# Objective
- RenderGraphExt was merged, but only used in limited situations
## Solution
- Fix some remaining issues with the existing api
- Use the new api in the main pass and mass writeback
- Add CORE_2D and CORE_3D constant to make render_graph code shorter
# Objective
While working on #8299, I noticed that we're using a `capacity` field,
even though `wgpu::Buffer` exposes a `size` accessor that does the same
thing.
## Solution
Remove it from all buffer wrappers. Use `wgpu::Buffer::size` instead.
Default to 0 if no buffer has been allocated yet.
# Objective
Fixes#8284. `values` is being pushed to separately from the actual
scratch buffer in `DynamicUniformBuffer::push` and
`DynamicStorageBuffer::push`. In both types, `values` is really only
used to track the number of elements being added to the buffer, yet is
causing extra allocations, size increments and excess copies.
## Solution
Remove it and its remaining uses. Replace it with accesses to `scratch`
instead.
I removed the `len` accessor, as it may be non-trivial to compute just
from `scratch`. If this is still desirable to have, we can keep a `len`
member field to track it instead of relying on `scratch`.
# Objective
State requires a kind of awkward `state.0` to get the current state and
exposes the field directly to manipulation.
## Solution
Make it accessible through a getter method as well as privatize the
field to make sure false assumptions about setting the state aren't
made.
## Migration Guide
- Use `State::get` instead of accessing the tuple field directly.
# Objective
- Adding a node to the render_graph can be quite verbose and error prone
because there's a lot of moving parts to it.
## Solution
- Encapsulate this in a simple utility method
- Mostly intended for optional nodes that have specific ordering
- Requires that the `Node` impl `FromWorld`, but every internal node is
built using a new function taking a `&mut World` so it was essentially
already `FromWorld`
- Use it for the bloom, fxaa and taa, nodes.
- The main nodes don't use it because they rely more on the order of
many nodes being added
---
## Changelog
- Impl `FromWorld` for `BloomNode`, `FxaaNode` and `TaaNode`
- Added `RenderGraph::add_node_edges()`
- Added `RenderGraph::sub_graph()`
- Added `RenderGraph::sub_graph_mut()`
- Added `RenderGraphApp`, `RenderGraphApp::add_render_graph_node`,
`RenderGraphApp::add_render_graph_edges`,
`RenderGraphApp::add_render_graph_edge`
## Notes
~~This was taken out of https://github.com/bevyengine/bevy/pull/7995
because it works on it's own. Once the linked PR is done, the new
`add_node()` will be simplified a bit since the input/output params
won't be necessary.~~
This feature will be useful in most of the upcoming render nodes so it's
impact will be more relevant at that point.
Partially fixes#7985
## Future work
* Add a way to automatically label nodes or at least make it part of the
trait. This would remove one more field from the functions added in this
PR
* Use it in the main pass 2d/3d
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
bevy-scene does not have a reason to depend on bevy-render except to
include the `Visibility` and `ComputedVisibility` components. Including
that in the dependency chain is unnecessary for people not using
`bevy_render`.
Also fixed a problem where compilation fails when the `serialize`
feature was not enabled.
## Solution
This was added in #5335 to address some of the problems caused by #5310.
Imo the user just always have to remember to include `VisibilityBundle`
when they spawn `SceneBundle` or `DynamicSceneBundle`, but that will be
a breaking change. This PR makes `bevy_render` an optional dependency of
`bevy_scene` instead to respect the existing behavior.
# Objective
While migrating the engine to use the `Tick` type in #7905, I forgot to
update `UnsafeWorldCell::increment_change_tick`.
## Solution
Update the function.
---
## Changelog
- The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
## Migration Guide
The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
# Objective
TAA, FXAA, and some other post processing effects can cause the image to
become blurry. Sharpening helps to counteract that.
## Solution
~~This is a port of AMD's Contrast Adaptive Sharpening (I ported it from
the
[SweetFX](https://github.com/CeeJayDK/SweetFX/blob/master/Shaders/CAS.fx)
version, which is still MIT licensed). CAS is a good sharpening
algorithm that is better at avoiding the full screen oversharpening
artifacts that simpler algorithms tend to create.~~
This is a port of AMD's Robust Contrast Adaptive Sharpening (RCAS) which
they developed for FSR 1 ([and continue to use in FSR
2](149cf26e12/src/ffx-fsr2-api/shaders/ffx_fsr1.h (L599))).
RCAS is a good sharpening algorithm that is better at avoiding the full
screen oversharpening artifacts that simpler algorithms tend to create.
---
## Future Work
- Consider porting this to a compute shader for potentially better
performance. (In my testing it is currently ridiculously cheap (0.01ms
in Bistro at 1440p where I'm GPU bound), so this wasn't a priority,
especially since it would increase complexity due to still needing the
non-compute version for webgl2 support).
---
## Changelog
- Added Contrast Adaptive Sharpening.
---------
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Closes https://github.com/bevyengine/bevy/issues/8008
## Solution
- Add a skybox plugin that renders a fullscreen triangle, and then
modifies the vertices in a vertex shader to enforce that it renders as a
skybox background.
- Skybox is run at the end of MainOpaquePass3dNode.
- In the future, it would be nice to get something like bevy_atmosphere
built-in, and have a default skybox+environment map light.
---
## Changelog
- Added `Skybox`.
- `EnvironmentMapLight` now renders in the correct orientation.
## Migration Guide
- Flip `EnvironmentMapLight` maps if needed to match how they previously
rendered (which was backwards).
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
These traits are both implemented, but not reflected, requiring user
code to do `app.register_type_data::<BloomSettings,
ReflectDefault>().register_type_data::<BloomSettings,
ReflectComponent>()` to make these usable via reflection.
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
Fix typo in bevy_reflect README: `MyType` is a struct and not a trait,
so `&dyn MyType` is incorrect.
## Solution
Replace `&dyn MyType` with `&dyn DoThing`
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Fix `CubicCurve::iter_samples` iteration count.
## Solution
If I understand the function and the docs correctly, this should iterate
over `0..=subdivisions` instead of `0..subdivisions`.
For example: Now the iteration returns 3 points at `subdivisions = 2`,
as indicated in the documentation.
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
Our regression tests for `SystemParam` currently consist of a bunch of
loosely dispersed struct definitions. This is messy, and doesn't fully
test their functionality.
## Solution
Group the struct definitions into functions annotated with `#[test]`.
This not only makes the module more organized, but it allows us to call
`assert_is_system`, which has the potential to catch some bugs that
would have been missed with the old approach. Also, this approach is
consistent with how `WorldQuery` regression tests are organized.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
The type `ThinSlicePtr` has a manual implementation of `Clone` that
manually clones each field. Since this type implements `Copy`, we can
change this implementation to simply dereference `&self`.
# Objective
I ran into a case where I need to create a `CommandQueue` and push
standard `Command` actions like `Insert` or `Remove` to it manually. I
saw that `Remove` looked as follows:
```rust
struct Remove<T> {
entity: Entity,
phantom: PhantomData<T>
}
```
so naturally, I tried to use `Remove::<Foo>::from(entity)` but it didn't
exist. We need to specify the `PhantomData` explicitly when creating
this command action. The same goes for `RemoveResource` and
`InitResource`
## Solution
This PR implements the following:
- `From<Entity>` for `Remove<T>`
- `Default` for `RemoveResource` and `InitResource`
- use these traits in the implementation of methods of `Commands`
- rename `phantom` field on the structs above to `_phantom` to have a
more uniform field naming scheme for the command actions
---
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
- Added: implemented `From<Entity>` for `Remove<T>` and `Default` for
`RemoveResource` and `InitResource` for ergonomics
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- We support enabling a normal prepass, but the main pass never actually
uses it and recomputes the normals in the main pass. This isn't ideal
since it's doing redundant work.
## Solution
- Use the normal texture from the prepass in the main pass
## Notes
~~I used `NORMAL_PREPASS_ENABLED` as a shader_def because
`NORMAL_PREPASS` is currently used to signify that it is running in the
prepass while this shader_def need to indicate the prepass is done and
the normal prepass was ran before. I'm not sure if there's a better way
to name this.~~
# Objective
Fix#8179
## Solution
- Added `#![warn(missing_docs)]` and document all public items. All
methods on `Gizmos` have doc examples.
- Expanded the docs on the module/crate. Some unfortunate duplication
there :/
- Moved the methods from `GizmoBuffer` to be directly on `Gizmos` and
made `GizmoBuffer` private. This means the methods on `Gizmos` will show
up on its doc page.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow the use of the "glam _assert" feature to help catch runtime
errors and validate the arguments passed to glam.
e.g.
```rs
// Will panic if self is zero length when glam_assert is enabled.
pub fn normalize(self) -> Self {
let normalized = self.mul(self.length_recip());
glam_assert!(normalized.is_finite());
normalized
}
```
## Solution
- Re-export the optional feature glam_assert
---
## Changelog
Added: Optional feature "glam_assert"
# Objective
WebP is a modern image format developed by Google that offers a
significant reduction in file size compared to other image formats such
as PNG and JPEG, while still maintaining good image quality. This makes
it particularly useful for games with large numbers of images, such as
those with high-quality textures or detailed sprites, where file size
and loading times can have a significant impact on performance.
By adding support for WebP images in Bevy, game developers using this
engine can now take advantage of this modern image format and reduce the
memory usage and loading times of their games. This improvement can
ultimately result in a better gaming experience for players.
In summary, the objective of adding WebP image format support in Bevy is
to enable game developers to use a modern image format that provides
better compression rates and smaller file sizes, resulting in faster
loading times and reduced memory usage for their games.
## Solution
To add support for WebP images in Bevy, this pull request leverages the
existing `image` crate support for WebP. This implementation is easily
integrated into the existing Bevy asset-loading system. To maintain
compatibility with existing Bevy projects, WebP image support is
disabled by default, and developers can enable it by adding a feature
flag to their project's `Cargo.toml` file. With this feature, Bevy
becomes even more versatile for game developers and provides a valuable
addition to the game engine.
---
## Changelog
- Added support for WebP image format in Bevy game engine
## Migration Guide
To enable WebP image support in your Bevy project, add the following
line to your project's Cargo.toml file:
```toml
bevy = { version = "*", features = ["webp"]}
```
# Objective
Fixes#8089.
## Solution
Splits the MainPass3dNode into 2 nodes, one for the opaque + alpha
passes and one for the transparent pass.
---
## Changelog
- Split MainPass3dNode into MainOpaquePass3dNode and
MainTransparentPass3dNode
- Combine opaque and alpha phases in MainOpaquePass3dNode into one pass
- Create `START_MAIN_PASS` and `END_MAIN_PASS` empty nodes as labels
- Main pass becomes `START_MAIN_PASS -> MAIN_OPAQUE_PASS ->
MAIN_TRANSPARENT_PASS -> END_MAIN_PASS`
## Migration Guide
Nodes that previously added edges involving `MAIN_PASS` should now add
edges to or from `START_MAIN_PASS` or `END_MAIN_PASS` respectively.

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/7990.
## Solution
- Register needed types, verified pasted code in issue works.
Do I need to register more `Option<T>` types?
# Objective
Fixes#7989
Based on #7991 by @CoffeeVampir3
## Solution
There were three parts to this issue:
1. `extend_where_clause` did not account for the optionality of a where
clause's trailing comma
```rust
// OKAY
struct Foo<T> where T: Asset, {/* ... */}
// ERROR
struct Foo<T> where T: Asset {/* ... */}
```
2. `FromReflect` derive logic was not actively using
`extend_where_clause` which led to some inconsistencies (enums weren't
adding _any_ additional bounds even)
3. Using `extend_where_clause` in the `FromReflect` derive logic meant
we had to optionally add `Default` bounds to ignored fields iff the
entire item itself was not already `Default` (otherwise the definition
for `Handle<T>` wouldn't compile since `HandleType` doesn't impl
`Default` but `Handle<T>` itself does)
---
## Changelog
- Fixed issue where a missing trailing comma could break the reflection
derives
- Fixes#7965
- Code quality improvements.
- Removes the unreferenced function `dither` in pbr_functions.wgsl
introduced in 72fbcc7, but made obsolete in c069c54.
- Makes the reference to `screen_space_dither` in pbr.wgsl conditional
on `#ifdef TONEMAP_IN_SHADER`, as the required import is conditional on
the same, as deband dithering can only occur if tonemapping is also
occurring.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- `Sprite` components are not included in scene (de)serialization.
- Fixes#8206
## Solution
- Add `#[reflect(Component, Default)]` to `Sprite`
- Add `#[derive(FromReflect)]` to `Sprite` and `Anchor`
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy with
```
default-features = false
features = [
"trace_tracy"
]
```
will fail due to `error: The platform you're compiling for is not
supported by winit`
## Solution
- Make bevy_winit/trace optional in trace feature
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
A `RegularPolygon` is described by the circumscribed radius, not the
inscribed radius.
## Objective
- Correct documentation for `RegularPolygon`
## Solution
- Use the correct term
---------
Co-authored-by: Paul Hüber <phueber@kernsp.in>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
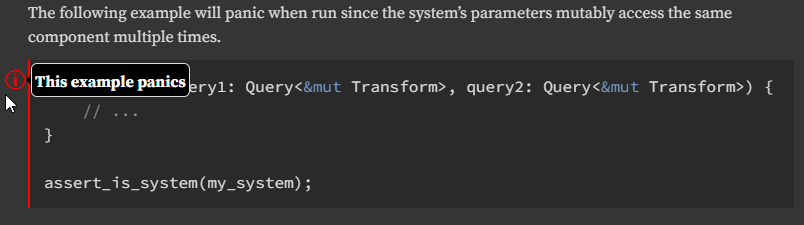
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
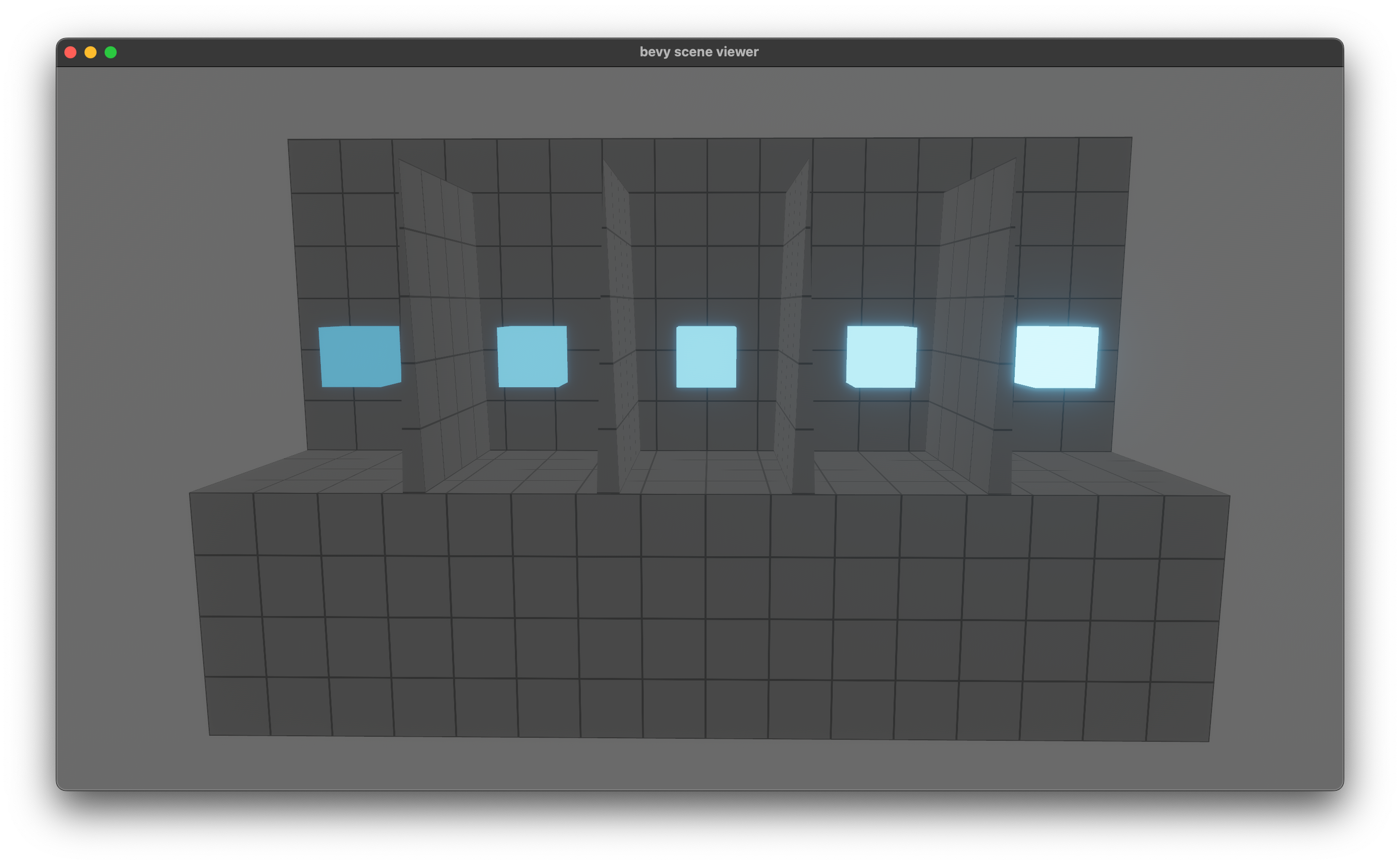
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
Add viewport variants to `Val` that specify a percentage length based on
the size of the window.
## Solution
Add the variants `Vw`, `Vh`, `VMin` and `VMax` to `Val`.
Add a physical window size parameter to the `from_style` function and
use it to convert the viewport variants to Taffy Points values.
One issue: It isn't responsive to window resizes. So `flex_node_system`
has to do a full update every time the window size changes. Perhaps this
can be fixed with support from Taffy.
---
## Changelog
* Added `Val` viewport unit variants `Vw`, `Vh`, `VMin` and `VMax`.
* Modified `convert` module to support the new `Val` variants.
* Changed `flex_node_system` to support the new `Val` variants.
* Perform full layout update on screen resizing, to propagate the new
viewport size to all nodes.
This MR is a rebased and alternative proposal to
https://github.com/bevyengine/bevy/pull/5602
# Objective
- https://github.com/bevyengine/bevy/pull/4447 implemented untyped
(using component ids instead of generics and TypeId) APIs for
inserting/accessing resources and accessing components, but left
inserting components for another PR (this one)
## Solution
- add `EntityMut::insert_by_id`
- split `Bundle` into `DynamicBundle` with `get_components` and `Bundle:
DynamicBundle`. This allows the `BundleInserter` machinery to be reused
for bundles that can only be written, not read, and have no statically
available `ComponentIds`
- Compared to the original MR this approach exposes unsafe endpoints and
requires the user to manage instantiated `BundleIds`. This is quite easy
for the end user to do and does not incur the performance penalty of
checking whether component input is correctly provided for the
`BundleId`.
- This MR does ensure that constructing `BundleId` itself is safe
---
## Changelog
- add methods for inserting bundles and components to:
`world.entity_mut(entity).insert_by_id`
# Objective
Add comments explaining:
* That `Val::Px` is a value in logical pixels
* That `Val::Percent` is based on the length of its parent along a
specific axis.
* How the layout algorithm determines which axis the percentage should
be based on.
# Objective
Co-Authored-By: davier
[bricedavier@gmail.com](mailto:bricedavier@gmail.com)
Fixes#3576.
Adds a `resources` field in scene serialization data to allow
de/serializing resources that have reflection enabled.
## Solution
Most of this code is taken from a previous closed PR:
https://github.com/bevyengine/bevy/pull/3580. Most of the credit goes to
@Davier , what I did was mostly getting it to work on the latest main
branch of Bevy, along with adding a few asserts in the currently
existing tests to be sure everything is working properly.
This PR changes the scene format to include resources in this way:
```
(
resources: {
// List of resources here, keyed by resource type name.
},
entities: [
// Previous scene format here
],
)
```
An example taken from the tests:
```
(
resources: {
"bevy_scene::serde::tests::MyResource": (
foo: 123,
),
},
entities: {
// Previous scene format here
},
)
```
For this, a `resources` fields has been added on the `DynamicScene` and
the `DynamicSceneBuilder` structs. The latter now also has a method
named `extract_resources` to properly extract the existing resources
registered in the local type registry, in a similar way to
`extract_entities`.
---
## Changelog
Added: Reflect resources registered in the type registry used by dynamic
scenes will now be properly de/serialized in scene data.
## Migration Guide
Since the scene format has been changed, the user may not be able to use
scenes saved prior to this PR due to the `resources` scene field being
missing. ~~To preserve backwards compatibility, I will try to make the
`resources` fully optional so that old scenes can be loaded without
issue.~~
## TODOs
- [x] I may have to update a few doc blocks still referring to dynamic
scenes as mere container of entities, since they now include resources
as well.
- [x] ~~I want to make the `resources` key optional, as specified in the
Migration Guide, so that old scenes will be compatible with this
change.~~ Since this would only be trivial for ron format, I think it
might be better to consider it in a separate PR/discussion to figure out
if it could be done for binary serialization too.
- [x] I suppose it might be a good idea to add a resources in the scene
example so that users will quickly notice they can serialize resources
just like entities.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
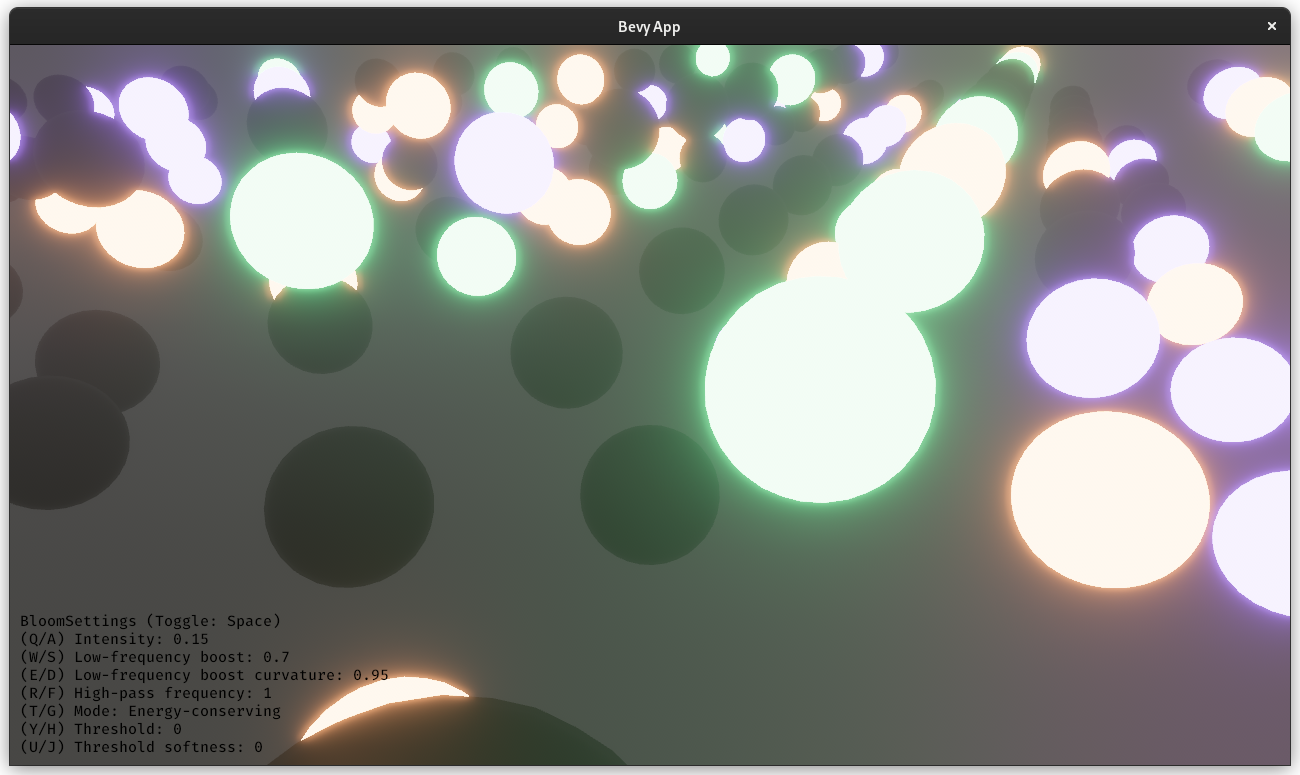
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6760
- adds line and position on line info to scene errors
```text
Before:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)`
After:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)` at scenes/test/scene.scn.ron:10:4
```
## Solution
- use span_error to get position info. This is what the ron crate does
internally to get the position info.
562963f887/src/options.rs (L158)
## Changelog
- added line numbers to scene errors
---------
Co-authored-by: Paul Hansen <mail@paul.rs>
# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
- Currently, https://github.com/vleue/bevy_bistro_playground crashes when enabling shadows, because this allocates a new buffer for the view uniforms, but the `TonemappingNode` uses a cached bind group that doesn't reference the new uniform buffer.
## Solution
- Check if the buffer id of the view uniforms buffer has changed and create a new bind group if it did.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
revert combining pipelines for AlphaMode::Blend and AlphaMode::Premultiplied & Add
the recent blend state pr changed `AlphaMode::Blend` to use a blend state of `Blend::PREMULTIPLIED_ALPHA_BLENDING`, and recovered the original behaviour by multiplying colour by alpha in the standard material's fragment shader.
this had some advantages (specifically it means more material instances can be batched together in future), but this also means that custom materials that specify `AlphaMode::Blend` now get a premultiplied blend state, so they must also multiply colour by alpha.
## Solution
revert that combination to preserve 0.9 behaviour for custom materials with AlphaMode::Blend.
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
Current `Node` doc comment:
```rust
/// The size of the node as width and height in pixels
/// automatically calculated by [`super::flex::flex_node_system`]
```
It should be changed to make it clear that `Node` stores the size in logical pixels, not physical.
# Objective
- Example `transparent_window` doesn't display a transparent window on macOS
- Fixes#6330
## Solution
- Set the `composite_alpha_mode` of the window to the correct value
- Update docs
# Objective
Upgrade to Taffy 0.3.3
Fixes: #7712
## Solution
Upgrade to Taffy 0.3.3 with the `grid` feature disabled.
---
## Changelog
* Changed Taffy version to 0.3.3 and disabled its `grid` feature.
* Added the `Start` and `End` variants to `AlignItems`, `AlignSelf`, `AlignContent` and `JustifyContent`.
* Added the `SpaceEvenly` variant to `AlignContent`.
* Updated `from_style` for Taffy 0.3.3.
# Objective
the current depth bias only adjusts ordering, so it doesn't work for opaque meshes vs alpha-blend meshes, and it doesn't help when two meshes are infinitesimally offset from one another.
## Solution
pass the material's depth bias into the pipeline depth stencil `constant` field.
# Objective
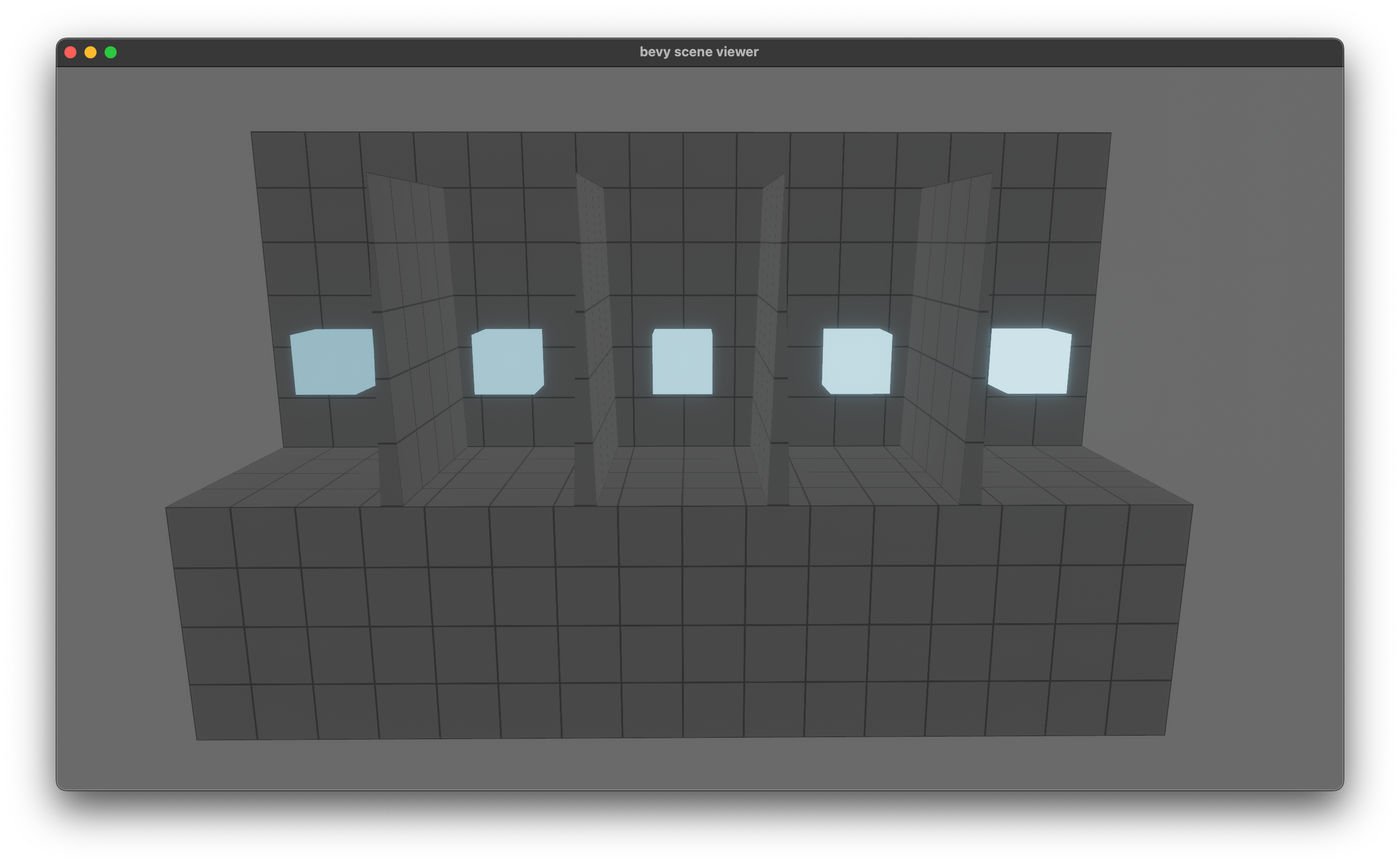
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
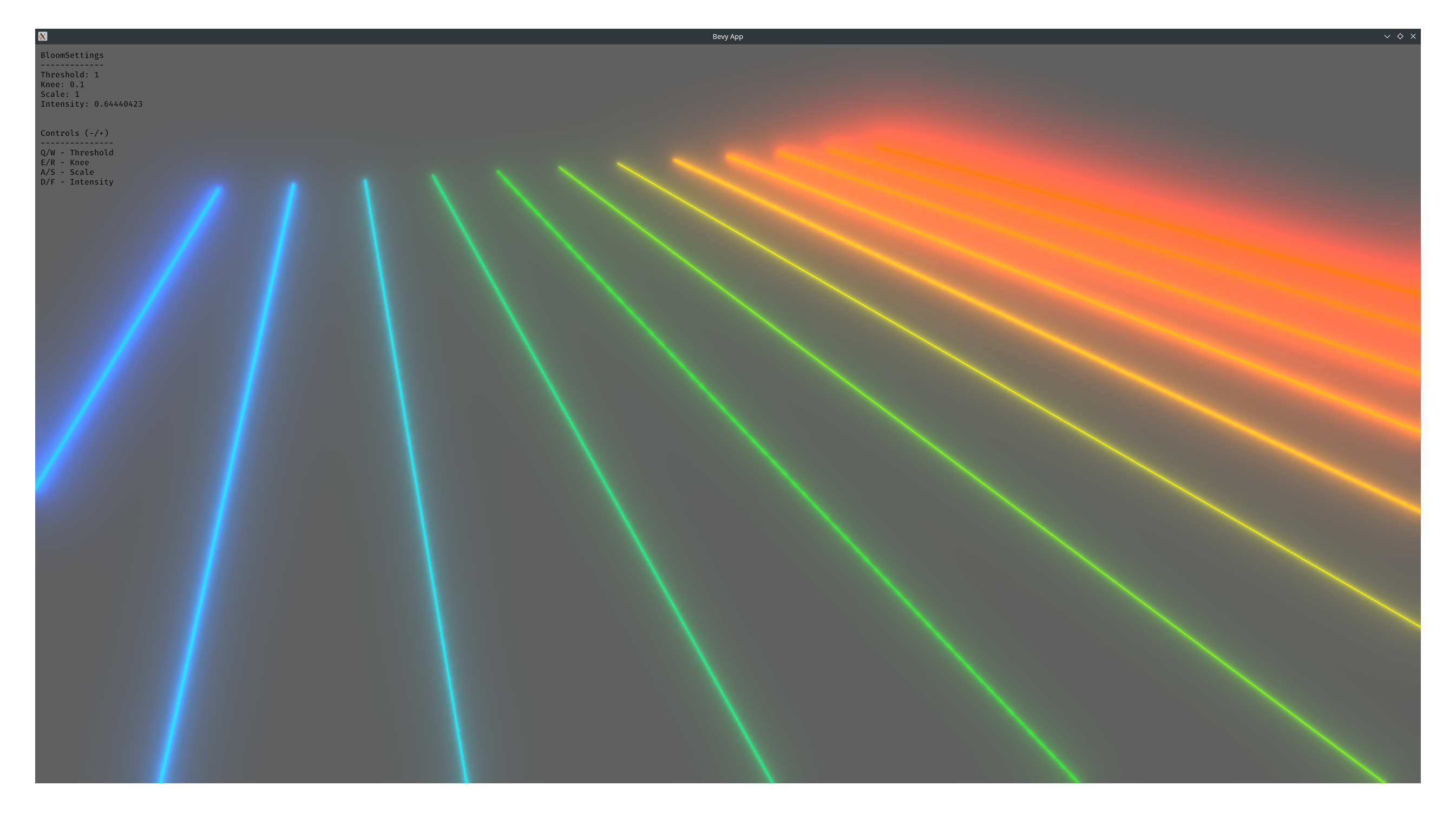
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
- Make cubic splines more flexible and more performant
- Remove the existing spline implementation that is generic over many degrees
- This is a potential performance footgun and adds type complexity for negligible gain.
- Add implementations of:
- Bezier splines
- Cardinal splines (inc. Catmull-Rom)
- B-Splines
- Hermite splines
https://user-images.githubusercontent.com/2632925/221780519-495d1b20-ab46-45b4-92a3-32c46da66034.mp4https://user-images.githubusercontent.com/2632925/221780524-2b154016-699f-404f-9c18-02092f589b04.mp4https://user-images.githubusercontent.com/2632925/221780525-f934f99d-9ad4-4999-bae2-75d675f5644f.mp4
## Solution
- Implements the concept that splines are curve generators (e.g. https://youtu.be/jvPPXbo87ds?t=3488) via the `CubicGenerator` trait.
- Common splines are bespoke data types that implement this trait. This gives us flexibility to add custom spline-specific methods on these types, while ultimately all generating a `CubicCurve`.
- All splines generate `CubicCurve`s, which are a chain of precomputed polynomial coefficients. This means that all splines have the same evaluation cost, as the calculations for determining position, velocity, and acceleration are all identical. In addition, `CubicCurve`s are simply a list of `CubicSegment`s, which are evaluated from t=0 to t=1. This also means cubic splines of different type can be chained together, as ultimately they all are simply a collection of `CubicSegment`s.
- Because easing is an operation on a singe segment of a Bezier curve, we can simply implement easing on `Beziers` that use the `Vec2` type for points. Higher level crates such as `bevy_ui` can wrap this in a more ergonomic interface as needed.
### Performance
Measured on a desktop i5 8600K (6-year-old CPU):
- easing: 2.7x faster (19ns)
- cubic vec2 position sample: 1.5x faster (1.8ns)
- cubic vec3 position sample: 1.5x faster (2.6ns)
- cubic vec3a position sample: 1.9x faster (1.4ns)
On a laptop i7 11800H:
- easing: 16ns
- cubic vec2 position sample: 1.6ns
- cubic vec3 position sample: 2.3ns
- cubic vec3a position sample: 1.2ns
---
## Changelog
- Added a generic cubic curve trait, and implementation for Cardinal splines (including Catmull-Rom), B-Splines, Beziers, and Hermite Splines. 2D cubic curve segments also implement easing functionality for animation.
# Objective
Unfortunately, there are three issues with my changes introduced by #7784.
1. The changes left some dead code. This is already taken care of here: #7875.
2. Disabling prepass causes failures because the shadow mapping relies on the `PrepassPlugin` now.
3. Custom materials use the `prepass.wgsl` shader, but this does not always define a fragment entry point.
This PR fixes 2. and 3. and resolves#7879.
## Solution
- Add a regression test with disabled prepass.
- Split `PrepassPlugin` into two plugins:
- `PrepassPipelinePlugin` contains the part that is required for the shadow mapping to work and is unconditionally added.
- `PrepassPlugin` now only adds the systems and resources required for the "real" prepasses.
- Add a noop fragment entry point to `prepass.wgsl`, used if `NORMAL_PASS` is not defined.
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
- Fixes#7874.
- The `bevy_text` dependency is optional for `bevy_ui`, but the `accessibility` module depended on it.
## Solution
- Guard the `accessibility` module behind the `bevy_text` feature and only add the plugin when it's enabled.
# Objective
- Remove dead code after #7784
# Changelog
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Migration Guide
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
# Objective
Fixes#7864
## Solution
Add the run conditions described in the issue. Also needed to add `bevy` as a dev dependency to `bevy_time` so the doctests can run.
---
## Changelog
- Add `on_timer` and `on_fixed_timer` run conditions
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
- Fixes#4372.
## Solution
- Use the prepass shaders for the shadow passes.
- Move `DEPTH_CLAMP_ORTHO` from `ShadowPipelineKey` to `MeshPipelineKey` and the associated clamp operation from `depth.wgsl` to `prepass.wgsl`.
- Remove `depth.wgsl` .
- Replace `ShadowPipeline` with `ShadowSamplers`.
Instead of running the custom `ShadowPipeline` we run the `PrepassPipeline` with the `DEPTH_PREPASS` flag and additionally the `DEPTH_CLAMP_ORTHO` flag for directional lights as well as the `ALPHA_MASK` flag for materials that use `AlphaMode::Mask(_)`.
# Objective
Fixes#7797
## Solution
This **seems** like a simple fix, but I'm not 100% confident and I may have messed up the math in some way. In particular, I'm not sure what I should be using for an FOV value.
However, this seems to be producing similar results to 0.9.
Here's the `orthographic` example with a default directional light.
edit: better screen grab below.
# Objective
Fixes#6780
## Solution
- record the asset path of each watched file
- call `AssetIo::watch_for_changes` in `LoadContext::read_asset_bytes`
---
## Changelog
### Fixed
- fixed hot reloading for `LoadContext::read_asset_bytes`
### Changed
- `AssetIo::watch_path_for_changes` allows watched path and path to reload to differ
## Migration Guide
- for custom `AssetIo`s, differentiate paths to watch and asset paths to reload as a consequence
Co-authored-by: Vincent Junge <specificprotagonist@posteo.org>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
UIs created for Bevy cannot currently be made accessible. This PR aims to address that.
## Solution
Integrate AccessKit as a dependency, adding accessibility support to existing bevy_ui widgets.
## Changelog
### Added
* Integrate with and expose [AccessKit](https://accesskit.dev) for platform accessibility.
* Add `Label` for marking text specifically as a label for UI controls.
# Objective
Alternative to #7490. I wrote all of the code in this PR, but I have added @robtfm as co-author on commits that build on ideas from #7490. I would not have been able to solve these problems on my own without much more time investment and I'm largely just rephrasing the ideas from that PR.
Fixes#7435Fixes#7361Fixes#5721
## Solution
This implements the solution I [outlined here](https://github.com/bevyengine/bevy/pull/7490#issuecomment-1426580633).
* Adds "msaa writeback" as an explicit "msaa camera feature" and default to msaa_writeback: true for each camera. If this is true, a camera has MSAA enabled, and it isn't the first camera for the target, add a writeback before the main pass for that camera.
* Adds a CameraOutputMode, which can be used to configure if (and how) the results of a camera's rendering will be written to the final RenderTarget output texture (via the upscaling node). The `blend_state` and `color_attachment_load_op` are now configurable, giving much more control over how a camera will write to the output texture.
* Made cameras with the same target share the same main_texture tracker by using `Arc<AtomicUsize>`, which ensures continuity across cameras. This was previously broken / could produce weird results in some cases. `ViewTarget::main_texture()` is now correct in every context.
* Added a new generic / specializable BlitPipeline, which the new MsaaWritebackNode uses internally. The UpscalingPipelineNode now uses BlitPipeline instead of its own pipeline. We might ultimately need to fork this back out if we choose to add more configurability to the upscaling, but for now this will save on binary size by not embedding the same shader twice.
* Moved the "camera sorting" logic from the camera driver node to its own system. The results are now stored in the `SortedCameras` resource, which can be used anywhere in the renderer. MSAA writeback makes use of this.
---
## Changelog
- Added `Camera::msaa_writeback` which can enable and disable msaa writeback.
- Added specializable `BlitPipeline` and ported the upscaling node to use this.
- Added SortedCameras, exposing information that was previously internal to the camera driver node.
- Made cameras with the same target share the same main_texture tracker, which ensures continuity across cameras.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
Text2d entity's text needs to be recomputed when their bounds are changed, but it isn't.
# Solution
Change `update_text2d_layout` to query for `Ref<Text2dBounds>` and recompute the text if the bounds have changed.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
# Objective
Implement `Reflect` for `std::collections::HashMap<K, V, S>` as well as `hashbrown::HashMap<K, V, S>` rather than just for `hashbrown::HashMap<K, V, RandomState>`. Fixes#7739.
## Solution
Rather than implementing on `HashMap<K, V>` I instead implemented most of the related traits on `HashMap<K, V, S> where S: BuildHasher + Send + Sync + 'static` and then `FromReflect` also needs the extra bound `S: Default` because it needs to use `with_capacity_and_hasher` so needs to be able to generate a default hasher.
As the API of `hashbrown::HashMap` is identical to `collections::HashMap` making them both work just required creating an `impl_reflect_for_hashmap` macro like the `impl_reflect_for_veclike` above and then applying this to both HashMaps.
---
## Changelog
`std::collections::HashMap` can now be reflected. Also more `State` generics than just `RandomState` can now be reflected for both `hashbrown::HashMap` and `collections::HashMap`
# Objective
Fix#7544. Update docs for `Window::transparent` regarding Windows 11 platform support. Following the update to winit 0.28, this has been fixed.
## Solution
Remove the mention in the docs.
`EntityMut::move_entity_from_remove` had two soundness bugs:
- When removing the entity from the archetype, the swapped entity had its table row updated to the same as the removed entity's
- When removing the entity from the table, the swapped entity did not have its table row updated
`BundleInsert::insert` had two/three soundness bugs
- When moving an entity to a new archetype from an `insert`, the swapped entity had its table row set to a different entities
- When moving an entity to a new table from an `insert`, the swapped entity did not have its table row updated
See added tests for examples that trigger those bugs
`EntityMut::despawn` had two soundness bugs
- When despawning an entity, the swapped entity had its table row set to a different entities even if the table didnt change
- When despawning an entity, the swapped entity did not have its table row updated
# Objective
- A more intuitive distinction between the two. `remove_intersection` is verbose and unclear.
- `EntityMut::remove` and `Commands::remove` should match.
## Solution
- What the title says.
---
## Migration Guide
Before
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).remove::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove_intersection::<Parent>();
}
}
}
```
After
```rust
fn clear_children(parent: Entity, world: &mut World) {
if let Some(children) = world.entity_mut(parent).take::<Children>() {
for &child in &children.0 {
world.entity_mut(child).remove::<Parent>();
}
}
}
```
# Objective
Common run conditions can be very useful for quick and ergonomic changes to when a system runs.
Specifically what I'd like to be able to do is
```rust
use bevy::prelude::*;
use bevy::input::common_conditions::input_toggle_active;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(
bevy_inspector_egui::quick::WorldInspectorPlugin::default()
.run_if(input_toggle_active(true, KeyCode::Escape)
)
.run();
}
```
## Solution
- add `bevy_input::common_conditions` module with `input_toggle_active`, `input_pressed`, `input_just_pressed`, `input_just_released`
## Changelog
- added common run conditions for `bevy_input`
- you can now use `.add_system(jump.run_if(input_just_pressed(KeyCode::Space)))`
# Objective
There were a couple primitive types missing from the default `TypeRegistry` constructor.
## Solution
Added the missing registrations for `char` and `String`.
# Objective
A couple of places in `bevy_app` use a scoped block that doesn't do anything. I imagine these are a relic from when `Mut<T>` implemented `Drop` in the early days of bevy.
## Solution
Remove the scopes.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
Alternative to #7804
Allows other instances of the `sync_simple_transforms` and `propagate_transforms` systems to be added.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
While working on #7784, I noticed that a `#define VAR` in a `.wgsl` file is always effective, even if it its scope is not accepting lines.
Example:
```c
#define A
#ifndef A
#define B
#endif
```
Currently, `B` will be defined although it shouldn't. This PR fixes that.
## Solution
Move the branch responsible for `#define` lines into the last else branch, which is only evaluated if the current scope is accepting lines.
# Objective
- `bevy_text` used to be "optional". the feature could be disabled, which meant that the systems were not added but `bevy_text` was still compiled because of a hard dependency in `bevy_ui`
- Running something without `bevy_text` enabled and with `bevy_ui` enabled now crashes:
```
thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /bevy/crates/bevy_ecs/src/schedule/schedule.rs:1147:34
```
- This is because `bevy_ui` declares some of its systems in ambiguity sets with systems from `bevy_text`, which were not added if `bevy_text` is disabled
## Solution
- Make `bevy_text` completely optional
## Migration Guide
- feature `bevy_text` now completely removes `bevy_text` from the dependencies when not enabled. Enable feature `bevy_text` if you use Bevy to render text
# Objective
While we use `#[doc(hidden)]` to try and hide marker generics from the user, these types reveal themselves in compiler errors, adding visual noise and confusion.
## Solution
Replace the `AlreadyWasSystem` marker generic with `()`, to reduce visual noise in error messages. This also makes it possible to return `impl Condition<()>` from combinators.
For function systems, use their function signature as the marker type. This should drastically improve the legibility of some error messages.
The `InputMarker` type has been removed, since it is unnecessary.
# Objective
Several places in the ECS use marker generics to avoid overlapping trait implementations, but different places alternately refer to it as `Params` and `Marker`. This is potentially confusing, since it might not be clear that the same pattern is being used. Additionally, users might be misled into thinking that the `Params` type corresponds to the `SystemParam`s of a system.
## Solution
Rename `Params` to `Marker`.
# Objective
There was PR that introduced support for storage buffer is `AsBindGroup` macro [#6129](https://github.com/bevyengine/bevy/pull/6129), but it does not give more granular control over storage buffer, it will always copy all the data no matter which part of it was updated. There is also currently another open PR #6669 that tries to achieve exactly that, it is just not up to date and seems abandoned (Sorry if that is not right). In this PR I'm proposing a solution for both of these approaches to co-exist using `#[storage(n, buffer)]` and `#[storage(n)]` to distinguish between the cases.
We could also discuss in this PR if there is a need to extend this support to DynamicBuffers as well.
# Objective
Fixes#3980
## Solution
Added examples to show how to run a `Schedule`, one with a unique system, and another with several systems
---
## Changelog
- Added: examples in docs to show how to run a `Schedule`
Co-authored-by: remiCzn <77072160+remiCzn@users.noreply.github.com>
# Objective
The `BoxedCondition` type alias does not require the underlying system to be read-only.
## Solution
Define the type alias using `ReadOnlySystem` instead of `System`.
Graph theory make head hurty. Closes#7367.
Basically, when we topologically sort the dependency graph, we already find its strongly-connected components (a really [neat algorithm][1]). This PR adds an algorithm that can dissect those into simple cycles, giving us more useful error reports.
test: `system_build_errors::dependency_cycle`
```
schedule has 1 before/after cycle(s):
cycle 1: system set 'A' must run before itself
system set 'A'
... which must run before system set 'B'
... which must run before system set 'A'
```
```
schedule has 1 before/after cycle(s):
cycle 1: system 'foo' must run before itself
system 'foo'
... which must run before system 'bar'
... which must run before system 'foo'
```
test: `system_build_errors::hierarchy_cycle`
```
schedule has 1 in_set cycle(s):
cycle 1: system set 'A' contains itself
system set 'A'
... which contains system set 'B'
... which contains system set 'A'
```
[1]: https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}