mirror of
https://github.com/bevyengine/bevy
synced 2025-02-18 15:08:36 +00:00
49 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
694c06f3d0
|
Inverse missing_docs logic (#11676)
# Objective Currently the `missing_docs` lint is allowed-by-default and enabled at crate level when their documentations is complete (see #3492). This PR proposes to inverse this logic by making `missing_docs` warn-by-default and mark crates with imcomplete docs allowed. ## Solution Makes `missing_docs` warn at workspace level and allowed at crate level when the docs is imcomplete. |
||
|
|
eb07d16871
|
Revert rendering-related associated type name changes (#11027)
# Objective > Can anyone explain to me the reasoning of renaming all the types named Query to Data. I'm talking about this PR https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to me that a bunch of types that are used to run queries aren't named Query anymore. Like ViewQuery on the ViewNode is the type of the Query. I don't really understand the point of the rename, it just seems like it hides the fact that a query will run based on those types. [@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387) ## Solution Revert several renames in #10779. ## Changelog - `ViewNode::ViewData` is now `ViewNode::ViewQuery` again. ## Migration Guide - This PR amends the migration guide in https://github.com/bevyengine/bevy/pull/10779 --------- Co-authored-by: atlas dostal <rodol@rivalrebels.com> |
||
|
|
a795de30b4
|
Use impl Into<A> for Assets::add (#10878)
# Motivation
When spawning entities into a scene, it is very common to create assets
like meshes and materials and to add them via asset handles. A common
setup might look like this:
```rust
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<StandardMaterial>>,
) {
commands.spawn(PbrBundle {
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
..default()
});
}
```
Let's take a closer look at the part that adds the assets using `add`.
```rust
mesh: meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
material: materials.add(StandardMaterial::from(Color::RED)),
```
Here, "mesh" and "material" are both repeated three times. It's very
explicit, but I find it to be a bit verbose. In addition to being more
code to read and write, the extra characters can sometimes also lead to
the code being formatted to span multiple lines even though the core
task, adding e.g. a primitive mesh, is extremely simple.
A way to address this is by using `.into()`:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }.into()),
material: materials.add(Color::RED.into()),
```
This is fine, but from the names and the type of `meshes`, we already
know what the type should be. It's very clear that `Cube` should be
turned into a `Mesh` because of the context it's used in. `.into()` is
just seven characters, but it's so common that it quickly adds up and
gets annoying.
It would be nice if you could skip all of the conversion and let Bevy
handle it for you:
```rust
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
```
# Objective
Make adding assets more ergonomic by making `Assets::add` take an `impl
Into<A>` instead of `A`.
## Solution
`Assets::add` now takes an `impl Into<A>` instead of `A`, so e.g. this
works:
```rust
commands.spawn(PbrBundle {
mesh: meshes.add(shape::Cube { size: 1.0 }),
material: materials.add(Color::RED),
..default()
});
```
I also changed all examples to use this API, which increases consistency
as well because `Mesh::from` and `into` were being used arbitrarily even
in the same file. This also gets rid of some lines of code because
formatting is nicer.
---
## Changelog
- `Assets::add` now takes an `impl Into<A>` instead of `A`
- Examples don't use `T::from(K)` or `K.into()` when adding assets
## Migration Guide
Some `into` calls that worked previously might now be broken because of
the new trait bounds. You need to either remove `into` or perform the
conversion explicitly with `from`:
```rust
// Doesn't compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }.into()),
// These compile
let mesh_handle = meshes.add(shape::Cube { size: 1.0 }),
let mesh_handle = meshes.add(Mesh::from(shape::Cube { size: 1.0 })),
```
## Concerns
I believe the primary concerns might be:
1. Is this too implicit?
2. Does this increase codegen bloat?
Previously, the two APIs were using `into` or `from`, and now it's
"nothing" or `from`. You could argue that `into` is slightly more
explicit than "nothing" in cases like the earlier examples where a
`Color` gets converted to e.g. a `StandardMaterial`, but I personally
don't think `into` adds much value even in this case, and you could
still see the actual type from the asset type.
As for codegen bloat, I doubt it adds that much, but I'm not very
familiar with the details of codegen. I personally value the user-facing
code reduction and ergonomics improvements that these changes would
provide, but it might be worth checking the other effects in more
detail.
Another slight concern is migration pain; apps might have a ton of
`into` calls that would need to be removed, and it did take me a while
to do so for Bevy itself (maybe around 20-40 minutes). However, I think
the fact that there *are* so many `into` calls just highlights that the
API could be made nicer, and I'd gladly migrate my own projects for it.
|
||
|
|
5af2f022d8
|
Rename WorldQueryData & WorldQueryFilter to QueryData & QueryFilter (#10779)
# Rename `WorldQueryData` & `WorldQueryFilter` to `QueryData` & `QueryFilter` Fixes #10776 ## Solution Traits `WorldQueryData` & `WorldQueryFilter` were renamed to `QueryData` and `QueryFilter`, respectively. Related Trait types were also renamed. --- ## Changelog - Trait `WorldQueryData` has been renamed to `QueryData`. Derive macro's `QueryData` attribute `world_query_data` has been renamed to `query_data`. - Trait `WorldQueryFilter` has been renamed to `QueryFilter`. Derive macro's `QueryFilter` attribute `world_query_filter` has been renamed to `query_filter`. - Trait's `ExtractComponent` type `Query` has been renamed to `Data`. - Trait's `GetBatchData` types `Query` & `QueryFilter` has been renamed to `Data` & `Filter`, respectively. - Trait's `ExtractInstance` type `Query` has been renamed to `Data`. - Trait's `ViewNode` type `ViewQuery` has been renamed to `ViewData`. - Trait's `RenderCommand` types `ViewWorldQuery` & `ItemWorldQuery` has been renamed to `ViewData` & `ItemData`, respectively. ## Migration Guide Note: if merged before 0.13 is released, this should instead modify the migration guide of #10776 with the updated names. - Rename `WorldQueryData` & `WorldQueryFilter` trait usages to `QueryData` & `QueryFilter` and their respective derive macro attributes `world_query_data` & `world_query_filter` to `query_data` & `query_filter`. - Rename the following trait type usages: - Trait's `ExtractComponent` type `Query` to `Data`. - Trait's `GetBatchData` type `Query` to `Data`. - Trait's `ExtractInstance` type `Query` to `Data`. - Trait's `ViewNode` type `ViewQuery` to `ViewData`' - Trait's `RenderCommand` types `ViewWolrdQuery` & `ItemWorldQuery` to `ViewData` & `ItemData`, respectively. ```rust // Before #[derive(WorldQueryData)] #[world_query_data(derive(Debug))] struct EmptyQuery { empty: (), } // After #[derive(QueryData)] #[query_data(derive(Debug))] struct EmptyQuery { empty: (), } // Before #[derive(WorldQueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // After #[derive(QueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // Before impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Query = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Query>) -> Option<Self::Out> { //... } } // After impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Data = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Data>) -> Option<Self::Out> { //... } } // Before impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Query = Entity; type QueryFilter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Query>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // After impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Data = Entity; type Filter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Data>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // Before impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Query = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Query>) -> Option<Self> { Some(item.id()) } } // After impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Data = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Data>) -> Option<Self> { Some(item.id()) } } // Before impl ViewNode for PostProcessNode { type ViewQuery = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewQuery>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // After impl ViewNode for PostProcessNode { type ViewData = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewData>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // Before impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewWorldQuery = (); type ItemWorldQuery = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } // After impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewData = (); type ItemData = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } ``` |
||
|
|
4bf20e7d27
|
Swap material and mesh bind groups (#10485)
# Objective - Materials should be a more frequent rebind then meshes (due to being able to use a single vertex buffer, such as in #10164) and therefore should be in a higher bind group. --- ## Changelog - For 2d and 3d mesh/material setups (but not UI materials, or other rendering setups such as gizmos, sprites, or text), mesh data is now in bind group 1, and material data is now in bind group 2, which is swapped from how they were before. ## Migration Guide - Custom 2d and 3d mesh/material shaders should now use bind group 2 `@group(2) @binding(x)` for their bound resources, instead of bind group 1. - Many internal pieces of rendering code have changed so that mesh data is now in bind group 1, and material data is now in bind group 2. Semi-custom rendering setups (that don't use the Material or Material2d APIs) should adapt to these changes. |
||
|
|
0e9f6e92ea
|
Add clippy::manual_let_else at warn level to lints (#10684)
# Objective Related to #10612. Enable the [`clippy::manual_let_else`](https://rust-lang.github.io/rust-clippy/master/#manual_let_else) lint as a warning. The `let else` form seems more idiomatic to me than a `match`/`if else` that either match a pattern or diverge, and from the clippy doc, the lint doesn't seem to have any possible false positive. ## Solution Add the lint as warning in `Cargo.toml`, refactor places where the lint triggers. |
||
|
|
b6ead2be95
|
Use EntityHashMap<Entity, T> for render world entity storage for better performance (#9903)
# Objective - Improve rendering performance, particularly by avoiding the large system commands costs of using the ECS in the way that the render world does. ## Solution - Define `EntityHasher` that calculates a hash from the `Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`. `0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a value close to π and that works well for hashing. Thanks for @SkiFire13 for the suggestion and to @nicopap for alternative suggestions and discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`) with some tweaks for the case of hashing an `Entity`. `FxHasher` and `SeaHasher` were also tested but were significantly slower. - Define `EntityHashMap` type that uses the `EntityHashser` - Use `EntityHashMap<Entity, T>` for render world entity storage, including: - `RenderMaterialInstances` - contains the `AssetId<M>` of the material associated with the entity. Also for 2D. - `RenderMeshInstances` - contains mesh transforms, flags and properties about mesh entities. Also for 2D. - `SkinIndices` and `MorphIndices` - contains the skin and morph index for an entity, respectively - `ExtractedSprites` - `ExtractedUiNodes` ## Benchmarks All benchmarks have been conducted on an M1 Max connected to AC power. The tests are run for 1500 frames. The 1000th frame is captured for comparison to check for visual regressions. There were none. ### 2D Meshes `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` #### `--ordered-z` This test spawns the 2D meshes with z incrementing back to front, which is the ideal arrangement allocation order as it matches the sorted render order which means lookups have a high cache hit rate. <img width="1112" alt="Screenshot 2023-09-27 at 07 50 45" src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb"> -39.1% median frame time. #### Random This test spawns the 2D meshes with random z. This not only makes the batching and transparent 2D pass lookups get a lot of cache misses, it also currently means that the meshes are almost certain to not be batchable. <img width="1108" alt="Screenshot 2023-09-27 at 07 51 28" src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4"> -7.2% median frame time. ### 3D Meshes `many_cubes --benchmark` <img width="1112" alt="Screenshot 2023-09-27 at 07 51 57" src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc"> -7.7% median frame time. ### Sprites **NOTE: On `main` sprites are using `SparseSet<Entity, T>`!** `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` #### `--ordered-z` This test spawns the sprites with z incrementing back to front, which is the ideal arrangement allocation order as it matches the sorted render order which means lookups have a high cache hit rate. <img width="1116" alt="Screenshot 2023-09-27 at 07 52 31" src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67"> +13.0% median frame time. #### Random This test spawns the sprites with random z. This makes the batching and transparent 2D pass lookups get a lot of cache misses. <img width="1109" alt="Screenshot 2023-09-27 at 07 53 01" src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033"> +0.6% median frame time. ### UI **NOTE: On `main` UI is using `SparseSet<Entity, T>`!** `many_buttons` <img width="1111" alt="Screenshot 2023-09-27 at 07 53 26" src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85"> +15.1% median frame time. ## Alternatives - Cart originally suggested trying out `SparseSet<Entity, T>` and indeed that is slightly faster under ideal conditions. However, `PassHashMap<Entity, T>` has better worst case performance when data is randomly distributed, rather than in sorted render order, and does not have the worst case memory usage that `SparseSet`'s dense `Vec<usize>` that maps from the `Entity` index to sparse index into `Vec<T>`. This dense `Vec` has to be as large as the largest Entity index used with the `SparseSet`. - I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()` as the key, but this proved to sometimes be slower and mostly no different. - The only outstanding approach that has not been implemented and tested is to _not_ clear the render world of its entities each frame. That has its own problems, though they could perhaps be solved. - Performance-wise, if the entities and their component data were not cleared, then they would incur table moves on spawn, and should not thereafter, rather just their component data would be overwritten. Ideally we would have a neat way of either updating data in-place via `&mut T` queries, or inserting components if not present. This would likely be quite cumbersome to have to remember to do everywhere, but perhaps it only needs to be done in the more performance-sensitive systems. - The main problem to solve however is that we want to both maintain a mapping between main world entities and render world entities, be able to run the render app and world in parallel with the main app and world for pipelined rendering, and at the same time be able to spawn entities in the render world in such a way that those Entity ids do not collide with those spawned in the main world. This is potentially quite solvable, but could well be a lot of ECS work to do it in a way that makes sense. --- ## Changelog - Changed: Component data for entities to be drawn are no longer stored on entities in the render world. Instead, data is stored in a `EntityHashMap<Entity, T>` in various resources. This brings significant performance benefits due to the way the render app clears entities every frame. Resources of most interest are `RenderMeshInstances` and `RenderMaterialInstances`, and their 2D counterparts. ## Migration Guide Previously the render app extracted mesh entities and their component data from the main world and stored them as entities and components in the render world. Now they are extracted into essentially `EntityHashMap<Entity, T>` where `T` are structs containing an appropriate group of data. This means that while extract set systems will continue to run extract queries against the main world they will store their data in hash maps. Also, systems in later sets will either need to look up entities in the available resources such as `RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>` for their own data. Before: ```rust fn queue_custom( material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>, ) { ... for (entity, mesh_transforms, mesh_handle) in &material_meshes { ... } } ``` After: ```rust fn queue_custom( render_mesh_instances: Res<RenderMeshInstances>, instance_entities: Query<Entity, With<InstanceMaterialData>>, ) { ... for entity in &instance_entities { let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; }; // The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now // be found in `mesh_instance` which is a `RenderMeshInstance` ... } } ``` --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> |
||
|
|
5c884c5a15
|
Automatic batching/instancing of draw commands (#9685)
# Objective - Implement the foundations of automatic batching/instancing of draw commands as the next step from #89 - NOTE: More performance improvements will come when more data is managed and bound in ways that do not require rebinding such as mesh, material, and texture data. ## Solution - The core idea for batching of draw commands is to check whether any of the information that has to be passed when encoding a draw command changes between two things that are being drawn according to the sorted render phase order. These should be things like the pipeline, bind groups and their dynamic offsets, index/vertex buffers, and so on. - The following assumptions have been made: - Only entities with prepared assets (pipelines, materials, meshes) are queued to phases - View bindings are constant across a phase for a given draw function as phases are per-view - `batch_and_prepare_render_phase` is the only system that performs this batching and has sole responsibility for preparing the per-object data. As such the mesh binding and dynamic offsets are assumed to only vary as a result of the `batch_and_prepare_render_phase` system, e.g. due to having to split data across separate uniform bindings within the same buffer due to the maximum uniform buffer binding size. - Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform in arrays in GPU buffers rather than each one being at a dynamic offset in a uniform buffer. This is the same optimisation that was made for 3D not long ago. - Change batch size for a range in `PhaseItem`, adding API for getting or mutating the range. This is more flexible than a size as the length of the range can be used in place of the size, but the start and end can be otherwise whatever is needed. - Add an optional mesh bind group dynamic offset to `PhaseItem`. This avoids having to do a massive table move just to insert `GpuArrayBufferIndex` components. ## Benchmarks All tests have been run on an M1 Max on AC power. `bevymark` and `many_cubes` were modified to use 1920x1080 with a scale factor of 1. I run a script that runs a separate Tracy capture process, and then runs the bevy example with `--features bevy_ci_testing,trace_tracy` and `CI_TESTING_CONFIG=../benchmark.ron` with the contents of `../benchmark.ron`: ```rust ( exit_after: Some(1500) ) ``` ...in order to run each test for 1500 frames. The recent changes to `many_cubes` and `bevymark` added reproducible random number generation so that with the same settings, the same rng will occur. They also added benchmark modes that use a fixed delta time for animations. Combined this means that the same frames should be rendered both on main and on the branch. The graphs compare main (yellow) to this PR (red). ### 3D Mesh `many_cubes --benchmark` <img width="1411" alt="Screenshot 2023-09-03 at 23 42 10" src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4"> The mesh and material are the same for all instances. This is basically the best case for the initial batching implementation as it results in 1 draw for the ~11.7k visible meshes. It gives a ~30% reduction in median frame time. The 1000th frame is identical using the flip tool:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4615 seconds ``` ### 3D Mesh `many_cubes --benchmark --material-texture-count 10` <img width="1404" alt="Screenshot 2023-09-03 at 23 45 18" src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf"> This run uses 10 different materials by varying their textures. The materials are randomly selected, and there is no sorting by material bind group for opaque 3D so any batching is 'random'. The PR produces a ~5% reduction in median frame time. If we were to sort the opaque phase by the material bind group, then this should be a lot faster. This produces about 10.5k draws for the 11.7k visible entities. This makes sense as randomly selecting from 10 materials gives a chance that two adjacent entities randomly select the same material and can be batched. The 1000th frame is identical in flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4537 seconds ``` ### 3D Mesh `many_cubes --benchmark --vary-per-instance` <img width="1394" alt="Screenshot 2023-09-03 at 23 48 44" src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f"> This run varies the material data per instance by randomly-generating its colour. This is the worst case for batching and that it performs about the same as `main` is a good thing as it demonstrates that the batching has minimal overhead when dealing with ~11k visible mesh entities. The 1000th frame is identical according to flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4568 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` <img width="1412" alt="Screenshot 2023-09-03 at 23 59 56" src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4"> This spawns 160 waves of 1000 quad meshes that are shaded with ColorMaterial. Each wave has a different material so 160 waves currently should result in 160 batches. This results in a 50% reduction in median frame time. Capturing a screenshot of the 1000th frame main vs PR gives:  ``` Mean: 0.001222 Weighted median: 0.750432 1st weighted quartile: 0.453494 3rd weighted quartile: 0.969758 Min: 0.000000 Max: 0.990296 Evaluation time: 0.4255 seconds ``` So they seem to produce the same results. I also double-checked the number of draws. `main` does 160000 draws, and the PR does 160, as expected. ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --material-texture-count 10` <img width="1392" alt="Screenshot 2023-09-04 at 00 09 22" src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c"> This generates 10 textures and generates materials for each of those and then selects one material per wave. The median frame time is reduced by 50%. Similar to the plain run above, this produces 160 draws on the PR and 160000 on `main` and the 1000th frame is identical (ignoring the fps counter text overlay).  ``` Mean: 0.002877 Weighted median: 0.964980 1st weighted quartile: 0.668871 3rd weighted quartile: 0.982749 Min: 0.000000 Max: 0.992377 Evaluation time: 0.4301 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --vary-per-instance` <img width="1396" alt="Screenshot 2023-09-04 at 00 13 53" src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb"> This creates unique materials per instance by randomly-generating the material's colour. This is the worst case for 2D batching. Somehow, this PR manages a 7% reduction in median frame time. Both main and this PR issue 160000 draws. The 1000th frame is the same:  ``` Mean: 0.001214 Weighted median: 0.937499 1st weighted quartile: 0.635467 3rd weighted quartile: 0.979085 Min: 0.000000 Max: 0.988971 Evaluation time: 0.4462 seconds ``` ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` <img width="1396" alt="Screenshot 2023-09-04 at 12 21 12" src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43"> This just spawns 160 waves of 1000 sprites. There should be and is no notable difference between main and the PR. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --material-texture-count 10` <img width="1389" alt="Screenshot 2023-09-04 at 12 36 08" src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413"> This spawns the sprites selecting a texture at random per instance from the 10 generated textures. This has no significant change vs main and shouldn't. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --vary-per-instance` <img width="1401" alt="Screenshot 2023-09-04 at 12 29 52" src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6"> This sets the sprite colour as being unique per instance. This can still all be drawn using one batch. There should be no difference but the PR produces median frame times that are 4% higher. Investigation showed no clear sources of cost, rather a mix of give and take that should not happen. It seems like noise in the results. ### Summary | Benchmark | % change in median frame time | | ------------- | ------------- | | many_cubes | 🟩 -30% | | many_cubes 10 materials | 🟩 -5% | | many_cubes unique materials | 🟩 ~0% | | bevymark mesh2d | 🟩 -50% | | bevymark mesh2d 10 materials | 🟩 -50% | | bevymark mesh2d unique materials | 🟩 -7% | | bevymark sprite | 🟥 2% | | bevymark sprite 10 materials | 🟥 0.6% | | bevymark sprite unique materials | 🟥 4.1% | --- ## Changelog - Added: 2D and 3D mesh entities that share the same mesh and material (same textures, same data) are now batched into the same draw command for better performance. --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> Co-authored-by: Nicola Papale <nico@nicopap.ch> |
||
|
|
4f1d9a6315
|
Reorder render sets, refactor bevy_sprite to take advantage (#9236)
This is a continuation of this PR: #8062 # Objective - Reorder render schedule sets to allow data preparation when phase item order is known to support improved batching - Part of the batching/instancing etc plan from here: https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074 - The original idea came from @inodentry and proved to be a good one. Thanks! - Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new ordering ## Solution - Move `Prepare` and `PrepareFlush` after `PhaseSortFlush` - Add a `PrepareAssets` set that runs in parallel with other systems and sets in the render schedule. - Put prepare_assets systems in the `PrepareAssets` set - If explicit dependencies are needed on Mesh or Material RenderAssets then depend on the appropriate system. - Add `ManageViews` and `ManageViewsFlush` sets between `ExtractCommands` and Queue - Move `queue_mesh*_bind_group` to the Prepare stage - Rename them to `prepare_` - Put systems that prepare resources (buffers, textures, etc.) into a `PrepareResources` set inside `Prepare` - Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set after `PrepareResources` - Move `prepare_lights` to the `ManageViews` set - `prepare_lights` creates views and this must happen before `Queue` - This system needs refactoring to stop handling all responsibilities - Gather lights, sort, and create shadow map views. Store sorted light entities in a resource - Remove `BatchedPhaseItem` - Replace `batch_range` with `batch_size` representing how many items to skip after rendering the item or to skip the item entirely if `batch_size` is 0. - `queue_sprites` has been split into `queue_sprites` for queueing phase items and `prepare_sprites` for batching after the `PhaseSort` - `PhaseItem`s are still inserted in `queue_sprites` - After sorting adjacent compatible sprite phase items are accumulated into `SpriteBatch` components on the first entity of each batch, containing a range of vertex indices. The associated `PhaseItem`'s `batch_size` is updated appropriately. - `SpriteBatch` items are then drawn skipping over the other items in the batch based on the value in `batch_size` - A very similar refactor was performed on `bevy_ui` --- ## Changelog Changed: - Reordered and reworked render app schedule sets. The main change is that data is extracted, queued, sorted, and then prepared when the order of data is known. - Refactor `bevy_sprite` and `bevy_ui` to take advantage of the reordering. ## Migration Guide - Assets such as materials and meshes should now be created in `PrepareAssets` e.g. `prepare_assets<Mesh>` - Queueing entities to `RenderPhase`s continues to be done in `Queue` e.g. `queue_sprites` - Preparing resources (textures, buffers, etc.) should now be done in `PrepareResources`, e.g. `prepare_prepass_textures`, `prepare_mesh_uniforms` - Prepare bind groups should now be done in `PrepareBindGroups` e.g. `prepare_mesh_bind_group` - Any batching or instancing can now be done in `Prepare` where the order of the phase items is known e.g. `prepare_sprites` ## Next Steps - Introduce some generic mechanism to ensure items that can be batched are grouped in the phase item order, currently you could easily have `[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching. - Investigate improved orderings for building the MeshUniform buffer - Implementing batching across the rest of bevy --------- Co-authored-by: Robert Swain <robert.swain@gmail.com> Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> |
||
|
|
0a11af9375
|
Reduce the size of MeshUniform to improve performance (#9416)
# Objective - Significantly reduce the size of MeshUniform by only including necessary data. ## Solution Local to world, model transforms are affine. This means they only need a 4x3 matrix to represent them. `MeshUniform` stores the current, and previous model transforms, and the inverse transpose of the current model transform, all as 4x4 matrices. Instead we can store the current, and previous model transforms as 4x3 matrices, and we only need the upper-left 3x3 part of the inverse transpose of the current model transform. This change allows us to reduce the serialized MeshUniform size from 208 bytes to 144 bytes, which is over a 30% saving in data to serialize, and VRAM bandwidth and space. ## Benchmarks On an M1 Max, running `many_cubes -- sphere`, main is in yellow, this PR is in red: <img width="1484" alt="Screenshot 2023-08-11 at 02 36 43" src="https://github.com/bevyengine/bevy/assets/302146/7d99c7b3-f2bb-4004-a8d0-4c00f755cb0d"> A reduction in frame time of ~14%. --- ## Changelog - Changed: Redefined `MeshUniform` to improve performance by using 4x3 affine transforms and reconstructing 4x4 matrices in the shader. Helper functions were added to `bevy_pbr::mesh_functions` to unpack the data. `affine_to_square` converts the packed 4x3 in 3x4 matrix data to a 4x4 matrix. `mat2x4_f32_to_mat3x3` converts the 3x3 in mat2x4 + f32 matrix data back into a 3x3. ## Migration Guide Shader code before: ``` var model = mesh[instance_index].model; ``` Shader code after: ``` #import bevy_pbr::mesh_functions affine_to_square var model = affine_to_square(mesh[instance_index].model); ``` |
||
|
|
10f5c92068
|
improve shader import model (#5703)
# Objective operate on naga IR directly to improve handling of shader modules. - give codespan reporting into imported modules - allow glsl to be used from wgsl and vice-versa the ultimate objective is to make it possible to - provide user hooks for core shader functions (to modify light behaviour within the standard pbr pipeline, for example) - make automatic binding slot allocation possible but ... since this is already big, adds some value and (i think) is at feature parity with the existing code, i wanted to push this now. ## Solution i made a crate called naga_oil (https://github.com/robtfm/naga_oil - unpublished for now, could be part of bevy) which manages modules by - building each module independantly to naga IR - creating "header" files for each supported language, which are used to build dependent modules/shaders - make final shaders by combining the shader IR with the IR for imported modules then integrated this into bevy, replacing some of the existing shader processing stuff. also reworked examples to reflect this. ## Migration Guide shaders that don't use `#import` directives should work without changes. the most notable user-facing difference is that imported functions/variables/etc need to be qualified at point of use, and there's no "leakage" of visible stuff into your shader scope from the imports of your imports, so if you used things imported by your imports, you now need to import them directly and qualify them. the current strategy of including/'spreading' `mesh_vertex_output` directly into a struct doesn't work any more, so these need to be modified as per the examples (e.g. color_material.wgsl, or many others). mesh data is assumed to be in bindgroup 2 by default, if mesh data is bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1` needs to be added to the pipeline shader_defs. |
||
|
|
f18f28874a
|
Allow tuples and single plugins in add_plugins, deprecate add_plugin (#8097)
# Objective - Better consistency with `add_systems`. - Deprecating `add_plugin` in favor of a more powerful `add_plugins`. - Allow passing `Plugin` to `add_plugins`. - Allow passing tuples to `add_plugins`. ## Solution - `App::add_plugins` now takes an `impl Plugins` parameter. - `App::add_plugin` is deprecated. - `Plugins` is a new sealed trait that is only implemented for `Plugin`, `PluginGroup` and tuples over `Plugins`. - All examples, benchmarks and tests are changed to use `add_plugins`, using tuples where appropriate. --- ## Changelog ### Changed - `App::add_plugins` now accepts all types that implement `Plugins`, which is implemented for: - Types that implement `Plugin`. - Types that implement `PluginGroup`. - Tuples (up to 16 elements) over types that implement `Plugins`. - Deprecated `App::add_plugin` in favor of `App::add_plugins`. ## Migration Guide - Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`. --------- Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
71842c5ac9
|
Webgpu support (#8336)
# Objective - Support WebGPU - alternative to #5027 that doesn't need any async / await - fixes #8315 - Surprise fix #7318 ## Solution ### For async renderer initialisation - Update the plugin lifecycle: - app builds the plugin - calls `plugin.build` - registers the plugin - app starts the event loop - event loop waits for `ready` of all registered plugins in the same order - returns `true` by default - then call all `finish` then all `cleanup` in the same order as registered - then execute the schedule In the case of the renderer, to avoid anything async: - building the renderer plugin creates a detached task that will send back the initialised renderer through a mutex in a resource - `ready` will wait for the renderer to be present in the resource - `finish` will take that renderer and place it in the expected resources by other plugins - other plugins (that expect the renderer to be available) `finish` are called and they are able to set up their pipelines - `cleanup` is called, only custom one is still for pipeline rendering ### For WebGPU support - update the `build-wasm-example` script to support passing `--api webgpu` that will build the example with WebGPU support - feature for webgl2 was always enabled when building for wasm. it's now in the default feature list and enabled on all platforms, so check for this feature must also check that the target_arch is `wasm32` --- ## Migration Guide - `Plugin::setup` has been renamed `Plugin::cleanup` - `Plugin::finish` has been added, and plugins adding pipelines should do it in this function instead of `Plugin::build` ```rust // Before impl Plugin for MyPlugin { fn build(&self, app: &mut App) { app.insert_resource::<MyResource> .add_systems(Update, my_system); let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<RenderResourceNeedingDevice>() .init_resource::<OtherRenderResource>(); } } // After impl Plugin for MyPlugin { fn build(&self, app: &mut App) { app.insert_resource::<MyResource> .add_systems(Update, my_system); let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<OtherRenderResource>(); } fn finish(&self, app: &mut App) { let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<RenderResourceNeedingDevice>(); } } ``` |
||
|
|
6b774c0fda
|
Compute vertex_count for indexed meshes on GpuMesh (#8460)
# Objective Compute the `vertex_count` for indexed meshes as well as non-indexed meshes. I will need this in a future PR based on #8427 that adds a gizmo component that draws the normals of a mesh when attached to an entity ([branch](https://github.com/devil-ira/bevy/compare/instanced-line-rendering...devil-ira:bevy:instanced-line-rendering-normals)). <details><summary>Example image</summary> <p>  </p> </details> ## Solution Move `vertex_count` field from `GpuBufferInfo::NonIndexed` to `GpuMesh` ## Migration Guide `vertex_count` is now stored directly on `GpuMesh` instead of `GpuBufferInfo::NonIndexed`. |
||
|
|
aefe1f0739
|
Schedule-First: the new and improved add_systems (#8079)
Co-authored-by: Mike <mike.hsu@gmail.com> |
||
|
|
fd1af7c8b8
|
Replace multiple calls to add_system with add_systems (#8001)
|
||
|
|
206c7ce219 |
Migrate engine to Schedule v3 (#7267)
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR. # Objective - Followup #6587. - Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45 ## Solution - [x] Remove old scheduling module - [x] Migrate new methods to no longer use extension methods - [x] Fix compiler errors - [x] Fix benchmarks - [x] Fix examples - [x] Fix docs - [x] Fix tests ## Changelog ### Added - a large number of methods on `App` to work with schedules ergonomically - the `CoreSchedule` enum - `App::add_extract_system` via the `RenderingAppExtension` trait extension method - the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms` ### Removed - stages, and all code that mentions stages - states have been dramatically simplified, and no longer use a stack - `RunCriteriaLabel` - `AsSystemLabel` trait - `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition) - systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world - `RunCriteriaLabel` - `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear. ### Changed - `System::default_labels` is now `System::default_system_sets`. - `App::add_default_labels` is now `App::add_default_sets` - `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet` - `App::add_system_set` was renamed to `App::add_systems` - The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum - `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)` - `SystemLabel` trait was replaced by `SystemSet` - `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>` - The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq` - Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria. - Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. - `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`. - `bevy_pbr::add_clusters` is no longer an exclusive system - the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling` - `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread. ## Migration Guide - Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)` - Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed. - The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved. - Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior. - Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you. - For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with - `add_system(my_system.in_set(CoreSet::PostUpdate)` - When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages - Run criteria have been renamed to run conditions. These can now be combined with each other and with states. - Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow. - For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label. - Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default. - Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually. - Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior. - the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity - `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl. - Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings. - `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds. - `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool. - States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set` ## TODO - [x] remove dead methods on App and World - [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule` - [x] avoid adding the default system set at inappropriate times - [x] remove any accidental cycles in the default plugins schedule - [x] migrate benchmarks - [x] expose explicit labels for the built-in command flush points - [x] migrate engine code - [x] remove all mentions of stages from the docs - [x] verify docs for States - [x] fix uses of exclusive systems that use .end / .at_start / .before_commands - [x] migrate RenderStage and AssetStage - [x] migrate examples - [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub) - [x] ensure that on_enter schedules are run at least once before the main app - [x] re-enable opt-in to execution order ambiguities - [x] revert change to `update_bounds` to ensure it runs in `PostUpdate` - [x] test all examples - [x] unbreak directional lights - [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples) - [x] game menu example shows loading screen and menu simultaneously - [x] display settings menu is a blank screen - [x] `without_winit` example panics - [x] ensure all tests pass - [x] SubApp doc test fails - [x] runs_spawn_local tasks fails - [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120) ## Points of Difficulty and Controversy **Reviewers, please give feedback on these and look closely** 1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup. 2. The outer schedule controls which schedule is run when `App::update` is called. 3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes. 4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset. 5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order 6. Implemetnation strategy for fixed timesteps 7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks. 8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements. ## Future Work (ideally before 0.10) - Rename schedule_v3 module to schedule or scheduling - Add a derive macro to states, and likely a `EnumIter` trait of some form - Figure out what exactly to do with the "systems added should basically work by default" problem - Improve ergonomics for working with fixed timesteps and states - Polish FixedTime API to match Time - Rebase and merge #7415 - Resolve all internal ambiguities (blocked on better tools, especially #7442) - Add "base sets" to replace the removed default sets. |
||
|
|
1be3b6d592 |
fix shader_instancing (#7305)
# Objective - The changes to the MeshPipeline done for the prepass broke the shader_instancing example. The issue is that the view_layout changes based on if MSAA is enabled or not, but the example hardcoded the view_layout. ## Solution - Don't overwrite the bind_group_layout of the descriptor since the MeshPipeline already takes care of this in the specialize function. Closes https://github.com/bevyengine/bevy/issues/7285 |
||
|
|
06ada2e93d |
Changed Msaa to Enum (#7292)
# Objective Fixes #6931 Continues #6954 by squashing `Msaa` to a flat enum Helps out #7215 # Solution ``` pub enum Msaa { Off = 1, #[default] Sample4 = 4, } ``` # Changelog - Modified - `Msaa` is now enum - Defaults to 4 samples - Uses `.samples()` method to get the sample number as `u32` # Migration Guide ``` let multi = Msaa { samples: 4 } // is now let multi = Msaa::Sample4 multi.samples // is now multi.samples() ``` Co-authored-by: Sjael <jakeobrien44@gmail.com> |
||
|
|
517deda215 |
Make PipelineCache internally mutable. (#7205)
# Objective - Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems. ## Solution - Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device. --- ## Changelog `PipelineCache` no longer requires mutable access in order to queue render / compute pipelines. ## Migration Guide * Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`. |
||
|
|
2d727afaf7 |
Flatten render commands (#6885)
# Objective Speed up the render phase of rendering. Simplify the trait structure for render commands. ## Solution - Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`) - Merge `EntityRenderCommand` into `RenderCommand`. - Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`. - Use the new associated types to construct two `QueryStates`s for `RenderCommandState`. - Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once. ## Performance `main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us) 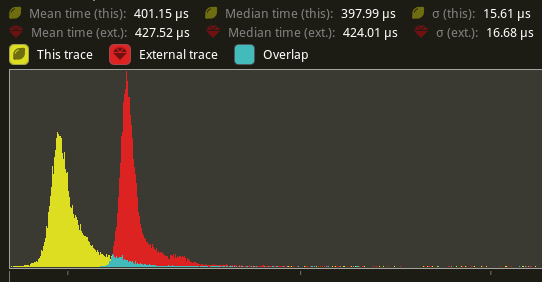 The shadow pass node is also slightly faster (344.52 -> 338.24us) 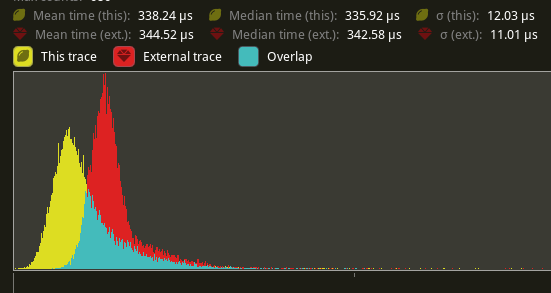 ## Future Work - Can we hoist the view level queries out of the core loop? --- ## Changelog Added: `PhaseItem::entity` Added: `RenderCommand::ViewWorldQuery` associated type. Added: `RenderCommand::ItemorldQuery` associated type. Added: `Draw<T>::prepare` optional trait function. Removed: `EntityPhaseItem` trait ## Migration Guide TODO |
||
|
|
a0448eca2f |
enum Visibility component (#6320)
Consolidation of all the feedback about #6271 as well as the addition of an "unconditionally visible" mode. # Objective The current implementation of the `Visibility` struct simply wraps a boolean.. which seems like an odd pattern when rust has such nice enums that allow for more expression using pattern-matching. Additionally as it stands Bevy only has two settings for visibility of an entity: - "unconditionally hidden" `Visibility { is_visible: false }`, - "inherit visibility from parent" `Visibility { is_visible: true }` where a root level entity set to "inherit" is visible. Note that given the behaviour, the current naming of the inner field is a little deceptive or unclear. Using an enum for `Visibility` opens the door for adding an extra behaviour mode. This PR adds a new "unconditionally visible" mode, which causes an entity to be visible even if its Parent entity is hidden. There should not really be any performance cost to the addition of this new mode. -- The recently added `toggle` method is removed in this PR, as its semantics could be confusing with 3 variants. ## Solution Change the Visibility component into ```rust enum Visibility { Hidden, // unconditionally hidden Visible, // unconditionally visible Inherited, // inherit visibility from parent } ``` --- ## Changelog ### Changed `Visibility` is now an enum ## Migration Guide - evaluation of the `visibility.is_visible` field should now check for `visibility == Visibility::Inherited`. - setting the `visibility.is_visible` field should now directly set the value: `*visibility = Visibility::Inherited`. - usage of `Visibility::VISIBLE` or `Visibility::INVISIBLE` should now use `Visibility::Inherited` or `Visibility::Hidden` respectively. - `ComputedVisibility::INVISIBLE` and `SpatialBundle::VISIBLE_IDENTITY` have been renamed to `ComputedVisibility::HIDDEN` and `SpatialBundle::INHERITED_IDENTITY` respectively. Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
f119d9df8e |
Add DrawFunctionsInternals::id() (#6745)
# Objective - Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate. ## Solution - Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible. - I also took the opportunity to improve the error message a little in the case where it fails. --- ## Changelog - Added `DrawFunctionsInternals::id()` |
||
|
|
174819be83 |
ExtractComponent output optional associated type (#6699)
# Objective
Allow more use cases where the user may benefit from both `ExtractComponentPlugin` _and_ `UniformComponentPlugin`.
## Solution
Add an associated type to `ExtractComponent` in order to allow specifying the output component (or bundle).
Make `extract_component` return an `Option<_>` such that components can be extracted only when needed.
What problem does this solve?
`ExtractComponentPlugin` allows extracting components, but currently the output type is the same as the input.
This means that use cases such as having a settings struct which turns into a uniform is awkward.
For example we might have:
```rust
struct MyStruct {
enabled: bool,
val: f32
}
struct MyStructUniform {
val: f32
}
```
With the new approach, we can extract `MyStruct` only when it is enabled, and turn it into its related uniform.
This chains well with `UniformComponentPlugin`.
The user may then:
```rust
app.add_plugin(ExtractComponentPlugin::<MyStruct>::default());
app.add_plugin(UniformComponentPlugin::<MyStructUniform>::default());
```
This then saves the user a fair amount of boilerplate.
## Changelog
### Changed
- `ExtractComponent` can specify output type, and outputting is optional.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
|
||
|
|
c3c4088317 |
Fix instancing example for hdr (#6554)
# Objective - Using the instancing example as reference, I found it was breaking when enabling HDR on the camera. I found that this was because, unlike in internal code, this was not updating the specialization key with `view.hdr`. ## Solution - Add the missing HDR bit. |
||
|
|
30e35764a1 |
Replace WorldQueryGats trait with actual gats (#6319)
# Objective Replace `WorldQueryGats` trait with actual gats ## Solution Replace `WorldQueryGats` trait with actual gats --- ## Changelog - Replaced `WorldQueryGats` trait with actual gats ## Migration Guide - Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait |
||
|
|
92ba6224b9 |
Use SpatialBundle/TransformBundle in examples (#6002)
Does what it do Co-authored-by: devil-ira <justthecooldude@gmail.com> |
||
|
|
01aedc8431 |
Spawn now takes a Bundle (#6054)
# Objective Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands). ## Solution All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input: ```rust // before: commands .spawn() .insert((A, B, C)); world .spawn() .insert((A, B, C); // after commands.spawn((A, B, C)); world.spawn((A, B, C)); ``` All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api. By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`). This improves spawn performance by over 10%:  To take this measurement, I added a new `world_spawn` benchmark. Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main. **Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).** --- ## Changelog - All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input - All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api - World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior. ## Migration Guide ```rust // Old (0.8): commands .spawn() .insert_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): commands.spawn_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): let entity = commands.spawn().id(); // New (0.9) let entity = commands.spawn_empty().id(); // Old (0.8) let entity = world.spawn().id(); // New (0.9) let entity = world.spawn_empty(); ``` |
||
|
|
cd15f0f5be |
Accept Bundles for insert and remove. Deprecate insert/remove_bundle (#6039)
# Objective Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there. ## Solution - Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World) - Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection` - Add `remove_intersection` --- ## Changelog - Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World) - `insert_bundle` and `remove_bundle` are deprecated ## Migration Guide Replace `insert_bundle` with `insert`: ```rust // Old (0.8) commands.spawn().insert_bundle(SomeBundle::default()); // New (0.9) commands.spawn().insert(SomeBundle::default()); ``` Replace `remove_bundle` with `remove`: ```rust // Old (0.8) commands.entity(some_entity).remove_bundle::<SomeBundle>(); // New (0.9) commands.entity(some_entity).remove::<SomeBundle>(); ``` Replace `remove_bundle_intersection` with `remove_intersection`: ```rust // Old (0.8) world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>(); // New (0.9) world.entity_mut(some_entity).remove_intersection::<SomeBundle>(); ``` Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves: ```rust // Old (0.8) commands.spawn() .insert_bundle(SomeBundle::default()) .insert(SomeComponent); // New (0.9) - Option 1 commands.spawn().insert(( SomeBundle::default(), SomeComponent, )) // New (0.9) - Option 2 commands.spawn_bundle(( SomeBundle::default(), SomeComponent, )) ``` ## Next Steps Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`. |
||
|
|
28205fd3f4 |
Remove AssetServer::watch_for_changes() (#5968)
# Objective `AssetServer::watch_for_changes()` is racy and redundant with `AssetServerSettings`. Closes #5964. ## Changelog * Remove `AssetServer::watch_for_changes()` * Add `AssetServerSettings` to the prelude. * Minor cleanup. ## Migration Guide `AssetServer::watch_for_changes()` was removed. Instead, use the `AssetServerSettings` resource. ```rust app // AssetServerSettings must be inserted before adding the AssetPlugin or DefaultPlugins. .insert_resource(AssetServerSettings { watch_for_changes: true, ..default() }) ``` Co-authored-by: devil-ira <justthecooldude@gmail.com> |
||
|
|
76ae6f4c6e |
Miscellaneous code-quality improvements. (#5860)
Does what it do. Co-authored-by: devil-ira <justthecooldude@gmail.com> |
||
|
|
992681b59b |
Make Resource trait opt-in, requiring #[derive(Resource)] V2 (#5577)
*This PR description is an edited copy of #5007, written by @alice-i-cecile.* # Objective Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds. While ergonomic, this results in several drawbacks: * it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource * it is challenging to discover if a type is intended to be used as a resource * we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component). * dependencies can use the same Rust type as a resource in invisibly conflicting ways * raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values * we cannot capture a definitive list of possible resources to display to users in an editor ## Notes to reviewers * Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits. *ira: My commits are not as well organized :')* * I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does. * I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981. ## Changelog `Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro. ## Migration Guide Add `#[derive(Resource)]` to all types you are using as a resource. If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics. `ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing. Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead. Co-authored-by: Alice <alice.i.cecile@gmail.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: devil-ira <justthecooldude@gmail.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
4847f7e3ad |
Update codebase to use IntoIterator where possible. (#5269)
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
5b5013d540 |
Add ViewRangefinder3d to reduce boilerplate when enqueuing standard 3D PhaseItems. (#5014)
# Objective Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect. ## Solution - Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance. - Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix. - Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation. ## Migration Guide Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value. Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before. |
||
|
|
cdbabb7053 |
Removed world cell from places where split multable access is not needed (#5167)
Fixes #5109. |
||
|
|
2f5a1c6e16 |
remove redundant query parameters (#4945)
# Objective In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access. ## Solution Remove the `With<Handle<Mesh>>` filter |
||
|
|
f487407e07 |
Camera Driven Rendering (#4745)
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier. Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):  Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work". Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id: ```rust // main camera (main window) commands.spawn_bundle(Camera2dBundle::default()); // second camera (other window) commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Window(window_id), ..default() }, ..default() }); ``` Rendering to a texture is as simple as pointing the camera at a texture: ```rust commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Texture(image_handle), ..default() }, ..default() }); ``` Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`). ```rust // main pass camera with a default priority of 0 commands.spawn_bundle(Camera2dBundle::default()); commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Texture(image_handle.clone()), priority: -1, ..default() }, ..default() }); commands.spawn_bundle(SpriteBundle { texture: image_handle, ..default() }) ``` Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system: ```rust commands.spawn_bundle(Camera3dBundle::default()); commands.spawn_bundle(Camera2dBundle { camera: Camera { // this will render 2d entities "on top" of the default 3d camera's render priority: 1, ..default() }, ..default() }); ``` There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active. Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections. ```rust // old 3d perspective camera commands.spawn_bundle(PerspectiveCameraBundle::default()) // new 3d perspective camera commands.spawn_bundle(Camera3dBundle::default()) ``` ```rust // old 2d orthographic camera commands.spawn_bundle(OrthographicCameraBundle::new_2d()) // new 2d orthographic camera commands.spawn_bundle(Camera2dBundle::default()) ``` ```rust // old 3d orthographic camera commands.spawn_bundle(OrthographicCameraBundle::new_3d()) // new 3d orthographic camera commands.spawn_bundle(Camera3dBundle { projection: OrthographicProjection { scale: 3.0, scaling_mode: ScalingMode::FixedVertical, ..default() }.into(), ..default() }) ``` Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors. If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component: ```rust commands.spawn_bundle(Camera3dBundle { camera_render_graph: CameraRenderGraph::new(some_render_graph_name), ..default() }) ``` Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added. Speaking of using components to configure graphs / passes, there are a number of new configuration options: ```rust commands.spawn_bundle(Camera3dBundle { camera_3d: Camera3d { // overrides the default global clear color clear_color: ClearColorConfig::Custom(Color::RED), ..default() }, ..default() }) commands.spawn_bundle(Camera3dBundle { camera_3d: Camera3d { // disables clearing clear_color: ClearColorConfig::None, ..default() }, ..default() }) ``` Expect to see more of the "graph configuration Components on Cameras" pattern in the future. By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component: ```rust commands .spawn_bundle(Camera3dBundle::default()) .insert(CameraUi { is_enabled: false, ..default() }) ``` ## Other Changes * The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr. * I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization. * I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler. * All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr. * Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic. * Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals: 1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs. 2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense. ## Follow Up Work * Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen) * Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor) * Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system). * Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable. * Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home. |
||
|
|
a0a3d8798b |
ExtractResourcePlugin (#3745)
# Objective - Add an `ExtractResourcePlugin` for convenience and consistency ## Solution - Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system. - Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource - Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()` - Use `ExtractResourcePlugin` wherever both possible and appropriate |
||
|
|
deeaf64897 |
shader examples wording coherence (#4810)
# Objective I noticed different examples descriptions were not using the same structure:  This results in sentences that a reader has to read differently each time, which might result in information being hard to find, especially foreign language users. Original discord discussion: https://discord.com/channels/691052431525675048/976846499889705020 ## Solution - Use less different words, similar structure and being straight to the point. --- ## Changelog - Examples descriptions more accessible. |
||
|
|
1ba7429371 |
Doc/module style doc blocks for examples (#4438)
# Objective Provide a starting point for #3951, or a partial solution. Providing a few comment blocks to discuss, and hopefully find better one in the process. ## Solution Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less. ## Changelog - Moved some existing comments from main() functions in the 2d examples to the file header level - Wrote some more comment blocks for most other 2d examples TODO: - [x] 2d/sprite_sheet, wasnt able to come up with something good yet - [x] all other example groups... Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed. I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please. |
||
|
|
4aa56050b6 |
Add infallible resource getters for WorldCell (#4104)
# Objective - Eliminate all `worldcell.get_resource().unwrap()` cases. - Provide helpful messages on panic. ## Solution - Adds infallible resource getters to `WorldCell`, mirroring `World`. |
||
|
|
f16768d868 |
bevy_derive: Add derives for Deref and DerefMut (#4328)
# Objective A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like: ```rust #[derive(Component)] struct Items(Vec<String>); fn give_sword(query: Query<&mut Items>) { query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom")); } ``` > We could then define another struct that wraps `Vec<String>` without anything clashing in the query. However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this. Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations. ## Solution Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field: ```rust #[derive(Deref)] struct Foo(String); #[derive(Deref, DerefMut)] struct Bar { name: String, } ``` This allows us to then remove that pesky `.0`: ```rust #[derive(Component, Deref, DerefMut)] struct Items(Vec<String>); fn give_sword(query: Query<&mut Items>) { query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom")); } ``` ### Alternatives There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now). ### Considerations One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree. ### Additional Context Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630)) --- ## Changelog - Add `Deref` derive macro (exported to prelude) - Add `DerefMut` derive macro (exported to prelude) - Updated most newtypes in examples to use one or both derives Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com> |
||
|
|
9e450f2827 |
Compute Pipeline Specialization (#3979)
# Objective - Fixes #3970 - To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines. ## Solution - renamed `RenderPipelineCache` to `PipelineCache` - Cached Pipelines are now represented by an enum (render, compute) - split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines` - updated the game of life example ## Open Questions - should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that? - should the `get_render_pipeline` and `get_compute_pipeline` methods be merged? - is pipeline specialization for different entry points a good pattern Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
024d98457c |
yeet unsound lifetime annotations on Query methods (#4243)
# Objective Continuation of #2964 (I really should have checked other methods when I made that PR) yeet unsound lifetime annotations on `Query` methods. Example unsoundness: ```rust use bevy::prelude::*; fn main() { App::new().add_startup_system(bar).add_system(foo).run(); } pub fn bar(mut cmds: Commands) { let e = cmds.spawn().insert(Foo { a: 10 }).id(); cmds.insert_resource(e); } #[derive(Component, Debug, PartialEq, Eq)] pub struct Foo { a: u32, } pub fn foo(mut query: Query<&mut Foo>, e: Res<Entity>) { dbg!("hi"); { let data: &Foo = query.get(*e).unwrap(); let data2: Mut<Foo> = query.get_mut(*e).unwrap(); assert_eq!(data, &*data2); // oops UB } { let data: &Foo = query.single(); let data2: Mut<Foo> = query.single_mut(); assert_eq!(data, &*data2); // oops UB } { let data: &Foo = query.get_single().unwrap(); let data2: Mut<Foo> = query.get_single_mut().unwrap(); assert_eq!(data, &*data2); // oops UB } { let data: &Foo = query.iter().next().unwrap(); let data2: Mut<Foo> = query.iter_mut().next().unwrap(); assert_eq!(data, &*data2); // oops UB } { let mut opt_data: Option<&Foo> = None; let mut opt_data_2: Option<Mut<Foo>> = None; query.for_each(|data| opt_data = Some(data)); query.for_each_mut(|data| opt_data_2 = Some(data)); assert_eq!(opt_data.unwrap(), &*opt_data_2.unwrap()); // oops UB } dbg!("bye"); } ``` ## Solution yeet unsound lifetime annotations on `Query` methods Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
b6a647cc01 |
default() shorthand (#4071)
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
|
||
|
|
e369a8ad51 |
Mesh vertex buffer layouts (#3959)
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120
Fixes #3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
|
||
|
|
b11ee3ffb8 |
Remove duplicate call to set_vertex_buffer(0, ...) in shader_instancing example (#3738)
## Objective
The [`DrawMeshInstanced`] command in the example sets vertex buffer 0 twice, with two identical calls to:
```rs
pass.set_vertex_buffer(0, gpu_mesh.vertex_buffer.slice(..));
```
## Solution
Remove the second call as it is unecessary.
[`DrawMeshInstanced`]:
|
||
|
|
55da315432 |
bevy_render: Provide a way to opt-out of the built-in frustum culling (#3711)
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
|
||
|
|
b1476015d9 |
add some more pipelined-rendering shader examples (#3041)
based on #3031 Adds some examples showing of how to use the new pipelined rendering for custom shaders. - a minimal shader example which doesn't use render assets - the same but using glsl - an example showing how to render instanced data - a shader which uses the seconds since startup to animate some textures Instancing shader:  Animated shader:  (the gif makes it look a bit ugly) Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}