# Objective
- Fixes#7294
## Solution
- Do not trigger change detection when setting the cursor position from winit
When moving the cursor continuously, Winit sends events:
- CursorMoved(0)
- CursorMoved(1)
- => start of Bevy schedule execution
- CursorMoved(2)
- CursorMoved(3)
- <= End of Bevy schedule execution
if Bevy schedule runs after the event 1, events 2 and 3 would happen during the execution but would be read only on the next system run. During the execution, the system would detect a change on cursor position, and send back an order to winit to move it back to 1, so event 2 and 3 would be ignored. By bypassing change detection when setting the cursor from winit event, it doesn't trigger sending back that change to winit out of order.
# Objective
- `Components::resource_id` doesn't exist. Like `Components::component_id` but for resources.
## Solution
- Created `Components::resource_id` and added some docs.
---
## Changelog
- Added `Components::resource_id`.
- Changed `World::init_resource` to return the generated `ComponentId`.
- Changed `World::init_non_send_resource` to return the generated `ComponentId`.
# Objective
- Fixes#7288
- Do not expose access directly to cursor position as it is the physical position, ignoring scale
## Solution
- Make cursor position private
- Expose getter/setter on the window to have access to the scale
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
After #6503, bevy_render uses the `send_blocking` method introduced in async-channel 1.7, but depended only on ^1.4.
I saw this after pulling main without running cargo update.
# Objective
- Fix minimum dependency version of async-channel
## Solution
- Bump async-channel version constraint to ^1.8, which is currently the latest version.
NOTE: Both bevy_ecs and bevy_tasks also depend on async-channel but they didn't use any newer features.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
## Problem
`extract_uinodes` checks if an image is loaded for nodes without images
## Solution
Move the image loading skip check so that it is only performed for nodes with a `UiImage` component.
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Safety comments for the `CommandQueue` type are quite sparse and very imprecise. Sometimes, they are right for the wrong reasons or use circular reasoning.
## Solution
- Document previously-implicit safety invariants.
- Rewrite safety comments to actually reflect the specific invariants of each operation.
- Use `OwningPtr` instead of raw pointers, to encode an invariant in the type system instead of via comments.
- Use typed pointer methods when possible to increase reliability.
---
## Changelog
+ Added the function `OwningPtr::read_unaligned`.
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
See:
- https://github.com/bevyengine/bevy/issues/7067#issuecomment-1381982285
- (This does not fully close that issue in my opinion.)
- https://discord.com/channels/691052431525675048/1063454009769340989
## Solution
This merge request adds documentation:
1. Alert users to the fact that `App::run()` might never return and code placed after it might never be executed.
2. Makes `winit::WinitSettings::return_from_run` discoverable.
3. Better explains why `winit::WinitSettings::return_from_run` is discouraged and better links to up-stream docs. on that topic.
4. Adds notes to the `app/return_after_run.rs` example which otherwise promotes a feature that carries caveats.
Furthermore, w.r.t `winit::WinitSettings::return_from_run`:
- Broken links to `winit` docs are fixed.
- Links now point to BOTH `EventLoop::run()` and `EventLoopExtRunReturn::run_return()` which are the salient up-stream pages and make more sense, taken together.
- Collateral damage: "Supported platforms" heading; disambiguation of "run" → `App::run()`; links.
## Future Work
I deliberately structured the "`run()` might not return" section under `App::run()` to allow for alternative patterns (e.g. `AppExit` event, `WindowClosed` event) to be listed or mentioned, beneath it, in the future.
# Objective
- Fixes#7260
## Solution
- #6649 used `init_non_send_resource` for `AudioOutput`, but this is before #6436 was merged.
- Use `init_resource` instead.
# Objective
Repeated calls to `init_non_send_resource` currently overwrite the old value because the wrong storage is being checked.
## Solution
Use the correct storage. Add some tests.
## Notes
Without the fix, the new test fails with
```
thread 'world::tests::init_non_send_resource_does_not_overwrite' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `0`', crates/bevy_ecs/src/world/mod.rs:2267:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test world::tests::init_non_send_resource_does_not_overwrite ... FAILED
```
This was introduced by #7174 and it seems like a fairly straightforward oopsie.
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
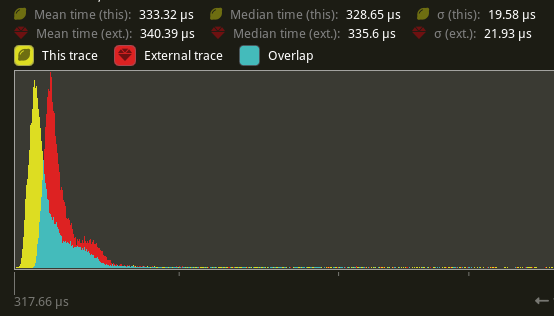
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
# Objective
- Enabling the `debug_asset_server` feature doesn't compile when using it with `load_internal_binary_asset!()`. The issue is because it assumes the loader takes an `&'static str` as a parameter, but binary assets loader expect `&'static [u8]`.
## Solution
- Add a generic type for the loader and use a different type in `load_internal_asset` and `load_internal_binary_asset`
# Objective
- Fixes#6361
- Fixes#6362
- Fixes#6364
## Solution
- Added an example for creating a custom `Decodable` type
- Clarified the documentation on `Decodable`
- Added an `AddAudioSource` trait and implemented it for `App`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
Fix#4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be.
## Solution
As `Parent` and `Children` are updated in tandem in hierarchy commands after #4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings.
Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it.
The tests from #4608 still pass, so the change detection here still works just fine under this approach.
# Objective
fix bloom when used on a camera with a viewport specified
## Solution
- pass viewport into the prefilter shader, and use it to read from the correct section of the original rendered screen
- don't apply viewport for the intermediate bloom passes, only for the final blend output
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes#7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
# Objective
Fixes#5859
## Solution
- Add `ClearChildren` and `ReplaceChildren` commands in the `crates/bevy_hierarchy/src/child_builder.rs`
---
## Changelog
- Added `ClearChildren` and `ReplaceChildren` struct
- Added `clear_children(&mut self) -> &mut Self` and `replace_children(&mut self, children: &[Entity]) -> &mut Self` function in `BuildChildren` trait
- Changed `PushChildren` `write` function body to a `push_children ` function to reused in `ReplaceChildren`
- Added `clear_children` function
- Added `push_and_replace_children_commands` and `push_and_clear_children_commands` test
Co-authored-by: ld000 <lidong9144@163.com>
Co-authored-by: lidong63 <lidong63@meituan.com>
# Objective
- Fixes a bug where `just_pressed` and `just_released` in `Input<GamepadButton>` might behave incorrectly due calling `clear` 3 times in a single frame through these three different systems: `gamepad_button_event_system`, `gamepad_axis_event_system` and `gamepad_connection_system` in any order
## Solution
- Call `clear` only once and before all the above three systems, i.e. in `gamepad_event_system`
## Additional Info
- Discussion in Discord: https://discord.com/channels/691052431525675048/768253008416342076/1064621963693273279
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
Currently, the `AxisSettings::new` function is unusable due to
an implementation quirk. It only allows `AxisSettings` where
the bounds that are supposed to be positive are negative!
## Solution
- We fix the bound check
- We add a test to make sure the method is usable
Seems like the error slipped through because of the relatively
verbose code style. With all those `if/else`, very long names,
range syntax, the bound check is actually hard to spot. I first
refactored a lot of code, but I left out the refactor because the
fix should be integrated independently.
---
## Changelog
- Fix `AxisSettings::new` only accepting invalid bounds
# Objective
Add useful information about cursor position relative to a UI node. Fixes#7079.
## Solution
- Added a new `RelativeCursorPosition` component
---
## Changelog
- Added
- `RelativeCursorPosition`
- an example showcasing the new component
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
Fix#5248.
## Solution
Support `In<T>` parameters and allow returning arbitrary types in exclusive systems.
---
## Changelog
- Exclusive systems may now be used with system piping.
## Migration Guide
Exclusive systems (systems that access `&mut World`) now support system piping, so the `ExclusiveSystemParamFunction` trait now has generics for the `In`put and `Out`put types.
```rust
// Before
fn my_generic_system<T, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<Param>
{ ... }
// After
fn my_generic_system<T, In, Out, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<In, Out, Param>
{ ... }
```
# Objective
Pipelines can be customized by wrapping an existing pipeline in a newtype and adding custom logic to its implementation of `SpecializedMeshPipeline::specialize`. To make that easier, the wrapped pipeline type needs to implement `Clone`.
For example, the current non-cloneable pipelines require wrapper pipelines to pull apart the wrapped pipeline like this:
```rust
impl FromWorld for Wireframe2dPipeline {
fn from_world(world: &mut World) -> Self {
let p = &world.resource::<Material2dPipeline<ColorMaterial>>();
Self {
mesh2d_pipeline: p.mesh2d_pipeline.clone(),
material2d_layout: p.material2d_layout.clone(),
vertex_shader: p.vertex_shader.clone(),
fragment_shader: p.fragment_shader.clone(),
}
}
}
```
## Solution
Derive or implement `Clone` on all built-in pipeline types. This is easy to do since they mostly just contain cheaply clonable reference-counted types.
---
## Changelog
Implement `Clone` for all pipeline types.
# Objective
fix error with shadow shader's spotlight direction calculation when direction.y ~= 0
fixes#7152
## Solution
same as #6167: in shadows.wgsl, clamp 1-x^2-z^2 to >= 0 so that we can safely sqrt it
# Objective
There are some utility functions for actually working with `Storages` inside `entity_ref.rs` that are used both for `EntityRef/EntityMut` and `World`, with a `// TODO: move to Storages`.
This PR moves them to private methods on `World`, because that's the safest API boundary. On `Storages` you would need to ensure that you pass `Components` from the same world.
## Solution
- move get_component[_with_type], get_ticks[_with_type], get_component_and_ticks[_with_type] to `World` (still pub(crate))
- replace `pub use entity_ref::*;` with `pub use entity_ref::{EntityRef, EntityMut}` and qualified `entity_ref::get_mut[_by_id]` in `world.rs`
- add safety comments to a bunch of methods
# Objective
* `World::init_resource` and `World::get_resource_or_insert_with` are implemented naively, and as such they perform duplicate `TypeId -> ComponentId` lookups.
* `World::get_resource_or_insert_with` contains an additional duplicate `ComponentId -> ResourceData` lookup.
* This function also contains an unnecessary panic branch, which we rely on the optimizer to be able to remove.
## Solution
Implement the functions using engine-internal code, instead of combining high-level functions. This allows computed variables to persist across different branches, instead of being recomputed.
{kind=link}
{kind=link}