# Objective
My motivation are to resolve some of the issues I describe in this
[PR](https://github.com/bevyengine/bevy/issues/11415):
- not being able to easily mapping entities because the current
EntityMapper requires `&mut World` access
- not being able to create my own `EntityMapper` because some components
(`Parent` or `Children`) do not provide any public way of modifying the
inner entities
This PR makes the `MapEntities` trait accept a generic type that
implements `Mapper` to perform the mapping.
This means we don't need to use `EntityMapper` to perform our mapping,
we can use any type that implements `Mapper`. Basically this change is
very similar to what `serde` does. Instead of specifying directly how to
map entities for a given type, we have 2 distinct steps:
- the user implements `MapEntities` to define how the type will be
traversed and which `Entity`s will be mapped
- the `Mapper` defines how the mapping is actually done
This is similar to the distinction between `Serialize` (`MapEntities`)
and `Serializer` (`Mapper`).
This allows networking library to map entities without having to use the
existing `EntityMapper` (which requires `&mut World` access and the use
of `world_scope()`)
## Migration Guide
- The existing `EntityMapper` (notably used to replicate `Scenes` across
different `World`s) has been renamed to `SceneEntityMapper`
- The `MapEntities` trait now works with a generic `EntityMapper`
instead of the specific struct `EntityMapper`.
Calls to `fn map_entities(&mut self, entity_mapper: &mut EntityMapper)`
need to be updated to
`fn map_entities<M: EntityMapper>(&mut self, entity_mapper: &mut M)`
- The new trait `EntityMapper` has been added to the prelude
---------
Co-authored-by: Charles Bournhonesque <cbournhonesque@snapchat.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: UkoeHB <37489173+UkoeHB@users.noreply.github.com>
# Objective
allow automatic fixing of bad joint weights.
fix#10447
## Solution
- remove automatic normalization of vertexes with all zero joint
weights.
- add `Mesh::normalize_joint_weights` which fixes zero joint weights,
and also ensures that all weights sum to 1. this is a manual call as it
may be slow to apply to large skinned meshes, and is unnecessary if you
have control over the source assets.
note: this became a more significant problem with 0.12, as weights that
are close to, but not exactly 1 now seem to use `Vec3::ZERO` for the
unspecified weight, where previously they used the entity translation.
# Objective
After #10520, I was experiencing seriously degraded performance that
ended up being due to never-drained `AssetEvent` events causing havoc
inside `extract_render_asset::<A>`. The same events being read over and
over again meant the same assets were being prepared every frame for
eternity. For what it's worth, I was noticing this on a static scene
about every 3rd or so time running my project.
* References #10520
* Fixes#11240
Why these events aren't sometimes drained between frames is beyond me
and perhaps worthy of another investigation, but the approach in this PR
effectively restores the original cached `EventReader` behavior (which
fixes it).
## Solution
I followed the [`CachedSystemState`
example](3a666cab23/crates/bevy_ecs/src/system/function_system.rs (L155))
to make sure that the `EventReader` state is cached between frames like
it used to be when it was an argument of `extract_render_asset::<A>`.
# Objective
Keep core dependencies up to date.
## Solution
Update the dependencies.
wgpu 0.19 only supports raw-window-handle (rwh) 0.6, so bumping that was
included in this.
The rwh 0.6 version bump is just the simplest way of doing it. There
might be a way we can take advantage of wgpu's new safe surface creation
api, but I'm not familiar enough with bevy's window management to
untangle it and my attempt ended up being a mess of lifetimes and rustc
complaining about missing trait impls (that were implemented). Thanks to
@MiniaczQ for the (much simpler) rwh 0.6 version bump code.
Unblocks https://github.com/bevyengine/bevy/pull/9172 and
https://github.com/bevyengine/bevy/pull/10812
~~This might be blocked on cpal and oboe updating their ndk versions to
0.8, as they both currently target ndk 0.7 which uses rwh 0.5.2~~ Tested
on android, and everything seems to work correctly (audio properly stops
when minimized, and plays when re-focusing the app).
---
## Changelog
- `wgpu` has been updated to 0.19! The long awaited arcanization has
been merged (for more info, see
https://gfx-rs.github.io/2023/11/24/arcanization.html), and Vulkan
should now be working again on Intel GPUs.
- Targeting WebGPU now requires that you add the new `webgpu` feature
(setting the `RUSTFLAGS` environment variable to
`--cfg=web_sys_unstable_apis` is still required). This feature currently
overrides the `webgl2` feature if you have both enabled (the `webgl2`
feature is enabled by default), so it is not recommended to add it as a
default feature to libraries without putting it behind a flag that
allows library users to opt out of it! In the future we plan on
supporting wasm binaries that can target both webgl2 and webgpu now that
wgpu added support for doing so (see
https://github.com/bevyengine/bevy/issues/11505).
- `raw-window-handle` has been updated to version 0.6.
## Migration Guide
- `bevy_render::instance_index::get_instance_index()` has been removed
as the webgl2 workaround is no longer required as it was fixed upstream
in wgpu. The `BASE_INSTANCE_WORKAROUND` shaderdef has also been removed.
- WebGPU now requires the new `webgpu` feature to be enabled. The
`webgpu` feature currently overrides the `webgl2` feature so you no
longer need to disable all default features and re-add them all when
targeting `webgpu`, but binaries built with both the `webgpu` and
`webgl2` features will only target the webgpu backend, and will only
work on browsers that support WebGPU.
- Places where you conditionally compiled things for webgl2 need to be
updated because of this change, eg:
- `#[cfg(any(not(feature = "webgl"), not(target_arch = "wasm32")))]`
becomes `#[cfg(any(not(feature = "webgl") ,not(target_arch = "wasm32"),
feature = "webgpu"))]`
- `#[cfg(all(feature = "webgl", target_arch = "wasm32"))]` becomes
`#[cfg(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))]`
- `if cfg!(all(feature = "webgl", target_arch = "wasm32"))` becomes `if
cfg!(all(feature = "webgl", target_arch = "wasm32", not(feature =
"webgpu")))`
- `create_texture_with_data` now also takes a `TextureDataOrder`. You
can probably just set this to `TextureDataOrder::default()`
- `TextureFormat`'s `block_size` has been renamed to `block_copy_size`
- See the `wgpu` changelog for anything I might've missed:
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md
---------
Co-authored-by: François <mockersf@gmail.com>
Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>Even better no_std</h2>
<p>Switching from thiserror to derive_more allows for no_std builds on
stable rust</p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/blob/master/Changelog.md">ruzstd's
changelog</a>.</em></p>
<blockquote>
<h1>After 0.5.0</h1>
<ul>
<li>Make the hashing checksum optional (thanks to <a
href="https://github.com/tamird"><code>@tamird</code></a>)
<ul>
<li>breaking change as the public API changes based on features</li>
</ul>
</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="e620d2a856"><code>e620d2a</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/50">#50</a>
from KillingSpark/remove_thiserror</li>
<li><a
href="9e9d204c63"><code>9e9d204</code></a>
make clippy happy</li>
<li><a
href="f4a6fc0cc1"><code>f4a6fc0</code></a>
bump the version, this is an incompatible change</li>
<li><a
href="64d65b5c4f"><code>64d65b5</code></a>
fix test compile...</li>
<li><a
href="07bbda98c8"><code>07bbda9</code></a>
remove the error_in_core feature and switch the io_nostd to use the
Display t...</li>
<li><a
href="e15eb1e568"><code>e15eb1e</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/49">#49</a>
from tamird/clippy</li>
<li><a
href="92a3f2e6b2"><code>92a3f2e</code></a>
Avoid unnecessary cast</li>
<li><a
href="f588d5c362"><code>f588d5c</code></a>
Avoid slow zero-filling initialization</li>
<li><a
href="e79f09876f"><code>e79f098</code></a>
Avoid single-match expression</li>
<li><a
href="c75cc2fbb9"><code>c75cc2f</code></a>
Remove useless assertion</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.4.0...v0.5.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- Prep for https://github.com/bevyengine/bevy/pull/10164
- Make deferred_lighting_pass_id a ColorAttachment
- Correctly extract shadow view frusta so that the view uniforms get
populated
- Make some needed things public
- Misc formatting
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
- Add the ability to describe storage texture bindings when deriving
`AsBindGroup`.
- This is especially valuable for the compute story of bevy which
deserves some extra love imo.
## Solution
- This add the ability to annotate struct fields with a
`#[storage_texture(0)]` annotation.
- Instead of adding specific option parsing for all the image formats
and access modes, I simply accept a token stream and defer checking to
see if the option is valid to the compiler. This still results in useful
and friendly errors and is free to maintain and always compatible with
wgpu changes.
---
## Changelog
- The `#[storage_texture(..)]` annotation is now accepted for fields of
`Handle<Image>` in structs that derive `AsBindGroup`.
- The game_of_life compute shader example has been updated to use
`AsBindGroup` together with `[storage_texture(..)]` to obtain the
`BindGroupLayout`.
## Migration Guide
# Objective
- since #9685 ,bevy introduce automatic batching of draw commands,
- `batch_and_prepare_render_phase` take the responsibility for batching
`phaseItem`,
- `GetBatchData` trait is used for indentify each phaseitem how to
batch. it defines a associated type `Data `used for Query to fetch data
from world.
- however,the impl of `GetBatchData ` in bevy always set ` type
Data=Entity` then we acually get following code
`let entity:Entity =query.get(item.entity())` that cause unnecessary
overhead .
## Solution
- remove associated type `Data ` and `Filter` from `GetBatchData `,
- change the type of the `query_item ` parameter in get_batch_data from`
Self::Data` to `Entity`.
- `batch_and_prepare_render_phase ` no longer takes a query using
`F::Data, F::Filter`
- `get_batch_data `now returns `Option<(Self::BufferData,
Option<Self::CompareData>)>`
---
## Performance
based in main merged with #11290
Window 11 ,Intel 13400kf, NV 4070Ti

frame time from 3.34ms to 3 ms, ~ 10%
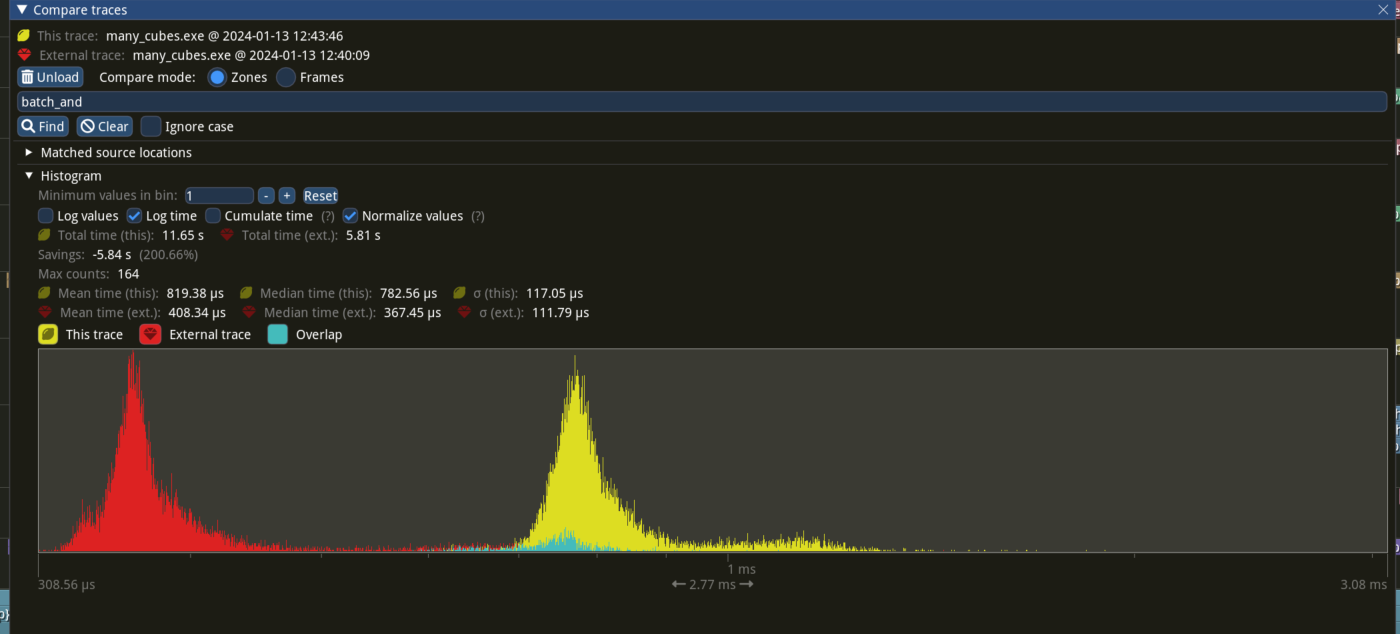
`batch_and_prepare_render_phase` from 800us ~ 400 us
## Migration Guide
trait `GetBatchData` no longer hold associated type `Data `and `Filter`
`get_batch_data` `query_item `type from `Self::Data` to `Entity` and
return `Option<(Self::BufferData, Option<Self::CompareData>)>`
`batch_and_prepare_render_phase` should not have a query
This pull request re-submits #10057, which was backed out for breaking
macOS, iOS, and Android. I've tested this version on macOS and Android
and on the iOS simulator.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
- Some users want to change the default texture usage of the main camera
but they are currently hardcoded
## Solution
- Add a component that is used to configure the main texture usage field
---
## Changelog
Added `CameraMainTextureUsage`
Added `CameraMainTextureUsage` to `Camera3dBundle` and `Camera2dBundle`
## Migration Guide
Add `main_texture_usages: Default::default()` to your camera bundle.
# Notes
Inspired by: #6815
# Objective
- `DynamicUniformBuffer::push` takes an owned `T` but only uses a shared
reference to it
- This in turn requires users of `DynamicUniformBuffer::push` to
potentially unecessarily clone data
## Solution
- Have `DynamicUniformBuffer::push` take a shared reference to `T`
---
## Changelog
- `DynamicUniformBuffer::push` now takes a `&T` instead of `T`
## Migration Guide
- Users of `DynamicUniformBuffer::push` now need to pass references to
`DynamicUniformBuffer::push` (e.g. existing `uniforms.push(value)` will
now become `uniforms.push(&value)`)
Rebased and finished version of
https://github.com/bevyengine/bevy/pull/8407. Huge thanks to @GitGhillie
for adjusting all the examples, and the many other people who helped
write this PR (@superdump , @coreh , among others) :)
Fixes https://github.com/bevyengine/bevy/issues/8369
---
## Changelog
- Added a `brightness` control to `Skybox`.
- Added an `intensity` control to `EnvironmentMapLight`.
- Added `ExposureSettings` and `PhysicalCameraParameters` for
controlling exposure of 3D cameras.
- Removed the baked-in `DirectionalLight` exposure Bevy previously
hardcoded internally.
## Migration Guide
- If using a `Skybox` or `EnvironmentMapLight`, use the new `brightness`
and `intensity` controls to adjust their strength.
- All 3D scene will now have different apparent brightnesses due to Bevy
implementing proper exposure controls. You will have to adjust the
intensity of your lights and/or your camera exposure via the new
`ExposureSettings` component to compensate.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: GitGhillie <jillisnoordhoek@gmail.com>
Co-authored-by: Marco Buono <thecoreh@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
Add support for presenting each UI tree on a specific window and
viewport, while making as few breaking changes as possible.
This PR is meant to resolve the following issues at once, since they're
all related.
- Fixes#5622
- Fixes#5570
- Fixes#5621
Adopted #5892 , but started over since the current codebase diverged
significantly from the original PR branch. Also, I made a decision to
propagate component to children instead of recursively iterating over
nodes in search for the root.
## Solution
Add a new optional component that can be inserted to UI root nodes and
propagate to children to specify which camera it should render onto.
This is then used to get the render target and the viewport for that UI
tree. Since this component is optional, the default behavior should be
to render onto the single camera (if only one exist) and warn of
ambiguity if multiple cameras exist. This reduces the complexity for
users with just one camera, while giving control in contexts where it
matters.
## Changelog
- Adds `TargetCamera(Entity)` component to specify which camera should a
node tree be rendered into. If only one camera exists, this component is
optional.
- Adds an example of rendering UI to a texture and using it as a
material in a 3D world.
- Fixes recalculation of physical viewport size when target scale factor
changes. This can happen when the window is moved between displays with
different DPI.
- Changes examples to demonstrate assigning UI to different viewports
and windows and make interactions in an offset viewport testable.
- Removes `UiCameraConfig`. UI visibility now can be controlled via
combination of explicit `TargetCamera` and `Visibility` on the root
nodes.
---------
Co-authored-by: davier <bricedavier@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
- Update async channel to v2.
## Solution
- async channel doesn't support `send_blocking` on wasm anymore. So
don't compile the pipelined rendering plugin on wasm anymore.
- Replaces https://github.com/bevyengine/bevy/pull/10405
## Migration Guide
- The `PipelinedRendering` plugin is no longer exported on wasm. If you
are including it in your wasm builds you should remove it.
```rust
#[cfg(all(not(target_arch = "wasm32"))]
app.add_plugins(bevy_render::pipelined_rendering::PipelinedRenderingPlugin);
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Issue #10243: rendering multiple triangles in the same place results in
flickering.
## Solution
Considered these alternatives:
- `depth_bias` may not work, because of high number of entities, so
creating a material per entity is practically not possible
- rendering at slightly different positions does not work, because when
camera is far, float rounding causes the same issues (edit: assuming we
have to use the same `depth_bias`)
- considered implementing deterministic operation like
`query.par_iter().flat_map(...).collect()` to be used in
`check_visibility` system (which would solve the issue since query is
deterministic), and could not figure out how to make it as cheap as
current approach with thread-local collectors (#11249)
So adding an option to sort entities after `check_visibility` system
run.
Should not be too bad, because after visibility check, only a handful
entities remain.
This is probably not the only source of non-determinism in Bevy, but
this is one I could find so far. At least it fixes the repro example.
## Changelog
- `DeterministicRenderingConfig` option to enable deterministic
rendering
## Test
<img width="1392" alt="image"
src="https://github.com/bevyengine/bevy/assets/28969/c735bce1-3a71-44cd-8677-c19f6c0ee6bd">
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Update to `glam` 0.25, `encase` 0.7 and `hexasphere` to 10.0
## Changelog
Added the `FloatExt` trait to the `bevy_math` prelude which adds `lerp`,
`inverse_lerp` and `remap` methods to the `f32` and `f64` types.
# Objective
This pull request implements *reflection probes*, which generalize
environment maps to allow for multiple environment maps in the same
scene, each of which has an axis-aligned bounding box. This is a
standard feature of physically-based renderers and was inspired by [the
corresponding feature in Blender's Eevee renderer].
## Solution
This is a minimal implementation of reflection probes that allows
artists to define cuboid bounding regions associated with environment
maps. For every view, on every frame, a system builds up a list of the
nearest 4 reflection probes that are within the view's frustum and
supplies that list to the shader. The PBR fragment shader searches
through the list, finds the first containing reflection probe, and uses
it for indirect lighting, falling back to the view's environment map if
none is found. Both forward and deferred renderers are fully supported.
A reflection probe is an entity with a pair of components, *LightProbe*
and *EnvironmentMapLight* (as well as the standard *SpatialBundle*, to
position it in the world). The *LightProbe* component (along with the
*Transform*) defines the bounding region, while the
*EnvironmentMapLight* component specifies the associated diffuse and
specular cubemaps.
A frequent question is "why two components instead of just one?" The
advantages of this setup are:
1. It's readily extensible to other types of light probes, in particular
*irradiance volumes* (also known as ambient cubes or voxel global
illumination), which use the same approach of bounding cuboids. With a
single component that applies to both reflection probes and irradiance
volumes, we can share the logic that implements falloff and blending
between multiple light probes between both of those features.
2. It reduces duplication between the existing *EnvironmentMapLight* and
these new reflection probes. Systems can treat environment maps attached
to cameras the same way they treat environment maps applied to
reflection probes if they wish.
Internally, we gather up all environment maps in the scene and place
them in a cubemap array. At present, this means that all environment
maps must have the same size, mipmap count, and texture format. A
warning is emitted if this restriction is violated. We could potentially
relax this in the future as part of the automatic mipmap generation
work, which could easily do texture format conversion as part of its
preprocessing.
An easy way to generate reflection probe cubemaps is to bake them in
Blender and use the `export-blender-gi` tool that's part of the
[`bevy-baked-gi`] project. This tool takes a `.blend` file containing
baked cubemaps as input and exports cubemap images, pre-filtered with an
embedded fork of the [glTF IBL Sampler], alongside a corresponding
`.scn.ron` file that the scene spawner can use to recreate the
reflection probes.
Note that this is intentionally a minimal implementation, to aid
reviewability. Known issues are:
* Reflection probes are basically unsupported on WebGL 2, because WebGL
2 has no cubemap arrays. (Strictly speaking, you can have precisely one
reflection probe in the scene if you have no other cubemaps anywhere,
but this isn't very useful.)
* Reflection probes have no falloff, so reflections will abruptly change
when objects move from one bounding region to another.
* As mentioned before, all cubemaps in the world of a given type
(diffuse or specular) must have the same size, format, and mipmap count.
Future work includes:
* Blending between multiple reflection probes.
* A falloff/fade-out region so that reflected objects disappear
gradually instead of vanishing all at once.
* Irradiance volumes for voxel-based global illumination. This should
reuse much of the reflection probe logic, as they're both GI techniques
based on cuboid bounding regions.
* Support for WebGL 2, by breaking batches when reflection probes are
used.
These issues notwithstanding, I think it's best to land this with
roughly the current set of functionality, because this patch is useful
as is and adding everything above would make the pull request
significantly larger and harder to review.
---
## Changelog
### Added
* A new *LightProbe* component is available that specifies a bounding
region that an *EnvironmentMapLight* applies to. The combination of a
*LightProbe* and an *EnvironmentMapLight* offers *reflection probe*
functionality similar to that available in other engines.
[the corresponding feature in Blender's Eevee renderer]:
https://docs.blender.org/manual/en/latest/render/eevee/light_probes/reflection_cubemaps.html
[`bevy-baked-gi`]: https://github.com/pcwalton/bevy-baked-gi
[glTF IBL Sampler]: https://github.com/KhronosGroup/glTF-IBL-Sampler
# Objective
- Since #10702, the way bevy updates the window leads to major slowdowns
as seen in
- #11122
- #11220
- Slow is bad, furthermore, _very_ slow is _very_ bad. We should fix
this issue.
## Solution
- Move the app update code into the `Event::WindowEvent { event:
WindowEvent::RedrawRequested }` branch of the event loop.
- Run `window.request_redraw()` When `runner_state.redraw_requested`
- Instead of swapping `ControlFlow` between `Poll` and `Wait`, we always
keep it at `Wait`, and use `window.request_redraw()` to schedule an
immediate call to the event loop.
- `runner_state.redraw_requested` is set to `true` when
`UpdateMode::Continuous` and when a `RequestRedraw` event is received.
- Extract the redraw code into a separate function, because otherwise
I'd go crazy with the indentation level.
- Fix#11122.
## Testing
I tested the WASM builds as follow:
```sh
cargo run -p build-wasm-example -- --api webgl2 bevymark
python -m http.server --directory examples/wasm/ 8080
# Open browser at http://localhost:8080
```
On main, even spawning a couple sprites is super choppy. Even if it says
"300 FPS". While on this branch, it is smooth as butter.
I also found that it fixes all choppiness on window resize (tested on
Linux/X11). This was another issue from #10702 IIRC.
So here is what I tested:
- On `wasm`: `many_foxes` and `bevymark`, with `argh::from_env()`
commented out, otherwise we get a cryptic error.
- Both with `PresentMode::AutoVsync` and `PresentMode::AutoNoVsync`
- On main, it is consistently choppy.
- With this PR, the visible frame rate is consistent with the diagnostic
numbers
- On native (linux/x11) I ran similar tests, making sure that
`AutoVsync` limits to monitor framerate, and `AutoNoVsync` doesn't.
## Future work
Code could be improved, I wanted a quick solution easy to review, but we
really need to make the code more accessible.
- #9768
- ~~**`WinitSettings::desktop_app()` is completely borked.**~~ actually
broken on main as well
### Review guide
Consider enable the non-whitespace diff to see the _real_ change set.
# Objective
- Since #10520, assets are unloaded from RAM by default. This breaks a
number of scenario:
- using `load_folder`
- loading a gltf, then going through its mesh to transform them /
compute a collider / ...
- any assets/subassets scenario should be `Keep` as you can't know what
the user will do with the assets
- android suspension, where GPU memory is unloaded
- Alternative to #11202
## Solution
- Keep assets on CPU memory by default
# Objective
In my code I use a lot of images as render targets.
I'd like some convenience methods for working with this type.
## Solution
- Allow `.into()` to construct a `RenderTarget`
- Add `.as_image()`
---
## Changelog
### Added
- `RenderTarget` can be constructed via `.into()` on a `Handle<Image>`
- `RenderTarget` new method: `as_image`
---------
Signed-off-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
Co-authored-by: Torstein Grindvik <torstein.grindvik@muybridge.com>
# Objective
- No point in keeping Meshes/Images in RAM once they're going to be sent
to the GPU, and kept in VRAM. This saves a _significant_ amount of
memory (several GBs) on scenes like bistro.
- References
- https://github.com/bevyengine/bevy/pull/1782
- https://github.com/bevyengine/bevy/pull/8624
## Solution
- Augment RenderAsset with the capability to unload the underlying asset
after extracting to the render world.
- Mesh/Image now have a cpu_persistent_access field. If this field is
RenderAssetPersistencePolicy::Unload, the asset will be unloaded from
Assets<T>.
- A new AssetEvent is sent upon dropping the last strong handle for the
asset, which signals to the RenderAsset to remove the GPU version of the
asset.
---
## Changelog
- Added `AssetEvent::NoLongerUsed` and
`AssetEvent::is_no_longer_used()`. This event is sent when the last
strong handle of an asset is dropped.
- Rewrote the API for `RenderAsset` to allow for unloading the asset
data from the CPU.
- Added `RenderAssetPersistencePolicy`.
- Added `Mesh::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `Image::cpu_persistent_access` for memory savings when the asset
is not needed except for on the GPU.
- Added `ImageLoaderSettings::cpu_persistent_access`.
- Added `ExrTextureLoaderSettings`.
- Added `HdrTextureLoaderSettings`.
## Migration Guide
- Asset loaders (GLTF, etc) now load meshes and textures without
`cpu_persistent_access`. These assets will be removed from
`Assets<Mesh>` and `Assets<Image>` once `RenderAssets<Mesh>` and
`RenderAssets<Image>` contain the GPU versions of these assets, in order
to reduce memory usage. If you require access to the asset data from the
CPU in future frames after the GLTF asset has been loaded, modify all
dependent `Mesh` and `Image` assets and set `cpu_persistent_access` to
`RenderAssetPersistencePolicy::Keep`.
- `Mesh` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `Image` now requires a new `cpu_persistent_access` field. Set it to
`RenderAssetPersistencePolicy::Keep` to mimic the previous behavior.
- `MorphTargetImage::new()` now requires a new `cpu_persistent_access`
parameter. Set it to `RenderAssetPersistencePolicy::Keep` to mimic the
previous behavior.
- `DynamicTextureAtlasBuilder::add_texture()` now requires that the
`TextureAtlas` you pass has an `Image` with `cpu_persistent_access:
RenderAssetPersistencePolicy::Keep`. Ensure you construct the image
properly for the texture atlas.
- The `RenderAsset` trait has significantly changed, and requires
adapting your existing implementations.
- The trait now requires `Clone`.
- The `ExtractedAsset` associated type has been removed (the type itself
is now extracted).
- The signature of `prepare_asset()` is slightly different
- A new `persistence_policy()` method is now required (return
RenderAssetPersistencePolicy::Unload to match the previous behavior).
- Match on the new `NoLongerUsed` variant for exhaustive matches of
`AssetEvent`.
# Objective
There are a lot of doctests that are `ignore`d for no documented reason.
And that should be fixed.
## Solution
I searched the bevy repo with the regex ` ```[a-z,]*ignore ` in order to
find all `ignore`d doctests. For each one of the `ignore`d doctests, I
did the following steps:
1. Attempt to remove the `ignored` attribute while still passing the
test. I did this by adding hidden dummy structs and imports.
2. If step 1 doesn't work, attempt to replace the `ignored` attribute
with the `no_run` attribute while still passing the test.
3. If step 2 doesn't work, keep the `ignored` attribute but add
documentation for why the `ignored` attribute was added.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Custom render passes, or future passes in the engine (such as
https://github.com/bevyengine/bevy/pull/10164) need a better way to know
and indicate to the core passes whether the view color/depth/prepass
attachments have been cleared or not yet this frame, to know if they
should clear it themselves or load it.
## Solution
- For all render targets (depth textures, shadow textures, prepass
textures, main textures) use an atomic bool to track whether or not each
texture has been cleared this frame. Abstracted away in the new
ColorAttachment and DepthAttachment wrappers.
---
## Changelog
- Changed `ViewTarget::get_color_attachment()`, removed arguments.
- Changed `ViewTarget::get_unsampled_color_attachment()`, removed
arguments.
- Removed `Camera3d::clear_color`.
- Removed `Camera2d::clear_color`.
- Added `Camera::clear_color`.
- Added `ExtractedCamera::clear_color`.
- Added `ColorAttachment` and `DepthAttachment` wrappers.
- Moved `ClearColor` and `ClearColorConfig` from
`bevy::core_pipeline::clear_color` to `bevy::render::camera`.
- Core render passes now track when a texture is first bound as an
attachment in order to decide whether to clear or load it.
## Migration Guide
- Remove arguments to `ViewTarget::get_color_attachment()` and
`ViewTarget::get_unsampled_color_attachment()`.
- Configure clear color on `Camera` instead of on `Camera3d` and
`Camera2d`.
- Moved `ClearColor` and `ClearColorConfig` from
`bevy::core_pipeline::clear_color` to `bevy::render::camera`.
- `ViewDepthTexture` must now be created via the `new()` method
---------
Co-authored-by: vero <email@atlasdostal.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Make the implementation order consistent between all sources to fit
the order in the trait.
## Solution
- Change the implementation order.
Matches versioning & features from other Cargo.toml files in the
project.
# Objective
Resolves#10932
## Solution
Added smallvec to the bevy_utils cargo.toml and added a line to
re-export the crate. Target version and features set to match what's
used in the other bevy crates.
The error conditions were not documented, this requires the user to
inspect the source code to know when to expect a `None`.
Error conditions should always be documented, so we document them.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fix an inconsistency in the calculation of aspect ratio's.
- Fixes#10288
## Solution
- Created an intermediate `AspectRatio` struct, as suggested in the
issue. This is currently just used in any places where aspect ratio
calculations happen, to prevent doing it wrong. In my and @mamekoro 's
opinion, it would be better if this was used instead of a normal `f32`
in various places, but I didn't want to make too many changes to begin
with.
## Migration Guide
- Anywhere where you are currently expecting a f32 when getting aspect
ratios, you will now receive a `AspectRatio` struct. this still holds
the same value.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Users are often confused when their command effects are not visible in
the next system. This PR auto inserts sync points if there are deferred
buffers on a system and there are dependents on that system (systems
with after relationships).
- Manual sync points can lead to users adding more than needed and it's
hard for the user to have a global understanding of their system graph
to know which sync points can be merged. However we can easily calculate
which sync points can be merged automatically.
## Solution
1. Add new edge types to allow opting out of new behavior
2. Insert an sync point for each edge whose initial node has deferred
system params.
3. Reuse nodes if they're at the number of sync points away.
* add opt outs for specific edges with `after_ignore_deferred`,
`before_ignore_deferred` and `chain_ignore_deferred`. The
`auto_insert_apply_deferred` boolean on `ScheduleBuildSettings` can be
set to false to opt out for the whole schedule.
## Perf
This has a small negative effect on schedule build times.
```text
group auto-sync main-for-auto-sync
----- ----------- ------------------
build_schedule/1000_schedule 1.06 2.8±0.15s ? ?/sec 1.00 2.7±0.06s ? ?/sec
build_schedule/1000_schedule_noconstraints 1.01 26.2±0.88ms ? ?/sec 1.00 25.8±0.36ms ? ?/sec
build_schedule/100_schedule 1.02 13.1±0.33ms ? ?/sec 1.00 12.9±0.28ms ? ?/sec
build_schedule/100_schedule_noconstraints 1.08 505.3±29.30µs ? ?/sec 1.00 469.4±12.48µs ? ?/sec
build_schedule/500_schedule 1.00 485.5±6.29ms ? ?/sec 1.00 485.5±9.80ms ? ?/sec
build_schedule/500_schedule_noconstraints 1.00 6.8±0.10ms ? ?/sec 1.02 6.9±0.16ms ? ?/sec
```
---
## Changelog
- Auto insert sync points and added `after_ignore_deferred`,
`before_ignore_deferred`, `chain_no_deferred` and
`auto_insert_apply_deferred` APIs to opt out of this behavior
## Migration Guide
- `apply_deferred` points are added automatically when there is ordering
relationship with a system that has deferred parameters like `Commands`.
If you want to opt out of this you can switch from `after`, `before`,
and `chain` to the corresponding `ignore_deferred` API,
`after_ignore_deferred`, `before_ignore_deferred` or
`chain_ignore_deferred` for your system/set ordering.
- You can also set `ScheduleBuildSettings::auto_insert_sync_points` to
`false` if you want to do it for the whole schedule. Note that in this
mode you can still add `apply_deferred` points manually.
- For most manual insertions of `apply_deferred` you should remove them
as they cannot be merged with the automatically inserted points and
might reduce parallelizability of the system graph.
## TODO
- [x] remove any apply_deferred used in the engine
- [x] ~~decide if we should deprecate manually using apply_deferred.~~
We'll still allow inserting manual sync points for now for whatever edge
cases users might have.
- [x] Update migration guide
- [x] rerun schedule build benchmarks
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
- Finish the work done in #8942 .
## Solution
- Rebase the changes made in #8942 and fix the issues stopping it from
being merged earlier
---------
Co-authored-by: Thomas <1234328+thmsgntz@users.noreply.github.com>
# Objective
Keep up to date with wgpu.
## Solution
Update the wgpu version.
Currently blocked on naga_oil updating to naga 0.14 and releasing a new
version.
3d scenes (or maybe any scene with lighting?) currently don't render
anything due to
```
error: naga_oil bug, please file a report: composer failed to build a valid header: Type [2] '' is invalid
= Capability Capabilities(CUBE_ARRAY_TEXTURES) is required
```
I'm not sure what should be passed in for `wgpu::InstanceFlags`, or if we want to make the gles3minorversion configurable (might be useful for debugging?)
Currently blocked on https://github.com/bevyengine/naga_oil/pull/63, and https://github.com/gfx-rs/wgpu/issues/4569 to be fixed upstream in wgpu first.
## Known issues
Amd+windows+vulkan has issues with texture_binding_arrays (see the image [here](https://github.com/bevyengine/bevy/pull/10266#issuecomment-1819946278)), but that'll be fixed in the next wgpu/naga version, and you can just use dx12 as a workaround for now (Amd+linux mesa+vulkan texture_binding_arrays are fixed though).
---
## Changelog
Updated wgpu to 0.18, naga to 0.14.2, and naga_oil to 0.11.
- Windows desktop GL should now be less painful as it no longer requires Angle.
- You can now toggle shader validation and debug information for debug and release builds using `WgpuSettings.instance_flags` and [InstanceFlags](https://docs.rs/wgpu/0.18.0/wgpu/struct.InstanceFlags.html)
## Migration Guide
- `RenderPassDescriptor` `color_attachments` (as well as `RenderPassColorAttachment`, and `RenderPassDepthStencilAttachment`) now use `StoreOp::Store` or `StoreOp::Discard` instead of a `boolean` to declare whether or not they should be stored.
- `RenderPassDescriptor` now have `timestamp_writes` and `occlusion_query_set` fields. These can safely be set to `None`.
- `ComputePassDescriptor` now have a `timestamp_writes` field. This can be set to `None` for now.
- See the [wgpu changelog](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v0180-2023-10-25) for additional details
I didn't notice minus where vertices are generated, so could not
understand the order there.
Adding a comment to help the next person who is going to understand Bevy
by reading its code.