# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
- Currently, https://github.com/vleue/bevy_bistro_playground crashes when enabling shadows, because this allocates a new buffer for the view uniforms, but the `TonemappingNode` uses a cached bind group that doesn't reference the new uniform buffer.
## Solution
- Check if the buffer id of the view uniforms buffer has changed and create a new bind group if it did.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
revert combining pipelines for AlphaMode::Blend and AlphaMode::Premultiplied & Add
the recent blend state pr changed `AlphaMode::Blend` to use a blend state of `Blend::PREMULTIPLIED_ALPHA_BLENDING`, and recovered the original behaviour by multiplying colour by alpha in the standard material's fragment shader.
this had some advantages (specifically it means more material instances can be batched together in future), but this also means that custom materials that specify `AlphaMode::Blend` now get a premultiplied blend state, so they must also multiply colour by alpha.
## Solution
revert that combination to preserve 0.9 behaviour for custom materials with AlphaMode::Blend.
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
Current `Node` doc comment:
```rust
/// The size of the node as width and height in pixels
/// automatically calculated by [`super::flex::flex_node_system`]
```
It should be changed to make it clear that `Node` stores the size in logical pixels, not physical.
# Objective
- Example `transparent_window` doesn't display a transparent window on macOS
- Fixes#6330
## Solution
- Set the `composite_alpha_mode` of the window to the correct value
- Update docs
# Objective
Upgrade to Taffy 0.3.3
Fixes: #7712
## Solution
Upgrade to Taffy 0.3.3 with the `grid` feature disabled.
---
## Changelog
* Changed Taffy version to 0.3.3 and disabled its `grid` feature.
* Added the `Start` and `End` variants to `AlignItems`, `AlignSelf`, `AlignContent` and `JustifyContent`.
* Added the `SpaceEvenly` variant to `AlignContent`.
* Updated `from_style` for Taffy 0.3.3.
# Objective
the current depth bias only adjusts ordering, so it doesn't work for opaque meshes vs alpha-blend meshes, and it doesn't help when two meshes are infinitesimally offset from one another.
## Solution
pass the material's depth bias into the pipeline depth stencil `constant` field.
# Objective
Simple text pipeline benchmark. It's quite expensive but current examples don't capture the performance of `queue_text` as it only runs on changes to the text.
# Objective
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
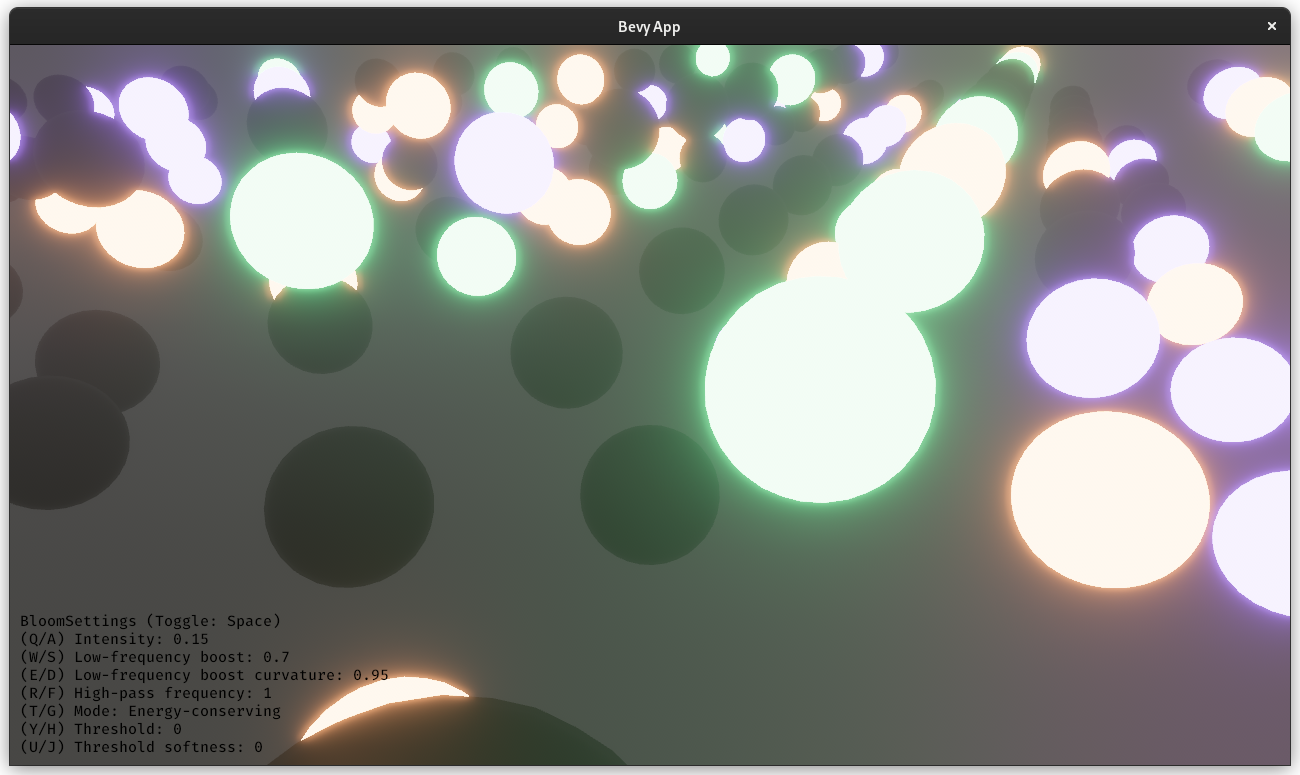
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
- Make cubic splines more flexible and more performant
- Remove the existing spline implementation that is generic over many degrees
- This is a potential performance footgun and adds type complexity for negligible gain.
- Add implementations of:
- Bezier splines
- Cardinal splines (inc. Catmull-Rom)
- B-Splines
- Hermite splines
https://user-images.githubusercontent.com/2632925/221780519-495d1b20-ab46-45b4-92a3-32c46da66034.mp4https://user-images.githubusercontent.com/2632925/221780524-2b154016-699f-404f-9c18-02092f589b04.mp4https://user-images.githubusercontent.com/2632925/221780525-f934f99d-9ad4-4999-bae2-75d675f5644f.mp4
## Solution
- Implements the concept that splines are curve generators (e.g. https://youtu.be/jvPPXbo87ds?t=3488) via the `CubicGenerator` trait.
- Common splines are bespoke data types that implement this trait. This gives us flexibility to add custom spline-specific methods on these types, while ultimately all generating a `CubicCurve`.
- All splines generate `CubicCurve`s, which are a chain of precomputed polynomial coefficients. This means that all splines have the same evaluation cost, as the calculations for determining position, velocity, and acceleration are all identical. In addition, `CubicCurve`s are simply a list of `CubicSegment`s, which are evaluated from t=0 to t=1. This also means cubic splines of different type can be chained together, as ultimately they all are simply a collection of `CubicSegment`s.
- Because easing is an operation on a singe segment of a Bezier curve, we can simply implement easing on `Beziers` that use the `Vec2` type for points. Higher level crates such as `bevy_ui` can wrap this in a more ergonomic interface as needed.
### Performance
Measured on a desktop i5 8600K (6-year-old CPU):
- easing: 2.7x faster (19ns)
- cubic vec2 position sample: 1.5x faster (1.8ns)
- cubic vec3 position sample: 1.5x faster (2.6ns)
- cubic vec3a position sample: 1.9x faster (1.4ns)
On a laptop i7 11800H:
- easing: 16ns
- cubic vec2 position sample: 1.6ns
- cubic vec3 position sample: 2.3ns
- cubic vec3a position sample: 1.2ns
---
## Changelog
- Added a generic cubic curve trait, and implementation for Cardinal splines (including Catmull-Rom), B-Splines, Beziers, and Hermite Splines. 2D cubic curve segments also implement easing functionality for animation.
# Objective
Unfortunately, there are three issues with my changes introduced by #7784.
1. The changes left some dead code. This is already taken care of here: #7875.
2. Disabling prepass causes failures because the shadow mapping relies on the `PrepassPlugin` now.
3. Custom materials use the `prepass.wgsl` shader, but this does not always define a fragment entry point.
This PR fixes 2. and 3. and resolves#7879.
## Solution
- Add a regression test with disabled prepass.
- Split `PrepassPlugin` into two plugins:
- `PrepassPipelinePlugin` contains the part that is required for the shadow mapping to work and is unconditionally added.
- `PrepassPlugin` now only adds the systems and resources required for the "real" prepasses.
- Add a noop fragment entry point to `prepass.wgsl`, used if `NORMAL_PASS` is not defined.
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
- Fixes#7874.
- The `bevy_text` dependency is optional for `bevy_ui`, but the `accessibility` module depended on it.
## Solution
- Guard the `accessibility` module behind the `bevy_text` feature and only add the plugin when it's enabled.
# Objective
- Remove dead code after #7784
# Changelog
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Migration Guide
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
# Objective
Fixes#7864
## Solution
Add the run conditions described in the issue. Also needed to add `bevy` as a dev dependency to `bevy_time` so the doctests can run.
---
## Changelog
- Add `on_timer` and `on_fixed_timer` run conditions
…or's ticker for one thread.
# Objective
- Fix debug_asset_server hang.
## Solution
- Reuse the thread_local executor for MainThreadExecutor resource, so there will be only one ThreadExecutor for main thread.
- If ThreadTickers from same executor, they are conflict with each other. Then only tick one.
# Objective
- Fixes#4372.
## Solution
- Use the prepass shaders for the shadow passes.
- Move `DEPTH_CLAMP_ORTHO` from `ShadowPipelineKey` to `MeshPipelineKey` and the associated clamp operation from `depth.wgsl` to `prepass.wgsl`.
- Remove `depth.wgsl` .
- Replace `ShadowPipeline` with `ShadowSamplers`.
Instead of running the custom `ShadowPipeline` we run the `PrepassPipeline` with the `DEPTH_PREPASS` flag and additionally the `DEPTH_CLAMP_ORTHO` flag for directional lights as well as the `ALPHA_MASK` flag for materials that use `AlphaMode::Mask(_)`.
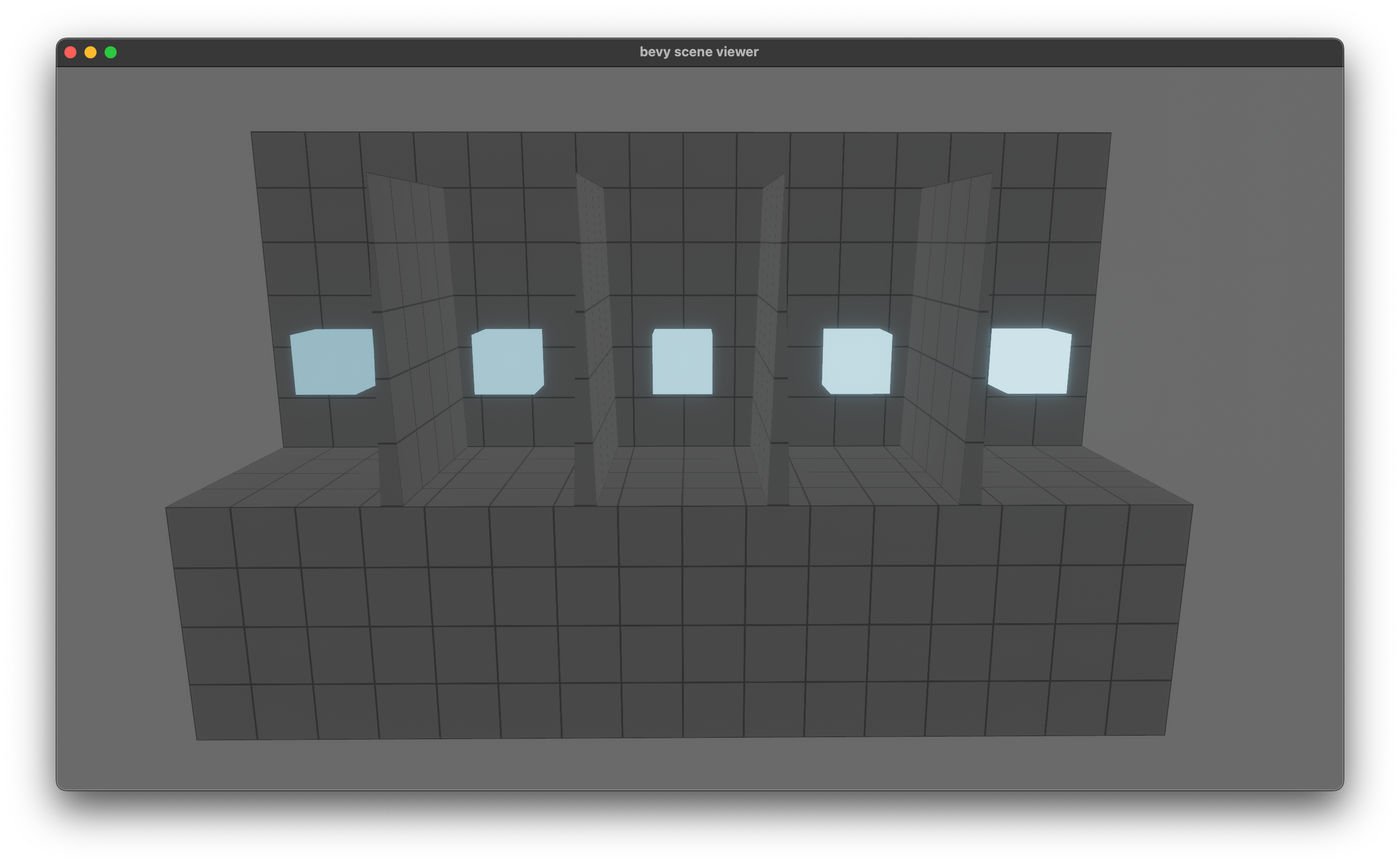
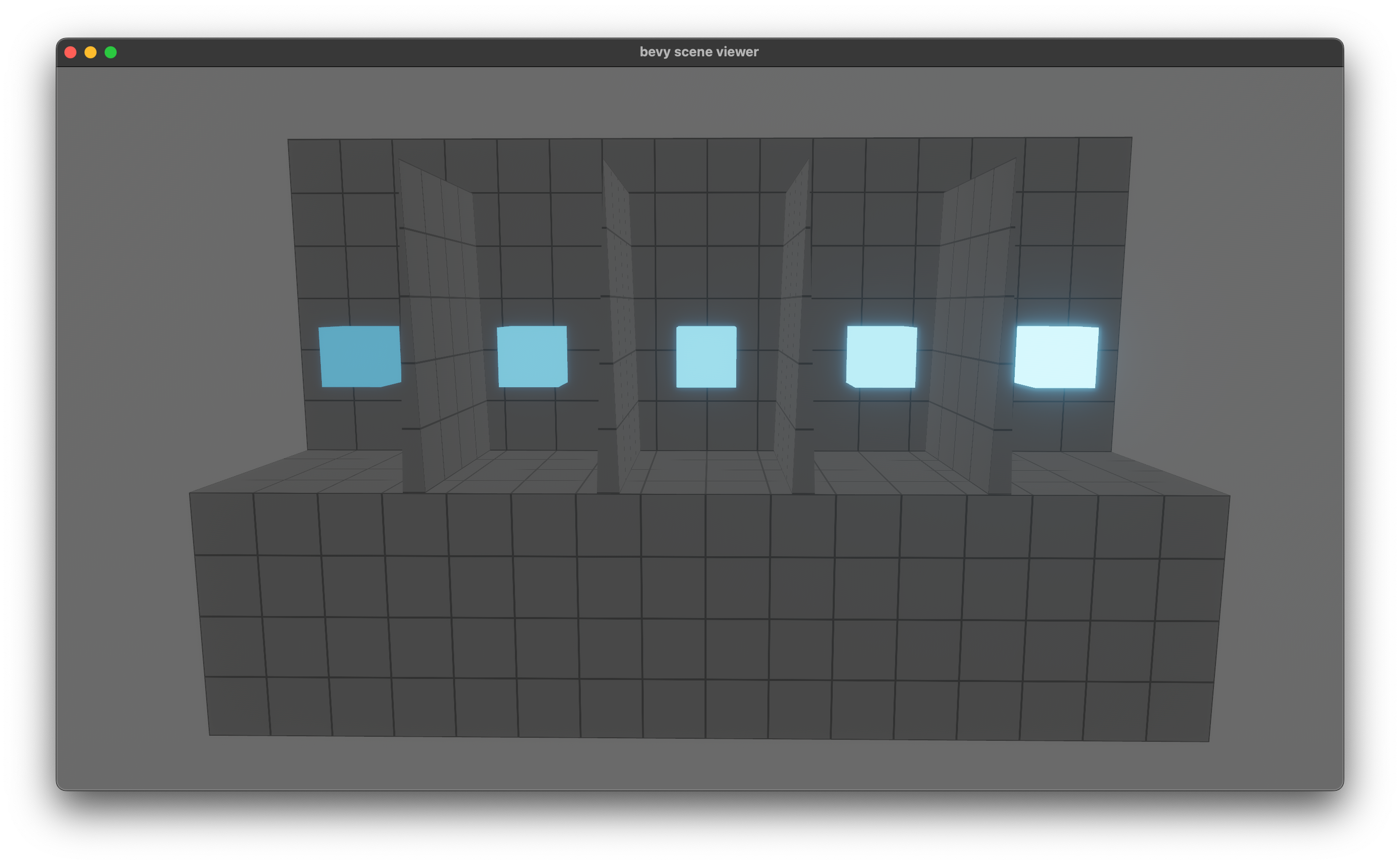
# Objective
Fixes#7797
## Solution
This **seems** like a simple fix, but I'm not 100% confident and I may have messed up the math in some way. In particular, I'm not sure what I should be using for an FOV value.
However, this seems to be producing similar results to 0.9.
Here's the `orthographic` example with a default directional light.
edit: better screen grab below.
# Objective
Fixes#6780
## Solution
- record the asset path of each watched file
- call `AssetIo::watch_for_changes` in `LoadContext::read_asset_bytes`
---
## Changelog
### Fixed
- fixed hot reloading for `LoadContext::read_asset_bytes`
### Changed
- `AssetIo::watch_path_for_changes` allows watched path and path to reload to differ
## Migration Guide
- for custom `AssetIo`s, differentiate paths to watch and asset paths to reload as a consequence
Co-authored-by: Vincent Junge <specificprotagonist@posteo.org>
# Objective
- Use the prepass textures in webgl
## Solution
- Bind the prepass textures even when using webgl, but only if msaa is disabled
- Also did some refactors to centralize how textures are bound, similar to the EnvironmentMapLight PR
- ~~Also did some refactors of the example to make it work in webgl~~
- ~~To make the example work in webgl, I needed to use a sampler for the depth texture, the resulting code looks a bit weird, but it's simple enough and I think it's worth it to show how it works when using webgl~~
# Objective
UIs created for Bevy cannot currently be made accessible. This PR aims to address that.
## Solution
Integrate AccessKit as a dependency, adding accessibility support to existing bevy_ui widgets.
## Changelog
### Added
* Integrate with and expose [AccessKit](https://accesskit.dev) for platform accessibility.
* Add `Label` for marking text specifically as a label for UI controls.
# Objective
Alternative to #7490. I wrote all of the code in this PR, but I have added @robtfm as co-author on commits that build on ideas from #7490. I would not have been able to solve these problems on my own without much more time investment and I'm largely just rephrasing the ideas from that PR.
Fixes#7435Fixes#7361Fixes#5721
## Solution
This implements the solution I [outlined here](https://github.com/bevyengine/bevy/pull/7490#issuecomment-1426580633).
* Adds "msaa writeback" as an explicit "msaa camera feature" and default to msaa_writeback: true for each camera. If this is true, a camera has MSAA enabled, and it isn't the first camera for the target, add a writeback before the main pass for that camera.
* Adds a CameraOutputMode, which can be used to configure if (and how) the results of a camera's rendering will be written to the final RenderTarget output texture (via the upscaling node). The `blend_state` and `color_attachment_load_op` are now configurable, giving much more control over how a camera will write to the output texture.
* Made cameras with the same target share the same main_texture tracker by using `Arc<AtomicUsize>`, which ensures continuity across cameras. This was previously broken / could produce weird results in some cases. `ViewTarget::main_texture()` is now correct in every context.
* Added a new generic / specializable BlitPipeline, which the new MsaaWritebackNode uses internally. The UpscalingPipelineNode now uses BlitPipeline instead of its own pipeline. We might ultimately need to fork this back out if we choose to add more configurability to the upscaling, but for now this will save on binary size by not embedding the same shader twice.
* Moved the "camera sorting" logic from the camera driver node to its own system. The results are now stored in the `SortedCameras` resource, which can be used anywhere in the renderer. MSAA writeback makes use of this.
---
## Changelog
- Added `Camera::msaa_writeback` which can enable and disable msaa writeback.
- Added specializable `BlitPipeline` and ported the upscaling node to use this.
- Added SortedCameras, exposing information that was previously internal to the camera driver node.
- Made cameras with the same target share the same main_texture tracker, which ensures continuity across cameras.
# Objective
The `ScheduleBuildError` type has a `Display` implementation which beautifully formats the error. However, schedule build errors are currently reported using `unwrap()`, which uses the `Debug` implementation and makes the error message look unfished.
## Solution
Use `unwrap_or_else` so we can customize the formatting of the error message.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
- Fixes#1800, fixes#6984
- Alternative to #7196
- Ensure feature list is always up to date and that all are documented
- Help discovery of features
## Solution
- Use a template to update the cargo feature list
- Use the comment just above the feature declaration as the description
- Add the checks to CI
- Add the features to the base crate doc
# Objective
Text2d entity's text needs to be recomputed when their bounds are changed, but it isn't.
# Solution
Change `update_text2d_layout` to query for `Ref<Text2dBounds>` and recompute the text if the bounds have changed.
# Objective
There is a panic that occurs when creating a run condition that accesses `NonSend` resources, but it refers to them as 'thread-local' resources instead.
## Solution
Correct the terminology.
# Objective
This PR adds an example that shows how to use `apply_system_buffers` and how to order it with respect to the relevant systems. It also shows how not ordering the systems can lead to unexpected behaviours.
## Solution
Add the example.
# Objective
This is a follow-up to #7745. An unbounded `async_channel` occasionally allocates whenever it exceeds the capacity of the current buffer in it's internal linked list. This is avoidable.
This also used to be a bounded channel before stageless, which was introduced in #4919.
## Solution
Use a bounded channel to avoid allocations on system completion.
This shouldn't conflict with #7745, as it's impossible for the scheduler to exceed the channel capacity, even if somehow every system completed at the same time.
# Objective
Implement `Reflect` for `std::collections::HashMap<K, V, S>` as well as `hashbrown::HashMap<K, V, S>` rather than just for `hashbrown::HashMap<K, V, RandomState>`. Fixes#7739.
## Solution
Rather than implementing on `HashMap<K, V>` I instead implemented most of the related traits on `HashMap<K, V, S> where S: BuildHasher + Send + Sync + 'static` and then `FromReflect` also needs the extra bound `S: Default` because it needs to use `with_capacity_and_hasher` so needs to be able to generate a default hasher.
As the API of `hashbrown::HashMap` is identical to `collections::HashMap` making them both work just required creating an `impl_reflect_for_hashmap` macro like the `impl_reflect_for_veclike` above and then applying this to both HashMaps.
---
## Changelog
`std::collections::HashMap` can now be reflected. Also more `State` generics than just `RandomState` can now be reflected for both `hashbrown::HashMap` and `collections::HashMap`
# Objective
Fix#7544. Update docs for `Window::transparent` regarding Windows 11 platform support. Following the update to winit 0.28, this has been fixed.
## Solution
Remove the mention in the docs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}