# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Fixes#3970
- To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines.
## Solution
- renamed `RenderPipelineCache` to `PipelineCache`
- Cached Pipelines are now represented by an enum (render, compute)
- split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines`
- updated the game of life example
## Open Questions
- should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that?
- should the `get_render_pipeline` and `get_compute_pipeline` methods be merged?
- is pipeline specialization for different entry points a good pattern
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
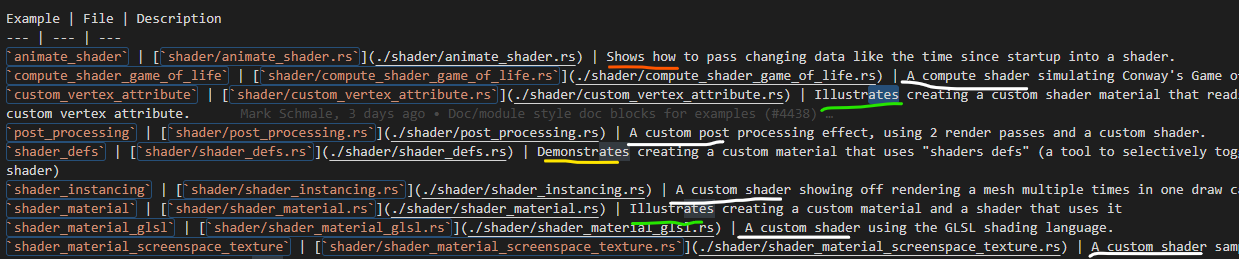
This PR makes a number of changes to how meshes and vertex attributes are handled, which the goal of enabling easy and flexible custom vertex attributes:
* Reworks the `Mesh` type to use the newly added `VertexAttribute` internally
* `VertexAttribute` defines the name, a unique `VertexAttributeId`, and a `VertexFormat`
* `VertexAttributeId` is used to produce consistent sort orders for vertex buffer generation, replacing the more expensive and often surprising "name based sorting"
* Meshes can be used to generate a `MeshVertexBufferLayout`, which defines the layout of the gpu buffer produced by the mesh. `MeshVertexBufferLayouts` can then be used to generate actual `VertexBufferLayouts` according to the requirements of a specific pipeline. This decoupling of "mesh layout" vs "pipeline vertex buffer layout" is what enables custom attributes. We don't need to standardize _mesh layouts_ or contort meshes to meet the needs of a specific pipeline. As long as the mesh has what the pipeline needs, it will work transparently.
* Mesh-based pipelines now specialize on `&MeshVertexBufferLayout` via the new `SpecializedMeshPipeline` trait (which behaves like `SpecializedPipeline`, but adds `&MeshVertexBufferLayout`). The integrity of the pipeline cache is maintained because the `MeshVertexBufferLayout` is treated as part of the key (which is fully abstracted from implementers of the trait ... no need to add any additional info to the specialization key).
* Hashing `MeshVertexBufferLayout` is too expensive to do for every entity, every frame. To make this scalable, I added a generalized "pre-hashing" solution to `bevy_utils`: `Hashed<T>` keys and `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . Why didn't I just do the quick and dirty in-place "pre-compute hash and use that u64 as a key in a hashmap" that we've done in the past? Because its wrong! Hashes by themselves aren't enough because two different values can produce the same hash. Re-hashing a hash is even worse! I decided to build a generalized solution because this pattern has come up in the past and we've chosen to do the wrong thing. Now we can do the right thing! This did unfortunately require pulling in `hashbrown` and using that in `bevy_utils`, because avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. Note that adding `hashbrown` doesn't increase our dependency count because it was already in our tree. I will probably break these changes out into their own PR.
* Specializing on `MeshVertexBufferLayout` has one non-obvious behavior: it can produce identical pipelines for two different MeshVertexBufferLayouts. To optimize the number of active pipelines / reduce re-binds while drawing, I de-duplicate pipelines post-specialization using the final `VertexBufferLayout` as the key. For example, consider a pipeline that needs the layout `(position, normal)` and is specialized using two meshes: `(position, normal, uv)` and `(position, normal, other_vec2)`. If both of these meshes result in `(position, normal)` specializations, we can use the same pipeline! Now we do. Cool!
To briefly illustrate, this is what the relevant section of `MeshPipeline`'s specialization code looks like now:
```rust
impl SpecializedMeshPipeline for MeshPipeline {
type Key = MeshPipelineKey;
fn specialize(
&self,
key: Self::Key,
layout: &MeshVertexBufferLayout,
) -> RenderPipelineDescriptor {
let mut vertex_attributes = vec![
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
Mesh::ATTRIBUTE_NORMAL.at_shader_location(1),
Mesh::ATTRIBUTE_UV_0.at_shader_location(2),
];
let mut shader_defs = Vec::new();
if layout.contains(Mesh::ATTRIBUTE_TANGENT) {
shader_defs.push(String::from("VERTEX_TANGENTS"));
vertex_attributes.push(Mesh::ATTRIBUTE_TANGENT.at_shader_location(3));
}
let vertex_buffer_layout = layout
.get_layout(&vertex_attributes)
.expect("Mesh is missing a vertex attribute");
```
Notice that this is _much_ simpler than it was before. And now any mesh with any layout can be used with this pipeline, provided it has vertex postions, normals, and uvs. We even got to remove `HAS_TANGENTS` from MeshPipelineKey and `has_tangents` from `GpuMesh`, because that information is redundant with `MeshVertexBufferLayout`.
This is still a draft because I still need to:
* Add more docs
* Experiment with adding error handling to mesh pipeline specialization (which would print errors at runtime when a mesh is missing a vertex attribute required by a pipeline). If it doesn't tank perf, we'll keep it.
* Consider breaking out the PreHash / hashbrown changes into a separate PR.
* Add an example illustrating this change
* Verify that the "mesh-specialized pipeline de-duplication code" works properly
Please dont yell at me for not doing these things yet :) Just trying to get this in peoples' hands asap.
Alternative to #3120Fixes#3030
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
## Objective
The [`DrawMeshInstanced`] command in the example sets vertex buffer 0 twice, with two identical calls to:
```rs
pass.set_vertex_buffer(0, gpu_mesh.vertex_buffer.slice(..));
```
## Solution
Remove the second call as it is unecessary.
[`DrawMeshInstanced`]: f3de12bc5e/examples/shader/shader_instancing.rs (L217-L258)
# Objective
- Allow opting-out of the built-in frustum culling for cases where its behaviour would be incorrect
- Make use of the this in the shader_instancing example that uses a custom instancing method. The built-in frustum culling breaks the custom instancing in the shader_instancing example if the camera is moved to:
```rust
commands.spawn_bundle(PerspectiveCameraBundle {
transform: Transform::from_xyz(12.0, 0.0, 15.0)
.looking_at(Vec3::new(12.0, 0.0, 0.0), Vec3::Y),
..Default::default()
});
```
...such that the Aabb of the cube Mesh that is at the origin goes completely out of view. This incorrectly (for the purpose of the custom instancing) culls the `Mesh` and so culls all instances even though some may be visible.
## Solution
- Add a `NoFrustumCulling` marker component
- Do not compute and add an `Aabb` to `Mesh` entities without an `Aabb` if they have a `NoFrustumCulling` marker component
- Do not apply frustum culling to entities with the `NoFrustumCulling` marker component
{kind=link}
{kind=link}
{kind=link}