# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
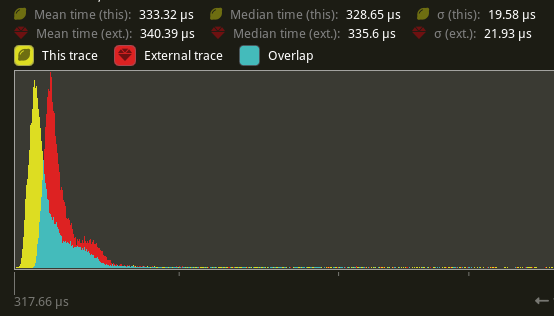
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes#7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
Fix#5248.
## Solution
Support `In<T>` parameters and allow returning arbitrary types in exclusive systems.
---
## Changelog
- Exclusive systems may now be used with system piping.
## Migration Guide
Exclusive systems (systems that access `&mut World`) now support system piping, so the `ExclusiveSystemParamFunction` trait now has generics for the `In`put and `Out`put types.
```rust
// Before
fn my_generic_system<T, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<Param>
{ ... }
// After
fn my_generic_system<T, In, Out, Param>(system_function: T)
where T: ExclusiveSystemParamFunction<In, Out, Param>
{ ... }
```
# Objective
There are some utility functions for actually working with `Storages` inside `entity_ref.rs` that are used both for `EntityRef/EntityMut` and `World`, with a `// TODO: move to Storages`.
This PR moves them to private methods on `World`, because that's the safest API boundary. On `Storages` you would need to ensure that you pass `Components` from the same world.
## Solution
- move get_component[_with_type], get_ticks[_with_type], get_component_and_ticks[_with_type] to `World` (still pub(crate))
- replace `pub use entity_ref::*;` with `pub use entity_ref::{EntityRef, EntityMut}` and qualified `entity_ref::get_mut[_by_id]` in `world.rs`
- add safety comments to a bunch of methods
# Objective
* `World::init_resource` and `World::get_resource_or_insert_with` are implemented naively, and as such they perform duplicate `TypeId -> ComponentId` lookups.
* `World::get_resource_or_insert_with` contains an additional duplicate `ComponentId -> ResourceData` lookup.
* This function also contains an unnecessary panic branch, which we rely on the optimizer to be able to remove.
## Solution
Implement the functions using engine-internal code, instead of combining high-level functions. This allows computed variables to persist across different branches, instead of being recomputed.
# Objective
Following #6681, both `TableRow` and `TableId` are now part of `EntityLocation`. However, the safety invariant on `EntityLocation` requires that all of the constituent fields are `repr(transprent)` or `repr(C)` and the bit pattern of all 1s must be valid. This is not true for `TableRow` and `TableId` currently.
## Solution
Mark `TableRow` and `TableId` to satisfy the safety requirement. Add safety comments on `ArchetypeId`, `ArchetypeRow`, `TableId` and `TableRow`.
# Objective
Improve safety testing when using `bevy_ptr` types. This is a follow-up to #7113.
## Solution
Add a debug-only assertion that pointers are aligned when casting to a concrete type. This should very quickly catch any unsoundness from unaligned pointers, even without miri. However, this can have a large negative perf impact on debug builds.
---
## Changelog
Added: `Ptr::deref` will now panic in debug builds if the pointer is not aligned.
Added: `PtrMut::deref_mut` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::read` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::drop_as` will now panic in debug builds if the pointer is not aligned.
# Objective
`MutUntyped` is a struct that stores a `PtrMut` alongside change tick metadata. Working with this type is cumbersome, and has few benefits over storing the pointer and change ticks separately.
Related: #6430 (title is out of date)
## Solution
Add a convenience method for transforming an untyped change detection pointer into its typed counterpart.
---
## Changelog
- Added the method `MutUntyped::with_type`.
# Objective
- Fixes#7066
## Solution
- Split the ChangeDetection trait into ChangeDetection and ChangeDetectionMut
- Added Ref as equivalent to &T with change detection
---
## Changelog
- Support for Ref which allow inspecting change detection flags in an immutable way
## Migration Guide
- While bevy prelude includes both ChangeDetection and ChangeDetectionMut any code explicitly referencing ChangeDetection might need to be updated to ChangeDetectionMut or both. Specifically any reading logic requires ChangeDetection while writes requires ChangeDetectionMut.
use bevy_ecs::change_detection::DetectChanges -> use bevy_ecs::change_detection::{DetectChanges, DetectChangesMut}
- Previously Res had methods to access change detection `is_changed` and `is_added` those methods have been moved to the `DetectChanges` trait. If you are including bevy prelude you will have access to these types otherwise you will need to `use bevy_ecs::change_detection::DetectChanges` to continue using them.
`Query`'s fields being `pub(crate)` means that the struct can be constructed via safe code from anywhere in `bevy_ecs` . This is Not Good since it is intended that all construction of this type goes through `Query::new` which is an `unsafe fn` letting various `Query` methods rely on those invariants holding even though they can be trivially bypassed.
This has no user facing impact
# Objective
- Fix#7103.
- The issue is caused because I forgot to add a where clause to a generated struct in #7056.
## Solution
- Add the where clause.
`Query` relies on the `World` it stores being the same as the world used for creating the `QueryState` it stores. If they are not the same then everything is very unsound. This was not actually being checked anywhere, `Query::new` did not have a safety invariant or even an assertion that the `WorldId`'s are the same.
This shouldn't have any user facing impact unless we have really messed up in bevy and have unsoundness elsewhere (in which case we would now get a panic instead of being unsound).
# Objective
- In some cases, you need a `Mut<T>` pointer, but you only have a mutable reference to one. There is no easy way of converting `&'a mut Mut<'_, T>` -> `Mut<'a, T>` outside of the engine.
### Example (Before)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// The function expects a `Mut<T>`, so `x` gets moved here.
do_with_mut(x);
// Error: use of moved value.
do_a_thing(&x);
}
```
## Solution
- Add the function `reborrow`, which performs the mapping. This is analogous to `PtrMut::reborrow`.
### Example (After)
```rust
fn do_with_mut<T>(val: Mut<T>) { ... }
for x: Mut<T> in &mut query {
// We reborrow `x`, so the original does not get moved.
do_with_mut(x.reborrow());
// Works fine.
do_a_thing(&x);
}
```
---
## Changelog
- Added the method `reborrow` to `Mut`, `ResMut`, `NonSendMut`, and `MutUntyped`.
# Objective
The type `Local<T>` unnecessarily has the bound `T: Sync` when the local is used in an exclusive system.
## Solution
Lift the bound.
---
## Changelog
Removed the bound `T: Sync` from `Local<T>` when used as an `ExclusiveSystemParam`.
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
- This pulls out some of the changes to Plugin setup and sub apps from #6503 to make that PR easier to review.
- Separate the extract stage from running the sub app's schedule to allow for them to be run on separate threads in the future
- Fixes#6990
## Solution
- add a run method to `SubApp` that runs the schedule
- change the name of `sub_app_runner` to extract to make it clear that this function is only for extracting data between the main app and the sub app
- remove the extract stage from the sub app schedule so it can be run separately. This is done by adding a `setup` method to the `Plugin` trait that runs after all plugin build methods run. This is required to allow the extract stage to be removed from the schedule after all the plugins have added their systems to the stage. We will also need the setup method for pipelined rendering to setup the render thread. See e3267965e1/crates/bevy_render/src/pipelined_rendering.rs (L57-L98)
## Changelog
- Separate SubApp Extract stage from running the sub app schedule.
## Migration Guide
### SubApp `runner` has conceptually been changed to an `extract` function.
The `runner` no longer is in charge of running the sub app schedule. It's only concern is now moving data between the main world and the sub app. The `sub_app.app.schedule` is now run for you after the provided function is called.
```rust
// before
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
render_app.app.schedule.run();
});
}
// after
fn main() {
let sub_app = App::empty();
sub_app.add_stage(MyStage, SystemStage::parallel());
App::new().add_sub_app(MySubApp, sub_app, move |main_world, sub_app| {
extract(app_world, render_app);
// schedule is automatically called for you after extract is run
});
}
```
Spiritual successor to #5205.
Actual successor to #6865.
# Objective
Currently, system params are defined using three traits: `SystemParam`, `ReadOnlySystemParam`, `SystemParamState`. The behavior for each param is specified by the `SystemParamState` trait, while `SystemParam` simply defers to the state.
Splitting the traits in this way makes it easier to implement within macros, but it increases the cognitive load. Worst of all, this approach requires each `MySystemParam` to have a public `MySystemParamState` type associated with it.
## Solution
* Merge the trait `SystemParamState` into `SystemParam`.
* Remove all trivial `SystemParam` state types.
* `OptionNonSendMutState<T>`: you will not be missed.
---
- [x] Fix/resolve the remaining test failure.
## Changelog
* Removed the trait `SystemParamState`, merging its functionality into `SystemParam`.
## Migration Guide
**Note**: this should replace the migration guide for #6865.
This is relative to Bevy 0.9, not main.
The traits `SystemParamState` and `SystemParamFetch` have been removed, and their functionality has been transferred to `SystemParam`.
```rust
// Before (0.9)
impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
}
unsafe impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
unsafe impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(&mut self, ...) -> Self::Item;
}
unsafe impl ReadOnlySystemParamFetch for MyParamState { }
// After (0.10)
unsafe impl SystemParam for MyParam<'_, '_> {
type State = MyParamState;
type Item<'w, 's> = MyParam<'w, 's>;
fn init_state(world: &mut World, system_meta: &mut SystemMeta) -> Self::State { ... }
fn get_param<'w, 's>(state: &mut Self::State, ...) -> Self::Item<'w, 's>;
}
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> { }
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl ReadOnlySystemParam for MyParam<'_, '_> {}
```
# Objective
- The doctest for `Mut::map_unchanged` uses a fake function `set_if_not_equal` to demonstrate usage.
- Now that #6853 has been merged, we can use `Mut::set_if_neq` directly instead of mocking it.
# Objective
`SystemParam` `Local`s documentation currently leaves out information that should be documented.
- What happens when multiple `SystemParam`s within the same system have the same `Local` type.
- What lifetime parameter is expected by `Local`.
## Solution
- Added sentences to documentation to communicate this information.
- Renamed `Local` lifetimes in code to `'s` where they previously were not. Users can get complicated incorrect suggested fixes if they pass the wrong lifetime. Some instance of the code had `'w` indicating the expected lifetime might not have been known to those that wrote the code either.
Co-authored-by: iiYese <83026177+iiYese@users.noreply.github.com>
# Objective
- Fix#4200
Currently, `#[derive(SystemParam)]` publicly exposes each field type, which makes it impossible to encapsulate private fields.
## Solution
Previously, the fields were leaked because they were used as an input generic type to the macro-generated `SystemParam::State` struct. That type has been changed to store its state in a field with a specific type, instead of a generic type.
---
## Changelog
- Fixed a bug that caused `#[derive(SystemParam)]` to leak the types of private fields.
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
Bevy uses custom `Ptr` types so the rust borrow checker can help ensure lifetimes are correct, even when types aren't known. However, these types don't benefit from the automatic lifetime coercion regular rust references enjoy
## Solution
Add a couple methods to Ptr, PtrMut, and MutUntyped to allow for easy usage of these types in more complex scenarios.
## Changelog
- Added `as_mut` and `as_ref` methods to `MutUntyped`.
- Added `shrink` and `as_ref` methods to `PtrMut`.
## Migration Guide
- `MutUntyped::into_inner` now marks things as changed.
# Objective
Resolve#6156.
The most common type of command is one that runs for a single entity. Built-in commands like this can be ergonomically added to the command queue using the `EntityCommands` struct. However, adding custom entity commands to the queue is quite cumbersome. You must first spawn an entity, store its ID in a local, then construct a command using that ID and add it to the queue. This prevents method chaining, which is the main benefit of using `EntityCommands`.
### Example (before)
```rust
struct MyCustomCommand(Entity);
impl Command for MyCustomCommand { ... }
let id = commands.spawn((...)).id();
commmands.add(MyCustomCommand(id));
```
## Solution
Add the `EntityCommand` trait, which allows directly adding per-entity commands to the `EntityCommands` struct.
### Example (after)
```rust
struct MyCustomCommand;
impl EntityCommand for MyCustomCommand { ... }
commands.spawn((...)).add(MyCustomCommand);
```
---
## Changelog
- Added the trait `EntityCommand`. This is a counterpart of `Command` for types that execute code for a single entity.
## Future Work
If we feel its necessary, we can simplify built-in commands (such as `Despawn`) to use this trait.
# Objective
Any closure with the signature `FnOnce(&mut World)` implicitly implements the trait `Command` due to a blanket implementation. However, this implementation unnecessarily has the `Sync` bound, which limits the types that can be used.
## Solution
Remove the bound.
---
## Changelog
- `Command` closures no longer need to implement the marker trait `std::marker::Sync`.
# Objective
- Be able to name the type that `ManualEventReader::iter/iter_with_id` returns and `EventReader::iter/iter_with_id` by proxy.
Currently for the purpose of https://github.com/bevyengine/bevy/pull/5719
## Solution
- Create a custom `Iterator` type.
# Objective
* Currently, the `SystemParam` derive does not support types with const generic parameters.
* If you try to use const generics, the error message is cryptic and unhelpful.
* Continuation of the work started in #6867 and #6957.
## Solution
Allow const generic parameters to be used with `#[derive(SystemParam)]`.
# Objective
Fixes#4729.
Continuation of #4854.
## Solution
Add documentation to `ParamSet` and its methods. Includes examples suggested by community members in the original PR.
Co-authored-by: Nanox19435 <50684926+Nanox19435@users.noreply.github.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
* The `SystemParam` derive internally uses tuples, which means it is constrained by the 16-field limit on `all_tuples`.
* The error message if you exceed this limit is abysmal.
* Supercedes #5965 -- this does the same thing, but is simpler.
## Solution
If any tuples have more than 16 fields, they are folded into tuples of tuples until they are under the 16-field limit.
# Objective
Currently, only named structs can be used with the `SystemParam` derive macro.
## Solution
Remove the restriction. Tuple structs and unit structs are now supported.
---
## Changelog
+ Added support for tuple structs and unit structs to the `SystemParam` derive macro.
# Objective
There is currently no way to iterate over key/value pairs inside an `EntityMap`, which makes the usage of this struct very awkward. I couldn't think of a good reason why the `iter()` function should not be exposed, considering the interface already exposes `keys()` and `values()`, so I made this PR.
## Solution
Implement `iter()` for `EntityMap` in terms of its inner map type.
# Objective
[Rust 1.66](https://blog.rust-lang.org/inside-rust/2022/12/12/1.66.0-prerelease.html) is coming in a few days, and bevy doesn't build with it.
Fix that.
## Solution
Replace output from a trybuild test, and fix a few new instances of `needless_borrow` and `unnecessary_cast` that are now caught.
## Note
Due to the trybuild test, this can't be merged until 1.66 is released.
# Objective
A separate `tracing` span for running a system's commands is created, even if the system doesn't have commands. This is adding extra measuring overhead (see #4892) where it's not needed.
## Solution
Move the span into `ParallelCommandState` and `CommandQueue`'s `SystemParamState::apply`. To get the right metadata for the span, a additional `&SystemMeta` parameter was added to `SystemParamState::apply`.
---
## Changelog
Added: `SystemMeta::name`
Changed: Systems without `Commands` and `ParallelCommands` will no longer show a "system_commands" span when profiling.
Changed: `SystemParamState::apply` now takes a `&SystemMeta` parameter in addition to the provided `&mut World`.
# Objective
Change detection can be spuriously triggered by setting a field to the same value as before. As a result, a common pattern is to write:
```rust
if *foo != value {
*foo = value;
}
```
This is confusing to read, and heavy on boilerplate.
Adopted from #5373, but untangled and rebased to current `bevy/main`.
## Solution
1. Add a method to the `DetectChanges` trait that implements this boilerplate when the appropriate trait bounds are met.
2. Document this minor footgun, and point users to it.
## Changelog
* added the `set_if_neq` method to avoid triggering change detection when the new and previous values are equal. This will work on both components and resources.
## Migration Guide
If you are manually checking if a component or resource's value is equal to its new value before setting it to avoid triggering change detection, migrate to the clearer and more convenient `set_if_neq` method.
## Context
Related to #2363 as it avoids triggering change detection, but not a complete solution (as it still requires triggering it when real changes are made).
Co-authored-by: Zoey <Dessix@Dessix.net>
# Objective
Speed up bundle insertion and spawning from a bundle.
## Solution
Use the same technique used in #6800 to remove the branch on storage type when writing components from a `Bundle` into storage.
- Add a `StorageType` argument to the closure on `Bundle::get_components`.
- Pass `C::Storage::STORAGE_TYPE` into that argument.
- Match on that argument instead of reading from a `Vec<StorageType>` in `BundleInfo`.
- Marked all implementations of `Bundle::get_components` as inline to encourage dead code elimination.
The `Vec<StorageType>` in `BundleInfo` was also removed as it's no longer needed. If users were reliant on this, they can either use the compile time constants or fetch the information from `Components`. Should save a rather negligible amount of memory.
## Performance
Microbenchmarks show a slight improvement to inserting components into existing entities, as well as spawning from a bundle. Ranging about 8-16% faster depending on the benchmark.
```
group main soft-constant-write-components
----- ---- ------------------------------
add_remove/sparse_set 1.08 1019.0±80.10µs ? ?/sec 1.00 944.6±66.86µs ? ?/sec
add_remove/table 1.07 1343.3±20.37µs ? ?/sec 1.00 1257.3±18.13µs ? ?/sec
add_remove_big/sparse_set 1.08 1132.4±263.10µs ? ?/sec 1.00 1050.8±240.74µs ? ?/sec
add_remove_big/table 1.02 2.6±0.05ms ? ?/sec 1.00 2.5±0.08ms ? ?/sec
get_or_spawn/batched 1.15 401.4±17.76µs ? ?/sec 1.00 349.3±11.26µs ? ?/sec
get_or_spawn/individual 1.13 732.1±43.35µs ? ?/sec 1.00 645.6±41.44µs ? ?/sec
insert_commands/insert 1.12 623.9±37.48µs ? ?/sec 1.00 557.4±34.99µs ? ?/sec
insert_commands/insert_batch 1.16 401.4±17.00µs ? ?/sec 1.00 347.4±12.87µs ? ?/sec
insert_simple/base 1.08 416.9±5.60µs ? ?/sec 1.00 385.2±4.14µs ? ?/sec
insert_simple/unbatched 1.06 934.5±44.58µs ? ?/sec 1.00 881.3±47.86µs ? ?/sec
spawn_commands/2000_entities 1.09 190.7±11.41µs ? ?/sec 1.00 174.7±9.15µs ? ?/sec
spawn_commands/4000_entities 1.10 386.5±25.33µs ? ?/sec 1.00 352.3±18.81µs ? ?/sec
spawn_commands/6000_entities 1.10 586.2±34.42µs ? ?/sec 1.00 535.3±27.25µs ? ?/sec
spawn_commands/8000_entities 1.08 778.5±45.15µs ? ?/sec 1.00 718.0±33.66µs ? ?/sec
spawn_world/10000_entities 1.04 1026.4±195.46µs ? ?/sec 1.00 985.8±253.37µs ? ?/sec
spawn_world/1000_entities 1.06 103.8±20.23µs ? ?/sec 1.00 97.6±18.22µs ? ?/sec
spawn_world/100_entities 1.15 11.4±4.25µs ? ?/sec 1.00 9.9±1.87µs ? ?/sec
spawn_world/10_entities 1.05 1030.8±229.78ns ? ?/sec 1.00 986.2±231.12ns ? ?/sec
spawn_world/1_entities 1.01 105.1±23.33ns ? ?/sec 1.00 104.6±31.84ns ? ?/sec
```
---
## Changelog
Changed: `Bundle::get_components` now takes a `FnMut(StorageType, OwningPtr)`. The provided storage type must be correct for the component being fetched.
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6417
## Solution
- clear_trackers was not being called on the render world. This causes the removed components vecs to continuously grow. This PR adds clear trackers to the end of RenderStage::Cleanup
## Migration Guide
The call to `clear_trackers` in `App` has been moved from the schedule to App::update for the main world and calls to `clear_trackers` have been added for sub_apps in the same function. This was due to needing stronger guarantees. If clear_trackers isn't called on a world it can lead to memory leaks in `RemovedComponents`.
{kind=link}