# Objective
Closes#7202
## Solution
~~Introduce a `not` helper to pipe conditions. Opened mostly for discussion. Maybe create an extension trait with `not` method? Please, advice.~~
Introduce `not(condition)` condition that inverses the result of the passed.
---
## Changelog
### Added
- `not` condition.
Small commit to remove an unused resource scoped within a single bevy_ecs unit test. Also rearranged the initialization to follow initialization conventions of surrounding tests. World/Schedule initialization followed by resource initialization.
This change was tested locally with `cargo test`, and `cargo fmt` was run.
Risk should be tiny as change is scoped to a single unit test and very tiny, and I can't see any way that this resource is being used in the test.
Thank you so much!
# Objective
Run conditions are a special type of system that do not modify the world, and which return a bool. Due to the way they are currently implemented, you can *only* use bare function systems as a run condition. Among other things, this prevents the use of system piping with run conditions. This make very basic constructs impossible, such as `my_system.run_if(my_condition.pipe(not))`.
Unblocks a basic solution for #7202.
## Solution
Add the trait `ReadOnlySystem`, which is implemented for any system whose parameters all implement `ReadOnlySystemParam`. Allow any `-> bool` system implementing this trait to be used as a run condition.
---
## Changelog
+ Added the trait `ReadOnlySystem`, which is implemented for any `System` type whose parameters all implement `ReadOnlySystemParam`.
+ Added the function `bevy::ecs::system::assert_is_read_only_system`.
# Objective
Implementing `States` manually is repetitive, so let's not.
One thing I'm unsure of is whether the macro import statement is in the right place.
# Objective
One pattern to increase parallelism is deferred mutation: instead of directly mutating the world (and preventing other systems from running at the same time), you queue up operations to be applied to the world at the end of the stage. The most common example of this pattern uses the `Commands` SystemParam.
In order to avoid the overhead associated with commands, some power users may want to add their own deferred mutation behavior. To do this, you must implement the unsafe trait `SystemParam`, which interfaces with engine internals in a way that we'd like users to be able to avoid.
## Solution
Add the `Deferred<T>` primitive `SystemParam`, which encapsulates the deferred mutation pattern.
This can be combined with other types of `SystemParam` to safely and ergonomically create powerful custom types.
Essentially, this is just a variant of `Local<T>` which can run code at the end of the stage.
This type is used in the engine to derive `Commands` and `ParallelCommands`, which removes a bunch of unsafe boilerplate.
### Example
```rust
use bevy_ecs::system::{Deferred, SystemBuffer};
/// Sends events with a delay, but may run in parallel with other event writers.
#[derive(SystemParam)]
pub struct BufferedEventWriter<'s, E: Event> {
queue: Deferred<'s, EventQueue<E>>,
}
struct EventQueue<E>(Vec<E>);
impl<'s, E: Event> BufferedEventWriter<'s, E> {
/// Queues up an event to be sent at the end of this stage.
pub fn send(&mut self, event: E) {
self.queue.0.push(event);
}
}
// The `SystemBuffer` trait controls how [`Deferred`] gets applied at the end of the stage.
impl<E: Event> SystemBuffer for EventQueue<E> {
fn apply(&mut self, world: &mut World) {
let mut events = world.resource_mut::<Events<E>>();
for e in self.0.drain(..) {
events.send(e);
}
}
}
```
---
## Changelog
+ Added the `SystemParam` type `Deferred<T>`, which can be used to defer `World` mutations. Powered by the new trait `SystemBuffer`.
# Objective
- There is a small perf cost for starting the multithreaded executor.
## Solution
- We can skip that cost when there are zero systems in the schedule. Overall not a big perf boost unless there are a lot of empty schedules that are trying to run, but it is something.
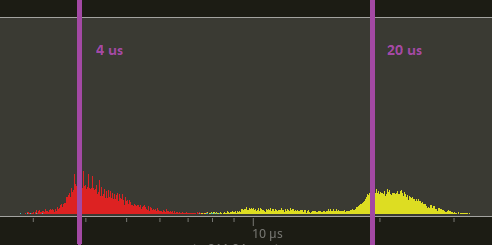
Below is a tracy trace of the run_fixed_update_schedule for many_foxes which has zero systems in it. Yellow is main and red is this pr. The time difference between the peaks of the humps is around 15us.
# Objective
- Implementing logic used by system params and `UnsafeWorldCell` on `&World` is sus since `&World` generally denotes shared read only access to world but this is a lie in the above situations. Move most/all logic that uses `&World` to mean `UnsafeWorldCell` onto `UnsafeWorldCell`
- Add a way to take a `&mut World` out of `UnsafeWorldCell` and use this in `WorldCell`'s `Drop` impl instead of a `UnsafeCell` field
---
## Changelog
- changed some `UnsafeWorldCell` methods to take `self` instead of `&self`/`&mut self` since there is literally no point to them doing that
- `UnsafeWorldCell::world` is now used to get immutable access to the whole world instead of just the metadata which can now be done via `UnsafeWorldCell::world_metadata`
- `UnsafeWorldCell::world_mut` now exists and can be used to get a `&mut World` out of `UnsafeWorldCell`
- removed `UnsafeWorldCell::storages` since that is probably unsound since storages contains the actual component/resource data not just metadata
## Migration guide
N/A none of the breaking changes here make any difference for a 0.9->0.10 transition since `UnsafeWorldCell` did not exist in 0.9
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Currently exclusive systems and applying buffers run outside of the multithreaded executor and just calls the funtions on the thread the schedule is running on. Stageless changes this to run these using tasks in a scope. Specifically It uses `spawn_on_scope` to run these. For the render thread this is incorrect as calling `spawn_on_scope` there runs tasks on the main thread. It should instead run these on the render thread and only run nonsend systems on the main thread.
## Solution
- Add another executor to `Scope` for spawning tasks on the scope. `spawn_on_scope` now always runs the task on the thread the scope is running on. `spawn_on_external` spawns onto the external executor than is optionally passed in. If None is passed `spawn_on_external` will spawn onto the scope executor.
- Eventually this new machinery will be able to be removed. This will happen once a fix for removing NonSend resources from the world lands. So this is a temporary fix to support stageless.
---
## Changelog
- add a spawn_on_external method to allow spawning on the scope's thread or an external thread
## Migration Guide
> No migration guide. The main thread executor was introduced in pipelined rendering which was merged for 0.10. spawn_on_scope now behaves the same way as on 0.9.
# Objective
- Make the internals of `RemovedComponents` clearer
## Solution
- Add a wrapper around `Entity`, used in `RemovedComponents` as `Events<RemovedComponentsEntity>`
---
## Changelog
- `RemovedComponents` now internally uses an `Events<RemovedComponentsEntity>` instead of an `Events<Entity>`
The `DoubleEndedIterator` impls produce incorrect results on subsequent calls to `iter()` if the iterator is only partially consumed.
The following code shows what happens
```rust
fn next_back_is_bad() {
let mut events = Events::<TestEvent>::default();
events.send(TestEvent { i: 0 });
events.send(TestEvent { i: 1 });
events.send(TestEvent { i: 2 });
let mut reader = events.get_reader();
let mut iter = reader.iter(&events);
assert_eq!(iter.next_back(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), Some(&TestEvent { i: 0 }));
let mut iter = reader.iter(&events);
// `i: 2` event is returned twice! The `i: 1` event is missed.
assert_eq!(iter.next(), Some(&TestEvent { i: 2 }));
assert_eq!(iter.next(), None);
}
```
I don't think this can be fixed without adding some very convoluted bookkeeping.
## Migration Guide
`ManualEventIterator` and `ManualEventIteratorWithId` are no longer `DoubleEndedIterator`s.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Removal events are unwieldy and require some knowledge of when to put systems that need to catch events for them, it is very easy to end up missing one and end up with memory leak-ish issues where you don't clean up after yourself.
## Solution
Consolidate removals with the benefits of `Events<...>` (such as double buffering and per system ticks for reading the events) and reduce the special casing of it, ideally I was hoping to move the removals to a `Resource` in the world, but that seems a bit more rough to implement/maintain because of double mutable borrowing issues.
This doesn't go the full length of change detection esque removal detection a la https://github.com/bevyengine/rfcs/pull/44.
Just tries to make the current workflow a bit more user friendly so detecting removals isn't such a scheduling nightmare.
---
## Changelog
- RemovedComponents<T> is now backed by an `Events<Entity>` for the benefits of double buffering.
## Migration Guide
- Add a `mut` for `removed: RemovedComponents<T>` since we are now modifying an event reader internally.
- Iterating over removed components now requires `&mut removed_components` or `removed_components.iter()` instead of `&removed_components`.
# Objective
The trait method `SystemParam::apply` allows a `SystemParam` type to defer world mutations, which is internally used to apply `Commands` at the end of the stage. Any operations that require `&mut World` access must be deferred in this way, since parallel systems do not have exclusive access to the world.
The `ExclusiveSystemParam` trait (added in #6083) has an `apply` method which serves the same purpose. However, deferring mutations in this way does not make sense for exclusive systems since they already have `&mut World` access: there is no need to wait until a hard sync point, as the system *is* a hard sync point. World mutations can and should be performed within the body of the system.
## Solution
Remove the method. There were no implementations of this method in the engine.
---
## Changelog
*Note for maintainers: this changelog makes more sense if it's placed above the one for #6919.*
- Removed the method `ExclusiveSystemParamState::apply`.
## Migration Guide
*Note for maintainers: this migration guide makes more sense if it's placed above the one for #6919.*
The trait method `ExclusiveSystemParamState::apply` has been removed. If you have an exclusive system with buffers that must be applied, you should apply them within the body of the exclusive system.
# Objective
Fixes#7434.
This is my first time contributing to a Rust project, so please let me know if this wasn't the change intended by the linked issue.
## Solution
Adds a test with a system that panics to `bevy_ecs`.
I'm not sure if this is the intended panic message, but this is what the test currently results in:
```
thread 'system::tests::panic_inside_system' panicked at 'called `Option::unwrap()` on a `None` value', /Users/bjorn/workplace/bevy/crates/bevy_tasks/src/task_pool.rs:354:49
```
# Objective
Fix#7447.
The `SystemParam` derive uses the wrong lifetimes for ignored fields.
## Solution
Use type inference instead of explicitly naming the types of ignored fields. This allows the compiler to automatically use the correct lifetime.
# Objective
- Fix panic_when_hierachy_cycle test hanging
- The problem is that the scope only awaits one task at a time in get_results. In stageless this task is the multithreaded executor. That tasks hangs when a system panics and cannot make anymore progress. This wasn't a problem before because the executor was spawned after all the system tasks had been spawned. But in stageless the executor is spawned before all the system tasks are spawned.
## Solution
- We can catch unwind on each system and close the finish channel if one panics. This then causes the receiver end of the finish channel to panic too.
- this might have a small perf impact, but when running many_foxes it seems to be within the noise. So less than 40us.
## Other possible solutions
- It might be possible to fairly poll all the tasks in get_results in the scope. If we could do that then the scope could panic whenever one of tasks panics. It would require a data structure that we could both poll the futures through a shared ref and also push to it. I tried FuturesUnordered, but it requires an exclusive ref to poll it.
- The catch unwind could be moved onto when we create the tasks for scope instead. We would then need something like a oneshot async channel to inform get_results if a task panics.
# Objective
Ability to use `ReflectComponent` methods in dynamic type contexts with no access to `&World`.
This problem occurred to me when wanting to apply reflected types to an entity where the `&World` reference was already consumed by query iterator leaving only `EntityMut`.
## Solution
- Remove redundant `EntityMut` or `EntityRef` lookup from `World` and `Entity` in favor of taking `EntityMut` directly in `ReflectComponentFns`.
- Added `RefectComponent::contains` to determine without panic whether `apply` can be used.
## Changelog
- Changed function signatures of `ReflectComponent` methods, `apply`, `remove`, `contains`, and `reflect`.
## Migration Guide
- Call `World::entity` before calling into the changed `ReflectComponent` methods, most likely user already has a `EntityRef` or `EntityMut` which was being queried redundantly.
# Objective
- Trying to move some of the fixes from https://github.com/bevyengine/bevy/pull/7267 to make that one easier to review
- The MainThreadExecutor is how the render world runs nonsend systems on the main thread for pipelined rendering.
- The multithread executor for stageless wasn't using the MainThreadExecutor.
- MainThreadExecutor was declared in the old executor_parallel module that is getting deleted.
- The way the MainThreadExecutor was getting passed to the scope was actually unsound as the resource could be dropped from the World while the schedule was running
## Solution
- Move MainThreadExecutor to the new multithreaded_executor's file.
- Make the multithreaded executor use the MainThreadExecutor
- Clone the MainThreadExecutor onto the stack and pass that ref in
## Changelog
- Move MainThreadExecutor for stageless migration.
# Objective
- After the multithreaded executor finishes running all the systems, we apply the buffers for any system that hasn't applied it's buffers. This is a courtesy apply for users who forget to order their systems before a apply_system_buffers. When checking stageless, it was found that this apply_system_buffers was running on the executor thread instead of the world's thread. This is a problem because anything with world access should be able to access nonsend resources.
## Solution
- Move the final apply_system_buffers outside of the executor and outside of the scope, so it runs on the same thread that schedule.run is called on.
# Objective
- The stageless executor keeps track of systems that have run, but have not applied their system buffers. The bitset for that was being cloned into apply_system_buffers and cleared in that function, but we need to clear the original version instead of the cloned version
## Solution
- move the clear out of the apply_system_buffers function.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Clearing the reader doesn't require iterating the events. Updating the `last_event_count` of the reader is enough.
I rewrote part of the documentation as some of it was incorrect or harder to understand than necessary.
## Changelog
Added `ManualEventReader::clear()`
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Found while working on #7385.
The struct `EntityMut` has the safety invariant that it's cached `EntityLocation` must always accurately specify where the entity is stored. Thus, any time its location might be invalidated (such as by calling `EntityMut::world_mut` and moving archetypes), the cached location *must* be updated by calling `EntityMut::update_location`.
The method `world_scope` encapsulates this pattern in safe API by requiring world mutations to be done in a closure, after which `update_location` will automatically be called. However, this method has a soundness hole: if a panic occurs within the closure, then `update_location` will never get called. If the panic is caught in an outer scope, then the `EntityMut` will be left with an outdated location, which is undefined behavior.
An example of this can be seen in the unit test `entity_mut_world_scope_panic`, which has been added to this PR as a regression test. Without the other changes in this PR, that test will invoke undefined behavior in safe code.
## Solution
Call `EntityMut::update_location()` from within a `Drop` impl, which ensures that it will get executed even if `EntityMut::world_scope` unwinds.
# Objective
The function `EntityMut::world_scope` is a safe abstraction that allows you to temporarily get mutable access to the underlying `World` of an `EntityMut`. This function is purely stateful, meaning it is not easily possible to return a value from it.
## Solution
Allow returning a computed value from the closure. This is similar to how `World::resource_scope` works.
---
## Changelog
- The function `EntityMut::world_scope` now allows returning a value from the immediately-computed closure.
# Objective
I found several words in code and docs are incorrect. This should be fixed.
## Solution
- Fix several minor typos
Co-authored-by: Chris Ohk <utilforever@gmail.com>
alternative to #5922, implements #5956
builds on top of https://github.com/bevyengine/bevy/pull/6402
# Objective
https://github.com/bevyengine/bevy/issues/5956 goes into more detail, but the TLDR is:
- bevy systems ensure disjoint accesses to resources and components, and for that to work there are methods `World::get_resource_unchecked_mut(&self)`, ..., `EntityRef::get_mut_unchecked(&self)` etc.
- we don't have these unchecked methods for `by_id` variants, so third-party crate authors cannot build their own safe disjoint-access abstractions with these
- having `_unchecked_mut` methods is not great, because in their presence safe code can accidentally violate subtle invariants. Having to go through `world.as_unsafe_world_cell().unsafe_method()` forces you to stop and think about what you want to write in your `// SAFETY` comment.
The alternative is to keep exposing `_unchecked_mut` variants for every operation that we want third-party crates to build upon, but we'd prefer to avoid using these methods alltogether: https://github.com/bevyengine/bevy/pull/5922#issuecomment-1241954543
Also, this is something that **cannot be implemented outside of bevy**, so having either this PR or #5922 as an escape hatch with lots of discouraging comments would be great.
## Solution
- add `UnsafeWorldCell` with `unsafe fn get_resource(&self)`, `unsafe fn get_resource_mut(&self)`
- add `fn World::as_unsafe_world_cell(&mut self) -> UnsafeWorldCell<'_>` (and `as_unsafe_world_cell_readonly(&self)`)
- add `UnsafeWorldCellEntityRef` with `unsafe fn get`, `unsafe fn get_mut` and the other utilities on `EntityRef` (no methods for spawning, despawning, insertion)
- use the `UnsafeWorldCell` abstraction in `ReflectComponent`, `ReflectResource` and `ReflectAsset`, so these APIs are easier to reason about
- remove `World::get_resource_mut_unchecked`, `EntityRef::get_mut_unchecked` and use `unsafe { world.as_unsafe_world_cell().get_mut() }` and `unsafe { world.as_unsafe_world_cell().get_entity(entity)?.get_mut() }` instead
This PR does **not** make use of `UnsafeWorldCell` for anywhere else in `bevy_ecs` such as `SystemParam` or `Query`. That is a much larger change, and I am convinced that having `UnsafeWorldCell` is already useful for third-party crates.
Implemented API:
```rust
struct World { .. }
impl World {
fn as_unsafe_world_cell(&self) -> UnsafeWorldCell<'_>;
}
struct UnsafeWorldCell<'w>(&'w World);
impl<'w> UnsafeWorldCell {
unsafe fn world(&self) -> &World;
fn get_entity(&self) -> UnsafeWorldCellEntityRef<'w>; // returns 'w which is `'self` of the `World::as_unsafe_world_cell(&'w self)`
unsafe fn get_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_resource_by_id(&self, ComponentId) -> Option<&'w T>;
unsafe fn get_resource_mut<T>(&self) -> Option<Mut<'w, T>>;
unsafe fn get_resource_mut_by_id(&self) -> Option<MutUntyped<'w>>;
unsafe fn get_non_send_resource<T>(&self) -> Option<&'w T>;
unsafe fn get_non_send_resource_mut<T>(&self) -> Option<Mut<'w, T>>>;
// not included: remove, remove_resource, despawn, anything that might change archetypes
}
struct UnsafeWorldCellEntityRef<'w> { .. }
impl UnsafeWorldCellEntityRef<'w> {
unsafe fn get<T>(&self, Entity) -> Option<&'w T>;
unsafe fn get_by_id(&self, Entity, ComponentId) -> Option<Ptr<'w>>;
unsafe fn get_mut<T>(&self, Entity) -> Option<Mut<'w, T>>;
unsafe fn get_mut_by_id(&self, Entity, ComponentId) -> Option<MutUntyped<'w>>;
unsafe fn get_change_ticks<T>(&self, Entity) -> Option<Mut<'w, T>>;
// fn id, archetype, contains, contains_id, containts_type_id
}
```
<details>
<summary>UnsafeWorldCell docs</summary>
Variant of the [`World`] where resource and component accesses takes a `&World`, and the responsibility to avoid
aliasing violations are given to the caller instead of being checked at compile-time by rust's unique XOR shared rule.
### Rationale
In rust, having a `&mut World` means that there are absolutely no other references to the safe world alive at the same time,
without exceptions. Not even unsafe code can change this.
But there are situations where careful shared mutable access through a type is possible and safe. For this, rust provides the [`UnsafeCell`](std::cell::UnsafeCell)
escape hatch, which allows you to get a `*mut T` from a `&UnsafeCell<T>` and around which safe abstractions can be built.
Access to resources and components can be done uniquely using [`World::resource_mut`] and [`World::entity_mut`], and shared using [`World::resource`] and [`World::entity`].
These methods use lifetimes to check at compile time that no aliasing rules are being broken.
This alone is not enough to implement bevy systems where multiple systems can access *disjoint* parts of the world concurrently. For this, bevy stores all values of
resources and components (and [`ComponentTicks`](crate::component::ComponentTicks)) in [`UnsafeCell`](std::cell::UnsafeCell)s, and carefully validates disjoint access patterns using
APIs like [`System::component_access`](crate::system::System::component_access).
A system then can be executed using [`System::run_unsafe`](crate::system::System::run_unsafe) with a `&World` and use methods with interior mutability to access resource values.
access resource values.
### Example Usage
[`UnsafeWorldCell`] can be used as a building block for writing APIs that safely allow disjoint access into the world.
In the following example, the world is split into a resource access half and a component access half, where each one can
safely hand out mutable references.
```rust
use bevy_ecs::world::World;
use bevy_ecs::change_detection::Mut;
use bevy_ecs::system::Resource;
use bevy_ecs::world::unsafe_world_cell_world::UnsafeWorldCell;
// INVARIANT: existance of this struct means that users of it are the only ones being able to access resources in the world
struct OnlyResourceAccessWorld<'w>(UnsafeWorldCell<'w>);
// INVARIANT: existance of this struct means that users of it are the only ones being able to access components in the world
struct OnlyComponentAccessWorld<'w>(UnsafeWorldCell<'w>);
impl<'w> OnlyResourceAccessWorld<'w> {
fn get_resource_mut<T: Resource>(&mut self) -> Option<Mut<'w, T>> {
// SAFETY: resource access is allowed through this UnsafeWorldCell
unsafe { self.0.get_resource_mut::<T>() }
}
}
// impl<'w> OnlyComponentAccessWorld<'w> {
// ...
// }
// the two interior mutable worlds borrow from the `&mut World`, so it cannot be accessed while they are live
fn split_world_access(world: &mut World) -> (OnlyResourceAccessWorld<'_>, OnlyComponentAccessWorld<'_>) {
let resource_access = OnlyResourceAccessWorld(unsafe { world.as_unsafe_world_cell() });
let component_access = OnlyComponentAccessWorld(unsafe { world.as_unsafe_world_cell() });
(resource_access, component_access)
}
```
</details>
# Objective
`add_system(system)` without any `.in_set` configuration should land in `CoreSet::Update`.
We check that the sets are empty, but for systems there is always the `SystemTypeset`.
## Solution
- instead of `is_empty()`, check that the only set it the `SystemTypeSet`
# Objective
`bevy_ecs/system_param.rs` contains many seemingly-arbitrary struct definitions which serve as compile tests.
## Solution
Add a comment to each one, linking the issue or PR that motivated its addition.
# Objective
- `Components::resource_id` doesn't exist. Like `Components::component_id` but for resources.
## Solution
- Created `Components::resource_id` and added some docs.
---
## Changelog
- Added `Components::resource_id`.
- Changed `World::init_resource` to return the generated `ComponentId`.
- Changed `World::init_non_send_resource` to return the generated `ComponentId`.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
- Safety comments for the `CommandQueue` type are quite sparse and very imprecise. Sometimes, they are right for the wrong reasons or use circular reasoning.
## Solution
- Document previously-implicit safety invariants.
- Rewrite safety comments to actually reflect the specific invariants of each operation.
- Use `OwningPtr` instead of raw pointers, to encode an invariant in the type system instead of via comments.
- Use typed pointer methods when possible to increase reliability.
---
## Changelog
+ Added the function `OwningPtr::read_unaligned`.
# Objective
Repeated calls to `init_non_send_resource` currently overwrite the old value because the wrong storage is being checked.
## Solution
Use the correct storage. Add some tests.
## Notes
Without the fix, the new test fails with
```
thread 'world::tests::init_non_send_resource_does_not_overwrite' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `0`', crates/bevy_ecs/src/world/mod.rs:2267:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test world::tests::init_non_send_resource_does_not_overwrite ... FAILED
```
This was introduced by #7174 and it seems like a fairly straightforward oopsie.
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
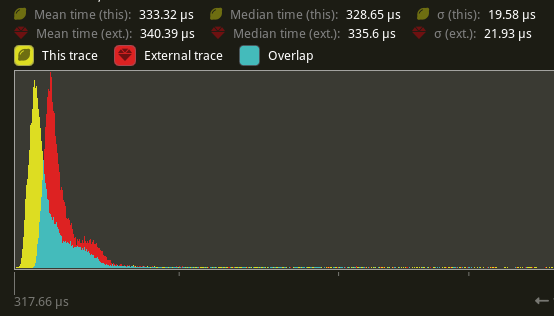
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
## Performance
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
# Objective
- Fixes#3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes#7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
{kind=link}
{kind=link}
{kind=link}