# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/discussions/6338
This PR allows for smooth transitions between different animations.
## Solution
- This PR uses very simple linear blending of animations.
- When starting a new animation, you can give it a duration, and throughout that duration, the previous and the new animation are being linearly blended, until only the new animation is running.
- I'm aware of https://github.com/bevyengine/rfcs/pull/49 and https://github.com/bevyengine/rfcs/pull/51, which are more complete solutions to this problem, but they seem still far from being implemented. Until they're ready, this PR allows for the most basic use case of blending, i.e. smoothly transitioning between different animations.
## Migration Guide
- no bc breaking changes
# Objective
Speed up animation by leveraging all threads in `ComputeTaskPool`.
## Solution
This PR parallelizes animation sampling across all threads.
To ensure that this is safely done, all animation is predicated with an ancestor query to ensure that there is no conflicting `AnimationPlayer` above each animated hierarchy that may cause this to alias.
Unlike the RFC, this does not add support for reflect based "animate anything", but only extends the existing `AnimationPlayer` to support high numbers of animated characters on screen at once.
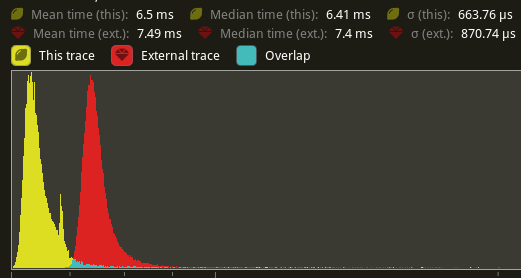
## Performance
This cuts `many_foxes`'s frame time on my machine by a full millisecond, from 7.49ms to 6.5ms. (yellow is this PR, red is main).
---
## Changelog
Changed: Animation sampling now runs fully multi-threaded using threads from `ComputeTaskPool`.
Changed: `AnimationPlayer` that are on a child or descendant of another entity with another player will no longer be run.
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective

^ enable this
Concretely, I need to
- list all handle ids for an asset type
- fetch the asset as `dyn Reflect`, given a `HandleUntyped`
- when encountering a `Handle<T>`, find out what asset type that handle refers to (`T`'s type id) and turn the handle into a `HandleUntyped`
## Solution
- add `ReflectAsset` type containing function pointers for working with assets
```rust
pub struct ReflectAsset {
type_uuid: Uuid,
assets_resource_type_id: TypeId, // TypeId of the `Assets<T>` resource
get: fn(&World, HandleUntyped) -> Option<&dyn Reflect>,
get_mut: fn(&mut World, HandleUntyped) -> Option<&mut dyn Reflect>,
get_unchecked_mut: unsafe fn(&World, HandleUntyped) -> Option<&mut dyn Reflect>,
add: fn(&mut World, &dyn Reflect) -> HandleUntyped,
set: fn(&mut World, HandleUntyped, &dyn Reflect) -> HandleUntyped,
len: fn(&World) -> usize,
ids: for<'w> fn(&'w World) -> Box<dyn Iterator<Item = HandleId> + 'w>,
remove: fn(&mut World, HandleUntyped) -> Option<Box<dyn Reflect>>,
}
```
- add `ReflectHandle` type relating the handle back to the asset type and providing a way to create a `HandleUntyped`
```rust
pub struct ReflectHandle {
type_uuid: Uuid,
asset_type_id: TypeId,
downcast_handle_untyped: fn(&dyn Any) -> Option<HandleUntyped>,
}
```
- add the corresponding `FromType` impls
- add a function `app.register_asset_reflect` which is supposed to be called after `.add_asset` and registers `ReflectAsset` and `ReflectHandle` in the type registry
---
## Changelog
- add `ReflectAsset` and `ReflectHandle` types, which allow code to use reflection to manipulate arbitrary assets without knowing their types at compile time
# Objective
- You usually want to say that a given animation *should* be playing, doing nothing if it's already playing.
## Solution
- Rename play to start and add new play method that won't overwrite the existing animation if it's already playing #6350
---
## Changelog
### Changed
`AnimationPlayer::play` will now not restart the animation if it's already playing
### Added
An `AnimationPlayer ::start` method, which has the old behavior of `play`
## Migration guide
- If you were using `play` to restart an animation that was already playing, that functionality has been moved to `start`. Now, `play` won't have any effect if the requested animation is already playing.
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
## Objective
Implement absolute minimum viable product for the changes proposed in bevyengine/rfcs#53.
## Solution
- Remove public mutative access to `Parent` (Children is already publicly read-only). This includes public construction methods like `Copy`, `Clone`, and `Default`.
- Remove `PreviousParent`
- Remove `parent_update_system`
- Update all hierarchy related commands to immediately update both `Parent` and `Children` references.
## Remaining TODOs
- [ ] Update documentation for both `Parent` and `Children`. Discourage using `EntityCommands::remove`
- [x] Add `HierarchyEvent` to notify listeners of hierarchy updates. This is meant to replace listening on `PreviousParent`
## Followup
- These changes should be best moved to the hooks mentioned in #3742.
- Backing storage for both might be best moved to indexes mentioned in the same relations.
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Reduce the catch-all grab-bag of functionality in bevy_core by minimally splitting off time functionality into bevy_time. Functionality like that provided by #3002 would increase the complexity of bevy_time, so this is a good candidate for pulling into its own unit.
A step in addressing #2931 and splitting bevy_core into more specific locations.
## Solution
Pull the time module of bevy_core into a new crate, bevy_time.
# Migration guide
- Time related types (e.g. `Time`, `Timer`, `Stopwatch`, `FixedTimestep`, etc.) should be imported from `bevy::time::*` rather than `bevy::core::*`.
- If you were adding `CorePlugin` manually, you'll also want to add `TimePlugin` from `bevy::time`.
- The `bevy::core::CorePlugin::Time` system label is replaced with `bevy::time::TimeSystem`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Small change that better facilitates custom animation systems
## Solution
- Added a public access function to `bevy::animation::AnimationClip`, making duration publicly readable
---
# Objective
- While playing with animated models, I noticed some were a little off
## Solution
- Some animations curves only have one keyframe, they are used to set a transform to a given value
- Those were ignored as we're never exactly at the ts 0.0 of an animation. going there explicitly (`.set_elapsed(0.0).pause()`) would crash
- Special case this as there isn't much to animate in this case
{kind=link}
{kind=link}