# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
- Do not implement `Copy` or `Clone` for `Fetch` types as this is kind of sus soundness wise (it feels like cloning an `IterMut` in safe code to me). Cloning a fetch seems important to think about soundness wise when doing it so I prefer this over adding a `Clone` bound to the assoc type definition (i.e. `type Fetch: Clone`) even though that would also solve the other listed things here.
- Remove a bunch of `QueryFetch<'w, Q>: Clone` bounds from our API as now all fetches can be "cloned" for use in `iter_combinations`. This should also help avoid the type inference regression ptrification introduced where `for<'a> QueryFetch<'a, Q>: Trait` bounds misbehave since we no longer need any of those kind of higher ranked bounds (although in practice we had none anyway).
- Stop being able to "forget" to implement clone for fetches, we've had a lot of issues where either `derive(Clone)` was used instead of a manual impl (so we ended up with too tight bounds on the impl) or flat out forgot to implement Clone at all. With this change all fetches are able to be cloned for `iter_combinations` so this will no longer be possible to mess up.
On an unrelated note, while making this PR I realised we probably want safety invariants on `archetype/table_fetch` that nothing aliases the table_row/archetype_index according to the access we set.
---
## Changelog
`Clone` and `Copy` were removed from all `Fetch` types.
## Migration Guide
- Call `WorldQuery::clone_fetch` instead of `fetch.clone()`. Make sure to add safety comments :)
# Objective
I was trying to implement a collision system for my game, and believed that the iter_combinations method might be what I need. But I couldn't find a simple explanation of what a combination was in Bevy and thought it could use some more explanation.
## Solution
I added some description to the documentation that can hopefully further elaborate on what a combination is.
I also changed up the docs for the method because a combination is a different thing than a permutation but the Bevy docs seemed to use them interchangeably.
# Objective
- `QueryCombinationIter` can have sizes greater than `usize::MAX`.
- Fixes#5846
## Solution
- Only the implementation of `ExactSizeIterator` has been removed. Instead of using `query_combination.len()`, you can use `query_combination.size_hint().0` to get the same value as before.
---
## Migration Guide
- Switch to using other methods of getting the length.
Add the following message:
```
Items are returned in the order of the list of entities.
Entities that don't match the query are skipped.
```
Additionally, the docs in `iter.rs` and `state.rs` were updated to match those in `query.rs`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Speed up queries that are fragmented over many empty archetypes and tables.
## Solution
Add a early-out to check if the table or archetype is empty before iterating over it. This adds an extra branch for every archetype matched, but skips setting the archetype/table to the underlying state and any iteration over it.
This may not be worth it for the default `Query::iter` and maybe even the `Query::for_each` implementations, but this definitely avoids scheduling unnecessary tasks in the `Query::par_for_each` case.
Ideally, `matched_archetypes` should only contain archetypes where there's actually work to do, but this would add a `O(n)` flat cost to every call to `update_archetypes` that scales with the number of matched archetypes.
TODO: Benchmark
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
Fixes Issue #6005.
## Solution
Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound.
## Migration Guide
Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead.
Make API users aware that the type aliases `QueryItem` and `QueryFetch` can be used instead of the more bloated alternative with `WorldQueryGats`.
Fixes#5842
# Objective
- Document `QueryCombinationIter`
## Solution
- Describe the item, add usage and examples
- Copy notes about the number of query items generated from the corresponding query methods (they will be removed in #5742 ([motivation]))
## Additional notes
- Derived from #4989
[motivation]: https://github.com/bevyengine/bevy/pull/4989#issuecomment-1208421496
# Objective
Simplify the worldquery trait hierarchy as much as possible by putting it all in one trait. If/when gats are stabilised this can be trivially migrated over to use them, although that's not why I made this PR, those reasons are:
- Moves all of the conceptually related unsafe code for a worldquery next to eachother
- Removes now unnecessary traits simplifying the "type system magic" in bevy_ecs
---
## Changelog
All methods/functions/types/consts on `FetchState` and `Fetch` traits have been moved to the `WorldQuery` trait and the other traits removed. `WorldQueryGats` now only contains an `Item` and `Fetch` assoc type.
## Migration Guide
Implementors should move items in impls to the `WorldQuery/Gats` traits and remove any `Fetch`/`FetchState` impls
Any use sites of items in the `Fetch`/`FetchState` traits should be updated to use the `WorldQuery` trait items instead
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Replace `many_for_each_mut` with `iter_many_mut` using the same tricks to avoid aliased mutability that `iter_combinations_mut` uses.
<sub>I tried rebasing the draft PR I made for this before and it died. F</sub>
## Why
`many_for_each_mut` is worse for a few reasons:
1. The closure prevents the use of `continue`, `break`, and `return` behaves like a limited `continue`.
2. rustfmt will crumple it and double the indentation when the line gets too long.
```rust
query.many_for_each_mut(
&entity_list,
|(mut transform, velocity, mut component_c)| {
// Double trouble.
},
);
```
3. It is more surprising to have `many_for_each_mut` as a mutable counterpart to `iter_many` than `iter_many_mut`.
4. It required a separate unsafe fn; more unsafe code to maintain.
5. The `iter_many_mut` API matches the existing `iter_combinations_mut` API.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`ReadOnlyWorldQuery` should have required `Self::ReadOnly = Self` so that calling `.iter()` on a readonly query is equivelent to calling `iter_mut()`.
## Solution
add `ReadOnly = Self` to the definition of `ReadOnlyWorldQuery`
---
## Changelog
ReadOnlyWorldQuery's `ReadOnly` assoc type is now always equal to `Self`
## Migration Guide
Make `Self::ReadOnly = Self` hold
# Objective
remove `QF` generics from a bunch of types and methods on query related items. this has a few benefits:
- simplifies type signatures `fn iter(&self) -> QueryIter<'_, 's, Q::ReadOnly, F::ReadOnly>` is (imo) conceptually simpler than `fn iter(&self) -> QueryIter<'_, 's, Q, ROQueryFetch<'_, Q>, F>`
- `Fetch` is mostly an implementation detail but previously we had to expose it on every `iter` `get` etc method
- Allows us to potentially in the future simplify the `WorldQuery` trait hierarchy by removing the `Fetch` trait
## Solution
remove the `QF` generic and add a way to (unsafely) turn `&QueryState<Q1, F1>` into `&QueryState<Q2, F2>`
---
## Changelog/Migration Guide
The `QF` generic was removed from various `Query` iterator types and some methods, you should update your code to use the type of the corresponding worldquery of the fetch type that was being used, or call `as_readonly`/`as_nop` to convert a querystate to the appropriate type. For example:
`.get_single_unchecked_manual::<ROQueryFetch<Q>>(..)` -> `.as_readonly().get_single_unchecked_manual(..)`
`my_field: QueryIter<'w, 's, Q, ROQueryFetch<'w, Q>, F>` -> `my_field: QueryIter<'w, 's, Q::ReadOnly, F::ReadOnly>`
Following https://github.com/bevyengine/bevy/pull/5124 I decided to add the `ExactSizeIterator` impl for `QueryCombinationIter`.
Also:
- Clean up the tests for `size_hint` and `len` for both the normal `QueryIter` and `QueryCombinationIter`.
- Add tests to `QueryCombinationIter` when it shouldn't be `ExactSizeIterator`
---
## Changelog
- Added `ExactSizeIterator` implementation for `QueryCombinatonIter`
# Objective
- `.iter_combinations_*()` cannot be used on custom derived `WorldQuery`, so this fixes that
- Fixes#5284
## Solution
- `#[derive(Clone)]` on the `Fetch` of the proc macro derive.
- `#[derive(Clone)]` for `AnyOf` to satisfy tests.
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
CI is now failing with some changes that landed in 1.62.
## Solution
* Fix an unused lifetime by using it (we double-used the `w` lifetime).
* Update compile_fail error messages
* temporarily disable check-unused-dependencies
# Objective
- Fixes#3142
## Solution
- Done according to #3142
- Created new marker trait `ArchetypeFilter`
- Implement said trait to:
- `With<T>`
- `Without<T>`
- tuples containing only types that implement `ArchetypeFilter`, from 0 to 15 elements
- `Or<T>` where T is a tuple as described previously
- Changed `ExactSizeIterator` impl to include a new generic that must implement `WorldQuery` and `ArchetypeFilter`
- Added new tests
---
## Changelog
### Added
- `Query`s with archetypal filters can now use `.iter().len()` to get the exact size of the iterator.
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
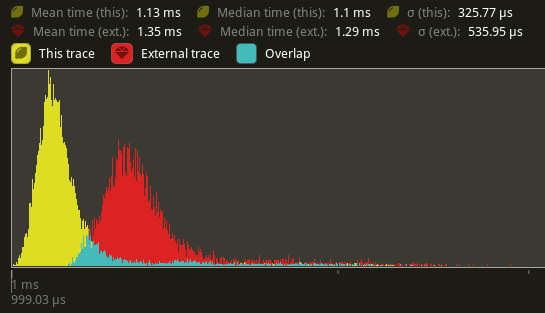
The command heavy `Extract` stage also saw a smaller overall improvement:
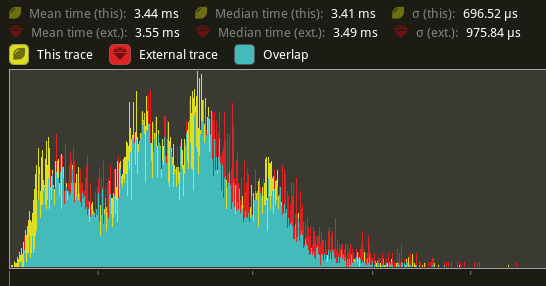
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
# Objective
Most of our `Iterator` impls satisfy the requirements of `std::iter::FusedIterator`, which has internal specialization that optimizes `Interator::fuse`. The std lib iterator combinators do have a few that rely on `fuse`, so this could optimize those use cases. I don't think we're using any of them in the engine itself, but beyond a light increase in compile time, it doesn't hurt to implement the trait.
## Solution
Implement the trait for all eligible iterators in first party crates. Also add a missing `ExactSizeIterator` on an iterator that could use it.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864Fixes#1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes#3183. Requiring a `&TaskPool` parameter is sort of meaningless if the only correct one is to use the one provided by `Res<ComputeTaskPool>` all the time.
## Solution
Have `QueryState` save a clone of the `ComputeTaskPool` which is used for all `par_for_each` functions.
~~Adds a small overhead of the internal `Arc` clone as a part of the startup, but the ergonomics win should be well worth this hardly-noticable overhead.~~
Updated the docs to note that it will panic the task pool is not present as a resource.
# Future Work
If https://github.com/bevyengine/rfcs/pull/54 is approved, we can replace these resource lookups with a static function call instead to get the `ComputeTaskPool`.
---
## Changelog
Removed: The `task_pool` parameter of `Query(State)::par_for_each(_mut)`. These calls will use the `World`'s `ComputeTaskPool` resource instead.
## Migration Guide
The `task_pool` parameter for `Query(State)::par_for_each(_mut)` has been removed. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(
task_pool: Res<ComputeTaskPool>,
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
If using `Query(State)` outside of a system run by the scheduler, you may need to manually configure and initialize a `ComputeTaskPool` as a resource in the `World`.
# Objective
- Rebase of #3159.
- Fixes https://github.com/bevyengine/bevy/issues/3156
- add #[inline] to single related functions so that they matches with other function defs
## Solution
* added functions to QueryState
* get_single_unchecked_manual
* get_single_unchecked
* get_single
* get_single_mut
* single
* single_mut
* make Query::get_single use QueryState::get_single_unchecked_manual
* added #[inline]
---
## Changelog
### Added
Functions `QueryState::single`, `QueryState::get_single`, `QueryState::single_mut`, `QueryState::get_single_mut`, `QueryState::get_single_unchecked`, `QueryState::get_single_unchecked_manual`.
### Changed
`QuerySingleError` is now in the `state` module.
## Migration Guide
Change `query::QuerySingleError` to `state::QuerySingleError`
Co-authored-by: 2ne1ugly <chattermin@gmail.com>
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
the code in these fns are always identical so stop having two functions
## Solution
make them the same function
---
## Changelog
change `matches_archetype` and `matches_table` to `fn matches_component_set(&self, &SparseArray<ComponentId, usize>) -> bool` then do extremely boring updating of all `FetchState` impls
## Migration Guide
- move logic of `matches_archetype` and `matches_table` into `matches_component_set` in any manual `FetchState` impls
# Objective
Fixes#4657
Example code that wasnt panic'ing before this PR (and so was unsound):
```rust
#[test]
#[should_panic = "error[B0001]"]
fn option_has_no_filter_with() {
fn sys(_1: Query<(Option<&A>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn any_of_has_no_filter_with() {
fn sys(_1: Query<(AnyOf<(&A, ())>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn or_has_no_filter_with() {
fn sys(_1: Query<&mut B, Or<(With<A>, With<B>)>>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
```
## Solution
- Only add the intersection of `with`/`without` accesses of all the elements in `Or/AnyOf` to the world query's `FilteredAccess<ComponentId>` instead of the union.
- `Option`'s fix can be thought of the same way since its basically `AnyOf<T, ()>` but its impl is just simpler as `()` has no `with`/`without` accesses
---
## Changelog
- `Or`/`AnyOf`/`Option` will now report more query conflicts in order to fix unsoundness
## Migration Guide
- If you are now getting query conflicts from `Or`/`AnyOf`/`Option` rip to you and ur welcome for it now being caught
# Objective
We have duplicated code between `QueryIter` and `QueryIterationCursor`. Reuse that code.
## Solution
- Reuse `QueryIterationCursor` inside `QueryIter`.
- Slim down `QueryIter` by removing the `&'w World`. It was only being used by the `size_hint` and `ExactSizeIterator` impls, which can use the QueryState and &Archetypes in the type already.
- Benchmark to make sure there is no significant regression.
Relevant benchmark results seem to show that there is no tangible difference between the two. Everything seems to be either identical or within a workable margin of error here.
```
group embed-cursor main
----- ------------ ----
fragmented_iter/base 1.00 387.4±19.70ns ? ?/sec 1.07 413.1±27.95ns ? ?/sec
many_maps_iter 1.00 27.3±0.22ms ? ?/sec 1.00 27.4±0.10ms ? ?/sec
simple_iter/base 1.00 13.8±0.07µs ? ?/sec 1.00 13.7±0.17µs ? ?/sec
simple_iter/sparse 1.00 61.9±0.37µs ? ?/sec 1.00 62.2±0.64µs ? ?/sec
simple_iter/system 1.00 13.7±0.34µs ? ?/sec 1.00 13.7±0.10µs ? ?/sec
sparse_fragmented_iter/base 1.00 11.0±0.54ns ? ?/sec 1.03 11.3±0.48ns ? ?/sec
world_query_iter/50000_entities_sparse 1.08 105.0±2.68µs ? ?/sec 1.00 97.5±2.18µs ? ?/sec
world_query_iter/50000_entities_table 1.00 27.3±0.13µs ? ?/sec 1.00 27.3±0.37µs ? ?/sec
```
# Objective
`Query::par_for_each` and it's variants do not show up when profiling using `tracy` or other profilers. Failing to show the impact of changing batch size, the overhead of scheduling tasks, overall thread utilization, etc. other than the effect on the surrounding system.
## Solution
Add a child span that is entered on every spawned task.
Example view of the results in `tracy` using a modified `parallel_query`:
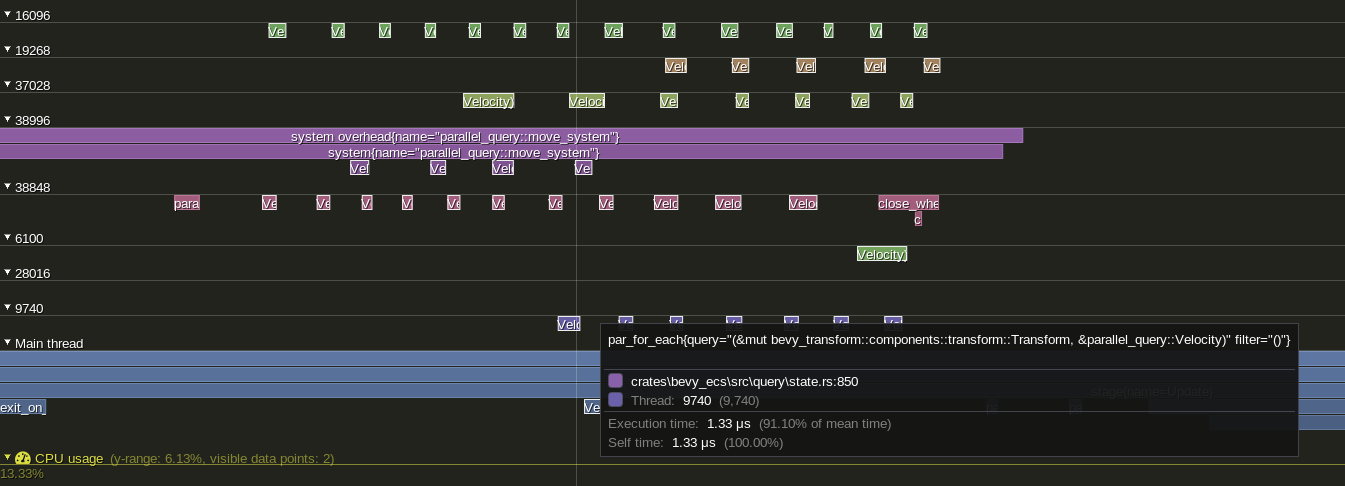
---
## Changelog
Added: `tracing` spans for `Query::par_for_each` and its variants. Spans should now be visible for all
# Objective
- (Eventually) reduce noise in reporting access conflicts between unordered systems.
- `SystemStage` only looks at unfiltered `ComponentId` access, any conflicts reported are potentially `false`.
- the systems could still be accessing disjoint archetypes
- Comparing systems' filtered access sets can maybe avoid that (for statically known component types).
- #4204
## Solution
- Modify `SparseSetIndex` trait to require `PartialEq`, `Eq`, and `Hash` (all internal types except `BundleId` already did).
- Add `is_compatible` and `get_conflicts` methods to `FilteredAccessSet<T>`
- (existing method renamed to `get_conflicts_single`)
- Add docs for those and all the other methods while I'm at it.
## Objective
- ~~Make absurdly long-lived changes stay detectable for even longer (without leveling up to `u64`).~~
- Give all changes a consistent maximum lifespan.
- Improve code clarity.
## Solution
- ~~Increase the frequency of `check_tick` scans to increase the oldest reliably-detectable change.~~
(Deferred until we can benchmark the cost of a scan.)
- Ignore changes older than the maximum reliably-detectable age.
- General refactoring—name the constants, use them everywhere, and update the docs.
- Update test cases to check for the specified behavior.
## Related
This PR addresses (at least partially) the concerns raised in:
- #3071
- #3082 (and associated PR #3084)
## Background
- #1471
Given the minimum interval between `check_ticks` scans, `N`, the oldest reliably-detectable change is `u32::MAX - (2 * N - 1)` (or `MAX_CHANGE_AGE`). Reducing `N` from ~530 million (current value) to something like ~2 million would extend the lifetime of changes by a billion.
| minimum `check_ticks` interval | oldest reliably-detectable change | usable % of `u32::MAX` |
| --- | --- | --- |
| `u32::MAX / 8` (536,870,911) | `(u32::MAX / 4) * 3` | 75.0% |
| `2_000_000` | `u32::MAX - 3_999_999` | 99.9% |
Similarly, changes are still allowed to be between `MAX_CHANGE_AGE`-old and `u32::MAX`-old in the interim between `check_tick` scans. While we prevent their age from overflowing, the test to detect changes still compares raw values. This makes failure ultimately unreliable, since when ancient changes stop being detected varies depending on when the next scan occurs.
## Open Question
Currently, systems and system states are incorrectly initialized with their `last_change_tick` set to `0`, which doesn't handle wraparound correctly.
For consistent behavior, they should either be initialized to the world's `last_change_tick` (and detect no changes) or to `MAX_CHANGE_AGE` behind the world's current `change_tick` (and detect everything as a change). I've currently gone with the latter since that was closer to the existing behavior.
## Follow-up Work
(Edited: entire section)
We haven't actually profiled how long a `check_ticks` scan takes on a "large" `World` , so we don't know if it's safe to increase their frequency. However, we are currently relying on play sessions not lasting long enough to trigger a scan and apps not having enough entities/archetypes for it to be "expensive" (our assumption). That isn't a real solution. (Either scanning never costs enough to impact frame times or we provide an option to use `u64` change ticks. Nobody will accept random hiccups.)
To further extend the lifetime of changes, we actually only need to increment the world tick if a system has `Fetch: !ReadOnlySystemParamFetch`. The behavior will be identical because all writes are sequenced, but I'm not sure how to implement that in a way that the compiler can optimize the branch out.
Also, since having no false positives depends on a `check_ticks` scan running at least every `2 * N - 1` ticks, a `last_check_tick` should also be stored in the `World` so that any lull in system execution (like a command flush) could trigger a scan if needed. To be completely robust, all the systems initialized on the world should be scanned, not just those in the current stage.
# Objective
The pointer types introduced in #3001 are useful not just in `bevy_ecs`, but also in crates like `bevy_reflect` (#4475) or even outside of bevy.
## Solution
Extract `Ptr<'a>`, `PtrMut<'a>`, `OwnedPtr<'a>`, `ThinSlicePtr<'a, T>` and `UnsafeCellDeref` from `bevy_ecs::ptr` into `bevy_ptr`.
**Note:** `bevy_ecs` still reexports the `bevy_ptr` as `bevy_ecs::ptr` so that crates like `bevy_transform` can use the `Bundle` derive without needing to depend on `bevy_ptr` themselves.
The only tests we had for `derive(WorldQuery)` checked that the derive doesnt panic/emit a `compiler_error!`. This PR adds tests that actually assert the returned values of a query using the derived `WorldQuery` impl. Also adds a compile fail test to check that we correctly error on read only world queries containing mutable world queries.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
# Objective
Reduce from scratch build time.
## Solution
Reduce the size of the critical path by removing dependencies between crates where not necessary. For `cargo check --no-default-features` this reduced build time from ~51s to ~45s. For some commits I am not completely sure if the tradeoff between build time reduction and convenience caused by the commit is acceptable. If not, I can drop them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}