diff --git a/.dockerignore b/.dockerignore
index 08408d22..27ad7a81 100644
--- a/.dockerignore
+++ b/.dockerignore
@@ -28,4 +28,5 @@ assets/
docker/
data/
+data*/
output/
diff --git a/.readthedocs.yaml b/.readthedocs.yaml
index 7224eee9..d90ccf6c 100644
--- a/.readthedocs.yaml
+++ b/.readthedocs.yaml
@@ -30,5 +30,4 @@ formats:
# See https://docs.readthedocs.io/en/stable/guides/reproducible-builds.html
python:
install:
- - requirements: requirements.txt
- - requirements: docs/requirements.txt
\ No newline at end of file
+ - requirements: docs/requirements.txt
diff --git a/Dockerfile b/Dockerfile
index 72259949..4a6cc4b5 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -294,9 +294,8 @@ WORKDIR "$DATA_DIR"
VOLUME "$DATA_DIR"
EXPOSE 8000
-# Optional:
-# HEALTHCHECK --interval=30s --timeout=20s --retries=15 \
-# CMD curl --silent 'http://localhost:8000/admin/login/' || exit 1
+HEALTHCHECK --interval=30s --timeout=20s --retries=15 \
+ CMD curl --silent 'http://localhost:8000/health/' | grep -q 'OK'
ENTRYPOINT ["dumb-init", "--", "/app/bin/docker_entrypoint.sh"]
CMD ["archivebox", "server", "--quick-init", "0.0.0.0:8000"]
diff --git a/README.md b/README.md
index f298e392..a961cb47 100644
--- a/README.md
+++ b/README.md
@@ -408,7 +408,7 @@ See below for usage examples using the CLI, W
> *Warning: These are contributed by external volunteers and may lag behind the official `pip` channel.*
-- TrueNAS
+- TrueNAS: Official ArchiveBox TrueChart / Custom App Guide
- UnRaid
- Yunohost
- Cloudron
@@ -1441,23 +1441,62 @@ archivebox init --setup
-#### Make migrations or enter a django shell
+#### Make DB migrations, enter Django shell, other dev helper commands
Click to expand...
-Make sure to run this whenever you change things in `models.py`.
-
```bash
+# generate the database migrations after changes to models.py
cd archivebox/
./manage.py makemigrations
+# enter a python shell or a SQL shell
cd path/to/test/data/
archivebox shell
archivebox manage dbshell
+
+# generate a graph of the ORM models
+brew install graphviz
+pip install pydot graphviz
+archivebox manage graph_models -a -o orm.png
+open orm.png
+
+# list all models with field db info and methods
+archivebox manage list_model_info --all --signature --db-type --field-class
+
+# print all django settings
+archivebox manage print_settings
+archivebox manage print_settings --format=yaml # pip install pyyaml
+
+# autogenerate an admin.py from given app models
+archivebox manage admin_generator core > core/admin.py
+
+# dump db data to a script that re-populates it
+archivebox manage dumpscript core > scripts/testdata.py
+archivebox manage reset core
+archivebox manage runscript testdata
+
+# resetdb and clear all data!
+archivebox manage reset_db
+
+# use django-tui to interactively explore commands
+pip install django-tui
+# ensure django-tui is in INSTALLED_APPS: core/settings.py
+archivebox manage tui
+
+# show python and JS package dependency trees
+pdm list --tree
+npm ls --all
```
-(uses `pytest -s`)
-https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
+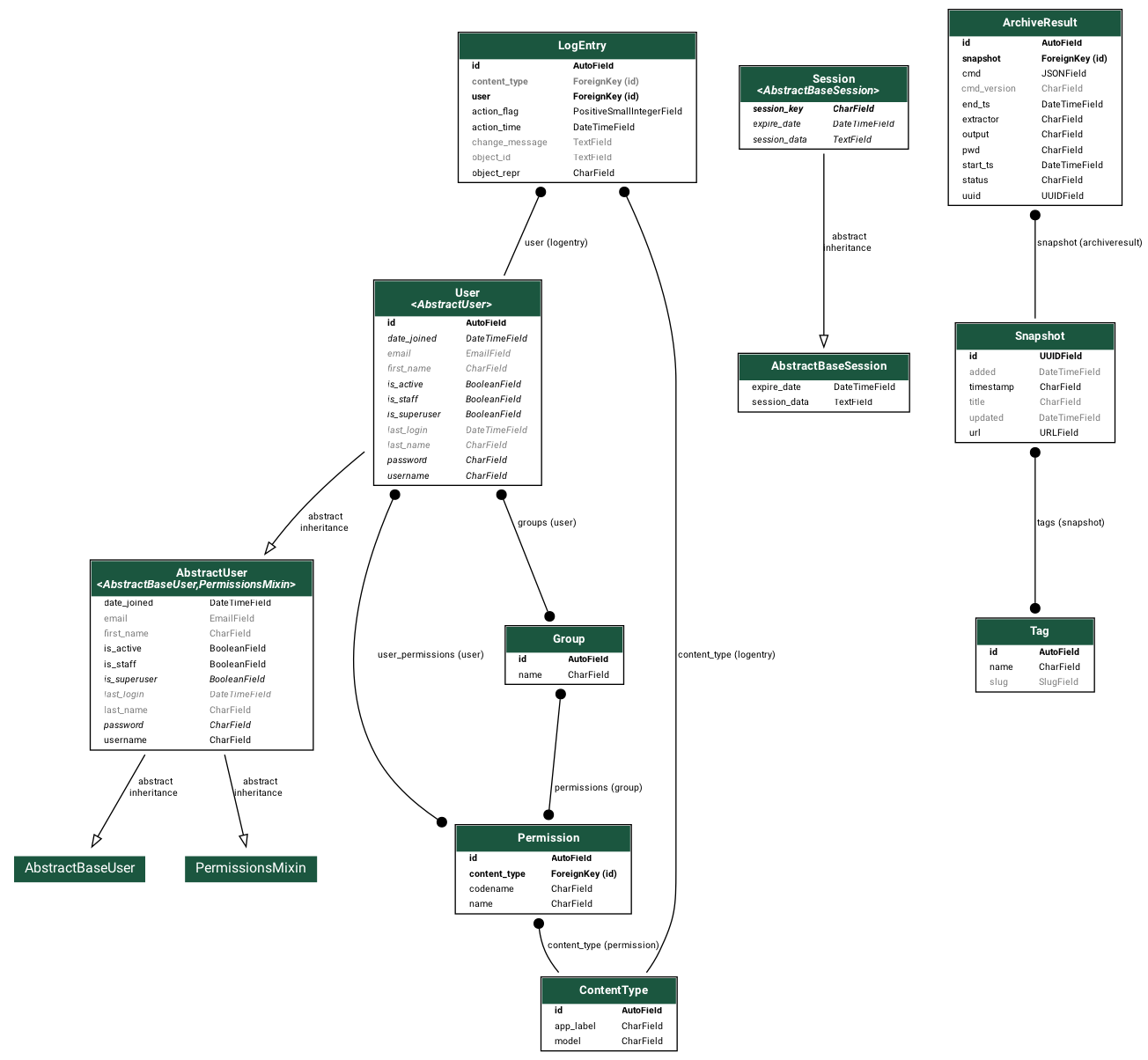 +
+- https://django-extensions.readthedocs.io/en/latest/command_extensions.html
+- https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
+- https://github.com/anze3db/django-tui (explore `manage.py` commands as TUI)
+- https://github.com/bloomberg/memray (advanced python profiler)
+- https://github.com/laixintao/flameshow (display flamegraphs in terminal)
+- https://github.com/taliraj/django-migrations-tui (explore migrations as TUI)
+
+- https://django-extensions.readthedocs.io/en/latest/command_extensions.html
+- https://stackoverflow.com/questions/1074212/how-can-i-see-the-raw-sql-queries-django-is-running
+- https://github.com/anze3db/django-tui (explore `manage.py` commands as TUI)
+- https://github.com/bloomberg/memray (advanced python profiler)
+- https://github.com/laixintao/flameshow (display flamegraphs in terminal)
+- https://github.com/taliraj/django-migrations-tui (explore migrations as TUI)