# Objective
Documents the `BufferVec` render resource.
`BufferVec` is a fairly low level object, that will likely be managed by a higher level API (e.g. through [`encase`](https://github.com/bevyengine/bevy/issues/4272)) in the future. For now, since it is still used by some simple
example crates (e.g. [bevy-vertex-pulling](https://github.com/superdump/bevy-vertex-pulling)), it will be helpful
to provide some simple documentation on what `BufferVec` does.
## Solution
I looked through Discord discussion on `BufferVec`, and found [a comment](https://discord.com/channels/691052431525675048/953222550568173580/956596218857918464 ) by @superdump to be particularly helpful, in the general discussion around `encase`.
I have taken care to clarify where the data is stored (host-side), when the device-side buffer is created (through calls to `reserve`), and when data writes from host to device are scheduled (using `write_buffer` calls).
---
## Changelog
- Added doc string for `BufferVec` and two of its methods: `reserve` and `write_buffer`.
Co-authored-by: Brian Merchant <bhmerchant@gmail.com>
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
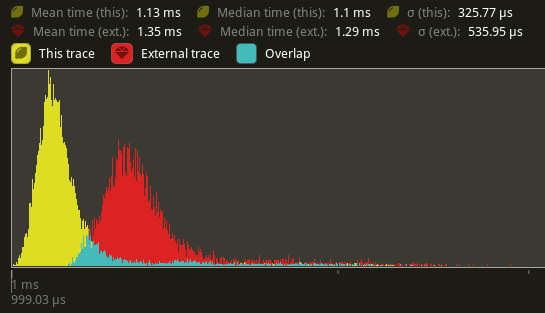
The command heavy `Extract` stage also saw a smaller overall improvement:
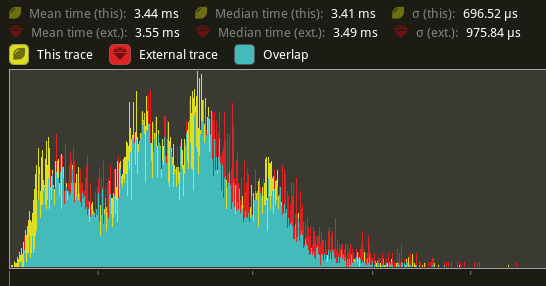
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
Currently, `Reflect` is unsafe to implement because of a contract in which `any` and `any_mut` must return `self`, or `downcast` will cause UB. This PR makes `Reflect` safe, makes `downcast` not use unsafe, and eliminates this contract.
## Solution
This PR adds a method to `Reflect`, `any`. It also renames the old `any` to `as_any`.
`any` now takes a `Box<Self>` and returns a `Box<dyn Any>`.
---
## Changelog
### Added:
- `any()` method
- `represents()` method
### Changed:
- `Reflect` is now a safe trait
- `downcast()` is now safe
- The old `any` is now called `as_any`, and `any_mut` is now `as_mut_any`
## Migration Guide
- Reflect derives should not have to change anything
- Manual reflect impls will need to remove the `unsafe` keyword, add `any()` implementations, and rename the old `any` and `any_mut` to `as_any` and `as_mut_any`.
- Calls to `any`/`any_mut` must be changed to `as_any`/`as_mut_any`
## Points of discussion:
- Should renaming `any` be avoided and instead name the new method `any_box`?
- ~~Could there be a performance regression from avoiding the unsafe? I doubt it, but this change does seem to introduce redundant checks.~~
- ~~Could/should `is` and `type_id()` be implemented differently? For example, moving `is` onto `Reflect` as an `fn(&self, TypeId) -> bool`~~
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
Small nitpicks over my full read over Contributing.md
# Objective
Fixes to Contributing file
- Lists more coherent: starting with capital letter and ending with point.
- Fixed a Typo.
- A clarification on approval aimed at newcomers.
- Reference links
# Objective
Add support for custom `AssetIo` implementations to trigger reloading of an asset.
## Solution
- Add a public method to `AssetServer` to allow forcing the reloading of an asset.
---
## Changelog
- Add method `reload_asset` to `AssetServer`.
Co-authored-by: Robert G. Jakabosky <rjakabosky+neopallium@neoawareness.com>
# Objective
- Small bug in the example game given in examples/ecs/ecs_guide
Currently, if there are 2 players in this example game, the function exclusive_player_system can add a player with the name "Player 2". However, the name should be "Player 3". This PR fixes this. I also add a message to inform that a new player has arrived in the mock game.
Co-authored-by: Dilyan Kostov <dilyanks@amazon.com>
# Objective
- Fixes#5083
## Solution
I looked at the implementation of those events. I noticed that they both are adaptations of `winit`'s `DeviceEvent`/`WindowEvent` enum variants. Therefore I based the description of the items on the documentation provided by the upstream crate. I also added a link to `CursorMoved`, just like `MouseMotion` already has.
## Observations
- Looking at the implementation of `MouseMotion`, I noticed the `DeviceId` field of the `winit` event is discarded by `bevy_input`. This means that in the case a machine has multiple pointing devices, it is impossible to distinguish to which one the event is referring to. **EDIT:** just tested, `MouseMotion` events are emitted for movement of both mice.
# Objective
Attempt to more clearly document `ImageSettings` and setting a default sampler for new images, as per #5046
## Changelog
- Moved ImageSettings into image.rs, image::* is already exported. Makes it simpler for linking docs.
- Renamed "DefaultImageSampler" to "RenderDefaultImageSampler". Not a great name, but more consistent with other render resources.
- Added/updated related docs
# Objective
- Allow custom shaders to reuse the HDR results of PBR.
## Solution
- Separate `pbr()` and `tone_mapping()` into 2 functions in `pbr_functions.wgsl`.
# Objective
- Simplify the process of obtaining a `ComponentId` instance corresponding to a `Component`.
- Resolves#5060.
## Solution
- Add a `component_id::<T: Component>(&self)` function to both `World` and `Components` to retrieve the `ComponentId` associated with `T` from a immutable reference.
---
## Changelog
- Added `World::component_id::<C>()` and `Components::component_id::<C>()` to retrieve a `Component`'s corresponding `ComponentId` if it exists.
# Objective
- Have information about examples only in one place that can be used for the repo and for the website (and remove the need to keep a list of example to build for wasm in the website 75acb73040/generate-wasm-examples/generate_wasm_examples.sh (L92-L99))
## Solution
- Add metadata about examples in `Cargo.toml`
- Build the `examples/README.md` from a template using those metadata. I used tera as the template engine to use the same tech as the website.
- Make CI fail if an example is missing metadata, or if the readme file needs to be updated (the command to update it is displayed in the failed step in CI)
## Remaining To Do
- After the next release with this merged in, the website will be able to be updated to use those metadata too
- I would like to build the examples in wasm and make them available at http://dev-docs.bevyengine.org/ but that will require more design
- https://github.com/bevyengine/bevy-website/issues/299 for other ToDos
Co-authored-by: Readme <github-actions@github.com>
# Objective
Update pbr mesh shader to use correct normals for skinned meshes.
## Solution
Only use `mesh_normal_local_to_world` for normals if `SKINNED` is not defined.
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
DioxusLabs and Bevy have taken over maintaining what was our abandoned ui layout dependency [stretch](https://github.com/vislyhq/stretch). Dioxus' fork has had a lot of work done on it by @alice-i-cecile, @Weibye , @jkelleyrtp, @mockersf, @HackerFoo, @TimJentzsch and a dozen other contributors and now is in much better shape than stretch was. The updated crate is called taffy and is available on github [here](https://github.com/DioxusLabs/taffy) ([taffy](https://crates.io/crates/taffy) on crates.io). The goal of this PR is to replace stretch v0.3.2 with taffy v0.1.0.
## Solution
I changed the bevy_ui Cargo.toml to depend on taffy instead of stretch and fixed all the errors rustc complained about.
---
## Changelog
Changed bevy_ui layout dependency from stretch to taffy (the maintained fork of stretch).
fixes#677
## Migration Guide
The public api of taffy is different from that of stretch so please advise me on what to do here @alice-i-cecile.
# Objective
- Builds on top of #4938
- Make clustered-forward PBR lighting/shadows functionality callable
- See #3969 for details
## Solution
- Add `PbrInput` struct type containing a `StandardMaterial`, occlusion, world_position, world_normal, and frag_coord
- Split functionality to calculate the unit view vector, and normal-mapped normal into `bevy_pbr::pbr_functions`
- Split high-level shading flow into `pbr(in: PbrInput, N: vec3<f32>, V: vec3<f32>, is_orthographic: bool)` function in `bevy_pbr::pbr_functions`
- Rework `pbr.wgsl` fragment stage entry point to make use of the new functions
- This has been benchmarked on an M1 Max using `many_cubes -- sphere`. `main` had a median frame time of 15.88ms, this PR 15.99ms, which is a 0.69% frame time increase, which is within noise in my opinion.
---
## Changelog
- Added: PBR shading code is now callable. Import `bevy_pbr::pbr_functions` and its dependencies, create a `PbrInput`, calculate the unit view and normal-mapped normal vectors and whether the projection is orthographic, and call `pbr()`!
# Objective
Closes#1557. Partially addresses #3362.
Cleanup the public facing API for storage types. Most of these APIs are difficult to use safely when directly interfacing with these types, and is also currently impossible to interact with in normal ECS use as there is no `World::storages_mut`. The majority of these types should be easy enough to read, and perhaps mutate the contents, but never structurally altered without the same checks in the rest of bevy_ecs code. This both cleans up the public facing types and helps use unused code detection to remove a few of the APIs we're not using internally.
## Solution
- Mark all APIs that take `&mut T` under `bevy_ecs::storage` as `pub(crate)` or `pub(super)`
- Cleanup after it all.
Entire type visibility changes:
- `BlobVec` is `pub(super)`, only storage code should be directly interacting with it.
- `SparseArray` is now `pub(crate)` for the entire type. It's an implementation detail for `Table` and `(Component)SparseSet`.
- `TableMoveResult` is now `pub(crate)
---
## Changelog
TODO
## Migration Guide
Dear God, I hope not.
# Objective
Further speed up visibility checking by removing the main sources of contention for the system.
## Solution
- ~~Make `ComputedVisibility` a resource wrapping a `FixedBitset`.~~
- ~~Remove `ComputedVisibility` as a component.~~
~~This adds a one-bit overhead to every entity in the app world. For a game with 100,000 entities, this is 12.5KB of memory. This is still small enough to fit entirely in most L1 caches. Also removes the need for a per-Entity change detection tick. This reduces the memory footprint of ComputedVisibility 72x.~~
~~The decreased memory usage and less fragmented memory locality should provide significant performance benefits.~~
~~Clearing visible entities should be significantly faster than before:~~
- ~~Setting one `u32` to 0 clears 32 entities per cycle.~~
- ~~No archetype fragmentation to contend with.~~
- ~~Change detection is applied to the resource, so there is no per-Entity update tick requirement.~~
~~The side benefit of this design is that it removes one more "computed component" from userspace. Though accessing the values within it are now less ergonomic.~~
This PR changes `crossbeam_channel` in `check_visibility` to use a `Local<ThreadLocal<Cell<Vec<Entity>>>` to mark down visible entities instead.
Co-Authored-By: TheRawMeatball <therawmeatball@gmail.com>
Co-Authored-By: Aevyrie <aevyrie@gmail.com>
# Objective
The descriptions included in the API docs of `entity` module, `Entity` struct, and `Component` trait have some issues:
1. the concept of entity is not clearly defined,
2. descriptions are a little bit out of place,
3. in a case the description leak too many details about the implementation,
4. some descriptions are not exhaustive,
5. there are not enough examples,
6. the content can be formatted in a much better way.
## Solution
1. ~~Stress the fact that entity is an abstract and elementary concept. Abstract because the concept of entity is not hardcoded into the library but emerges from the interaction of `Entity` with every other part of `bevy_ecs`, like components and world methods. Elementary because it is a fundamental concept that cannot be defined with other terms (like point in euclidean geometry, or time in classical physics).~~ We decided to omit the definition of entity in the API docs ([see why]). It is only described in its relationship with components.
2. Information has been moved to relevant places and links are used instead in the other places.
3. Implementation details about `Entity` have been reduced.
4. Descriptions have been made more exhaustive by stating how to obtain and use items. Entity operations are enriched with `World` methods.
5. Examples have been added or enriched.
6. Sections have been added to organize content. Entity operations are now laid out in a table.
### Todo list
- [x] Break lines at sentence-level.
## For reviewers
- ~~I added a TODO over `Component` docs, make sure to check it out and discuss it if necessary.~~ ([Resolved])
- You can easily check the rendered documentation by doing `cargo doc -p bevy_ecs --no-deps --open`.
[see why]: https://github.com/bevyengine/bevy/pull/4767#discussion_r875106329
[Resolved]: https://github.com/bevyengine/bevy/pull/4767#discussion_r874127825
# Objective
`bevy_ui` doesn't support correctly touch inputs because of two problems in the focus system:
- It attempts to retrieve touch input with a specific `0` id
- It doesn't retrieve touch positions and bases its focus solely on mouse position, absent from mobile devices
## Solution
I added a few methods to the `Touches` resource, allowing to check if **any** touch input was pressed, released or cancelled and to retrieve the *position* of the first pressed touch input and adapted the focus system.
I added a test button to the *iOS* example and it works correclty on emulator. I did not test on a real touch device as:
- Android is not working (https://github.com/bevyengine/bevy/issues/3249)
- I don't have an iOS device
# Objective
`nix-shell` reported: ```error: 'x11' has been renamed to/replaced by 'xlibsWrapper'```.
## Solution
Replacing `x11` with `xlibsWrapper` in the Nix section of linux_dependencies.md fixes the problem on my system, and bevy projects build fine.
**This Commit**
1. Makes it so the sentence doesn't read "are contributors who have Have
actively ..."
2. Makes it so all three bullet points end in punctuation
**Notes**
Could also remove the leading "Have" from all bullet points and leave it
on the previous sentence. That's the least redundant but I guess this is
more flexible if we want to add a sentence that doesn't start with
"Have" later.
# Objective
- Fixes#4996
## Solution
- Panicking on the global task pool is probably bad. This changes the panicking test to use a single threaded stage to run the test instead.
- I checked the other #[should_panic]
- I also added explicit ordering between the transform propagate system and the parent update system. The ambiguous ordering didn't seem to be causing problems, but the tests are probably more correct this way. The plugins that add these systems have an explicit ordering. I can remove this if necessary.
## Note
I don't have a 100% mental model of why panicking is causing intermittent failures. It probably has to do with a task for one of the other tests landing on the panicking thread when it actually panics. Why this causes a problem I'm not sure, but this PR seems to fix things.
## Open questions
- there are some other #[should_panic] tests that run on the task pool in stage.rs. I don't think we restart panicked threads, so this might be killing most of the threads on the pool. But since they're not causing test failures, we should probably decide what to do about that separately. The solution in this PR won't work since those tests are explicitly testing parallelism.
# Objective
- Add benchmarks to test the performance of `Schedule`'s system dependency resolution.
## Solution
- Do a series of benchmarks while increasing the number of systems in the schedule to see how the run-time scales.
- Split the benchmarks into a group with no dependencies, and a group with many dependencies.
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
- changed `EntityCountDiagnosticsPlugin` to not use an exclusive system to get its entity count
- removed mention of `WgpuResourceDiagnosticsPlugin` in example `log_diagnostics` as it doesn't exist anymore
- added ability to enable, disable ~~or toggle~~ a diagnostic (fix#3767)
- made diagnostic values lazy, so they are only computed if the diagnostic is enabled
- do not log an average for diagnostics with only one value
- removed `sum` function from diagnostic as it isn't really useful
- ~~do not keep an average of the FPS diagnostic. it is already an average on the last 20 frames, so the average FPS was an average of the last 20 frames over the last 20 frames~~
- do not compute the FPS value as an average over the last 20 frames but give the actual "instant FPS"
- updated log format to use variable capture
- added some doc
- the frame counter diagnostic value can be reseted to 0
# Objective
- Optional dependencies were enabled by some features as a side effect. for example, enabling the `webgl` feature enables the `bevy_pbr` optional dependency
## Solution
- Use the syntax introduced in rust 1.60 to specify weak dependency features: https://blog.rust-lang.org/2022/04/07/Rust-1.60.0.html#new-syntax-for-cargo-features
> Weak dependency features tackle the second issue where the `"optional-dependency/feature-name"` syntax would always enable `optional-dependency`. However, often you want to enable the feature on the optional dependency only if some other feature has enabled the optional dependency. Starting in 1.60, you can add a ? as in `"package-name?/feature-name"` which will only enable the given feature if something else has enabled the optional dependency.
# Objective
- `.x` is not the correct syntax to access a column in a matrix in WGSL: https://www.w3.org/TR/WGSL/#matrix-access-expr
- naga accepts it and translates it correctly, but it's not valid when shaders are kept as is and used directly in WGSL
## Solution
- Use the correct syntax
# Objective
- Update hashbrown to 0.12
## Solution
- Replace #4004
- As the 0.12 is already in Bevy dependency tree, it shouldn't be an issue to update
- The exception for the 0.11 should be removed once https://github.com/zakarumych/gpu-descriptor/pull/21 is merged and released
- Also removed a few exceptions that weren't needed anymore
# Objective
- KTX2 UASTC format mapping was incorrect. For some reason I had written it to map to a set of data formats based on the count of KTX2 sample information blocks, but the mapping should be done based on the channel type in the sample information.
- This is a valid change pulled out from #4514 as the attempt to fix the array textures there was incorrect
## Solution
- Fix the KTX2 UASTC `DataFormat` enum to contain the correct formats based on the channel types in section 3.10.2 of https://github.khronos.org/KTX-Specification/ (search for "Basis Universal UASTC Format")
- Correctly map from the sample information channel type to `DataFormat`
- Correctly configure transcoding and the resulting texture format based on the `DataFormat`
---
## Changelog
- Fixed: KTX2 UASTC format handling
# Use Case
Seems generally useful, but specifically motivated by my work on the [`bevy_datasize`](https://github.com/BGR360/bevy_datasize) crate.
For that project, I'm implementing "heap size estimators" for all of the Bevy internal types. To do this accurately for `Mesh`, I need to get the lengths of all of the mesh's attribute vectors.
Currently, in order to accomplish this, I am doing the following:
* Checking all of the attributes that are mentioned in the `Mesh` class ([see here](0531ec2d02/src/builtins/render/mesh.rs (L46-L54)))
* Providing the user with an option to configure additional attributes to check ([see here](0531ec2d02/src/config.rs (L7-L21)))
This is both overly complicated and a bit wasteful (since I have to check every attribute name that I know about in case there are attributes set for it).
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Working with a large number of entities with `Aabbs`, rendered with an instanced shader, I found the bottleneck became the frustum culling system. The goal of this PR is to significantly improve culling performance without any major changes. We should consider constructing a BVH for more substantial improvements.
## Solution
- Convert the inner entity query to a parallel iterator with `par_for_each_mut` using a batch size of 1,024.
- This outperforms single threaded culling when there are more than 1,000 entities.
- Below this they are approximately equal, with <= 10 microseconds of multithreading overhead.
- Above this, the multithreaded version is significantly faster, scaling linearly with core count.
- In my million-entity-workload, this PR improves my framerate by 200% - 300%.
## log-log of `check_visibility` time vs. entities for single/multithreaded
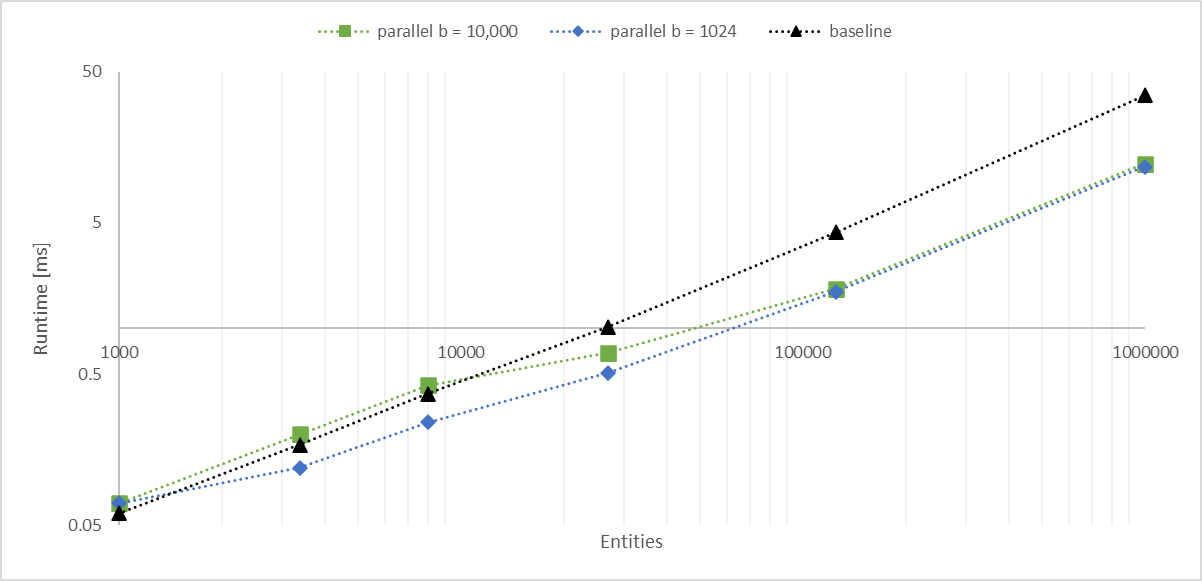
---
## Changelog
Frustum culling is now run with a parallel query. When culling more than a thousand entities, this is faster than the previous method, scaling proportionally with the number of available cores.
# Objective
- Builds on top of #4901
- Separate out PBR lighting, shadows, clustered forward, and utils from `pbr.wgsl` as part of making the PBR code more reusable and extensible.
- See #3969 for details.
## Solution
- Add `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
---
## Changelog
- Added: `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}