…able like Table. Rename clear to clear_entities to clarify that metadata keeps, only value cleared
# Objective
- Provide some inspectability for SparseSets.
## Solution
- `Tables` has these three methods, len, is_empty and iter too. Add these methods to `SparseSets`, so user can print the shape of storage.
---
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- Add `len`, `is_empty`, `iter` methods on SparseSets.
- Rename `clear` to `clear_entities` to clarify its purpose.
- Add `new_for_test` on `ComponentInfo` to make test code easy.
- Add test case covering new methods.
## Migration Guide
> This section is optional. If there are no breaking changes, you can delete this section.
- Simply adding new functionality is not a breaking change.
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
* `World::init_resource` and `World::get_resource_or_insert_with` are implemented naively, and as such they perform duplicate `TypeId -> ComponentId` lookups.
* `World::get_resource_or_insert_with` contains an additional duplicate `ComponentId -> ResourceData` lookup.
* This function also contains an unnecessary panic branch, which we rely on the optimizer to be able to remove.
## Solution
Implement the functions using engine-internal code, instead of combining high-level functions. This allows computed variables to persist across different branches, instead of being recomputed.
# Objective
Following #6681, both `TableRow` and `TableId` are now part of `EntityLocation`. However, the safety invariant on `EntityLocation` requires that all of the constituent fields are `repr(transprent)` or `repr(C)` and the bit pattern of all 1s must be valid. This is not true for `TableRow` and `TableId` currently.
## Solution
Mark `TableRow` and `TableId` to satisfy the safety requirement. Add safety comments on `ArchetypeId`, `ArchetypeRow`, `TableId` and `TableRow`.
# Objective
Improve safety testing when using `bevy_ptr` types. This is a follow-up to #7113.
## Solution
Add a debug-only assertion that pointers are aligned when casting to a concrete type. This should very quickly catch any unsoundness from unaligned pointers, even without miri. However, this can have a large negative perf impact on debug builds.
---
## Changelog
Added: `Ptr::deref` will now panic in debug builds if the pointer is not aligned.
Added: `PtrMut::deref_mut` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::read` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::drop_as` will now panic in debug builds if the pointer is not aligned.
# Objective
Fixes#3310. Fixes#6282. Fixes#6278. Fixes#3666.
## Solution
Split out `!Send` resources into `NonSendResources`. Add a `origin_thread_id` to all `!Send` Resources, check it on dropping `NonSendResourceData`, if there's a mismatch, panic. Moved all of the checks that `MainThreadValidator` would do into `NonSendResources` instead.
All `!Send` resources now individually track which thread they were inserted from. This is validated against for every access, mutation, and drop that could be done against the value.
A regression test using an altered version of the example from #3310 has been added.
This is a stopgap solution for the current status quo. A full solution may involve fully removing `!Send` resources/components from `World`, which will likely require a much more thorough design on how to handle the existing in-engine and ecosystem use cases.
This PR also introduces another breaking change:
```rust
use bevy_ecs::prelude::*;
#[derive(Resource)]
struct Resource(u32);
fn main() {
let mut world = World::new();
world.insert_resource(Resource(1));
world.insert_non_send_resource(Resource(2));
let res = world.get_resource_mut::<Resource>().unwrap();
assert_eq!(res.0, 2);
}
```
This code will run correctly on 0.9.1 but not with this PR, since NonSend resources and normal resources have become actual distinct concepts storage wise.
## Changelog
Changed: Fix soundness bug with `World: Send`. Dropping a `World` that contains a `!Send` resource on the wrong thread will now panic.
## Migration Guide
Normal resources and `NonSend` resources no longer share the same backing storage. If `R: Resource`, then `NonSend<R>` and `Res<R>` will return different instances from each other. If you are using both `Res<T>` and `NonSend<T>` (or their mutable variants), to fetch the same resources, it's strongly advised to use `Res<T>`.
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
Prevent future unsoundness that was seen in #6623.
## Solution
Newtype both indexes in `Archetype` and `Table` as `ArchetypeRow` and `TableRow`. This avoids weird numerical manipulation on the indices, and can be stored and treated opaquely. Also enforces the source and destination of where these indices at a type level.
---
## Changelog
Changed: `Archetype` indices and `Table` rows have been newtyped as `ArchetypeRow` and `TableRow`.
# Objective
Fixes#4884. `ComponentTicks` stores both added and changed ticks contiguously in the same 8 bytes. This is convenient when passing around both together, but causes half the bytes fetched from memory for the purposes of change detection to effectively go unused. This is inefficient when most queries (no filter, mutating *something*) only write out to the changed ticks.
## Solution
Split the storage for change detection ticks into two separate `Vec`s inside `Column`. Fetch only what is needed during iteration.
This also potentially also removes one blocker from autovectorization of dense queries.
EDIT: This is confirmed to enable autovectorization of dense queries in `for_each` and `par_for_each` where possible. Unfortunately `iter` has other blockers that prevent it.
### TODO
- [x] Microbenchmark
- [x] Check if this allows query iteration to autovectorize simple loops.
- [x] Clean up all of the spurious tuples now littered throughout the API
### Open Questions
- ~~Is `Mut::is_added` absolutely necessary? Can we not just use `Added` or `ChangeTrackers`?~~ It's optimized out if unused.
- ~~Does the fetch of the added ticks get optimized out if not used?~~ Yes it is.
---
## Changelog
Added: `Tick`, a wrapper around a single change detection tick.
Added: `Column::get_added_ticks`
Added: `Column::get_column_ticks`
Added: `SparseSet::get_added_ticks`
Added: `SparseSet::get_column_ticks`
Changed: `Column` now stores added and changed ticks separately internally.
Changed: Most APIs returning `&UnsafeCell<ComponentTicks>` now returns `TickCells` instead, which contains two separate `&UnsafeCell<Tick>` for either component ticks.
Changed: `Query::for_each(_mut)`, `Query::par_for_each(_mut)` will now leverage autovectorization to speed up query iteration where possible.
## Migration Guide
TODO
# Objective
BlobVec currently relies on a scratch piece of memory allocated at initialization to make a temporary copy of a component when using `swap_remove_and_{forget/drop}`. This is potentially suboptimal as it writes to a, well-known, but random part of memory instead of using the stack.
## Solution
As the `FIXME` in the file states, replace `swap_scratch` with a call to `swap_nonoverlapping::<u8>`. The swapped last entry is returned as a `OwnedPtr`.
In theory, this should be faster as the temporary swap is allocated on the stack, `swap_nonoverlapping` allows for easier vectorization for bigger types, and the same memory is used between the swap and the returned `OwnedPtr`.
# Objective
* Enable `Res` and `Query` parameter mutual exclusion
* Required for https://github.com/bevyengine/bevy/pull/5080
The `FilteredAccessSet::get_conflicts` methods didn't work properly with
`Res` and `ResMut` parameters. Because those added their access by using
the `combined_access_mut` method and directly modifying the global
access state of the FilteredAccessSet. This caused an inconsistency,
because get_conflicts assumes that ALL added access have a corresponding
`FilteredAccess` added to the `filtered_accesses` field.
In practice, that means that SystemParam that adds their access through
the `Access` returned by `combined_access_mut` and the ones that add
their access using the `add` method lived in two different universes. As
a result, they could never be mutually exclusive.
## Solution
This commit fixes it by removing the `combined_access_mut` method. This
ensures that the `combined_access` field of FilteredAccessSet is always
updated consistently with the addition of a filter. When checking for
filtered access, it is now possible to account for `Res` and `ResMut`
invalid access. This is currently not needed, but might be in the
future.
We add the `add_unfiltered_{read,write}` methods to replace previous
usages of `combined_access_mut`.
We also add improved Debug implementations on FixedBitSet so that their
meaning is much clearer in debug output.
---
## Changelog
* Fix `Res` and `Query` parameter never being mutually exclusive.
## Migration Guide
Note: this mostly changes ECS internals, but since the API is public, it is technically breaking:
* Removed `FilteredAccessSet::combined_access_mut`
* Replace _immutable_ usage of those by `combined_access`
* For _mutable_ usages, use the new `add_unfiltered_{read,write}` methods instead of `combined_access_mut` followed by `add_{read,write}`
# Objective
Make core types in ECS smaller. The column sparse set in Tables is never updated after creation.
## Solution
Create `ImmutableSparseSet` which removes the capacity fields in the backing vec's and the APIs for inserting or removing elements. Drops the size of the sparse set by 3 usizes (24 bytes on 64-bit systems)
## Followup
~~After #4809, Archetype's component SparseSet should be replaced with it.~~ This has been done.
---
## Changelog
Removed: `Table::component_capacity`
## Migration Guide
`Table::component_capacity()` has been removed as Tables do not support adding/removing columns after construction.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
In bevy 0.8 you could list all resources using `world.archetypes().resource().components()`. As far as I can tell the resource archetype has been replaced with the `Resources` storage, and it would be nice if it could be used to iterate over all resource component IDs as well.
## Solution
- add `fn Resources::iter(&self) -> impl Iterator<Item = (ComponentId, &ResourceData)>`
# Objective
Fixes#6615.
`BlobVec` does not respect alignment for zero-sized types, which results in UB whenever a ZST with alignment other than 1 is used in the world.
## Solution
Add the fn `bevy_ptr::dangling_with_align`.
---
## Changelog
+ Added the function `dangling_with_align` to `bevy_ptr`, which creates a well-aligned dangling pointer to a type whose alignment is not known at compile time.
# Objective
Fixes#6059, changing all incorrect occurrences of ``id`` in the ``entity`` module to ``index``:
* struct level documentation,
* ``id`` struct field,
* ``id`` method and its documentation.
## Solution
Renaming and verifying using CI.
Co-authored-by: Edvin Kjell <43633999+Edwox@users.noreply.github.com>
# Objective
At least partially addresses #6282.
Resources are currently stored as a dedicated Resource archetype (ID 1). This allows for easy code reusability, but unnecessarily adds 72 bytes (on 64-bit systems) to the struct that is only used for that one archetype. It also requires several fields to be `pub(crate)` which isn't ideal.
This should also remove one sparse-set lookup from fetching, inserting, and removing resources from a `World`.
## Solution
- Add `Resources` parallel to `Tables` and `SparseSets` and extract the functionality used by `Archetype` in it.
- Remove `unique_components` from `Archetype`
- Remove the `pub(crate)` on `Archetype::components`.
- Remove `ArchetypeId::RESOURCE`
- Remove `Archetypes::resource` and `Archetypes::resource_mut`
---
## Changelog
Added: `Resources` type to store resources.
Added: `Storages::resource`
Removed: `ArchetypeId::RESOURCE`
Removed: `Archetypes::resource` and `Archetypes::resources`
Removed: `Archetype::unique_components` and `Archetypes::unique_components_mut`
## Migration Guide
Resources have been moved to `Resources` under `Storages` in `World`. All code dependent on `Archetype::unique_components(_mut)` should access it via `world.storages().resources()` instead.
All APIs accessing the raw data of individual resources (mutable *and* read-only) have been removed as these APIs allowed for unsound unsafe code. All usages of these APIs should be changed to use `World::{get, insert, remove}_resource`.
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
# Objective
remove `insert_resource_with_id` because `insert_resource_by_id` exists and does almost exactly the same thing
blocked on #5587 because otherwise we will leak a resource when it's inserted
## Solution
remove the function and also add a safety invariant of to `insert_resource_by_id` that the id be valid for the world.
I didn't see any discussion in #4447 about this safety invariant being left off in favor of a panic so I'm curious if there was one or if it just seemed nicer to have less safety invariants for callers to uphold 😅
---
## Changelog
- safety invariant added to `insert_resource_by_id` requiring the id to be valid for world
## Migration Guide
- audit any calls to `insert_resource_by_id` making sure that the id is valid for the world
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
The first leak:
```rust
#[test]
fn blob_vec_drop_empty_capacity() {
let item_layout = Layout:🆕:<Foo>();
let drop = drop_ptr::<Foo>;
let _ = unsafe { BlobVec::new(item_layout, Some(drop), 0) };
}
```
this is because we allocate the swap scratch in blobvec regardless of what the capacity is, but we only deallocate if capacity is > 0
The second leak:
```rust
#[test]
fn panic_while_overwriting_component() {
let helper = DropTestHelper::new();
let res = panic::catch_unwind(|| {
let mut world = World::new();
world
.spawn()
.insert(helper.make_component(true, 0))
.insert(helper.make_component(false, 1));
println!("Done inserting! Dropping world...");
});
let drop_log = helper.finish(res);
assert_eq!(
&*drop_log,
[
DropLogItem::Create(0),
DropLogItem::Create(1),
DropLogItem::Drop(0),
]
);
}
```
this is caused by us not running the drop impl on the to-be-inserted component if the drop impl of the overwritten component panics
---
managed to figure out where the leaks were by using this 10/10 command
```
cargo --quiet test --lib -- --list | sed 's/: test$//' | MIRIFLAGS="-Zmiri-disable-isolation" xargs -n1 cargo miri test --lib -- --exact
```
which runs every test one by one rather than all at once which let miri actually tell me which test had the leak 🙃
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
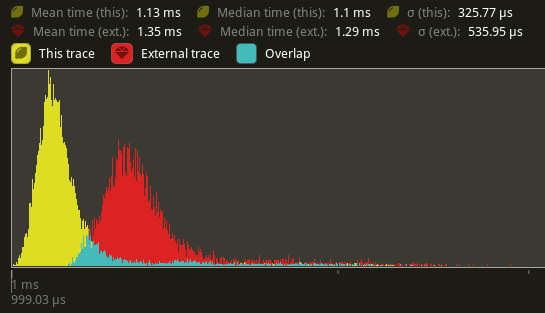
The command heavy `Extract` stage also saw a smaller overall improvement:
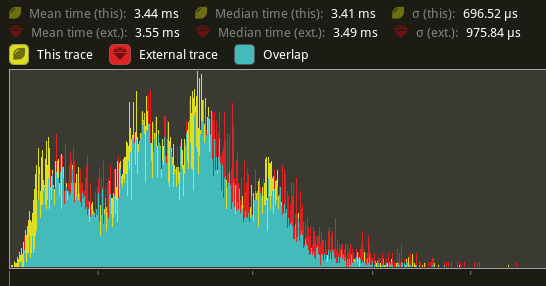
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
Closes#1557. Partially addresses #3362.
Cleanup the public facing API for storage types. Most of these APIs are difficult to use safely when directly interfacing with these types, and is also currently impossible to interact with in normal ECS use as there is no `World::storages_mut`. The majority of these types should be easy enough to read, and perhaps mutate the contents, but never structurally altered without the same checks in the rest of bevy_ecs code. This both cleans up the public facing types and helps use unused code detection to remove a few of the APIs we're not using internally.
## Solution
- Mark all APIs that take `&mut T` under `bevy_ecs::storage` as `pub(crate)` or `pub(super)`
- Cleanup after it all.
Entire type visibility changes:
- `BlobVec` is `pub(super)`, only storage code should be directly interacting with it.
- `SparseArray` is now `pub(crate)` for the entire type. It's an implementation detail for `Table` and `(Component)SparseSet`.
- `TableMoveResult` is now `pub(crate)
---
## Changelog
TODO
## Migration Guide
Dear God, I hope not.
# Objective
Following #4855, `Column` is just a parallel `BlobVec`/`Vec<UnsafeCell<ComponentTicks>>` pair, which is identical to the dense and ticks vecs in `ComponentSparseSet`, which has some code duplication with `Column`.
## Solution
Replace dense and ticks in `ComponentSparseSet` with a `Column`.
# Objective
`debug_assert!` macros must still compile properly in release mode due to how they're implemented. This is causing release builds to fail.
## Solution
Change them to `assert!` macros inside `#[cfg(debug_assertions)]` blocks.
# Objective
Use less memory to store SparseSet components.
## Solution
Change `ComponentSparseSet` to only use `Entity::id` in it's key internally, and change the usize value in it's SparseArray to use u32 instead, as it cannot have more than u32::MAX live entities stored at once.
This should reduce the overhead of storing components in sparse set storage by 50%.
# Objective
The `ComponentId` in `Column` is redundant as it's stored in parallel in the surrounding `SparseSet` all the time.
## Solution
Remove it. Add `SparseSet::iter(_mut)` to parallel `HashMap::iter(_mut)` to allow iterating pairs of columns and their IDs.
---
## Changelog
Added: `SparseSet::iter` and `SparseSet::iter_mut`.
# Objective
Even if bevy itself does not provide any builtin scripting or modding APIs, it should have the foundations for building them yourself.
For that it should be enough to have APIs that are not tied to the actual rust types with generics, but rather accept `ComponentId`s and `bevy_ptr` ptrs.
## Solution
Add the following APIs to bevy
```rust
fn EntityRef::get_by_id(ComponentId) -> Option<Ptr<'w>>;
fn EntityMut::get_by_id(ComponentId) -> Option<Ptr<'_>>;
fn EntityMut::get_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
fn World::get_resource_by_id(ComponentId) -> Option<Ptr<'_>>;
fn World::get_resource_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
// Safety: `value` must point to a valid value of the component
unsafe fn World::insert_resource_by_id(ComponentId, value: OwningPtr);
fn ComponentDescriptor::new_with_layout(..) -> Self;
fn World::init_component_with_descriptor(ComponentDescriptor) -> ComponentId;
```
~~This PR would definitely benefit from #3001 (lifetime'd pointers) to make sure that the lifetimes of the pointers are valid and the my-move pointer in `insert_resource_by_id` could be an `OwningPtr`, but that can be adapter later if/when #3001 is merged.~~
### Not in this PR
- inserting components on entities (this is very tied to types with bundles and the `BundleInserter`)
- an untyped version of a query (needs good API design, has a large implementation complexity, can be done in a third-party crate)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- We do a lot of function pointer calls in a hot loop (clearing entities in render). This is slow, since calling function pointers cannot be optimised out. We can avoid that in the cases where the function call is a no-op.
- Alternative to https://github.com/bevyengine/bevy/pull/2897
- On my machine, in `many_cubes`, this reduces dropping time from ~150μs to ~80μs.
## Solution
- Make `drop` in `BlobVec` an `Option`, recording whether the given drop impl is required or not.
- Note that this does add branching in some cases - we could consider splitting this into two fields, i.e. unconditionally call the `drop` fn pointer.
- My intuition of how often types stored in `World` should have non-trivial drops makes me think that would be slower, however.
N.B. Even once this lands, we should still test having a 'drop_multiple' variant - for types with a real `Drop` impl, the current implementation is definitely optimal.
# Objective
- (Eventually) reduce noise in reporting access conflicts between unordered systems.
- `SystemStage` only looks at unfiltered `ComponentId` access, any conflicts reported are potentially `false`.
- the systems could still be accessing disjoint archetypes
- Comparing systems' filtered access sets can maybe avoid that (for statically known component types).
- #4204
## Solution
- Modify `SparseSetIndex` trait to require `PartialEq`, `Eq`, and `Hash` (all internal types except `BundleId` already did).
- Add `is_compatible` and `get_conflicts` methods to `FilteredAccessSet<T>`
- (existing method renamed to `get_conflicts_single`)
- Add docs for those and all the other methods while I'm at it.
1. change `PtrMut::as_ptr(self)` and `OwnedPtr::as_ptr(self)` to take `&self`, otherwise printing the pointer will prevent doing anything else afterwards
2. make all `as_ptr` methods safe. There's nothing unsafe about obtaining a pointer, these kinds of methods are safe in std as well [str::as_ptr](https://doc.rust-lang.org/stable/std/primitive.str.html#method.as_ptr), [Rc::as_ptr](https://doc.rust-lang.org/stable/std/rc/struct.Rc.html#method.as_ptr)
3. rename `offset`/`add` to `byte_offset`/`byte_add`. The unprefixed methods in std add in increments of `std::mem::size_of::<T>`, not in bytes. There's a PR for rust to add these byte_ methods https://github.com/rust-lang/rust/pull/95643 and at the call site it makes it much more clear that you need to do `.byte_add(i * layout_size)` instead of `.add(i)`
# Objective
The pointer types introduced in #3001 are useful not just in `bevy_ecs`, but also in crates like `bevy_reflect` (#4475) or even outside of bevy.
## Solution
Extract `Ptr<'a>`, `PtrMut<'a>`, `OwnedPtr<'a>`, `ThinSlicePtr<'a, T>` and `UnsafeCellDeref` from `bevy_ecs::ptr` into `bevy_ptr`.
**Note:** `bevy_ecs` still reexports the `bevy_ptr` as `bevy_ecs::ptr` so that crates like `bevy_transform` can use the `Bundle` derive without needing to depend on `bevy_ptr` themselves.
# Objective
The `Ptr` types gives free access to the underlying `NonNull<u8>`, which adds more publicly visible pointer wrangling than there needs to be. There are also a few edge cases where Ptr types could be more readily utilized for properly validating the soundness of ECS operations.
## Solution
- Replace `*Ptr(Mut)::inner` with `cast` which requires a concrete type to give the pointer. This function could also have a `debug_assert` with an alignment check to ensure that the pointer is aligned properly, but is currently not included.
- Use `OwningPtr::read` in ECS macros over casting the inner pointer around.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
For some keys, it is too expensive to hash them on every lookup. Historically in Bevy, we have regrettably done the "wrong" thing in these cases (pre-computing hashes, then re-hashing them) because Rust's built in hashed collections don't give us the tools we need to do otherwise. Doing this is "wrong" because two different values can result in the same hash. Hashed collections generally get around this by falling back to equality checks on hash collisions. You can't do that if the key _is_ the hash. Additionally, re-hashing a hash increase the odds of collision!
#3959 needs pre-hashing to be viable, so I decided to finally properly solve the problem. The solution involves two different changes:
1. A new generalized "pre-hashing" solution in bevy_utils: `Hashed<T>` types, which store a value alongside a pre-computed hash. And `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . `PreHashMap` is just an alias for a normal HashMap that uses `Hashed<T>` as the key and a new `PassHash` implementation as the Hasher.
2. Replacing the `std::collections` re-exports in `bevy_utils` with equivalent `hashbrown` impls. Avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. The latest version of `hashbrown` adds support for the `entity_ref` api, so we can move to that in preparation for an std migration, if thats the direction they seem to be going in. Note that adding hashbrown doesn't increase our dependency count because it was already in our tree.
In addition to providing these core tools, I also ported the "table identity hashing" in `bevy_ecs` to `raw_entry_mut`, which was a particularly egregious case.
The biggest outstanding case is `AssetPathId`, which stores a pre-hash. We need AssetPathId to be cheaply clone-able (and ideally Copy), but `Hashed<AssetPath>` requires ownership of the AssetPath, which makes cloning ids way more expensive. We could consider doing `Hashed<Arc<AssetPath>>`, but cloning an arc is still a non-trivial expensive that needs to be considered. I would like to handle this in a separate PR. And given that we will be re-evaluating the Bevy Assets implementation in the very near future, I'd prefer to hold off until after that conversation is concluded.
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
# Objective
- Storages are used to store the ECS data.
- They're undocumented.
## Solution
- Add some very basic docs.
## Notes
- Some of this was hard to immediately understand when reading the code, so suggestions on improvements / things to add are particularly welcome.
# Objective
I thought I'd have a go a trying to fix#2597.
Hopefully fixes#2597.
## Solution
I reused the memory pointed to by the value parameter, that is already required by `insert` to not be dropped, to contain the extracted value while dropping it.
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Objective
The upcoming Bevy Book makes many references to the API documentation of bevy.
Most references belong to the first two chapters of the Bevy Book:
- bevyengine/bevy-website#176
- bevyengine/bevy-website#182
This PR attempts to improve the documentation of `bevy_ecs` and `bevy_app` in order to help readers of the Book who want to delve deeper into technical details.
## Solution
- Add crate and level module documentation
- Document the most important items (basically those included in the preludes), with the following style, where applicable:
- **Summary.** Short description of the item.
- **Second paragraph.** Detailed description of the item, without going too much in the implementation.
- **Code example(s).**
- **Safety or panic notes.**
## Collaboration
Any kind of collaboration is welcome, especially corrections, wording, new ideas and guidelines on where the focus should be put in.
---
### Related issues
- Fixes#2246
{kind=link}
{kind=link}