Conceptually, bins are ordered hash maps. We currently implement these
as a list of keys with an associated hash map. But we already have a
data type that implements ordered hash maps directly: `IndexMap`. This
patch switches Bevy to use `IndexMap`s for bins. Because we're memory
bound, this doesn't affect performance much, but it is cleaner.
* Use texture atomics rather than buffer atomics for the visbuffer
(haven't tested perf on a raster-heavy scene yet)
* Unfortunately to clear the visbuffer we now need a compute pass to
clear it. Using wgpu's clear_texture function internally uses a buffer
-> image copy that's insanely expensive. Ideally it should be using
vkCmdClearColorImage, which I've opened an issue for
https://github.com/gfx-rs/wgpu/issues/7090. For now we'll have to stick
with a custom compute pass and all the extra code that brings.
* Faster resolve depth pass by discarding 0 depth pixels instead of
redundantly writing zero (2x faster for big depth textures like shadow
views)
# Objective
https://github.com/bevyengine/bevy/issues/17746
## Solution
- Change `Image.data` from being a `Vec<u8>` to a `Option<Vec<u8>>`
- Added functions to help with creating images
## Testing
- Did you test these changes? If so, how?
All current tests pass
Tested a variety of existing examples to make sure they don't crash
(they don't)
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
Linux x86 64-bit NixOS
---
## Migration Guide
Code that directly access `Image` data will now need to use unwrap or
handle the case where no data is provided.
Behaviour of new_fill slightly changed, but not in a way that is likely
to affect anything. It no longer panics and will fill the whole texture
instead of leaving black pixels if the data provided is not a nice
factor of the size of the image.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
- publish script copy the license files to all subcrates, meaning that
all publish are dirty. this breaks git verification of crates
- the order and list of crates to publish is manually maintained,
leading to error. cargo 1.84 is more strict and the list is currently
wrong
## Solution
- duplicate all the licenses to all crates and remove the
`--allow-dirty` flag
- instead of a manual list of crates, get it from `cargo package
--workspace`
- remove the `--no-verify` flag to... verify more things?
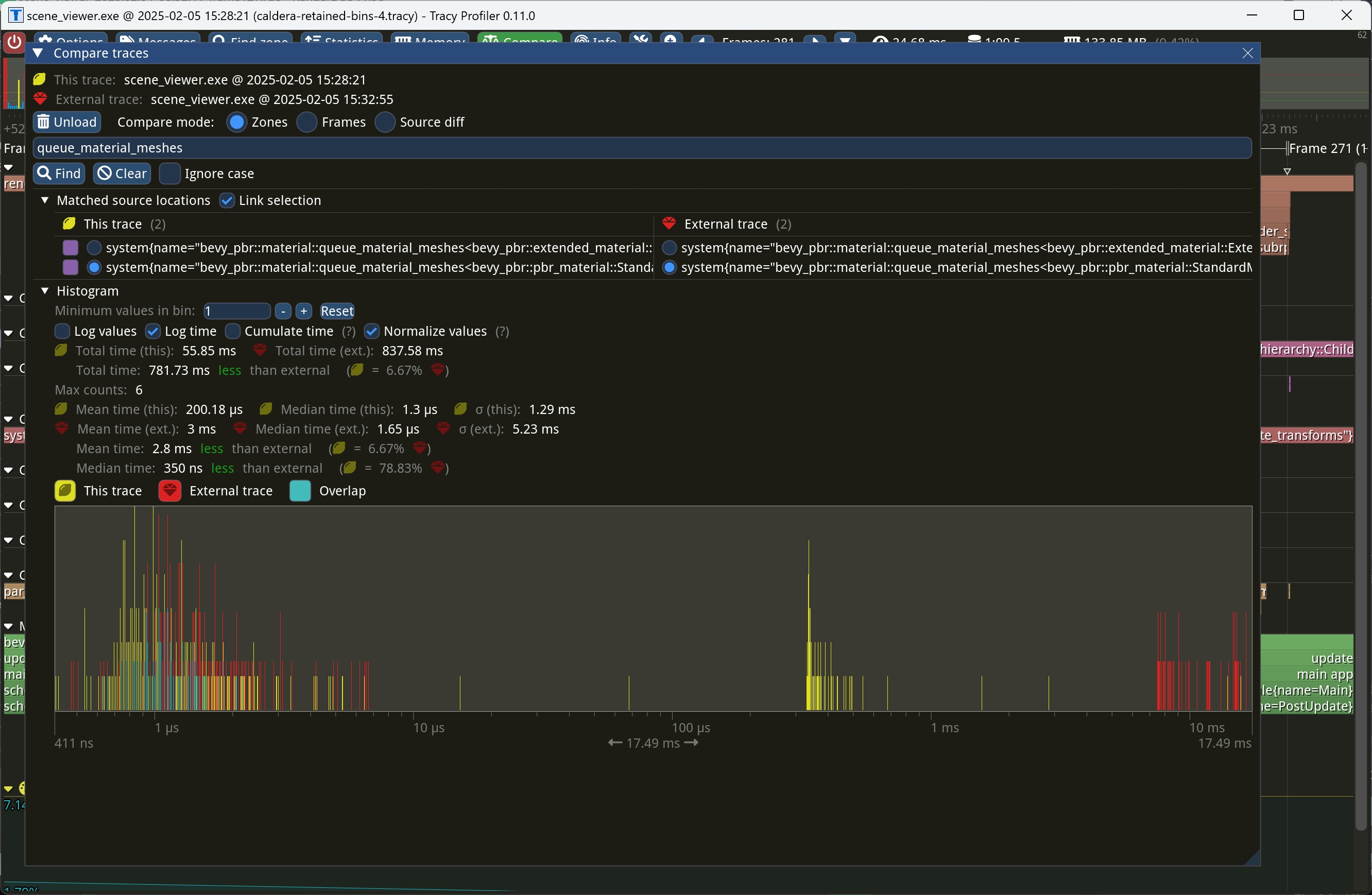
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
# Objective
- Make use of the new `weak_handle!` macro added in
https://github.com/bevyengine/bevy/pull/17384
## Solution
- Migrate bevy from `Handle::weak_from_u128` to the new `weak_handle!`
macro that takes a random UUID
- Deprecate `Handle::weak_from_u128`, since there are no remaining use
cases that can't also be addressed by constructing the type manually
## Testing
- `cargo run -p ci -- test`
---
## Migration Guide
Replace `Handle::weak_from_u128` with `weak_handle!` and a random UUID.
# Objective
- Fixes#17411
## Solution
- Deprecated `Component::register_component_hooks`
- Added individual methods for each hook which return `None` if the hook
is unused.
## Testing
- CI
---
## Migration Guide
`Component::register_component_hooks` is now deprecated and will be
removed in a future release. When implementing `Component` manually,
also implement the respective hook methods on `Component`.
```rust
// Before
impl Component for Foo {
// snip
fn register_component_hooks(hooks: &mut ComponentHooks) {
hooks.on_add(foo_on_add);
}
}
// After
impl Component for Foo {
// snip
fn on_add() -> Option<ComponentHook> {
Some(foo_on_add)
}
}
```
## Notes
I've chosen to deprecate `Component::register_component_hooks` rather
than outright remove it to ease the migration guide. While it is in a
state of deprecation, it must be used by
`Components::register_component_internal` to ensure users who haven't
migrated to the new hook definition scheme aren't left behind. For users
of the new scheme, a default implementation of
`Component::register_component_hooks` is provided which forwards the new
individual hook implementations.
Personally, I think this is a cleaner API to work with, and would allow
the documentation for hooks to exist on the respective `Component`
methods (e.g., documentation for `OnAdd` can exist on
`Component::on_add`). Ideally, `Component::on_add` would be the hook
itself rather than a getter for the hook, but it is the only way to
early-out for a no-op hook, which is important for performance.
## Migration Guide
`Component::register_component_hooks` has been deprecated. If you are
manually implementing the `Component` trait and registering hooks there,
use the individual methods such as `on_add` instead for increased
clarity.
# Objective
Fixes#16628
## Solution
Matrices were being applied in the wrong order.
## Testing
Ran `skybox` example with rotations applied to the `Skybox` on the `x`,
`y`, and `z` axis (one at a time).
e.g.
```rust
Skybox {
image: skybox_handle.clone(),
brightness: 1000.0,
rotation: Quat::from_rotation_y(-45.0_f32.to_radians()),
}
```
## Showcase
[Screencast_20250121_151232.webm](https://github.com/user-attachments/assets/3df68714-f5f1-4d8c-8e08-cbab525a8bda)
*Occlusion culling* allows the GPU to skip the vertex and fragment
shading overhead for objects that can be quickly proved to be invisible
because they're behind other geometry. A depth prepass already
eliminates most fragment shading overhead for occluded objects, but the
vertex shading overhead, as well as the cost of testing and rejecting
fragments against the Z-buffer, is presently unavoidable for standard
meshes. We currently perform occlusion culling only for meshlets. But
other meshes, such as skinned meshes, can benefit from occlusion culling
too in order to avoid the transform and skinning overhead for unseen
meshes.
This commit adapts the same [*two-phase occlusion culling*] technique
that meshlets use to Bevy's standard 3D mesh pipeline when the new
`OcclusionCulling` component, as well as the `DepthPrepass` component,
are present on the camera. It has these steps:
1. *Early depth prepass*: We use the hierarchical Z-buffer from the
previous frame to cull meshes for the initial depth prepass, effectively
rendering only the meshes that were visible in the last frame.
2. *Early depth downsample*: We downsample the depth buffer to create
another hierarchical Z-buffer, this time with the current view
transform.
3. *Late depth prepass*: We use the new hierarchical Z-buffer to test
all meshes that weren't rendered in the early depth prepass. Any meshes
that pass this check are rendered.
4. *Late depth downsample*: Again, we downsample the depth buffer to
create a hierarchical Z-buffer in preparation for the early depth
prepass of the next frame. This step is done after all the rendering, in
order to account for custom phase items that might write to the depth
buffer.
Note that this patch has no effect on the per-mesh CPU overhead for
occluded objects, which remains high for a GPU-driven renderer due to
the lack of `cold-specialization` and retained bins. If
`cold-specialization` and retained bins weren't on the horizon, then a
more traditional approach like potentially visible sets (PVS) or low-res
CPU rendering would probably be more efficient than the GPU-driven
approach that this patch implements for most scenes. However, at this
point the amount of effort required to implement a PVS baking tool or a
low-res CPU renderer would probably be greater than landing
`cold-specialization` and retained bins, and the GPU driven approach is
the more modern one anyway. It does mean that the performance
improvements from occlusion culling as implemented in this patch *today*
are likely to be limited, because of the high CPU overhead for occluded
meshes.
Note also that this patch currently doesn't implement occlusion culling
for 2D objects or shadow maps. Those can be addressed in a follow-up.
Additionally, note that the techniques in this patch require compute
shaders, which excludes support for WebGL 2.
This PR is marked experimental because of known precision issues with
the downsampling approach when applied to non-power-of-two framebuffer
sizes (i.e. most of them). These precision issues can, in rare cases,
cause objects to be judged occluded that in fact are not. (I've never
seen this in practice, but I know it's possible; it tends to be likelier
to happen with small meshes.) As a follow-up to this patch, we desire to
switch to the [SPD-based hi-Z buffer shader from the Granite engine],
which doesn't suffer from these problems, at which point we should be
able to graduate this feature from experimental status. I opted not to
include that rewrite in this patch for two reasons: (1) @JMS55 is
planning on doing the rewrite to coincide with the new availability of
image atomic operations in Naga; (2) to reduce the scope of this patch.
A new example, `occlusion_culling`, has been added. It demonstrates
objects becoming quickly occluded and disoccluded by dynamic geometry
and shows the number of objects that are actually being rendered. Also,
a new `--occlusion-culling` switch has been added to `scene_viewer`, in
order to make it easy to test this patch with large scenes like Bistro.
[*two-phase occlusion culling*]:
https://medium.com/@mil_kru/two-pass-occlusion-culling-4100edcad501
[Aaltonen SIGGRAPH 2015]:
https://www.advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf
[Some literature]:
https://gist.github.com/reduz/c5769d0e705d8ab7ac187d63be0099b5?permalink_comment_id=5040452#gistcomment-5040452
[SPD-based hi-Z buffer shader from the Granite engine]:
https://github.com/Themaister/Granite/blob/master/assets/shaders/post/hiz.comp
## Migration guide
* When enqueuing a custom mesh pipeline, work item buffers are now
created with
`bevy::render::batching::gpu_preprocessing::get_or_create_work_item_buffer`,
not `PreprocessWorkItemBuffers::new`. See the
`specialized_mesh_pipeline` example.
## Showcase
Occlusion culling example:

Bistro zoomed out, before occlusion culling:

Bistro zoomed out, after occlusion culling:

In this scene, occlusion culling reduces the number of meshes Bevy has
to render from 1591 to 585.
# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
# Objective
- Make the function signature for `ComponentHook` less verbose
## Solution
- Refactored `Entity`, `ComponentId`, and `Option<&Location>` into a new
`HookContext` struct.
## Testing
- CI
---
## Migration Guide
Update the function signatures for your component hooks to only take 2
arguments, `world` and `context`. Note that because `HookContext` is
plain data with all members public, you can use de-structuring to
simplify migration.
```rust
// Before
fn my_hook(
mut world: DeferredWorld,
entity: Entity,
component_id: ComponentId,
) { ... }
// After
fn my_hook(
mut world: DeferredWorld,
HookContext { entity, component_id, caller }: HookContext,
) { ... }
```
Likewise, if you were discarding certain parameters, you can use `..` in
the de-structuring:
```rust
// Before
fn my_hook(
mut world: DeferredWorld,
entity: Entity,
_: ComponentId,
) { ... }
// After
fn my_hook(
mut world: DeferredWorld,
HookContext { entity, .. }: HookContext,
) { ... }
```
# Objective
Fixes#14708
Also fixes some commands not updating tracked location.
## Solution
`ObserverTrigger` has a new `caller` field with the
`track_change_detection` feature;
hooks take an additional caller parameter (which is `Some(…)` or `None`
depending on the feature).
## Testing
See the new tests in `src/observer/mod.rs`
---
## Showcase
Observers now know from where they were triggered (if
`track_change_detection` is enabled):
```rust
world.observe(move |trigger: Trigger<OnAdd, Foo>| {
println!("Added Foo from {}", trigger.caller());
});
```
## Migration
- hooks now take an additional `Option<&'static Location>` argument
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
`bevy_ecs`'s `system` module is something of a grab bag, and *very*
large. This is particularly true for the `system_param` module, which is
more than 2k lines long!
While it could be defensible to put `Res` and `ResMut` there (lol no
they're in change_detection.rs, obviously), it doesn't make any sense to
put the `Resource` trait there. This is confusing to navigate (and
painful to work on and review).
## Solution
- Create a root level `bevy_ecs/resource.rs` module to mirror
`bevy_ecs/component.rs`
- move the `Resource` trait to that module
- move the `Resource` derive macro to that module as well (Rust really
likes when you pun on the names of the derive macro and trait and put
them in the same path)
- fix all of the imports
## Notes to reviewers
- We could probably move more stuff into here, but I wanted to keep this
PR as small as possible given the absurd level of import changes.
- This PR is ground work for my upcoming attempts to store resource data
on components (resources-as-entities). Splitting this code out will make
the work and review a bit easier, and is the sort of overdue refactor
that's good to do as part of more meaningful work.
## Testing
cargo build works!
## Migration Guide
`bevy_ecs::system::Resource` has been moved to
`bevy_ecs::resource::Resource`.
# Objective
The existing `RelationshipSourceCollection` uses `Vec` as the only
possible backing for our relationships. While a reasonable choice,
benchmarking use cases might reveal that a different data type is better
or faster.
For example:
- Not all relationships require a stable ordering between the
relationship sources (i.e. children). In cases where we a) have many
such relations and b) don't care about the ordering between them, a hash
set is likely a better datastructure than a `Vec`.
- The number of children-like entities may be small on average, and a
`smallvec` may be faster
## Solution
- Implement `RelationshipSourceCollection` for `EntityHashSet`, our
custom entity-optimized `HashSet`.
-~~Implement `DoubleEndedIterator` for `EntityHashSet` to make things
compile.~~
- This implementation was cursed and very surprising.
- Instead, by moving the iterator type on `RelationshipSourceCollection`
from an erased RPTIT to an explicit associated type we can add a trait
bound on the offending methods!
- Implement `RelationshipSourceCollection` for `SmallVec`
## Testing
I've added a pair of new tests to make sure this pattern compiles
successfully in practice!
## Migration Guide
`EntityHashSet` and `EntityHashMap` are no longer re-exported in
`bevy_ecs::entity` directly. If you were not using `bevy_ecs` / `bevy`'s
`prelude`, you can access them through their now-public modules,
`hash_set` and `hash_map` instead.
## Notes to reviewers
The `EntityHashSet::Iter` type needs to be public for this impl to be
allowed. I initially renamed it to something that wasn't ambiguous and
re-exported it, but as @Victoronz pointed out, that was somewhat
unidiomatic.
In
1a8564898f,
I instead made the `entity_hash_set` public (and its `entity_hash_set`)
sister public, and removed the re-export. I prefer this design (give me
module docs please), but it leads to a lot of churn in this PR.
Let me know which you'd prefer, and if you'd like me to split that
change out into its own micro PR.
# Objective
- Contributes to #16877
## Solution
- Initial creation of `bevy_platform_support` crate.
- Moved `bevy_utils::Instant` into new `bevy_platform_support` crate.
- Moved `portable-atomic`, `portable-atomic-util`, and
`critical-section` into new `bevy_platform_support` crate.
## Testing
- CI
---
## Showcase
Instead of needing code like this to import an `Arc`:
```rust
#[cfg(feature = "portable-atomic")]
use portable_atomic_util::Arc;
#[cfg(not(feature = "portable-atomic"))]
use alloc::sync::Arc;
```
We can now use:
```rust
use bevy_platform_support::sync::Arc;
```
This applies to many other types, but the goal is overall the same:
allowing crates to use `std`-like types without the boilerplate of
conditional compilation and platform-dependencies.
## Migration Guide
- Replace imports of `bevy_utils::Instant` with
`bevy_platform_support::time::Instant`
- Replace imports of `bevy::utils::Instant` with
`bevy::platform_support::time::Instant`
## Notes
- `bevy_platform_support` hasn't been reserved on `crates.io`
- ~~`bevy_platform_support` is not re-exported from `bevy` at this time.
It may be worthwhile exporting this crate, but I am unsure of a
reasonable name to export it under (`platform_support` may be a bit
wordy for user-facing).~~
- I've included an implementation of `Instant` which is suitable for
`no_std` platforms that are not Wasm for the sake of eliminating feature
gates around its use. It may be a controversial inclusion, so I'm happy
to remove it if required.
- There are many other items (`spin`, `bevy_utils::Sync(Unsafe)Cell`,
etc.) which should be added to this crate. I have kept the initial scope
small to demonstrate utility without making this too unwieldy.
---------
Co-authored-by: TimJentzsch <TimJentzsch@users.noreply.github.com>
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/17111
## Solution
Move `#![warn(clippy::allow_attributes,
clippy::allow_attributes_without_reason)]` to the workspace `Cargo.toml`
## Testing
Lots of CI testing, and local testing too.
---------
Co-authored-by: Benjamin Brienen <benjamin.brienen@outlook.com>
# Objective
- https://github.com/bevyengine/bevy/issues/17111
## Solution
Set the `clippy::allow_attributes` and
`clippy::allow_attributes_without_reason` lints to `warn`, and bring
`bevy_core_pipeline` in line with the new restrictions.
## Testing
`cargo clippy` and `cargo test --package bevy_core_pipeline` were run,
and no warnings were encountered.
This commit allows Bevy to use `multi_draw_indirect_count` for drawing
meshes. The `multi_draw_indirect_count` feature works just like
`multi_draw_indirect`, but it takes the number of indirect parameters
from a GPU buffer rather than specifying it on the CPU.
Currently, the CPU constructs the list of indirect draw parameters with
the instance count for each batch set to zero, uploads the resulting
buffer to the GPU, and dispatches a compute shader that bumps the
instance count for each mesh that survives culling. Unfortunately, this
is inefficient when we support `multi_draw_indirect_count`. Draw
commands corresponding to meshes for which all instances were culled
will remain present in the list when calling
`multi_draw_indirect_count`, causing overhead. Proper use of
`multi_draw_indirect_count` requires eliminating these empty draw
commands.
To address this inefficiency, this PR makes Bevy fully construct the
indirect draw commands on the GPU instead of on the CPU. Instead of
writing instance counts to the draw command buffer, the mesh
preprocessing shader now writes them to a separate *indirect metadata
buffer*. A second compute dispatch known as the *build indirect
parameters* shader runs after mesh preprocessing and converts the
indirect draw metadata into actual indirect draw commands for the GPU.
The build indirect parameters shader operates on a batch at a time,
rather than an instance at a time, and as such each thread writes only 0
or 1 indirect draw parameters, simplifying the current logic in
`mesh_preprocessing`, which currently has to have special cases for the
first mesh in each batch. The build indirect parameters shader emits
draw commands in a tightly packed manner, enabling maximally efficient
use of `multi_draw_indirect_count`.
Along the way, this patch switches mesh preprocessing to dispatch one
compute invocation per render phase per view, instead of dispatching one
compute invocation per view. This is preparation for two-phase occlusion
culling, in which we will have two mesh preprocessing stages. In that
scenario, the first mesh preprocessing stage must only process opaque
and alpha tested objects, so the work items must be separated into those
that are opaque or alpha tested and those that aren't. Thus this PR
splits out the work items into a separate buffer for each phase. As this
patch rewrites so much of the mesh preprocessing infrastructure, it was
simpler to just fold the change into this patch instead of deferring it
to the forthcoming occlusion culling PR.
Finally, this patch changes mesh preprocessing so that it runs
separately for indexed and non-indexed meshes. This is because draw
commands for indexed and non-indexed meshes have different sizes and
layouts. *The existing code is actually broken for non-indexed meshes*,
as it attempts to overlay the indirect parameters for non-indexed meshes
on top of those for indexed meshes. Consequently, right now the
parameters will be read incorrectly when multiple non-indexed meshes are
multi-drawn together. *This is a bug fix* and, as with the change to
dispatch phases separately noted above, was easiest to include in this
patch as opposed to separately.
## Migration Guide
* Systems that add custom phase items now need to populate the indirect
drawing-related buffers. See the `specialized_mesh_pipeline` example for
an example of how this is done.
We won't be able to retain render phases from frame to frame if the keys
are unstable. It's not as simple as simply keying off the main world
entity, however, because some main world entities extract to multiple
render world entities. For example, directional lights extract to
multiple shadow cascades, and point lights extract to one view per
cubemap face. Therefore, we key off a new type, `RetainedViewEntity`,
which contains the main entity plus a *subview ID*.
This is part of the preparation for retained bins.
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
Stumbled upon a `from <-> form` transposition while reviewing a PR,
thought it was interesting, and went down a bit of a rabbit hole.
## Solution
Fix em
# Objective
Many instances of `clippy::too_many_arguments` linting happen to be on
systems - functions which we don't call manually, and thus there's not
much reason to worry about the argument count.
## Solution
Allow `clippy::too_many_arguments` globally, and remove all lint
attributes related to it.
# Objective
I never realized `clippy::type_complexity` was an allowed lint - I've
been assuming it'd generate a warning when performing my linting PRs.
## Solution
Removes any instances of `#[allow(clippy::type_complexity)]` and
`#[expect(clippy::type_complexity)]`
## Testing
`cargo clippy` ran without errors or warnings.
# Objective
https://github.com/bevyengine/bevy/pull/16338 forgot to remove this
previously-deprecated item. In fact, it only removed the `#[deprecated]`
attribute attached to it.
## Solution
Removes `bevy_core_pipeline::core_2d::Camera2dBundle`.
## Testing
CI.
Currently, our batchable binned items are stored in a hash table that
maps bin key, which includes the batch set key, to a list of entities.
Multidraw is handled by sorting the bin keys and accumulating adjacent
bins that can be multidrawn together (i.e. have the same batch set key)
into multidraw commands during `batch_and_prepare_binned_render_phase`.
This is reasonably efficient right now, but it will complicate future
work to retain indirect draw parameters from frame to frame. Consider
what must happen when we have retained indirect draw parameters and the
application adds a bin (i.e. a new mesh) that shares a batch set key
with some pre-existing meshes. (That is, the new mesh can be multidrawn
with the pre-existing meshes.) To be maximally efficient, our goal in
that scenario will be to update *only* the indirect draw parameters for
the batch set (i.e. multidraw command) containing the mesh that was
added, while leaving the others alone. That means that we have to
quickly locate all the bins that belong to the batch set being modified.
In the existing code, we would have to sort the list of bin keys so that
bins that can be multidrawn together become adjacent to one another in
the list. Then we would have to do a binary search through the sorted
list to find the location of the bin that was just added. Next, we would
have to widen our search to adjacent indexes that contain the same batch
set, doing expensive comparisons against the batch set key every time.
Finally, we would reallocate the indirect draw parameters and update the
stored pointers to the indirect draw parameters that the bins store.
By contrast, it'd be dramatically simpler if we simply changed the way
bins are stored to first map from batch set key (i.e. multidraw command)
to the bins (i.e. meshes) within that batch set key, and then from each
individual bin to the mesh instances. That way, the scenario above in
which we add a new mesh will be simpler to handle. First, we will look
up the batch set key corresponding to that mesh in the outer map to find
an inner map corresponding to the single multidraw command that will
draw that batch set. We will know how many meshes the multidraw command
is going to draw by the size of that inner map. Then we simply need to
reallocate the indirect draw parameters and update the pointers to those
parameters within the bins as necessary. There will be no need to do any
binary search or expensive batch set key comparison: only a single hash
lookup and an iteration over the inner map to update the pointers.
This patch implements the above technique. Because we don't have
retained bins yet, this PR provides no performance benefits. However, it
opens the door to maximally efficient updates when only a small number
of meshes change from frame to frame.
The main churn that this patch causes is that the *batch set key* (which
uniquely specifies a multidraw command) and *bin key* (which uniquely
specifies a mesh *within* that multidraw command) are now separate,
instead of the batch set key being embedded *within* the bin key.
In order to isolate potential regressions, I think that at least #16890,
#16836, and #16825 should land before this PR does.
## Migration Guide
* The *batch set key* is now separate from the *bin key* in
`BinnedPhaseItem`. The batch set key is used to collect multidrawable
meshes together. If you aren't using the multidraw feature, you can
safely set the batch set key to `()`.
Bump version after release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
# Objective
- Contributes to #11478
## Solution
- Made `bevy_utils::tracing` `doc(hidden)`
- Re-exported `tracing` from `bevy_log` for end-users
- Added `tracing` directly to crates that need it.
## Testing
- CI
---
## Migration Guide
If you were importing `tracing` via `bevy::utils::tracing`, instead use
`bevy::log::tracing`. Note that many items within `tracing` are also
directly re-exported from `bevy::log` as well, so you may only need
`bevy::log` for the most common items (e.g., `warn!`, `trace!`, etc.).
This also applies to the `log_once!` family of macros.
## Notes
- While this doesn't reduce the line-count in `bevy_utils`, it further
decouples the internal crates from `bevy_utils`, making its eventual
removal more feasible in the future.
- I have just imported `tracing` as we do for all dependencies. However,
a workspace dependency may be more appropriate for version management.
# Objective
Use the latest version of `typos` and fix the typos that it now detects
# Additional Info
By the way, `typos` has a "low priority typo suggestions issue" where we
can throw typos we find that `typos` doesn't catch.
(This link may go stale) https://github.com/crate-ci/typos/issues/1200
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/16556
- Closes https://github.com/bevyengine/bevy/issues/11807
## Solution
- Simplify custom projections by using a single source of truth -
`Projection`, removing all existing generic systems and types.
- Existing perspective and orthographic structs are no longer components
- I could dissolve these to simplify further, but keeping them around
was the fast way to implement this.
- Instead of generics, introduce a third variant, with a trait object.
- Do an object safety dance with an intermediate trait to allow cloning
boxed camera projections. This is a normal rust polymorphism papercut.
You can do this with a crate but a manual impl is short and sweet.
## Testing
- Added a custom projection example
---
## Showcase
- Custom projections and projection handling has been simplified.
- Projection systems are no longer generic, with the potential for many
different projection components on the same camera.
- Instead `Projection` is now the single source of truth for camera
projections, and is the only projection component.
- Custom projections are still supported, and can be constructed with
`Projection::custom()`.
## Migration Guide
- `PerspectiveProjection` and `OrthographicProjection` are no longer
components. Use `Projection` instead.
- Custom projections should no longer be inserted as a component.
Instead, simply set the custom projection as a value of `Projection`
with `Projection::custom()`.
A previous PR, #14599, attempted to enable lightmaps in deferred mode,
but it still used the `OpaqueNoLightmap3dBinKey`, which meant that it
would be broken if multiple lightmaps were used. This commit fixes that
issue, and allows bindless lightmaps to work with deferred rendering as
well.
# Objective
- Fixes#16892
## Solution
- Removed `TypeRegistryPlugin` (`Name` is now automatically registered
with a default `App`)
- Moved `TaskPoolPlugin` to `bevy_app`
- Moved `FrameCountPlugin` to `bevy_diagnostic`
- Deleted now-empty `bevy_core`
## Testing
- CI
## Migration Guide
- `TypeRegistryPlugin` no longer exists. If you can't use a default
`App` but still need `Name` registered, do so manually with
`app.register_type::<Name>()`.
- References to `TaskPoolPlugin` and associated types will need to
import it from `bevy_app` instead of `bevy_core`
- References to `FrameCountPlugin` and associated types will need to
import it from `bevy_diagnostic` instead of `bevy_core`
## Notes
This strategy was agreed upon by Cart and several other members in
[Discord](https://discord.com/channels/691052431525675048/692572690833473578/1319137218312278077).
This commit allows Bevy to bind 16 lightmaps at a time, if the current
platform supports bindless textures. Naturally, if bindless textures
aren't supported, Bevy falls back to binding only a single lightmap at a
time. As lightmaps are usually heavily atlased, I doubt many scenes will
use more than 16 lightmap textures.
This has little performance impact now, but it's desirable for us to
reap the benefits of multidraw and bindless textures on scenes that use
lightmaps. Otherwise, we might have to break batches in order to switch
those lightmaps.
Additionally, this PR slightly reduces the cost of binning because it
makes the lightmap index in `Opaque3dBinKey` 32 bits instead of an
`AssetId`.
## Migration Guide
* The `Opaque3dBinKey::lightmap_image` field is now
`Opaque3dBinKey::lightmap_slab`, which is a lightweight identifier for
an entire binding array of lightmaps.
# Objective
We were waiting for 1.83 to address most of these, due to a bug with
`missing_docs` and `expect`. Relates to, but does not entirely complete,
#15059.
## Solution
- Upgrade to 1.83
- Switch `allow(missing_docs)` to `expect(missing_docs)`
- Remove a few now-unused `allow`s along the way, or convert to `expect`
This patch replaces the undocumented `NoGpuCulling` component with a new
component, `NoIndirectDrawing`, effectively turning indirect drawing on
by default. Indirect mode is needed for the recently-landed multidraw
feature (#16427). Since multidraw is such a win for performance, when
that feature is supported the small performance tax that indirect mode
incurs is virtually always worth paying.
To ensure that custom drawing code such as that in the
`custom_shader_instancing` example continues to function, this commit
additionally makes GPU culling take the `NoFrustumCulling` component
into account.
This PR is an alternative to #16670 that doesn't break the
`custom_shader_instancing` example. **PR #16755 should land first in
order to avoid breaking deferred rendering, as multidraw currently
breaks it**.
## Migration Guide
* Indirect drawing (GPU culling) is now enabled by default, so the
`GpuCulling` component is no longer available. To disable indirect mode,
which may be useful with custom render nodes, add the new
`NoIndirectDrawing` component to your camera.
This commit resolves most of the failures seen in #16670. It contains
two major fixes:
1. The prepass shaders weren't updated for bindless mode, so they were
accessing `material` as a single element instead of as an array. I added
the needed `BINDLESS` check.
2. If the mesh didn't support batch set keys (i.e. `get_batch_set_key()`
returns `None`), and multidraw was enabled, the batching logic would try
to multidraw all the meshes in a bin together instead of disabling
multidraw. This is because we checked whether the `Option<BatchSetKey>`
for the previous batch was equal to the `Option<BatchSetKey>` for the
next batch to determine whether objects could be multidrawn together,
which would return true if batch set keys were absent, causing an entire
bin to be multidrawn together. This patch fixes the logic so that
multidraw is only enabled if the batch set keys match *and are `Some`*.
Additionally, this commit adds batch key support for bins that use
`Opaque3dNoLightmapBinKey`, which in practice means prepasses.
Consequently, this patch enables multidraw for the prepass when GPU
culling is enabled.
When testing this patch, try adding `GpuCulling` to the camera in the
`deferred_rendering` and `ssr` examples. You can see that these examples
break without this patch and work properly with it.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Updating dependencies; adopted version of #15696. (Supercedes #15696.)
Long answer: hashbrown is no longer using ahash by default, meaning that
we can't use the default-hasher methods with ahasher. So, we have to use
the longer-winded versions instead. This takes the opportunity to also
switch our default hasher as well, but without actually enabling the
default-hasher feature for hashbrown, meaning that we'll be able to
change our hasher more easily at the cost of all of these method calls
being obnoxious forever.
One large change from 0.15 is that `insert_unique_unchecked` is now
`unsafe`, and for cases where unsafe code was denied at the crate level,
I replaced it with `insert`.
## Migration Guide
`bevy_utils` has updated its version of `hashbrown` to 0.15 and now
defaults to `foldhash` instead of `ahash`. This means that if you've
hard-coded your hasher to `bevy_utils::AHasher` or separately used the
`ahash` crate in your code, you may need to switch to `foldhash` to
ensure that everything works like it does in Bevy.
# Objective
Fixes typos in bevy project, following suggestion in
https://github.com/bevyengine/bevy-website/pull/1912#pullrequestreview-2483499337
## Solution
I used https://github.com/crate-ci/typos to find them.
I included only the ones that feel undebatable too me, but I am not in
game engine so maybe some terms are expected.
I left out the following typos:
- `reparametrize` => `reparameterize`: There are a lot of occurences, I
believe this was expected
- `semicircles` => `hemicircles`: 2 occurences, may mean something
specific in geometry
- `invertation` => `inversion`: may mean something specific
- `unparented` => `parentless`: may mean something specific
- `metalness` => `metallicity`: may mean something specific
## Testing
- Did you test these changes? If so, how? I did not test the changes,
most changes are related to raw text. I expect the others to be tested
by the CI.
- Are there any parts that need more testing? I do not think
- How can other people (reviewers) test your changes? Is there anything
specific they need to know? To me there is nothing to test
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
---
## Migration Guide
> This section is optional. If there are no breaking changes, you can
delete this section.
(kept in case I include the `reparameterize` change here)
- If this PR is a breaking change (relative to the last release of
Bevy), describe how a user might need to migrate their code to support
these changes
- Simply adding new functionality is not a breaking change.
- Fixing behavior that was definitely a bug, rather than a questionable
design choice is not a breaking change.
## Questions
- [x] Should I include the above typos? No
(https://github.com/bevyengine/bevy/pull/16702#issuecomment-2525271152)
- [ ] Should I add `typos` to the CI? (I will check how to configure it
properly)
This project looks awesome, I really enjoy reading the progress made,
thanks to everyone involved.
This commit adds support for *multidraw*, which is a feature that allows
multiple meshes to be drawn in a single drawcall. `wgpu` currently
implements multidraw on Vulkan, so this feature is only enabled there.
Multiple meshes can be drawn at once if they're in the same vertex and
index buffers and are otherwise placed in the same bin. (Thus, for
example, at present the materials and textures must be identical, but
see #16368.) Multidraw is a significant performance improvement during
the draw phase because it reduces the number of rebindings, as well as
the number of drawcalls.
This feature is currently only enabled when GPU culling is used: i.e.
when `GpuCulling` is present on a camera. Therefore, if you run for
example `scene_viewer`, you will not see any performance improvements,
because `scene_viewer` doesn't add the `GpuCulling` component to its
camera.
Additionally, the multidraw feature is only implemented for opaque 3D
meshes and not for shadows or 2D meshes. I plan to make GPU culling the
default and to extend the feature to shadows in the future. Also, in the
future I suspect that polyfilling multidraw on APIs that don't support
it will be fruitful, as even without driver-level support use of
multidraw allows us to avoid expensive `wgpu` rebindings.
# Objective
- Remove `derive_more`'s error derivation and replace it with
`thiserror`
## Solution
- Added `derive_more`'s `error` feature to `deny.toml` to prevent it
sneaking back in.
- Reverted to `thiserror` error derivation
## Notes
Merge conflicts were too numerous to revert the individual changes, so
this reversion was done manually. Please scrutinise carefully during
review.
# Objective
- Fixes#16208
## Solution
- Added an associated type to `Component`, `Mutability`, which flags
whether a component is mutable, or immutable. If `Mutability= Mutable`,
the component is mutable. If `Mutability= Immutable`, the component is
immutable.
- Updated `derive_component` to default to mutable unless an
`#[component(immutable)]` attribute is added.
- Updated `ReflectComponent` to check if a component is mutable and, if
not, panic when attempting to mutate.
## Testing
- CI
- `immutable_components` example.
---
## Showcase
Users can now mark a component as `#[component(immutable)]` to prevent
safe mutation of a component while it is attached to an entity:
```rust
#[derive(Component)]
#[component(immutable)]
struct Foo {
// ...
}
```
This prevents creating an exclusive reference to the component while it
is attached to an entity. This is particularly powerful when combined
with component hooks, as you can now fully track a component's value,
ensuring whatever invariants you desire are upheld. Before this would be
done my making a component private, and manually creating a `QueryData`
implementation which only permitted read access.
<details>
<summary>Using immutable components as an index</summary>
```rust
/// This is an example of a component like [`Name`](bevy::prelude::Name), but immutable.
#[derive(Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash, Component)]
#[component(
immutable,
on_insert = on_insert_name,
on_replace = on_replace_name,
)]
pub struct Name(pub &'static str);
/// This index allows for O(1) lookups of an [`Entity`] by its [`Name`].
#[derive(Resource, Default)]
struct NameIndex {
name_to_entity: HashMap<Name, Entity>,
}
impl NameIndex {
fn get_entity(&self, name: &'static str) -> Option<Entity> {
self.name_to_entity.get(&Name(name)).copied()
}
}
fn on_insert_name(mut world: DeferredWorld<'_>, entity: Entity, _component: ComponentId) {
let Some(&name) = world.entity(entity).get::<Name>() else {
unreachable!()
};
let Some(mut index) = world.get_resource_mut::<NameIndex>() else {
return;
};
index.name_to_entity.insert(name, entity);
}
fn on_replace_name(mut world: DeferredWorld<'_>, entity: Entity, _component: ComponentId) {
let Some(&name) = world.entity(entity).get::<Name>() else {
unreachable!()
};
let Some(mut index) = world.get_resource_mut::<NameIndex>() else {
return;
};
index.name_to_entity.remove(&name);
}
// Setup our name index
world.init_resource::<NameIndex>();
// Spawn some entities!
let alyssa = world.spawn(Name("Alyssa")).id();
let javier = world.spawn(Name("Javier")).id();
// Check our index
let index = world.resource::<NameIndex>();
assert_eq!(index.get_entity("Alyssa"), Some(alyssa));
assert_eq!(index.get_entity("Javier"), Some(javier));
// Changing the name of an entity is also fully capture by our index
world.entity_mut(javier).insert(Name("Steven"));
// Javier changed their name to Steven
let steven = javier;
// Check our index
let index = world.resource::<NameIndex>();
assert_eq!(index.get_entity("Javier"), None);
assert_eq!(index.get_entity("Steven"), Some(steven));
```
</details>
Additionally, users can use `Component<Mutability = ...>` in trait
bounds to enforce that a component _is_ mutable or _is_ immutable. When
using `Component` as a trait bound without specifying `Mutability`, any
component is applicable. However, methods which only work on mutable or
immutable components are unavailable, since the compiler must be
pessimistic about the type.
## Migration Guide
- When implementing `Component` manually, you must now provide a type
for `Mutability`. The type `Mutable` provides equivalent behaviour to
earlier versions of `Component`:
```rust
impl Component for Foo {
type Mutability = Mutable;
// ...
}
```
- When working with generic components, you may need to specify that
your generic parameter implements `Component<Mutability = Mutable>`
rather than `Component` if you require mutable access to said component.
- The entity entry API has had to have some changes made to minimise
friction when working with immutable components. Methods which
previously returned a `Mut<T>` will now typically return an
`OccupiedEntry<T>` instead, requiring you to add an `into_mut()` to get
the `Mut<T>` item again.
## Draft Release Notes
Components can now be made immutable while stored within the ECS.
Components are the fundamental unit of data within an ECS, and Bevy
provides a number of ways to work with them that align with Rust's rules
around ownership and borrowing. One part of this is hooks, which allow
for defining custom behavior at key points in a component's lifecycle,
such as addition and removal. However, there is currently no way to
respond to _mutation_ of a component using hooks. The reasons for this
are quite technical, but to summarize, their addition poses a
significant challenge to Bevy's core promises around performance.
Without mutation hooks, it's relatively trivial to modify a component in
such a way that breaks invariants it intends to uphold. For example, you
can use `core::mem::swap` to swap the components of two entities,
bypassing the insertion and removal hooks.
This means the only way to react to this modification is via change
detection in a system, which then begs the question of what happens
_between_ that alteration and the next run of that system?
Alternatively, you could make your component private to prevent
mutation, but now you need to provide commands and a custom `QueryData`
implementation to allow users to interact with your component at all.
Immutable components solve this problem by preventing the creation of an
exclusive reference to the component entirely. Without an exclusive
reference, the only way to modify an immutable component is via removal
or replacement, which is fully captured by component hooks. To make a
component immutable, simply add `#[component(immutable)]`:
```rust
#[derive(Component)]
#[component(immutable)]
struct Foo {
// ...
}
```
When implementing `Component` manually, there is an associated type
`Mutability` which controls this behavior:
```rust
impl Component for Foo {
type Mutability = Mutable;
// ...
}
```
Note that this means when working with generic components, you may need
to specify that a component is mutable to gain access to certain
methods:
```rust
// Before
fn bar<C: Component>() {
// ...
}
// After
fn bar<C: Component<Mutability = Mutable>>() {
// ...
}
```
With this new tool, creating index components, or caching data on an
entity should be more user friendly, allowing libraries to provide APIs
relying on components and hooks to uphold their invariants.
## Notes
- ~~I've done my best to implement this feature, but I'm not happy with
how reflection has turned out. If any reflection SMEs know a way to
improve this situation I'd greatly appreciate it.~~ There is an
outstanding issue around the fallibility of mutable methods on
`ReflectComponent`, but the DX is largely unchanged from `main` now.
- I've attempted to prevent all safe mutable access to a component that
does not implement `Component<Mutability = Mutable>`, but there may
still be some methods I have missed. Please indicate so and I will
address them, as they are bugs.
- Unsafe is an escape hatch I am _not_ attempting to prevent. Whatever
you do with unsafe is between you and your compiler.
- I am marking this PR as ready, but I suspect it will undergo fairly
major revisions based on SME feedback.
- I've marked this PR as _Uncontroversial_ based on the feature, not the
implementation.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Benjamin Brienen <benjamin.brienen@outlook.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Co-authored-by: Nuutti Kotivuori <naked@iki.fi>
# Objective
Make documentation of a component's required components more visible by
moving it to the type's docs
## Solution
Change `#[require]` from a derive macro helper to an attribute macro.
Disadvantages:
- this silences any unused code warnings on the component, as it is used
by the macro!
- need to import `require` if not using the ecs prelude (I have not
included this in the migration guilde as Rust tooling already suggests
the fix)
---
## Showcase

---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
This patch adds the infrastructure necessary for Bevy to support
*bindless resources*, by adding a new `#[bindless]` attribute to
`AsBindGroup`.
Classically, only a single texture (or sampler, or buffer) can be
attached to each shader binding. This means that switching materials
requires breaking a batch and issuing a new drawcall, even if the mesh
is otherwise identical. This adds significant overhead not only in the
driver but also in `wgpu`, as switching bind groups increases the amount
of validation work that `wgpu` must do.
*Bindless resources* are the typical solution to this problem. Instead
of switching bindings between each texture, the renderer instead
supplies a large *array* of all textures in the scene up front, and the
material contains an index into that array. This pattern is repeated for
buffers and samplers as well. The renderer now no longer needs to switch
binding descriptor sets while drawing the scene.
Unfortunately, as things currently stand, this approach won't quite work
for Bevy. Two aspects of `wgpu` conspire to make this ideal approach
unacceptably slow:
1. In the DX12 backend, all binding arrays (bindless resources) must
have a constant size declared in the shader, and all textures in an
array must be bound to actual textures. Changing the size requires a
recompile.
2. Changing even one texture incurs revalidation of all textures, a
process that takes time that's linear in the total size of the binding
array.
This means that declaring a large array of textures big enough to
encompass the entire scene is presently unacceptably slow. For example,
if you declare 4096 textures, then `wgpu` will have to revalidate all
4096 textures if even a single one changes. This process can take
multiple frames.
To work around this problem, this PR groups bindless resources into
small *slabs* and maintains a free list for each. The size of each slab
for the bindless arrays associated with a material is specified via the
`#[bindless(N)]` attribute. For instance, consider the following
declaration:
```rust
#[derive(AsBindGroup)]
#[bindless(16)]
struct MyMaterial {
#[buffer(0)]
color: Vec4,
#[texture(1)]
#[sampler(2)]
diffuse: Handle<Image>,
}
```
The `#[bindless(N)]` attribute specifies that, if bindless arrays are
supported on the current platform, each resource becomes a binding array
of N instances of that resource. So, for `MyMaterial` above, the `color`
attribute is exposed to the shader as `binding_array<vec4<f32>, 16>`,
the `diffuse` texture is exposed to the shader as
`binding_array<texture_2d<f32>, 16>`, and the `diffuse` sampler is
exposed to the shader as `binding_array<sampler, 16>`. Inside the
material's vertex and fragment shaders, the applicable index is
available via the `material_bind_group_slot` field of the `Mesh`
structure. So, for instance, you can access the current color like so:
```wgsl
// `uniform` binding arrays are a non-sequitur, so `uniform` is automatically promoted
// to `storage` in bindless mode.
@group(2) @binding(0) var<storage> material_color: binding_array<Color, 4>;
...
@fragment
fn fragment(in: VertexOutput) -> @location(0) vec4<f32> {
let color = material_color[mesh[in.instance_index].material_bind_group_slot];
...
}
```
Note that portable shader code can't guarantee that the current platform
supports bindless textures. Indeed, bindless mode is only available in
Vulkan and DX12. The `BINDLESS` shader definition is available for your
use to determine whether you're on a bindless platform or not. Thus a
portable version of the shader above would look like:
```wgsl
#ifdef BINDLESS
@group(2) @binding(0) var<storage> material_color: binding_array<Color, 4>;
#else // BINDLESS
@group(2) @binding(0) var<uniform> material_color: Color;
#endif // BINDLESS
...
@fragment
fn fragment(in: VertexOutput) -> @location(0) vec4<f32> {
#ifdef BINDLESS
let color = material_color[mesh[in.instance_index].material_bind_group_slot];
#else // BINDLESS
let color = material_color;
#endif // BINDLESS
...
}
```
Importantly, this PR *doesn't* update `StandardMaterial` to be bindless.
So, for example, `scene_viewer` will currently not run any faster. I
intend to update `StandardMaterial` to use bindless mode in a follow-up
patch.
A new example, `shaders/shader_material_bindless`, has been added to
demonstrate how to use this new feature.
Here's a Tracy profile of `submit_graph_commands` of this patch and an
additional patch (not submitted yet) that makes `StandardMaterial` use
bindless. Red is those patches; yellow is `main`. The scene was Bistro
Exterior with a hack that forces all textures to opaque. You can see a
1.47x mean speedup.

## Migration Guide
* `RenderAssets::prepare_asset` now takes an `AssetId` parameter.
* Bin keys now have Bevy-specific material bind group indices instead of
`wgpu` material bind group IDs, as part of the bindless change. Use the
new `MaterialBindGroupAllocator` to map from bind group index to bind
group ID.
# Objective
Fixes#16531
I also added change detection when creating the pipeline, which
technically isn't needed but it felt weird leaving it as is.
## Solution
Remove the pipeline if CAS is disabled. The uniform was already being
removed, which caused flickering / weirdness.
## Testing
Tested the anti_alias example by toggling CAS a bunch on/off.