# Objective
- Closes#4954
- Reduce the complexity of the `{System, App, *}Label` APIs.
## Solution
For the sake of brevity I will only refer to `SystemLabel`, but everything applies to all of the other label types as well.
- Add `SystemLabelId`, a lightweight, `copy` struct.
- Convert custom types into `SystemLabelId` using the trait `SystemLabel`.
## Changelog
- String literals implement `SystemLabel` for now, but this should be changed with #4409 .
## Migration Guide
- Any previous use of `Box<dyn SystemLabel>` should be replaced with `SystemLabelId`.
- `AsSystemLabel` trait has been modified.
- No more output generics.
- Method `as_system_label` now returns `SystemLabelId`, removing an unnecessary level of indirection.
- If you *need* a label that is determined at runtime, you can use `Box::leak`. Not recommended.
## Questions for later
* Should we generate a `Debug` impl along with `#[derive(*Label)]`?
* Should we rename `as_str()`?
* Should we remove the extra derives (such as `Hash`) from builtin `*Label` types?
* Should we automatically derive types like `Clone, Copy, PartialEq, Eq`?
* More-ergonomic comparisons between `Label` and `LabelId`.
* Move `Dyn{Eq, Hash,Clone}` somewhere else.
* Some API to make interning dynamic labels easier.
* Optimize string representation
* Empty string for unit structs -- no debug info but faster comparisons
* Don't show enum types -- same tradeoffs as asbove.
Add compile time check for if a system is an exclusive system. Resolves#4788
Co-authored-by: Daniel Liu <mr.picklepinosaur@gmail.com>
Co-authored-by: Daniel Liu <danieliu3120@gmail.com>
Following https://github.com/bevyengine/bevy/pull/5124 I decided to add the `ExactSizeIterator` impl for `QueryCombinationIter`.
Also:
- Clean up the tests for `size_hint` and `len` for both the normal `QueryIter` and `QueryCombinationIter`.
- Add tests to `QueryCombinationIter` when it shouldn't be `ExactSizeIterator`
---
## Changelog
- Added `ExactSizeIterator` implementation for `QueryCombinatonIter`
# Objective
- `.iter_combinations_*()` cannot be used on custom derived `WorldQuery`, so this fixes that
- Fixes#5284
## Solution
- `#[derive(Clone)]` on the `Fetch` of the proc macro derive.
- `#[derive(Clone)]` for `AnyOf` to satisfy tests.
# Objective
Improve documentation, information users of the limitations in bevy's idiomatic patterns, and suggesting alternatives for when those limitations are encountered.
## Solution
* Add documentation to `Commands` informing the user of the option of writing one-shot commands with closures.
* Add documentation to `EventWriter` regarding the limitations of event types, and suggesting alternatives using commands.
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`ReflectResource` and `ReflectComponent` will panic on `apply` method if there is no such component. It's not very ergonomic. And not very good for performance since I need to check if such component exists first.
## Solution
* Add `ReflectComponent::apply_or_insert` and `ReflectResource::apply_or_insert` functions.
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
---
## Changelog
### Added
* `ReflectResource::apply_or_insert` and `ReflectComponent::apply_on_insert`.
### Changed
* Rename `ReflectComponent::add` into `ReflectComponent::insert` for consistency.
* Use `ReflectComponent::apply_on_insert` in `DynamicScene` instead of manual checking.
## Migration Guide
* Rename `ReflectComponent::add` into `ReflectComponent::insert`.
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`EntityMap` lacks documentation, don't have `len()` / `is_empty` and `insert` doesn't work as in the regular HashMap`.
## Solution
* Add `len()` method.
* Return previously mapped entity from `insert()` as in the regular `HashMap`.
* Add documentation.
---
## Changelog
* Add `EntityMap::len()`.
* Return previously mapped entity from `EntityMap::insert()` as in the regular `HashMap`.
* Add documentation for `EntityMap` methods.
# Objective
Remove suffixes from reflect component and resource methods to closer match bevy norms.
## Solution
removed suffixes and also fixed a spelling error
---
# Objective
- Help users fix issue when their app panic when executing a command on a despawned entity
## Solution
- Add an error code and a page describing how to debug the issue
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
This is a common and useful type. I frequently use this when working with `Events` resource directly, typically when caching the data or manipulating the `World` directly.
This is also useful when manually configuring the cleanup strategy for events.
The first leak:
```rust
#[test]
fn blob_vec_drop_empty_capacity() {
let item_layout = Layout:🆕:<Foo>();
let drop = drop_ptr::<Foo>;
let _ = unsafe { BlobVec::new(item_layout, Some(drop), 0) };
}
```
this is because we allocate the swap scratch in blobvec regardless of what the capacity is, but we only deallocate if capacity is > 0
The second leak:
```rust
#[test]
fn panic_while_overwriting_component() {
let helper = DropTestHelper::new();
let res = panic::catch_unwind(|| {
let mut world = World::new();
world
.spawn()
.insert(helper.make_component(true, 0))
.insert(helper.make_component(false, 1));
println!("Done inserting! Dropping world...");
});
let drop_log = helper.finish(res);
assert_eq!(
&*drop_log,
[
DropLogItem::Create(0),
DropLogItem::Create(1),
DropLogItem::Drop(0),
]
);
}
```
this is caused by us not running the drop impl on the to-be-inserted component if the drop impl of the overwritten component panics
---
managed to figure out where the leaks were by using this 10/10 command
```
cargo --quiet test --lib -- --list | sed 's/: test$//' | MIRIFLAGS="-Zmiri-disable-isolation" xargs -n1 cargo miri test --lib -- --exact
```
which runs every test one by one rather than all at once which let miri actually tell me which test had the leak 🙃
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
CI is now failing with some changes that landed in 1.62.
## Solution
* Fix an unused lifetime by using it (we double-used the `w` lifetime).
* Update compile_fail error messages
* temporarily disable check-unused-dependencies
# Objective
- Provide a way to see the components of an entity.
- Fixes#1467
## Solution
- Add `World::inspect_entity`. It accepts an `Entity` and returns a vector of `&ComponentInfo` that the entity has.
- Add `EntityCommands::log_components`. It logs the component names of the entity. (info level)
---
## Changelog
### Added
- Ability to inspect components of an entity through `World::inspect_entity` or `EntityCommands::log_components`
There are some outdated error messages for when a resource is not found. It references `add_resource` and `add_non_send_resource` which were renamed to `insert_resource` and `insert_non_send_resource`.
# Objective
- Fixes#3142
## Solution
- Done according to #3142
- Created new marker trait `ArchetypeFilter`
- Implement said trait to:
- `With<T>`
- `Without<T>`
- tuples containing only types that implement `ArchetypeFilter`, from 0 to 15 elements
- `Or<T>` where T is a tuple as described previously
- Changed `ExactSizeIterator` impl to include a new generic that must implement `WorldQuery` and `ArchetypeFilter`
- Added new tests
---
## Changelog
### Added
- `Query`s with archetypal filters can now use `.iter().len()` to get the exact size of the iterator.
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
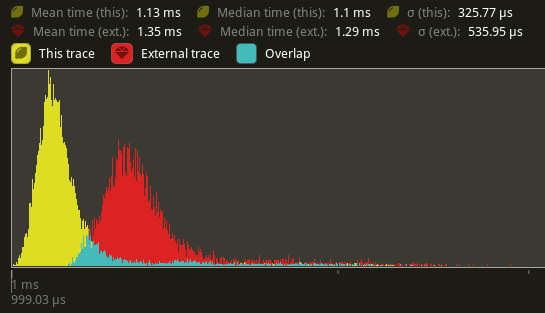
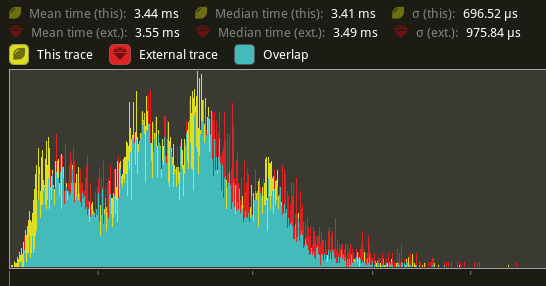
The command heavy `Extract` stage also saw a smaller overall improvement:
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
- Simplify the process of obtaining a `ComponentId` instance corresponding to a `Component`.
- Resolves#5060.
## Solution
- Add a `component_id::<T: Component>(&self)` function to both `World` and `Components` to retrieve the `ComponentId` associated with `T` from a immutable reference.
---
## Changelog
- Added `World::component_id::<C>()` and `Components::component_id::<C>()` to retrieve a `Component`'s corresponding `ComponentId` if it exists.
# Objective
Closes#1557. Partially addresses #3362.
Cleanup the public facing API for storage types. Most of these APIs are difficult to use safely when directly interfacing with these types, and is also currently impossible to interact with in normal ECS use as there is no `World::storages_mut`. The majority of these types should be easy enough to read, and perhaps mutate the contents, but never structurally altered without the same checks in the rest of bevy_ecs code. This both cleans up the public facing types and helps use unused code detection to remove a few of the APIs we're not using internally.
## Solution
- Mark all APIs that take `&mut T` under `bevy_ecs::storage` as `pub(crate)` or `pub(super)`
- Cleanup after it all.
Entire type visibility changes:
- `BlobVec` is `pub(super)`, only storage code should be directly interacting with it.
- `SparseArray` is now `pub(crate)` for the entire type. It's an implementation detail for `Table` and `(Component)SparseSet`.
- `TableMoveResult` is now `pub(crate)
---
## Changelog
TODO
## Migration Guide
Dear God, I hope not.
# Objective
The descriptions included in the API docs of `entity` module, `Entity` struct, and `Component` trait have some issues:
1. the concept of entity is not clearly defined,
2. descriptions are a little bit out of place,
3. in a case the description leak too many details about the implementation,
4. some descriptions are not exhaustive,
5. there are not enough examples,
6. the content can be formatted in a much better way.
## Solution
1. ~~Stress the fact that entity is an abstract and elementary concept. Abstract because the concept of entity is not hardcoded into the library but emerges from the interaction of `Entity` with every other part of `bevy_ecs`, like components and world methods. Elementary because it is a fundamental concept that cannot be defined with other terms (like point in euclidean geometry, or time in classical physics).~~ We decided to omit the definition of entity in the API docs ([see why]). It is only described in its relationship with components.
2. Information has been moved to relevant places and links are used instead in the other places.
3. Implementation details about `Entity` have been reduced.
4. Descriptions have been made more exhaustive by stating how to obtain and use items. Entity operations are enriched with `World` methods.
5. Examples have been added or enriched.
6. Sections have been added to organize content. Entity operations are now laid out in a table.
### Todo list
- [x] Break lines at sentence-level.
## For reviewers
- ~~I added a TODO over `Component` docs, make sure to check it out and discuss it if necessary.~~ ([Resolved])
- You can easily check the rendered documentation by doing `cargo doc -p bevy_ecs --no-deps --open`.
[see why]: https://github.com/bevyengine/bevy/pull/4767#discussion_r875106329
[Resolved]: https://github.com/bevyengine/bevy/pull/4767#discussion_r874127825
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
# Objective
- Fixes#4271
## Solution
- Check for a pending transition in addition to a scheduled operation.
- I don't see a valid reason for updating the state unless both `scheduled` and `transition` are empty.
# Objective
Following #4855, `Column` is just a parallel `BlobVec`/`Vec<UnsafeCell<ComponentTicks>>` pair, which is identical to the dense and ticks vecs in `ComponentSparseSet`, which has some code duplication with `Column`.
## Solution
Replace dense and ticks in `ComponentSparseSet` with a `Column`.
# Objective
Most of our `Iterator` impls satisfy the requirements of `std::iter::FusedIterator`, which has internal specialization that optimizes `Interator::fuse`. The std lib iterator combinators do have a few that rely on `fuse`, so this could optimize those use cases. I don't think we're using any of them in the engine itself, but beyond a light increase in compile time, it doesn't hurt to implement the trait.
## Solution
Implement the trait for all eligible iterators in first party crates. Also add a missing `ExactSizeIterator` on an iterator that could use it.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864Fixes#1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
(follow-up to #4423)
# Objective
Currently, it isn't possible to easily fire commands from within par_for_each blocks. This PR allows for issuing commands from within parallel scopes.
# Objective
This PR aims to improve the soundness of `CommandQueue`. In particular it aims to:
- make it sound to store commands that contain padding or uninitialized bytes;
- avoid uses of commands after moving them in the queue's buffer (`std::mem::forget` is technically a use of its argument);
- remove useless checks: `self.bytes.as_mut_ptr().is_null()` is always `false` because even `Vec`s that haven't allocated use a dangling pointer. Moreover the same pointer was used to write the command, so it ought to be valid for reads if it was for writes.
## Solution
- To soundly store padding or uninitialized bytes `CommandQueue` was changed to contain a `Vec<MaybeUninit<u8>>` instead of `Vec<u8>`;
- To avoid uses of the command through `std::mem::forget`, `ManuallyDrop` was used.
## Other observations
While writing this PR I noticed that `CommandQueue` doesn't seem to drop the commands that weren't applied. While this is a pretty niche case (you would have to be manually using `CommandQueue`/`std::mem::swap`ping one), I wonder if it should be documented anyway.
# Objective
Don't allocate memory for Component types known at compile-time. Save a bit of memory.
## Solution
Change `ComponentDescriptor::name` from `String` to `Cow<'static, str>` to use the `&'static str` returned by `std::any::type_name`.
# Objective
`debug_assert!` macros must still compile properly in release mode due to how they're implemented. This is causing release builds to fail.
## Solution
Change them to `assert!` macros inside `#[cfg(debug_assertions)]` blocks.
# Objective
- Higher order system could not be created by users.
- However, a simple change to `SystemParamFunction` allows this.
- Higher order systems in this case mean functions which return systems created using other systems, such as `chain` (which is basically equivalent to map)
## Solution
- Change `SystemParamFunction` to be a safe abstraction over `FnMut([In<In>,] ...params)->Out`.
- Note that I believe `SystemParamFunction` should not have been counted as part of our public api before this PR.
- This is because its only use was an unsafe function without an actionable safety comment.
- The safety comment was basically 'call this within bevy code'.
- I also believe that there are no external users in its current form.
- A quick search on Google and in the discord confirmed this.
## See also
- https://github.com/bevyengine/bevy/pull/4666, which uses this and subsumes the example here
---
## Changelog
### Added
- `SystemParamFunction`, which can be used to create higher order systems.
# Objective
Use less memory to store SparseSet components.
## Solution
Change `ComponentSparseSet` to only use `Entity::id` in it's key internally, and change the usize value in it's SparseArray to use u32 instead, as it cannot have more than u32::MAX live entities stored at once.
This should reduce the overhead of storing components in sparse set storage by 50%.
{kind=link}
{kind=link}
{kind=link}