mirror of
https://github.com/bevyengine/bevy
synced 2025-01-08 11:18:55 +00:00
6 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
04aedf12fa
|
optimize batch_and_prepare_render_phase (#11323)
# Objective - since #9685 ,bevy introduce automatic batching of draw commands, - `batch_and_prepare_render_phase` take the responsibility for batching `phaseItem`, - `GetBatchData` trait is used for indentify each phaseitem how to batch. it defines a associated type `Data `used for Query to fetch data from world. - however,the impl of `GetBatchData ` in bevy always set ` type Data=Entity` then we acually get following code `let entity:Entity =query.get(item.entity())` that cause unnecessary overhead . ## Solution - remove associated type `Data ` and `Filter` from `GetBatchData `, - change the type of the `query_item ` parameter in get_batch_data from` Self::Data` to `Entity`. - `batch_and_prepare_render_phase ` no longer takes a query using `F::Data, F::Filter` - `get_batch_data `now returns `Option<(Self::BufferData, Option<Self::CompareData>)>` --- ## Performance based in main merged with #11290 Window 11 ,Intel 13400kf, NV 4070Ti  frame time from 3.34ms to 3 ms, ~ 10% 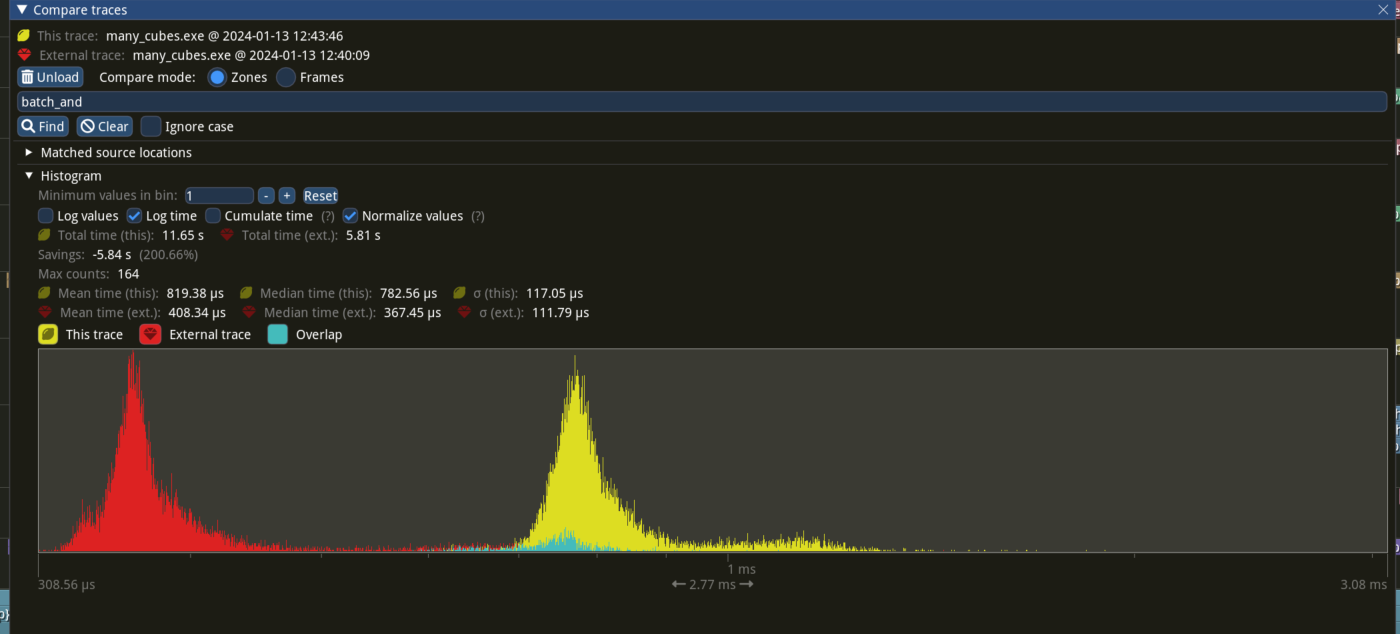 `batch_and_prepare_render_phase` from 800us ~ 400 us ## Migration Guide trait `GetBatchData` no longer hold associated type `Data `and `Filter` `get_batch_data` `query_item `type from `Self::Data` to `Entity` and return `Option<(Self::BufferData, Option<Self::CompareData>)>` `batch_and_prepare_render_phase` should not have a query |
||
|
|
5af2f022d8
|
Rename WorldQueryData & WorldQueryFilter to QueryData & QueryFilter (#10779)
# Rename `WorldQueryData` & `WorldQueryFilter` to `QueryData` & `QueryFilter` Fixes #10776 ## Solution Traits `WorldQueryData` & `WorldQueryFilter` were renamed to `QueryData` and `QueryFilter`, respectively. Related Trait types were also renamed. --- ## Changelog - Trait `WorldQueryData` has been renamed to `QueryData`. Derive macro's `QueryData` attribute `world_query_data` has been renamed to `query_data`. - Trait `WorldQueryFilter` has been renamed to `QueryFilter`. Derive macro's `QueryFilter` attribute `world_query_filter` has been renamed to `query_filter`. - Trait's `ExtractComponent` type `Query` has been renamed to `Data`. - Trait's `GetBatchData` types `Query` & `QueryFilter` has been renamed to `Data` & `Filter`, respectively. - Trait's `ExtractInstance` type `Query` has been renamed to `Data`. - Trait's `ViewNode` type `ViewQuery` has been renamed to `ViewData`. - Trait's `RenderCommand` types `ViewWorldQuery` & `ItemWorldQuery` has been renamed to `ViewData` & `ItemData`, respectively. ## Migration Guide Note: if merged before 0.13 is released, this should instead modify the migration guide of #10776 with the updated names. - Rename `WorldQueryData` & `WorldQueryFilter` trait usages to `QueryData` & `QueryFilter` and their respective derive macro attributes `world_query_data` & `world_query_filter` to `query_data` & `query_filter`. - Rename the following trait type usages: - Trait's `ExtractComponent` type `Query` to `Data`. - Trait's `GetBatchData` type `Query` to `Data`. - Trait's `ExtractInstance` type `Query` to `Data`. - Trait's `ViewNode` type `ViewQuery` to `ViewData`' - Trait's `RenderCommand` types `ViewWolrdQuery` & `ItemWorldQuery` to `ViewData` & `ItemData`, respectively. ```rust // Before #[derive(WorldQueryData)] #[world_query_data(derive(Debug))] struct EmptyQuery { empty: (), } // After #[derive(QueryData)] #[query_data(derive(Debug))] struct EmptyQuery { empty: (), } // Before #[derive(WorldQueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // After #[derive(QueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // Before impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Query = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Query>) -> Option<Self::Out> { //... } } // After impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Data = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Data>) -> Option<Self::Out> { //... } } // Before impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Query = Entity; type QueryFilter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Query>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // After impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Data = Entity; type Filter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Data>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // Before impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Query = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Query>) -> Option<Self> { Some(item.id()) } } // After impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Data = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Data>) -> Option<Self> { Some(item.id()) } } // Before impl ViewNode for PostProcessNode { type ViewQuery = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewQuery>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // After impl ViewNode for PostProcessNode { type ViewData = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewData>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // Before impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewWorldQuery = (); type ItemWorldQuery = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } // After impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewData = (); type ItemData = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } ``` |
||
|
|
f0a8994f55
|
Split WorldQuery into WorldQueryData and WorldQueryFilter (#9918)
# Objective - Fixes #7680 - This is an updated for https://github.com/bevyengine/bevy/pull/8899 which had the same objective but fell a long way behind the latest changes ## Solution The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter : WorldQuery` have been added and some of the types and functions from `WorldQuery` has been moved into them. `ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`. `WorldQueryFilter` is safe (as long as `WorldQuery` is implemented safely). `WorldQueryData` is unsafe - safely implementing it requires that `Self::ReadOnly` is a readonly version of `Self` (this used to be a safety requirement of `WorldQuery`) The type parameters `Q` and `F` of `Query` must now implement `WorldQueryData` and `WorldQueryFilter` respectively. This makes it impossible to accidentally use a filter in the data position or vice versa which was something that could lead to bugs. ~~Compile failure tests have been added to check this.~~ It was previously sometimes useful to use `Option<With<T>>` in the data position. Use `Has<T>` instead in these cases. The `WorldQuery` derive macro has been split into separate derive macros for `WorldQueryData` and `WorldQueryFilter`. Previously it was possible to derive both `WorldQuery` for a struct that had a mixture of data and filter items. This would not work correctly in some cases but could be a useful pattern in others. *This is no longer possible.* --- ## Notes - The changes outside of `bevy_ecs` are all changing type parameters to the new types, updating the macro use, or replacing `Option<With<T>>` with `Has<T>`. - All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL` so I moved it to `WorldQueryFilter` and replaced all calls to it with `true`. That should be the only logic change outside of the macro generation code. - `Changed<T>` and `Added<T>` were being generated by a macro that I have expanded. Happy to revert that if desired. - The two derive macros share some functions for implementing `WorldQuery` but the tidiest way I could find to implement them was to give them a ton of arguments and ask clippy to ignore that. ## Changelog ### Changed - Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which now have separate derive macros. It is not possible to derive both for the same type. - `Query` now requires that the first type argument implements `WorldQueryData` and the second implements `WorldQueryFilter` ## Migration Guide - Update derives ```rust // old #[derive(WorldQuery)] #[world_query(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA } #[derive(WorldQuery)] struct QueryFilter { _c: With<ComponentC> } // new #[derive(WorldQueryData)] #[world_query_data(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA, } #[derive(WorldQueryFilter)] struct QueryFilter { _c: With<ComponentC> } ``` - Replace `Option<With<T>>` with `Has<T>` ```rust /// old fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>) { for (entity, has_a_option) in query.iter(){ let has_a:bool = has_a_option.is_some(); //todo!() } } /// new fn my_system(query: Query<(Entity, Has<ComponentA>)>) { for (entity, has_a) in query.iter(){ //todo!() } } ``` - Fix queries which had filters in the data position or vice versa. ```rust // old fn my_system(query: Query<(Entity, With<ComponentA>)>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Entity, With<ComponentA>>) { for entity in query.iter(){ //todo!() } } // old fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>) { for entity in query.iter(){ //todo!() } } ``` --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
44928e0df4
|
StandardMaterial Light Transmission (#8015)
# Objective
<img width="1920" alt="Screenshot 2023-04-26 at 01 07 34"
src="https://user-images.githubusercontent.com/418473/234467578-0f34187b-5863-4ea1-88e9-7a6bb8ce8da3.png">
This PR adds both diffuse and specular light transmission capabilities
to the `StandardMaterial`, with support for screen space refractions.
This enables realistically representing a wide range of real-world
materials, such as:
- Glass; (Including frosted glass)
- Transparent and translucent plastics;
- Various liquids and gels;
- Gemstones;
- Marble;
- Wax;
- Paper;
- Leaves;
- Porcelain.
Unlike existing support for transparency, light transmission does not
rely on fixed function alpha blending, and therefore works with both
`AlphaMode::Opaque` and `AlphaMode::Mask` materials.
## Solution
- Introduces a number of transmission related fields in the
`StandardMaterial`;
- For specular transmission:
- Adds logic to take a view main texture snapshot after the opaque
phase; (in order to perform screen space refractions)
- Introduces a new `Transmissive3d` phase to the renderer, to which all
meshes with `transmission > 0.0` materials are sent.
- Calculates a light exit point (of the approximate mesh volume) using
`ior` and `thickness` properties
- Samples the snapshot texture with an adaptive number of taps across a
`roughness`-controlled radius enabling “blurry” refractions
- For diffuse transmission:
- Approximates transmitted diffuse light by using a second, flipped +
displaced, diffuse-only Lambertian lobe for each light source.
## To Do
- [x] Figure out where `fresnel_mix()` is taking place, if at all, and
where `dielectric_specular` is being calculated, if at all, and update
them to use the `ior` value (Not a blocker, just a nice-to-have for more
correct BSDF)
- To the _best of my knowledge, this is now taking place, after
|
||
|
|
b6ead2be95
|
Use EntityHashMap<Entity, T> for render world entity storage for better performance (#9903)
# Objective - Improve rendering performance, particularly by avoiding the large system commands costs of using the ECS in the way that the render world does. ## Solution - Define `EntityHasher` that calculates a hash from the `Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`. `0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a value close to π and that works well for hashing. Thanks for @SkiFire13 for the suggestion and to @nicopap for alternative suggestions and discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`) with some tweaks for the case of hashing an `Entity`. `FxHasher` and `SeaHasher` were also tested but were significantly slower. - Define `EntityHashMap` type that uses the `EntityHashser` - Use `EntityHashMap<Entity, T>` for render world entity storage, including: - `RenderMaterialInstances` - contains the `AssetId<M>` of the material associated with the entity. Also for 2D. - `RenderMeshInstances` - contains mesh transforms, flags and properties about mesh entities. Also for 2D. - `SkinIndices` and `MorphIndices` - contains the skin and morph index for an entity, respectively - `ExtractedSprites` - `ExtractedUiNodes` ## Benchmarks All benchmarks have been conducted on an M1 Max connected to AC power. The tests are run for 1500 frames. The 1000th frame is captured for comparison to check for visual regressions. There were none. ### 2D Meshes `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` #### `--ordered-z` This test spawns the 2D meshes with z incrementing back to front, which is the ideal arrangement allocation order as it matches the sorted render order which means lookups have a high cache hit rate. <img width="1112" alt="Screenshot 2023-09-27 at 07 50 45" src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb"> -39.1% median frame time. #### Random This test spawns the 2D meshes with random z. This not only makes the batching and transparent 2D pass lookups get a lot of cache misses, it also currently means that the meshes are almost certain to not be batchable. <img width="1108" alt="Screenshot 2023-09-27 at 07 51 28" src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4"> -7.2% median frame time. ### 3D Meshes `many_cubes --benchmark` <img width="1112" alt="Screenshot 2023-09-27 at 07 51 57" src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc"> -7.7% median frame time. ### Sprites **NOTE: On `main` sprites are using `SparseSet<Entity, T>`!** `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` #### `--ordered-z` This test spawns the sprites with z incrementing back to front, which is the ideal arrangement allocation order as it matches the sorted render order which means lookups have a high cache hit rate. <img width="1116" alt="Screenshot 2023-09-27 at 07 52 31" src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67"> +13.0% median frame time. #### Random This test spawns the sprites with random z. This makes the batching and transparent 2D pass lookups get a lot of cache misses. <img width="1109" alt="Screenshot 2023-09-27 at 07 53 01" src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033"> +0.6% median frame time. ### UI **NOTE: On `main` UI is using `SparseSet<Entity, T>`!** `many_buttons` <img width="1111" alt="Screenshot 2023-09-27 at 07 53 26" src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85"> +15.1% median frame time. ## Alternatives - Cart originally suggested trying out `SparseSet<Entity, T>` and indeed that is slightly faster under ideal conditions. However, `PassHashMap<Entity, T>` has better worst case performance when data is randomly distributed, rather than in sorted render order, and does not have the worst case memory usage that `SparseSet`'s dense `Vec<usize>` that maps from the `Entity` index to sparse index into `Vec<T>`. This dense `Vec` has to be as large as the largest Entity index used with the `SparseSet`. - I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()` as the key, but this proved to sometimes be slower and mostly no different. - The only outstanding approach that has not been implemented and tested is to _not_ clear the render world of its entities each frame. That has its own problems, though they could perhaps be solved. - Performance-wise, if the entities and their component data were not cleared, then they would incur table moves on spawn, and should not thereafter, rather just their component data would be overwritten. Ideally we would have a neat way of either updating data in-place via `&mut T` queries, or inserting components if not present. This would likely be quite cumbersome to have to remember to do everywhere, but perhaps it only needs to be done in the more performance-sensitive systems. - The main problem to solve however is that we want to both maintain a mapping between main world entities and render world entities, be able to run the render app and world in parallel with the main app and world for pipelined rendering, and at the same time be able to spawn entities in the render world in such a way that those Entity ids do not collide with those spawned in the main world. This is potentially quite solvable, but could well be a lot of ECS work to do it in a way that makes sense. --- ## Changelog - Changed: Component data for entities to be drawn are no longer stored on entities in the render world. Instead, data is stored in a `EntityHashMap<Entity, T>` in various resources. This brings significant performance benefits due to the way the render app clears entities every frame. Resources of most interest are `RenderMeshInstances` and `RenderMaterialInstances`, and their 2D counterparts. ## Migration Guide Previously the render app extracted mesh entities and their component data from the main world and stored them as entities and components in the render world. Now they are extracted into essentially `EntityHashMap<Entity, T>` where `T` are structs containing an appropriate group of data. This means that while extract set systems will continue to run extract queries against the main world they will store their data in hash maps. Also, systems in later sets will either need to look up entities in the available resources such as `RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>` for their own data. Before: ```rust fn queue_custom( material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>, ) { ... for (entity, mesh_transforms, mesh_handle) in &material_meshes { ... } } ``` After: ```rust fn queue_custom( render_mesh_instances: Res<RenderMeshInstances>, instance_entities: Query<Entity, With<InstanceMaterialData>>, ) { ... for entity in &instance_entities { let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; }; // The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now // be found in `mesh_instance` which is a `RenderMeshInstance` ... } } ``` --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> |
||
|
|
5c884c5a15
|
Automatic batching/instancing of draw commands (#9685)
# Objective - Implement the foundations of automatic batching/instancing of draw commands as the next step from #89 - NOTE: More performance improvements will come when more data is managed and bound in ways that do not require rebinding such as mesh, material, and texture data. ## Solution - The core idea for batching of draw commands is to check whether any of the information that has to be passed when encoding a draw command changes between two things that are being drawn according to the sorted render phase order. These should be things like the pipeline, bind groups and their dynamic offsets, index/vertex buffers, and so on. - The following assumptions have been made: - Only entities with prepared assets (pipelines, materials, meshes) are queued to phases - View bindings are constant across a phase for a given draw function as phases are per-view - `batch_and_prepare_render_phase` is the only system that performs this batching and has sole responsibility for preparing the per-object data. As such the mesh binding and dynamic offsets are assumed to only vary as a result of the `batch_and_prepare_render_phase` system, e.g. due to having to split data across separate uniform bindings within the same buffer due to the maximum uniform buffer binding size. - Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform in arrays in GPU buffers rather than each one being at a dynamic offset in a uniform buffer. This is the same optimisation that was made for 3D not long ago. - Change batch size for a range in `PhaseItem`, adding API for getting or mutating the range. This is more flexible than a size as the length of the range can be used in place of the size, but the start and end can be otherwise whatever is needed. - Add an optional mesh bind group dynamic offset to `PhaseItem`. This avoids having to do a massive table move just to insert `GpuArrayBufferIndex` components. ## Benchmarks All tests have been run on an M1 Max on AC power. `bevymark` and `many_cubes` were modified to use 1920x1080 with a scale factor of 1. I run a script that runs a separate Tracy capture process, and then runs the bevy example with `--features bevy_ci_testing,trace_tracy` and `CI_TESTING_CONFIG=../benchmark.ron` with the contents of `../benchmark.ron`: ```rust ( exit_after: Some(1500) ) ``` ...in order to run each test for 1500 frames. The recent changes to `many_cubes` and `bevymark` added reproducible random number generation so that with the same settings, the same rng will occur. They also added benchmark modes that use a fixed delta time for animations. Combined this means that the same frames should be rendered both on main and on the branch. The graphs compare main (yellow) to this PR (red). ### 3D Mesh `many_cubes --benchmark` <img width="1411" alt="Screenshot 2023-09-03 at 23 42 10" src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4"> The mesh and material are the same for all instances. This is basically the best case for the initial batching implementation as it results in 1 draw for the ~11.7k visible meshes. It gives a ~30% reduction in median frame time. The 1000th frame is identical using the flip tool:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4615 seconds ``` ### 3D Mesh `many_cubes --benchmark --material-texture-count 10` <img width="1404" alt="Screenshot 2023-09-03 at 23 45 18" src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf"> This run uses 10 different materials by varying their textures. The materials are randomly selected, and there is no sorting by material bind group for opaque 3D so any batching is 'random'. The PR produces a ~5% reduction in median frame time. If we were to sort the opaque phase by the material bind group, then this should be a lot faster. This produces about 10.5k draws for the 11.7k visible entities. This makes sense as randomly selecting from 10 materials gives a chance that two adjacent entities randomly select the same material and can be batched. The 1000th frame is identical in flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4537 seconds ``` ### 3D Mesh `many_cubes --benchmark --vary-per-instance` <img width="1394" alt="Screenshot 2023-09-03 at 23 48 44" src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f"> This run varies the material data per instance by randomly-generating its colour. This is the worst case for batching and that it performs about the same as `main` is a good thing as it demonstrates that the batching has minimal overhead when dealing with ~11k visible mesh entities. The 1000th frame is identical according to flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4568 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` <img width="1412" alt="Screenshot 2023-09-03 at 23 59 56" src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4"> This spawns 160 waves of 1000 quad meshes that are shaded with ColorMaterial. Each wave has a different material so 160 waves currently should result in 160 batches. This results in a 50% reduction in median frame time. Capturing a screenshot of the 1000th frame main vs PR gives:  ``` Mean: 0.001222 Weighted median: 0.750432 1st weighted quartile: 0.453494 3rd weighted quartile: 0.969758 Min: 0.000000 Max: 0.990296 Evaluation time: 0.4255 seconds ``` So they seem to produce the same results. I also double-checked the number of draws. `main` does 160000 draws, and the PR does 160, as expected. ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --material-texture-count 10` <img width="1392" alt="Screenshot 2023-09-04 at 00 09 22" src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c"> This generates 10 textures and generates materials for each of those and then selects one material per wave. The median frame time is reduced by 50%. Similar to the plain run above, this produces 160 draws on the PR and 160000 on `main` and the 1000th frame is identical (ignoring the fps counter text overlay).  ``` Mean: 0.002877 Weighted median: 0.964980 1st weighted quartile: 0.668871 3rd weighted quartile: 0.982749 Min: 0.000000 Max: 0.992377 Evaluation time: 0.4301 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --vary-per-instance` <img width="1396" alt="Screenshot 2023-09-04 at 00 13 53" src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb"> This creates unique materials per instance by randomly-generating the material's colour. This is the worst case for 2D batching. Somehow, this PR manages a 7% reduction in median frame time. Both main and this PR issue 160000 draws. The 1000th frame is the same:  ``` Mean: 0.001214 Weighted median: 0.937499 1st weighted quartile: 0.635467 3rd weighted quartile: 0.979085 Min: 0.000000 Max: 0.988971 Evaluation time: 0.4462 seconds ``` ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` <img width="1396" alt="Screenshot 2023-09-04 at 12 21 12" src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43"> This just spawns 160 waves of 1000 sprites. There should be and is no notable difference between main and the PR. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --material-texture-count 10` <img width="1389" alt="Screenshot 2023-09-04 at 12 36 08" src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413"> This spawns the sprites selecting a texture at random per instance from the 10 generated textures. This has no significant change vs main and shouldn't. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --vary-per-instance` <img width="1401" alt="Screenshot 2023-09-04 at 12 29 52" src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6"> This sets the sprite colour as being unique per instance. This can still all be drawn using one batch. There should be no difference but the PR produces median frame times that are 4% higher. Investigation showed no clear sources of cost, rather a mix of give and take that should not happen. It seems like noise in the results. ### Summary | Benchmark | % change in median frame time | | ------------- | ------------- | | many_cubes | 🟩 -30% | | many_cubes 10 materials | 🟩 -5% | | many_cubes unique materials | 🟩 ~0% | | bevymark mesh2d | 🟩 -50% | | bevymark mesh2d 10 materials | 🟩 -50% | | bevymark mesh2d unique materials | 🟩 -7% | | bevymark sprite | 🟥 2% | | bevymark sprite 10 materials | 🟥 0.6% | | bevymark sprite unique materials | 🟥 4.1% | --- ## Changelog - Added: 2D and 3D mesh entities that share the same mesh and material (same textures, same data) are now batched into the same draw command for better performance. --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> Co-authored-by: Nicola Papale <nico@nicopap.ch> |
{kind=link}