I ported the two existing PCF techniques to the cubemap domain as best I
could. Generally, the technique is to create a 2D orthonormal basis
using Gram-Schmidt normalization, then apply the technique over that
basis. The results look fine, though the shadow bias often needs
adjusting.
For comparison, Unity uses a 4-tap pattern for PCF on point lights of
(1, 1, 1), (-1, -1, 1), (-1, 1, -1), (1, -1, -1). I tried this but
didn't like the look, so I went with the design above, which ports the
2D techniques to the 3D domain. There's surprisingly little material on
point light PCF.
I've gone through every example using point lights and verified that the
shadow maps look fine, adjusting biases as necessary.
Fixes#3628.
---
## Changelog
### Added
* Shadows from point lights now support percentage-closer filtering
(PCF), and as a result look less aliased.
### Changed
* `ShadowFilteringMethod::Castano13` and
`ShadowFilteringMethod::Jimenez14` have been renamed to
`ShadowFilteringMethod::Gaussian` and `ShadowFilteringMethod::Temporal`
respectively.
## Migration Guide
* `ShadowFilteringMethod::Castano13` and
`ShadowFilteringMethod::Jimenez14` have been renamed to
`ShadowFilteringMethod::Gaussian` and `ShadowFilteringMethod::Temporal`
respectively.
Currently, `MeshUniform`s are rather large: 160 bytes. They're also
somewhat expensive to compute, because they involve taking the inverse
of a 3x4 matrix. Finally, if a mesh is present in multiple views, that
mesh will have a separate `MeshUniform` for each and every view, which
is wasteful.
This commit fixes these issues by introducing the concept of a *mesh
input uniform* and adding a *mesh uniform building* compute shader pass.
The `MeshInputUniform` is simply the minimum amount of data needed for
the GPU to compute the full `MeshUniform`. Most of this data is just the
transform and is therefore only 64 bytes. `MeshInputUniform`s are
computed during the *extraction* phase, much like skins are today, in
order to avoid needlessly copying transforms around on CPU. (In fact,
the render app has been changed to only store the translation of each
mesh; it no longer cares about any other part of the transform, which is
stored only on the GPU and the main world.) Before rendering, the
`build_mesh_uniforms` pass runs to expand the `MeshInputUniform`s to the
full `MeshUniform`.
The mesh uniform building pass does the following, all on GPU:
1. Copy the appropriate fields of the `MeshInputUniform` to the
`MeshUniform` slot. If a single mesh is present in multiple views, this
effectively duplicates it into each view.
2. Compute the inverse transpose of the model transform, used for
transforming normals.
3. If applicable, copy the mesh's transform from the previous frame for
TAA. To support this, we double-buffer the `MeshInputUniform`s over two
frames and swap the buffers each frame. The `MeshInputUniform`s for the
current frame contain the index of that mesh's `MeshInputUniform` for
the previous frame.
This commit produces wins in virtually every CPU part of the pipeline:
`extract_meshes`, `queue_material_meshes`,
`batch_and_prepare_render_phase`, and especially
`write_batched_instance_buffer` are all faster. Shrinking the amount of
CPU data that has to be shuffled around speeds up the entire rendering
process.
| Benchmark | This branch | `main` | Speedup |
|------------------------|-------------|---------|---------|
| `many_cubes -nfc` | 17.259 | 24.529 | 42.12% |
| `many_cubes -nfc -vpi` | 302.116 | 312.123 | 3.31% |
| `many_foxes` | 3.227 | 3.515 | 8.92% |
Because mesh uniform building requires compute shader, and WebGL 2 has
no compute shader, the existing CPU mesh uniform building code has been
left as-is. Many types now have both CPU mesh uniform building and GPU
mesh uniform building modes. Developers can opt into the old CPU mesh
uniform building by setting the `use_gpu_uniform_builder` option on
`PbrPlugin` to `false`.
Below are graphs of the CPU portions of `many-cubes
--no-frustum-culling`. Yellow is this branch, red is `main`.
`extract_meshes`:

It's notable that we get a small win even though we're now writing to a
GPU buffer.
`queue_material_meshes`:

There's a bit of a regression here; not sure what's causing it. In any
case it's very outweighed by the other gains.
`batch_and_prepare_render_phase`:

There's a huge win here, enough to make batching basically drop off the
profile.
`write_batched_instance_buffer`:

There's a massive improvement here, as expected. Note that a lot of it
simply comes from the fact that `MeshInputUniform` is `Pod`. (This isn't
a maintainability problem in my view because `MeshInputUniform` is so
simple: just 16 tightly-packed words.)
## Changelog
### Added
* Per-mesh instance data is now generated on GPU with a compute shader
instead of CPU, resulting in rendering performance improvements on
platforms where compute shaders are supported.
## Migration guide
* Custom render phases now need multiple systems beyond just
`batch_and_prepare_render_phase`. Code that was previously creating
custom render phases should now add a `BinnedRenderPhasePlugin` or
`SortedRenderPhasePlugin` as appropriate instead of directly adding
`batch_and_prepare_render_phase`.
Adopted #8266, so copy-pasting the description from there:
# Objective
Support the KHR_texture_transform extension for the glTF loader.
- Fixes#6335
- Fixes#11869
- Implements part of #11350
- Implements the GLTF part of #399
## Solution
As is, this only supports a single transform. Looking at Godot's source,
they support one transform with an optional second one for detail, AO,
and emission. glTF specifies one per texture. The public domain
materials I looked at seem to share the same transform. So maybe having
just one is acceptable for now. I tried to include a warning if multiple
different transforms exist for the same material.
Note the gltf crate doesn't expose the texture transform for the normal
and occlusion textures, which it should, so I just ignored those for
now. (note by @janhohenheim: this is still the case)
Via `cargo run --release --example scene_viewer
~/src/clone/glTF-Sample-Models/2.0/TextureTransformTest/glTF/TextureTransformTest.gltf`:

## Changelog
Support for the
[KHR_texture_transform](https://github.com/KhronosGroup/glTF/tree/main/extensions/2.0/Khronos/KHR_texture_transform)
extension added. Texture UVs that were scaled, rotated, or offset in a
GLTF are now properly handled.
---------
Co-authored-by: Al McElrath <hello@yrns.org>
Co-authored-by: Kanabenki <lucien.menassol@gmail.com>
# Objective
- Supercedes #8872
- Improve sprite rendering performance after the regression in #9236
## Solution
- Use an instance-rate vertex buffer to store per-instance data.
- Store color, UV offset and scale, and a transform per instance.
- Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine
3x4 matrix and store the transpose of that in the per-instance data.
This is similar to how MeshUniform uses transpose affine matrices.
- Use a special index buffer that has batches of 6 indices referencing 4
vertices. The lower 2 bits indicate the x and y of a quad such that the
corners are:
```
10 11
00 01
```
UVs are implicit but get modified by UV offset and scale The remaining
upper bits contain the instance index.
## Benchmarks
I will compare versus `main` before #9236 because the results should be
as good as or faster than that. Running `bevymark -- 10000 16` on an M1
Max with `main` at `e8b38925` in yellow, this PR in red:
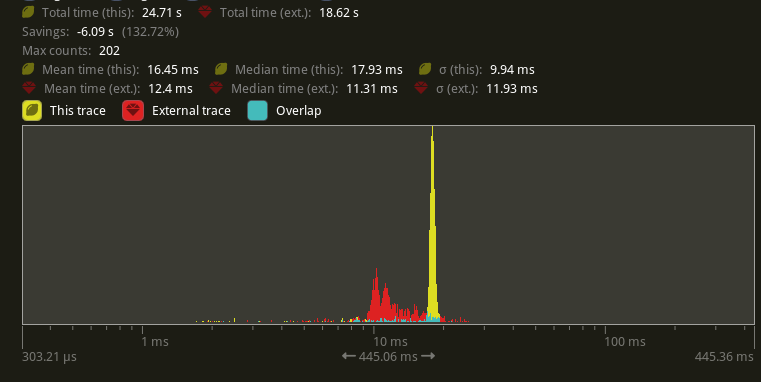
Looking at the median frame times, that's a 37% reduction from before.
---
## Changelog
- Changed: Improved sprite rendering performance by leveraging an
instance-rate vertex buffer.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
{kind=link}