~~Currently blocked on an upstream bug that causes crashes when
minimizing/resizing on dx12 https://github.com/gfx-rs/wgpu/issues/3967~~
wgpu 0.17.1 is out which fixes it
# Objective
Keep wgpu up to date.
## Solution
Update wgpu and naga_oil.
Currently this depends on an unreleased (and unmerged) branch of
naga_oil, and hasn't been properly tested yet.
The wgpu side of this seems to have been an extremely trivial upgrade
(all the upgrade work seems to be in naga_oil). This also lets us remove
the workarounds for pack/unpack4x8unorm in the SSAO shaders.
Lets us close the dx12 part of
https://github.com/bevyengine/bevy/issues/8888
related: https://github.com/bevyengine/bevy/issues/9304
---
## Changelog
Update to wgpu 0.17 and naga_oil 0.9
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
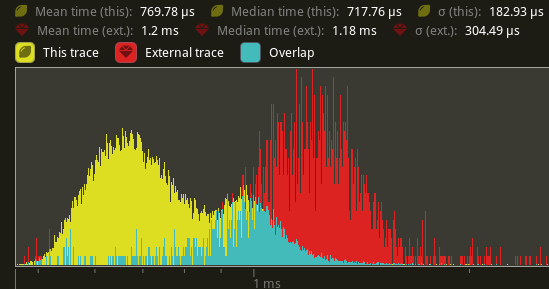
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
This is a continuation of this PR: #8062
# Objective
- Reorder render schedule sets to allow data preparation when phase item
order is known to support improved batching
- Part of the batching/instancing etc plan from here:
https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074
- The original idea came from @inodentry and proved to be a good one.
Thanks!
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new
ordering
## Solution
- Move `Prepare` and `PrepareFlush` after `PhaseSortFlush`
- Add a `PrepareAssets` set that runs in parallel with other systems and
sets in the render schedule.
- Put prepare_assets systems in the `PrepareAssets` set
- If explicit dependencies are needed on Mesh or Material RenderAssets
then depend on the appropriate system.
- Add `ManageViews` and `ManageViewsFlush` sets between
`ExtractCommands` and Queue
- Move `queue_mesh*_bind_group` to the Prepare stage
- Rename them to `prepare_`
- Put systems that prepare resources (buffers, textures, etc.) into a
`PrepareResources` set inside `Prepare`
- Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set
after `PrepareResources`
- Move `prepare_lights` to the `ManageViews` set
- `prepare_lights` creates views and this must happen before `Queue`
- This system needs refactoring to stop handling all responsibilities
- Gather lights, sort, and create shadow map views. Store sorted light
entities in a resource
- Remove `BatchedPhaseItem`
- Replace `batch_range` with `batch_size` representing how many items to
skip after rendering the item or to skip the item entirely if
`batch_size` is 0.
- `queue_sprites` has been split into `queue_sprites` for queueing phase
items and `prepare_sprites` for batching after the `PhaseSort`
- `PhaseItem`s are still inserted in `queue_sprites`
- After sorting adjacent compatible sprite phase items are accumulated
into `SpriteBatch` components on the first entity of each batch,
containing a range of vertex indices. The associated `PhaseItem`'s
`batch_size` is updated appropriately.
- `SpriteBatch` items are then drawn skipping over the other items in
the batch based on the value in `batch_size`
- A very similar refactor was performed on `bevy_ui`
---
## Changelog
Changed:
- Reordered and reworked render app schedule sets. The main change is
that data is extracted, queued, sorted, and then prepared when the order
of data is known.
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the
reordering.
## Migration Guide
- Assets such as materials and meshes should now be created in
`PrepareAssets` e.g. `prepare_assets<Mesh>`
- Queueing entities to `RenderPhase`s continues to be done in `Queue`
e.g. `queue_sprites`
- Preparing resources (textures, buffers, etc.) should now be done in
`PrepareResources`, e.g. `prepare_prepass_textures`,
`prepare_mesh_uniforms`
- Prepare bind groups should now be done in `PrepareBindGroups` e.g.
`prepare_mesh_bind_group`
- Any batching or instancing can now be done in `Prepare` where the
order of the phase items is known e.g. `prepare_sprites`
## Next Steps
- Introduce some generic mechanism to ensure items that can be batched
are grouped in the phase item order, currently you could easily have
`[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching.
- Investigate improved orderings for building the MeshUniform buffer
- Implementing batching across the rest of bevy
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
- Reduce the number of rebindings to enable batching of draw commands
## Solution
- Use the new `GpuArrayBuffer` for `MeshUniform` data to store all
`MeshUniform` data in arrays within fewer bindings
- Sort opaque/alpha mask prepass, opaque/alpha mask main, and shadow
phases also by the batch per-object data binding dynamic offset to
improve performance on WebGL2.
---
## Changelog
- Changed: Per-object `MeshUniform` data is now managed by
`GpuArrayBuffer` as arrays in buffers that need to be indexed into.
## Migration Guide
Accessing the `model` member of an individual mesh object's shader
`Mesh` struct the old way where each `MeshUniform` was stored at its own
dynamic offset:
```rust
struct Vertex {
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh.model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
The new way where one needs to index into the array of `Mesh`es for the
batch:
```rust
struct Vertex {
@builtin(instance_index) instance_index: u32,
@location(0) position: vec3<f32>,
};
fn vertex(vertex: Vertex) -> VertexOutput {
var out: VertexOutput;
out.clip_position = mesh_position_local_to_clip(
mesh[vertex.instance_index].model,
vec4<f32>(vertex.position, 1.0)
);
return out;
}
```
Note that using the instance_index is the default way to pass the
per-object index into the shader, but if you wish to do custom rendering
approaches you can pass it in however you like.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by moving FloatOrd to bevy_utils.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Move FloatOrd into bevy_utils. Fix the compile errors.
As a result, bevy_core_pipeline, bevy_pbr, bevy_sprite, bevy_text, and bevy_ui no longer depend on bevy_core (they were only using it for `FloatOrd` previously).
# Objective
- While animating 501 https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/BrainStem, I noticed things were getting a little slow
- Looking in tracy, the system `extract_skinned_meshes` is taking a lot of time, with a mean duration of 15.17ms
## Solution
- ~~Use `Vec` instead of a `SmallVec`~~
- ~~Don't use an temporary variable~~
- Compute the affine matrix as an `Affine3A` instead
- Remove the `temp` vec
| |mean|
|---|---|
|base|15.17ms|
|~~vec~~|~~9.31ms~~|
|~~no temp variable~~|~~11.31ms~~|
|removing the temp vector|8.43ms|
|affine|13.21ms|
|all together|7.23ms|
# Objective
Load skeletal weights and indices from GLTF files. Animate meshes.
## Solution
- Load skeletal weights and indices from GLTF files.
- Added `SkinnedMesh` component and ` SkinnedMeshInverseBindPose` asset
- Added `extract_skinned_meshes` to extract joint matrices.
- Added queue phase systems for enqueuing the buffer writes.
Some notes:
- This ports part of # #2359 to the current main.
- This generates new `BufferVec`s and bind groups every frame. The expectation here is that the number of `Query::get` calls during extract is probably going to be the stronger bottleneck, with up to 256 calls per skinned mesh. Until that is optimized, caching buffers and bind groups is probably a non-concern.
- Unfortunately, due to the uniform size requirements, this means a 16KB buffer is allocated for every skinned mesh every frame. There's probably a few ways to get around this, but most of them require either compute shaders or storage buffers, which are both incompatible with WebGL2.
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
This adds "high level" `Material` and `SpecializedMaterial` traits, which can be used with a `MaterialPlugin<T: SpecializedMaterial>`. `MaterialPlugin` automatically registers the appropriate resources, draw functions, and queue systems. The `Material` trait is simpler, and should cover most use cases. `SpecializedMaterial` is like `Material`, but it also requires defining a "specialization key" (see #3031). `Material` has a trivial blanket impl of `SpecializedMaterial`, which allows us to use the same types + functions for both.
This makes defining custom 3d materials much simpler (see the `shader_material` example diff) and ensures consistent behavior across all 3d materials (both built in and custom). I ported the built in `StandardMaterial` to `MaterialPlugin`. There is also a new `MaterialMeshBundle<T: SpecializedMaterial>`, which `PbrBundle` aliases to.
# Objective
- Our crevice is still called "crevice", which we can't use for a release
- Users would need to use our "crevice" directly to be able to use the derive macro
## Solution
- Rename crevice to bevy_crevice, and crevice-derive to bevy-crevice-derive
- Re-export it from bevy_render, and use it from bevy_render everywhere
- Fix derive macro to work either from bevy_render, from bevy_crevice, or from bevy
## Remaining
- It is currently re-exported as `bevy::render::bevy_crevice`, is it the path we want?
- After a brief suggestion to Cart, I changed the version to follow Bevy version instead of crevice, do we want that?
- Crevice README.md need to be updated
- in the `Cargo.toml`, there are a few things to change. How do we want to change them? How do we keep attributions to original Crevice?
```
authors = ["Lucien Greathouse <me@lpghatguy.com>"]
documentation = "https://docs.rs/crevice"
homepage = "https://github.com/LPGhatguy/crevice"
repository = "https://github.com/LPGhatguy/crevice"
```
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- 3d examples fail to run in webgl2 because of unsupported texture formats or texture too large
## Solution
- switch to supported formats if a feature is enabled. I choose a feature instead of a build target to not conflict with a potential webgpu support
Very inspired by 6813b2edc5, and need #3290 to work.
I named the feature `webgl2`, but it's only needed if one want to use PBR in webgl2. Examples using only 2D already work.
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
Fixes#3352Fixes#3208
## Solution
- Update wgpu to 0.12
- Update naga to 0.8
- Resolve compilation errors
- Remove [[block]] from WGSL shaders (because it is depracated and now wgpu cant parse it)
- Replace `elseif` with `else if` in pbr.wgsl
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
Objective
During work on #3009 I've found that not all jobs use actions-rs, and therefore, an previous version of Rust is used for them. So while compilation and other stuff can pass, checking markup and Android build may fail with compilation errors.
Solution
This PR adds `action-rs` for any job running cargo, and updates the edition to 2021.
This relicenses Bevy under the dual MIT or Apache-2.0 license. For rationale, see #2373.
* Changes the LICENSE file to describe the dual license. Moved the MIT license to docs/LICENSE-MIT. Added the Apache-2.0 license to docs/LICENSE-APACHE. I opted for this approach over dumping both license files at the root (the more common approach) for a number of reasons:
* Github links to the "first" license file (LICENSE-APACHE) in its license links (you can see this in the wgpu and rust-analyzer repos). People clicking these links might erroneously think that the apache license is the only option. Rust and Amethyst both use COPYRIGHT or COPYING files to solve this problem, but this creates more file noise (if you do everything at the root) and the naming feels way less intuitive.
* People have a reflex to look for a LICENSE file. By providing a single license file at the root, we make it easy for them to understand our licensing approach.
* I like keeping the root clean and noise free
* There is precedent for putting the apache and mit license text in sub folders (amethyst)
* Removed the `Copyright (c) 2020 Carter Anderson` copyright notice from the MIT license. I don't care about this attribution, it might make license compliance more difficult in some cases, and it didn't properly attribute other contributors. We shoudn't replace it with something like "Copyright (c) 2021 Bevy Contributors" because "Bevy Contributors" is not a legal entity. Instead, we just won't include the copyright line (which has precedent ... Rust also uses this approach).
* Updates crates to use the new "MIT OR Apache-2.0" license value
* Removes the old legion-transform license file from bevy_transform. bevy_transform has been its own, fully custom implementation for a long time and that license no longer applies.
* Added a License section to the main readme
* Updated our Bevy Plugin licensing guidelines.
As a follow-up we should update the website to properly describe the new license.
Closes#2373
# Objective
Reduce compilation time
# Solution
Remove unused dependencies. While this PR doesn't remove any crates from `Cargo.lock`, it may unlock more build parallelism.
This gets rid of multiple unsafe blocks that we had to maintain ourselves, and instead depends on library that's commonly used and supported by the ecosystem. We also get support for glam types for free.
There is still some things to clear up with the `Bytes` trait, but that is a bit more substantial change and can be done separately. Also there are already separate efforts to use `crevice` crate, so I've just added that as a TODO.
{kind=link}
{kind=link}