamFunction` (and `ExclusiveSystemParamFunction`) trait is very cumbersome to use, due to it requiring four generic type parameters. These are currently all used as marker parameters to satisfy rust's trait coherence rules.
### Example (before)
```rust
pub fn pipe<AIn, Shared, BOut, A, AParam, AMarker, B, BParam, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<AIn>, ParamSet<(AParam, BParam)>) -> BOut
where
A: SystemParamFunction<AIn, Shared, AParam, AMarker>,
B: SystemParamFunction<Shared, BOut, BParam, BMarker>,
AParam: SystemParam,
BParam: SystemParam,
```
## Solution
Turn the `In`, `Out`, and `Param` generics into associated types. Merge the marker types together to retain coherence.
### Example (after)
```rust
pub fn pipe<A, B, AMarker, BMarker>(
mut system_a: A,
mut system_b: B,
) -> impl FnMut(In<A::In>, ParamSet<(A::Param, B::Param)>) -> B::Out
where
A: SystemParamFunction<AMarker>,
B: SystemParamFunction<BMarker, In = A::Out>,
```
---
## Changelog
+ Simplified the `SystemParamFunction` and `ExclusiveSystemParamFunction` traits.
## Migration Guide
For users of the `SystemParamFunction` trait, the generic type parameters `In`, `Out`, and `Param` have been turned into associated types. The same has been done with the `ExclusiveSystemParamFunction` trait.
# Objective
- #6402 changed `World::fetch_table` (now `UnsafeWorldCell::fetch_table`) to access the archetype in order to get the `table_id` and `table_row` of the entity involved. However this is useless since those were already present in the `EntityLocation`
- Moreover it's useless for `UnsafeWorldCell::fetch_table` to return the `TableRow` too, since the caller must already have access to the `EntityLocation` which contains the `TableRow`.
- The result is that `UnsafeWorldCell::fetch_table` now only does 2 memory fetches instead of 4.
## Solution
- Revert the changes to the implementation of `UnsafeWorldCell::fetch_table` made in #6402
…u64, so hash safety is not a concern
# Objective
- While reading the code, just noticed the BundleInfo's HashMap is std::collections::HashMap, which uses a slow but safe hasher.
## Solution
- Use bevy_utils::HashMap instead
benchmark diff (I run several times in a linux box, the perf improvement is consistent, though numbers varies from time to time, I paste my last run result here):
``` bash
cargo bench -- spawn
Compiling bevy_ecs v0.9.0 (/home/lishuo/developer/pr/bevy/crates/bevy_ecs)
Compiling bevy_app v0.9.0 (/home/lishuo/developer/pr/bevy/crates/bevy_app)
Compiling benches v0.1.0 (/home/lishuo/developer/pr/bevy/benches)
Finished bench [optimized] target(s) in 1m 17s
Running benches/bevy_ecs/change_detection.rs (/home/lishuo/developer/pr/bevy/benches/target/release/deps/change_detection-86c5445d0dc34529)
Gnuplot not found, using plotters backend
Running benches/bevy_ecs/benches.rs (/home/lishuo/developer/pr/bevy/benches/target/release/deps/ecs-e49b3abe80bfd8c0)
Gnuplot not found, using plotters backend
spawn_commands/2000_entities
time: [153.94 µs 159.19 µs 164.37 µs]
change: [-14.706% -11.050% -6.9633%] (p = 0.00 < 0.05)
Performance has improved.
spawn_commands/4000_entities
time: [328.77 µs 339.11 µs 349.11 µs]
change: [-7.6331% -3.9932% +0.0487%] (p = 0.06 > 0.05)
No change in performance detected.
spawn_commands/6000_entities
time: [445.01 µs 461.29 µs 477.36 µs]
change: [-16.639% -13.358% -10.006%] (p = 0.00 < 0.05)
Performance has improved.
spawn_commands/8000_entities
time: [657.94 µs 677.71 µs 696.95 µs]
change: [-8.8708% -5.2591% -1.6847%] (p = 0.01 < 0.05)
Performance has improved.
get_or_spawn/individual time: [452.02 µs 466.70 µs 482.07 µs]
change: [-17.218% -14.041% -10.728%] (p = 0.00 < 0.05)
Performance has improved.
get_or_spawn/batched time: [291.12 µs 301.12 µs 311.31 µs]
change: [-12.281% -8.9163% -5.3660%] (p = 0.00 < 0.05)
Performance has improved.
spawn_world/1_entities time: [81.668 ns 84.284 ns 86.860 ns]
change: [-12.251% -6.7872% -1.5402%] (p = 0.02 < 0.05)
Performance has improved.
spawn_world/10_entities time: [789.78 ns 821.96 ns 851.95 ns]
change: [-19.738% -14.186% -8.0733%] (p = 0.00 < 0.05)
Performance has improved.
spawn_world/100_entities
time: [7.9906 µs 8.2449 µs 8.5013 µs]
change: [-12.417% -6.6837% -0.8766%] (p = 0.02 < 0.05)
Change within noise threshold.
spawn_world/1000_entities
time: [81.602 µs 84.161 µs 86.833 µs]
change: [-13.656% -8.6520% -3.0491%] (p = 0.00 < 0.05)
Performance has improved.
Found 1 outliers among 100 measurements (1.00%)
1 (1.00%) high mild
Benchmarking spawn_world/10000_entities: Warming up for 500.00 ms
Warning: Unable to complete 100 samples in 4.0s. You may wish to increase target time to 4.0s, enable flat sampling, or reduce sample count to 70.
spawn_world/10000_entities
time: [813.02 µs 839.76 µs 865.41 µs]
change: [-12.133% -6.1970% -0.2302%] (p = 0.05 < 0.05)
Change within noise threshold.
```
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- use bevy_utils::HashMap for Bundles::bundle_ids
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- Not a breaking change, hashmap is internal impl.
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
- Improve readability of the run condition for systems only running in a certain state
## Solution
- Rename `state_equals` to `in_state` (see [comment by cart](https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428740311) in #7634 )
- `.run_if(state_equals(variant))` now is `.run_if(in_state(variant))`
This breaks the naming pattern a bit with the related conditions `state_exists` and `state_exists_and_equals` but I could not think of better names for those and think the improved readability of `in_state` is worth it.
# Objective
Fixes#7632.
As discussed in #7634, it can be quite challenging for users to intuit the mental model of how states now work.
## Solution
Rather than change the behavior of the `OnUpdate` system set, instead work on making sure it's easy to understand what's going on.
Two things have been done:
1. Remove the `.on_update` method from our bevy of system building traits. This was special-cased and made states feel much more magical than they need to.
2. Improve the docs for the `OnUpdate` system set.
# Objective
- Fixes: #7187
Since avoiding the `SRes::into_inner` call does not seem to be possible, this PR tries to at least document its usage.
I am not sure if I explained the lifetime issue correctly, please let me know if something is incorrect.
## Solution
- Add information about the `SRes::into_inner` usage on both `RenderCommand` and `Res`
# Objective
Related to #7530.
`EventReader` iterators currently use the default impl for `.count()`, which unnecessarily loops over all unread events.
# Solution
Add specialized impls that mark the `EventReader` as consumed and return the number of unread events.
# Objective
Make the name less verbose without sacrificing clarity.
---
## Migration Guide
*Note for maintainers:* This PR has no breaking changes relative to bevy 0.9. Instead of this PR having its own migration guide, we should just edit the changelog for #6404.
The type `UnsafeWorldCellEntityRef` has been renamed to `UnsafeEntityCell`.
# Objective
Continuation of #7560.
`MutUntyped::last_changed` and `set_last_changed` do not behave as described in their docs.
## Solution
Fix them using the same approach that was used for `Mut<>` in #7560.
# Objective
Make `last_changed` behave as described in its docs.
## Solution
- Return `changed` instead of `last_change_tick`. `last_change_tick` is the system's previous tick and is just used for comparison.
- Update the docs of the similarly named `set_last_changed` (which does correctly interact with `last_change_tick`) to clarify that the two functions touch different data. (I advocate for renaming one or the other if anyone has any good suggestions).
It also might make sense to return a cloned `Tick` instead of `u32`.
---
## Changelog
- Fixed `DetectChanges::last_changed` returning the wrong value.
- Fixed `DetectChangesMut::set_last_changed` not actually updating the `changed` tick.
## Migration Guide
- The incorrect value that was being returned by `DetectChanges::last_changed` was the previous run tick of the system checking for changed values. If you depended on this value, you can get it from the `SystemChangeTick` `SystemParam` instead.
# Objective
Clarify what the function is actually calculating.
The `Tick::is_older_than` function is actually calculating whether the tick is newer than the system's `last_change_tick`, not older. As far as I can tell, the engine was using it correctly everywhere already.
## Solution
- Rename the function.
---
## Changelog
- `Tick::is_older_than` was renamed to `Tick::is_newer_than`. This is not a functional change, since that was what was always being calculated, despite the wrong name.
## Migration Guide
- Replace usages of `Tick::is_older_than` with `Tick::is_newer_than`.
# Objective
Closes#7202
## Solution
~~Introduce a `not` helper to pipe conditions. Opened mostly for discussion. Maybe create an extension trait with `not` method? Please, advice.~~
Introduce `not(condition)` condition that inverses the result of the passed.
---
## Changelog
### Added
- `not` condition.
Small commit to remove an unused resource scoped within a single bevy_ecs unit test. Also rearranged the initialization to follow initialization conventions of surrounding tests. World/Schedule initialization followed by resource initialization.
This change was tested locally with `cargo test`, and `cargo fmt` was run.
Risk should be tiny as change is scoped to a single unit test and very tiny, and I can't see any way that this resource is being used in the test.
Thank you so much!
# Objective
Run conditions are a special type of system that do not modify the world, and which return a bool. Due to the way they are currently implemented, you can *only* use bare function systems as a run condition. Among other things, this prevents the use of system piping with run conditions. This make very basic constructs impossible, such as `my_system.run_if(my_condition.pipe(not))`.
Unblocks a basic solution for #7202.
## Solution
Add the trait `ReadOnlySystem`, which is implemented for any system whose parameters all implement `ReadOnlySystemParam`. Allow any `-> bool` system implementing this trait to be used as a run condition.
---
## Changelog
+ Added the trait `ReadOnlySystem`, which is implemented for any `System` type whose parameters all implement `ReadOnlySystemParam`.
+ Added the function `bevy::ecs::system::assert_is_read_only_system`.
# Objective
Implementing `States` manually is repetitive, so let's not.
One thing I'm unsure of is whether the macro import statement is in the right place.
# Objective
One pattern to increase parallelism is deferred mutation: instead of directly mutating the world (and preventing other systems from running at the same time), you queue up operations to be applied to the world at the end of the stage. The most common example of this pattern uses the `Commands` SystemParam.
In order to avoid the overhead associated with commands, some power users may want to add their own deferred mutation behavior. To do this, you must implement the unsafe trait `SystemParam`, which interfaces with engine internals in a way that we'd like users to be able to avoid.
## Solution
Add the `Deferred<T>` primitive `SystemParam`, which encapsulates the deferred mutation pattern.
This can be combined with other types of `SystemParam` to safely and ergonomically create powerful custom types.
Essentially, this is just a variant of `Local<T>` which can run code at the end of the stage.
This type is used in the engine to derive `Commands` and `ParallelCommands`, which removes a bunch of unsafe boilerplate.
### Example
```rust
use bevy_ecs::system::{Deferred, SystemBuffer};
/// Sends events with a delay, but may run in parallel with other event writers.
#[derive(SystemParam)]
pub struct BufferedEventWriter<'s, E: Event> {
queue: Deferred<'s, EventQueue<E>>,
}
struct EventQueue<E>(Vec<E>);
impl<'s, E: Event> BufferedEventWriter<'s, E> {
/// Queues up an event to be sent at the end of this stage.
pub fn send(&mut self, event: E) {
self.queue.0.push(event);
}
}
// The `SystemBuffer` trait controls how [`Deferred`] gets applied at the end of the stage.
impl<E: Event> SystemBuffer for EventQueue<E> {
fn apply(&mut self, world: &mut World) {
let mut events = world.resource_mut::<Events<E>>();
for e in self.0.drain(..) {
events.send(e);
}
}
}
```
---
## Changelog
+ Added the `SystemParam` type `Deferred<T>`, which can be used to defer `World` mutations. Powered by the new trait `SystemBuffer`.
# Objective
- There is a small perf cost for starting the multithreaded executor.
## Solution
- We can skip that cost when there are zero systems in the schedule. Overall not a big perf boost unless there are a lot of empty schedules that are trying to run, but it is something.
Below is a tracy trace of the run_fixed_update_schedule for many_foxes which has zero systems in it. Yellow is main and red is this pr. The time difference between the peaks of the humps is around 15us.
# Objective
- Implementing logic used by system params and `UnsafeWorldCell` on `&World` is sus since `&World` generally denotes shared read only access to world but this is a lie in the above situations. Move most/all logic that uses `&World` to mean `UnsafeWorldCell` onto `UnsafeWorldCell`
- Add a way to take a `&mut World` out of `UnsafeWorldCell` and use this in `WorldCell`'s `Drop` impl instead of a `UnsafeCell` field
---
## Changelog
- changed some `UnsafeWorldCell` methods to take `self` instead of `&self`/`&mut self` since there is literally no point to them doing that
- `UnsafeWorldCell::world` is now used to get immutable access to the whole world instead of just the metadata which can now be done via `UnsafeWorldCell::world_metadata`
- `UnsafeWorldCell::world_mut` now exists and can be used to get a `&mut World` out of `UnsafeWorldCell`
- removed `UnsafeWorldCell::storages` since that is probably unsound since storages contains the actual component/resource data not just metadata
## Migration guide
N/A none of the breaking changes here make any difference for a 0.9->0.10 transition since `UnsafeWorldCell` did not exist in 0.9
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Currently exclusive systems and applying buffers run outside of the multithreaded executor and just calls the funtions on the thread the schedule is running on. Stageless changes this to run these using tasks in a scope. Specifically It uses `spawn_on_scope` to run these. For the render thread this is incorrect as calling `spawn_on_scope` there runs tasks on the main thread. It should instead run these on the render thread and only run nonsend systems on the main thread.
## Solution
- Add another executor to `Scope` for spawning tasks on the scope. `spawn_on_scope` now always runs the task on the thread the scope is running on. `spawn_on_external` spawns onto the external executor than is optionally passed in. If None is passed `spawn_on_external` will spawn onto the scope executor.
- Eventually this new machinery will be able to be removed. This will happen once a fix for removing NonSend resources from the world lands. So this is a temporary fix to support stageless.
---
## Changelog
- add a spawn_on_external method to allow spawning on the scope's thread or an external thread
## Migration Guide
> No migration guide. The main thread executor was introduced in pipelined rendering which was merged for 0.10. spawn_on_scope now behaves the same way as on 0.9.
# Objective
- Make the internals of `RemovedComponents` clearer
## Solution
- Add a wrapper around `Entity`, used in `RemovedComponents` as `Events<RemovedComponentsEntity>`
---
## Changelog
- `RemovedComponents` now internally uses an `Events<RemovedComponentsEntity>` instead of an `Events<Entity>`
The `DoubleEndedIterator` impls produce incorrect results on subsequent calls to `iter()` if the iterator is only partially consumed.
The following code shows what happens
```rust
fn next_back_is_bad() {
let mut events = Events::<TestEvent>::default();
events.send(TestEvent { i: 0 });
events.send(TestEvent { i: 1 });
events.send(TestEvent { i: 2 });
let mut reader = events.get_reader();
let mut iter = reader.iter(&events);
assert_eq!(iter.next_back(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), Some(&TestEvent { i: 0 }));
let mut iter = reader.iter(&events);
// `i: 2` event is returned twice! The `i: 1` event is missed.
assert_eq!(iter.next(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), None);
}
```
I don't think this can be fixed without adding some very convoluted bookkeeping.
## Migration Guide
`ManualEventIterator` and `ManualEventIteratorWithId` are no longer `DoubleEndedIterator`s.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Removal events are unwieldy and require some knowledge of when to put systems that need to catch events for them, it is very easy to end up missing one and end up with memory leak-ish issues where you don't clean up after yourself.
## Solution
Consolidate removals with the benefits of `Events<...>` (such as double buffering and per system ticks for reading the events) and reduce the special casing of it, ideally I was hoping to move the removals to a `Resource` in the world, but that seems a bit more rough to implement/maintain because of double mutable borrowing issues.
This doesn't go the full length of change detection esque removal detection a la https://github.com/bevyengine/rfcs/pull/44.
Just tries to make the current workflow a bit more user friendly so detecting removals isn't such a scheduling nightmare.
---
## Changelog
- RemovedComponents<T> is now backed by an `Events<Entity>` for the benefits of double buffering.
## Migration Guide
- Add a `mut` for `removed: RemovedComponents<T>` since we are now modifying an event reader internally.
- Iterating over removed components now requires `&mut removed_components` or `removed_components.iter()` instead of `&removed_components`.
# Objective
The trait method `SystemParam::apply` allows a `SystemParam` type to defer world mutations, which is internally used to apply `Commands` at the end of the stage. Any operations that require `&mut World` access must be deferred in this way, since parallel systems do not have exclusive access to the world.
The `ExclusiveSystemParam` trait (added in #6083) has an `apply` method which serves the same purpose. However, deferring mutations in this way does not make sense for exclusive systems since they already have `&mut World` access: there is no need to wait until a hard sync point, as the system *is* a hard sync point. World mutations can and should be performed within the body of the system.
## Solution
Remove the method. There were no implementations of this method in the engine.
---
## Changelog
*Note for maintainers: this changelog makes more sense if it's placed above the one for #6919.*
- Removed the method `ExclusiveSystemParamState::apply`.
## Migration Guide
*Note for maintainers: this migration guide makes more sense if it's placed above the one for #6919.*
The trait method `ExclusiveSystemParamState::apply` has been removed. If you have an exclusive system with buffers that must be applied, you should apply them within the body of the exclusive system.
# Objective
Fixes#7434.
This is my first time contributing to a Rust project, so please let me know if this wasn't the change intended by the linked issue.
## Solution
Adds a test with a system that panics to `bevy_ecs`.
I'm not sure if this is the intended panic message, but this is what the test currently results in:
```
thread 'system::tests::panic_inside_system' panicked at 'called `Option::unwrap()` on a `None` value', /Users/bjorn/workplace/bevy/crates/bevy_tasks/src/task_pool.rs:354:49
```
# Objective
Fix#7447.
The `SystemParam` derive uses the wrong lifetimes for ignored fields.
## Solution
Use type inference instead of explicitly naming the types of ignored fields. This allows the compiler to automatically use the correct lifetime.
# Objective
- Fix panic_when_hierachy_cycle test hanging
- The problem is that the scope only awaits one task at a time in get_results. In stageless this task is the multithreaded executor. That tasks hangs when a system panics and cannot make anymore progress. This wasn't a problem before because the executor was spawned after all the system tasks had been spawned. But in stageless the executor is spawned before all the system tasks are spawned.
## Solution
- We can catch unwind on each system and close the finish channel if one panics. This then causes the receiver end of the finish channel to panic too.
- this might have a small perf impact, but when running many_foxes it seems to be within the noise. So less than 40us.
## Other possible solutions
- It might be possible to fairly poll all the tasks in get_results in the scope. If we could do that then the scope could panic whenever one of tasks panics. It would require a data structure that we could both poll the futures through a shared ref and also push to it. I tried FuturesUnordered, but it requires an exclusive ref to poll it.
- The catch unwind could be moved onto when we create the tasks for scope instead. We would then need something like a oneshot async channel to inform get_results if a task panics.
# Objective
Ability to use `ReflectComponent` methods in dynamic type contexts with no access to `&World`.
This problem occurred to me when wanting to apply reflected types to an entity where the `&World` reference was already consumed by query iterator leaving only `EntityMut`.
## Solution
- Remove redundant `EntityMut` or `EntityRef` lookup from `World` and `Entity` in favor of taking `EntityMut` directly in `ReflectComponentFns`.
- Added `RefectComponent::contains` to determine without panic whether `apply` can be used.
## Changelog
- Changed function signatures of `ReflectComponent` methods, `apply`, `remove`, `contains`, and `reflect`.
## Migration Guide
- Call `World::entity` before calling into the changed `ReflectComponent` methods, most likely user already has a `EntityRef` or `EntityMut` which was being queried redundantly.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
- After the multithreaded executor finishes running all the systems, we apply the buffers for any system that hasn't applied it's buffers. This is a courtesy apply for users who forget to order their systems before a apply_system_buffers. When checking stageless, it was found that this apply_system_buffers was running on the executor thread instead of the world's thread. This is a problem because anything with world access should be able to access nonsend resources.
## Solution
- Move the final apply_system_buffers outside of the executor and outside of the scope, so it runs on the same thread that schedule.run is called on.
# Objective
- The stageless executor keeps track of systems that have run, but have not applied their system buffers. The bitset for that was being cloned into apply_system_buffers and cleared in that function, but we need to clear the original version instead of the cloned version
## Solution
- move the clear out of the apply_system_buffers function.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Clearing the reader doesn't require iterating the events. Updating the `last_event_count` of the reader is enough.
I rewrote part of the documentation as some of it was incorrect or harder to understand than necessary.
## Changelog
Added `ManualEventReader::clear()`
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Found while working on #7385.
The struct `EntityMut` has the safety invariant that it's cached `EntityLocation` must always accurately specify where the entity is stored. Thus, any time its location might be invalidated (such as by calling `EntityMut::world_mut` and moving archetypes), the cached location *must* be updated by calling `EntityMut::update_location`.
The method `world_scope` encapsulates this pattern in safe API by requiring world mutations to be done in a closure, after which `update_location` will automatically be called. However, this method has a soundness hole: if a panic occurs within the closure, then `update_location` will never get called. If the panic is caught in an outer scope, then the `EntityMut` will be left with an outdated location, which is undefined behavior.
An example of this can be seen in the unit test `entity_mut_world_scope_panic`, which has been added to this PR as a regression test. Without the other changes in this PR, that test will invoke undefined behavior in safe code.
## Solution
Call `EntityMut::update_location()` from within a `Drop` impl, which ensures that it will get executed even if `EntityMut::world_scope` unwinds.
# Objective
The function `EntityMut::world_scope` is a safe abstraction that allows you to temporarily get mutable access to the underlying `World` of an `EntityMut`. This function is purely stateful, meaning it is not easily possible to return a value from it.
## Solution
Allow returning a computed value from the closure. This is similar to how `World::resource_scope` works.
---
## Changelog
- The function `EntityMut::world_scope` now allows returning a value from the immediately-computed closure.
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
alternative to #5922, implements #5956
builds on top of https://github.com/bevyengine/bevy/pull/6402
# Objective
https://github.com/bevyengine/bevy/issues/5956 goes into more detail, but the TLDR is:
- bevy systems ensure disjoint accesses to resources and components, and for that to work there are methods `World::get_resource_unchecked_mut(&self)`, ..., `EntityRef::get_mut_unchecked(&self)` etc.
- we don't have these unchecked methods for `by_id` variants, so third-party crate authors cannot build their own safe disjoint-access abstractions with these
- having `_unchecked_mut` methods is not great, because in their presence safe code can accidentally violate subtle invariants. Having to go through `world.as_unsafe_world_cell().unsafe_method()` forces you to stop and think about what you want to write in your `// SAFETY` comment.
The alternative is to keep exposing `_unchecked_mut` variants for every operation that we want third-party crates to build upon, but we'd prefer to avoid using these methods alltogether: https://github.com/bevyengine/bevy/pull/5922#issuecomment-1241954543
Also, this is something that **cannot be implemented outside of bevy**, so having either this PR or #5922 as an escape hatch with lots of discouraging comments would be great.
## Solution
- add `UnsafeWorldCell` with `unsafe fn get_resource(&self)`, `unsafe fn get_resource_mut(&self)`
- add `fn World::as_unsafe_world_cell(&mut self) -> UnsafeWorldCell<'_>` (and `as_unsafe_world_cell_readonly(&self)`)
- add `UnsafeWorldCellEntityRef` with `unsafe fn get`, `unsafe fn get_mut` and the other utilities on `EntityRef` (no methods for spawning, despawning, insertion)
- use the `UnsafeWorldCell` abstraction in `ReflectComponent`, `ReflectResource` and `ReflectAsset`, so these APIs are easier to reason about
- remove `World::get_resource_mut_unchecked`, `EntityRef::get_mut_unchecked` and use `unsafe { world.as_unsafe_world_cell().get_mut() }` and `unsafe { world.as_unsafe_world_cell().get_entity(entity)?.get_mut() }` instead
This PR does **not** make use of `UnsafeWorldCell` for anywhere else in `bevy_ecs` such as `SystemParam` or `Query`. That is a much larger change, and I am convinced that having `UnsafeWorldCell` is already useful for third-party crates.
Implemented API:
```rust
struct World { .. }
impl World {
fn as_unsafe_world_cell(&self) -> UnsafeWorldCell<'_>;
}
struct UnsafeWorldCell<'w>(&'w World);
impl<'w> UnsafeWorldCell {
unsafe fn world(&self) -> &World;
fn get_entity(&self) -> UnsafeWorldCellEntityRef<'w>; // returns 'w which is `'self` of the `World::as_unsafe_world_cell(&'w self)`
unsafe fn get_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_resource_by_id(&self, ComponentId) -> Option<&'w T>;
unsafe fn get_resource_mut<T>(&self) -> Option<Mut<'w, T>>;
unsafe fn get_resource_mut_by_id(&self) -> Option<MutUntyped<'w>>;
unsafe fn get_non_send_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_non_send_resource_mut<T>(&self) -> Option<Mut<'w, T>>>;
// not included: remove, remove_resource, despawn, anything that might change archetypes
}
struct UnsafeWorldCellEntityRef<'w> { .. }
impl UnsafeWorldCellEntityRef<'w> {
unsafe fn get<T>(&self, Entity) -> Option<&'w T>;
unsafe fn get_by_id(&self, Entity, ComponentId) -> Option<Ptr<'w>>;
unsafe fn get_mut<T>(&self, Entity) -> Option<Mut<'w, T>>;
unsafe fn get_mut_by_id(&self, Entity, ComponentId) -> Option<MutUntyped<'w>>;
unsafe fn get_change_ticks<T>(&self, Entity) -> Option<Mut<'w, T>>;
// fn id, archetype, contains, contains_id, containts_type_id
}
```
<details>
<summary>UnsafeWorldCell docs</summary>
Variant of the [`World`] where resource and component accesses takes a `&World`, and the responsibility to avoid
aliasing violations are given to the caller instead of being checked at compile-time by rust's unique XOR shared rule.
### Rationale
In rust, having a `&mut World` means that there are absolutely no other references to the safe world alive at the same time,
without exceptions. Not even unsafe code can change this.
But there are situations where careful shared mutable access through a type is possible and safe. For this, rust provides the [`UnsafeCell`](std::cell::UnsafeCell)
escape hatch, which allows you to get a `*mut T` from a `&UnsafeCell<T>` and around which safe abstractions can be built.
Access to resources and components can be done uniquely using [`World::resource_mut`] and [`World::entity_mut`], and shared using [`World::resource`] and [`World::entity`].
These methods use lifetimes to check at compile time that no aliasing rules are being broken.
This alone is not enough to implement bevy systems where multiple systems can access *disjoint* parts of the world concurrently. For this, bevy stores all values of
resources and components (and [`ComponentTicks`](crate::component::ComponentTicks)) in [`UnsafeCell`](std::cell::UnsafeCell)s, and carefully validates disjoint access patterns using
APIs like [`System::component_access`](crate::system::System::component_access).
A system then can be executed using [`System::run_unsafe`](crate::system::System::run_unsafe) with a `&World` and use methods with interior mutability to access resource values.
access resource values.
### Example Usage
[`UnsafeWorldCell`] can be used as a building block for writing APIs that safely allow disjoint access into the world.
In the following example, the world is split into a resource access half and a component access half, where each one can
safely hand out mutable references.
```rust
use bevy_ecs::world::World;
use bevy_ecs::change_detection::Mut;
use bevy_ecs::system::Resource;
use bevy_ecs::world::unsafe_world_cell_world::UnsafeWorldCell;
// INVARIANT: existance of this struct means that users of it are the only ones being able to access resources in the world
struct OnlyResourceAccessWorld<'w>(UnsafeWorldCell<'w>);
// INVARIANT: existance of this struct means that users of it are the only ones being able to access components in the world
struct OnlyComponentAccessWorld<'w>(UnsafeWorldCell<'w>);
impl<'w> OnlyResourceAccessWorld<'w> {
fn get_resource_mut<T: Resource>(&mut self) -> Option<Mut<'w, T>> {
// SAFETY: resource access is allowed through this UnsafeWorldCell
unsafe { self.0.get_resource_mut::<T>() }
}
}
// impl<'w> OnlyComponentAccessWorld<'w> {
// ...
// }
// the two interior mutable worlds borrow from the `&mut World`, so it cannot be accessed while they are live
fn split_world_access(world: &mut World) -> (OnlyResourceAccessWorld<'_>, OnlyComponentAccessWorld<'_>) {
let resource_access = OnlyResourceAccessWorld(unsafe { world.as_unsafe_world_cell() });
let component_access = OnlyComponentAccessWorld(unsafe { world.as_unsafe_world_cell() });
(resource_access, component_access)
}
```
</details>
# Objective
`add_system(system)` without any `.in_set` configuration should land in `CoreSet::Update`.
We check that the sets are empty, but for systems there is always the `SystemTypeset`.
## Solution
- instead of `is_empty()`, check that the only set it the `SystemTypeSet`
# Objective
`bevy_ecs/system_param.rs` contains many seemingly-arbitrary struct definitions which serve as compile tests.
## Solution
Add a comment to each one, linking the issue or PR that motivated its addition.
# Objective
- `Components::resource_id` doesn't exist. Like `Components::component_id` but for resources.
## Solution
- Created `Components::resource_id` and added some docs.
---
## Changelog
- Added `Components::resource_id`.
- Changed `World::init_resource` to return the generated `ComponentId`.
- Changed `World::init_non_send_resource` to return the generated `ComponentId`.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
- Safety comments for the `CommandQueue` type are quite sparse and very imprecise. Sometimes, they are right for the wrong reasons or use circular reasoning.
## Solution
- Document previously-implicit safety invariants.
- Rewrite safety comments to actually reflect the specific invariants of each operation.
- Use `OwningPtr` instead of raw pointers, to encode an invariant in the type system instead of via comments.
- Use typed pointer methods when possible to increase reliability.
---
## Changelog
+ Added the function `OwningPtr::read_unaligned`.
# Objective
Repeated calls to `init_non_send_resource` currently overwrite the old value because the wrong storage is being checked.
## Solution
Use the correct storage. Add some tests.
## Notes
Without the fix, the new test fails with
```
thread 'world::tests::init_non_send_resource_does_not_overwrite' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `0`', crates/bevy_ecs/src/world/mod.rs:2267:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test world::tests::init_non_send_resource_does_not_overwrite ... FAILED
```
This was introduced by #7174 and it seems like a fairly straightforward oopsie.
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes#7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
Fix#5248.
## Solution
Support `In<T>` parameters and allow returning arbitrary types in exclusive systems.
---
## Changelog
- Exclusive systems may now be used with system piping.
## Migration Guide
Exclusive systems (systems that access `&mut World`) now support system piping, so the `ExclusiveSystemParamFunction` trait now has generics for the `In`put and `Out`put types.
```rust
// Before
fn my_generic_system<T, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<Param>
{ ... }
// After
fn my_generic_system<T, In, Out, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<In, Out, Param>
{ ... }
```
# Objective
There are some utility functions for actually working with `Storages` inside `entity_ref.rs` that are used both for `EntityRef/EntityMut` and `World`, with a `// TODO: move to Storages`.
This PR moves them to private methods on `World`, because that's the safest API boundary. On `Storages` you would need to ensure that you pass `Components` from the same world.
## Solution
- move get_component[_with_type], get_ticks[_with_type], get_component_and_ticks[_with_type] to `World` (still pub(crate))
- replace `pub use entity_ref::*;` with `pub use entity_ref::{EntityRef, EntityMut}` and qualified `entity_ref::get_mut[_by_id]` in `world.rs`
- add safety comments to a bunch of methods
# Objective
* `World::init_resource` and `World::get_resource_or_insert_with` are implemented naively, and as such they perform duplicate `TypeId -> ComponentId` lookups.
* `World::get_resource_or_insert_with` contains an additional duplicate `ComponentId -> ResourceData` lookup.
* This function also contains an unnecessary panic branch, which we rely on the optimizer to be able to remove.
## Solution
Implement the functions using engine-internal code, instead of combining high-level functions. This allows computed variables to persist across different branches, instead of being recomputed.
# Objective
Following #6681, both `TableRow` and `TableId` are now part of `EntityLocation`. However, the safety invariant on `EntityLocation` requires that all of the constituent fields are `repr(transprent)` or `repr(C)` and the bit pattern of all 1s must be valid. This is not true for `TableRow` and `TableId` currently.
## Solution
Mark `TableRow` and `TableId` to satisfy the safety requirement. Add safety comments on `ArchetypeId`, `ArchetypeRow`, `TableId` and `TableRow`.
# Objective
Improve safety testing when using `bevy_ptr` types. This is a follow-up to #7113.
## Solution
Add a debug-only assertion that pointers are aligned when casting to a concrete type. This should very quickly catch any unsoundness from unaligned pointers, even without miri. However, this can have a large negative perf impact on debug builds.
---
## Changelog
Added: `Ptr::deref` will now panic in debug builds if the pointer is not aligned.
Added: `PtrMut::deref_mut` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::read` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::drop_as` will now panic in debug builds if the pointer is not aligned.
# Objective
`MutUntyped` is a struct that stores a `PtrMut` alongside change tick metadata. Working with this type is cumbersome, and has few benefits over storing the pointer and change ticks separately.
Related: #6430 (title is out of date)
## Solution
Add a convenience method for transforming an untyped change detection pointer into its typed counterpart.
---
## Changelog
- Added the method `MutUntyped::with_type`.
# Objective
- Fixes#7066
## Solution
- Split the ChangeDetection trait into ChangeDetection and ChangeDetectionMut
- Added Ref as equivalent to &T with change detection
---
## Changelog
- Support for Ref which allow inspecting change detection flags in an immutable way
## Migration Guide
- While bevy prelude includes both ChangeDetection and ChangeDetectionMut any code explicitly referencing ChangeDetection might need to be updated to ChangeDetectionMut or both. Specifically any reading logic requires ChangeDetection while writes requires ChangeDetectionMut.
use bevy_ecs::change_detection::DetectChanges -> use bevy_ecs::change_detection::{DetectChanges, DetectChangesMut}
- Previously Res had methods to access change detection `is_changed` and `is_added` those methods have been moved to the `DetectChanges` trait. If you are including bevy prelude you will have access to these types otherwise you will need to `use bevy_ecs::change_detection::DetectChanges` to continue using them.
`Query`'s fields being `pub(crate)` means that the struct can be constructed via safe code from anywhere in `bevy_ecs` . This is Not Good since it is intended that all construction of this type goes through `Query::new` which is an `unsafe fn` letting various `Query` methods rely on those invariants holding even though they can be trivially bypassed.
This has no user facing impact
# Objective
- Fix#7103.
- The issue is caused because I forgot to add a where clause to a generated struct in #7056.
## Solution
- Add the where clause.
`Query` relies on the `World` it stores being the same as the world used for creating the `QueryState` it stores. If they are not the same then everything is very unsound. This was not actually being checked anywhere, `Query::new` did not have a safety invariant or even an assertion that the `WorldId`'s are the same.
This shouldn't have any user facing impact unless we have really messed up in bevy and have unsoundness elsewhere (in which case we would now get a panic instead of being unsound).
# Objective
- In some cases, you need a `Mut<T>` pointer, but you only have a mutable reference to one. There is no easy way of converting `&'a mut Mut<'_, T>` -> `Mut<'a, T>` outside of the engine.
### Example (Before)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// The function expects a `Mut<T>`, so `x` gets moved here.
do_with_mut(x);
// Error: use of moved value.
do_a_thing(&x);
}
```
## Solution
- Add the function `reborrow`, which performs the mapping. This is analogous to `PtrMut::reborrow`.
### Example (After)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// We reborrow `x`, so the original does not get moved.
do_with_mut(x.reborrow());
// Works fine.
do_a_thing(&x);
}
```
---
## Changelog
- Added the method `reborrow` to `Mut`, `ResMut`, `NonSendMut`, and `MutUntyped`.
# Objective
The type `Local<T>` unnecessarily has the bound `T: Sync` when the local is used in an exclusive system.
## Solution
Lift the bound.
---
## Changelog
Removed the bound `T: Sync` from `Local<T>` when used as an `ExclusiveSystemParam`.
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
- This pulls out some of the changes to Plugin setup and sub apps from #6503 to make that PR easier to review.
- Separate the extract stage from running the sub app's schedule to allow for them to be run on separate threads in the future
- Fixes#6990
## Solution
- add a run method to `SubApp` that runs the schedule
- change the name of `sub_app_runner` to extract to make it clear that this function is only for extracting data between the main app and the sub app
- remove the extract stage from the sub app schedule so it can be run separately. This is done by adding a `setup` method to the `Plugin` trait that runs after all plugin build methods run. This is required to allow the extract stage to be removed from the schedule after all the plugins have added their systems to the stage. We will also need the setup method for pipelined rendering to setup the render thread. See e3267965e1/crates/bevy_render/src/pipelined_rendering.rs (L57-L98)
## Changelog
- Separate SubApp Extract stage from running the sub app schedule.
## Migration Guide
### SubApp `runner` has conceptually been changed to an `extract` function.
The `runner` no longer is in charge of running the sub app schedule. It's only concern is now moving data between the main world and the sub app. The `sub_app.app.schedule` is now run for you after the provided function is called.
```rust
// before
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
render_app.app.schedule.run();
});
}
// after
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
// schedule is automatically called for you after extract is run
});
}
```
Spiritual successor to #5205.
Actual successor to #6865.
# Objective
Currently, system params are defined using three traits: `SystemParam`, `ReadOnlySystemParam`, `SystemParamState`. The behavior for each param is specified by the `SystemParamState` trait, while `SystemParam` simply defers to the state.
Splitting the traits in this way makes it easier to implement within macros, but it increases the cognitive load. Worst of all, this approach requires each `MySystemParam` to have a public `MySystemParamState` type associated with it.
## Solution
* Merge the trait `SystemParamState` into `SystemParam`.
* Remove all trivial `SystemParam` state types.
* `OptionNonSendMutState<T>`: you will not be missed.
---
- [x] Fix/resolve the remaining test failure.
## Changelog
* Removed the trait `SystemParamState`, merging its functionality into `SystemParam`.
## Migration Guide
**Note**: this should replace the migration guide for #6865.
This is relative to Bevy 0.9, not main.
The traits `SystemParamState` and `SystemParamFetch` have been removed, and their functionality has been transferred to `SystemParam`.
```rust
// Before (0.9)
impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
}
unsafe impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
unsafe impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(&mut self, ...) -> Self::Item;
}
unsafe impl ReadOnlySystemParamFetch for MyParamState { }
// After (0.10)
unsafe impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
type Item<'w, 's> = MyParam<'w, 's>;
fn init_state(world: &mut World, system_meta: &mut SystemMeta) -> Self::State { ... }
fn get_param<'w, 's>(state: &mut Self::State, ...) -> Self::Item<'w, 's>;
}
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> { }
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> {}
```
# Objective
- The doctest for `Mut::map_unchanged` uses a fake function `set_if_not_equal` to demonstrate usage.
- Now that #6853 has been merged, we can use `Mut::set_if_neq` directly instead of mocking it.
# Objective
`SystemParam` `Local`s documentation currently leaves out information that should be documented.
- What happens when multiple `SystemParam`s within the same system have the same `Local` type.
- What lifetime parameter is expected by `Local`.
## Solution
- Added sentences to documentation to communicate this information.
- Renamed `Local` lifetimes in code to `'s` where they previously were not. Users can get complicated incorrect suggested fixes if they pass the wrong lifetime. Some instance of the code had `'w` indicating the expected lifetime might not have been known to those that wrote the code either.
Co-authored-by: iiYese <83026177+iiYese@users.noreply.github.com>
# Objective
- Fix#4200
Currently, `#[derive(SystemParam)]` publicly exposes each field type, which makes it impossible to encapsulate private fields.
## Solution
Previously, the fields were leaked because they were used as an input generic type to the macro-generated `SystemParam::State` struct. That type has been changed to store its state in a field with a specific type, instead of a generic type.
---
## Changelog
- Fixed a bug that caused `#[derive(SystemParam)]` to leak the types of private fields.
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
Bevy uses custom `Ptr` types so the rust borrow checker can help ensure lifetimes are correct, even when types aren't known. However, these types don't benefit from the automatic lifetime coercion regular rust references enjoy
## Solution
Add a couple methods to Ptr, PtrMut, and MutUntyped to allow for easy usage of these types in more complex scenarios.
## Changelog
- Added `as_mut` and `as_ref` methods to `MutUntyped`.
- Added `shrink` and `as_ref` methods to `PtrMut`.
## Migration Guide
- `MutUntyped::into_inner` now marks things as changed.
# Objective
Resolve#6156.
The most common type of command is one that runs for a single entity. Built-in commands like this can be ergonomically added to the command queue using the `EntityCommands` struct. However, adding custom entity commands to the queue is quite cumbersome. You must first spawn an entity, store its ID in a local, then construct a command using that ID and add it to the queue. This prevents method chaining, which is the main benefit of using `EntityCommands`.
### Example (before)
```rust
struct MyCustomCommand(Entity);
impl Command for MyCustomCommand { ... }
let id = commands.spawn((...)).id();
commmands.add(MyCustomCommand(id));
```
## Solution
Add the `EntityCommand` trait, which allows directly adding per-entity commands to the `EntityCommands` struct.
### Example (after)
```rust
struct MyCustomCommand;
impl EntityCommand for MyCustomCommand { ... }
commands.spawn((...)).add(MyCustomCommand);
```
---
## Changelog
- Added the trait `EntityCommand`. This is a counterpart of `Command` for types that execute code for a single entity.
## Future Work
If we feel its necessary, we can simplify built-in commands (such as `Despawn`) to use this trait.
# Objective
Any closure with the signature `FnOnce(&mut World)` implicitly implements the trait `Command` due to a blanket implementation. However, this implementation unnecessarily has the `Sync` bound, which limits the types that can be used.
## Solution
Remove the bound.
---
## Changelog
- `Command` closures no longer need to implement the marker trait `std::marker::Sync`.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}